Springboot使用kafka事务-生产者方
前言
在上一篇文章中,我们使用了springboot的AOP功能实现了kafka的分布式事务,但是那样实现的kafka事务是不完美的,因为请求进来之后分配的是不同线程,但不同线程使用的kafka事务却是同一个,这样会造成多请求情况下的事务失效。
而解决这个问题的方法,就是每个线程都使用一个新的事务生产者去发送一条新的事务消息,然后这个事务还要和当前线程进行绑定,实现不同线程之间的事务隔离。
通常来说,这个繁杂的过程虽然我们可以实现,但是始终没有框架研发者做的那么完美,所以,我们首先要去看一下框架的作者有没有实现这个功能。
幸运地是,上述功能在kafka之中是有实现的,而且首次实现的时间是在2017年,所以我们可以直接使用作者提供的基于springboot的事务管理功能。
注入kafka事务
在springboot中启用kafka的事务,有两种方式,第一种方式为使用springboot提供的自动配置,第二种是自己往容器中注入。
方式一:springboot自动注入
想要使用自动注入,我们只需要在配置文件中加入transaction-id-prefix即可,配置文件如下:
spring:kafka:producer:bootstrap-servers: localhost:9092#bootstrap-servers: localhost:9010key-serializer: org.apache.kafka.common.serialization.StringSerializervalue-serializer: org.apache.kafka.common.serialization.StringSerializertransaction-id-prefix: test
这样配置之后,就开启了kafka的事务。
方式一弊端
这样虽然可以直接使用springboot自动装配功能,但是却有下面两个弊端
- 只能使用一个kafka的集群地址
- 全局开启了事务,有的方法并不需要全局开启事务
所以一旦有多个kafka的地址需要配置,或者只想让部分方法使用事务,那么就可以使用第二种方法来解决,那就是自己往容器里面添加kafka的事务管理器。
方式二:向spring容器中添加自定义kafka事务管理器
在kafka事务管理器中,有三个重要的对象,分别是ProducerFactory、KafkaTemplate、KafkaTransactionManager,他们的作用如下:
- ProducerFactory,用来创建kafka的生产者对象
- KafkaTemplate,springboot封装的kafka模版
- KafkaTransactionManager,kafka的事务管理器
想要往spring容器中添加自定义的kafka事务管理器,其实就是添加一个自定义的KafkaTransactionManager对象,那么我们只需要想办法构造一个KafkaTransactionManager就好。
利用springboot的配置类,我们能很轻松的做到这一点。
第一步,构造一个配置类KafkaAndDataTransactionConfig,加上@Configuration注解。
@Configuration
public class KafkaAndDataTransactionConfig {
}
第二步,构建一个ProducerFactory对象的Bean,交给spring容器。
@ResourceNacosDiscoveryProperties nacosDiscoveryProperties;/*** 注入一个kafka生产者,这个生产者的transactional.id自定义,避免导致多个生产者的事务id相同* @param props yaml文件中的定义属性*/@BeanProducerFactory<String, String> pf1(KafkaProperties props) {Map<String, Object> pProps = props.buildProducerProperties();pProps.put(ProducerConfig.TRANSACTIONAL_ID_CONFIG, "product-transactional-id-" + nacosDiscoveryProperties.getIp() + "-" + nacosDiscoveryProperties.getPort());pProps.put(ProducerConfig.CLIENT_ID_CONFIG, "product-client-id-" + nacosDiscoveryProperties.getIp() + "-" + nacosDiscoveryProperties.getPort());return new DefaultKafkaProducerFactory<>(pProps);}
注意其中的nacosDiscoveryProperties变量,这是用来获取实例在nacos中的ip地址,因为在多实例的情况下需要保证每一个事务id的唯一,才不会被kafka的事务管理器识别为失效事务生产者,从而导致事务冲突失效。
第三步,创建一个KafkaTransactionManager对象的Bean,添加到spring容器。
