CDH集群离线配置python3环境,并安装pyhive、impyla、pyspark
背景:
项目需要对数仓千万级数据进行分析、算法建模。因数据安全,数据无法大批量导出,需在集群内进行分析建模,但CDH集群未安装python3 环境,需在无网情况下离线配置python3环境及一系列第三方库。
采取策略,使用外部联网linux环境创建python3虚拟环境,然后整体迁移集群环境。
文章目录
- 1. 外部机器和集群统一安装anaconda3环境[官网下载地址](https://www.anaconda.com/download#downloads)
- 2. 外部机器安装pyhive、impyla、pyspark、ipykernel
- 3. 环境迁移
- 4. 问题解决(坏的解释器:没有那个文件或目录)
- 5. jupyterlab 内核生成
- 6. pyhive、impyla连接测试
- 7. pyspark 对接CDH集群spark测试【pyspark版本要和集群CDH spark版本一致】
1. 外部机器和集群统一安装anaconda3环境官网下载地址
>> sh Anaconda3-2023.03-1-Linux-x86_64.sh
2. 外部机器安装pyhive、impyla、pyspark、ipykernel
>> conda create -n python3.7 python=3.7 # 创建py3.7虚拟环境,CDH集群spark2.4.0最高支持python3.7
>> conda activate python3.7 # 激活虚拟环境
>> pip install pyhive,impyla,pyspark # pip会自动安装thrif等依赖包,若报gcc等系统问题,具体问题百度分析
>> pip install ipykernel # 创建jupyter内核使用,使用jupyterlab远程进行数据分析
>> pip install scikit-learn、lightgbm # 安装其他需要第三方库
3. 环境迁移
外部机器/anaconda3/envs>> zip -r python3.7.zip ./python3.7 # 压缩整个虚拟环境
集群/anaconda3/envs>> unzip python3.7.zip # 大功告成
4. 问题解决(坏的解释器:没有那个文件或目录)
迁移后 >> ./pip 提示 找不到python解释器
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-NTKhm2QL-1692673902815)(C:\Users\zy\Desktop\集群离线配置python3+jupyterlab+pyspark+impyla.assets\image-20230801101207769.png)]](https://img-blog.csdnimg.cn/ec31b84345b047f19f2a950eccac453f.png)
迁移后 ipykernel 提示找不到python解释器
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-QvUlMG9n-1692673902816)(C:\Users\zy\Desktop\集群离线配置python3+jupyterlab+pyspark+impyla.assets\image-20230815102600598.png)]](https://img-blog.csdnimg.cn/e7185d05b17b4a56974eddbccf1b6dda.png)
解决:
进入envs/python3.7/bin 下,修改pip、pip3、ipykernel等命令内容,将第一行改为集群python对应路径。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-jGdIrACZ-1692673902816)(C:\Users\zy\Desktop\集群离线配置python3+jupyterlab+pyspark+impyla.assets\image-20230801101924909.png)]](https://img-blog.csdnimg.cn/8c0a1a530c3f435288e7f350309b675d.png)
5. jupyterlab 内核生成
#1 激活、退出虚拟环境
>> conda activate python3.7 [conda deactivate]#2. 虚拟环境下
>> ipython kernel install --user --name=python3.7#3. 重启jupyter-lab 查看即可
>> nohup ./jupyter-lab --allow-root > /data/xx/anaconda3/log.out &# 备注:jupyterlab 服务由anaconda3主环境base创建
>> jupyter-lab --generate-config (配置远程访问)
>> vim jupyter_lab_config.py
'''
c.ServerApp.ip = '0.0.0.0'
c.ServerApp.port = 8888
c.ServerApp.passwd = 8888
c.ServerApp.notebook_dir = '/data/xx/anaconda3/data'
c.ServerApp.open_browser = False
c.NotebookApp.passwords = {'user1': 'sha1:user1_password_hash', # >> python -c "from notebook.auth import passwd; print(passwd())" 生成用户密码'user2': 'sha1:user2_password_hash','user3': 'sha1:user3_password_hash'
}
'''
