初步介绍CUDA中的统一内存
初步介绍CUDA中的统一内存
更多精彩内容:
https://www.nvidia.cn/gtc-global/?ncid=ref-dev-876561
文章目录
- 初步介绍CUDA中的统一内存
- 为此,我向您介绍了统一内存,它可以非常轻松地分配和访问可由系统中任何处理器、CPU 或 GPU 上运行的代码使用的数据。
- Fast GPU, Fast Memory… Right?
- 什么是统一内存?
- 当我在Kepler平台上调用cudaMallocManaged()时会发生什么?
- 当我在Pascal平台上调用cudaMallocManaged()时会发生什么?
- 我该怎么办?
- 初始化内核中的数据
- 多次运行
- 预获取
- 关于并发的说明
- 统一内存在 Pascal 和更高版本 GPU 上的优势

为此,我向您介绍了统一内存,它可以非常轻松地分配和访问可由系统中任何处理器、CPU 或 GPU 上运行的代码使用的数据。
首先,因为 NVIDIA Titan X 和 NVIDIA Tesla P100 等 Pascal GPU 是第一批包含页面迁移引擎的 GPU,该引擎是统一内存页面错误和页面迁移的硬件支持。 第二个原因是它提供了一个很好的机会来了解更多关于统一内存的信息。
Fast GPU, Fast Memory… Right?
对! 但是让我们看看。 首先,我将重新打印在两个 NVIDIA Kepler GPU 上运行的结果(一个在我的笔记本电脑上,一个在服务器上)。
| Laptop (GeForce GT 750M) | Laptop (GeForce GT 750M) | Server (Tesla K80) | Server (Tesla K80) | |
|---|---|---|---|---|
| Version | Time | Bandwidth | Time | Bandwidth |
| 1 CUDA Thread | 411ms | 30.6 MB/s | 463ms | 27.2 MB/s |
| 1 CUDA Block | 3.2ms | 3.9 GB/s | 2.7ms | 4.7 GB/s |
| Many CUDA Blocks | 0.68ms | 18.5 GB/s | 0.094ms | 134 GB/s |
现在让我们尝试在基于 Pascal GP100 GPU 的非常快的 Tesla P100 加速器上运行。
> nvprof ./add_grid
...
Time(%) Time Calls Avg Min Max Name
100.00% 2.1192ms 1 2.1192ms 2.1192ms 2.1192ms add(int, float*, float*)
嗯,低于 6 GB/s:比在我的笔记本电脑的基于 Kepler 的 GeForce GPU 上运行要慢。 不过,不要气馁; 我们可以解决这个问题。 为了理解如何,我将不得不告诉你更多关于统一内存的信息。
下面是参考,这是上次 add_grid.cu 的完整代码。
#include <iostream>
#include <math.h>// CUDA kernel to add elements of two arrays
__global__
void add(int n, float *x, float *y)
{int index = blockIdx.x * blockDim.x + threadIdx.x;int stride = blockDim.x * gridDim.x;for (int i = index; i < n; i += stride)y[i] = x[i] + y[i];
}int main(void)
{int N = 1<<20;float *x, *y;// Allocate Unified Memory -- accessible from CPU or GPUcudaMallocManaged(&x, N*sizeof(float));cudaMallocManaged(&y, N*sizeof(float));// initialize x and y arrays on the hostfor (int i = 0; i < N; i++) {x[i] = 1.0f;y[i] = 2.0f;}// Launch kernel on 1M elements on the GPUint blockSize = 256;int numBlocks = (N + blockSize - 1) / blockSize;add<<<numBlocks, blockSize>>>(N, x, y);// Wait for GPU to finish before accessing on hostcudaDeviceSynchronize();// Check for errors (all values should be 3.0f)float maxError = 0.0f;for (int i = 0; i < N; i++)maxError = fmax(maxError, fabs(y[i]-3.0f));std::cout << "Max error: " << maxError << std::endl;// Free memorycudaFree(x);cudaFree(y);return 0;
}
分配和初始化内存的代码在第 19-27 行。
什么是统一内存?
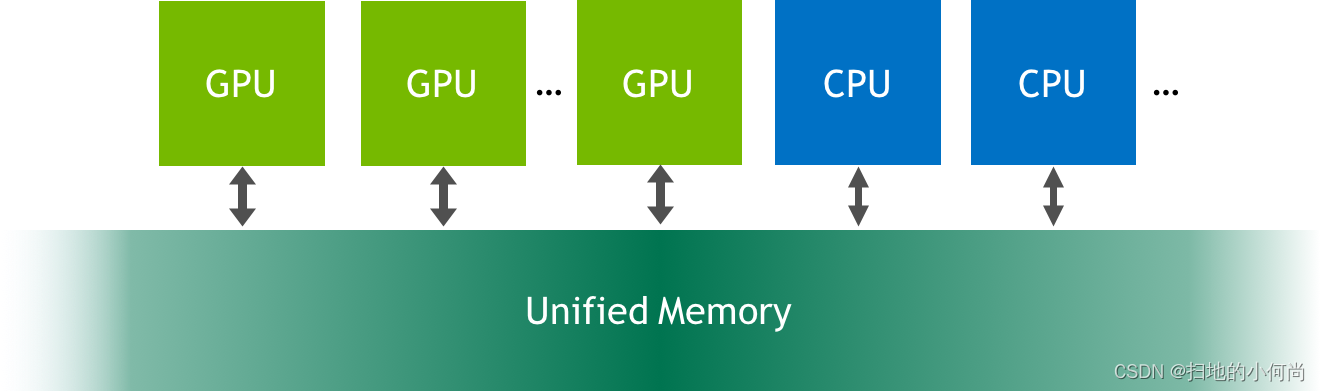
统一内存是可从系统中的任何处理器访问的单个内存地址空间(参见上图)。 这种硬件/软件技术允许应用程序分配可以从 CPU 或 GPU 上运行的代码读取或写入的数据。 分配统一内存就像用调用 cudaMallocManaged() 替换对 malloc() 或 new 的调用一样简单,这是一个分配函数,它返回一个可从任何处理器访问的指针(下文中的 ptr)。
cudaError_t cudaMallocManaged(void** ptr, size_t size);
当在 CPU 或 GPU 上运行的代码访问以这种方式分配的数据(通常称为 CUDA 托管数据)时,CUDA 系统软件和/或硬件负责将内存页面迁移到访问处理器的内存。 这里重要的一点是,Pascal GPU 架构是第一个通过其页面迁移引擎为虚拟内存页面错误和页面迁移提供硬件支持的架构。 基于 Kepler 和 Maxwell 架构的旧 GPU 也支持更有限的统一内存形式。
当我在Kepler平台上调用cudaMallocManaged()时会发生什么?
在具有 pre-Pascal GPU (如 Tesla K80)的系统上,调用 cudaMallocManaged() 会在调用时处于活动状态的 GPU 设备上分配 size 字节的托管内存。 在内部,驱动程序还为分配覆盖的所有页面设置页表条目,以便系统知道这些页面驻留在该 GPU 上。
因此,在我们的示例中,在 Tesla K80 GPU(Kepler 架构)上运行时,x 和 y 最初都完全驻留在 GPU 内存中。 然后在从第 6 行开始的循环中,CPU 遍历两个数组,将它们的元素分别初始化为 1.0f 和 2.0f。 由于页面最初驻留在设备内存中,因此对于它写入的每个数组页面,CPU 都会发生页面错误,并且 GPU 驱动程序会将页面从设备内存迁移到 CPU 内存。 循环之后,两个数组的所有页面都驻留在 CPU 内存中。
在 CPU 上初始化数据后,程序启动 add() 内核将 x 的元素添加到 y 的元素中。
add<<<1, 256>>>(N, x, y);
在 pre-Pascal GPU 上,在启动内核时,CUDA 运行时必须将之前迁移到主机内存或另一个 GPU 的所有页面迁移回运行内核的设备的设备内存。 由于这些较旧的 GPU 不能出现页面错误,因此所有数据都必须驻留在 GPU 上,以防内核访问它(即使它不会访问)。 这意味着每次内核启动都有潜在的迁移开销。
