RNN循环神经网络
目录
一、卷积核与循环核
二、循环核
1.循环核引入
2.循环核:循环核按时间步展开。
3.循环计算层:向输出方向生长。
4.TF描述循环计算层
三、TF描述循环计算
四、RNN使用案例
1.数据集准备
2.Sequential中RNN
3.存储模型,acc和lose可视化曲线和测试交互窗口
五、Embedding编码
Embedding改进上述案例
六、LSTM
1.循环时间核计算过程编辑
2.TF描述LSTM层
3.代码
七、GRU
1.循环时间核计算过程
2.TF描述GRU层
3.代码
总结
一、卷积核与循环核
卷积核:参数空间共享,卷积层提取空间信息。
循环核:参数时间共享,循环层提取时间信息
前向传播:只有ht会变化
反向传播:Wxh、Whh、Why才会变换
二、循环核
1.循环核引入

2.循环核:循环核按时间步展开。
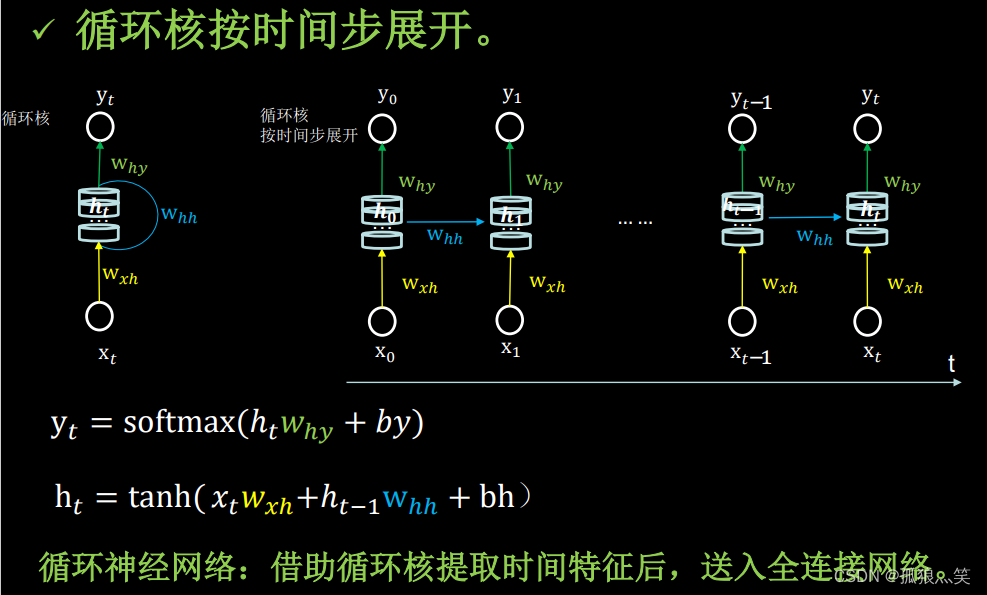
3.循环计算层:向输出方向生长。

4.TF描述循环计算层
# 如何使用
tf.keras.layers.SimpleRNN(记忆体个数,activation=‘激活函数’ ,
return_sequences=是否每个时刻输出ht到下一层)
# 说明
activation=‘激活函数’ (不写,默认使用tanh)
return_sequences=True 各时间步输出ht
return_sequences=False 仅最后时间步输出ht(默认)
例:SimpleRNN(3, return_sequences=True三、TF描述循环计算
举例说明
计算预测abcde