/*** 注入一个kafka事务管理器,这个事务管理器使用事务id* @param pf1* @return*/@BeanKafkaTransactionManager<String, String> kafkaTransactionManagerWithTxId(ProducerFactory<String, String> pf1) {return new KafkaTransactionManager<>(pf1);}
只需要将创建好的生产者bean,作为构造参数传入即可。
通过以上三步,我们就得到了一个支持事务的kafka事务管理器了,不过,此时我们还少创建了一个KafkaTemplate,没有这个对象我们将完不成事务发送的管控。
第四步,创建KafkaTemplate
/*** 注入一个使用事务id的kafkaTemplate,这个kafkaTemplate可以使用事务* @param pf1* @return*/@BeanKafkaTemplate<String, String> kafkaTemplateWithTxId(ProducerFactory<String, String> pf1) {return new KafkaTemplate<>(pf1);}
经过以上代码,我们就得到了一个完整的kafka事务管理器了。
全部代码如下:
@Configuration
public class KafkaAndDataTransactionConfig {@ResourceNacosDiscoveryProperties nacosDiscoveryProperties;/*** 注入一个kafka生产者,这个生产者的transactional.id自定义,避免导致多个生产者的事务id相同* @param props yaml文件中的定义属性*/@BeanProducerFactory<String, String> pf1(KafkaProperties props) {Map<String, Object> pProps = props.buildProducerProperties();pProps.put(ProducerConfig.TRANSACTIONAL_ID_CONFIG, "product-transactional-id-" + nacosDiscoveryProperties.getIp() + "-" + nacosDiscoveryProperties.getPort());pProps.put(ProducerConfig.CLIENT_ID_CONFIG, "product-client-id-" + nacosDiscoveryProperties.getIp() + "-" + nacosDiscoveryProperties.getPort());return new DefaultKafkaProducerFactory<>(pProps);/*** 注入一个kafka事务管理器,这个事务管理器使用事务id* @param pf1* @return*/@BeanKafkaTransactionManager<String, String> kafkaTransactionManagerWithTxId(ProducerFactory<String, String> pf1) {return new KafkaTransactionManager<>(pf1);}/*** 注入一个使用事务id的kafkaTemplate,这个kafkaTemplate可以使用事务* @param pf1* @return*/@BeanKafkaTemplate<String, String> kafkaTemplateWithTxId(ProducerFactory<String, String> pf1) {return new KafkaTemplate<>(pf1);}}
增加DataSourceTransaction事务管理器
默认情况,DataSourceTransaction事务管理器springboot会帮我们自动配置,但是在使用了kafka的事务之后,会存在一个类的加载冲突,导致DataSourceTransaction没有被springboot自动加载到,所以我们还需要自己将DataSourceTransaction事务管理加入进来。
在上面的代码中,再加入以下代码
//构造器注入DataSource和transactionManagerCustomizersprivate final DataSource dataSource;private final TransactionManagerCustomizers transactionManagerCustomizers;KafkaAndDataTransactionConfig(DataSource dataSource,ObjectProvider<TransactionManagerCustomizers> transactionManagerCustomizers) {this.dataSource = dataSource;this.transactionManagerCustomizers = transactionManagerCustomizers.getIfAvailable();}/*** @Bean 去掉了ConditionalOnMissingBean 避免注入了kafka事务管理器后,springboot不再注入DataSourceTransactionManager* @Primary 