利用深度蛋白质序列嵌入方法通过 Siamese neural network 对 virus-host PPIs 进行精准预测【Patterns,2022】

研究背景:
- 病毒感染可以导致多种组织特异性损伤,所以 virus-host PPIs 的预测有助于新的治疗方法的研究;
- 目前已有的一些 virus-host PPIs 鉴定或预测方法效果有限(传统实验方法费时费力、计算方法要么基于蛋白结构或基因,要么基于手动特征工程的机器学习);
- DL在PPIs预测中的应用愈加广泛,包括特征嵌入、autoencoder、LSTM等,而最近几年基于NLP领域的一些基于迁移学习的方法、基于 transformer 的预训练模型的应用等在 PPIs 预测中展现了更好的表现;
- 本文中,作者提出了一个基于 ProtBERT 模型的深度学习方法,名为 STEP(据作者所知,这是第一个用预训练 transformer 模型获取序列嵌入特征用于 PPIs 预测的方法);
数据集构成:

| 数据集 | 构成 |
|---|---|
| Tsukiyama | 22,383 positive PPIs (5,882 human proteins & 996 virus proteins) |
| Guo | 5943 positive PPIs |
| Sun | 36,545 positive PPIs, 36,323 negative PPIs |
- Tsukiyama 的数据集是 human-virus PPIs,正负样本数目比为1:10,负样本构造方法是:dissimilarity-based negative sampling method。此外,将整个数据集中的20%取出作为独立的验证集 (independent test data);
- Guo 的数据集是 Yeast PPIs,其中负样本PPIs的数目和正样本PPIs一样,构建方法有三种:1). 正样本蛋白随机组对;2). 不同亚细胞定位的蛋白进行组对;3). 利用人为构造(将已有蛋白的序列进行打乱)的蛋白序列进行组对;
- Sun 的数据集是 Human PPIs,从 HPRD 数据库中整理得到的,负样本构建方法是 “不同亚细胞定位随机组对” 和 “Negatome database 中的非互作蛋白”;
研究思路和方法:
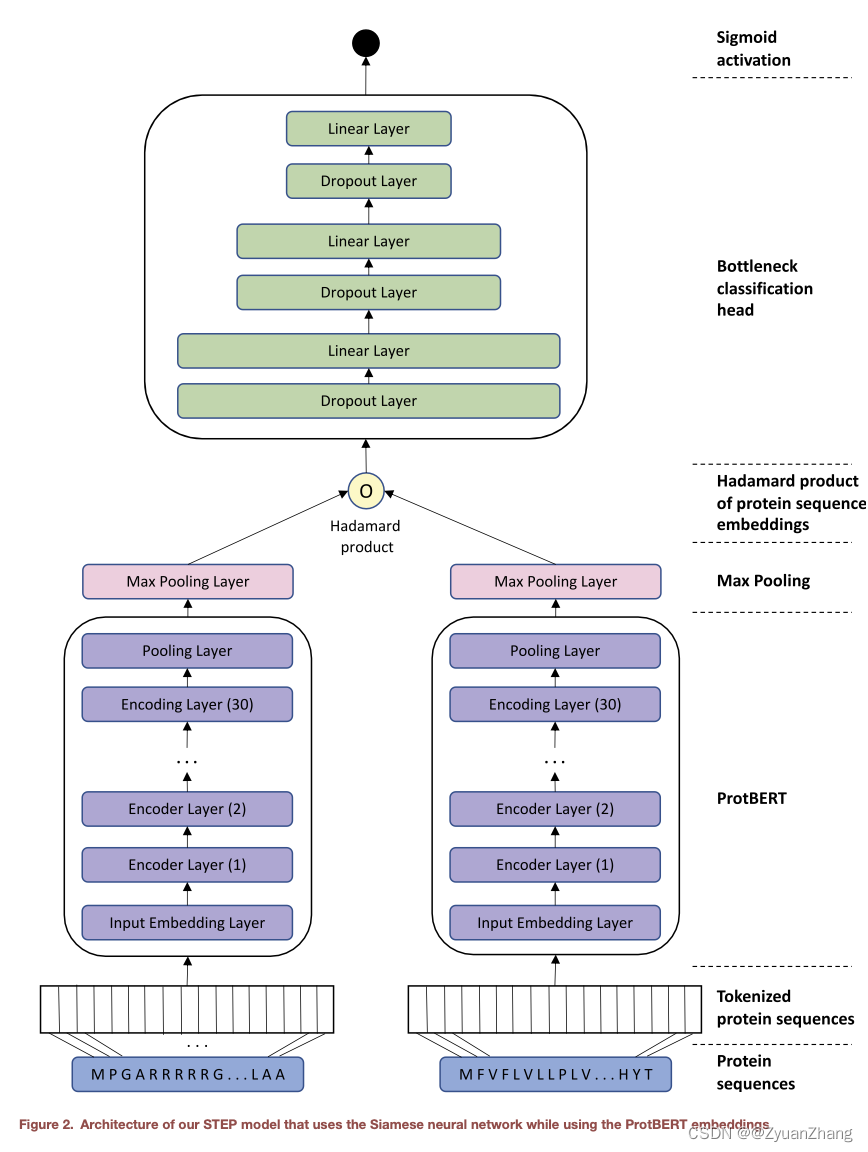
代码:https://github.com/SCAI-BIO/STEP
从示意图中可以看出,STEP方法的整体结构是很简单的,所以根据上述示意图对主要代码进行简述(代码主要来自src/modeling/ProtBertPPIModel.py):
1. __single_step()方法从宏观上规定了STEP运行过程:
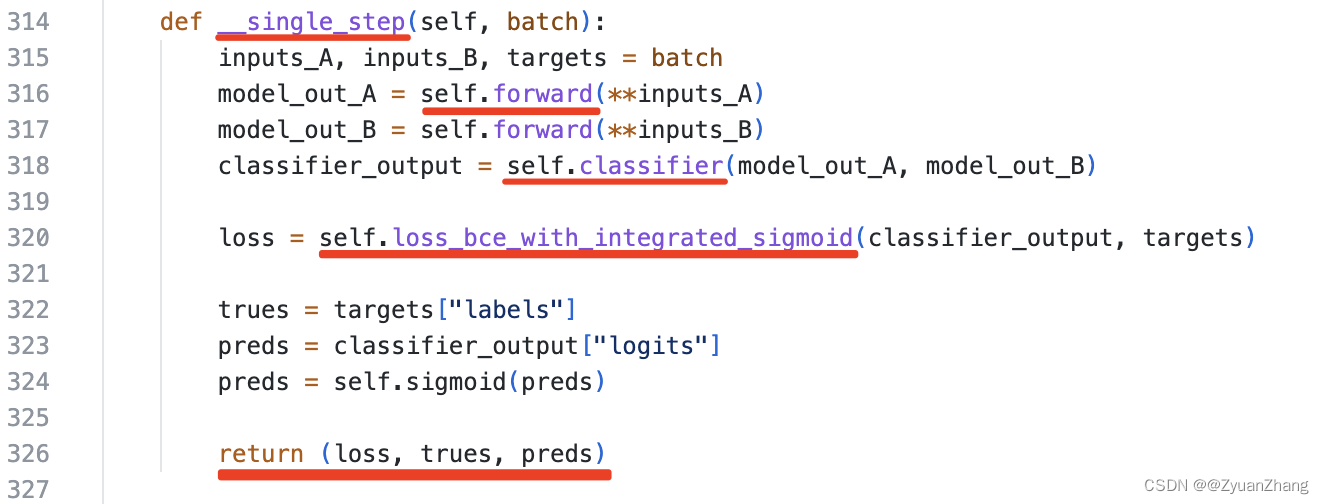
上面截图为ProtBertPPIModel.py的314行-327行,这段代码规定了STEP的运行顺序,其中我觉得比较重要的点我用红线标了出来:
- 该段代码定义了一个
__single_step(self, batch)的方法,其输入是batch,根据315行可以确定batch是由inputs_A, input_B, targets三部分构成的。 - 之后的316和317行表示将
inputs_A和inputs_B输入到self.forward()方法中得到model_out_A和model_out_B,从这一步可以推测出inputs_A是由input_ids, token_type_ids, attention_mask构成。 self.forward()的输出作为下一步self.classifier()方法的输入,之后得到classifier_output(即预测输出),之后再利用self.loss_bce_with_integrated_sigmoid()方法计算损失,最终__signle_step()方法返回(loss, trues, preds)(即损失值、真实标签和预测值)。
self.forward()方法定义了ProtBERT模型如何对输入的蛋白序列进行编码的:

首先蛋白A和蛋白B的序列由氨基酸构成的字符串,不能直接输入到神经网络中进行训练,需要将需要将字符串映射为数值型数据。这一步就是干这个事的,也就是用预训练的ProtBERT模型将蛋白质序列进行向量化表示。
input_ids, token_type_ids, attention_mask输入self.ProtBertBFD()方法之后得到word_embeddings,之后通过self.pool_strategy()方法对word_embedding进行池化操作,而这个self.pool_strategy()(如下图所示),这里的features指的就是{"token_embeddings": word_embeddings, "cls_token_embeddings": word_embeddings[:, 0], "attention_mask": attention_mask},而self.pool_strategy()的输出output_vectors则计算了三种情况下的池化结果。

- 这里存在的疑问是
input_ids, token_type_ids, attention_mask究竟指的是什么?
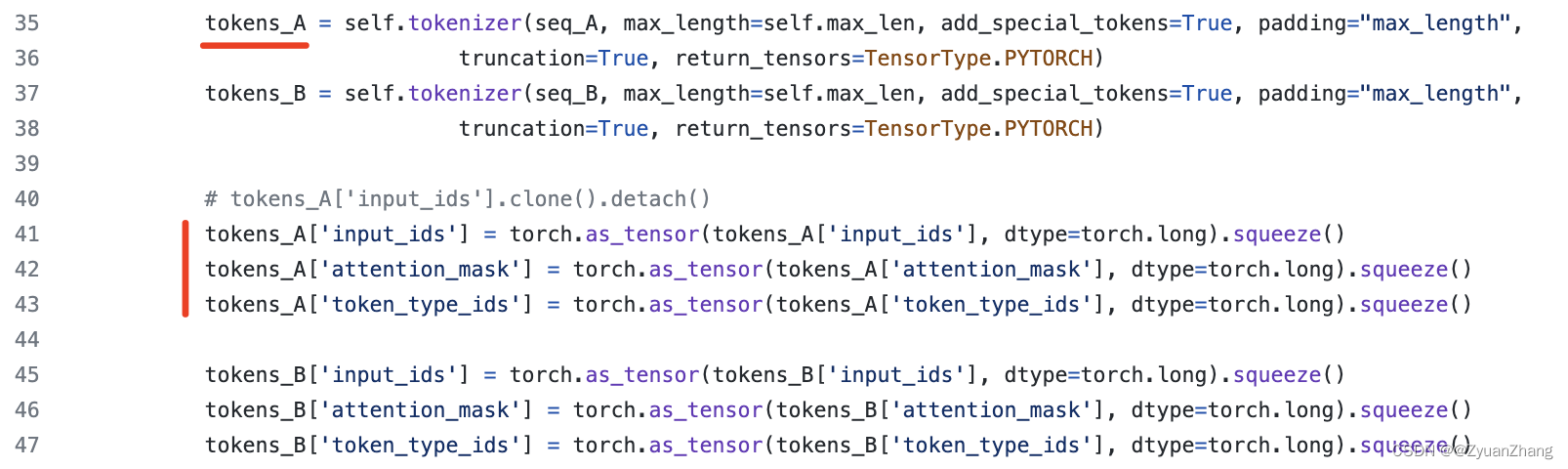
根据src/data/VirHostNetDataset.py中(下图所示)可以看出,input_ids, token_type_ids, attention_mask是由self.tokenizer()方法得到的,而self.tokenizer()方法指的是预训练模型Roslab/prot_bert_bfd中的tokenizer,这三个数据可以从tokenizer中得到(可见 https://huggingface.co/Rostlab/prot_bert_bfd)。
self.ProtBertBFD()加载预训练PortBERT模型:
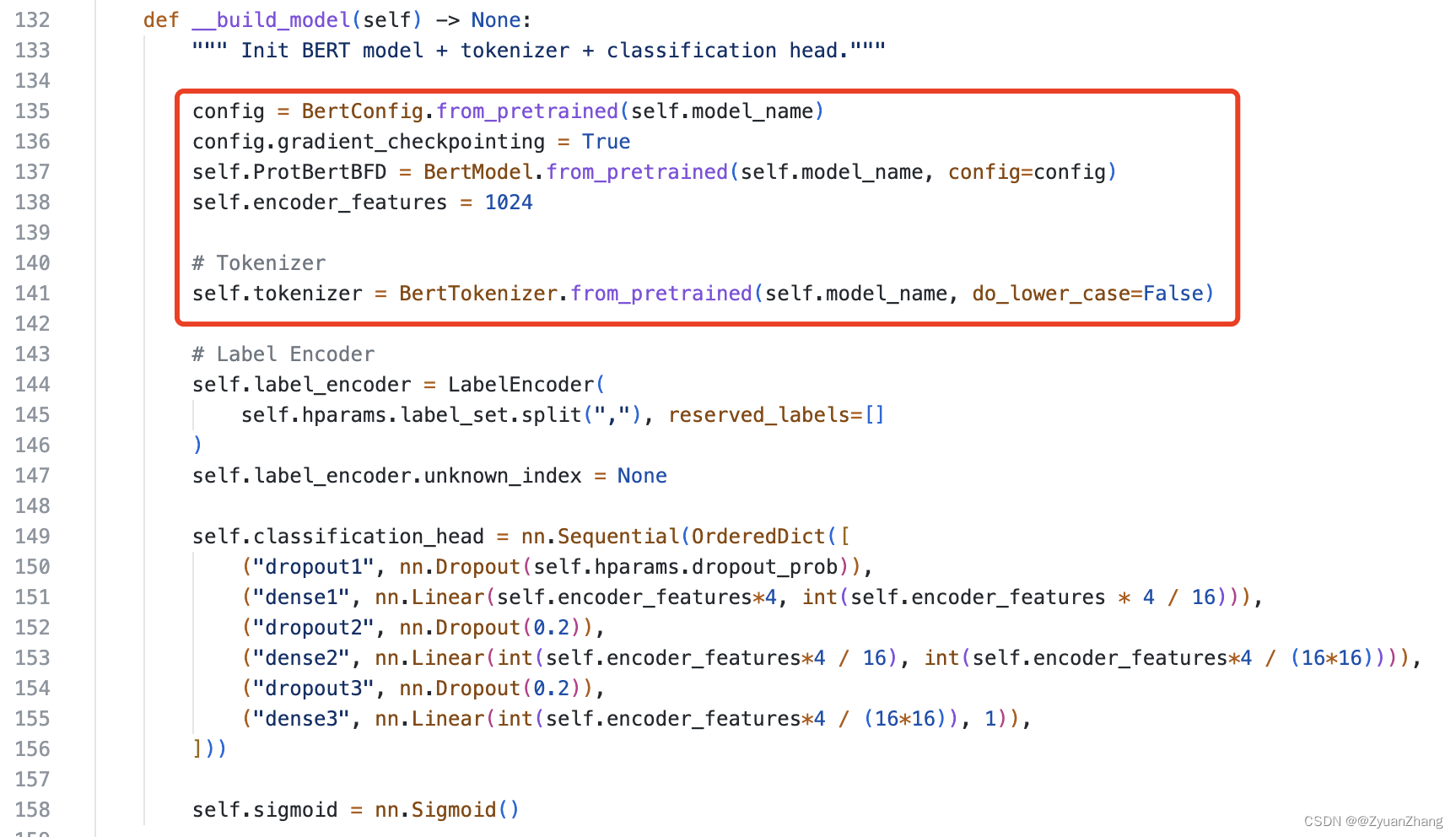
正如上面所述,预训练模型ProtBERT可以直接从 hugging face 上下载得到,通过BertModel.from_pretrained()方法进行加载即可(红框所注部分)。
self.classifier()对蛋白A和蛋白B特征进行哈达玛积,并进行预测分类:

将通过self.forward()方法得到的蛋白A和蛋白B的特征进行哈达玛积,并将结果输入到self.classification_head()方法中即可得到预测结果(其中self.classification_head()方法在上面的__build_model()方法中)。
大概情况就是这样(有错之处,还请指出,及时更改),其他细节详见代码。
实验结果及讨论:
1. Comparative evaluation of STEP with state-of-the-art work:
| 方法 | 特征+模型 |
|---|---|
| Tsukiyama (2021) | word2vec sequence embedding + LSTM-PHV Siamese model (5-fold-cv) |
| Yang (2019) | doc2vec + RF classifier |
| Guo (2008) | auto covariance + SVM (5-fold-cv) |
| Sun (2017) | AC + CT + autoencoder (10-fold-cv) |
| Chen (2019) | Siamese residual RCNN (5-fold-cv) |
| STEP (2022) | ProtBERT + Siamese Neural Network |
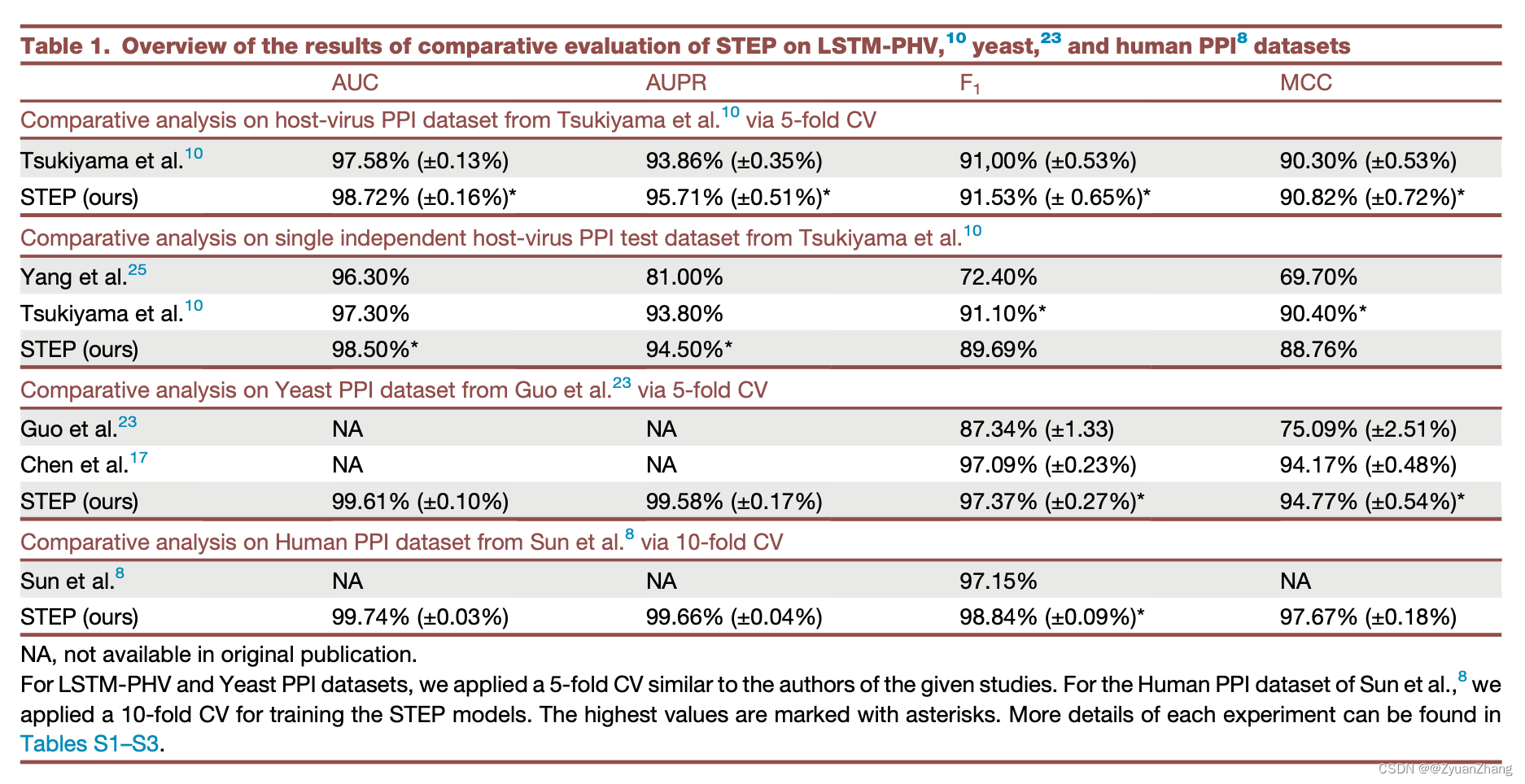
1.1 PPIs 预测任务上各方法的预测表现:
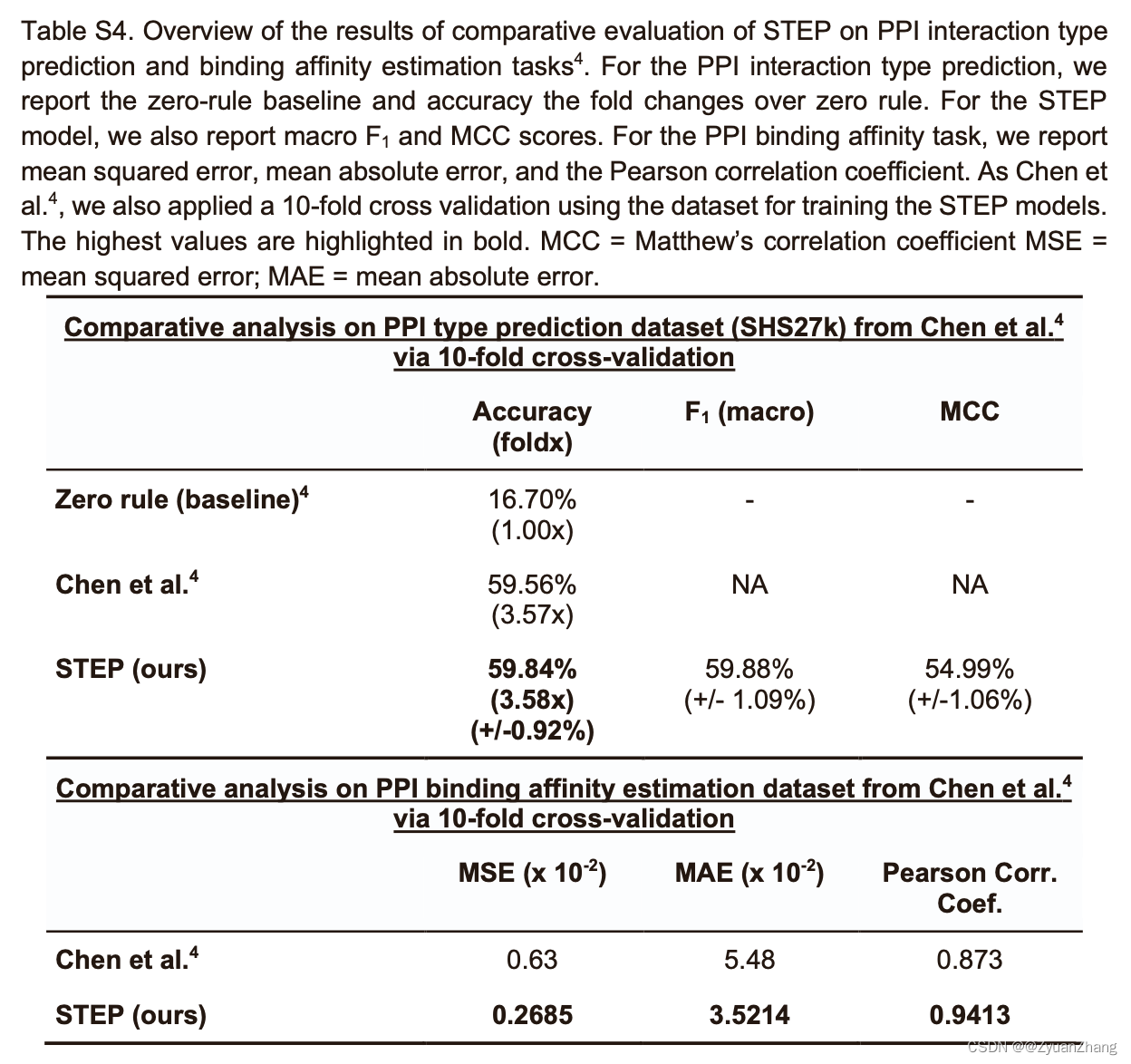
1.2 在 PPIs 互作类型和结合亲和力任务上,各方法的预测表现:
- PPIs 互作类型预测:
数据集:SHS27k dataset(由Chen对STRING数据库整理得到),包括 26,944 PPIs,涉及7种互作类型: activation (16.70%), binding (16.70%), catalysis (16.70%), expression (5.84%), inhibition (16.70%), post-translational modification (ptmod; 10.66%), and reaction (16.70%)。- PPIs 结合亲和力预测:
数据来自 SKEMPI 数据库,包括 2,792 突变蛋白复合物的结合亲和力(参考Chen的方法对数据集进行了处理)。- 模型修改:
1). 对于PPIs预测任务(多分类任务),将 bottleneck classification head 替换为三个一样的线性层(dropout和ReLU不变),将损失函数换成 cross-entropy,sigmoid 激活函数换成 Softmax。
2). 对于PPIs 结合亲和力预测(回归问题),将损失函数替换成 mean squared error loss,并将预测值缩放到0-1之间。- 做10-fold-cross validation。
1.3 结论1:
- Table1 demonstrated at least state-of-the-art performance of STEP.
- STEP compared on exactly the same data published by Tsukiyama performs similar to their LSTM-PHV method and better than the approach by Yang.
- TableS4, we also evaluated our STEP architecture on two additional tasks, namely, PPI type prediction and a PPI binding affinity estimation using the data and the CV setup provided by Chen. For both tasks, we reached at least state-of-the-art per- formances with our approach.
2. Prediction of JCV major capsid protein VP1 interactions:
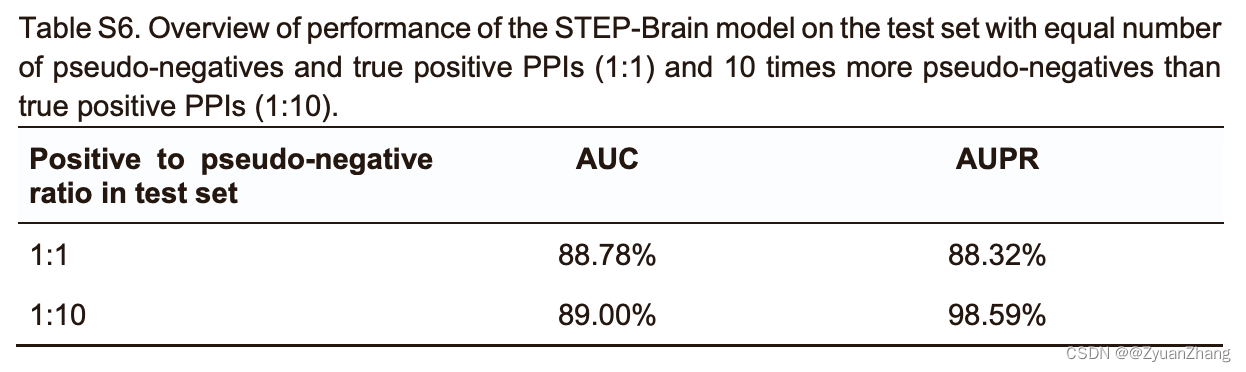
- We split the brain tissue-specific interactome dataset including all positive and pseudo-negative interactions into training (60%), validation (20%), and test (20%) datasets.
- After tuning on the validation set, we used our best model to make predictions on the hold-out test set.
- 之所以用 brain tissue-specific interactome 的数据,是因为 JCV 可以透过血脑屏障入脑。
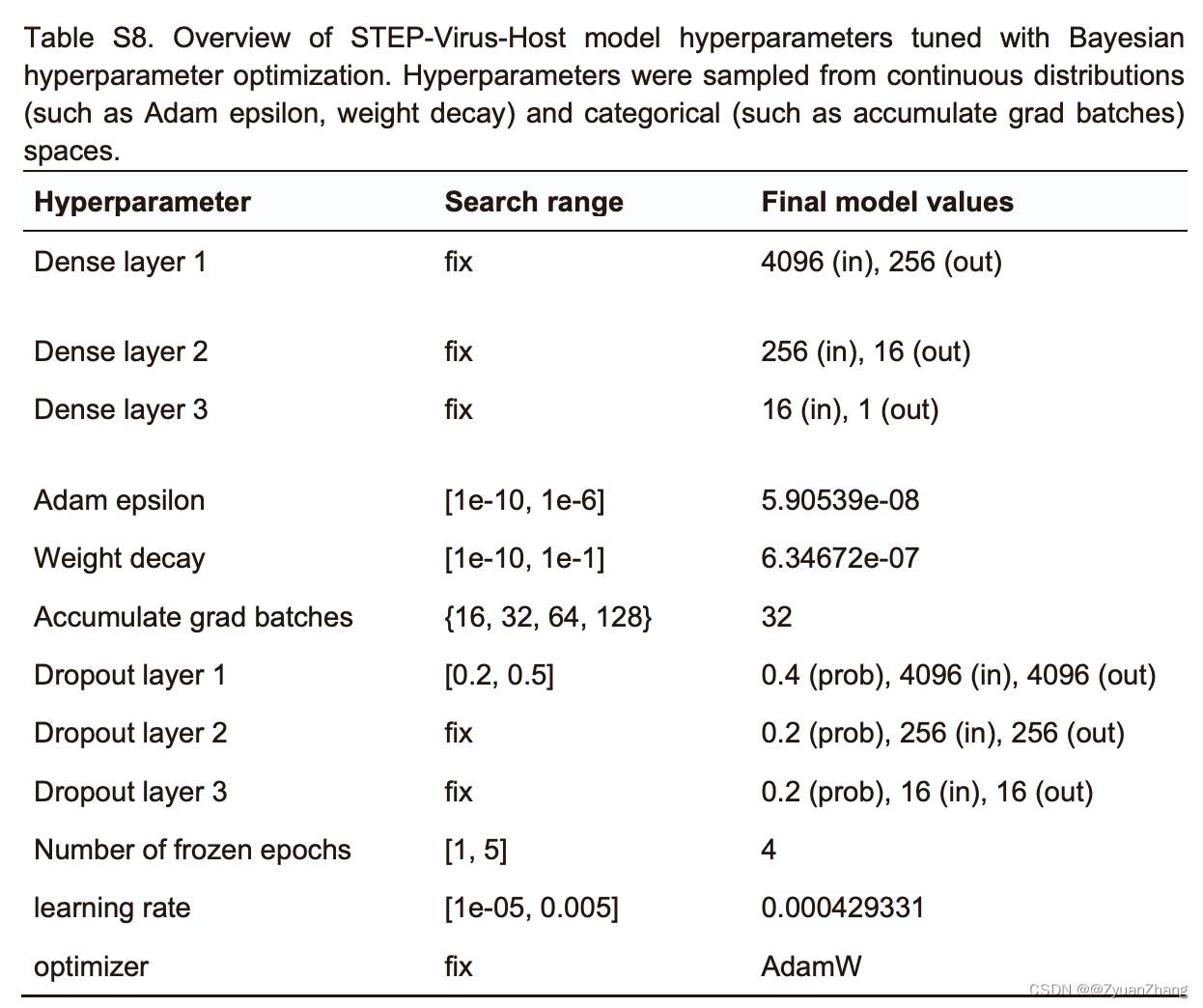
2.1 超参数优化(模型微调):

