Springboot整合HBase
Springboot整合HBase数据库
1、添加依赖
<!-- Spring Boot HBase 依赖 -->
<dependency><groupId>com.spring4all</groupId><artifactId>spring-boot-starter-hbase</artifactId>
</dependency>
<dependency><groupId>org.springframework.data</groupId><artifactId>spring-data-hadoop-hbase</artifactId><version>2.5.0.RELEASE</version>
</dependency>
<dependency><groupId>org.springframework.data</groupId><artifactId>spring-data-hadoop</artifactId><version>2.5.0.RELEASE</version>
</dependency>
2、添加配置
通过Yaml方式配置
spring:hbase:zookeeper:quorum: hbase1.xxx.org,hbase2.xxx.org,hbase3.xxx.orgproperty:clientPort: 2181data:hbase:quorum: XXXrootDir: XXXnodeParent: XXXzookeeper:znode:parent: /hbase3、添加配置类
@Configuration
public class HBaseConfig {@Beanpublic HBaseService getHbaseService() {//设置临时的hadoop环境变量,之后程序会去这个目录下的\bin目录下找winutils.exe工具,windows连接hadoop时会用到//System.setProperty("hadoop.home.dir", "D:\\Program Files\\Hadoop");//执行此步时,会去resources目录下找相应的配置文件,例如hbase-site.xmlorg.apache.hadoop.conf.Configuration conf = HBaseConfiguration.create();return new HBaseService(conf);}
}
4、工具类的方式实现HBASE操作
@Service
public class HBaseService {private Admin admin = null;private Connection connection = null;public HBaseService(Configuration conf) {connection = ConnectionFactory.createConnection(conf);admin = connection.getAdmin();}//创建表 create <table>, {NAME => <column family>, VERSIONS => <VERSIONS>}public boolean creatTable(String tableName, List<String> columnFamily) {//列族column familyList<ColumnFamilyDescriptor> cfDesc = new ArrayList<>(columnFamily.size());columnFamily.forEach(cf -> {cfDesc.add(ColumnFamilyDescriptorBuilder.newBuilder(Bytes.toBytes(cf)).build());});//表 tableTableDescriptor tableDesc = TableDescriptorBuilder.newBuilder(TableName.valueOf(tableName)).setColumnFamilies(cfDesc).build();if (admin.tableExists(TableName.valueOf(tableName))) {log.debug("table Exists!");} else {admin.createTable(tableDesc);log.debug("create table Success!");}close(admin, null, null);return true;}public List<String> getAllTableNames() {List<String> result = new ArrayList<>();TableName[] tableNames = admin.listTableNames();for (TableName tableName : tableNames) {result.add(tableName.getNameAsString());}close(admin, null, null);return result;}public Map<String, Map<String, String>> getResultScanner(String tableName) {Scan scan = new Scan();return this.queryData(tableName, scan);}private Map<String, Map<String, String>> queryData(String tableName, Scan scan) {// <rowKey,对应的行数据>Map<String, Map<String, String>> result = new HashMap<>();ResultScanner rs = null;//获取表Table table = null;table = getTable(tableName);rs = table.getScanner(scan);for (Result r : rs) {// 每一行数据Map<String, String> columnMap = new HashMap<>();String rowKey = null;// 行键,列族和列限定符一起确定一个单元(Cell)for (Cell cell : r.listCells()) {if (rowKey == null) {rowKey = Bytes.toString(cell.getRowArray(), cell.getRowOffset(), cell.getRowLength());}columnMap.put(//列限定符Bytes.toString(cell.getQualifierArray(), cell.getQualifierOffset(), cell.getQualifierLength()),//列族Bytes.toString(cell.getValueArray(), cell.getValueOffset(), cell.getValueLength()));}if (rowKey != null) {result.put(rowKey, columnMap);}}close(null, rs, table);return result;}public void putData(String tableName, String rowKey, String familyName, String[] columns, String[] values) {Table table = null;table = getTable(tableName);putData(table, rowKey, tableName, familyName, columns, values);close(null, null, table);}private void putData(Table table, String rowKey, String tableName, String familyName, String[] columns, String[] values) {//设置rowkeyPut put = new Put(Bytes.toBytes(rowKey));if (columns != null && values != null && columns.length == values.length) {for (int i = 0; i < columns.length; i++) {if (columns[i] != null && values[i] != null) {put.addColumn(Bytes.toBytes(familyName), Bytes.toBytes(columns[i]), Bytes.toBytes(values[i]));} else {throw new NullPointerException(MessageFormat.format("列名和列数据都不能为空,column:{0},value:{1}", columns[i], values[i]));}}}table.put(put);log.debug("putData add or update data Success,rowKey:" + rowKey);table.close();}private Table getTable(String tableName) throws IOException {return connection.getTable(TableName.valueOf(tableName));}private void close(Admin admin, ResultScanner rs, Table table) {if (admin != null) {try {admin.close();} catch (IOException e) {log.error("关闭Admin失败", e);}if (rs != null) {rs.close();}if (table != null) {rs.close();}if (table != null) {try {table.close();} catch (IOException e) {log.error("关闭Table失败", e);}}}}
}测试类
@RunWith(SpringJUnit4ClassRunner.class)
@SpringBootTest
class HBaseApplicationTests {@Resourceprivate HBaseService hbaseService;//测试创建表@Testpublic void testCreateTable() {hbaseService.creatTable("test_base", Arrays.asList("a", "back"));}//测试加入数据@Testpublic void testPutData() {hbaseService.putData("test_base", "000001", "a", new String[]{"project_id", "varName", "coefs", "pvalues", "tvalues","create_time"}, new String[]{"40866", "mob_3", "0.9416","0.0000", "12.2293", "null"});hbaseService.putData("test_base", "000002", "a", new String[]{"project_id", "varName", "coefs", "pvalues", "tvalues","create_time"}, new String[]{"40866", "idno_prov", "0.9317","0.0000", "9.8679", "null"});hbaseService.putData("test_base", "000003", "a", new String[]{"project_id", "varName", "coefs", "pvalues", "tvalues","create_time"}, new String[]{"40866", "education", "0.8984","0.0000", "25.5649", "null"});}//测试遍历全表@Testpublic void testGetResultScanner() {Map<String, Map<String, String>> result2 = hbaseService.getResultScanner("test_base");System.out.println("-----遍历查询全表内容-----");result2.forEach((k, value) -> {System.out.println(k + "--->" + value);});}
}三、使用spring-data-hadoop-hbase
3、配置类
@Configuration
public class HBaseConfiguration {@Value("${hbase.zookeeper.quorum}")private String zookeeperQuorum;@Value("${hbase.zookeeper.property.clientPort}")private String clientPort;@Value("${zookeeper.znode.parent}")private String znodeParent;@Beanpublic HbaseTemplate hbaseTemplate() {org.apache.hadoop.conf.Configuration conf = new org.apache.hadoop.conf.Configuration();conf.set("hbase.zookeeper.quorum", zookeeperQuorum);conf.set("hbase.zookeeper.property.clientPort", clientPort);conf.set("zookeeper.znode.parent", znodeParent);return new HbaseTemplate(conf);}
}
4、业务类中使用HbaseTemplate
这个是作为工具类
@Service
@Slf4j
public class HBaseService {@Autowiredprivate HbaseTemplate hbaseTemplate;//查询列簇public List<Result> getRowKeyAndColumn(String tableName, String startRowkey, String stopRowkey, String column, String qualifier) {FilterList filterList = new FilterList(FilterList.Operator.MUST_PASS_ALL);if (StringUtils.isNotBlank(column)) {log.debug("{}", column);filterList.addFilter(new FamilyFilter(CompareFilter.CompareOp.EQUAL,new BinaryComparator(Bytes.toBytes(column))));}if (StringUtils.isNotBlank(qualifier)) {log.debug("{}", qualifier);filterList.addFilter(new QualifierFilter(CompareFilter.CompareOp.EQUAL, new BinaryComparator(Bytes.toBytes(qualifier))));}Scan scan = new Scan();if (filterList.getFilters().size() > 0) {scan.setFilter(filterList);}scan.setStartRow(Bytes.toBytes(startRowkey));scan.setStopRow(Bytes.toBytes(stopRowkey));return hbaseTemplate.find(tableName, scan, (rowMapper, rowNum) -> rowMapper);}public List<Result> getListRowkeyData(String tableName, List<String> rowKeys, String familyColumn, String column) {return rowKeys.stream().map(rk -> {if (StringUtils.isNotBlank(familyColumn)) {if (StringUtils.isNotBlank(column)) {return hbaseTemplate.get(tableName, rk, familyColumn, column, (rowMapper, rowNum) -> rowMapper);} else {return hbaseTemplate.get(tableName, rk, familyColumn,(rowMapper, rowNum) -> rowMapper);}}return hbaseTemplate.get(tableName, rk, (rowMapper, rowNum) -> rowMapper);}).collect(Collectors.toList());}