这就是我在 K80 或我的 Macbook Pro 上运行程序时发生的情况。 但是请注意,分析器将内核运行时间与迁移时间分开显示,因为迁移发生在内核运行之前。
==15638== Profiling application: ./add_grid
==15638== Profiling result:
Time(%) Time Calls Avg Min Max Name
100.00% 93.471us 1 93.471us 93.471us 93.471us add(int, float*, float*)==15638== Unified Memory profiling result:
Device "Tesla K80 (0)"Count Avg Size Min Size Max Size Total Size Total Time Name6 1.3333MB 896.00KB 2.0000MB 8.000000MB 1.154720ms Host To Device102 120.47KB 4.0000KB 0.9961MB 12.00000MB 1.895040ms Device To Host
Total CPU Page faults: 51
当我在Pascal平台上调用cudaMallocManaged()时会发生什么?
在 Pascal 和更高版本的 GPU 上,当 cudaMallocManaged() 返回时,托管内存可能不会被物理分配;它只能在访问(或预取)时填充。换句话说,页面和页表条目可能不会被创建,直到它们被 GPU 或 CPU 访问。页面可以随时迁移到任何处理器的内存,驱动程序采用启发式方法来维护数据局部性并防止过多的页面错误。 (注意:应用程序可以使用 cudaMemAdvise() 引导驱动程序,并使用 cudaMemPrefetchAsync() 显式迁移内存,如这篇博文所述)。
与pre-Pascal GPU 不同,Tesla P100 支持硬件页面错误和页面迁移。因此在这种情况下,运行时不会在运行内核之前自动将所有页面复制回 GPU。内核在没有任何迁移开销的情况下启动,当它访问任何缺少的页面时,GPU 会停止访问线程的执行,并且页面迁移引擎会在恢复线程之前将页面迁移到设备。
这意味着当我在 Tesla P100 (2.1192 ms) 上运行我的程序时,迁移的成本包含在内核运行时间中。在这个内核中,数组中的每一页都是由 CPU 写入,然后由 GPU 上的 CUDA 内核访问,导致内核等待大量的页面迁移。这就是为什么分析器测量的内核时间在像 Tesla P100 这样的 Pascal GPU 上更长的原因。让我们看看 P100 上程序的完整 nvprof 输出。
==19278== Profiling application: ./add_grid
==19278== Profiling result:
Time(%) Time Calls Avg Min Max Name
100.00% 2.1192ms 1 2.1192ms 2.1192ms 2.1192ms add(int, float*, float*)==19278== Unified Memory profiling result:
Device "Tesla P100-PCIE-16GB (0)"Count Avg Size Min Size Max Size Total Size Total Time Name146 56.109KB 4.0000KB 988.00KB 8.000000MB 860.5760us Host To Device24 170.67KB 4.0000KB 0.9961MB 4.000000MB 339.5520us Device To Host12 - - - - 1.067526ms GPU Page fault groups
Total CPU Page faults: 36
如您所见,有许多主机到设备的页面错误,降低了 CUDA 内核实现的吞吐量。
我该怎么办?
在实际应用程序中,GPU 可能会在 CPU 不接触数据的情况下对数据执行更多计算(可能很多次)。 这段简单代码中的迁移开销是由 CPU 初始化数据而 GPU 只使用一次数据造成的。 有几种不同的方法可以消除或更改迁移开销,以更准确地测量vector add内核性能。
- 将数据初始化移动到另一个 CUDA 内核中的 GPU。
- 多次运行内核并查看平均和最小运行时间。
- 在运行内核之前将数据预取到 GPU 内存。
让我们来看看这三种方法中的每一种。
初始化内核中的数据
如果我们将初始化从 CPU 转移到 GPU,则添加内核不会出现页面错误。 这是一个用于初始化数据的简单 CUDA C++ 内核。 我们可以通过启动这个内核来替换初始化 x 和 y 的主机代码。
__global__ void init(int n, float *x, float *y) {int index = threadIdx.x + blockIdx.x * blockDim.x;int stride = blockDim.x * gridDim.x;for (int i = index; i < n; i += stride) {x[i] = 1.0f;y[i] = 2.0f;}
}当我这样做时,我在 Tesla P100 GPU 的配置文件中看到了两个内核:
==44292== Profiling application: ./add_grid_init
==44292== Profiling result:
Time(%) Time Calls Avg Min Max Name98.06% 1.3018ms 1 1.3018ms 1.3018ms 1.3018ms init(int, float*, float*)1.94% 25.792us 1 25.792us 25.792us 25.792us add(int, float*, float*)==44292== Unified Memory profiling result:
Device "Tesla P100-PCIE-16GB (0)"Count Avg Size Min Size Max Size Total Size Total Time Name24 170.67KB 4.0000KB 0.9961MB 4.000000MB 344.2880us Device To Host16 - - - - 551.9940us GPU Page fault groups
Total CPU Page faults: 12
add 内核现在运行得更快:25.8us,相当于近 500 GB/s。 这是计算带宽的方法。
带宽 = 字节/秒 = 3 * 4,194,304 bytes * 1e-9 bytes/GB) / 25.8e-6s = 488 GB/s
(要了解如何计算理论和实现的带宽,请参阅这篇文章。)仍然存在设备到主机页面错误,但这是由于程序末尾的循环检查 CPU 上的结果。
多次运行
另一种方法是多次运行内核并查看分析器中的平均时间。 为此,我需要修改我的错误检查代码,以便正确报告结果。 以下是在 Tesla P100 上运行内核 100 次的结果:
==48760== Profiling application: ./add_grid_many
==48760== Profiling result:
Time(%) Time Calls Avg Min Max Name
100.00% 4.5526ms 100 45.526us 24.479us 2.0616ms add(int, float*, float*)==48760== Unified Memory profiling result:
Device "Tesla P100-PCIE-16GB (0)"Count Avg Size Min Size Max Size Total Size Total Time Name174 47.080KB 4.0000KB 0.9844MB 8.000000MB 829.2480us Host To Device24 170.67KB 4.0000KB 0.9961MB 4.000000MB 339.7760us Device To Host14 - - - - 1.008684ms GPU Page fault groups
Total CPU Page faults: 36
最小内核运行时间仅为 24.5 微秒,这意味着它实现了超过 500GB/s 的内存带宽。 我还包括了来自 nvprof 的统一内存分析输出,它显示了从主机到设备总共 8MB 的页面错误,对应于第一次添加运行时通过页面错误复制到设备的两个 4MB 数组(x 和 y)。
预获取
第三种方法是使用统一内存预取在初始化数据后将数据移动到 GPU。 CUDA 为此提供了 cudaMemPrefetchAsync()。 我可以在内核启动之前添加以下代码。
// Prefetch the data to the GPUint device = -1;cudaGetDevice(&device);cudaMemPrefetchAsync(x, N*sizeof(float), device, NULL);cudaMemPrefetchAsync(y, N*sizeof(float), device, NULL);// Run kernel on 1M elements on the GPUint blockSize = 256;int numBlocks = (N + blockSize - 1) / blockSize;saxpy<<<numBlocks, blockSize>>>(N, 1.0f, x, y);
现在,当我在 Tesla P100 上进行分析时,我得到以下输出。
==50360== Profiling application: ./add_grid_prefetch
==50360== Profiling result:
Time(%) Time Calls Avg Min Max Name
100.00% 26.112us 1 26.112us 26.112us 26.112us add(int, float*, float*)==50360== Unified Memory profiling result:
Device "Tesla P100-PCIE-16GB (0)"Count Avg Size Min Size Max Size Total Size Total Time Name4 2.0000MB 2.0000MB 2.0000MB 8.000000MB 689.0560us Host To Device24 170.67KB 4.0000KB 0.9961MB 4.000000MB 346.5600us Device To Host
Total CPU Page faults: 36
在这里,您可以看到内核只运行了一次,耗时 26.1us — 与之前显示的 100 次运行中的最快速度相似。 您还可以看到不再报告任何 GPU 页面错误,并且由于预取,主机到设备的传输仅显示为四个 2MB 传输。
现在我们让它在 P100 上快速运行,让我们将它添加到上次的结果表中。
| Laptop (GeForce GT 750M) | Laptop (GeForce GT 750M) | Server (Tesla K80) | Server (Tesla K80) | Server (Tesla P100) | Server (Tesla P100) | |
|---|---|---|---|---|---|---|
| Version | Time | Bandwidth | Time | Bandwidth | Time | Bandwidth |
| 1 CUDA Thread | 411ms | 30.6 MB/s | 463ms | 27.2 MB/s | NA | NA |
| 1 CUDA Block | 3.2ms | 3.9 GB/s | 2.7ms | 4.7 GB/s | NA | NA |
| Many CUDA Blocks | 0.68ms | 18.5 GB/s | 0.094ms | 134 GB/s | 0.025ms | 503 GB/s |
关于并发的说明
请记住,您的系统有多个处理器同时运行您的 CUDA 应用程序的一部分:一个或多个 CPU 和一个或多个 GPU。即使在我们的简单示例中,也有一个 CPU 线程和一个 GPU 执行上下文。因此,在访问任一处理器上的托管分配时,我们必须小心,以确保没有竞争条件。
无法从计算能力低于 6.0 的 CPU 和 GPU 同时访问托管内存。这是因为 pre-Pascal GPU 缺乏硬件页面错误,因此无法保证一致性。在这些 GPU 上,当内核运行时从 CPU 进行访问将导致segmentation fault。
在 Pascal 和更高版本的 GPU 上,CPU 和 GPU 可以同时访问托管内存,因为它们都可以处理页面错误;但是,由应用程序开发人员来确保不存在由同时访问引起的竞争条件。
在我们的简单示例中,我们在内核启动后调用了 cudaDeviceSynchronize()。这可确保内核在 CPU 尝试从托管内存指针读取结果之前运行完成。否则,CPU 可能会读取无效数据(在 Pascal 和更高版本上),或出现segmentation fault(在pre-Pascal GPU 上)。
统一内存在 Pascal 和更高版本 GPU 上的优势
从 Pascal GPU 架构开始,统一内存功能通过 49 位虚拟寻址和按需页面迁移得到显着改进。 49 位虚拟地址足以让 GPU 访问整个系统内存以及系统中所有 GPU 的内存。页面迁移引擎允许 GPU 线程在非驻留内存访问时出错,因此系统可以根据需要将页面从系统中的任何位置迁移到 GPU 的内存,以进行高效处理。
换句话说,统一内存透明地启用了超额订阅 GPU 内存,为任何使用统一内存进行分配的代码启用了核外计算(例如 cudaMallocManaged())。无论是在一个 GPU 上还是在多个 GPU 上运行,它都可以“正常工作”而无需对应用程序进行任何修改。
此外,Pascal 和 Volta GPU 支持系统范围的原子内存操作。这意味着您可以从多个 GPU 对系统中任何位置的值进行原子操作。这对于编写高效的多 GPU 协作算法很有用。
请求分页对于以 稀疏 模式访问数据的应用程序特别有益。在某些应用程序中,事先不知道特定处理器将访问哪些特定内存地址。如果没有硬件页面错误,应用程序只能预加载整个阵列,或者承受高延迟的设备外访问(也称为“零复制”)的成本。但是页面错误意味着只需要迁移内核访问的页面。
更多精彩内容:
https://www.nvidia.cn/gtc-global/?ncid=ref-dev-876561
相关文章:
初步介绍CUDA中的统一内存
初步介绍CUDA中的统一内存 更多精彩内容: https://www.nvidia.cn/gtc-global/?ncidref-dev-876561 文章目录初步介绍CUDA中的统一内存为此,我向您介绍了统一内存,它可以非常轻松地分配和访问可由系统中任何处理器、CPU 或 GPU 上运行的代码使用的数据。…...
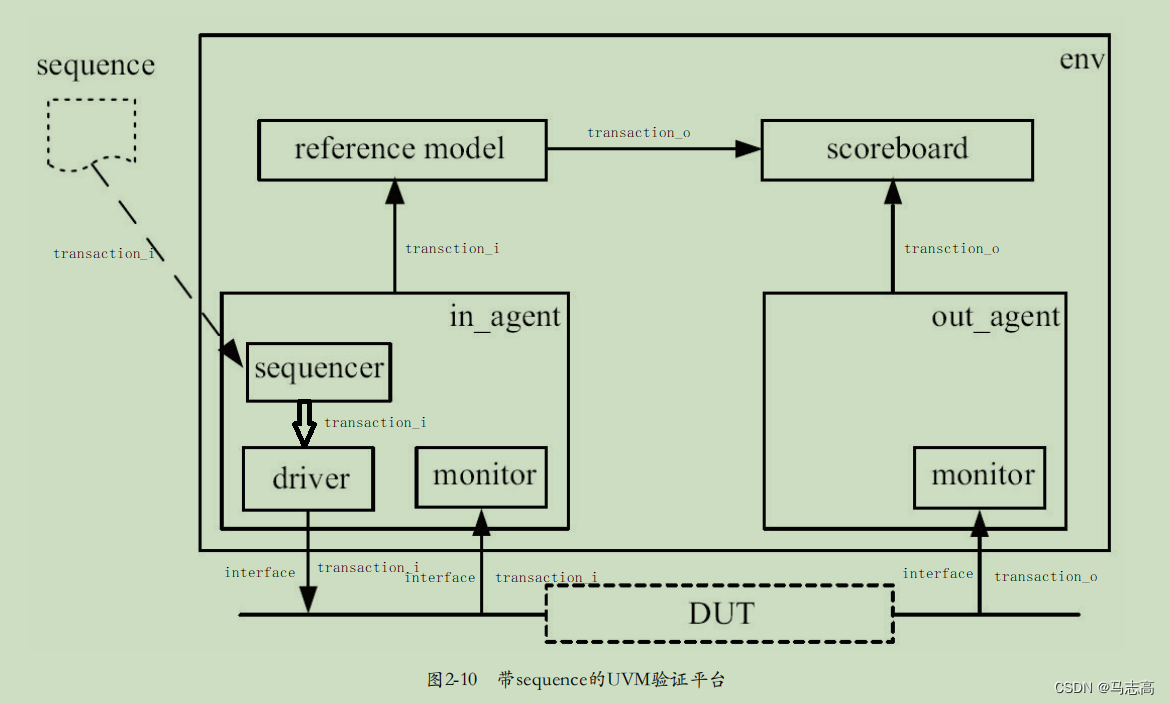
UVM实战--加法器
前言 这里以UVM实战(张强)第二章为基础修改原有的DUT,将DUT修改为加法器,从而修改代码以使得更加深入的了解各个组件的类型和使用。 一. 组件的基本框架 和第二章的平台的主要区别点 (1)有两个transactio…...