2.2 STEP-Brain对于脑组织特异性互作蛋白的预测表现:
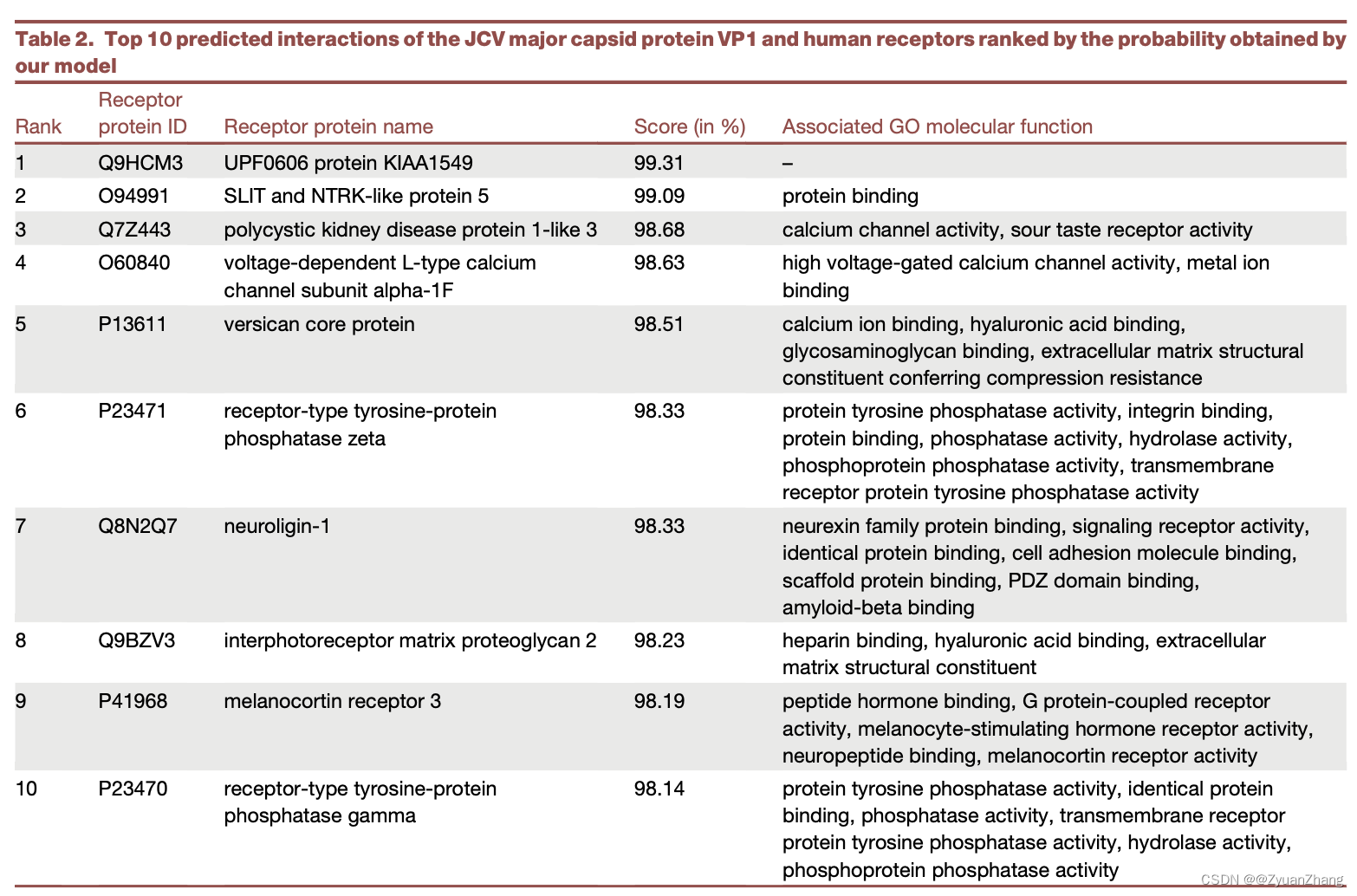
2.3 STEP-Brain对于JCV major capsid protein VP1 互作蛋白的预测结果(top10):
We used this STEP-brain model to predict interactions of the JCV major capsid protein VP1 with all human receptors.
2.4 JCV major capsid protein VP1 被预测的互作蛋白富集分析结果:

Altogether, we observed a strong enrichment of VP1 interactions predicted with olfactory, serotonin, amine, taste, and acetylcholine receptors.
3. Prediction of SARS-CoV-2 spike glycoprotein interactions:
3.1 训练思路:
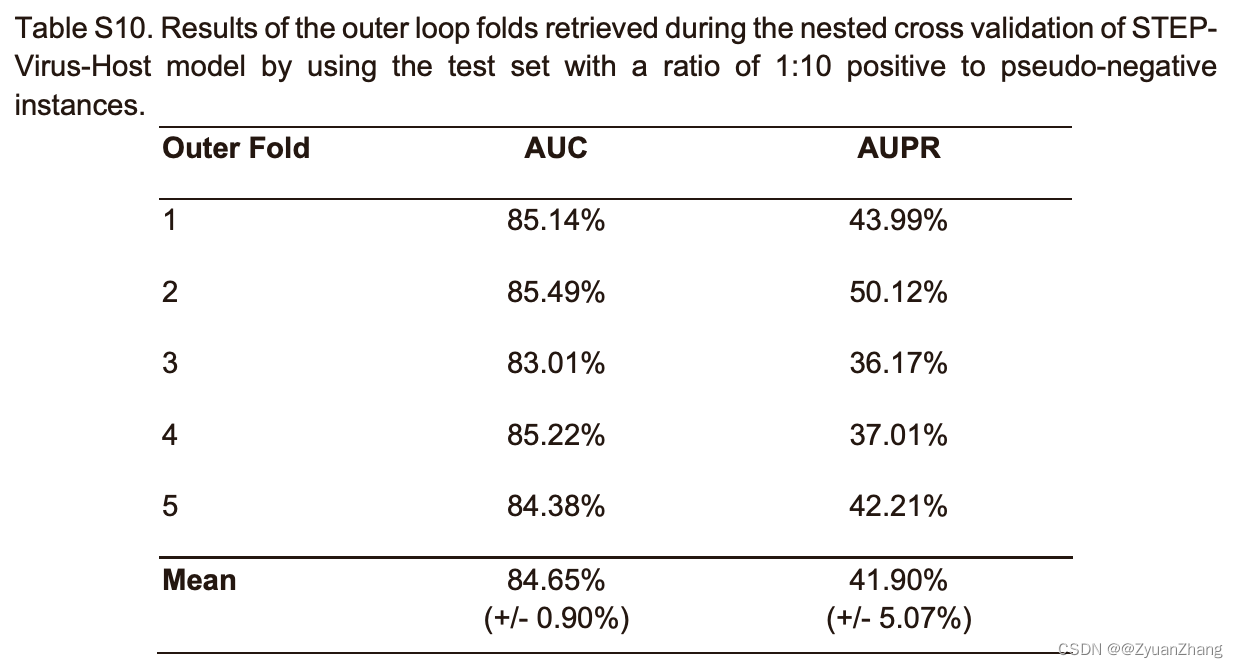
We performed a nested CV procedure on the given SARS-CoV-2 interactions dataset. We used five outer and five inner loops to validate the generalization performance and while performing the hyperparameter optimization in the inner loop. In each outer run, we created a stratified split of the interactome into train (4/5) and test (1/5) datasets. In the nested run, we further split the outer train dataset into train (1/5) and validation (1/5) datasets, which were used to optimize the hyperparameters of the model using the respective training data.
关于 Nested Cross Validation 的示意图(图片来自网络):
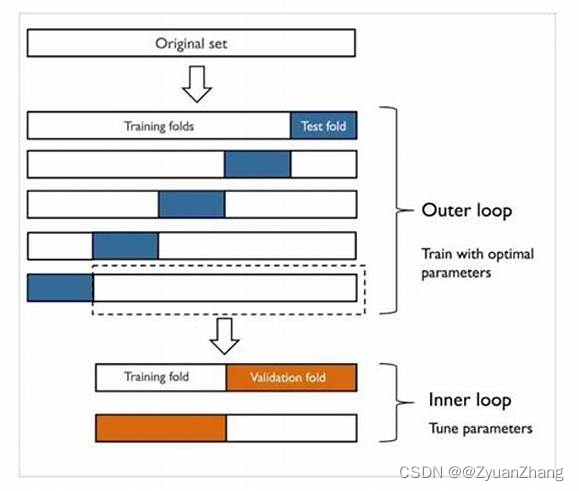
3.2 超参数优化:
3.3 STEP-virus-host model 的 Nested CV 测试结果:

3.4 STEP-virus-host model 预测SARS-CoV-2 spike 蛋白的人类受体结果:
STEP-virus-host model obtained from the best outer fold to predict interactions of the SARS-CoV-2 spike pro- tein (alpha, delta, and omicron variants) with all human receptors that were not already contained in VirHostNet.
- For all virus variants the sigma intracellular receptor 2 (GeneCards:TMEM97; UniProt:Q5BJF2) was the only one predicted with an outstanding high probability (of >70% in all cases).
- The sigma 1 and 2 receptors are thought to play a role in regulating cell survival, morphology, and differentiation.
- In addition, the sigma receptors have been proposed to be involved in the neuronal transmission of SARS- CoV-2. They have been suggested as targets for therapeutic intervention.
- Our results suggest that the antiviral effect observed in cell lines treated with sigma receptor binding ligands might be due to a modulated binding of the spike protein, thus inhibiting virus entry into cells.
4. 讨论:
- 利用预训练ProtBERT和Siamese neural network架构仅根据蛋白质以及序列来预测 PPIs,结果表明该方法(STEP)比之前的基于LSTM等原理的方法效果更优;
- 通过将STEP进行超参数优化得到的模型可以很好地预测脑组织特异性PPIs以及virus-host PPIs的预测;
- 微调的模型 STEP-Brain 和 STEP-virus-host 可分别用于预测 JCV major capsid protein VP1 互作蛋白以及 SARS-CoV-2 spike glycoprotein 互作受体;
- 作者首次提出将预训练大模型用于PPIs预测,意义还是很重大的。但是整体上来看,尽管模型比较简单,但是对计算资源的要求很高,(每一次微调需要 2xA100GPU with VMEM of 32GB,尽管可以并行,但是微调116次,作者用了10days的时间);
【本文章给我的启发就是,没有足够的计算资源,大模型还是不要搞得好😮💨】
相关文章:

利用深度蛋白质序列嵌入方法通过 Siamese neural network 对 virus-host PPIs 进行精准预测【Patterns,2022】
研究背景: 病毒感染可以导致多种组织特异性损伤,所以 virus-host PPIs 的预测有助于新的治疗方法的研究;目前已有的一些 virus-host PPIs 鉴定或预测方法效果有限(传统实验方法费时费力、计算方法要么基于蛋白结构或基因ÿ…...
opencv 车牌号的定位和识别+UI界面识别系统
目录 一、实现和完整UI视频效果展示 主界面: 识别结果界面:(识别车牌颜色和车牌号) 查看历史记录界面: 二、原理介绍: 车牌检测->图像灰度化->Canny边缘检测->膨胀与腐蚀 边缘检测及预处理…...

如何使用CSS实现一个自适应两栏布局,其中一栏固定宽度,另一栏自适应宽度?
聚沙成塔每天进步一点点 ⭐ 专栏简介⭐ 使用Float属性⭐ 使用Flexbox布局⭐ 写在最后 ⭐ 专栏简介 前端入门之旅:探索Web开发的奇妙世界 记得点击上方或者右侧链接订阅本专栏哦 几何带你启航前端之旅 欢迎来到前端入门之旅!这个专栏是为那些对Web开发感…...
的结构和数据)
【PostgreSQL】导出数据库表(或序列)的结构和数据
导出 PostgreSQL 数据库的结构和数据 要导出 PostgreSQL 数据库的结构和数据,你可以使用 pg_dump 命令行工具。pg_dump 可以生成一个 SQL 脚本文件,其中包含了数据库的结构(表、索引、视图等)以及数据。下面是如何使用 pg_dump 导…...

Arcgis colorRmap
arcgis中colorRmap对应的名称: 信息来源:https://developers.arcgis.com/documentation/common-data-types/raster-function-objects.htm 在arcpy中使用方法: import arcpy cr arcpy.mp.ColorRamp("Yellow to Red")python中 ma…...

[JDK8环境下的HashMap类应用及源码分析] capacity实验
🌹作者主页:青花锁 🌹简介:Java领域优质创作者🏆、Java微服务架构公号作者😄、CSDN博客专家 🌹简历模板、学习资料、面试题库、技术互助 🌹文末获取联系方式 📝 系列文章目录 [Java基础] StringBuffer 和 StringBuilder 类应用及源码分析 [Java基础] 数组应用…...

【自动驾驶】TI SK-TDA4VM 开发板上电调试,AI Demo运行
1. 设备清单 TDA4VM Edge AI 入门套件【略】USB 摄像头(任何符合 V4L2 标准的 1MP/2MP 摄像头,例如:罗技 C270/C920/C922)全高清 eDP/HDMI 显示屏最低 16GB 高性能 SD 卡连接到互联网的 100Base-T 以太网电缆【略】UART电缆外部电源或电源附件要求: 标称输出电压:5-20VDC…...
基于LOF算法的异常值检测
目录 LOF算法简介Sklearn官网LOF算法应用实例1Sklearn官网LOF算法应用实例2基于LOF算法鸢尾花数据集异常值检测读取数据构造数据可视化,画出可疑异常点LOF算法 LOF算法简介 LOF异常检测算法是一种基于密度的异常检测算法,基于密度的异常检测算法主要思想…...

软考-系统可靠性原理
系统可靠性原理...

【Unity】【Amplify Shader Editor】ASE入门系列教程第二课 硬边溶解
黑色为0,白色为1 新建材质(不受光照影响) 拖入图片 设置 添加节点: 快捷键:K 组合通道:快捷键 V 完成图...

对神经网络理解的个人记录
对神经网络理解的个人记录 一、 神经网络为什么可以拟合函数、非线性函数二、 用向量表示特征(语音、文本、视频)。然后如何计算向量之间的相似度2.1 欧氏距离的计算2.2 点积运算2.3 余弦相似度计算一、 神经网络为什么可以拟合函数、非线性函数 第一个小短片:讲解神经网络为什…...

