基于Hive的河北新冠确诊人数分析系统的设计与实现
项目描述
临近学期结束,还是毕业设计,你还在做java程序网络编程,期末作业,老师的作业要求觉得大了吗?不知道毕业设计该怎么办?网页功能的数量是否太多?没有合适的类型或系统?等等。这里根据疫情当下,你想解决的问题,今天给大家介绍一篇基于Hive的河北新冠确诊人数分析系统的设计与实现。
功能需求
首先要采集数据,采用脚本定时采集的那种,用java程序,先转化为用tab键分割的文本数据,然后导入hive中;
其次是在hive中对导进来的数据进行处理过滤,再建几个表,把处理结果存到新建的表里,然后把hive处理结果的数据表导入mysql中;这样做完一次后,开始写脚本,每隔一天采集一次数据,hive处理数据一次,mysql统计数据一次;
接着就是编程,用ssm框架连接到mysql,对数据用javaBean进行封装,用mvc模式将部分数据显示到前台页面;
最后用echarts对封装的数据进行数据可视化,可以做成条形图,折线图,饼图,气泡图,地图等可视化图标。
数据清理流程:
- 首先执行GetData.jar写好的程序获取数据,会自动生成txt数据文件在/home/kt/devHive/data文件夹里面
- 然后执行导入数据到建好的hive表里面的脚本
- 接着执行sql,sql会执行clean.sql里面的加工数据的hql语句,会将清理好的数据导入Ed的清洁hive表中
- 接着执行hiveToMySql.sh,将Ed表里面的清洁数据用sqoop导入对应的MySQL表中(会清空 *Ed 的所有数据)
- 最后可以用远程连接获取MySQL里的数据
部分效果图
数据库设计
hive对数据处理筛选,导入MySQL
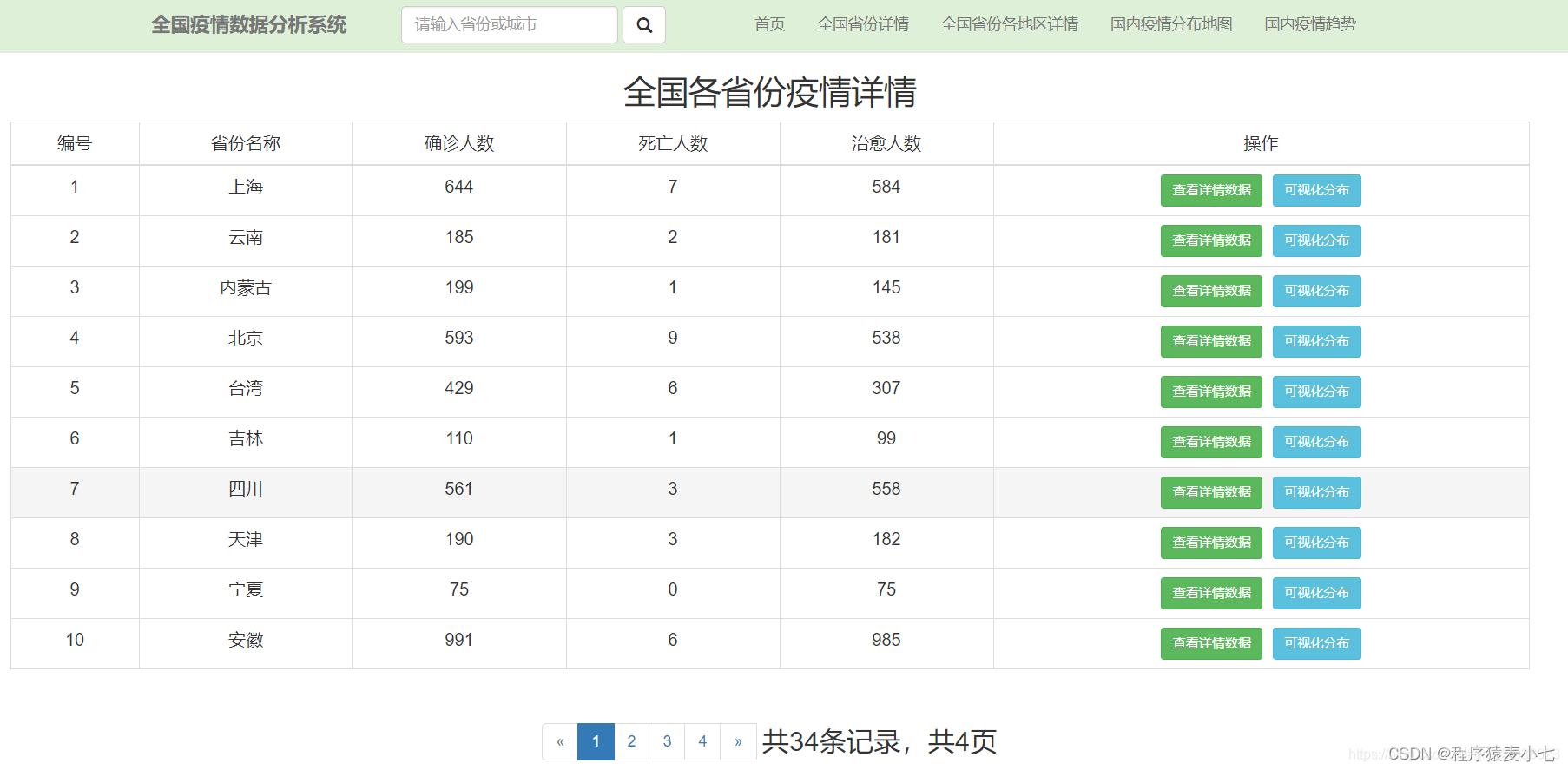
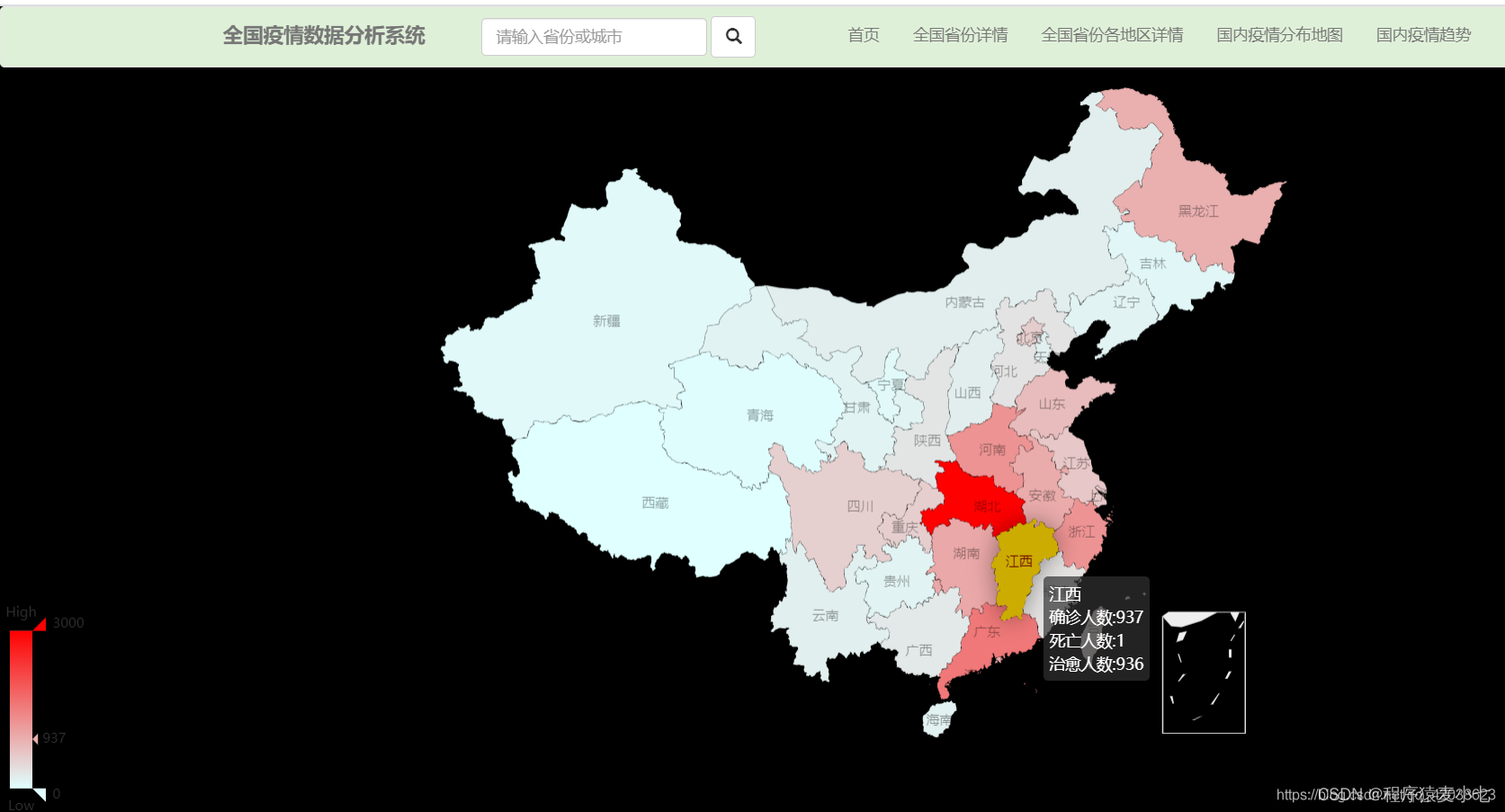
1. 河北疫情分布地图
确诊病例
死亡病例
治愈病例
create table provinceEd(
provinceName string,
confirmedNum int,
deathsNum int,
curesNum int
)
row format delimited fields terminated by ‘\t’;
2. 各个地区的疫情分布地图
确诊病例
死亡病例
治愈病例
create table areaEd(
provinceName string,
cityName string,
confirmedCount int,
deadCount int,
curedCount int
)
row format delimited fields terminated by ‘\t’;
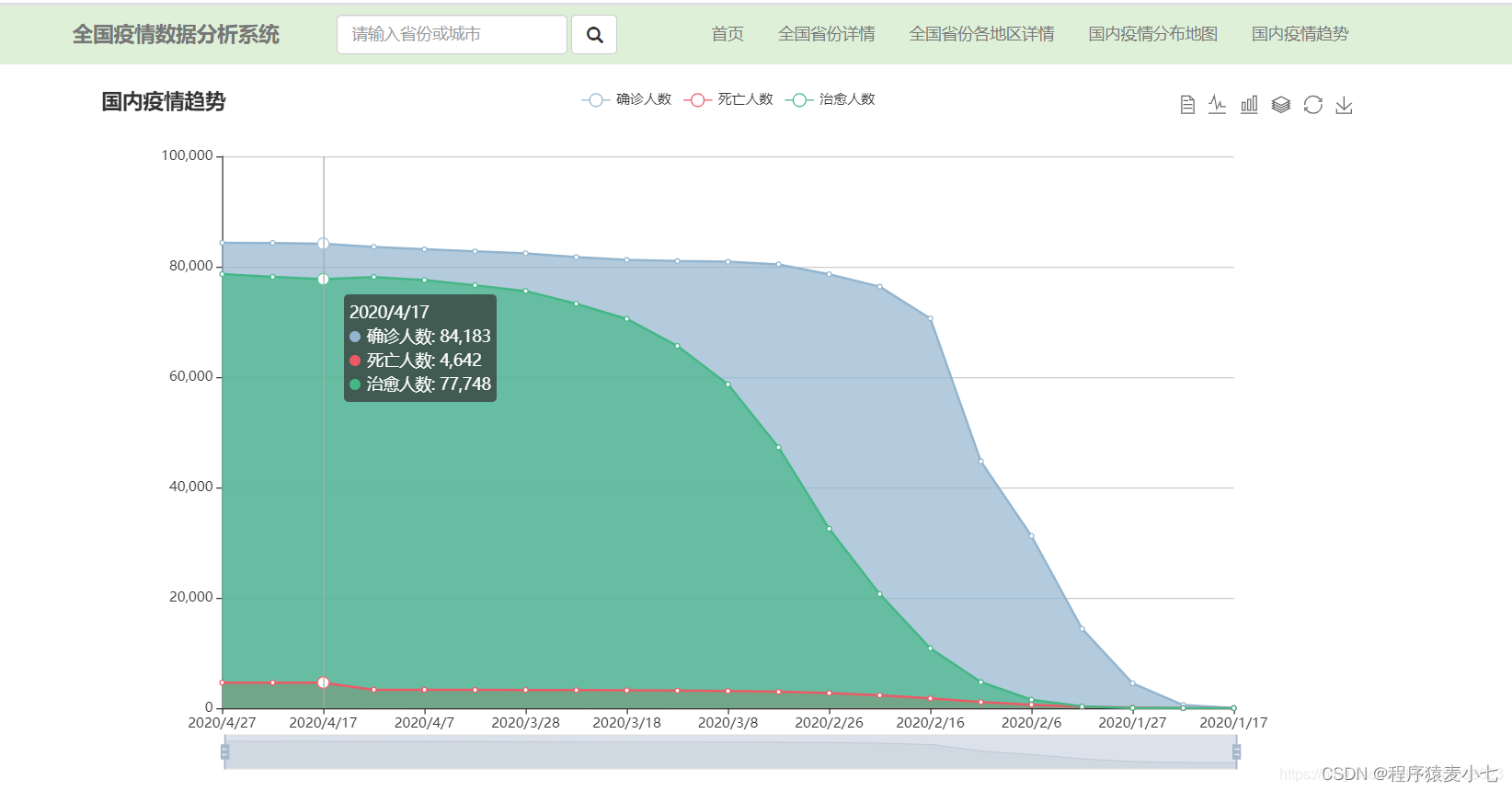
3. 国内疫情趋势
确诊病例
死亡病例
治愈病例
create table historyEd(
date string,
confirmedNum int,
deathsNum int,
curesNum int
)
row format delimited fields terminated by ‘\t’;
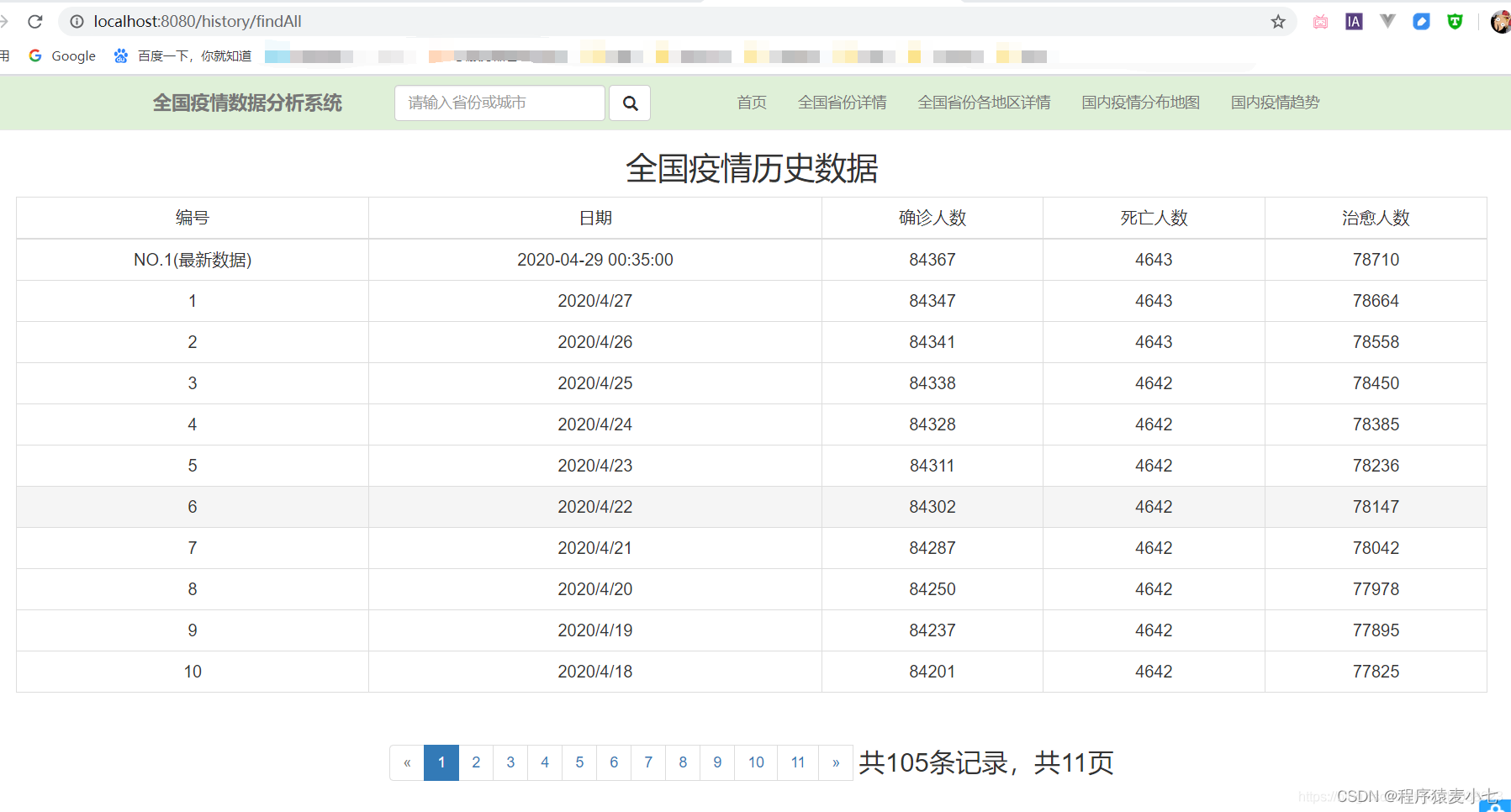
4. 各市地区疫情的表格
(用historyEd,带有全国数据的最新数据totlaed)
#建表语句
CREATE TABLE totalEd(
date string,
diagnosed int,
death int,
cured int
)
row format delimited fields terminated by ‘\t’;
5. 一个新闻的专栏
pubData 具体时间
title 新闻标题
summary 新闻详情
infoSource 新闻来源
sourceUrl 新闻正文链接传送
CREATE TABLE newsEd(
pubDate string,
title string,
summary string,
infoSource string,
sourceUrl string,
provinceName string
)
row format delimited fields terminated by ‘\t’;
脚本
1. 导入数据的hql语句(load.sql)
set hive.exec.mode.local.auto=true;
set hive.support.sql11.reserved.keywords=false;
use kongtao;
load data local inpath ‘/home/kt/devHive/data/history.txt’ overwrite into table history;