Linux系统点亮LED
目录应用层操控硬件的两种方式sysfs 文件系统sysfs 与/sys总结标准接口与非标准接口LED 硬件控制方式编写LED 应用程序在开发板上测试对于一款学习型开发板来说,永远都绕不开LED 这个小小的设备,基本上每块板子都至少会有一颗 LED 小灯,对于我…...
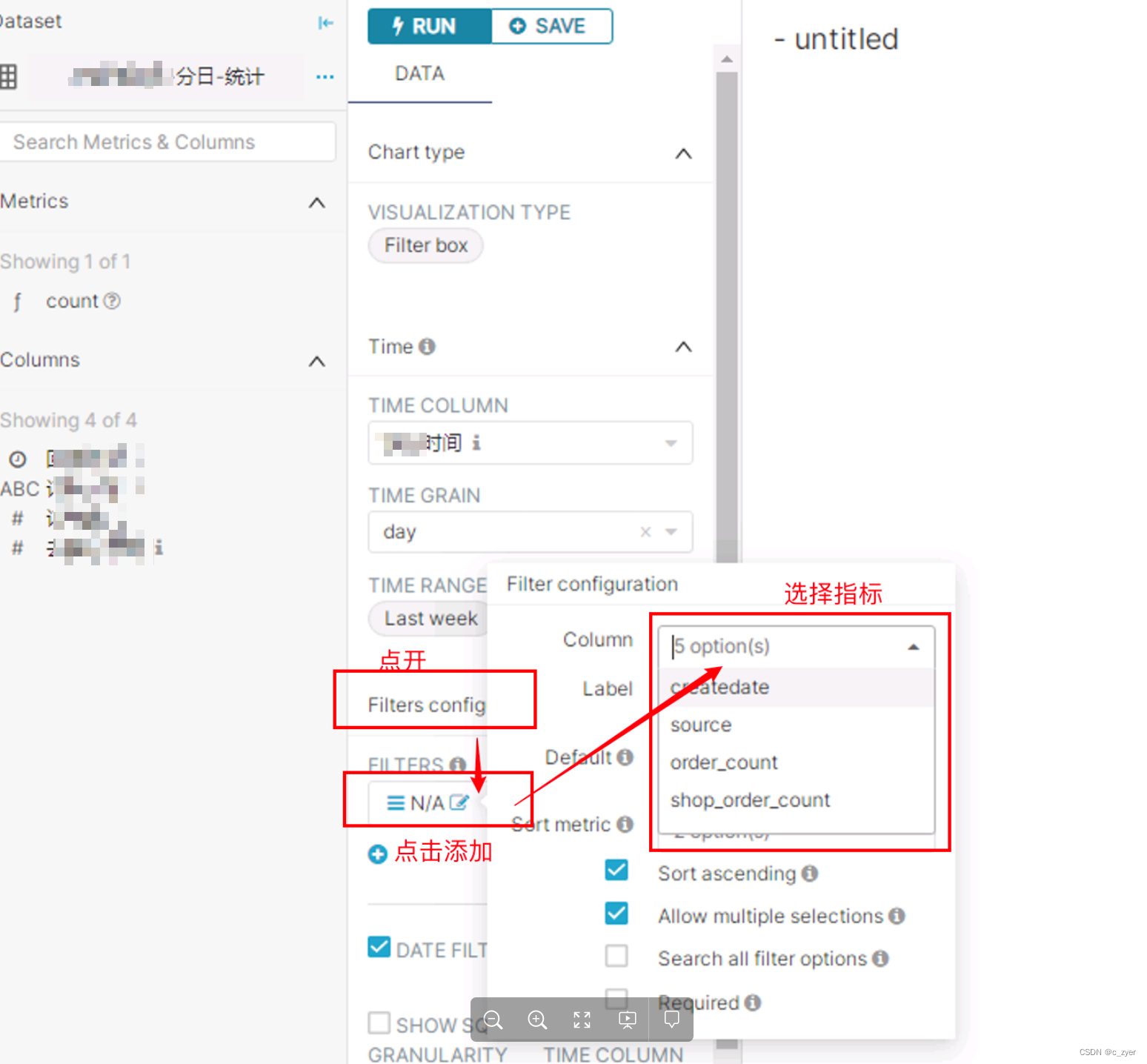
在superset中快速制作报表或仪表盘
在中小型企业,当下需要快速迭代、快速了解运营效果的业务,急需一款开源、好用、能快速迭代生产的报表系统。 老板很关心,BI工程师很关心,同时系统开发人员也同样关心,一个好的技术选型往往能够帮助公司减少很多成本&a…...
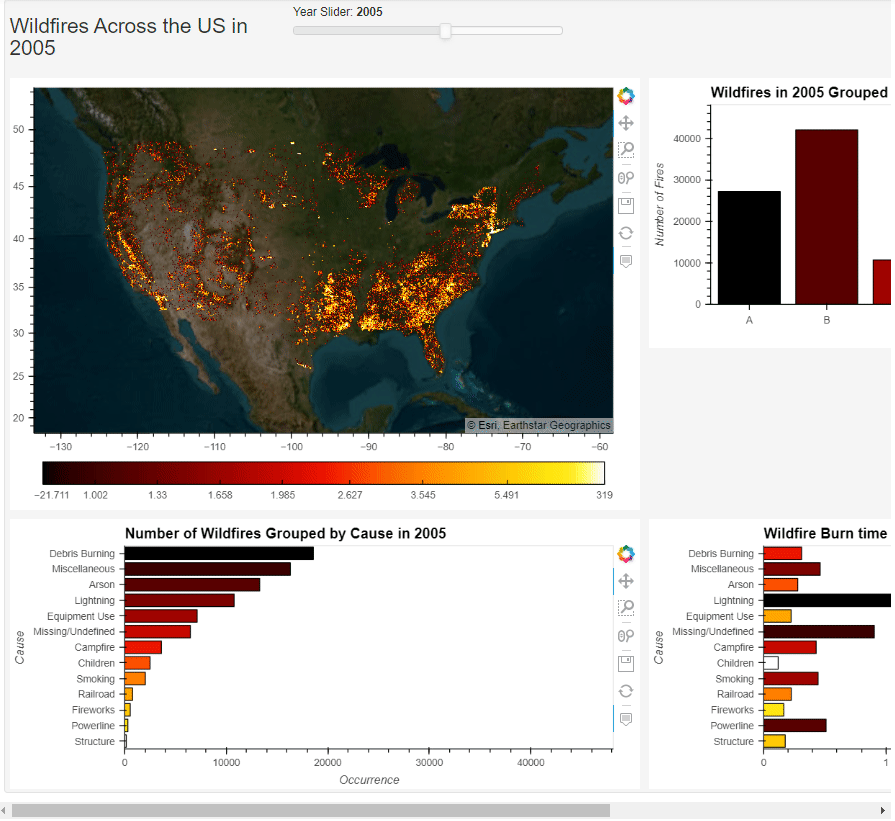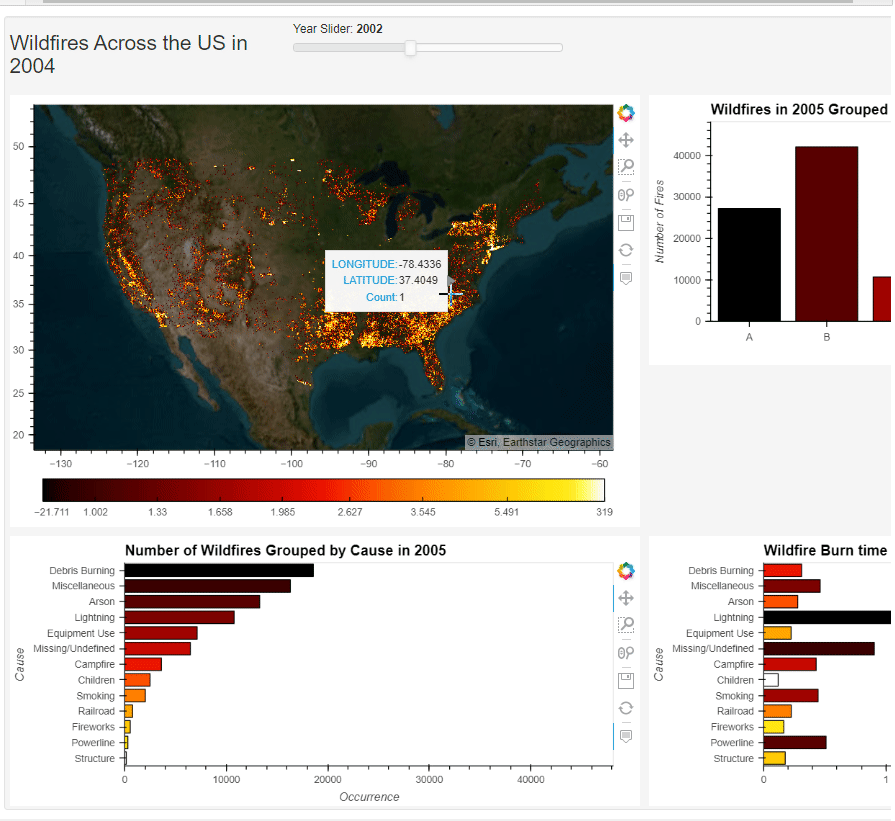