四、RNN使用案例
1.数据集准备
input_word = "abcde"
w_to_id = {'a': 0, 'b': 1, 'c': 2, 'd': 3, 'e': 4} # 单词映射到数值id的词典
id_to_onehot = {0: [1., 0., 0., 0., 0.], 1: [0., 1., 0., 0., 0.], 2: [0., 0., 1., 0., 0.], 3: [0., 0., 0., 1., 0.],4: [0., 0., 0., 0., 1.]} # id编码为one-hotx_train = [id_to_onehot[w_to_id['a']], id_to_onehot[w_to_id['b']], id_to_onehot[w_to_id['c']],id_to_onehot[w_to_id['d']], id_to_onehot[w_to_id['e']]]
y_train = [w_to_id['b'], w_to_id['c'], w_to_id['d'], w_to_id['e'], w_to_id['a']]
# 打乱顺序
np.random.seed(7)
np.random.shuffle(x_train)
np.random.seed(7)
np.random.shuffle(y_train)
tf.random.set_seed(7)
2.Sequential中RNN
# Sequential层中的循环序列Rnn,时间序列
model = tf.keras.Sequential([SimpleRNN(3), # 存储单元Dense(5, activation='softmax')
])model.compile(optimizer=tf.keras.optimizers.Adam(0.01),loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=False),metrics=['sparse_categorical_accuracy'])checkpoint_save_path = "./checkpoint/rnn_onehot_1pre1.ckpt"if os.path.exists(checkpoint_save_path + '.index'):print('-------------load the model-----------------')model.load_weights(checkpoint_save_path)cp_callback = tf.keras.callbacks.ModelCheckpoint(filepath=checkpoint_save_path,save_weights_only=True,save_best_only=True,monitor='loss') # 由于fit没有给出测试集,不计算测试集准确率,根据loss,保存最优模型history = model.fit(x_train, y_train, batch_size=32, epochs=100, callbacks=[cp_callback])model.summary()3.存储模型,acc和lose可视化曲线和测试交互窗口
# print(model.trainable_variables)
file = open('./weights.txt', 'w') # 参数提取
for v in model.trainable_variables:file.write(str(v.name) + '\n')file.write(str(v.shape) + '\n')file.write(str(v.numpy()) + '\n')
file.close()############################################### show ################################################ 显示训练集和验证集的acc和loss曲线
acc = history.history['sparse_categorical_accuracy']
loss = history.history['loss']plt.subplot(1, 2, 1)
plt.plot(acc, label='Training Accuracy')
plt.title('Training Accuracy')
plt.legend()plt.subplot(1, 2, 2)
plt.plot(loss, label='Training Loss')
plt.title('Training Loss')
plt.legend()
plt.show()############### predict #############preNum = int(input("input the number of test alphabet:"))
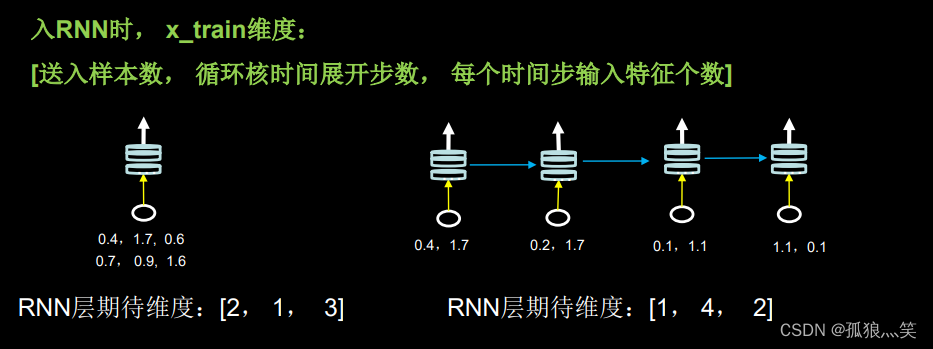
for i in range(preNum):alphabet1 = input("input test alphabet:")alphabet = [id_to_onehot[w_to_id[alphabet1]]]# 使alphabet符合SimpleRNN输入要求:[送入样本数, 循环核时间展开步数, 每个时间步输入特征个数]。此处验证效果送入了1个样本,送入样本数为1;输入1个字母出结果,所以循环核时间展开步数为1; 表示为独热码有5个输入特征,每个时间步输入特征个数为5alphabet = np.reshape(alphabet, (1, 1, 5))result = model.predict([alphabet])pred = tf.argmax(result, axis=1)pred = int(pred)tf.print(alphabet1 + '->' + input_word[pred])五、Embedding编码
目的:每次时间预测都要进行编码,而且编码很麻烦,并且如果简单的话站的内存就比较多,所以就引入Embedding
独热码:数据量大 过于稀疏,映射之间是独立的,没有表现出关联性
Embedding:是一种单词编码方法,用低维向量实现了编码, 这种编码通过神经网络训练优化,能表达出单词间的相关性。
tf.keras.layers.Embedding(词汇表大小,编码维度)
Embedding改进上述案例
# Sequential有变化
model = tf.keras.Sequential([Embedding(5, 2),SimpleRNN(3),Dense(5, activation='softmax')
])# 输入有变化alphabet = [w_to_id[alphabet1]]# 使alphabet符合Embedding输入要求:[送入样本数, 循环核时间展开步数]。# 此处验证效果送入了1个样本,送入样本数为1;输入1个字母出结果,循环核时间展开步数为1。alphabet = np.reshape(alphabet, (1, 1))六、LSTM
1.循环时间核计算过程
2.TF描述LSTM层
tf.keras.layers.LSTM(记忆体个数,return_sequences=是否返回输出) return_sequences=True 各时间步输出ht return_sequences=False 仅最后时间步输出ht(默认
3.代码
model = tf.keras.Sequential([LSTM(80, return_sequences=True),Dropout(0.2),LSTM(100),Dropout(0.2),Dense(1)
])七、GRU
1.循环时间核计算过程