}
四、使用spring-boot-starter-data-hbase
参考:https://blog.csdn.net/cpongo1/article/details/89550486
## 下载spring-boot-starter-hbase代码
git clone https://github.com/SpringForAll/spring-boot-starter-hbase.git
## 安装
cd spring-boot-starter-hbase
mvn clean install
2、添加配置项
- spring.data.hbase.quorum 指定 HBase 的 zk 地址
- spring.data.hbase.rootDir 指定 HBase 在 HDFS 上存储的路径
- spring.data.hbase.nodeParent 指定 ZK 中 HBase 的根 ZNode
3、定义好DTO
@Data
public class City {private Long id;private Integer age;private String cityName;
}
4、创建对应rowMapper
public class CityRowMapper implements RowMapper<City> {private static byte[] COLUMN_FAMILY = "f".getBytes();private static byte[] NAME = "name".getBytes();private static byte[] AGE = "age".getBytes();@Overridepublic City mapRow(Result result, int rowNum) throws Exception {String name = Bytes.toString(result.getValue(COLUMN_FAMILY, NAME));int age = Bytes.toInt(result.getValue(COLUMN_FAMILY, AGE));City dto = new City();dto.setCityName(name);dto.setAge(age);return dto;}
}
5、操作实现增改查
- HbaseTemplate.find 返回 HBase 映射的 City 列表
- HbaseTemplate.get 返回 row 对应的 City 信息
- HbaseTemplate.saveOrUpdates 保存或者更新
如果 HbaseTemplate 操作不满足需求,完全可以使用 hbaseTemplate 的getConnection() 方法,获取连接。进而类似 HbaseTemplate 实现的逻辑,实现更复杂的需求查询等功能
@Service
public class CityServiceImpl implements CityService {@Autowired private HbaseTemplate hbaseTemplate;//查询public List<City> query(String startRow, String stopRow) {Scan scan = new Scan(Bytes.toBytes(startRow), Bytes.toBytes(stopRow));scan.setCaching(5000);List<City> dtos = this.hbaseTemplate.find("people_table", scan, new CityRowMapper());return dtos;}//查询public City query(String row) {City dto = this.hbaseTemplate.get("people_table", row, new CityRowMapper());return dto;}//新增或者更新public void saveOrUpdate() {List<Mutation> saveOrUpdates = new ArrayList<Mutation>();Put put = new Put(Bytes.toBytes("135xxxxxx"));put.addColumn(Bytes.toBytes("people"), Bytes.toBytes("name"), Bytes.toBytes("test"));saveOrUpdates.add(put);this.hbaseTemplate.saveOrUpdates("people_table", saveOrUpdates);}
}
Springboot整合Influxdb
中文文档:https://jasper-zhang1.gitbooks.io/influxdb/content/Introduction/installation.html
注意,项目建立在spring-boot-web基础上
1、添加依赖
<dependency><groupId>org.influxdb</groupId><artifactId>influxdb-java</artifactId><version>2.15</version>
</dependency>
2、添加配置
spring:influx:database: my_sensor1password: adminurl: http://127.0.0.1:6086user: admin
3、编写配置类
@Configuration
public class InfluxdbConfig {@Value("${spring.influx.url}")private String influxDBUrl; @Value("${spring.influx.user}")private String userName; @Value("${spring.influx.password}")private String password; @Value("${spring.influx.database}")private String database; @Bean("influxDB")public InfluxDB influxdb(){ InfluxDB influxDB = InfluxDBFactory.connect(influxDBUrl, userName, password);try {/** * 异步插入:* enableBatch这里第一个是point的个数,第二个是时间,单位毫秒 * point的个数和时间是联合使用的,如果满100条或者60 * 1000毫秒 * 满足任何一个条件就会发送一次写的请求。*/influxDB.setDatabase(database).enableBatch(100,1000 * 60, TimeUnit.MILLISECONDS);} catch (Exception e) { e.printStackTrace();} finally { //设置默认策略influxDB.setRetentionPolicy("sensor_retention"); }//设置日志输出级别influxDB.setLogLevel(InfluxDB.LogLevel.BASIC); return influxDB;}
}
4、InfluxDB原生API实现
@SpringBootTest(classes = {MainApplication.class})
@RunWith(SpringJUnit4ClassRunner.class)
public class InfluxdbDBTest {@Autowiredprivate InfluxDB influxDB;//measurementprivate final String measurement = "sensor";@Value("${spring.influx.database}")private String database;/*** 批量插入第一种方式*/@Testpublic void insert(){List<String> lines = new ArrayList<String>(); Point point = null; for(int i=0;i<50;i++){ point = Point.measurement(measurement).tag("deviceId", "sensor" + i).addField("temp", 3).addField("voltage", 145+i).addField("A1", "4i").addField("A2", "4i").build();lines.add(point.lineProtocol());}//写入influxDB.write(lines);}/*** 批量插入第二种方式*/@Testpublic void batchInsert(){BatchPoints batchPoints = BatchPoints.database(database).consistency(InfluxDB.ConsistencyLevel.ALL).build();//遍历sqlserver获取数据for(int i=0;i<50;i++){//创建单条数据对象——表名Point point = Point.measurement(measurement)//tag属性——只能存储String类型.tag("deviceId", "sensor" + i).addField("temp", 3).addField("voltage", 145+i).addField("A1", "4i").addField("A2", "4i").build();//将单条数据存储到集合中batchPoints.point(point);}//批量插入influxDB.write(batchPoints); }/*** 获取数据*/@Testpublic void datas(@RequestParam Integer page){int pageSize = 10;// InfluxDB支持分页查询,因此可以设置分页查询条件String pageQuery = " LIMIT " + pageSize + " OFFSET " + (page - 1) * pageSize;String queryCondition = ""; //查询条件暂且为空// 此处查询所有内容,如果String queryCmd = "SELECT * FROM "// 查询指定设备下的日志信息// 要指定从 RetentionPolicyName.measurement中查询指定数据,默认的策略可以不加;// + 策略name + "." + measurement+ measurement// 添加查询条件(注意查询条件选择tag值,选择field数值会严重拖慢查询速度)+ queryCondition// 查询结果需要按照时间排序+ " ORDER BY time DESC"// 添加分页查询条件+ pageQuery;QueryResult queryResult = influxDB.query(new Query(queryCmd, database));System.out.println("query result => "+queryResult);}
}
5、采用封装工具类
1、创建实体类
@Data
@Measurement(name = "sensor")
public class Sensor {@Column(name="deviceId",tag=true)private String deviceId;@Column(name="temp")private float temp;@Column(name="voltage")private float voltage;@Column(name="A1")private float A1;@Column(name="A2")private float A2;@Column(name="time")private String time; }
2、创建工具类
@Component
public class InfluxdbUtils {@Autowiredprivate InfluxDB influxDB;@Value("${spring.influx.database}")private String database; /*** 新增单条记录,利用java的反射机制进行新增操作*/@SneakyThrowspublic void insertOne(Object obj){//获取度量Class<?> clasz = obj.getClass();Measurement measurement = clasz.getAnnotation(Measurement.class);//构建Point.Builder builder = Point.measurement(measurement.name());// 获取对象属性Field[] fieldArray = clasz.getDeclaredFields();Column column = null;for(Field field : fieldArray){column = field.getAnnotation(Column.class);//设置属性可操作field.setAccessible(true); if(column.tag()){//tag属性只能存储String类型builder.tag(column.name(), field.get(obj).toString());}else{//设置fieldif(field.get(obj) != null){builder.addField(column.name(), field.get(obj).toString());}}}influxDB.write(builder.build());}/*** 批量新增,方法一*/@SneakyThrowspublic void insertBatchByRecords(List<?> records){List<String> lines = new ArrayList<String>(); records.forEach(record->{Class<?> clasz = record.getClass();//获取度量Measurement measurement = clasz.getAnnotation(Measurement.class);//构建Point.Builder builder = Point.measurement(measurement.name());Field[] fieldArray = clasz.getDeclaredFields();Column column = null;for(Field field : fieldArray){column = field.getAnnotation(Column.class);//设置属性可操作field.setAccessible(true); if(column.tag()){//tag属性只能存储String类型builder.tag(column.name(), field.get(record).toString());}else{//设置fieldif(field.get(record) != null){builder.addField(column.name(), field.get(record).toString());}}}lines.add(builder.build().lineProtocol());});influxDB.write(lines);}/*** 批量新增,方法二*/@SneakyThrowspublic void insertBatchByPoints(List<?> records){BatchPoints batchPoints = BatchPoints.database(database).consistency(InfluxDB.ConsistencyLevel.ALL).build();records.forEach(record->{Class<?