机器学习基础12-Pipeline实现自动化流程处理(基于印第安糖尿病Pima 数据集)
有一些标准的流程可以实现对机器学习问题的自动化处理,在 scikitlearn 中通过Pipeline来定义和自动化运行这些流程。本节就将介绍如何通过Pipeline实现自动化流程处理。
- 如何通过Pipeline来最小化数据缺失。
- 如何构建数据准备和生成模型的Pipeline。
- 如何构建特征选择和生成模型的Pipeline。
机器学习的自动流程
在机器学习方面有一些可以采用的标准化流程,这些标准化流程是从共同的问题中提炼出来的,例如评估框架中的数据缺失等。在 scikit-learn中提供了自动化运行流程的工具——Pipeline。Pipeline 能够将从数据转换到评估模型的整个机器学习流程进行自动化处理。读者可以到scikit-learn的官方网站阅读关于Pipeline的章节,加深对Pipeline的理解。
数据准备和生成模型的Pipeline
在机器学习的实践中有一个很常见的错误,就是训练数据集与评估数据集之间的数据泄露,这会影响到评估的准确度。要想避免这个问题,需要有一个合适的方式把数据分离成训练数据集和评估数据集,这个过程被包含在数据的准备过程中。数据准备过程是很好的理解数据和算法关系的过程,举例来说,当对训练数据集做标准化和正态化处理来训练算法时,就应该理解并接受这同样要受评估数据集的影响。
Pipeline能够处理训练数据集与评估数据集之间的数据泄露问题,通常会在数据处理过程中对分离出的所有数据子集做同样的数据处理,如正态化处理。
下面将演示如何通过Pipeline来处理这个过程,共分为以下两个步
骤:
(1)正态化数据。
(2)训练一个线性判别分析模型。
在使用Pipeline进行流程化算法模型的评估过程中,采用10折交叉验证来分离数据集。
数据集下载
其代码如下:
import pandas as pd
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
from sklearn.linear_model import LogisticRegressionfrom sklearn.model_selection import cross_val_score, ShuffleSplit, KFold
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler#数据预处理
path = 'D:\down\\archive\\diabetes.csv'
data = pd.read_csv(path)#将数据转成数组
array = data.values
#分割数据,去掉最后一个标签
X = array[:, 0:8]Y = array[:, 8]
# 分割数据集
n_splits = 10# 随机数种子
seed = 7kfold = KFold(n_splits=n_splits, random_state=seed, shuffle=True)steps = []
steps.append(('Standardize', StandardScaler()))
steps.append(('lda',LinearDiscriminantAnalysis()))model = Pipeline(steps)result = cross_val_score(model, X, Y, cv=kfold)print("算法评估结果:%.3f (%.3f)" % (result.mean(), result.std()))Pipeline的各个步骤,通过列表参数传递给Pipeline实例,并通过
Pipeline进行流程化处理过程。运行结果:
算法评估结果:0.767 (0.048)
特征选择和生成模型的Pipeline
特征选择也是一个容易受到数据泄露影响的过程。和数据准备一样,特征选择时也必须确保数据的稳固性,Pipeline 也提供了一个工具(FeatureUnion)来保证数据特征选择时数据的稳固性。下面是一个在数据选择过程中保持数据稳固性的例子。
这个过程包括以下四个步骤:
(1)通过主要成分分析进行特征选择。
(2)通过统计选择进行特征选择。
(3)特征集合。
(4)生成一个逻辑回归模型。
在本例中也采用10折交叉验证来分离训练数据集和评估数据集。
代码如下:
import pandas as pd
from sklearn.decomposition import PCA
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
from sklearn.feature_selection import SelectKBest
from sklearn.linear_model import LogisticRegressionfrom sklearn.model_selection import cross_val_score, ShuffleSplit, KFold
from sklearn.pipeline import Pipeline, FeatureUnion
from sklearn.preprocessing import StandardScaler#数据预处理
path = 'D:\down\\archive\\diabetes.csv'
data = pd.read_csv(path)#将数据转成数组
array = data.values
#分割数据,去掉最后一个标签
X = array[:, 0:8]Y = array[:, 8]
# 分割数据集
n_splits = 10# 随机数种子
seed = 7kfold = KFold(n_splits=n_splits, random_state=seed, shuffle=True)features = []
features.append(('PCA', PCA(n_components=3)))
#添加select_best
features.append(('select_best', SelectKBest(k=6)))steps = []
steps.append(('feature_union', FeatureUnion(features)))steps.append(('logistic', LogisticRegression()))model = Pipeline(steps)result = cross_val_score(model, X, Y, cv=kfold)print("算法评估结果:%.3f (%.3f)" % (result.mean(), result.std()))运行结果:
此处先创建了FeatureUnion,然后将其作为Pipeline的一个生成步骤。
算法评估结果:0.771 (0.048)
本节学习了通过 scikit-learn 中的 Pipeline 进行自动流程化数据准备和特征选择的过程。接下来将探讨针对要处理的问题,如何提高机器学习算法的准确度。
相关文章:
)
机器学习基础12-Pipeline实现自动化流程处理(基于印第安糖尿病Pima 数据集)
有一些标准的流程可以实现对机器学习问题的自动化处理,在 scikitlearn 中通过Pipeline来定义和自动化运行这些流程。本节就将介绍如何通过Pipeline实现自动化流程处理。 如何通过Pipeline来最小化数据缺失。如何构建数据准备和生成模型的Pipeline。如何构建特征选择…...
Ansible学习笔记15
1、roles:(难点) roles介绍: roles(角色):就是通过分别将variables,tasks及handlers等放置于单独的目录中,并可以便捷地调用他们的一种机制。 假设我们要写一个playbo…...