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-oZ45Demg-1692673902817)(C:\Users\zy\Desktop\集群离线配置python3+jupyterlab+pyspark+impyla.assets\image-20230822105553580.png)]](https://img-blog.csdnimg.cn/e409e6b2f0f64d3898f045cc3e52f39b.png)
6. pyhive、impyla连接测试
from pyhive import hive
from impala.dbapi import connect
from impala.util import as_pandas## python 读取数仓第一种方式 hive:jbdc
# pyhive 连接
conn = hive.Connection(host='namenode',port=10000,database='库名')
cursor = conn.cursor()# 执行查询
cursor.execute('desc user_info')
col_name = [i[0] for i in cursor.fetchall()]
cursor.execute('select * from user_info limit 2')
data = cursor.fetchall()
print(pd.DataFrame(data=data,columns=col_name))# 关闭hive连接
cursor.close()
conn.close()## python 读取数仓第二种方式 impala:jbdc
# 连接impala
conn = connect(host='namenode',port=21050,database='库名')
cursor = conn.cursor()# 执行查询
cursor.execute('select * from user_info where name is not null')
data = as_pandas(cursor)
备注:使用pyhive和impyla 读取数据,还是读取到一台集群节点内存上,速度慢,占内存,且分析比较困难,适合小批量处理。如处理千万级数据,还是使用pyspark进行并行分析。
7. pyspark 对接CDH集群spark测试【pyspark版本要和集群CDH spark版本一致】
## python 分析大量数据 pyspark
import os
from pyspark import SparkContext,SparkConf
from pyspark.sql import SparkSessionimport warnings
warnings.filterwarnings(action='ignore')# 制定集群spark、hadoop家目录os.environ['SPARK_HOME'] = '/opt/cloudera/parcels/CDH-6.3.4-1.cdh6.3.4.p0.6751098/lib/spark'
os.environ['HADOOP_CONF_DIR'] = '/opt/cloudera/parcels/CDH-6.3.4-1.cdh6.3.4.p0.6751098/lib/hadoop'
os.environ['PYSPARK_PYTHON'] = './py3/bin/python' parameters = [('spark.app.name','sklearn'),('spark.yarn.dist.files','hdfs://namenode:8020/python3/python3.7.zip#py3')('spark.master','yarn'),('spark.submit.deploymode','client'),]conf = SparkConf().setAll(parameters)
#sc = SparkContext.getOrCreate(conf=conf)
spark = SparkSession.builder.config(conf=conf).enableHiveSupport().getOrCreate()
spark![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-hcaapiDV-1692673902817)(C:\Users\zy\Desktop\集群离线配置python3+jupyterlab+pyspark+impyla.assets\image-20230822110440084.png)]](https://img-blog.csdnimg.cn/1e2a09f236a945cdb3bdab0b4e50200a.png)
备注:一般会报
Permission denied: user=root, access=WRITE, inode=“/user/spark/applicationHistory”:spark:spark:drwxr-xr-x 权限错误,
这是因为写代码得用户时jupyter服务启动用户,而CDH 中hadoop、hive、spark 文件的用户分别为hdfs、hive、spark用户。
相关文章:
CDH集群离线配置python3环境,并安装pyhive、impyla、pyspark
背景: 项目需要对数仓千万级数据进行分析、算法建模。因数据安全,数据无法大批量导出,需在集群内进行分析建模,但CDH集群未安装python3 环境,需在无网情况下离线配置python3环境及一系列第三方库。 采取策略…...
)
python并行操作(基于concurrent.futures.ThreadPoolExecutor)
文章目录 一、明确自身cpu可并行的核数二、根据所有任务计算在各个核上平均跑多少任务三、最后把任务划分在不同的核上跑四、拿来主义 此为利用cpu并行计算的能力,充分利用cpu在循环时并行计算。其实也是受C并行操作的影响,如果需要C版,可以移…...