作为主事务管理器,这样在使用@Transactional时,就会使用DataSourceTransactionManager* @param properties* @return*/@Bean@Primarypublic DataSourceTransactionManager dstm(DataSourceProperties properties) {DataSourceTransactionManager transactionManager = new DataSourceTransactionManager(this.dataSource);if (this.transactionManagerCustomizers != null) {this.transactionManagerCustomizers.customize(transactionManager);}return transactionManager;}
增加ChainedKafkaTransactionManager管理器
在实际开发中,有时候一个方法需要既支持kafka的事务,又需要支持JDBC的事务,这个时候为了兼容两者的事务,我们需要将两者的事务放到同一个事务管理器中,让他们两个构成一个事务。kafka的作者为我们提供了ChainedKafkaTransactionManager这个对象,来支持这个操作,只需要加入以下代码即可
//多个事务管理器构成一个事务,使用ChainedKafkaTransactionManager管理,是因为可以自动偏移kafka事务给消费者@Bean public ChainedKafkaTransactionManager kafkaAndDataSourceTransactionManager(DataSourceTransactionManager transactionManager,@Autowired @Qualifier("kafkaTransactionManagerWithTxId") KafkaTransactionManager<?, ?> kafkaTransactionManager){return new ChainedKafkaTransactionManager<>(transactionManager, kafkaTransactionManager);}
以上,就是kafka集成springboot的方案,接下来,看看怎么使用
使用
基于以上的配置,一共有三种使用方式
- 只使用kafka事务
- 只使用JDBC事务
- 同时使用kafka和JDBC事务
针对于上面的三种情况的切换,其实就是使用不同Transactional注解中的value值切换不同的事务管理器,事务的指定都在service层的实现类中。
只使用kafka事务
//指定事务模版为自定义模版@Resource(name = "kafkaTemplateWithTxId")private KafkaTemplate<String, String> kafkaTemplate;@Transactional(rollbackFor = Exception.class,value = "kafkaAndDataSourceTransactionManager")public void transation() {ProducerRecord<String, String> stringStringProducerRecord = new ProducerRecord<>("test-topic", "test");kafkaTemplate.send(stringStringProducerRecord);}
只使用JDBC事务
不需要指定任何的事务管理器
@Override@Transactional(rollbackFor = Exception.class)public void transationOfJdbc() {xxxService.update(user);}
同时使用kafka和JDBC事务
指定自定义的事务管理器
//指定事务模版为自定义模版@Resource(name = "kafkaTemplateWithTxId")private KafkaTemplate<String, String> kafkaTemplate;@Transactional(rollbackFor = Exception.class,value = "kafkaAndDataSourceTransactionManager")public void transationAll() {xxxService.update(user);spreadMonitorService.sendMsg();ProducerRecord<String, String> stringStringProducerRecord = new ProducerRecord<>("test-topic", "test");kafkaTemplate.send(stringStringProducerRecord);}
结语
以上,就是在springboot中生产端实现事务的方法,总结一下,一共分为以下几步
- 增加kafka事务管理器
- 增加JDBC事务管理器
- 增加事务链事务管理器
- 使用三种事务管理器
下一篇,将写springboot中消费端如何配置。
引用资料:
kafka官网
kafka的github
spring-kafka官网
相关文章:

Springboot使用kafka事务-生产者方
前言 在上一篇文章中,我们使用了springboot的AOP功能实现了kafka的分布式事务,但是那样实现的kafka事务是不完美的,因为请求进来之后分配的是不同线程,但不同线程使用的kafka事务却是同一个,这样会造成多请求情况下的…...

您的计算机已被.halo勒索病毒感染?恢复您的数据的方法在这里!
导言: 在当今数字时代,网络安全已经成为了我们生活和工作中不可或缺的一部分。然而, .Halo 勒索病毒的出现,使网络威胁变得更加真切和具体。本文91数据恢复将深入介绍 .Halo 勒索病毒的危害,详细探讨如何高效地恢复被其…...

生成式AI颠覆传统数据库的十种方式
对于生成式AI的所有闪光点,这个新时代最大的转变可能深埋在软件堆栈中。AI算法正在不易觉察地改变一个又一个数据库。他们正在用复杂、自适应且看似更直观的AI新功能颠覆传统数据库。 与此同时,数据库制造商正在改变我们存储信息的方式,以便…...
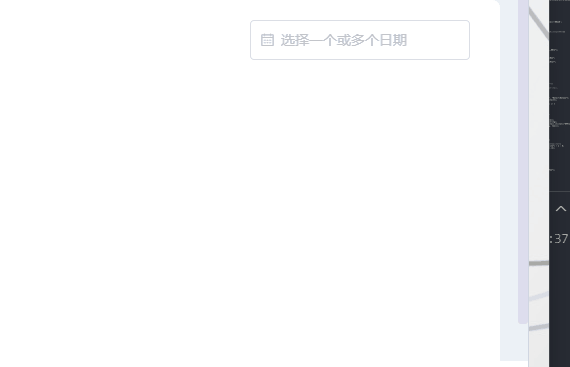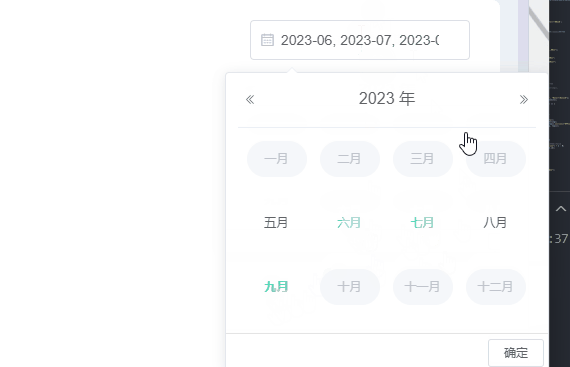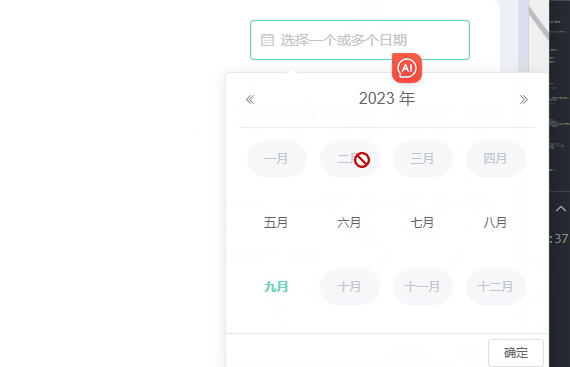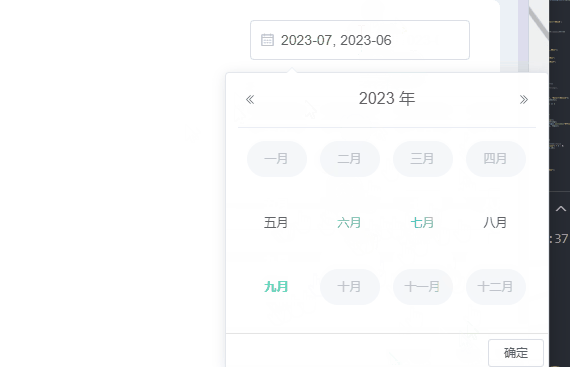
el-date-picker自定义只能选中当前月份和半年内月份等
需求:el-date-picker只能选中当前月期和当前月期往前半年,其他时间就禁用了不让选择了,因为没数据哈哈。当然也可以选择往前一年等。 一、效果 二、写个日期选择器 :picker-options:日期选项 value-format:选择后的格…...
:使用Pyecharts绘制带有滑动数据缩放功能的K线图)
Pyecharts教程(十一):使用Pyecharts绘制带有滑动数据缩放功能的K线图
Pyecharts教程(十一):使用Pyecharts绘制带有滑动数据缩放功能的K线图 作者:安静到无声 个人主页 目录 Pyecharts教程(十一):使用Pyecharts绘制带有滑动数据缩放功能的K线图前言步骤总结推荐专栏前言 K线图是金融市场分析中常见的图表类型之一,它能够直观地展示价格的变化…...

2023年高教社杯数学建模思路 - 案例:ID3-决策树分类算法
文章目录 0 赛题思路1 算法介绍2 FP树表示法3 构建FP树4 实现代码 建模资料 0 赛题思路 (赛题出来以后第一时间在CSDN分享) https://blog.csdn.net/dc_sinor?typeblog 1 算法介绍 FP-Tree算法全称是FrequentPattern Tree算法,就是频繁模…...

