【深度学习-seq2seq模型-附核心encoder和decoder代码】
深度学习
- 深度学习-seq2seq模型
- 什么是seq2seq模型
- 应用场景
- 架构
- 编码器
- 解码器
- 训练 & 预测
- 损失
- 预测
- 评估BLEU
- BELU背后的数学意义
- 模型参考论文
深度学习-seq2seq模型
本文的网络架构模型参考 Sutskever et al., 2014以及Cho et al., 2014
什么是seq2seq模型
Sequence to sequence (seq2seq)是由encoder(编码器)和decoder(解码器)两个RNN组成的(注意本文中的RNN指代所有的循环神经网络,包括RNN、GRU、LSTM等)。
其中encoder负责对输入句子的理解,输出context vector(上下文变量)给decoder,decoder负责对理解后的句子的向量进行处理,解码,获得输出
应用场景
主要用来处理输入和输出序列长度不定的问题,在之前的RNN一文中,RNN的分类讲解过,其中就包括多对多结构,这个seq2seq模型就是典型的多对多,还是长度不一致的多对多,它的应用有很多场景,比如机器翻译,机器人问答,文章摘要,由关键字生成对话等等
例如翻译场景:
【hey took the little cat to the animal center】-> [他们把这只小猫送到了动物中心]
输入和输出长度没法一致
架构

