大语言模型初学者指南 (2023)
大语言模型 (LLM) 是深度学习的一个子集,它正在彻底改变自然语言处理领域。它们是功能强大的通用语言模型,可以针对大量数据进行预训练,然后针对特定任务进行微调。这使得LLM能够拥有大量的一般数据。如果一个人想将LLM用于特定目的,他们可以简单地根据各自的目的微调模型。此过程涉及在与任务相关的较小数据集上训练模型。训练它的数据集可以包括书籍、文章、代码存储库和其他形式的文本。
大语言模型 (LLM) 已成为人工智能 (AI) 领域的突破性发展,通过自监督学习技术来处理和理解人类语言或文本。改变了自然语言处理 (NLP) 和机器学习 (ML) 应用。此类LLM模型包括 OpenAI 的 GPT-3 和谷歌的 BERT,在理解和生成类人文本方面表现出了令人印象深刻的能力,使其成为各个行业的宝贵工具。这份综合指南将涵盖LLM的基础知识、训练过程、用例和未来趋势。
一、大语言模型简史
大语言模型的历史可以追溯到 20 世纪 60 年代。 1967 年,麻省理工学院的一位教授构建了第一个 NLP 程序 Eliza 来理解自然语言。它使用模式匹配和替换技术来理解人类并与人类交互。后来,在 1970 年,麻省理工学院团队构建了另一个 NLP 程序,用于理解人类并与人类互动,称为 SHRDLU。
1988 年,RNN 架构被引入来捕获文本数据中存在的顺序信息。但 RNN 只能处理较短的句子,但不能处理长句子。因此,LSTM于1997年被提出。在此期间,基于LSTM的应用出现了巨大的发展。后来,注意力机制的研究也开始了。
LSTM 有两个主要问题。 LSTM 在一定程度上解决了长句子的问题,但在处理非常长的句子时,它并不能真正表现出色。训练 LSTM 模型无法并行化。因此,这些模型的训练需要更长的时间。

2017年,通过《Attention Is All You Need》论文,NLP研究取得了突破。这篇论文彻底改变了整个 NLP 领域。研究人员引入了名为 Transformer 的新架构来克服 LSTM 的挑战。Transformer 本质上是第一个开发的LLM,包含一个巨大的数字。参数。 Transformers 成为LLM最先进的模型。即使在今天,LLM的发展仍然受到变压器的影响。
在接下来的五年里,大量研究集中在构建比 Transformer 更好的 LLM。 LLM 的规模随着时间的推移呈指数增长。实验证明,增加LLM和数据集的规模可以提高LLM的知识水平。因此,随着参数和训练数据集大小的增加,引入了 GPT-2、GPT-3、GPT 3.5、GPT-4 等 GPT 变体。
2022年,NLP又有了突破,ChatGPT。 ChatGPT 是一个对话优化的LLM,能够回答您想要的任何问题。几个月后,Google 推出了 BARD 作为 ChatGPT 的竞争对手。
在过去的一年里,已经开发了数百个大语言模型。您可以获取开源 LLM 列表以及 Hugging Face Open LLM 排行榜上的排名。迄今为止最先进的LLM是 Falcon 40B Instruct。
二、什么是大语言模型
简而言之,大语言模型是在巨大数据集上训练以理解人类语言的深度学习模型。其核心目标是准确地学习和理解人类语言。大语言模型使机器能够像我们人类解释语言一样解释语言,彻底改变了计算机理解和生成人类语言的方式。
大语言模型学习语言中单词之间的模式和关系。例如,它理解语言的句法和语义结构,如语法、单词顺序以及单词和短语的含义。它获得了掌握整个语言本身的能力。
过去,语言处理严重依赖于遵循预定义指令的基于规则的系统。然而,这些系统在捕捉人类语言复杂而细致的方面面临着局限性——深度学习和神经网络的出现带来了重大突破。一种著名的 Transformer 架构,例如 GPT-3(生成式预训练 Transformer 3)等模型,它带来了变革性的转变。
大语言模型中的术语“大”是指神经网络的大小,即参数数量及其训练数据量。由于其规模大且复杂,它们可以生成令人印象深刻的连贯且上下文相关的句子。
如果只通过 GPT(生成式预训练 Transformer)模型的演进规模来看:
-
2018 年发布的 GPT-1 包含 1.17 亿个参数,9.85 亿个单词。
-
2019年发布的GPT-2 包含15亿个参数。
-
2020年发布的GPT-3 包含1750亿个参数。 ChatGPT 就是基于这个模型。
-
2023年发布的GPT-4 它可能包含数万亿个参数。
三、大语言模型的架构
大语言模型 (LLM) 的架构由多种因素决定,例如特定模型设计的目标、可用的计算资源以及 LLM 将执行的语言处理任务的类型。 LLM的总体架构由许多层组成,例如前馈层、嵌入层、注意力层。嵌入其中的文本相互协作以生成预测。
大语言模型 (LLM) 由几个关键构建块组成,使它们能够有效地处理和理解自然语言数据。