POJ 3273 Monthly Expense 二分
我们对每个月花费的最小花费进行二分,对于每一次二分的值mid,计算能花的月份数量,如果月份数量小于等于m,我们就不断的缩小mid,直到找到月份数量小于等于m 与 月份数量大于m的临界值,取最后一次满足条件的m…...
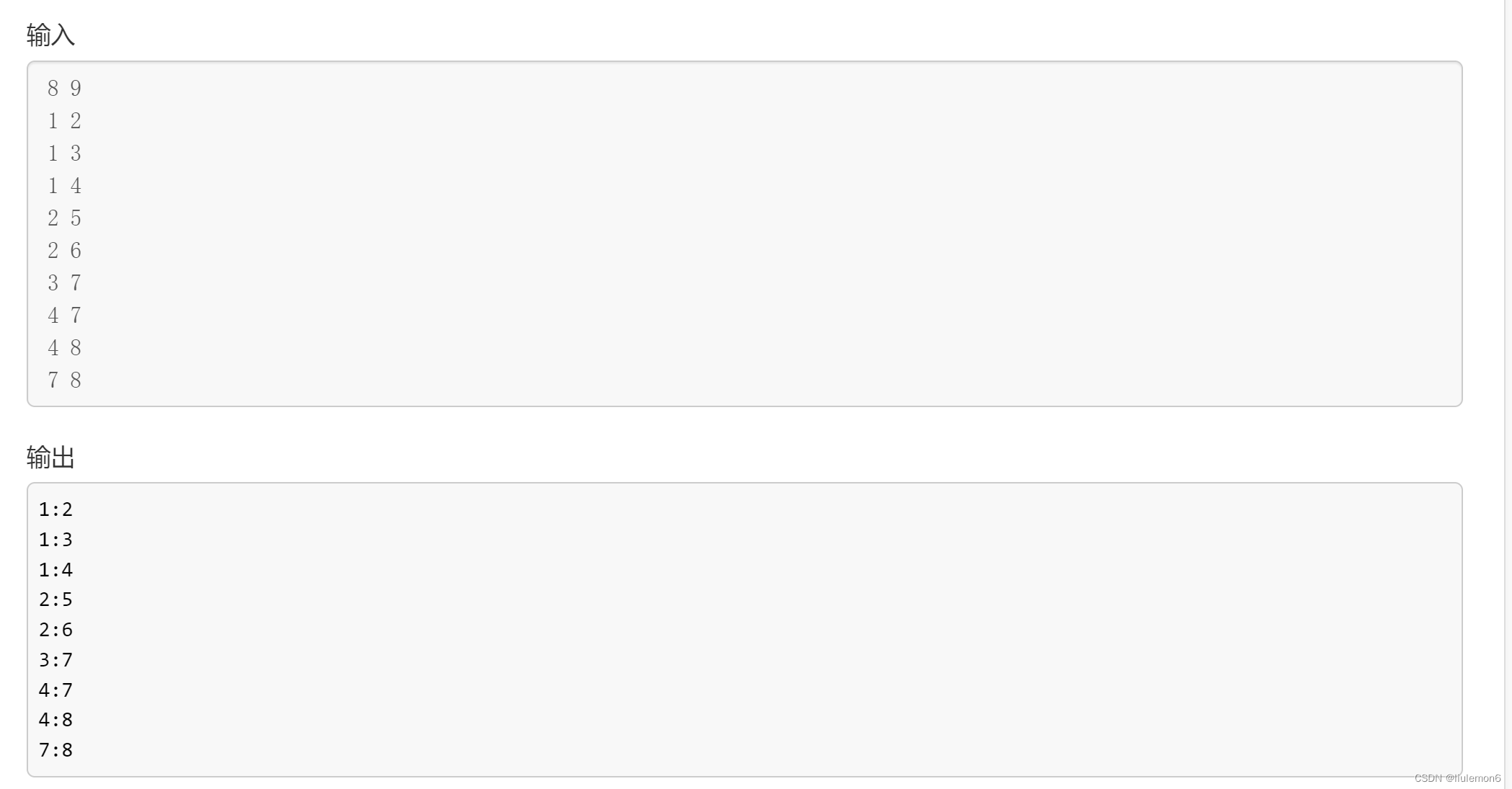
图论(基础)
知识: 顶点,边 | 权,度数 1.图的种类: 有向图 | 无向图 有环 | 无环 联通性 基础1:图的存储(主要是邻接矩阵和邻接表) 例一:B3643 图的存储 - 洛谷 | 计算机科学教育新生态 (…...