load data local inpath ‘/home/kt/devHive/data/total.txt’ overwrite into table total;
load data local inpath ‘/home/kt/devHive/data/province.txt’ overwrite into table province;
load data local inpath ‘/home/kt/devHive/data/area.txt’ overwrite into table area;
load data local inpath ‘/home/kt/devHive/data/news.txt’ overwrite into table news;
2. 获取数据的脚本 getData.sh
#!/bin/bash
. /etc/profile
HIVE_HOME=/app/hive/
yesterday=date -d -0days '+%Y%m%d'
hour=date -d -0hour '+%H'
echo $yesterday
HIVEHOME/bin/hive−−hiveconfdailyparam={HIVE_HOME}/bin/hive --hiveconf daily_param=HIVEHOME/bin/hive−−hiveconfdailyparam={yesterday}
–hiveconf hour_param=${hour}
-f /home/kt/devHive/0425/loa.sql
date >> /var/log/httpd/hivetToMysql.log
echo yesterday{yesterday}yesterday{hour} >> /home/kt/devHive/log/hivetToMysql.log
3. clean.sql语句脚本
set hive.exec.mode.local.auto=true;
set hive.support.sql11.reserved.keywords=false;
insert into table kongtao.provinceEd
select provinceName,confirmedNum,deathsNum,curesNum from province;
insert into table kongtao.areaEd
select provinceName, cityName, confirmedCount,deadCount,curedCount from area;
insert into table kongtao.historyEd
select date, confirmedNum, deathsNum,curesNum from history;
insert into table kongtao.totalEd
select date, diagnosed, death,cured from total;
insert into table kongtao.newsEd
select pubDate, title, summary,infoSource,sourceUrl,provinceName from news;
4. 定时执行clean.sql的语句 sql.sh
#!/bin/bash
. /etc/profile
HIVE_HOME=/app/hive/
yesterday=`date -d -0days '+%Y%m%d'`
hour=`date -d -0hour '+%H'`
echo $yesterday
${HIVE_HOME}/bin/hive --hiveconf daily_param=${yesterday} \
--hiveconf hour_param=${hour} \-f /home/kt/devHive/0425/clean.sql
date >> /var/log/httpd/hivetToMysql.log
echo ${yesterday}${hour} >> /home/kt/devHive/log/hivetToMysql.log
hive -e "use ${kongtao};select * from province;"
chmod +x sql.sh
- 定时执行hive导入MySQL的语句
注意:MySQL建表的时候要设置字符编码,否则会字符不匹配导不进去
ENGINE=InnoDB DEFAULT CHARSET=utf8
sqoop导入hive数据到MySql碰到hive表中列的值如果为null的情况,hive中为null的是以\N代替的,所以你在导入到MySql时,需要加上两个参数:–input-null-string ‘\N’ --input-null-non-string ‘\N’,多加一个’',是为转义