圆圈加数字的css
方式一 .circle { width: 50px; height: 50px; border-radius: 50%; background-color: #f00; color: #fff; text-align: center; line-height: 50px; } .circle::before { content: attr(data-number); display: block; } <div class"circle" data-number"…...

YOLOV5/YOLOV7/YOLOV8改进:用于低分辨率图像和小物体的新 CNN 模块SPD-Conv
1.该文章属于YOLOV5/YOLOV7/YOLOV8改进专栏,包含大量的改进方式,主要以2023年的最新文章和2022年的文章提出改进方式。 2.提供更加详细的改进方法,如将注意力机制添加到网络的不同位置,便于做实验,也可以当做论文的创新点。 3.涨点效果:SPD-Conv提升小目标识别,实现有效…...
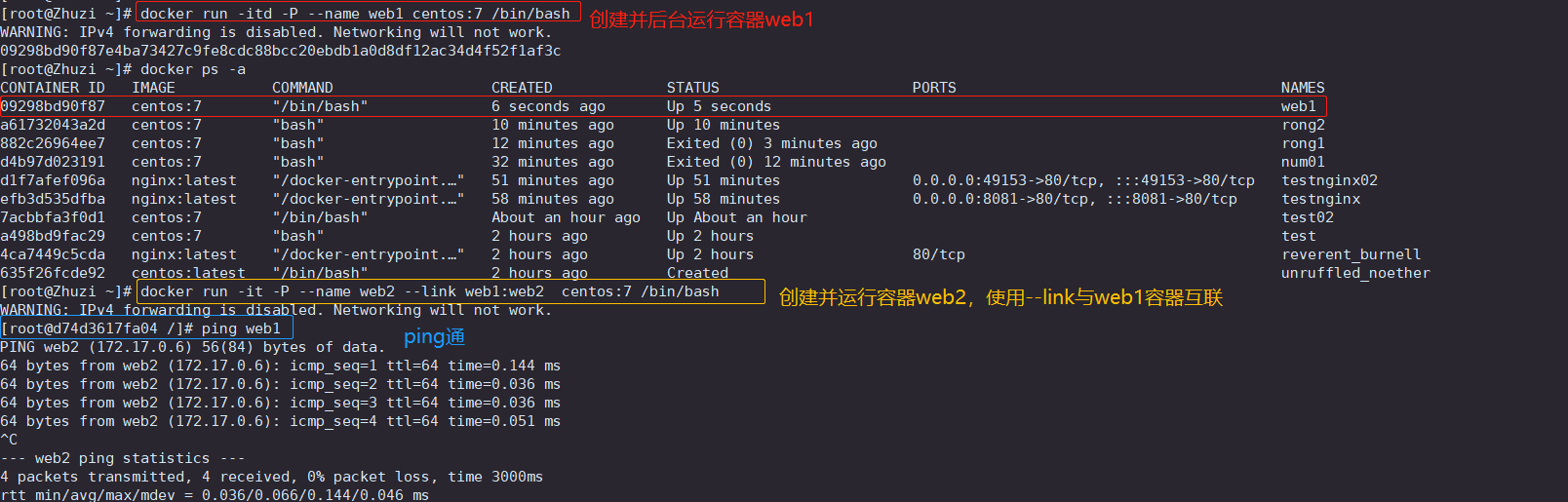
Docker数据管理(数据卷与数据卷容器)
目录 一、数据卷(Data Volumes) 1、概述 2、原理 3、作用 4、示例:宿主机目录 /var/test 挂载同步到容器中的 /data1 二、数据卷容器(DataVolumes Containers) 1、概述 2、作用 3、示例:创建并使用…...