2.TF描述GRU层
tf.keras.layers.GRU(记忆体个数,return_sequences=是否返回输出) return_sequences=True 各时间步输出ht return_sequences=False 仅最后时间步输出ht(默认
3.代码
model = tf.keras.Sequential([GRU(80, return_sequences=True),Dropout(0.2),GRU(100),Dropout(0.2),Dense(1)
])总结
- 本文主要借鉴:mooc曹健老师的《人工智能实践:Tensorflow笔记》
- RNN 是最简单的循环神经网络,它的优点是结构简单,易于实现,但是也有缺点,比如梯度消失或爆炸、难以处理长期依赖等。
- LSTM 是一种改进的 RNN,它的优点是能够避免梯度消失和长期依赖问题,学习更长的序列,但是也有缺点,比如参数较多,计算复杂度高。
- GRU 是一种简化的 LSTM,它的优点是参数较少,计算速度快,但是也有缺点,比如表达能力可能不如 LSTM 强 。
- 选择情况:一般来说,LSTM 和 GRU 的表现要优于 RNN
相关文章:
RNN循环神经网络
目录 一、卷积核与循环核 二、循环核 1.循环核引入 2.循环核:循环核按时间步展开。 3.循环计算层:向输出方向生长。 4.TF描述循环计算层 三、TF描述循环计算 四、RNN使用案例 1.数据集准备 2.Sequential中RNN 3.存储模型,acc和lose…...
安防视频监控/视频集中存储/云存储平台EasyCVR无法播放HLS协议该如何解决?
视频云存储/安防监控EasyCVR视频汇聚平台基于云边端智能协同,支持海量视频的轻量化接入与汇聚、转码与处理、全网智能分发、视频集中存储等。音视频流媒体视频平台EasyCVR拓展性强,视频能力丰富,具体可实现视频监控直播、视频轮播、视频录像、…...