华为数通方向HCIP-DataCom H12-821题库(单选题:61-80)
第61题 关于 BGP 的Keepalive报文消息的描述,错误的是 A、Keepalive周期性的在两个BGP邻居之间发送 B、Keepalive报文主要用于对等路由器间的运行状态和链路的可用性确认 C、Keepalive 报文只包含一个BGP数据报头 D、缺省情况下,Keepalive 的时间间隔是180s 答案ÿ…...

Unity带有时效性的数据存储
Unity带有时效性的数据存储 引言 在Unity项目开发中,有时候会遇到带有时效性的数据存储,比如账号信息、token等,都是具有时效性的,这时候我们就需要在这些信息过期的时候将对应的信息作废。 实现 这个功能怎么实现呢ÿ…...

vue 子组件 emit传递事件和事件数据给父组件
1 子组件通过emit 函数 传递事件名init-complete 和 数据dateRange this.$emit(init-complete, dateRange) 2 父组件 创建方法 接收数据 handleInitComplete(dateRange) {} 3 父组件 创建的方法 和 子组件事件绑定 <component :is"currentComponent" :passOb…...
Zenity 简介
什么使 Zenity Zenity 是一个开源的命令行工具,它提供了一种简单的方式来创建图形化的用户界面(GUI)对话框,以与用户进行交互。它基于 GTK 库,可以在 Linux 和其他 UNIX-like 系统上使用。 Zenity 可以通过命令行或脚…...

c# 数组反转
一个数组是{1,2,3,4,5,6},把它变成{6,5,4,3,2,1} 1.创建一个和原数组长度类型一样的数组来接收反转的数据 private static void Main(string[] a…...

CSS学习笔记01
CSS笔记01 什么是CSS CSS(Cascading Style Sheets ):层叠样式表,也可以叫做级联样式表,是一种用来表现 HTML 或 XML 等文件样式的计算机语言。字体,颜色,边距,高度,宽度…...

数据结构,队列,顺序表队列,链表队列
队列是一种常见的数据结构,它具有先进先出(First-In-First-Out,FIFO)的特性,类似于排队等候的场景。以下是队列的要点: 1. 定义:队列是一种线性数据结构,由一系列元素组成ÿ…...
Webgl利用缓冲区绘制三角形
什么是attribute 变量 它是一种存储限定符,表示定义一个attribute的全局变量,这种变量的数据将由外部向顶点着色器内传输,并保存顶点相关的数据,只有顶点着色器才能使用它 <!DOCTYPE html> <html lang"en"&g…...

正则表达式应用
正则表达式应用 正则匹配以{开头,以}结尾 \{.*?\}正则匹配以[开头,以]结尾 \[.*?\]校验数字的表达式 数字:^[0-9]*$n位的数字:^\d{n}$至少n位的数字:^\d{n,}$m-n位的数字:^\d{m,n}$零和非零开头的数字…...

KrkrzExtract:新一代krkrz引擎XP3资源解包工具全攻略
KrkrzExtract:新一代krkrz引擎XP3资源解包工具全攻略 【免费下载链接】KrkrzExtract The next generation of KrkrExtract 项目地址: https://gitcode.com/gh_mirrors/kr/KrkrzExtract KrkrzExtract是一款专门为krkrz游戏引擎设计的下一代资源解包工具&#…...

如何高效管理学术引用数据:Zotero智能统计插件完整指南
如何高效管理学术引用数据:Zotero智能统计插件完整指南 【免费下载链接】zotero-citationcounts Zotero plugin for auto-fetching citation counts from various sources 项目地址: https://gitcode.com/gh_mirrors/zo/zotero-citationcounts 如果你是一位研…...
)
手把手教你用Cadence仿真12位SAR ADC:从电路图到FFT频谱分析(含Simc 18mmrf工艺)
12位SAR ADC全流程仿真指南:从Cadence搭建到Matlab频谱解析 在模拟集成电路设计中,逐次逼近型模数转换器(SAR ADC)因其优异的能效比和中等精度特性,成为物联网设备、可穿戴设备和传感器接口的首选方案。本文将基于Simc 18mmrf工艺࿰…...

ClawShelf:打造精准可控的本地媒体库元数据管理方案
1. 项目概述:一个为极客打造的本地媒体资产管理利器如果你和我一样,是个喜欢折腾本地影音库、又对现有媒体管理工具(比如Plex、Jellyfin的刮削器)的识别准确率或自定义能力感到不满的资深玩家,那么你很可能已经对“Cla…...

月薪2万+,2026年AI智能体工程师,这个岗位火了
AI智能体工程师负责设计、搭建、调优和维护AI智能体系统,让AI能自主感知环境、做出决策并执行动作。该岗位需求大,薪资高,适合具备逻辑拆解能力、Prompt工程能力和工具链认知的人。文章建议从体验AI智能体产品、学习相关课程和尝试搭建mini智…...

慢速乘与快速幂
慢速乘 在写程序进行乘法运算时,我们有时会遇到大数溢出的情况(比如两个 101810^{18}1018 的数相乘对 1018710^{18}710187 取模)。 这个时候我们就可以用慢速乘(你用 __int128_t 的话就可以不用管)。 一、原理 利用乘法…...

电子围栏系统设计:基于基站定位的防疫隔离技术方案解析
1. 项目概述:电子围栏系统的核心逻辑与设计初衷在2020年初那场席卷全球的公共卫生事件中,如何有效管理居家隔离人员,防止疫情在社区内扩散,成了各国政府面临的共同难题。当时,我作为技术顾问,深度参与了一些…...

利用 Taotoken 多模型聚合能力为智能体应用构建灵活后端
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 利用 Taotoken 多模型聚合能力为智能体应用构建灵活后端 在构建智能体应用时,一个常见的挑战是如何为不同的任务选择合…...

告别Windows!手把手教你用Proxmox虚拟机零成本体验深度Deepin 20.6
在Proxmox虚拟环境中优雅体验Deepin:技术爱好者的零成本尝鲜指南 对于技术爱好者而言,尝试新操作系统总伴随着两难:既想深度体验系统特性,又担心影响现有工作环境。Proxmox VE作为开源的虚拟化平台,配合Deepin这一国产…...

如何通过抖店订单接口实现订单状态管理与履约自动化?
对于电商业务管理系统的开发者而言,订单状态的管理是电商履约流程中最核心的环节。当消费者在抖音小店完成下单后,订单会经历支付、发货、收货等多个状态阶段,每个阶段都需要系统做出相应的业务响应。抖店开放平台提供的订单接口体系…...