#!/bin/bash
. /etc/profile
先清楚表中的所有数据
host="kt01"
port="3306"
userName="root"
password="123456"
dbname="kongtao"
dbset="--default-character-set=utf8 -A"
先清空所有的表,保证数据不重复
cmd="
truncate table areaEd;
truncate table historyEd;
truncate table totalEd;
truncate table provinceEd;
"mysql -h${host} -u${userName} -p${password} ${dbname} -P${port} -e "${cmd}"
导入areaed表
sqoop export
–connect “jdbc:mysql://kt01:3306/kongtao?useUnicode=true&characterEncoding=utf-8”
–username root
–password 123456
–table areaEd
–num-mappers 1
–input-fields-terminated-by “\t”
–export-dir /user/hive/warehouse/kongtao.db/areaed
导入historyed表
sqoop export
–connect “jdbc:mysql://kt01:3306/kongtao?useUnicode=true&characterEncoding=utf-8”
–username root
–password 123456
–table historyEd
–num-mappers 1
–input-fields-terminated-by “\t”
–export-dir /user/hive/warehouse/kongtao.db/historyed
#导入totaled表
sqoop export
–connect “jdbc:mysql://kt01:3306/kongtao?useUnicode=true&characterEncoding=utf-8”
–username root
–password 123456
–table totalEd
–num-mappers 1
–input-fields-terminated-by “\t”
–export-dir /user/hive/warehouse/kongtao.db/totaled
导入provinceed表
sqoop export \
--connect "jdbc:mysql://kt01:3306/kongtao?useUnicode=true&characterEncoding=utf-8" \
--username root \
--password 123456 \
--table provinceEd \
--num-mappers 1 \
--input-fields-terminated-by "\t" \
--export-dir /user/hive/warehouse/kongtao.db/provinceed/app/hadoop/bin/hdfs dfs -rm -r /user/hive/warehouse/kongtao.db/*eddate >> /home/kt/devHive/log/hivetToMysql.log
chmod +x hiveToMySql.sh
数据清理流程
首先执行GetData.jar写好的程序获取数据,会自动生成txt数据文件在/home/kt/devHive/data文件夹里面
然后执行导入数据到建好的hive表里面的脚本
接着执行sql,sql会执行clean.sql里面的加工数据的hql语句,会将清理好的数据导入*Ed的清洁hive表中
接着执行hiveToMySql.sh,将Ed表里面的清洁数据用sqoop导入对应的MySQL表中(会清空 Ed 的所有数据)
最后可以用远程连接获取MySQL里的数据
给脚本设置定时器
crontab -e
30 8 * * * /home/kt/devHive/0425/getData.sh
32 8 * * * /home/kt/devHive/0425/sql.sh
34 8 * * * /home/kt/devHive/0425/hiveToMySql.sh
相关文章:
基于Hive的河北新冠确诊人数分析系统的设计与实现
项目描述 临近学期结束,还是毕业设计,你还在做java程序网络编程,期末作业,老师的作业要求觉得大了吗?不知道毕业设计该怎么办?网页功能的数量是否太多?没有合适的类型或系统?等等。这里根据疫情当下,你想解决的问…...