Leetcode.73矩阵置零
给定一个 m x n 的矩阵,如果一个元素为 0 ,则将其所在行和列的所有元素都设为 0 。请使用 原地 算法 class Solution {public void setZeroes(int[][] matrix) {int m matrix.length, n matrix[0].length;boolean[] row new boolean[m];boolean[] col…...

jdk 04 stream的collect方法
01.收集(collect) collect,收集,可以说是内容最繁多、功能最丰富的部分了。 从字面上去理解,就是把一个流收集起来,最终可以是收集成一个值也可以收集成一个新的集合。 collect主要依赖java.util.stream.Collectors类内置的静态方…...

介绍REST API
REST (Representational State Transfer) 是一种基于 web 架构的 API 设计风格, 允许客户端应用程序通过 HTTP 请求与服务器进行交互。RESTful API就是按照REST风格设计的API。 RESTful API 的设计原则包括:使用统一资源标识符 (URI) 标识资源ÿ…...
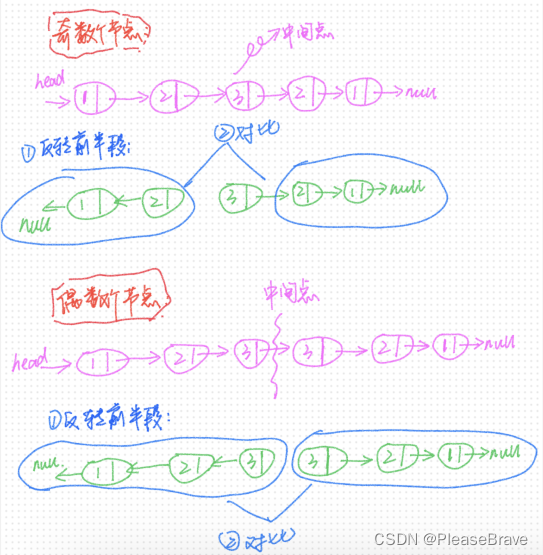
【leetcode 力扣刷题】反转链表+递归求解
反转链表递归求解 206. 反转链表解法①:取下一个节点在当前头节点前插入解法②:反转每个节点next的指向解法③:递归 92.反转链表Ⅱ反转left到right间节点的next指向 234.回文链表解法①:将链表元素存在数组中,在数组上…...

一文读懂Redis配置,史上真香配置
文章目录 基本配置项AOF持久化配置项RDB持久化配置项淘汰策略配置项主从复制配置项鸣谢 让那些总为redis连接异常的小白指引明灯,少走弯路。为那些不知道如何进行高级配置的大佬整一杯小酒。 基本配置项 bind:用于设置Redis绑定的IP地址。默认情况下&…...

maven打出jar中动态替换占位符
使用场景: maven打出的jar中pom.xml动态替换占位符 有些时候某些公共工具jar包被项目引用后发现公共jar的pom.xml中的version依然还是占位符,例如下面 <dependency><groupId>org.projectlombok</groupId><artifactId>lombok<…...

【Git游戏】通过游戏重新学习Git
在提交树上移动 HEAD HEAD:一个标志符号(通常情况下指向当前分支,间接指向当前最新的提交记录) 可以通过git checkout commitID从而指向提交记录 commitID 本身是一串哈希值(基于 SHA-1,共 40 位) 我们在…...

如何通过以太坊JSON-RPC方式获取ERC-20代币的信息?
目录 一、ERC-20介绍 二、ERC-20代币标准功能 1、可选功能 2、标准功能 三、获取代币信息...

线性代数的学习和整理4: 求逆矩阵的多种方法汇总
目录 原始问题:如何求逆矩阵? 1 EXCEL里,直接可以用黑盒表内公式 minverse() 数组公式求A- 2 非线性代数方法:解方程组的方法 3 增广矩阵的方法 4 用行列式的方法计算(未验证) 5 A-1/|A|*A* &…...

【C#学习笔记】匿名函数和lambda表达式
文章目录 匿名函数匿名函数的定义匿名函数作为参数传递匿名函数的缺点 lambda表达式什么是lambda表达式闭包 匿名函数 为什么我们要使用匿名函数?匿名函数存在的意义是为了简化一些函数的定义,特别是那些定义了之后只会被调用一次的函数,与其…...