> clasz = record.getClass();//获取度量Measurement measurement = clasz.getAnnotation(Measurement.class);//构建Point.Builder builder = Point.measurement(measurement.name());Field[] fieldArray = clasz.getDeclaredFields();Column column = null;for(Field field : fieldArray){column = field.getAnnotation(Column.class);//设置属性可操作field.setAccessible(true); if(column.tag()){//tag属性只能存储String类型builder.tag(column.name(), field.get(record).toString());}else{//设置fieldif(field.get(record) != null){builder.addField(column.name(), field.get(record).toString());}}}batchPoints.point(builder.build());});influxDB.write(batchPoints);}/*** 查询,返回Map集合* @param query 完整的查询语句*/public List<Object> fetchRecords(String query){List<Object> results = new ArrayList<Object>();QueryResult queryResult = influxDB.query(new Query(query, database));queryResult.getResults().forEach(result->{result.getSeries().forEach(serial->{List<String> columns = serial.getColumns();int fieldSize = columns.size();serial.getValues().forEach(value->{ Map<String,Object> obj = new HashMap<String,Object>();for(int i=0;i<fieldSize;i++){ obj.put(columns.get(i), value.get(i));}results.add(obj);});});});return results;}/*** 查询,返回map集合* @param fieldKeys 查询的字段,不可为空;不可为单独的tag* @param measurement 度量,不可为空;*/public List<Object> fetchRecords(String fieldKeys, String measurement){StringBuilder query = new StringBuilder();query.append("select ").append(fieldKeys).append(" from ").append(measurement); return this.fetchRecords(query.toString());}/*** 查询,返回map集合* @param fieldKeys 查询的字段,不可为空;不可为单独的tag* @param measurement 度量,不可为空;*/public List<Object> fetchRecords(String fieldKeys, String measurement, String order){StringBuilder query = new StringBuilder();query.append("select ").append(fieldKeys).append(" from ").append(measurement);query.append(" order by ").append(order); return this.fetchRecords(query.toString());}/*** 查询,返回map集合* @param fieldKeys 查询的字段,不可为空;不可为单独的tag* @param measurement 度量,不可为空;*/public List<Object> fetchRecords(String fieldKeys, String measurement, String order, String limit){StringBuilder query = new StringBuilder();query.append("select ").append(fieldKeys).append(" from ").append(measurement);query.append(" order by ").append(order);query.append(limit);return this.fetchRecords(query.toString());}/*** 查询,返回对象的list集合*/@SneakyThrowspublic <T> List<T> fetchResults(String query, Class<?> clasz){List results = new ArrayList<>();QueryResult queryResult = influxDB.query(new Query(query, database));queryResult.getResults().forEach(result->{result.getSeries().forEach(serial->{List<String> columns = serial.getColumns();int fieldSize = columns.size(); serial.getValues().forEach(value->{ Object obj = null;obj = clasz.newInstance();for(int i=0;i<fieldSize;i++){ String fieldName = columns.get(i);Field field = clasz.getDeclaredField(fieldName);field.setAccessible(true);Class<?> type = field.getType();if(type == float.class){field.set(obj, Float.valueOf(value.get(i).toString()));}else{field.set(obj, value.get(i));} }results.add(obj);});});});return results;}/*** 查询,返回对象的list集合*/public <T> List<T> fetchResults(String fieldKeys, String measurement, Class<?> clasz){StringBuilder query = new StringBuilder();query.append("select ").append(fieldKeys).append(" from ").append(measurement); return this.fetchResults(query.toString(), clasz);}/*** 查询,返回对象的list集合*/public <T> List<T> fetchResults(String fieldKeys, String measurement, String order, Class<?> clasz){StringBuilder query = new StringBuilder();query.append("select ").append(fieldKeys).append(" from ").append(measurement);query.append(" order by ").append(order);return this.fetchResults(query.toString(), clasz);}/*** 查询,返回对象的list集合*/public <T> List<T> fetchResults(String fieldKeys, String measurement, String order, String limit, Class<?> clasz){StringBuilder query = new StringBuilder();query.append("select ").append(fieldKeys).append(" from ").append(measurement);query.append(" order by ").append(order);query.append(limit); return this.fetchResults(query.toString(), clasz);}
}
3、使用工具类的测试代码
@SpringBootTest(classes = {MainApplication.class})
@RunWith(SpringJUnit4ClassRunner.class)
public class InfluxdbUtilTest {@Autowiredprivate InfluxdbUtils influxdbUtils;/*** 插入单条记录*/@Testpublic void insert(){Sensor sensor = new Sensor();sensor.setA1(10);sensor.setA2(10);sensor.setDeviceId("0002");sensor.setTemp(10L);sensor.setTime("2021-01-19");sensor.setVoltage(10);influxdbUtils.insertOne(sensor);}/*** 批量插入第一种方式*/@GetMapping("/index22")public void batchInsert(){ List<Sensor> sensorList = new ArrayList<Sensor>();for(int i=0; i<50; i++){Sensor sensor = new Sensor();sensor.setA1(2);sensor.setA2(12);sensor.setTemp(9);sensor.setVoltage(12);sensor.setDeviceId("sensor4545-"+i);sensorList.add(sensor);}influxdbUtils.insertBatchByRecords(sensorList);}/*** 批量插入第二种方式*/@GetMapping("/index23")public void batchInsert1(){ List<Sensor> sensorList = new ArrayList<Sensor>();Sensor sensor = null;for(int i=0; i<50; i++){sensor = new Sensor();sensor.setA1(2);sensor.setA2(12);sensor.setTemp(9);sensor.setVoltage(12);sensor.setDeviceId("sensor4545-"+i);sensorList.add(sensor);}influxdbUtils.insertBatchByPoints(sensorList);}/*** 查询数据*/@GetMapping("/datas2")public void datas(@RequestParam Integer page){int pageSize = 10;// InfluxDB支持分页查询,因此可以设置分页查询条件String pageQuery = " LIMIT " + pageSize + " OFFSET " + (page - 1) * pageSize;String queryCondition = ""; //查询条件暂且为空// 此处查询所有内容,如果String queryCmd = "SELECT * FROM sensor"// 查询指定设备下的日志信息// 要指定从 RetentionPolicyName.measurement中查询指定数据,默认的策略可以不加;// + 策略name + "." + measurement// 添加查询条件(注意查询条件选择tag值,选择field数值会严重拖慢查询速度)+ queryCondition// 查询结果需要按照时间排序+ " ORDER BY time DESC"// 添加分页查询条件+ pageQuery;List<Object> sensorList = influxdbUtils.fetchRecords(queryCmd);System.out.println("query result => {}"+sensorList );}/*** 获取数据*/@GetMapping("/datas21")public void datas1(@RequestParam Integer page){int pageSize = 10;// InfluxDB支持分页查询,因此可以设置分页查询条件String pageQuery = " LIMIT " + pageSize + " OFFSET " + (page - 1) * pageSize;String queryCondition = ""; //查询条件暂且为空// 此处查询所有内容,如果String queryCmd = "SELECT * FROM sensor"// 查询指定设备下的日志信息// 要指定从 RetentionPolicyName.measurement中查询指定数据,默认的策略可以不加;// + 策略name + "." + measurement// 添加查询条件(注意查询条件选择tag值,选择field数值会严重拖慢查询速度)+ queryCondition// 查询结果需要按照时间排序+ " ORDER BY time DESC"// 添加分页查询条件+ pageQuery;List<Sensor> sensorList = influxdbUtils.fetchResults(queryCmd, Sensor.class);//List<Sensor> sensorList = influxdbUtils.fetchResults("*", "sensor", Sensor.class);sensorList.forEach(sensor->{System.out.println("query result => {}"+sensorList );}); }
}
6、采用封装数据模型的方式
1、在Influxdb库中创建存储策略
CREATE RETENTION POLICY "rp_order_payment" ON "db_order" DURATION 30d REPLICATION 1 DEFAULT
2、创建数据模型
@Data
@Measurement(name = "m_order_payment",database = "db_order", retentionPolicy = "rp_order_payment")
public class OrderPayment implements Serializable {// 统计批次@Column(name = "batch_id", tag = true)private String batchId;// 哪个BU@Column(name = "bu_id", tag = true)private String buId;// BU 名称@Column(name = "bu_name")private String buName;// 总数@Column(name = "total_count", tag = true)private String totalCount;// 支付量@Column(name = "pay_count", tag = true)private String payCount;// 金额@Column(name = "total_money", tag = true)private String totalMoney;
}
3、创建Mapper
public class InfluxMapper extends InfluxDBMapper {public InfluxMapper(InfluxDB influxDB) {super(influxDB);}
}
4、配置Mapper
@Log4j2
@Configuration
public class InfluxAutoConfiguration {@Beanpublic InfluxMapper influxMapper(InfluxDB influxDB) {InfluxMapper influxMapper = new InfluxMapper(influxDB);return influxMapper;}
}
5、测试CRUD
@SpringBootTest(classes = {MainApplication.class})
@RunWith(SpringJUnit4ClassRunner.class)
public class InfluxdbMapperTest {@Autowiredprivate InfluxMapper influxMapper;@Testpublic void save(OrderPayment product) {influxMapper.save(product);}@Testpublic void queryAll() {List<OrderPayment> products = influxMapper.query(OrderPayment.class);System.out.println(products);}@Testpublic void queryByBu(String bu) {String sql = String.format("%s'%s'", "select * from m_order_payment where bu_id = ", bu);Query query = new Query(sql, "db_order");List<OrderPayment> products = influxMapper.query(query, OrderPayment.class);System.out.println(products);}
}
参考:https://blog.csdn.net/cpongo1/article/details/89550486
https://github.com/SpringForAll/spring-boot-starter-hbase
https://github.com/JeffLi1993/springboot-learning-example
相关文章:

Springboot整合HBase
Springboot整合HBase数据库 1、添加依赖 <!-- Spring Boot HBase 依赖 --> <dependency><groupId>com.spring4all</groupId><artifactId>spring-boot-starter-hbase</artifactId> </dependency> <dependency><groupId>…...
)
在不同操作系统上如何安装符号表提取工具(eu-strip)
前言 C开发的小伙伴都知道符号表在调试和解决崩溃时扮演着非常重要的角色,那么如何提取和保存发布应用程序的符号表就变得非常重要。今天就来聊一下如何在不同的操作系统上使用eu-strip提取应用程序中的符号表信息。 正文 问题 如何在不同操作系统上安装符号表提…...
钡铼R40边缘计算网关与华为云合作,促进物联网传感器数据共享与应用
场景说明 微型气象是不可预测的,基本上不能通过人工手段来分析其变化,因此必须运用新技术,对气象进行实时监测,以便采取相应的措施来避免或解决事故的发生。而常规气象环境数据采集容易造成数据损失、人力成本高、数据安全性差、…...
图表背后的故事:数据可视化的威力与影响
数据可视化现在在市场上重不重要?这已经不再是一个简单的问题,而是一个不可忽视的现实。随着信息时代的来临,数据已经成为企业和组织的核心资产,而数据可视化则成为释放数据价值的重要工具。 在当今竞争激烈的商业环境中…...