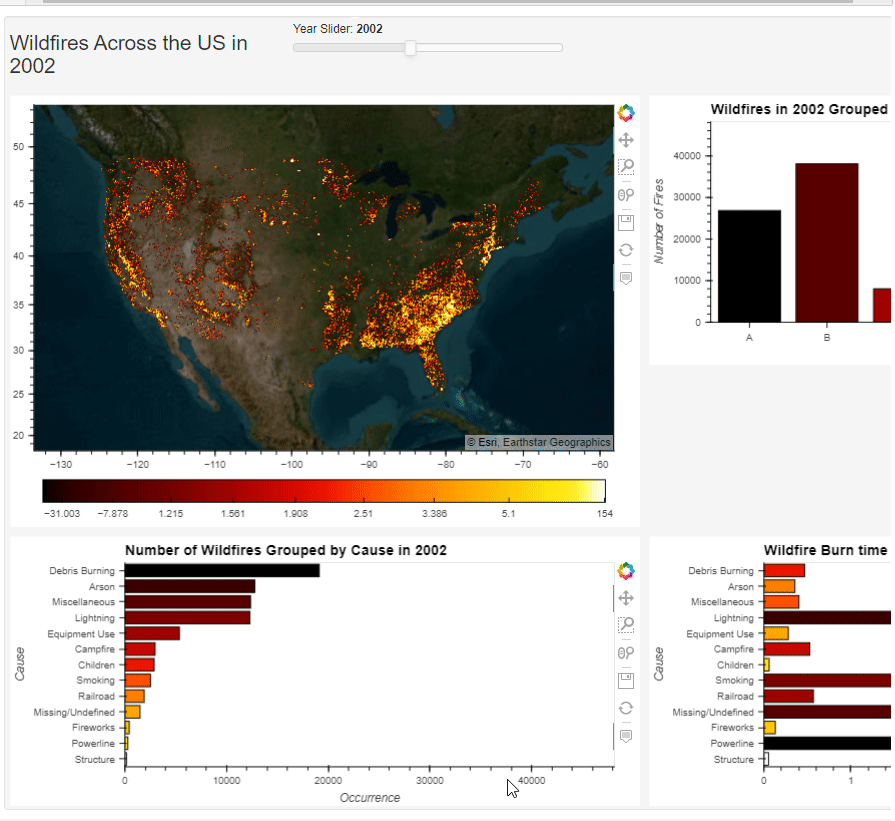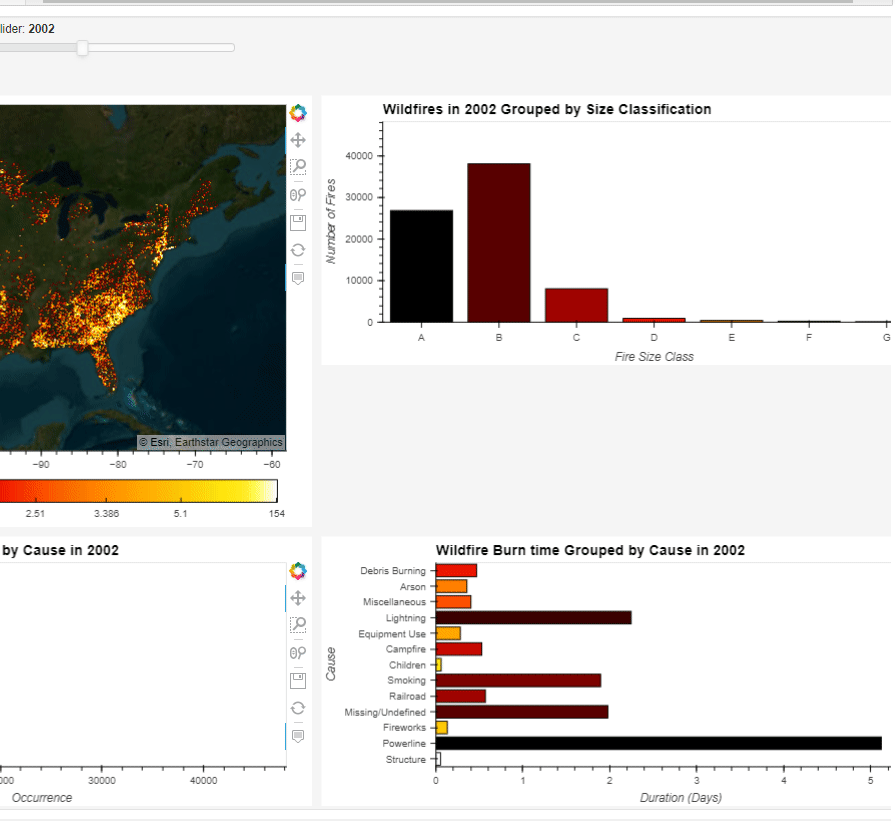
【可视化实战】Python 绘制出来的数据大屏真的太惊艳了
今天我们在进行一个Python数据可视化的实战练习,用到的模块叫做Panel,我们通过调用此模块来绘制动态可交互的图表以及数据大屏的制作。 而本地需要用到的数据集,可在kaggle上面获取 https://www.kaggle.com/datasets/rtatman/188-million-us…...
Obsidium一键编码作业,Obsidia惊人属性
Obsidium一键编码作业,Obsidia惊人属性 每个区域都包含几个可定制的功能,允许用户确定如何完全执行应用程序的安全性。Obsidia的功能区允许用户存储任何调整或一键编码作业。 Obsidia惊人属性: 代码虚拟化:代码虚拟化允许您转换程序代码的特定…...