docker的运行原理
Docker 是一个开源的容器化技术,它能够让开发者将应用及其依赖打包到一个轻量级的、可移植的容器中,这个容器可以在几乎任何机器上一致地运行。要了解 Docker 的运行原理,我们首先要理解以下几个核心概念: 容器 (Container): 容器是一个轻量级的、独立的、可执行的软件包,…...
vue自定义键盘
<template><div class"mark" click"isOver"></div><div class"mycar"><div class"mycar_list"><div class"mycar_list_con"><p class"mycar_list_p">车牌号</p>…...
k8s 安装 kubernetes安装教程 虚拟机安装k8s centos7安装k8s kuberadmin安装k8s k8s工具安装 k8s安装前配置参数
k8s采用master, node1, node2 。三台虚拟机安装的一主两从,机器已提前安装好docker。下面是机器配置,k8s安装过程,以及出现的问题与解决方法 虚拟机全部采用静态ip, master 30机器, node1 31机器, node2 32机器 机器ip 192.168.164.30 # ma…...
2023年高教社杯数学建模思路 - 案例:感知机原理剖析及实现
文章目录 1 感知机的直观理解2 感知机的数学角度3 代码实现 4 建模资料 # 0 赛题思路 (赛题出来以后第一时间在CSDN分享) https://blog.csdn.net/dc_sinor?typeblog 1 感知机的直观理解 感知机应该属于机器学习算法中最简单的一种算法,其…...
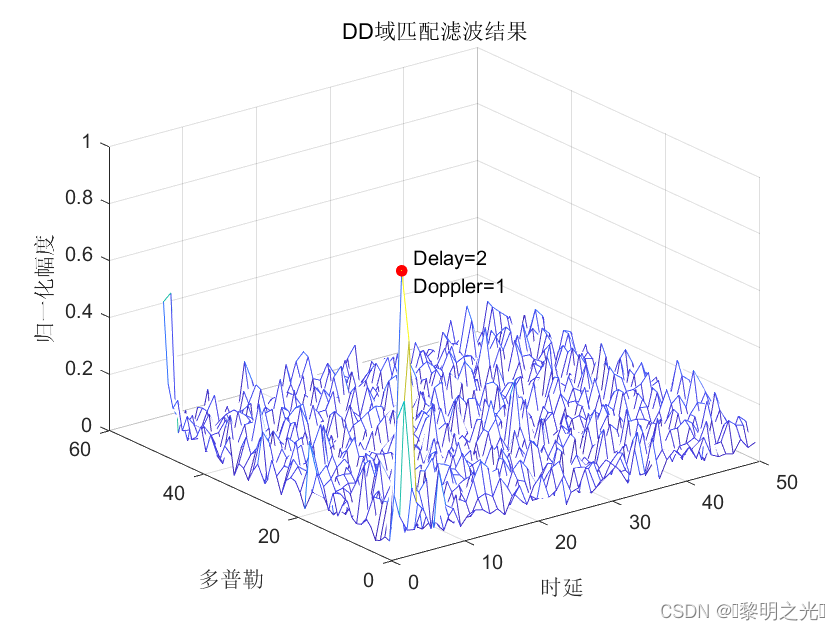
OTFS-ISAC雷达部分最新进展(含matlab仿真+USRP验证)
OTFS基带参数设置 我将使用带宽为80MHz的OTFS波形进行设计,对应参数如下: matlab Tx仿真 Tx导频Tx功率密度谱 帧结构我使用的是经典嵌入导频帧结构,Tx信号波形的带宽从右图可以看出约为80Mhz USRP验证 测试环境 无人机位于1m处 Rx导频Rx…...
Cell | 超深度宏基因组!复原消失的肠道微生物
期刊:Cell IF:64.5 (Q1) 发表时间:2023.6 研究背景 不同的生活方式会影响微生物组组成,但目前微生物组的研究严重偏向于西方工业化人群,其中工业化人群的特点是微生物群多样性较低。为了理解工…...

Centos7 设置代理方法
针对上面变量的设置方法: 1、在/etc/profile文件 2、在~/.bashrc 3、在~/.zshrc 4、在/etc/profile.d/文件夹下新建一个文件xxx.sh 写入如下配置: export proxy"http://192.168.5.14:8118" export http_proxy$proxy export https_proxy$pro…...
)
Android versions (Android 版本)
Android versions (Android 版本) All Android releases https://developer.android.com/about/versions Android 1.0 G1 Android 1.5 Cupcake Android 1.6 Donut Android 2.0 Eclair Android 2.2 Froyo Android 2.3 Gingerbread Android 3.0 Honeycomb Android 4.0 Ic…...
LNMP 平台搭建(四十)
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 目录 前言 搭建LNMP 一、安装Nginx 二、安装Mysql 三、安装PHP 四、部署应用 前言 LNMP平台指的是将Linux、Nginx、MySQL和PHP(或者其他的编程语言,如…...

pcie 6.0/7.0相对pcie 5.0的变化有哪些?
引言 话说,小编在CSDN博客跟客服机器人聊天,突然看到有个搜索热搜“pcie最全科普贴”。小编有点似曾相识呀,我就好奇点击了一下,没想到几年前写的帖子在CSDN又火了一把。 说到这里,顺带给自己打个广告哈~ …...