Docker技术--Docker的安装
1..Docker的安装方式介绍 Docker官方提供了三种方式可以实现Docker环境的安装。分别为:Script、yum、rpm。在实际的环境中建议使用yum或者是rpm。 2..Docker的yum安装 # 1.下载docker wget https://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo -O /etc/yum.re…...
客户案例|MemFire Cloud助推应急管理业务,打造百万级数据可视化大屏
「导语」 硬石科技,成立于2018年,总部位于武汉,是一家专注于应急管理行业和物联感知预警算法模型的技术核心的物联网产品和解决方案提供商。硬石科技作为一家高新技术企业,持有6项发明专利,拥有100余项各类平台认证和资…...
蒲公英路由器如何设置远程打印?
现如今,打印机已经是企业日常办公中必不可少的设备,无论何时何地,总有需要用到打印的地方,包括资料文件、统计报表等等。 但若人在外地或分公司,有文件急需通过总部的打印机进行打印时,由于不在同一物理网络…...
国产自主可控C++工业软件可视化图形架构源码
关于国产自主代替的问题是当前热点,尤其是工业软件领域。 “一个功能强大的全自主C跨平台图形可视化架构对开发自主可控工业基础软件至关重要!” 作为全球领先的C工业基础图形可视化软件提供商,UCanCode软件有自己的思考,我们认…...

【linux命令讲解大全】022.网络管理工具和命令概述
文章目录 lsattr命令语法选项参数实例 nmcli补充说明语法选项OPTIONSOBJECT 实例 systemctl补充说明任务 旧指令 新指令 实例 开启防火墙22端口 从零学 python lsattr命令 用于查看文件的第二扩展文件系统属性。 语法 lsattr(选项)(参数) 选项 -E:可显示设备属…...

应急响应流程及思路
应急响应流程及思路 一:前言 对于还没有在项目中真正接触、参与过应急响应的同学来说,“应急响应”这四个字见的最多的就是建筑工地上的横幅 —— 人人懂应急,人人会响应。这里的应急响应和我们网络安全中的应急响应有着某种本质的相似&…...

网页自适应
自适应 那就要最好提前商量好 是全局自适应 或者是 局部自适应 一般网站页面纵向滚动条都是无法避免的 都是做横向适配也就是宽度 那就不能写死宽度像素 局部自适应 一般对父元素设置百分比就行 里面的子元素就设置固定像素、 比如一些登录 全局自适应 也就是要对每个元素…...

什么是Sui Kiosk,它可以做什么,如何赋能创作者?
创作者和IP持有者需要一些工具帮助他们在区块链上实现其商业模式。Sui Kiosk作为Sui上的一种原语可以满足这种需求,为创作者提供动态选项,使他们能够在任何交易场景中设置完成交易的条件。 本文将向您介绍为什么要在SuiFrens中使用Sui Kiosk,…...

【MySQL】mysql connect
目录 一、准备工作 1、创建mysql用户 2、删除用户 3、修改用户密码 3.1、自己改自己密码 3.2、root用户修改指定用户的密码 4、数据库的权限 4.1、给用户授权 4.2、回收权限 二、连接mysql client 1、安装mysql客户端库 2、验证是否引入成功 三、 mysql接口 1、初…...
基于 vue2 发布 npm包
背景:组件化开发需要,走了一遍发布npm包的过程,采用很简单的模式实现包的发布流程,记录如下。 项目参考:基于vue的时间播放器组件,并发布到npm_timeplay.js_xmy_wh的博客-CSDN博客 1、项目初始化 首先&a…...

基于Axios完成前后端分离项目数据交互
一、安装Axios npm i axios -S 封装一个请求工具:request.js import axios from axios// 创建可一个新的axios对象 const request axios.create({baseURL: http://localhost:9090, // 后端的接口地址 ip:porttimeout: 30000 })// request 拦截器 // 可以自请求…...