k8s二进制部署
目录 一、环境准备 常见的k8s部署方式 关闭防火墙 关闭selinux 关闭swap 根据规划设置主机名 在master添加hosts 将桥接的IPv4流量传递到iptables的链 时间同步 二、部署etcd集群 1、master节点部署 #查看证书的信息 上传etcd-cert.sh 和etcd.sh 到/opt/k8s/ 目录…...
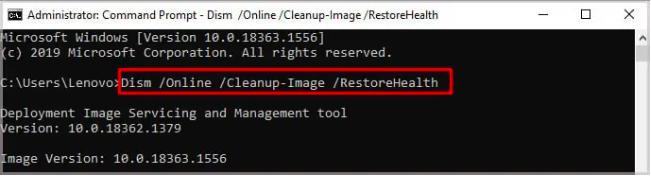
Windows出现0xc00d36e5错误怎么办?
当我们使用Windows Media Player来播放视频文件时,可能会出现无法播放,并显示0xc00d36e5错误代码。该错误可能是因为Windows Media Player不支持视频格式、注册表项损坏、系统配置问题、第三方应用程序冲突等。下面将开始介绍0xc00d36e5错误的解决方法&a…...
Idea搭建Spring5.3.x源码阅读环境
1. 概述 Spring是一个轻量级Java开源框架,在Java项目开发过程中已经离不开Spring全家桶了,包括Spring、SpringBoot、SpringCloud等,学习好Spring基础源码也有助于更好在项目中使用Spring相关组件,在学习源码前需要搭建好源码学习…...