百度Apollo:自动驾驶技术的未来应用之路
文章目录 前言一、城市交通二、出行体验三、环境保护四、未来前景总结 前言 随着科技的不断进步,自动驾驶技术正逐渐成为现实,颠覆着我们的出行方式。作为中国领先的自动驾驶平台,百度Apollo以其卓越的技术和开放的合作精神,正在…...

C++之std::distance应用实例(一百八十八)
简介: CSDN博客专家,专注Android/Linux系统,分享多mic语音方案、音视频、编解码等技术,与大家一起成长! 优质专栏:Audio工程师进阶系列【原创干货持续更新中……】🚀 人生格言: 人生…...

程序员需求攀升:数字化浪潮下的行业必然
在数字经济深度渗透的今天,软件开发行业正经历着前所未有的扩张期,程序员岗位需求的持续攀升成为行业发展的鲜明特征。作为与开发环节紧密联动的测试从业者,深入理解这一现象背后的逻辑,不仅能帮助我们把握行业趋势,更…...

观察Taotoken账单明细实现精准成本追溯
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 观察Taotoken账单明细实现精准成本追溯 对于使用大模型API的开发者而言,成本控制与优化是项目持续运营的关键。单纯依赖…...

[QA]插件式测试用例生成工具:LLM Test Case Tool 的设计与实现
一句话介绍:QA 在需求分析和测试设计中常用的能力沉淀到浏览器插件里:用户在阅读 PRD 时,可以直接在页面右下角调用 Workee,完成摘要、大纲、疑点、测试点、测试用例、UAT 用例和多页面分析。 1. 背景:为什么还需要这个…...

RT-DETRv2训练自定义数据集的排坑全记录
RT-DETRv2训练自定义数据集的排坑全记录 最近在使用lyuwenyu/RT-DETR的PyTorch版本训练自定义缺陷检测数据集,从启动报错到成功训练,踩了不少典型的“新手坑”,这里把完整的排坑过程和解决方案整理出来,帮大家一次性避坑ÿ…...
)
银河麒麟V10找不到应用商店?手把手教你从源码编译安装录屏神器Capture(附ffmpeg配置避坑)
银河麒麟V10系统下从源码构建专业录屏工具Capture的全流程指南 在国产操作系统银河麒麟V10上,许多用户发现系统默认没有提供应用商店,导致无法直接安装常用的录屏工具。本文将详细介绍如何从源码编译安装功能强大的录屏软件Capture,并解决ARM…...

PeaZip:完全免费的跨平台压缩软件,支持200+格式的终极解决方案
PeaZip:完全免费的跨平台压缩软件,支持200格式的终极解决方案 【免费下载链接】PeaZip Free Zip / Unzip software and Rar file extractor. Cross-platform file and archive manager. Features volume spanning, compression, authenticated encryptio…...

别再死记硬背了!用Wireshark抓包带你搞懂PPPoE的Discovery、Session、Terminate三阶段
用Wireshark透视PPPoE全流程:从Discovery到Session的实战诊断手册 当你面对一台华为路由器,PPPoE拨号配置看似完美却频繁出现认证超时,或是NAT转换后外网访问时断时续,传统的命令行检查往往只能告诉你"哪里出错"&#x…...

ElevenLabs瑞典文语音生成延迟超800ms?独家逆向分析其WebRTC音频缓冲机制,给出3行代码级低延迟注入方案
更多请点击: https://codechina.net 第一章:ElevenLabs瑞典文语音生成延迟超800ms?独家逆向分析其WebRTC音频缓冲机制,给出3行代码级低延迟注入方案 ElevenLabs 在瑞典语(sv-SE)TTS 服务中默认启用高保真音…...

体验Taotoken官方折扣与Token Plan带来的实际费用节省
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 体验Taotoken官方折扣与Token Plan带来的实际费用节省 对于开发者个人或小团队而言,在项目开发或日常工作中使用大模型…...

机器人仿真创新方案:基于ROS的工业级虚拟测试平台
机器人仿真创新方案:基于ROS的工业级虚拟测试平台 【免费下载链接】wpr_simulation 项目地址: https://gitcode.com/gh_mirrors/wp/wpr_simulation 在机器人技术快速发展的今天,硬件成本高昂、测试周期漫长、算法验证困难已成为制约机器人产业发…...