以下是一些关键组件的概述:
-
标记化:标记化是将文本序列转换为模型可以理解的单个单词、子词或标记的过程。在LLM中,标记化通常使用字节对编码 (BPE) 或 WordPiece 等子字算法来执行,这些算法将文本分割成更小的单元,以捕获频繁和罕见的单词。这种方法有助于限制模型的词汇量大小,同时保持其表示任何文本序列的能力。
-
嵌入:嵌入是单词或标记的连续向量表示,可捕获它们在高维空间中的语义。它们允许模型将离散标记转换为神经网络可以处理的格式。在LLM中,嵌入是在训练过程中学习的,所得的向量表示可以捕获单词之间的复杂关系,例如同义词或类比。
-
注意力:LLM 中的注意力机制,特别是 Transformer 中使用的自注意力机制,允许模型权衡给定上下文中不同单词或短语的重要性。通过为输入序列中的标记分配不同的权重,模型可以专注于最相关的信息,同时忽略不太重要的细节。这种有选择地关注输入的特定部分的能力对于捕获远程依赖性和理解自然语言的细微差别至关重要。
-
预训练:预训练是在针对特定任务进行微调之前,在大型数据集(通常是无监督或自监督)上训练 LLM 的过程。在预训练期间,模型学习一般语言模式、单词之间的关系以及其他基础知识。此过程产生预训练模型,可以使用较小的特定于任务的数据集进行微调,从而显着减少在各种 NLP 任务上实现高性能所需的标记数据量和训练时间。
-
迁移学习:迁移学习是一种利用预训练期间获得的知识并将其应用于新的相关任务的技术。在LLM的背景下,迁移学习涉及在较小的特定任务数据集上微调预训练模型,以实现该任务的高性能。迁移学习的好处在于,它允许模型从预训练期间学到的大量通用语言知识中受益,从而减少对大型标记数据集和每个新任务的大量训练的需求。
3.1、影响大语言模型架构的重要组成部分
-
模型大小和参数数量
-
输入表示
-
自注意力机制
-
训练目标
-
计算效率
-
解码和输出生成
3.2、基于 Transformer 的 LLM 模型架构
基于 Transformer 的模型彻底改变了自然语言处理任务,通常遵循包含以下组件的通用架构:

-
输入嵌入:输入文本被标记为更小的单元,例如单词或子词,并且每个标记被嵌入到连续向量表示中。此嵌入步骤捕获输入的语义和句法信息。
-
位置编码:位置编码被添加到输入嵌入中以提供有关标记位置的信息,因为转换器不会自然地对标记的顺序进行编码。这使得模型能够处理标记,同时考虑它们的顺序。
-
编码器:基于神经网络技术,编码器分析输入文本并创建许多隐藏状态来保护文本数据的上下文和含义。多个编码器层构成了 Transformer 架构的核心。自注意力机制和前馈神经网络是每个编码器层的两个基本子组件。
-
自注意力机制:自注意力使模型能够通过计算注意力分数来权衡输入序列中不同标记的重要性。它允许模型以上下文感知的方式考虑不同标记之间的依赖关系和关系。
-
前馈神经网络:在自注意力步骤之后,前馈神经网络独立地应用于每个标记。该网络包括具有非线性激活函数的完全连接层,使模型能够捕获令牌之间的复杂交互。
-
解码器层:在一些基于变压器的模型中,除了编码器之外还包含解码器组件。解码器层支持自回归生成,其中模型可以通过关注先前生成的标记来生成顺序输出。
-
多头注意力:Transformers 通常采用多头注意力,其中自注意力与不同的学习注意力权重同时执行。这使得模型能够捕获不同类型的关系并同时处理输入序列的各个部分。
-
层归一化:层归一化应用于变压器架构中的每个子组件或层之后。它有助于稳定学习过程并提高模型泛化不同输入的能力。
-
输出层:变压器模型的输出层可以根据具体任务而变化。例如,在语言建模中,通常使用线性投影和 SoftMax 激活来生成下一个标记的概率分布。
最重要的是要记住,基于 Transformer 的模型的实际架构可以根据特定的研究和模型创建进行更改和增强。为了完成不同的任务和目标,GPT、BERT 和 T5 等多种模型可能会集成更多组件。
四、大语言模型的类型
4.1、Zero-shot Model 零样本模型
零样本模型是大语言模型中一个有趣的发展。它具有无需特定微调即可执行任务的非凡能力,展示了其适应和概括对新的和未经训练的任务的理解的能力。这一成就是通过对大量数据进行广泛的预训练来实现的,使其能够在单词、概念和上下文之间建立关系。
4.2、微调或特定领域的模型
零样本模型显示出广泛的适应性,但微调或特定领域的模型采用更有针对性的方法。这些模型经过专门针对特定领域或任务的培训,加深了对这些模型的理解,从而在这些领域表现出色。例如,可以对大语言模型进行微调,使其在分析医学文本或解释法律文档方面表现出色。这种专业化极大地提高了他们在特定环境下提供准确结果的效率。微调为提高专业领域的准确性和效率铺平了道路。
4.3、语言表示模型
语言表示模型构成了众多广泛语言模型的基础。这些模型经过训练,能够通过获得在多维空间中表示单词和短语的能力来理解语言的微妙之处。这有助于捕获单词之间的联系,例如同义词、反义词和上下文含义。因此,这些模型可以掌握任何给定文本中复杂的含义层次,使它们能够生成连贯且适合上下文的响应。
4.4、多模态模型
技术不断进步,各种感官输入的整合也随之变得越来越重要。多模态模型通过结合图像和音频等其他形式的数据,超越了语言理解。这种融合使模型能够理解和生成文本,同时解释和响应视觉和听觉线索。多模态模式的应用涵盖多个领域,例如图像字幕(该模式为图像生成文本描述)以及有效响应文本和语音输入的对话式人工智能。这些模型使我们更接近开发能够更真实地模拟类人交互的人工智能系统。
五、大语言模型的挑战和局限性
大语言模型带来了人工智能和自然语言处理的革命。然而,尽管取得了显着的进步,但像 ChatGPT 这样的聊天机器人技术的扩展系统并非没有挑战和局限性。虽然他们开辟了新的沟通途径,但他们也遇到了需要仔细考虑的障碍。
5.1、计算和训练数据的复杂性
主要挑战之一来自大语言模型的复杂性。这些模型具有复杂的神经架构,需要大量的计算资源来进行训练和操作。此外,收集支持这些模型所需的大量训练数据是一项艰巨的任务。虽然互联网是宝贵的信息来源,但确保数据质量和相关性仍然是一个持续的挑战。
5.2、偏见和道德问题
大语言模型很容易受到训练数据中发现的偏差的影响。无意中,这些偏见可能会持续存在于他们学习的内容中,从而导致潜在的响应质量问题和不良结果。这种偏见会强化刻板印象并传播错误信息,从而引发道德担忧。它强调了对这些模型进行细致评估和微调的必要性。
5.3、缺乏理解力和创造力