时序预测 | MATLAB实现基于PSO-BiLSTM、BiLSTM时间序列预测对比
时序预测 | MATLAB实现基于PSO-BiLSTM、BiLSTM时间序列预测对比 目录 时序预测 | MATLAB实现基于PSO-BiLSTM、BiLSTM时间序列预测对比效果一览基本描述程序设计参考资料 效果一览 基本描述 MATLAB实现基于PSO-BiLSTM、BiLSTM时间序列预测对比。 1.Matlab实现PSO-BiLSTM和BiLSTM…...
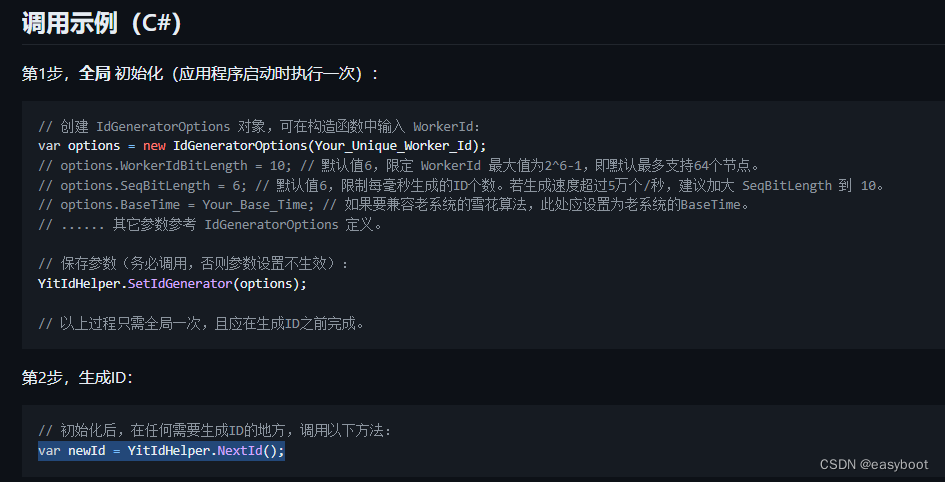
C# 生成唯一ID
1.首先通过nuget安装yitter.idgenerator 下面的三行代码搞定...

python怎么提取视频中的音频
目录 操作步骤 1. 安装MoviePy库: 2. 导入MoviePy库和所需的模块: 3. 提取音频: 可能遇到的问题 1. 编解码器支持: 2. 依赖项安装: 3. 文件路径问题: 4. 内存消耗: 5. 输出文件大小&a…...

学习设计模式之建造者模式,但是宝可梦
前言 作者在准备秋招中,学习设计模式,做点小笔记,用宝可梦为场景举例,有错误欢迎指出。 建造者模式 建造者模式是一种创建型模式,主要针对于某一个类有特别繁杂的属性,并且这些属性中有部分不是必须的。…...

数学建模:变异系数法
🔆 文章首发于我的个人博客:欢迎大佬们来逛逛 变异系数法 变异系数法的设计原理是: 若某项指标的数值差异较大,能明确区分开各被评价对象,说明该指标的分辨信息丰富,因而应给该指标以较大的权重…...
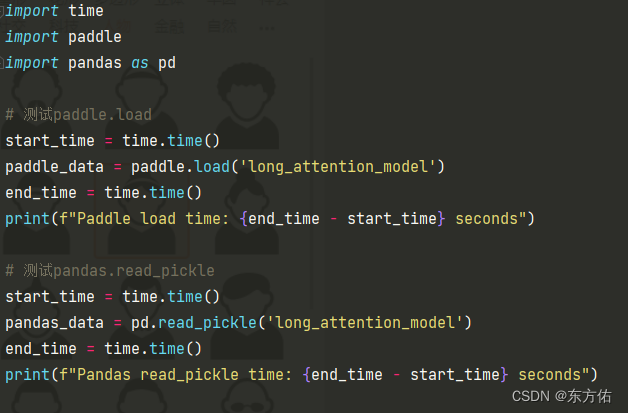
paddle.load与pandas.read_pickle的速度对比(分别在有gpu 何无gpu 对比)
有GPU 平台 测试通用代码 import time import paddle import pandas as pd# 测试paddle.load start_time time.time() paddle_data paddle.load(long_attention_model) end_time time.time() print(f"Paddle load time: {end_time - start_time} seconds")# 测试…...
探讨uniapp的路由与页面栈及参数传递问题
1首先引入页面栈 框架以栈的形式管理当前所有页面, 当发生路由切换的时候,页面栈的表现如下: 页面的路由操作无非:初始化、打开新页面、页面重定向、页面返回、tab切换、重加载。 2页面路由 uni-app 有两种页面路由跳转方式&am…...
)
别再到处找汉化包了!PowerDesigner 15.1 保姆级安装与汉化教程(附资源)
PowerDesigner 15.1 完整安装与汉化实战指南 对于数据库设计领域的初学者和专业开发者来说,PowerDesigner无疑是一款功能强大的建模工具。然而,英文界面常常成为非英语母语用户的第一道门槛。本文将提供一份从零开始的完整解决方案,涵盖软件安…...