2.20jdbc
一.数据库编程的必备条件编程语言:java c c Python数据库 Oracle,MySQL,SQL Server数据库驱动包:不同的数据库,对应不同的编程语言提供了不同的数据库驱动包:MySQL提供了Java的驱动包mysqlconnector-java,需要就Java操作MySQL需要该驱动包二.Java的数据库编程JDBC,即…...
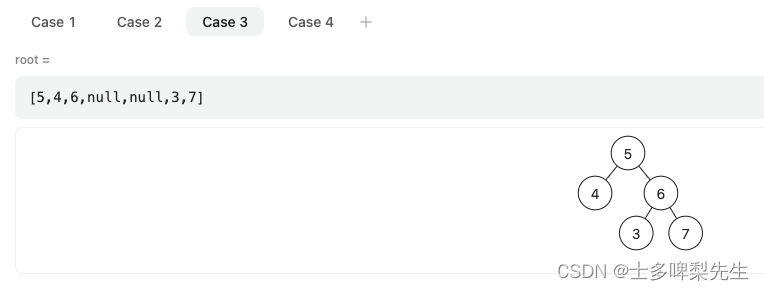
【代码随想录训练营】【Day19休息】【Day20】第六章|二叉树|654.最大二叉树|617.合并二叉树|700.二叉搜索树中的搜索|98.验证二叉搜索树
最大二叉树 题目详细:LeetCode.654 这道题在题目几乎就说明了解题的思路了: 创建一个根节点,其值为 nums 中的最大值;递归地在最大值左边的子数组上构建左子树;递归地在最大值右边的子数组上构建右子树;…...
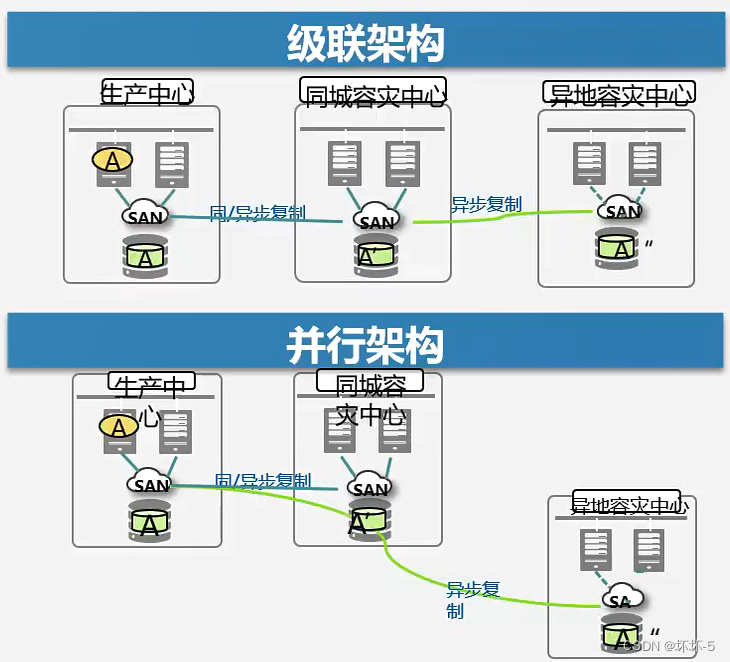
华为云计算之容灾技术
容灾是物理上的容错技术,不是逻辑上的容错同步远程复制:主备距离≤200km,只有在主备设备上都写成功,才会告诉主机写成功,不会丢失数据异步远程复制:主备距离>200km,只要主设备上写成…...