约束优化:约束优化的三种序列无约束优化方法
文章目录约束优化:约束优化的三种序列无约束优化方法外点罚函数法L2-罚函数法:非精确算法对于等式约束对于不等式约束L1-罚函数法:精确算法内点罚函数法:障碍函数法等式约束优化问题的拉格朗日函数法:Uzawas Method fo…...

RocketMQ快速入门:消息发送、延迟消息、消费重试
一起学编程,让生活更随和! 如果你觉得是个同道中人,欢迎关注博主gzh:【随和的皮蛋桑】。 专注于Java基础、进阶、面试以及计算机基础知识分享🐳。偶尔认知思考、日常水文🐌。 目录1、RocketMQ消息结构1.1…...
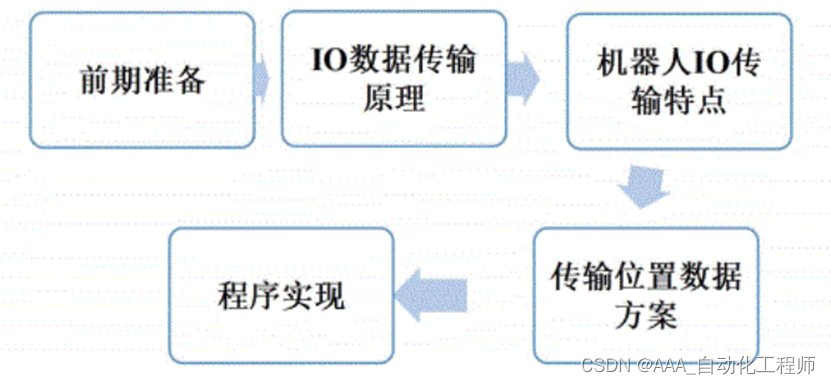
FANUC机器人通过KAREL程序实现与PLC位置坐标通信的具体方法示例
FANUC机器人通过KAREL程序实现与PLC位置坐标通信的具体方法示例 在通信IO点位数量足够的情况下,可以使用机器人的IO点传输位置数据,这里以传输机器人的实时位置为例进行说明。 基本流程如下图所示: 基本步骤可参考如下: 首先确认机器人控制柜已经安装了总线通信软件(例如…...