观察不同模型在Taotoken平台上的实际响应速度与效果差异
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 观察不同模型在Taotoken平台上的实际响应速度与效果差异 在开发与创作过程中,我们常常需要调用大模型API来完成文本生成…...

【Perplexity商业搜索避坑白皮书】:5类典型误搜场景、4种权威信源验证法,附Gartner认证验证清单
更多请点击: https://kaifayun.com 第一章:【Perplexity商业搜索避坑白皮书】:5类典型误搜场景、4种权威信源验证法,附Gartner认证验证清单 高频误搜场景识别 在企业级商业情报检索中,以下五类误搜行为显著降低决策可…...

经典的网格寻路问题实例分析
经典的网格寻路问题消除墙砖 这一设置会导致地形发生变化,增加问题处理的难度。让我们先去掉这一要求,这样题目就简化成了经典的 网格寻路问题:给你一个 的网格,其中每个单元格不是 (空)就是 (障…...

pdf2pptx:打破学术演示壁垒的智能转换神器
pdf2pptx:打破学术演示壁垒的智能转换神器 【免费下载链接】pdf2pptx Convert your (Beamer) PDF slides to (Powerpoint) PPTX 项目地址: https://gitcode.com/gh_mirrors/pd/pdf2pptx 你是否曾因LaTeX Beamer制作的精美数学公式幻灯片无法在PowerPoint中完…...

5步快速上手OmenSuperHub:彻底掌控暗影精灵性能的终极指南
5步快速上手OmenSuperHub:彻底掌控暗影精灵性能的终极指南 【免费下载链接】OmenSuperHub 使用 WMI BIOS控制性能和风扇速度,自动解除DB功耗限制。 项目地址: https://gitcode.com/gh_mirrors/om/OmenSuperHub 你是否对官方Omen Gaming Hub的臃肿…...

利用Taotoken的Token Plan套餐,为创业项目实现精准成本控制
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 利用Taotoken的Token Plan套餐,为创业项目实现精准成本控制 对于创业团队和独立开发者而言,在项目初期&…...

Slide离线阅读功能详解:随时随地浏览Reddit内容的完整教程
Slide离线阅读功能详解:随时随地浏览Reddit内容的完整教程 【免费下载链接】Slide Slide is an open-source, ad-free Reddit browser for Android. 项目地址: https://gitcode.com/gh_mirrors/sl/Slide 你是否经常在地铁、飞机或网络信号不佳的地方想要浏览…...

Windows 11 LTSC微软商店安装终极指南:5分钟快速解决方案
Windows 11 LTSC微软商店安装终极指南:5分钟快速解决方案 【免费下载链接】LTSC-Add-MicrosoftStore Add Windows Store to Windows 11 24H2 LTSC 项目地址: https://gitcode.com/gh_mirrors/ltscad/LTSC-Add-MicrosoftStore Windows 11 LTSC版本以其卓越的稳…...

Keil C编译器字符串常量合并机制与内存优化
1. Keil C编译器中的字符串常量合并机制解析在嵌入式开发中,内存优化是一个永恒的话题。Keil C编译器(包括C51、C166和C251版本)提供了一项智能特性——自动合并重复的字符串常量。这个功能看似简单,但对资源受限的嵌入式系统而言…...