React系列之Redux
1 Redux概述 Redux 是 JavaScript 状态容器,提供可预测化的状态管理。Redux中文文档 Redux 和react没有必然关系,redux可以应用于各种框架,包括jquery,甚至js都可以使用redux,只不过redux和react更加搭配。redux也推…...

最简单得方法解决TCP分包粘包问题
如何用最简单的方法解决TCP传输中的分包粘包问题? 首先需要说明一点,分包粘包等等一系列的问题并不是协议本身存在的问题,而是程序员在写代码的时候,没有搞清楚数据的边界导致的。 看个简单的例子,TCP客户端不断的向服…...
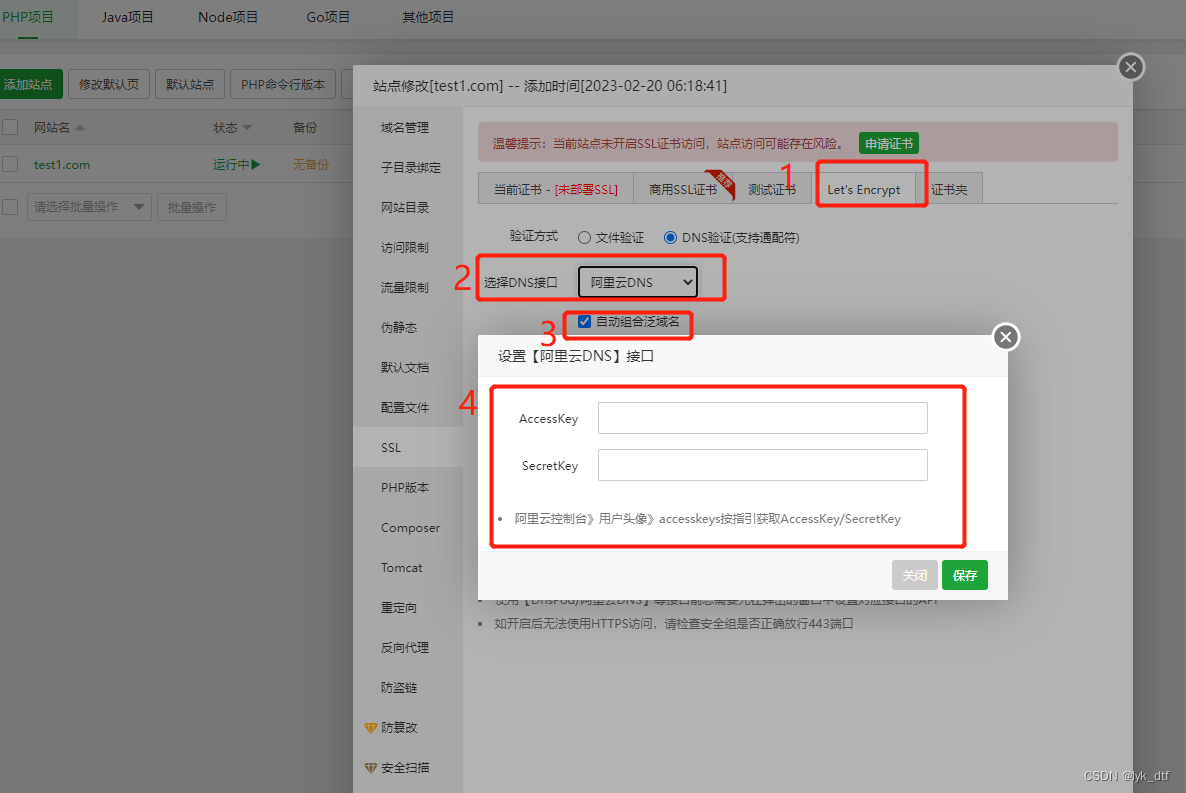
免费使用通配符域名证书
文章目录前言一、手动安装acme.sh操作1、安装acme.sh2、使用dns api自动续签二、宝塔自动操作【推荐】总结前言 之前个人站点一般都是使用阿里云免费单域名证书,虽然好用但是只有一年有效,到期只能手动重新申请,并且每次弄个子域名出来就要重…...