尽管它们的能力令人印象深刻,但大语言模型在正确的理解和创造力方面却遇到了困难。这些模型依靠从训练数据中学到的模式来生成响应,这有时会导致听起来似乎合理但实际上不正确的答案。不幸的是,这种限制影响了他们参与细致入微的讨论、提供原创见解或完全掌握上下文微妙之处的能力。
5.4、需要人类反馈和模型可解释性
人类反馈在增强大语言模型方面发挥着关键作用。尽管这些模型可以独立生成文本,但人类指导对于保证连贯和准确的响应至关重要。此外,为了建立信任并通过了解模型如何得出特定答案来识别潜在错误,解决可解释性的挑战至关重要。
六、大语言模型的用途
大语言模型作为具有广泛应用的变革工具而受到重视。这些模型利用机器学习和自然语言处理的力量来理解和生成与人类表达非常相似的文本。让我们深入研究这些模型如何彻底改变涉及文本和交互的各种任务。
6.1、文本生成和完成
大语言模型带来了文本生成和完成的新时代。这些模型具有理解上下文、含义和语言的微妙复杂性的固有能力。因此,他们可以生成连贯且上下文相关的文本。他们非凡的才能已在各个领域得到实际应用。
-
写作帮助:专业和业余作家体验利用大语言模型的好处。这些模型能够建议适当的短语、句子甚至整个段落,从而简化创作过程并提高书面内容的质量。
-
改进版本:语言模型通过帮助创作者生成引人入胜且信息丰富的文本,彻底改变了内容创建。通过分析大量数据,这些模型可以定制内容以满足特定的目标受众。
6.2、问答与信息检索
大语言模型在问答和信息检索领域正在快速发展。他们理解人类语言的卓越能力使他们能够从庞大的数据存储库中提取相关细节。
-
虚拟助手:它由大语言模型提供支持,为寻求准确且相关信息的用户提供便捷的解决方案。这些先进的人工智能系统可以无缝地协助完成各种任务,例如检查天气、发现食谱或解决复杂的查询。通过理解上下文并生成适当响应的能力,这些虚拟助手可以促进顺畅的人机交互。
-
搜索引擎:它们是数字探索的基础,依靠其无与伦比的能力来理解用户查询并提供相关结果。通过利用广泛的语言模型,这些搜索平台的效率进一步提高,不断完善算法以提供更精确和个性化的搜索结果。
6.3、情感分析与意见挖掘
了解人类的情感和观点在不同的环境中都具有巨大的意义,从塑造品牌认知到进行市场分析。利用大语言模型为有效分析文本数据中的情感提供了强大的工具。
-
社交媒体监控:它允许企业和组织利用先进的语言模型来分析和监控社交平台上表达的情绪。这一宝贵的工具使他们能够评估公众意见、跟踪品牌情绪并做出明智的决策。
-
品牌认知分析:大语言模型通过分析客户评论、评论和反馈来评估品牌情绪。这种有价值的分析可以帮助公司根据公众的看法完善其产品、服务和营销策略。
6.4、辅助代码生成
2021 年 6 月,GitHub 宣布与 OpenAI 合作推出 GitHub Copilot。 Copilot 在您键入时自动建议整行或整段代码,从而帮助您更高效地编写代码,类似于 Gmail 在您编写电子邮件时建议单词和句子的方式。 Copilot 确实可以帮助您更快地编写代码,减少编码时所犯的错误数量,甚至可以帮助您介绍新的代码库和函数。
七、如何在业务中应用大语言模型
将大语言模型集成到业务应用中会带来许多可能性。这些先进的人工智能系统被称为大语言模型,具有理解和生成与人类语音非常相似的文本的能力。它们的潜力跨越不同领域,使其成为提高生产力和创新的宝贵工具。在本指南中,我们将为您提供有关如何将大语言模型无缝整合到您的工作流程中的分步说明,利用其功能来推动卓越的成果。
7.1、确定您的需求
要成功实现大语言模型,必须首先确定其特定的业务场景。这一关键步骤有助于理解需求并指导选择合适的大语言模型,同时调整参数以获得最佳结果。LLM的一些典型应用包括机器翻译、聊天机器人实现、自然语言推理、计算语言学等。
7.2、选择合适的型号
多种大语言模型可供选择。流行的选择包括 OpenAI 的 GPT、Google 的 BERT(双向编码器表示)以及基于 Transformer 的模型。每个大语言模型都具有独特的优势,并且是针对特定任务量身定制的。相反,Transformer 模型因其自我关注机制而脱颖而出,这对于理解文本中的上下文信息非常有价值。
7.3、访问模型
选择适当的模型后,下一步就是访问它。许多LLM都可以在 GitHub 等平台上作为开源选项访问。例如,可以通过其 API 或从其官方存储库下载 Google 的 BERT 模型来访问 OpenAI 的模型。如果所需的大语言模型无法开源,则可能需要联系提供商或获取许可证。