百度Apollo:引领自动驾驶技术创新的先锋
文章目录 前言一、内容总结 前言 大家好,我是萝卜头不吃萝卜头,今天和大家分享一下我学习百度Apollo自动驾驶的心得。 在七月份的时候,我收到了Apollo开发者社区的邀请,进行学习Apollo自动驾驶汽车的2023星火培训训练,…...
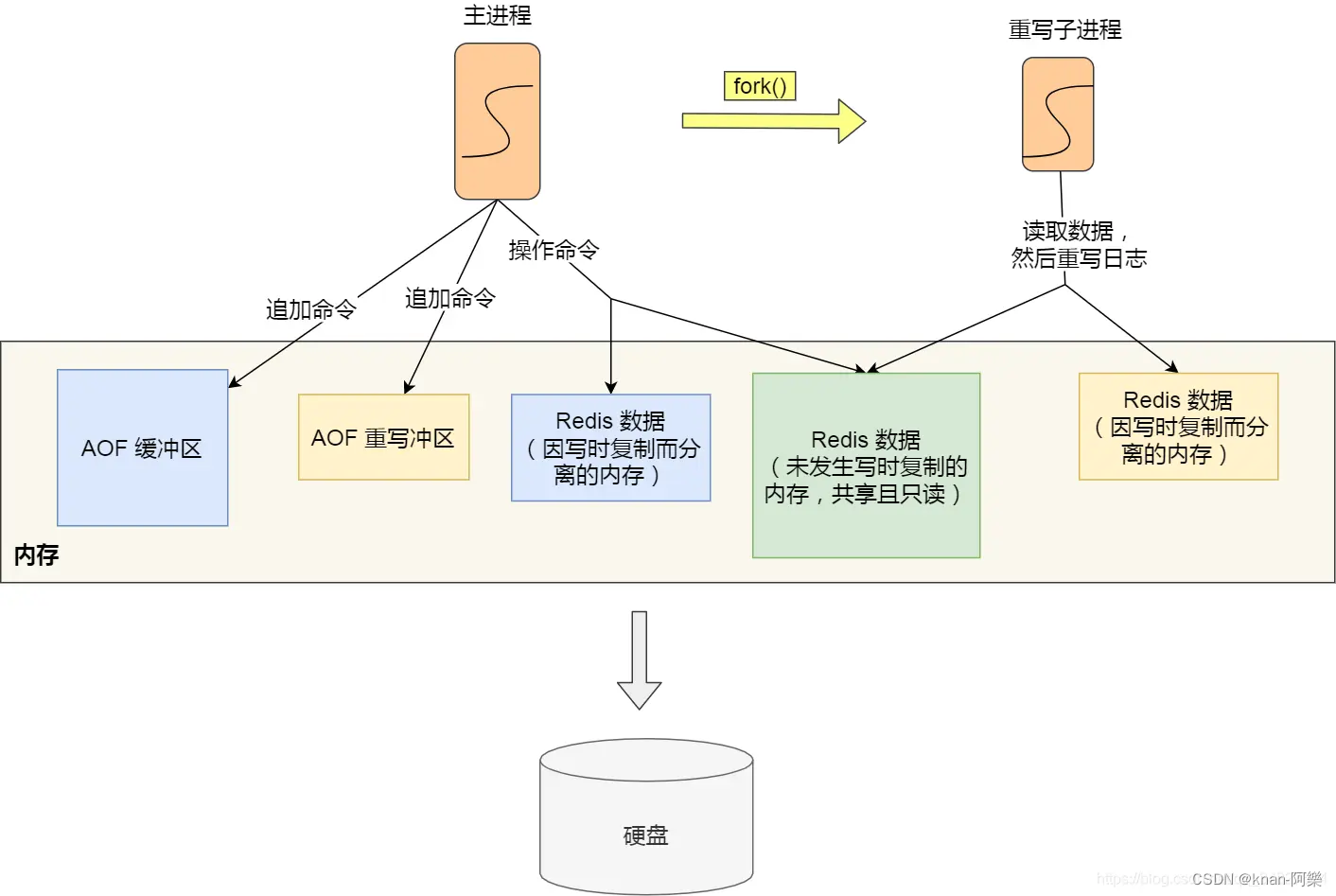
Redis 重写 AOF 日志期间,主进程可以正常处理命令吗?
重写 AOF 日志的过程是怎样的? Redis 的重写 AOF 过程是由后台子进程 bgrewriteaof 来完成的,这么做有以下两个好处。 子进程进行 AOF 重写期间,主进程可以继续处理命令请求,从而避免阻塞主进程子进程带有主进程的数据副本。这里…...
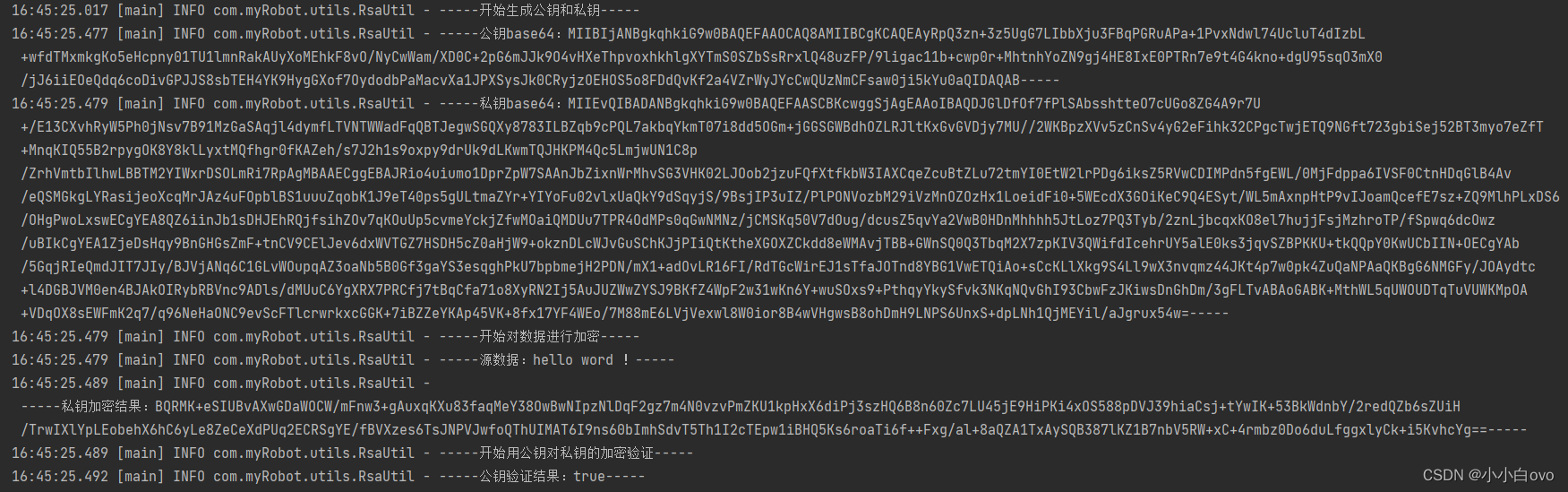
java实现生成RSA公私钥、SHA256withRSA加密以及验证工具类
前言: RSA属于非对称加密。所谓非对称加密,需要两个密钥:公钥 (publickey) 和私钥 (privatekey)。公钥和私钥是一对,如果用公钥对数据加密,那么只能用对应的私钥解密。如果用私钥对数据加密,只能用对应的公…...
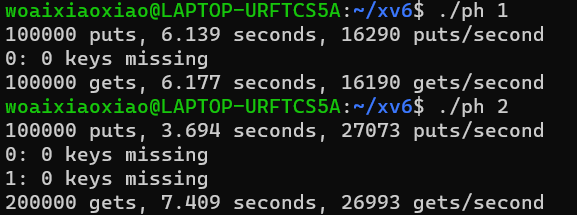
lab7 thread
文章目录 Uthread: switching between threadstaskhints思路上下文的恢复和保存thread_createthread_schedule Using threads思路 Barrier Uthread: switching between threads 在这个练习中,你将为一个用户级别线程系统设计上下文切换机制,并实现它。 …...