0基础成功转行Python自动化测试工程师,年薪30W+,经验总结都在这(建议收藏)
两年前的决定我觉得还是非常正确的,就是自学了python,然后学习了自动化测试、性能测试、框架、持续集成,同时也把前面的软件测试基础知识全部补全了。目前的收入还比较满意,月入2W(仅代表个人收入),13薪&am…...

MyBaits
MyBaitsMyBaits的jar包介绍MyBaits的入门案例创建实体java日志处理框架常用的日志处理框架Log4j的日志级别Mybatis配置的完善Mybatis的日志管理使用别名alias方式一方式二SqlSession对象下的常用API查询操作Mapper动态代理Mapper 动态代理规范查询所有用户根据用户ID查询用户Ma…...
kubeadm的部署、Dashboard UI以及连接私有仓库
目录 一、kubeadm 部署 K8S 集群架构 1、环境准备 2、所有节点安装docker 3、所有节点安装kubeadm,kubelet和kubectl 3、部署K8S集群 二、dashboard 部署 1、 安装dashboard 2、使用火狐或者360浏览器访问 三 、安装Harbor私有仓库 四、 内核参数优化方案 …...

刷题记录:牛客NC20325[SDOI2009]HH的项链
传送门:牛客 题目描述: HH有一串由各种漂亮的贝壳组成的项链。 HH相信不同的贝壳会带来好运,所以每次散步完后,他都会随意取出一 段贝壳,思考它们所表达的含义。 HH不断地收集新的贝壳,因此他的项链变得越来越长。 有一天&#…...

【REACT-路由v6】
REACT-路由v61. App.js2. 搭建路由2.1 普通写法2.2 使用useRoutes构建路由2.3 重定向封装2.4 嵌套路由中的组件Outlet3. 导航跳转3.2 声明式导航(NavLink标签)3.2 编程式导航跳转(useNavigate)3.2.1 获取参数3.2.1.1 useSearchPar…...
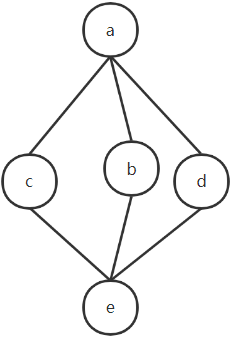
【离散数学】3. 代数系统
1.数理逻辑 2. 集合论 3. 代数系统 4. 图论 代数系统:把一些形式上很不相同的代数系统,用统一的方法描述、研究、推理,从而得到反映出他们共性的一些结论,在将结论运用到具体的代数系统中 系统:运算研究对象 运算&…...

深度学习常用的优化器整理
常见优化器整理 一、SGD(随机梯度下降) 公式: 经典的mini-batch SGD使用的很多,效果也比较不错,但是存在一部分问题 选择恰当的初始学习率很困难学习率调整策略受限于预先制定的调整规则相同的学习率被应用于各个参数…...