7.4、预处理您的数据
为了有效地利用大语言模型,首先必须对数据进行必要的准备。这涉及消除不相关的信息、纠正错误以及将数据转换为大语言模型可以轻松理解的格式。这些细致的步骤至关重要,因为它们通过塑造输入质量对模型的性能产生重大影响。
7.5、微调模型
准备好数据后,大语言模型微调过程就可以开始。这一关键步骤专门针对您的用例优化模型参数。虽然这个过程可能很耗时,但对于实现最佳结果至关重要。它可能需要尝试不同的设置并在各种数据集上训练模型以发现理想的配置。
7.6、实施模型
微调模型后,您可以将其集成到您的流程中。这可能涉及将大语言模型嵌入到您的软件中或将其设置为系统可以查询的独立服务。确保模型与您的基础设施兼容并且可以处理所需的工作负载。
7.7、监控和更新模型
一旦实现了大语言模型,监控其性能并进行必要的更新就变得至关重要。新的数据可用性可能会使机器学习模型变得过时。因此,定期更新对于保持最佳性能至关重要。此外,随着您的需求的变化,可能需要调整模型的参数。
八、总结
大语言模型是一种强大的工具,可以在最少的人工干预下快速、准确地处理自然语言数据。这些模型可用于各种任务,例如文本生成、情感分析、问答系统、自动摘要、机器翻译、文档分类等。凭借LLM快速、准确地处理大量文本数据的能力,它们已成为不同行业各种应用程序的宝贵工具。 NLP 研究人员和专家如果想在这个快速发展的领域保持领先地位,绝对应该熟悉大语言模型。总而言之,大语言模型在 NLP 中发挥着重要作用,因为它们使机器能够更好地理解自然语言并在处理文本时生成更准确的结果。通过利用深度学习神经网络等人工智能技术,这些模型可以快速分析大量数据并提供高度准确的结果,可用于不同行业的各种应用。
九、References
-
Neural Machine Translation by Jointly Learning to Align and Translate (2014) by Bahdanau, Cho, and Bengio, https://arxiv.org/abs/1409.0473
-
Attention Is All You Need (2017) by Vaswani, Shazeer, Parmar, Uszkoreit, Jones, Gomez, Kaiser, and Polosukhin, https://arxiv.org/abs/1706.03762
-
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding (2018) by Devlin, Chang, Lee, and Toutanova, https://arxiv.org/abs/1810.04805
-
Improving Language Understanding by Generative Pre-Training (2018) by Radford and Narasimhan, [PDF] Improving Language Understanding by Generative Pre-Training | Semantic Scholar
-
BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension (2019), by Lewis, Liu, Goyal, Ghazvininejad, Mohamed, Levy, Stoyanov, and Zettlemoyer, https://arxiv.org/abs/1910.13461
-
Harnessing the Power of LLMs in Practice: A Survey on ChatGPT and Beyond (2023) by Yang, Jin, Tang, Han, Feng, Jiang, Yin, and Hu, https://arxiv.org/abs/2304.13712
相关文章:
大语言模型初学者指南 (2023)
大语言模型 (LLM) 是深度学习的一个子集,它正在彻底改变自然语言处理领域。它们是功能强大的通用语言模型,可以针对大量数据进行预训练,然后针对特定任务进行微调。这使得LLM能够拥有大量的一般数据。如果一个人想将LLM用于特定目的ÿ…...