[蓝桥杯 2015 省 B] 移动距离
蓝桥杯 2015 年省赛 B 组 H 题题目描述X 星球居民小区的楼房全是一样的,并且按矩阵样式排列。其楼房的编号为 1,2,3,⋯ 。当排满一行时,从下一行相邻的楼往反方向排号。比如:当小区排号宽度为 6 时,开始情形如下:我们的…...
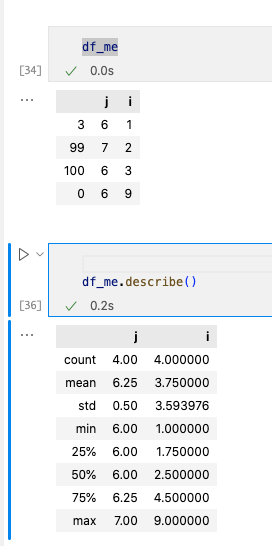
Pandas库入门仅需10分钟
数据处理的时候经常性需要整理出表格,在这里介绍pandas常见使用,目录如下: 数据结构导入导出文件对数据进行操作 – 增加数据(创建数据) – 删除数据 – 改动数据 – 查找数据 – 常用操作(转置࿰…...

python的socket通信中,如何设置可以让两台主机通过外网访问?
要让两台主机通过外网进行Socket通信,需要在网络设置和代码实现两个方面进行相应的配置。下面是具体的步骤: 确认网络环境:首先要确保两台主机都能够通过外网访问。可以通过ping命令或者telnet命令来测试两台主机之间是否可以互相访问。 确定…...
)
检测数据的方法(回顾)
检测数据类型的4种方法typeofinstanceofconstructor{}.toString.call() 检测数据类型的4种方法 typeof 定义 用来检测数据类型的运算符 返回一个字符串,表示操作值的数据类型(7种) number,string,boolean,object,u…...
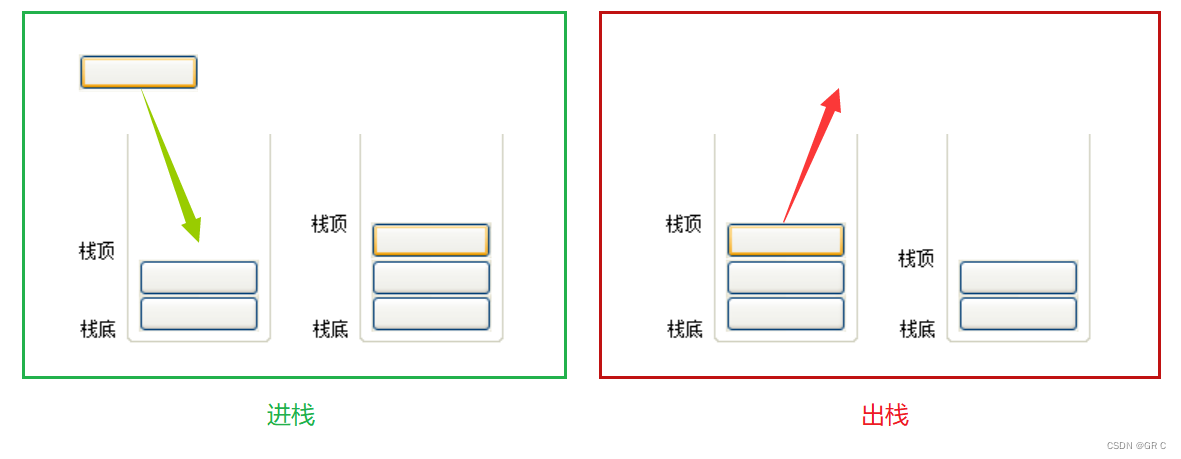
比特数据结构与算法(第三章_上)栈的概念和实现(力扣:20. 有效的括号)
一、栈(stack)栈的概念:① 栈是一种特殊的线性表,它只允许在固定的一端进行插入和删除元素的操作。② 进行数据插入的删除和操作的一端,称为栈顶 。另一端则称为 栈底 。③ 栈中的元素遵守后进先出的原则,即…...
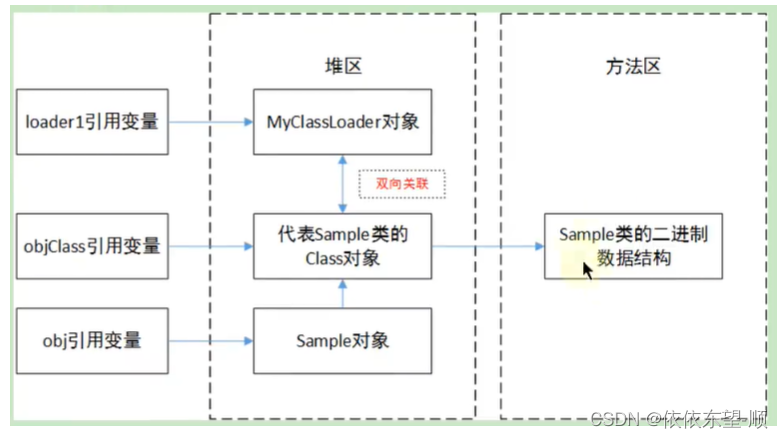
JVM13 类的生命周期
1. 概述 在 Java 中数据类型分为基本数据类型和引用数据类型。基本数据类型由虚拟机预先定义,引用数据类型则需要进行类的加载。 按照 Java 虚拟机规范,从 class 文件到加载到内存中的类,到类卸载出内存为止,它的整个生命周期包…...
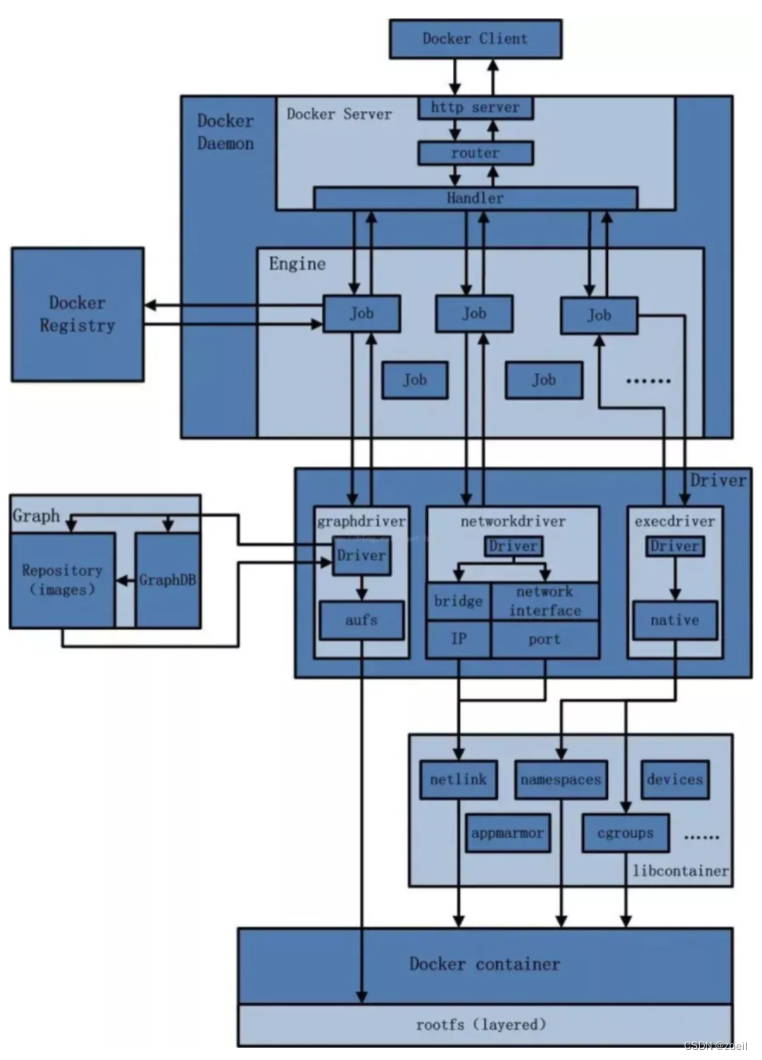
Docker网络模式解析
目录 前言 一、常用基本命令 (一)查看网络 (二)创建网络 (三)查看网络源数据 (四)删除网络 二、网络模式 (一)总体介绍 (二)…...