C++ 信号处理
信号是由操作系统传给进程的中断,会提早终止一个程序。在 UNIX、LINUX、Mac OS X 或 Windows 系统上,可以通过按 CtrlC 产生中断。 有些信号不能被程序捕获,但是下表所列信号可以在程序中捕获,并可以基于信号采取适当的动作。这些…...
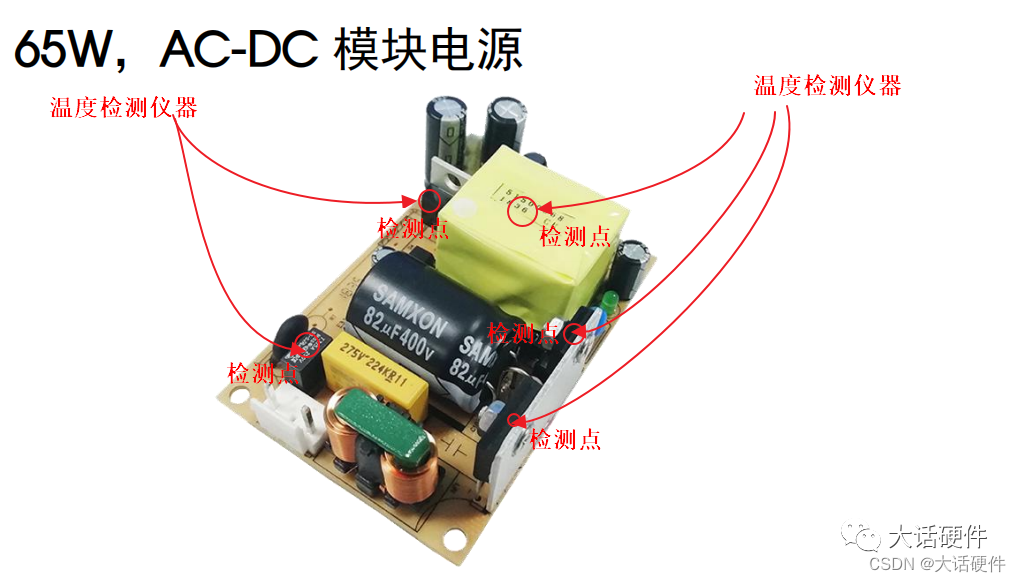
电源模块的降额曲线
大家好,这里是大话硬件。 今天想写这篇文章来分享在前段时间了解的一个知识点——电源模块的降额曲线。 为什么要写这个呢?对于专门做电源的同学来说,肯定觉得很简单。但是对于一个非电源行业的人来说,曲线应该如何解读ÿ…...