日常生活小技巧 -- 单位换算
开发过程中经常需要需要单位换算的地方。 可以使用工具进行转换: 工具:单位转换 常用单位: 1、角度转换 1弧度(rad) 180/PI 度(deg) 57.29577951308232 度(deg) 1度…...

利用深度蛋白质序列嵌入方法通过 Siamese neural network 对 virus-host PPIs 进行精准预测【Patterns,2022】
研究背景: 病毒感染可以导致多种组织特异性损伤,所以 virus-host PPIs 的预测有助于新的治疗方法的研究;目前已有的一些 virus-host PPIs 鉴定或预测方法效果有限(传统实验方法费时费力、计算方法要么基于蛋白结构或基因ÿ…...
opencv 车牌号的定位和识别+UI界面识别系统
目录 一、实现和完整UI视频效果展示 主界面: 识别结果界面:(识别车牌颜色和车牌号) 查看历史记录界面: 二、原理介绍: 车牌检测->图像灰度化->Canny边缘检测->膨胀与腐蚀 边缘检测及预处理…...

如何使用CSS实现一个自适应两栏布局,其中一栏固定宽度,另一栏自适应宽度?
聚沙成塔每天进步一点点 ⭐ 专栏简介⭐ 使用Float属性⭐ 使用Flexbox布局⭐ 写在最后 ⭐ 专栏简介 前端入门之旅:探索Web开发的奇妙世界 记得点击上方或者右侧链接订阅本专栏哦 几何带你启航前端之旅 欢迎来到前端入门之旅!这个专栏是为那些对Web开发感…...
的结构和数据)
【PostgreSQL】导出数据库表(或序列)的结构和数据
导出 PostgreSQL 数据库的结构和数据 要导出 PostgreSQL 数据库的结构和数据,你可以使用 pg_dump 命令行工具。pg_dump 可以生成一个 SQL 脚本文件,其中包含了数据库的结构(表、索引、视图等)以及数据。下面是如何使用 pg_dump 导…...

Arcgis colorRmap
arcgis中colorRmap对应的名称: 信息来源:https://developers.arcgis.com/documentation/common-data-types/raster-function-objects.htm 在arcpy中使用方法: import arcpy cr arcpy.mp.ColorRamp("Yellow to Red")python中 ma…...

[JDK8环境下的HashMap类应用及源码分析] capacity实验
🌹作者主页:青花锁 🌹简介:Java领域优质创作者🏆、Java微服务架构公号作者😄、CSDN博客专家 🌹简历模板、学习资料、面试题库、技术互助 🌹文末获取联系方式 📝 系列文章目录 [Java基础] StringBuffer 和 StringBuilder 类应用及源码分析 [Java基础] 数组应用…...