大量TCP连接滞留TIME_WAIT、SYN_SENT、CLOSE_WAIT状态的分析
文章目录 一、统计各类状态的tcp连接数量二、TIME_WAIT应用服务器上,来自反向代理的连接反向代理上,访问应用服务的连接反向代理上,来自用户的连接 三、SYN_SENT反向代理上,访问位于防火墙另一侧的目标反向代理上,访问…...

kotlin怎么定义类
在Kotlin中,你可以使用class关键字来定义一个类。以下是一个简单的例子: class MyClass {// class body} 这个例子定义了一个名为MyClass的类。你可以在类体中定义属性和方法。 如果你想定义一个带有属性的类,你可以这样做: cla…...

如何查看数据集下载后保存的绝对路径?
1.问题 当我们下载torchvision.datasets里面的数据集时,有时候会遇到找不到数据集保存路径的问题。 2.解决 引入os库 import os调用如下方法 os.path.abspath(数据集对象.root)以下面代码为例 import os import torchvision.datasets as datasets# 指定数据集…...
使用php实现微信登录其实并不难,可以简单地分为三步进行
使用php实现微信登录其实并不难,可以简单地分为三步进行。 第一步:用户同意授权,获取code //微信登录public function wxlogin(){$appid "";$secret "";$str"http://***.***.com/getToken";$redirect_uriu…...
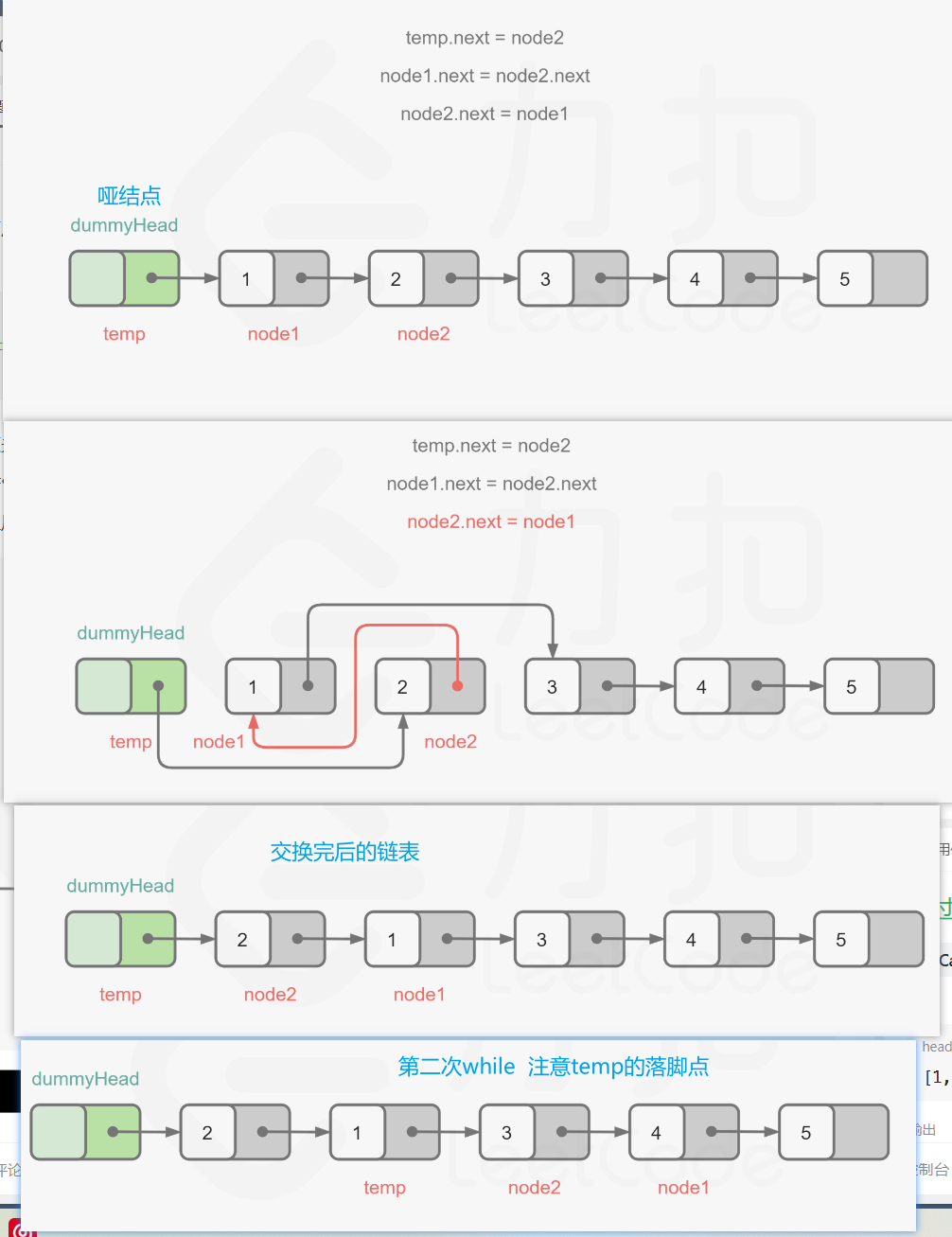
【LeetCode-中等题】24. 两两交换链表中的节点
文章目录 题目方法一:递归方法二:三指针迭代 题目 方法一:递归 图解: 详细版 public ListNode swapPairs(ListNode head) {/*递归法:宗旨就是紧紧抓住原来的函数究竟返回的是什么?作用是什么即可其余的细枝末节不要细究,编译器…...