uni-app 之 安装uView,安装scss/sass编译
uni-app 之 安装uView,安装scss/sass编译 image.png image.png image.png 点击HBuilder X 顶部,工具,插件安装,安装新插件 image.png image.png 安装成功! 注意,一定要先登录才可以安装 image.png 1. 引…...

CSS中如何隐藏元素但保留其占位空间(display:nonevsvisibility:hidden)?
聚沙成塔每天进步一点点 ⭐ 专栏简介⭐ 隐藏元素但保留占位空间⭐ display: none;⭐ visibility: hidden;⭐ 总结⭐ 写在最后 ⭐ 专栏简介 前端入门之旅:探索Web开发的奇妙世界 记得点击上方或者右侧链接订阅本专栏哦 几何带你启航前端之旅 欢迎来到前端入门之旅&a…...
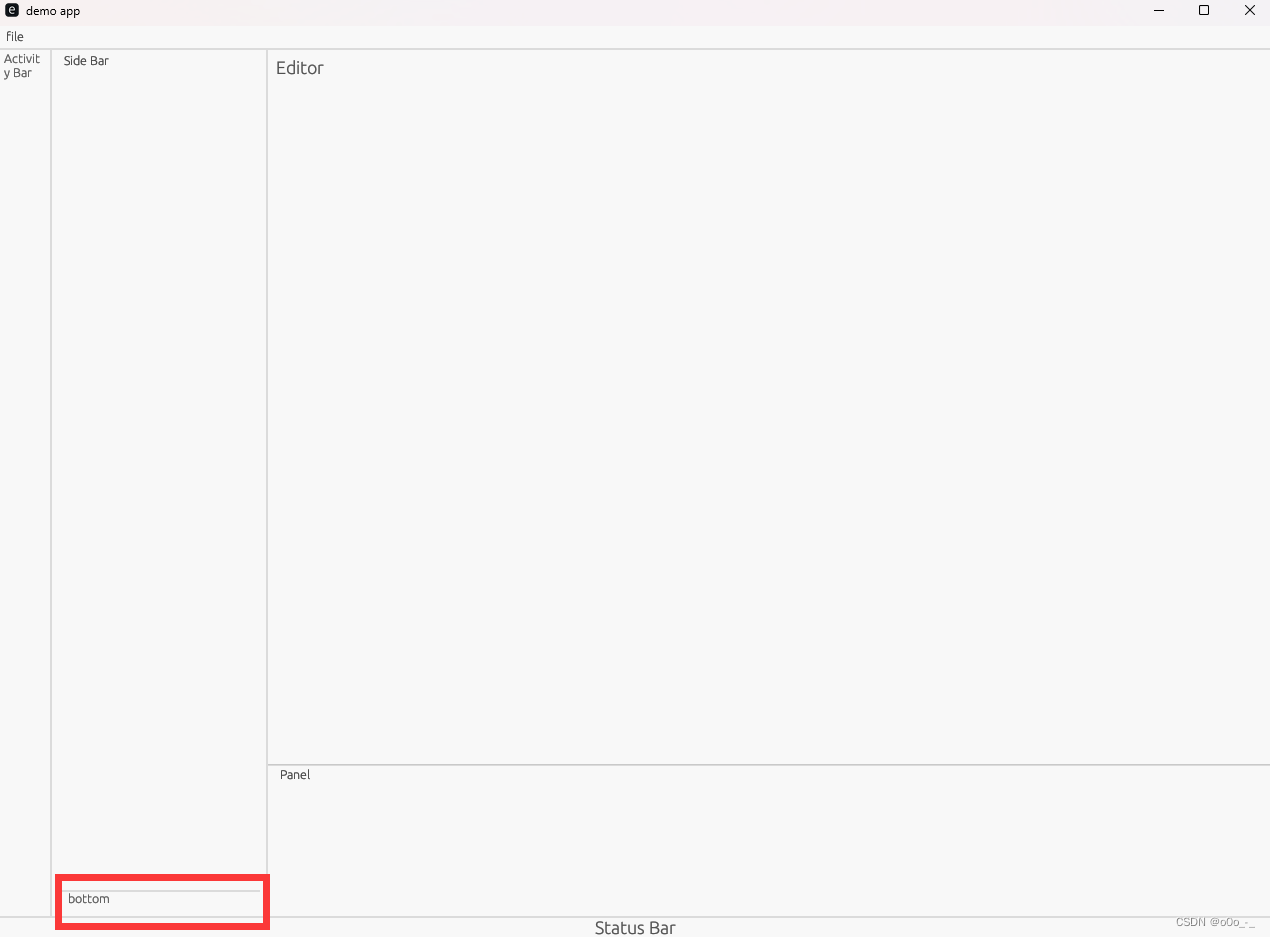
【rust/egui】(八)使用panels给你的应用划分功能区块
说在前面 rust新手,egui没啥找到啥教程,这里自己记录下学习过程环境:windows11 22H2rust版本:rustc 1.71.1egui版本:0.22.0eframe版本:0.22.0上一篇:这里 panel是啥 panel是ui上的一块区域&…...
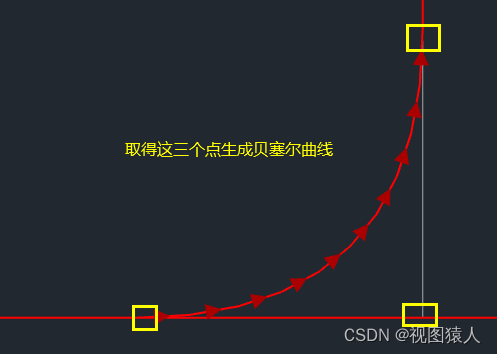
QT实现任意阶贝塞尔曲线绘制
bezier曲线在编程中的难点在于求取曲线的系数,如果系数确定了那么就可以用微小的直线段画出曲线。bezier曲线的系数也就是bernstein系数,此系数的性质可以自行百度,我们在这里是利用bernstein系数的递推性质求取: 简单举例 两个…...