【自动驾驶】TI SK-TDA4VM 开发板上电调试,AI Demo运行
1. 设备清单 TDA4VM Edge AI 入门套件【略】USB 摄像头(任何符合 V4L2 标准的 1MP/2MP 摄像头,例如:罗技 C270/C920/C922)全高清 eDP/HDMI 显示屏最低 16GB 高性能 SD 卡连接到互联网的 100Base-T 以太网电缆【略】UART电缆外部电源或电源附件要求: 标称输出电压:5-20VDC…...
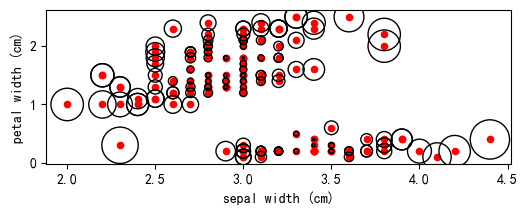
基于LOF算法的异常值检测
目录 LOF算法简介Sklearn官网LOF算法应用实例1Sklearn官网LOF算法应用实例2基于LOF算法鸢尾花数据集异常值检测读取数据构造数据可视化,画出可疑异常点LOF算法 LOF算法简介 LOF异常检测算法是一种基于密度的异常检测算法,基于密度的异常检测算法主要思想…...

软考-系统可靠性原理
系统可靠性原理...

【Unity】【Amplify Shader Editor】ASE入门系列教程第二课 硬边溶解
黑色为0,白色为1 新建材质(不受光照影响) 拖入图片 设置 添加节点: 快捷键:K 组合通道:快捷键 V 完成图...

对神经网络理解的个人记录
对神经网络理解的个人记录 一、 神经网络为什么可以拟合函数、非线性函数二、 用向量表示特征(语音、文本、视频)。然后如何计算向量之间的相似度2.1 欧氏距离的计算2.2 点积运算2.3 余弦相似度计算一、 神经网络为什么可以拟合函数、非线性函数 第一个小短片:讲解神经网络为什…...

华为数通方向HCIP-DataCom H12-821题库(单选题:61-80)
第61题 关于 BGP 的Keepalive报文消息的描述,错误的是 A、Keepalive周期性的在两个BGP邻居之间发送 B、Keepalive报文主要用于对等路由器间的运行状态和链路的可用性确认 C、Keepalive 报文只包含一个BGP数据报头 D、缺省情况下,Keepalive 的时间间隔是180s 答案ÿ…...

Unity带有时效性的数据存储
Unity带有时效性的数据存储 引言 在Unity项目开发中,有时候会遇到带有时效性的数据存储,比如账号信息、token等,都是具有时效性的,这时候我们就需要在这些信息过期的时候将对应的信息作废。 实现 这个功能怎么实现呢ÿ…...

vue 子组件 emit传递事件和事件数据给父组件
1 子组件通过emit 函数 传递事件名init-complete 和 数据dateRange this.$emit(init-complete, dateRange) 2 父组件 创建方法 接收数据 handleInitComplete(dateRange) {} 3 父组件 创建的方法 和 子组件事件绑定 <component :is"currentComponent" :passOb…...
Zenity 简介
什么使 Zenity Zenity 是一个开源的命令行工具,它提供了一种简单的方式来创建图形化的用户界面(GUI)对话框,以与用户进行交互。它基于 GTK 库,可以在 Linux 和其他 UNIX-like 系统上使用。 Zenity 可以通过命令行或脚…...

c# 数组反转
一个数组是{1,2,3,4,5,6},把它变成{6,5,4,3,2,1} 1.创建一个和原数组长度类型一样的数组来接收反转的数据 private static void Main(string[] a…...

CSS学习笔记01
CSS笔记01 什么是CSS CSS(Cascading Style Sheets ):层叠样式表,也可以叫做级联样式表,是一种用来表现 HTML 或 XML 等文件样式的计算机语言。字体,颜色,边距,高度,宽度…...

数据结构,队列,顺序表队列,链表队列
队列是一种常见的数据结构,它具有先进先出(First-In-First-Out,FIFO)的特性,类似于排队等候的场景。以下是队列的要点: 1. 定义:队列是一种线性数据结构,由一系列元素组成ÿ…...