5.10 汇编语言:汇编过程与结构
过程的实现离不开堆栈的应用,堆栈是一种后进先出(LIFO)的数据结构,最后压入栈的值总是最先被弹出,而新数值在执行压栈时总是被压入到栈的最顶端,栈主要功能是暂时存放数据和地址,通常用来保护断点和现场。 栈是由CPU管…...

【每日一题Day304】LC1267统计参与通信的服务器 | 哈希表
统计参与通信的服务器【LC1267】 这里有一幅服务器分布图,服务器的位置标识在 m * n 的整数矩阵网格 grid 中,1 表示单元格上有服务器,0 表示没有。 如果两台服务器位于同一行或者同一列,我们就认为它们之间可以进行通信。 请你统…...

深度解读零信任身份安全—— 全面身份化:零信任安全的基石
事实上,无论是零信任安全在数据中心的实践,还是通用的零信任安全架构实践,全面身份化都是至关重要的,是“企业边界正在瓦解,基于边界的安全防护体系正在失效”这一大背景下,构筑全新的零信任身份安全架构的…...

音视频 ffmpeg命令提取音视频数据
保留封装格式 ffmpeg -i test.mp4 -acodec copy -vn audio.mp4 ffmpeg -i test.mp4 -vcodec copy -an video.mp4提取视频 保留编码格式:ffmpeg -i test.mp4 -vcodec copy -an test_copy.h264 强制格式:ffmpeg -i test.mp4 -vcodec libx264 -an test.h2…...

vscode 配置
vscode 配置 安装插件 Better C SyntaxC/CCMake、CMake Tools 、CMake Language SupportDoxygen Documentation GeneratorGit Graphhighlight-wordsPythonvscode-iconsClang-Format和clangdtyporahex editor .vscode 中的文件 在 VS Code 中,.vscode 文件夹是用于…...

企业数字化管控平台及信息化治理体系建设方案(附300份方案)
本资料来源公开网络,仅供个人学习,请勿商用,如有侵权请联系删除,更多浏览公众号:智慧方案文库 数字化校园整体解决方案.doc150页6万字数字化智能工厂信息化系统集成整合规划建设方案.docx2022年采购数字化市场研究报告…...

ABB PCD231B通信输入/输出模块
多通道输入和输出: PCD231B 模块通常配备多个输入通道和输出通道,用于连接传感器、执行器和其他设备。 通信接口: 这种模块通常支持各种通信接口,如以太网、串口(RS-232、RS-485)、Profibus、CAN 等&#…...
在springboot项目中显示Services面板的方法
文章目录 前言方法一:Alt8快捷键方法二:使用Component标签总结 前言 在一个springboot项目中,通过开启Services面板,可以快速的启动、配置、管理多个子项目。 方法一:Alt8快捷键 1、在idea界面输入Alt8,在…...