接口自动化测试:mock server之Moco工具
什么是mock server mock:英文可以翻译为模仿的,mock server是我们用来解除依赖(耦合),假装实现的技术,比如说,前端需要使用某些api进行调试,但是服务端并没有开发完成这些api&#…...
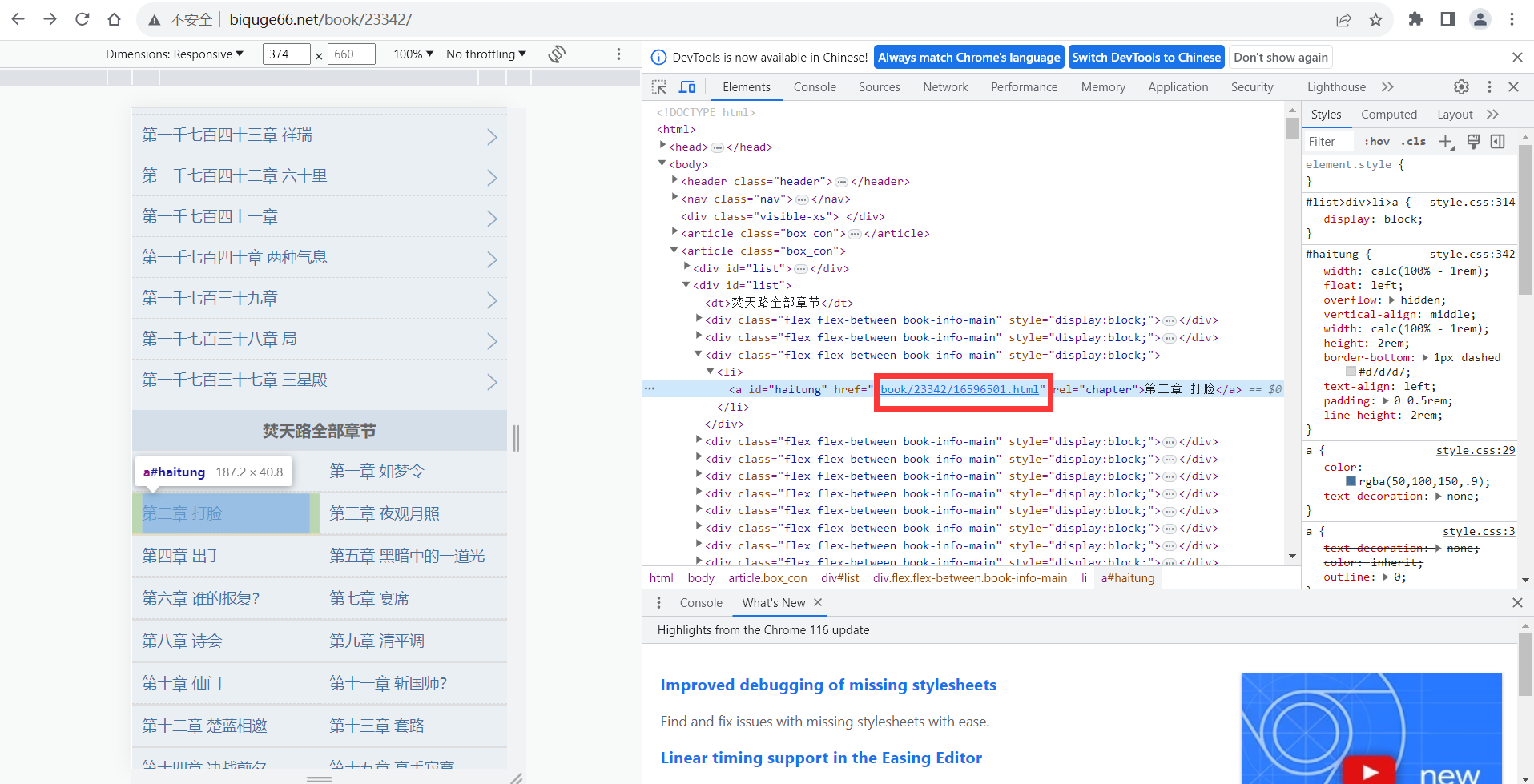
用python从零开始做一个最简单的小说爬虫带GUI界面(2/3)
目录 前一章博客 前言 主函数的代码实现 逐行代码解析 获取链接 获取标题 获取网页源代码 获取各个文章的链接 函数的代码 导入库文件 获取文章的标题 获取文章的源代码 提取文章目录的各个文章的链接 总代码 下一章内容 前一章博客 用python从零开始做一个最简单…...