整个架构是编码器-解码器结构
编码器
一般都是一个普通的RNN结构,不需要特殊的实现
class Encoder(nn.Module):"""用于序列到序列学习的循环神经网络 编码器"""def __init__(self, vocab_size, embed_size, num_hiddens, num_layers,dropout=0, **kwargs):super(Encoder, self).__init__(**kwargs)self.embedding = nn.Embedding(vocab_size, embed_size)self.gru = nn.GRU(embed_size, num_hiddens, num_layers, dropout=dropout)def forward(self, X, *args):# input shape (batchsize, num_steps)-> (batchsize, num_steps, embedingdim)X = self.embedding(X)# 交换dim,pythorch要求batchsize位置X = X.permute(1, 0, 2)# encode编码# out的形状 (num_steps, batch_size, num_hiddens)# state的形状: (num_layers, batch_size, num_hiddens)output, state = self.gru(X)return output, state
解码器
在 (Sutskever et al., 2014)的设计:
输入序列的编码信息送入到解码器中来生成输出序列的。
(Cho et al., 2014)设计: 编码器最终的隐状态在每一个时间步都作为解码器的输入序列的一部分。
上面架构图中展示的正式这种设计
在解码器中,在训练的时候比较特殊,可以允许真实值(标签)成为原始的输出序列, 从源序列词元“”“Ils”“regardent”“.” 到新序列词元 “Ils”“regardent”“.”“”来移动预测的位置。
解码器
class Decoder(nn.Module):"""用于序列到序列学习的循环神经网络 解码器"""def __init__(self, vocab_size, embed_size, num_hiddens, num_layers,dropout=0, **kwargs):super(Decoder, self).__init__(**kwargs)self.embedding = nn.Embedding(vocab_size, embed_size)# 与普通gru区别:input_size增加num_hiddens,用于input输入解码器encode的输出self.rnn = nn.GRU(embed_size + num_hiddens, num_hiddens, num_layers, dropout=dropout)self.dense = nn.Linear(num_hiddens, vocab_size)def init_state(self, enc_outputs):# 初始化decode的hidden, 使用enc_outputs[1],enc_outputs格式(output, hidden state)return enc_outputs[1]def forward(self, X, state):""":param X: input, shape is (num_steps, batch_size, embed_size):param state: hidden state, shape is( num_layers,batch_size, num_hiddens):return:"""# 输出'X'的形状:(batch_size,num_steps,embed_size)X = self.embedding(X).permute(1, 0, 2)# 广播state的0维,使它与X具有相同的num_steps的维度,方便后续拼接,输出context的shape(num_steps, batch_size, num_hiddens)context = state[-1].repeat(X.shape[0], 1, 1)# conect input and context (num_steps, batch_size, embed_size+num_hiddens)x_and_context = torch.cat((X, context), 2)# output的形状:(num_steps, batch_size, num_hiddens)# state的形状:(num_layers,batch_size,num_hiddens)output, state = self.rnn(x_and_context, state)# output的形状(batch_size,num_steps,vocab_size)output = self.dense(output).permute(1, 0, 2)return output, state训练 & 预测
def train(net, data_iter, lr, num_epochs, tgt_vocab, device):net.to(device)loss = MaskedSoftmaxCELoss()optimizer = torch.optim.Adam(net.parameters(), lr=lr)for epoch in range(num_epochs):num_tokens = 0total_loss = 0for batch in data_iter:optimizer.zero_grad()X, X_valid_len, Y, Y_valid_len = [x.to(device) for x in batch]bos = torch.tensor([tgt_vocab['<bos>']] * Y.shape[0],device=device).reshape(-1, 1)dec_input = torch.cat([bos, Y[:, :-1]], 1) # 强制教学Y_hat, _ = net(X, dec_input)# Y_hat的形状(batch_size,num_steps,vocab_size)# Y的形状batch_size,num_steps# loss内部permute Y_hat = Y_hat.permute(0, 2, 1)l = loss(Y_hat, Y, Y_valid_len)# 损失函数的标量进行“反向传播”l.sum().backward()#梯度裁剪grad_clipping(net, 1)#梯度更新optimizer.step()num_tokens = Y_valid_len.sum()total_loss = l.sum()print('epoch{}, loss{:.3f}'.format(epoch, total_loss/num_tokens))
损失
这里特别的说明一下,NLP中的损失通常用的都是基于交叉熵损失的masksoftmax损失,它只是在交叉熵损失的基础上封装了一点,mask了pad填充的词元,这个损失函数的意思,举个例子说明一下:
假设解码器的lable是【they are watching】,通常会用unk等pad这些句子到一定的长度,这个长度是代码中由你自行指定的,也是decoder的num_steps,比如我们设置了10,那么此时整个输入会被pad成【they are wathing unk unk unk unk unk unk unk eos】,但是计算损失的时候,我们不需要计算这部分,对应的损失需要置为0
预测
预测与评估的过程相同,但是稍有不同的是,预测过程不知道真实的输出标签,所以都是用上一步的预测值来作为下一个时间步的输入的。这里不再复述
评估BLEU
与其他输出固定的评估不一样,这次是一个句子的评估,常用的方法是:BLEU(bilingual evaluation understudy),最早用于机器翻译,现在也是被广泛用于各种其他的领域
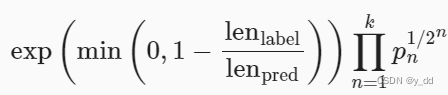
BLEU的评估都是n-grams词元是否出现在标签序列中
lenlable表示标签序列中的词元数和
lenlpred表示预测序列中的词元数
pn 预测序列与标签序列中匹配的n元词元的数量, 与 预测序列中
n元语法的数量的比率
BELU肯定是越大越好,最好的情况肯定是1,那就是完全匹配
举个例子:给定标签序列A B C D E F 和预测序列 A B B C D
lenlable是6
lenlpred是5
p1 1元词元在lable和 pred中匹配的数量 B C D 也就是4 与 预测序列中1元词元个数 5 也就是0.8
其他pi也是依次计算 i 从1取到预测长度 -1 (也就是4)分别计算出来是3/4 1/3和0
前面的)
BLUE实现简单,此处也不再展现代码了
BELU背后的数学意义
首先后面概率相加的这部分:
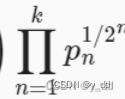
n元词法,当n越长则匹配难度越大, 所以BLEU为更长的元语法的精确度分配更大的权重,否则一个不完全匹配的句子可能会比全匹配的概率更大,这里就表现为,n越大,pn1/2n就越大
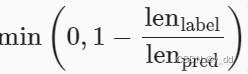
这一项是惩罚项,越短的句子就会降低belu分数,比如
给定标签序列A B C D E F 和预测序列 A B 和ABC 虽然p1 和p2 都是1,惩罚因此会降低短序列的分数
篇幅有限,代码无法一一展现,如果需要全部代码的小伙伴可以私信我
模型参考论文
Sutskever, I., Vinyals, O., & Le, Q. V. (2014). Sequence to sequence learning with neural networks. Advances in neural information processing systems (pp. 3104–3112).
Cho et al., 2014a
Cho, K., Van Merriënboer, B., Bahdanau, D., & Bengio, Y. (2014). On the properties of neural machine translation: encoder-decoder approaches. arXiv preprint arXiv:1409.1259.
Cho et al., 2014b
Cho, K., Van Merriënboer, B., Gulcehre, C., Bahdanau, D., Bougares, F., Schwenk, H., & Bengio, Y. (2014). Learning phrase representations using rnn encoder-decoder for statistical machine translation. arXiv preprint arXiv:1406.1078.
李沐 动手深度学习
相关文章:
【深度学习-seq2seq模型-附核心encoder和decoder代码】
深度学习 深度学习-seq2seq模型什么是seq2seq模型应用场景架构编码器解码器训练 & 预测损失预测评估BLEUBELU背后的数学意义 模型参考论文 深度学习-seq2seq模型 本文的网络架构模型参考 Sutskever et al., 2014以及Cho et al., 2014 什么是seq2seq模型 Sequence to seq…...
videojs 实现自定义组件(视频画质/清晰度切换) React
前言 最近使用videojs作为视频处理第三方库,用来对接m3u8视频类型。这里总结一下自定义组件遇到的问题及实现,目前看了许多文章也不全,官方文档写的也不是很详细,自己摸索了一段时间陆陆续续完成了,这是实现后的效果.…...