FPG财盛国际:数字化能力升级的全面观察
FPG财盛国际:数字化能力升级的全面观察在评估金融服务平台时,监管合规、技术能力、客户服务等维度构成了重要的观察方向。FPG财盛国际作为业内较为活跃的服务机构,其在这些方面的实践具有一定的参考价值。本文将围绕评测视角,对其…...

基于 ESP32-S3 的四博 AI 双目智能音箱工程方案:四路触摸、IMU 姿态识别、震动反馈、双目屏状态机与语音克隆知识库接入
基于 ESP32-S3 的四博 AI 双目智能音箱工程方案:四路触摸、IMU 姿态识别、震动反馈、双目屏状态机与语音克隆知识库接入1. 方案概述本文设计一套基于 ESP32-S3 的四博 AI 双目智能音箱工程方案。系统目标是实现:1. 双目光屏表情显示 2. 四路触控输入 3. …...

开源监控仪表盘Hermes-Dashboard:轻量级微服务健康状态聚合方案
1. 项目概述:一个面向开发者的开源监控仪表盘最近在折腾一个内部服务,部署了十几个微服务实例,日志和指标散落在各处,想找个统一的视图看看整体运行状态。市面上成熟的监控方案不少,比如 Grafana 配 Prometheus&#x…...

量子金融强化学习:FinRL-Library实现AI量化交易的终极指南
量子金融强化学习:FinRL-Library实现AI量化交易的终极指南 【免费下载链接】FinRL FinRL: Financial Reinforcement Learning. 🔥 项目地址: https://gitcode.com/gh_mirrors/fi/FinRL-Library FinRL-Library作为金融强化学习领域的开源框架&…...

深入解析ZYNQ启动流程:从Boot引脚到FSBL的完整路径
1. ZYNQ启动流程全景概览 当你第一次拿到一块ZYNQ开发板时,按下电源键后究竟发生了什么?这个问题困扰过很多嵌入式开发者。作为Xilinx推出的经典SoC芯片,ZYNQ的启动流程就像一场精心编排的交响乐,每个环节都环环相扣。我当年调试第…...

Blender 3MF插件:从设计到打印的无缝桥梁 [特殊字符]
Blender 3MF插件:从设计到打印的无缝桥梁 🚀 【免费下载链接】Blender3mfFormat Blender add-on to import/export 3MF files 项目地址: https://gitcode.com/gh_mirrors/bl/Blender3mfFormat 还在为3D模型在不同软件间转换而烦恼吗?B…...

为LLM构建安全代码执行环境:e2b代码解释器实战指南
1. 项目概述:当LLM拥有一个真正的代码执行环境最近在折腾AI应用开发,特别是想让大语言模型(LLM)不只是“纸上谈兵”,而是能真正动手执行代码、处理数据、生成图表。这让我找到了一个非常有意思的项目:e2b-d…...

Halcon局部阈值分割避坑指南:dyn_threshold与var_threshold到底怎么选?
Halcon局部阈值分割避坑指南:dyn_threshold与var_threshold到底怎么选? 在工业视觉检测中,遇到反光金属表面的划痕识别或明暗不均背景下的轮廓定位时,全局阈值分割往往力不从心。Halcon提供的dyn_threshold和var_threshold两个局部…...

链表存储式栈
#include <stdio.h> #include <stdlib.h>#include <stdio.h> #include <stdlib.h> #include <string.h>#include <stdlib.h> typedef struct stack_node{int data;struct stack_node * next; } STstacknode; /*声明一个结构体来存储栈顶&a…...

数据中心48V直连供电架构:从效率瓶颈到硬件设计实战
1. 数据中心供电演进:从香农理论到48V直连架构1948年,克劳德香农发表《通信的数学理论》,用1和0的二进制语言为信息时代奠基。六十八年后的今天,当我们谈论数据中心——这个承载着全球信息洪流的数字心脏时,讨论的焦点…...