【Java 基础篇】Java 数组使用详解:从零基础到数组专家
如果你正在学习编程,那么数组是一个不可或缺的重要概念。数组是一种数据结构,用于存储一组相同类型的数据。在 Java 编程中,数组扮演着非常重要的角色,可以帮助你组织、访问和操作数据。在本篇博客中,我们将从零基础开…...

基于Citespace、vosviewer、R语言的文献计量学可视化分析技术及全流程文献可视化SCI论文高效写作
文献计量学是指用数学和统计学的方法,定量地分析一切知识载体的交叉科学。它是集数学、统计学、文献学为一体,注重量化的综合性知识体系。特别是,信息可视化技术手段和方法的运用,可直观的展示主题的研究发展历程、研究现状、研究…...

docker_python-django_uwsgi_nginx_浏览器_网络访问映过程
介绍 1:介绍docker中使用uwsgi服务器启动django 设置了uwsgi的脚本 2:介绍启动uwsgi后,使用本地浏览器去访问这个容器中的端口 3:分别使用了3个ip地址去访问这个服务 1:使用本地连接*2 2:使用windows系统里…...

Python爬取天气数据并进行分析与预测
随着全球气候的不断变化,对于天气数据的获取、分析和预测显得越来越重要。本文将介绍如何使用Python编写一个简单而强大的天气数据爬虫,并结合相关库实现对历史和当前天气数据进行分析以及未来趋势预测。 1 、数据源选择 选择可靠丰富的公开API或网站作…...
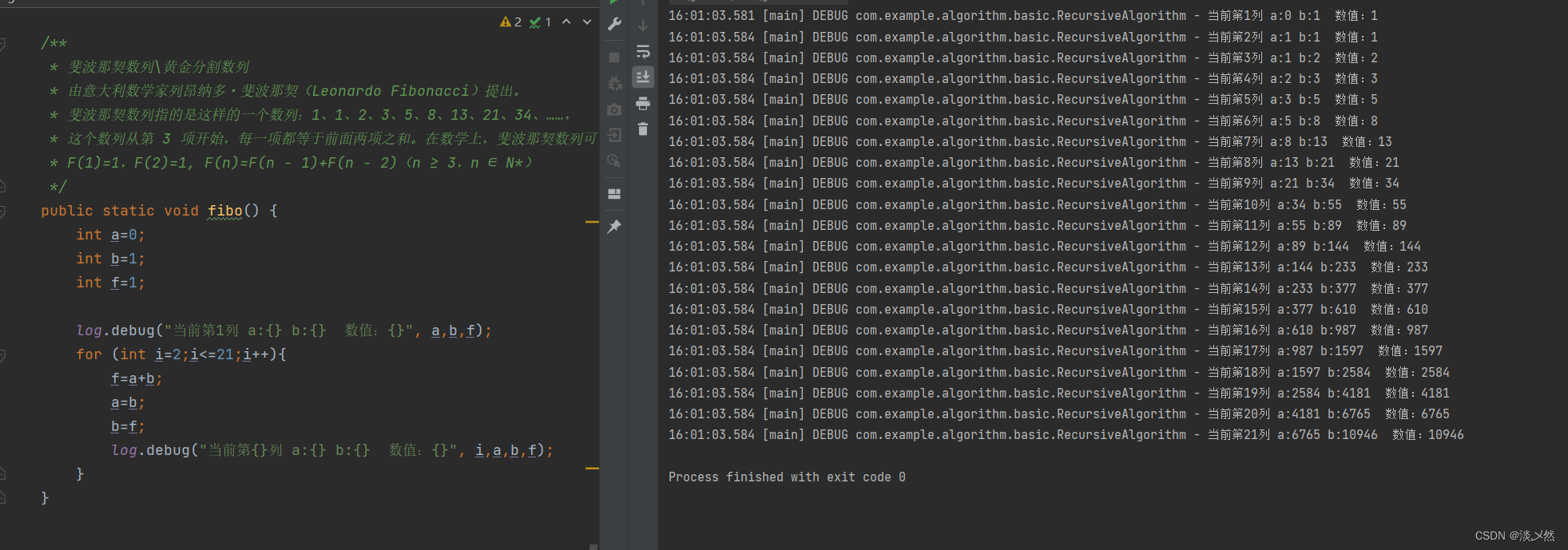
基础算法-递推算法-学习
现象: 基础算法-递推算法-学习 方法: 这就是一种递推的算法思想。递推思想的核心就是从已知条件出发,逐步推算出问题的解 最常见案例: 一:正向递推案例: 弹力球回弹问题: * 弹力球从100米高…...
 测试点全过)
L1-056 猜数字(Python实现) 测试点全过
前言: {\color{Blue}前言:} 前言: 本系列题使用的是,“PTA中的团体程序设计天梯赛——练习集”的题库,难度有L1、L2、L3三个等级,分别对应团体程序设计天梯赛的三个难度。更新取决于题目的难度,…...
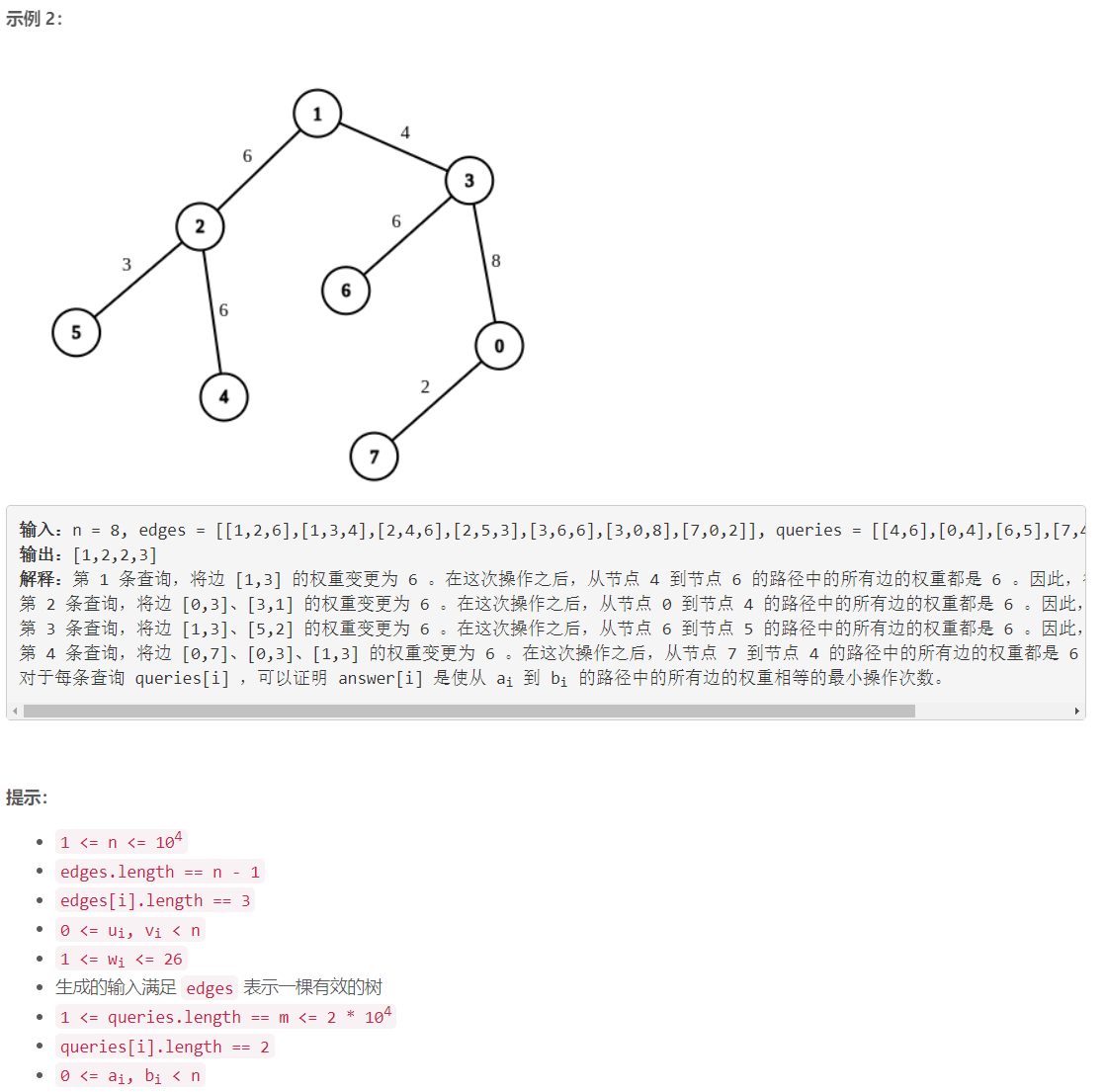
第 361 场 LeetCode 周赛题解
A 统计对称整数的数目 枚举 x x x class Solution { public:int countSymmetricIntegers(int low, int high) {int res 0;for (int i low; i < high; i) {string s to_string(i);if (s.size() & 1)continue;int s1 0, s2 0;for (int k 0; k < s.size(); k)if …...