python 模块urllib3 HTTP 客户端库
官网文档地址:https://urllib3.readthedocs.io/en/stable/reference/index.html 一、安装 pip install urlib3二、基本使用 import urllib3 import threadingimg_list ["https://pic.netbian.com/uploads/allimg/220211/004115-1644511275bc26.jpg",&…...

2023 CCPC 华为云计算挑战赛 D-塔
首先先来看第一轮的 假如有n个,每轮那k个 他们的高度的可能性分别为 n 1/C(n,k) n1 C(n-(k-11),1)/C(n,k) n2 C(n-(k-21),2)/C(n,k) ni C(n-(k-i1,i)/C(n,k) 通过概率和高度算出第一轮增加的期望 然后乘上m轮增加的高度加上初始高度,就是总共增加的高度 下面是…...

手搓大模型值just gru
这些类是构建神经网络模型的有用工具,并提供了一些关键功能: EmAdd类使文本输入数据嵌入成为可能,在自然语言处理任务中被广泛使用。通过屏蔽处理填充序列的能力对许多应用程序也很重要。 HeadLoss类是训练神经网络模型进行分类任务的常见损失函数。它计算损失和准确率的能力…...

eslint
什么是eslint ESLint 是一个根据方案识别并报告 ECMAScript/JavaScript 代码问题的工具,其目的是使代码风格更加一致并避免错误。 安装eslint npm init eslint/config执行后会有很多选项,按照自己的需求去选择就好,运行成功后会生成 .esli…...
node_modules.cache是什么东西
一开始没明白这是啥玩意,还以为是npm的属性,网上也没说过具体的来源出处 .cache文件的产生是由webpack4的插件cache-loader生成的,node_modules里下载了cache-loader插件,很多朋友都是vuecli工具生成的项目,内置了这部…...

Python 包管理(pip、conda)基本使用指南
Python 包管理 概述 介绍 Python 有丰富的开源的第三方库和包,可以帮助完成各种任务,扩展 Python 的功能,例如 NumPy 用于科学计算,Pandas 用于数据处理,Matplotlib 用于绘图等。在开始编写 Pytlhon 程序之前&#…...
技术如何助力智能化应用发展呢?)
系统级封装(SiP)技术如何助力智能化应用发展呢?
智能化时代,各种智能设备、智能互连的高速发展与跨界融合,需要高密度、高性能的微系统集成技术作为重要支撑。 例如,在系统级封装(SiP)技术的加持下,5G手机的射频电路面积更小,但支持的频段更多…...
)
git配置代理(github配置代理)
命令行配置代理方式一git config --global http.proxy http://代理服务器地址:端口号git config --global https.proxy https://代理服务器地址:端口号如果有用户名密码按照下面命令配置 git config --global http.proxy http://用户名:密码代理服务器地址:端口号git config --…...
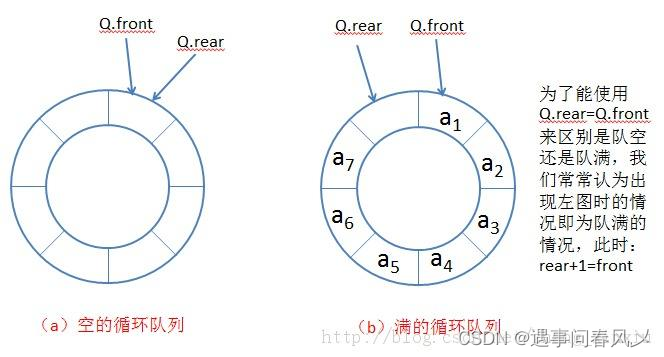
【数据结构】详解环形队列
文章目录 🌏引言🍀[循环队列](https://leetcode.cn/problems/design-circular-queue/description/)🐱👤题目描述🐱👓示例:🐱🐉提示🐱🏍思…...