CEF 缓存处理:清理缓存、禁用缓存、忽略缓存
目录 一、CEF缓存处理 1、指定缓存路径 2、清理缓存 3、禁用缓存 1)、原理分析...
Android 系统桌面 App —— Launcher 开发(1)
Android 系统桌面 App —— Launcher 开发(1) Launcher简介 Launcher就是Android系统的桌面,俗称“HomeScreen”也就是我们开机后看到的第一个App。launcher其实就是一个app,它的作用是显示和管理手机上其他App。目前市场上有很…...

PDPI Spec:规格驱动开发协议,让AI编程告别“氛围编码”
1. 项目概述:从“感觉对了”到“规格对了”在软件开发的江湖里,我们可能都经历过这样的场景:产品经理丢过来一个模糊的需求,开发同学凭着一腔热血和“感觉对了”的直觉,一头扎进代码里。几周后,功能上线了&…...

音频AI DSP:低功耗边缘智能的硬件架构与实现
1. 项目概述:当音频AI遇见边缘DSP几年前,如果有人告诉我,一个比指甲盖还小的芯片,能在不到1毫瓦的功耗下,持续监听环境声音、识别特定关键词,甚至能分辨出你是在嘈杂的餐厅还是在安静的办公室,我…...

Taotoken模型广场如何帮助开发者快速选型,对比主流模型特性
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken模型广场如何帮助开发者快速选型,对比主流模型特性 对于需要接入大模型能力的开发者而言,面对市场…...

ComfyUI ControlNet Aux预处理器深度解析:从模型下载到性能优化全攻略
ComfyUI ControlNet Aux预处理器深度解析:从模型下载到性能优化全攻略 【免费下载链接】comfyui_controlnet_aux ComfyUIs ControlNet Auxiliary Preprocessors 项目地址: https://gitcode.com/gh_mirrors/co/comfyui_controlnet_aux ComfyUI ControlNet Aux…...

APK安装器完整指南:在Windows上轻松安装安卓应用的终极方案
APK安装器完整指南:在Windows上轻松安装安卓应用的终极方案 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 你是否想在Windows电脑上直接运行手机应用&…...

FanControl终极指南:5步解决Windows风扇噪音与过热难题
FanControl终极指南:5步解决Windows风扇噪音与过热难题 【免费下载链接】FanControl.Releases This is the release repository for Fan Control, a highly customizable fan controlling software for Windows. 项目地址: https://gitcode.com/GitHub_Trending/f…...

别让答辩 PPT 拖垮你的毕业季!PaperXie AI 帮你把论文成果 “说清楚”
paperxie-免费查重复率aigc检测/开题报告/毕业论文/智能排版/文献综述/AI PPThttps://www.paperxie.cn/ppt/createhttps://www.paperxie.cn/ppt/create 论文查重过了、导师意见改完了,你以为毕业的最后一关只剩答辩?可打开 PPT 的瞬间,很多人…...

如何轻松解决软件授权难题?智能授权管理脚本全解析
如何轻松解决软件授权难题?智能授权管理脚本全解析 【免费下载链接】KMS_VL_ALL_AIO Smart Activation Script 项目地址: https://gitcode.com/gh_mirrors/km/KMS_VL_ALL_AIO 你是否曾经遇到过这样的情况:重要的办公软件突然提示授权过期…...

别再死记硬背了!我用这5个C语言内存模型的实际案例,搞懂了嵌入式面试的底层逻辑
从崩溃现场到面试答案:5个嵌入式开发中的内存实战案例 凌晨三点的调试灯依然亮着,屏幕上的十六进制数字像某种神秘代码——这是许多嵌入式开发者都熟悉的场景。当系统突然崩溃,内存错误往往是最难追踪的幽灵问题。但有趣的是,这些…...

OpenClaw 长期使用避坑指南:环境稳定性维护、数据备份策略、版本兼容处理全方案
OpenClaw 长期使用避坑指南:环境稳定性维护、数据备份策略、版本兼容处理全方案引言OpenClaw 作为一款强大的开源自动化抓取与数据处理平台,因其灵活性、可定制性和社区支持,在众多领域如数据采集、RPA(机器人流程自动化ÿ…...