游山城重庆
山城楼梯多,路都是上坡。 为了赶早上8点从成都到重庆的动车,凌晨5点半就爬起床来,由于昨天喝了咖啡,所以我将尽3点才睡觉,这意味着我只睡了2个多小时。起来简单休息之后,和朋友协商好时间就一起出门了。 …...

Vuex的创建和简单使用
Vuex 1.简介 1.1简介 1.框框里面才是Vuex state:状态数据action:处理异步mutations:处理同步,视图可以同步进行渲染1.2项目创建 1.vue create 名称 2.运行后 3.下载vuex。采用的是基于vue2的版本。 npm install vuex3 --save 4.vu…...

Arduino IDE搭建Heltec开发板开发环境
Arduino IDE搭建Heltec开发板开发环境Heltec开发板开发环境下载与搭建Arduino IDE下载与安装搭建Heltec开发板的开发环境添加package URL方法通过Git的方法安装离线安装Heltec开发板开发环境下载与搭建 Arduino IDE下载与安装 Heltec的ESP系列和大部分的LoRa系列开发板都是用A…...

Using the GNU Compiler Collection 目录翻译
文章目录Introduction1 Programming Languages Supported by GCC2 Language Standards Supported by GCC2.1 C Language3 GCC Command Options3.1 Option Summary4 C Implementation-Defined Behavior6 Extensions to the C Language Family9 Binary Compatibility其他工具10 g…...

3个实用技巧让你彻底告别浏览器自动化测试的版本兼容性烦恼
3个实用技巧让你彻底告别浏览器自动化测试的版本兼容性烦恼 【免费下载链接】chrome-for-testing 项目地址: https://gitcode.com/gh_mirrors/ch/chrome-for-testing 还在为Chrome浏览器和ChromeDriver版本不匹配而头疼吗?Chrome for Testing项目正是为了解…...

Qwen3-14B镜像深度解析:内置权重+FlashAttention-2+PyTorch 2.4优化
Qwen3-14B镜像深度解析:内置权重FlashAttention-2PyTorch 2.4优化 1. 镜像概述与核心优势 Qwen3-14B私有部署镜像是专为RTX 4090D 24GB显存环境优化的开箱即用解决方案。这个镜像最大的特点是将模型权重、运行环境和优化组件全部预装完成,用户无需处理…...

从概念到应用:基于openclaw101.dev功能构思在快马平台构建实战项目
今天想和大家分享一个实战项目经验——如何快速将openclaw101.dev这类技术理念转化为可交互的实际应用。最近我在InsCode(快马)平台上尝试构建了一个任务管理中心SPA,整个过程意外地顺畅,特别适合想快速验证产品原型的开发者。 项目构思 我选择了任务管理…...

实战应用:基于快马ai为全栈项目快速构建集成wsl2开发环境
实战应用:基于快马AI为全栈项目快速构建集成WSL2开发环境 最近在准备一个全栈项目,需要同时开发Python Django后端和Vue.js前端。为了保持开发环境的一致性,我决定使用WSL2来搭建开发环境。下面记录下我的完整配置过程,希望能帮助…...

光通信行业彻底爆了!三项世界纪录背后藏着多少财富密码
在6G尚未正式投入商业应用之际,我国的科研工作者已然悄然斩获了三项世界纪录?于此同时,全球范围内的人工智能领域的大型企业正大肆投入资金用于提升算力,进而直接促使光模块市场变得异常火爆。这背后所蕴含的不仅仅是技术层面的突…...

Qwen3-14B API服务压测报告:QPS 23+,P99延迟<1.2s高并发表现
Qwen3-14B API服务压测报告:QPS 23,P99延迟<1.2s高并发表现 1. 测试环境与配置 1.1 硬件配置 本次压测采用专门优化的Qwen3-14B私有部署镜像,运行在以下硬件环境: GPU:RTX 4090D 24GB显存(与镜像完美…...

如何利用 SEO 标题和关键词提高网站可发现性_如何利用 SEO 标题和关键词进行分析和优化
如何利用 SEO 标题和关键词提高网站可发现性 在当今的数字化时代,网站的可发现性直接关系到其流量和成功。在这个竞争激烈的环境中,搜索引擎优化(SEO)成为了提高网站可发现性的关键。其中,SEO标题和关键词的运用尤为重…...
颠覆屏幕翻译体验:Screen Translator创新技术重构多语言信息获取方式
颠覆屏幕翻译体验:Screen Translator创新技术重构多语言信息获取方式 【免费下载链接】ScreenTranslator Screen capture, OCR and translation tool. 项目地址: https://gitcode.com/gh_mirrors/sc/ScreenTranslator 在全球化协作日益频繁的今天,…...
)
【2026年恒生电子春招- 4月2日-第一题- 等差数列模最大值】(题目+思路+JavaC++Python解析+在线测试)
题目内容 某智能手环公司需统计用户在 $ 2024 $ 年 $ 5 $ 月的健康数据,分析用户的步数达标情况。由于部分设备存在数据上报故障,需在分析中排除故障期间的数据。具体表如下: 用户表( $ users $ )存储用户基本信息 $ user_id $ : $ INT $ 类型,主键,用户唯一标识。 $…...
Buck仿真)
基于Simulink的滞环电压控制(Bang-Bang)Buck仿真
目录 手把手教你学Simulink ——基于Simulink的滞环电压控制(Bang-Bang)Buck仿真 一、问题背景 二、滞环控制原理 1. 控制思想 三、系统架构 四、Simulink 建模步骤 第一步:搭建 Buck 主电路 第二步:实现滞环比较器 第三步:死区时间插入(防直通) 第四步:驱动…...