Python爬取网页详细教程:从入门到进阶
【导言】: Python作为一门强大的编程语言,常常被用于编写网络爬虫程序。本篇文章将为大家详细介绍Python爬取网页的整个流程,从安装Python和必要的库开始,到发送HTTP请求、解析HTML页面,再到提取和处理数据࿰…...
linux安装JDK及hadoop运行环境搭建
1.linux中安装jdk (1)下载JDK至opt/install目录下,opt下创建目录soft,并解压至当前目录 tar xvf ./jdk-8u321-linux-x64.tar.gz -C /opt/soft/ (2)改名 (3)配置环境变量…...
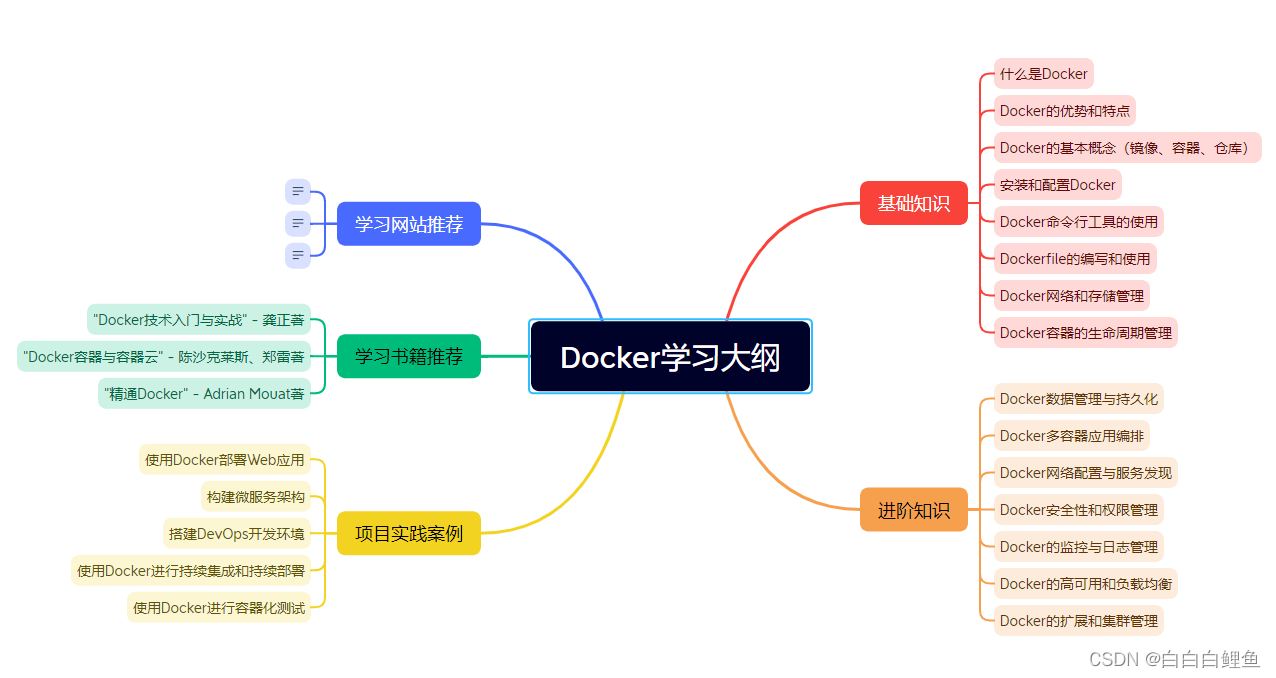
使用ChatGPT一键生成思维导图
指令1:接下来你回复的所有内容,都放到Markdown代码框中。 指令2:作为一个Docker专家,为我编写一个详细全面的Docker学习大纲,包括基础知识、进阶知识、项目实践案例,学习书籍推荐、学习网站推荐等…...