Java 内部类
文章目录1、初识内部类2、非静态内部类(实例内部类)3、静态内部类(重点)4、内部类的使用5、局部内部类6、匿名内部类1、初识内部类 如果一个事物的内部包含另一个事物,那么这是一个类的内部包含另一个类。 例如&…...
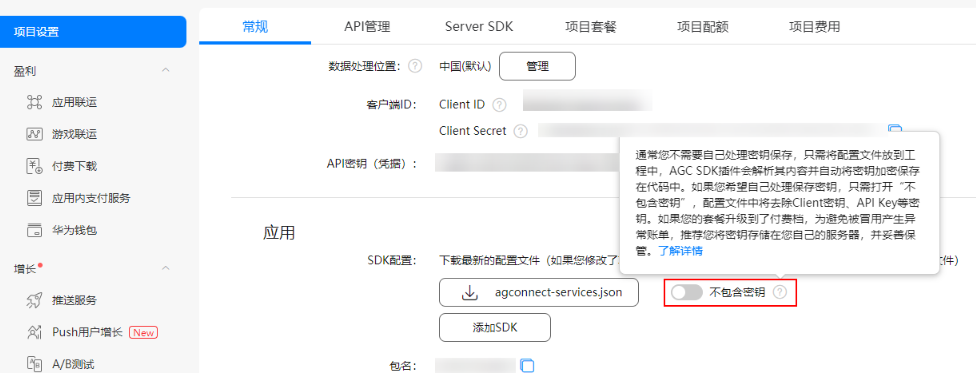
【FAQ】集成分析服务的常见问题及解决方案
常见问题一:如何验证Analytics是否上报/接入成功?以及关键日志含义是什么? 在初始化Analytics SDK前添加SDK日志开关如下: HiAnalyticsTools.enableLog (); 2.初始化SDK代码如下: HiAnalyticsInstance instance Hi…...

11.注意力机制
11.注意力机制 目录 注意力提示 查询、键和值 注意力的可视化 注意力汇聚:Nadaraya-Watson 核回归 生成数据集 非参注意力池化层 Nadaraya-Watson核回归 参数化的注意力机制 批量矩阵乘法 定义模型 训练 注意力评分函数 掩蔽softmax操作 加性注意力 缩…...

Side-Menu.iOS高级定制:打造个性化菜单样式和交互体验的完整指南
Side-Menu.iOS高级定制:打造个性化菜单样式和交互体验的完整指南 【免费下载链接】Side-Menu.iOS Animated side menu with customizable UI 项目地址: https://gitcode.com/gh_mirrors/si/Side-Menu.iOS 想要为你的iOS应用添加一个炫酷的侧边菜单吗…...

突破8大平台限制:开源工具实现高速下载的3种创新方案
突破8大平台限制:开源工具实现高速下载的3种创新方案 【免费下载链接】Online-disk-direct-link-download-assistant 一个基于 JavaScript 的网盘文件下载地址获取工具。基于【网盘直链下载助手】修改 ,支持 百度网盘 / 阿里云盘 / 中国移动云盘 / 天翼云…...

实战指南:基于快马平台与comfyui,快速构建带姿势控制的人像卡通化应用
今天想和大家分享一个特别实用的技术方案:如何用ComfyUI快速搭建一个带姿势控制的人像卡通化应用。这个方案特别适合需要批量生成统一风格头像、制作产品海报等场景,我自己在实际工作中就经常用到。 首先说说为什么选择ComfyUI。它是一个基于节点的工作流…...

BRV自定义扩展开发:从零构建专属列表组件的终极教程
BRV自定义扩展开发:从零构建专属列表组件的终极教程 【免费下载链接】BRV [永久维护] Android 快速构建 RecyclerView, 比 BRVAH 更简单强大 项目地址: https://gitcode.com/gh_mirrors/br/BRV 想要在Android开发中快速构建功能强大的RecyclerView列表吗&…...

Mac窗口置顶终极指南:用Topit解锁你的多任务超能力 [特殊字符]
Mac窗口置顶终极指南:用Topit解锁你的多任务超能力 🚀 【免费下载链接】Topit Pin any window to the top of your screen / 在Mac上将你的任何窗口强制置顶 项目地址: https://gitcode.com/gh_mirrors/to/Topit 还在为频繁切换窗口而烦恼&#x…...

学术论文利器:使用LaTeX撰写cv_unet_image-colorization技术报告与实验图表
学术论文利器:使用LaTeX撰写cv_unet_image-colorization技术报告与实验图表 写技术报告或者论文,尤其是涉及图像处理、深度学习这类需要大量公式和图表的领域,你是不是也遇到过这些烦恼?用Word排版,公式稍微复杂一点就…...

CPU fallback方案:Qwen3-4B-Instruct-2507低算力环境适配
CPU fallback方案:Qwen3-4B-Instruct-2507低算力环境适配 1. 引言:当大模型遇上小算力 想象一下,你拿到一个功能强大的新模型,参数高达40亿,支持26万字的超长上下文,指令理解和逻辑推理能力都大幅提升。你…...

OpenClaw+gemma-3-12b-it内容助手:自动生成技术文章与排版
OpenClawgemma-3-12b-it内容助手:自动生成技术文章与排版 1. 为什么需要自动化内容生产线 作为技术自媒体创作者,我每周需要产出3-5篇深度技术文章。传统写作流程中,最耗时的不是核心内容创作,而是反复调整格式、插入代码块、优…...

OpenClaw+千问3.5-35B-A3B-FP8:个人知识库自动化更新系统
OpenClaw千问3.5-35B-A3B-FP8:个人知识库自动化更新系统 1. 为什么需要自动化知识库更新 作为一个长期依赖个人知识库的技术写作者,我深刻体会到手动维护知识库的痛点。每当遇到新资料,我需要经历"阅读→摘录→分类→归档"的全流…...

Qwen-Image-Edit快速上手:模糊图片变清晰,效果惊艳实测
Qwen-Image-Edit快速上手:模糊图片变清晰,效果惊艳实测 1. 引言:从模糊到清晰的魔法 你是否遇到过这样的困扰?手机里珍藏的老照片变得模糊不清,或是抓拍的精彩瞬间因为手抖而糊成一片。传统修图软件对这些模糊图片往…...