spring之AOP简介
1.AOP简介 什么是AOP Aspect Oriented Program面向切面编程在不改变原有逻辑上增加额外的功能,比如解决系统层面的问题,或者增加新的功能 场景 权限控制缓存日志处理事务控制 AOP思想把功能分两个部分,分离系统中的各种关注点 核心关注点&a…...

ros::init用途用法
文章目录 用途:用法:ros::init 是 ROS(Robot Operating System)中的一个重要函数,它用于初始化 ROS 节点。在启动任何 ROS 节点之前,都必须首先调用这个函数。以下是其用途和基本用法。 用途: 节点初始化:为ROS系统中的节点进行初始化。一个节点是ROS计算图中的一个可…...

claudecode用户如何通过taotoken解决封号与token不足的痛点
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 claudecode用户如何通过taotoken解决封号与token不足的痛点 1. 场景与核心挑战 对于深度使用 Claude Code 编程助手的开发者而言&…...

免费解密网易云音乐NCM格式:ncmdumpGUI完整使用指南
免费解密网易云音乐NCM格式:ncmdumpGUI完整使用指南 【免费下载链接】ncmdumpGUI C#版本网易云音乐ncm文件格式转换,Windows图形界面版本 项目地址: https://gitcode.com/gh_mirrors/nc/ncmdumpGUI 你是否在网易云音乐下载了喜欢的歌曲ÿ…...

终极指南:如何用WinDiskWriter快速制作Windows启动盘并绕过硬件限制
终极指南:如何用WinDiskWriter快速制作Windows启动盘并绕过硬件限制 【免费下载链接】windiskwriter 🖥 Windows Bootable USB creator for macOS. 🛠 Patches Windows 11 to bypass TPM and Secure Boot requirements. 👾 UEFI &…...

AhabAssistantLimbusCompany终极指南:10分钟快速掌握智能自动化技巧
AhabAssistantLimbusCompany终极指南:10分钟快速掌握智能自动化技巧 【免费下载链接】AhabAssistantLimbusCompany AALC,PC端Limbus Company小助手。AALC,Limbus Company Assistant on PC 项目地址: https://gitcode.com/gh_mirrors/ah/Aha…...

PSLab Desktop性能优化:提升仪器响应速度与数据精度的终极指南
PSLab Desktop性能优化:提升仪器响应速度与数据精度的终极指南 【免费下载链接】pslab-desktop PSLab Desktop Application https://pslab.io 项目地址: https://gitcode.com/gh_mirrors/ps/pslab-desktop PSLab Desktop是一款强大的开源硬件实验平台应用程序…...

【独家首发】ElevenLabs未公开的粤语语音增强技巧:3个隐藏prompt指令+2个音频后处理脚本
更多请点击: https://intelliparadigm.com 第一章:ElevenLabs广东话语音合成的技术边界与本地化挑战 ElevenLabs 作为全球领先的语音合成平台,其多语言支持能力广受关注,但粤语(广东话)尚未被官方列为正式…...

3分钟掌握Windows安卓应用安装:APK Installer终极指南
3分钟掌握Windows安卓应用安装:APK Installer终极指南 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 你是否曾想过在Windows电脑上直接运行安卓应用&#…...

Co-IP/MS:蛋白免疫共沉淀质谱分析服务
免疫共沉淀质谱法(Co-IP/MS)是一种由免疫共沉淀技术联用质谱技术的蛋白互作研究技术,具备高分辨率鉴定和精确定量蛋白质复合物中每个组分的优势。Co-IP/MS使用靶向目标蛋白的特异性抗体,选择性地捕获目标蛋白质与其相互作用的分子…...

FLUX.1-dev FP8量化模型:6GB显存也能玩转AI绘画的终极解决方案
FLUX.1-dev FP8量化模型:6GB显存也能玩转AI绘画的终极解决方案 【免费下载链接】flux1-dev 项目地址: https://ai.gitcode.com/hf_mirrors/Comfy-Org/flux1-dev 还在为AI绘画需要昂贵显卡而烦恼吗?FLUX.1-dev FP8量化模型彻底改变了游戏规则&…...
)
Linux驱动开发实战:为I.MX6ULL编写一个DS18B20的字符设备驱动(从设备树到应用测试)
Linux驱动开发实战:I.MX6ULL平台DS18B20字符设备驱动全流程解析 在嵌入式Linux开发领域,能够完整实现一个符合内核规范的设备驱动是工程师的核心能力之一。本文将带您深入探索如何为I.MX6ULL处理器开发DS18B20温度传感器的标准字符设备驱动,…...