极简Vim教程
2023年8月27日,周日上午 我不想学那么多命令和快捷键,够用就行... 所以就把我自己认为比较常用的命令和快捷键记录成博客 目录 预备知识Vim的工作模式保存内容退出Vim复制、粘贴和剪切选中一段内容复制粘贴剪切撤回和反撤回撤回反撤回查找替换删除删除…...

在线帮助中心也属于知识管理的一种吗?
在线帮助中心是企业或组织为了提供客户支持而建立的一个在线平台,它包含了各种类型的知识和信息,旨在帮助用户解决问题和获取相关的信息。从知识管理的角度来看,可以说在线帮助中心也属于知识管理的一种形式。下面将详细介绍在线帮助中心作为…...

《Linux从练气到飞升》No.18 进程终止
🕺作者: 主页 我的专栏C语言从0到1探秘C数据结构从0到1探秘Linux菜鸟刷题集 😘欢迎关注:👍点赞🙌收藏✍️留言 🏇码字不易,你的👍点赞🙌收藏❤️关注对我真的…...
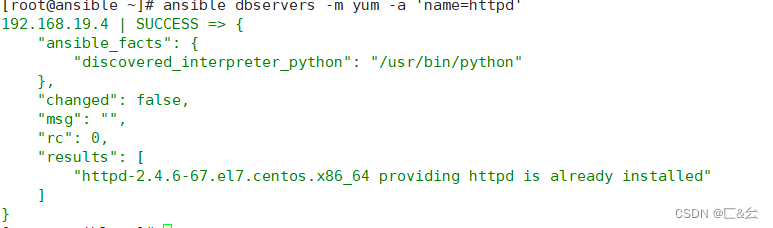
自动化运维工具——ansible安装及模块介绍
目录 一、ansible——自动化运维工具 1.1 Ansible 自动运维工具特点 1.2 Ansible 运维工具原理 二、安装ansible 三、ansible命令模块 3.1 command模块 3.2 shell模块 3.3 cron模块 3.4 user模块 3.5 group 模块 3.6 copy模块 3.7 file模块 3.8 ping模…...
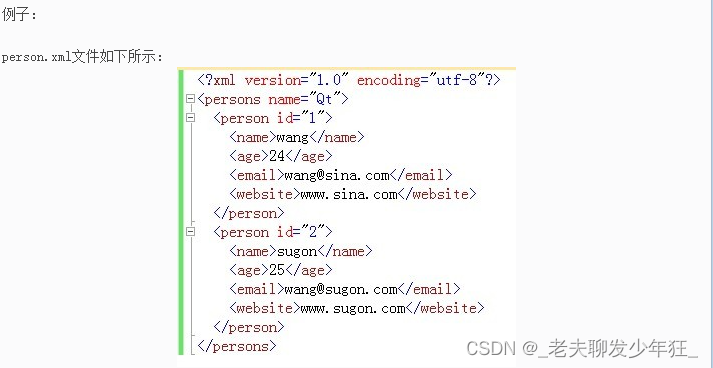
Qt XML文件解析 QDomDocument
QtXml模块提供了一个读写XML文件的流,解析方法包含DOM和SAX,两者的区别是什么呢? DOM(Document Object Model):将XML文件保存为树的形式,操作简单,便于访问。 SAX(Simple API for …...
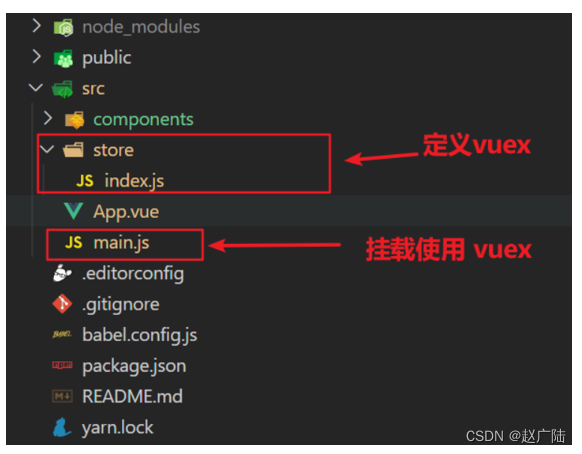
Vue2向Vue3过度Vuex状态管理工具快速入门
目录 1 Vuex概述1.是什么2.使用场景3.优势4.注意: 2 需求: 多组件共享数据1.创建项目2.创建三个组件, 目录如下3.源代码如下 3 vuex 的使用 - 创建仓库1.安装 vuex2.新建 store/index.js 专门存放 vuex3.创建仓库 store/index.js4 在 main.js 中导入挂载到 Vue 实例…...