07-架构2023版-centos+docker部署Canal 实现多端数据同步
canal 工作原理 canal 模拟 MySQL slave 的交互协议,伪装自己为 MySQL slave ,向 MySQL master 发送dump 协议MySQL master 收到 dump 请求,开始推送 binary log 给 slave (即 canal )canal 解析 binary log 对象(原始为 byte 流)基于日志增量订阅和消费的业务包括 数据库镜…...
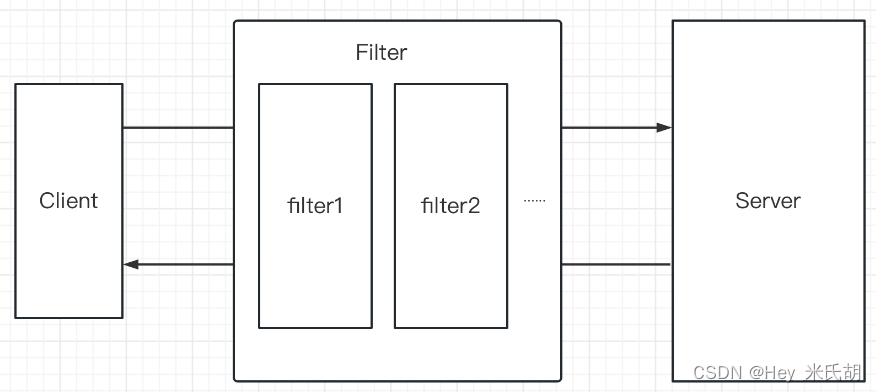
过滤器的应用-Filter
过滤器 1.工作原理 2.创建Filter 2.1通过注解的方式实现 //创建一个类,实现Filter接口 WebFilter(urlPatterns "/myfilter") //urlPatterns表示需要拦截的路径 public class MyFilter implements Filter {Overridepublic void doFilter(ServletReques…...

leetcode236. 二叉树的最近公共祖先(java)
二叉树的最近公共祖先 题目描述递归法代码演示 上期经典 题目描述 给定一个二叉树, 找到该树中两个指定节点的最近公共祖先。 百度百科中最近公共祖先的定义为:“对于有根树 T 的两个节点 p、q,最近公共祖先表示为一个节点 x,满足 x 是 p、q …...

终极指南:Seal中Kotlin协程上下文组合的实用技巧
终极指南:Seal中Kotlin协程上下文组合的实用技巧 【免费下载链接】Seal 🦭 Video/Audio Downloader for Android, based on yt-dlp 项目地址: https://gitcode.com/gh_mirrors/se/Seal Seal是一款基于yt-dlp的Android音视频下载器,在其…...

tcpdive性能评估报告:CPU占用率与QPS影响分析终极指南
tcpdive性能评估报告:CPU占用率与QPS影响分析终极指南 【免费下载链接】tcpdive A TCP performance profiling tool. 项目地址: https://gitcode.com/gh_mirrors/tc/tcpdive tcpdive作为一款专业的TCP性能分析工具,在生产环境中的性能表现至关重要…...
)
ubuntu linux虚拟机安装部署hermes详细教程(安装、问题处理)
文章目录 前言 一、Hermes 介绍 1. 什么是 Hermes Agent? 2. 核心特性 3. 为什么选择 Hermes Agent? 4. 适用场景 二、安装Hermes 1.安装 2.配置 3.开始对话 4.接入多平台(可选) 5.保持更新 三、Hermes接入微信 四、常见错误解决 1.Failed to connect to github.com port 4…...

NotebookLM技能集成:自动化文档问答与RAG应用实践
1. 项目概述:当NotebookLM遇上自定义技能最近在折腾AI工具链的时候,发现了一个挺有意思的项目:jasontsaicc/notebooklm-studio-skill。乍一看这个名字,你可能和我最初的反应一样,有点摸不着头脑。NotebookLM我知道&…...

基于Taotoken构建每日大赛自动评分与反馈Agent工作流
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 基于Taotoken构建每日大赛自动评分与反馈Agent工作流 对于编程大赛、算法竞赛或日常训练的组织者与教练而言,每日处理大…...

基于BMapGL与MapVGL,实战城市人流热力图可视化
1. 从零开始搭建热力图开发环境 第一次接触百度地图GL版开发时,我也被各种配置搞得晕头转向。现在把完整的环境搭建流程梳理出来,帮你避开我踩过的那些坑。BMapGL作为百度地图的WebGL版本,相比传统API渲染效率提升明显,特别适合数…...

Spek音频频谱分析器:3分钟掌握专业音频分析技术
Spek音频频谱分析器:3分钟掌握专业音频分析技术 【免费下载链接】spek Acoustic spectrum analyser 项目地址: https://gitcode.com/gh_mirrors/sp/spek 音频频谱分析是理解音频文件内在结构的关键技术,而Spek正是这一领域的专业工具。这款免费开…...

2025届必备的十大AI写作工具实际效果
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 为科研从业者、学子以及技术研发人员,在人工智能领域,合规可靠的AI论…...

从零到一搭建 AI Agent 财务分析系统
一、核心目标拆解(先对齐业务) 你的系统要支撑 4 类核心场景: 财务报告自动生成 + 智能解读 智能问答 + 异常预警 财务预测、预算编制、风险识别 对接业务部门,推动需求落地 基于这个目标,我给你定了 **「轻量化 MVP → 企业级生产」两阶段架构 **,兼顾快速出 Demo 和长…...

告别重复操作:M9A如何用智能自动化重塑《重返未来:1999》游戏体验
告别重复操作:M9A如何用智能自动化重塑《重返未来:1999》游戏体验 【免费下载链接】M9A 重返未来:1999 小助手 | Assistant For Reverse: 1999 项目地址: https://gitcode.com/gh_mirrors/m9/M9A 在当今快节奏的生活中,游戏…...