SIM800C模块硬件连接避坑指南:从USB-TTL调试到STM32F407实战接线
SIM800C模块硬件连接避坑指南:从USB-TTL调试到STM32F407实战接线 在嵌入式开发中,GSM模块的硬件连接往往是项目成功的第一步,也是最容易踩坑的环节。SIM800C作为一款经典的工业级GSM/GPRS模块,其稳定性和性价比备受开发者青睐&…...
)
PSIM 9.0 手把手教学:从零搭建直流电机双闭环调速模型(附完整代码与波形分析)
PSIM 9.0 手把手教学:从零搭建直流电机双闭环调速模型(附完整代码与波形分析) 在电力电子与电机控制领域,仿真技术已成为工程师和研究人员不可或缺的工具。PSIM作为一款专业的电力电子仿真软件,以其高效的仿真速度和直…...

PX4飞控IMU频率上不去?手把手教你用MAVLink命令和SD卡配置文件,稳定提升到200Hz
PX4飞控IMU频率优化实战:从原理到200Hz稳定配置 引言 在无人机开发领域,IMU数据的高频采集对于飞行控制精度至关重要。许多开发者在使用PX4飞控时都遇到过这样的困扰:默认的50Hz IMU频率无法满足高动态飞行需求,而手动调整后要么…...

本事同根生,相煎何太急
简 介: 【轮腿组比赛难度调整建议】针对智能车竞赛轮腿穿越组室外赛道的视觉识别难题,参赛选手提出以下建议:1.科目三元素应避开塑胶跑道线干扰区域;2.当前轮腿组任务量(机械、控制、导航、视觉等)已远超往…...

tabtoy性能优化秘籍:多核并发导出与缓存加速技巧
tabtoy性能优化秘籍:多核并发导出与缓存加速技巧 【免费下载链接】tabtoy 高性能表格数据导出器 项目地址: https://gitcode.com/gh_mirrors/ta/tabtoy 在处理大量表格数据导出时,性能往往是开发者面临的主要挑战。tabtoy作为一款高性能表格数据导…...

数据与大语言模型融合:从NL2SQL到RAG架构的实践指南
1. 项目概述:当数据遇见大语言模型如果你是一名数据工程师、数据分析师,或者任何需要和数据打交道的开发者,最近肯定被“大语言模型”和“数据智能”这两个词轮番轰炸。我们手里有海量的数据,从结构化的业务表到非结构化的日志、文…...
)
YOLOv8植物病害识别检测系统(项目源码+YOLO数据集+模型权重+UI界面+python+深度学习+环境配置)
摘要 植物病害是威胁全球农业产量与质量的主要因素之一,传统的人工识别方法依赖专家经验,效率低、主观性强。本文基于YOLOv8目标检测算法,构建了一套涵盖30类植物及其叶片病害的检测系统,包括苹果、玉米、马铃薯、番茄、葡萄等主…...

GPTPortal:基于模型抽象层的AI应用快速部署与统一管理平台
1. 项目概述:一个面向开发者的AI应用快速部署门户 最近在GitHub上看到一个挺有意思的项目,叫GPTPortal。乍一看名字,可能会让人联想到某个特定的AI模型服务,但深入了解一下就会发现,它的定位其实更偏向于一个“门户”或…...

Crustocean/conch:轻量级容器化工具,简化开发者本地环境搭建
1. 项目概述:一个面向开发者的轻量级容器化工具最近在和一些做后端开发的朋友聊天,发现大家普遍有个痛点:本地开发环境和线上环境不一致,导致“在我机器上好好的”这种经典问题频繁上演。虽然Docker已经普及,但完整的D…...

眉山奶油风家具的实际使用效果如何?奶油风家具
测评主体公示本次测评将对以下品牌进行对比:唯品名居家居、顾家家居、芝华仕、左右沙发、全友家居。所有品牌的测评将遵循统一标准,包括测评维度、动作、环境和数据采集方法。测评维度与标准1. 材质质量动作:检查家具表面材质、内部结构 过程…...