Vision Transformer(VIT 网络架构)
论文下载链接:https://arxiv.org/abs/2010.11929
文章目录
- 引言
- 1. VIT与传统CNN的比较
- 2. 为什么需要Transformer在图像任务中?
- 1. 深入Transformer
- 1.1 Transformer的起源:NLP领域的突破
- 1.2 Transformer的基本组成
- 1.2.1 自注意机制 (Self-Attention Mechanism)
- 1.2.2 前馈神经网络 (Feed-forward Neural Networks)
- 1.2.3 残差连接 (Residual Connections)
- 1.2.4 层标准化 (Layer Normalization)
- 2. 从CNN到Vision Transformer
- 2.1 CNN的局限性
- 2.2 Vision Transformer的出现与动机
- 3. Vision Transformer的工作原理
- 3.1 输入:将图像分割成patches
- 3.2 嵌入:linear embedding和位置嵌入
- 3.3 Transformer编码器
- 3.4 输出头:分类任务
- 4. ViT的变种和相关工作
- 4.1 DeiT (Data-efficient Image Transformer)
- 4.1.1 概述
- 4.1.2 知识蒸馏
- 4.1.3 利用知识蒸馏进行优化的Transformer模型
- 4.2 Hybrid models (ViT + CNN)
- 4.2.1 为什么使用混合模型?
- 4.2.2 基础架构
- 4.2.3 示例
- 4.3 Swin Transformer
- 4.3.1 主要特点
- 4.3.2 基础架构
- 4.3.3 代码示例
- 5. ViT的优点与缺点
- 5.1 与CNN相比的优点
- 5.2 ViT的挑战和限制
引言
1. VIT与传统CNN的比较
ViT(Vision Transformer)与传统的卷积神经网络(CNN)在图像处理方面有几个关键的不同点:
1. 模型结构:
- ViT:主要基于Transformer结构,没有使用卷积层。
- CNN:使用卷积层、池化层和全连接层。
2. 输入处理:
- ViT:将图像分为多个固定大小的块并一次性处理。
- CNN:通过卷积窗口逐渐扫描整个图像。
3. 计算复杂性:
- ViT:由于自注意力机制,计算复杂性可能更高。
- CNN:通常更易于优化,计算复杂性相对较低。
4. 数据依赖性:
- ViT:通常需要更多的数据和计算资源来进行有效的训练。
- CNN:相对更容易在小数据集上进行训练。
2. 为什么需要Transformer在图像任务中?
在深度学习的历史中,卷积神经网络(Convolutional Neural Networks, CNNs)长期以来一直是处理图像任务的主流架构。然而,随着Transformer的成功应用于自然语言处理(NLP)任务,研究人员开始考虑其在计算机视觉中的潜力。
灵活的全局注意机制
- 全局上下文: 与局部感受野的CNN不同,Transformer具有全局的感受野,这使其可以在整个图像上进行信息融合。这种全局上下文可能在某些任务中非常有用,如图像分割、物体检测和多物体交互等。
可解释性和注意可视化
- 更好的可解释性: 由于自注意机制,我们可以很容易地可视化模型在做决策时关注的区域,这增加了模型的可解释性。
序列到序列任务
- 更容易处理序列输出: 在像图像字幕这样的任务中,同时考虑图像和文本信息变得更为直接,因为两者都可以用相似的Transformer架构来处理。
适应性
- 更容易适应不同尺度和形状: Transformer不依赖于固定尺寸的滤波器,因此理论上更容易适应各种各样的输入。
1. 深入Transformer
1.1 Transformer的起源:NLP领域的突破
Transformer模型最初是由Google的研究人员在2017年的论文《Attention Is All You Need》中提出的。这个模型引入了一种全新的架构,主要以自注意(Self-Attention)机制为基础,并成功地解决了当时自然语言处理(NLP)中的一系列任务。这里列举一些Transformer在NLP领域的重要突破和影响:
1. 序列建模问题的新视角
传统的RNN(循环神经网络)和LSTM(长短时记忆)网络因为其递归的特性,在处理长序列时会遇到梯度消失或梯度爆炸的问题。Transformer通过自注意机制成功地捕获了序列内部的依赖关系,并且能够并行处理整个序列,从而在很多方面超过了RNN和LSTM。
2. 自注意机制
Transformer模型中的自注意机制允许模型在不同位置的输入之间建立直接的依赖关系,这让模型能更容易地理解句子或文档内部的上下文关系。这种机制特别适用于诸如机器翻译、文本摘要、问答系统等需要捕获长距离依赖的任务。
3. 可扩展性
由于其并行性和相对较少的时间复杂性,Transformer架构能更有效地利用现代硬件。这使得研究人员能够训练更大、更强大的模型,从而取得更好的性能。
4. 多模态和多任务学习
Transformer的架构具有高度的灵活性,可以容易地扩展到其他类型的数据和任务,包括图像、音频和多模态输入。这一点在后续的研究和应用中得到了广泛的证实。
5. 预训练和微调
Transformer架构适用于预训练和微调的工作流程。大型的预训练模型如BERT、GPT和T5都是基于Transformer构建的,并在多种NLP任务上设立了新的性能基准。
1.2 Transformer的基本组成
1.2.1 自注意机制 (Self-Attention Mechanism)
从心理学上来讲
- 动物需要在复杂环境下有效关注值得注意的点
- 心理学框架:人类根据随意(volitional)线索和不随意线索选择注意点(注意:这里的随意不是随便的意思,因为是翻译过来的,这里的随意应当为主动观察和不主动观察的意思,也可以理解为刻意和无意)
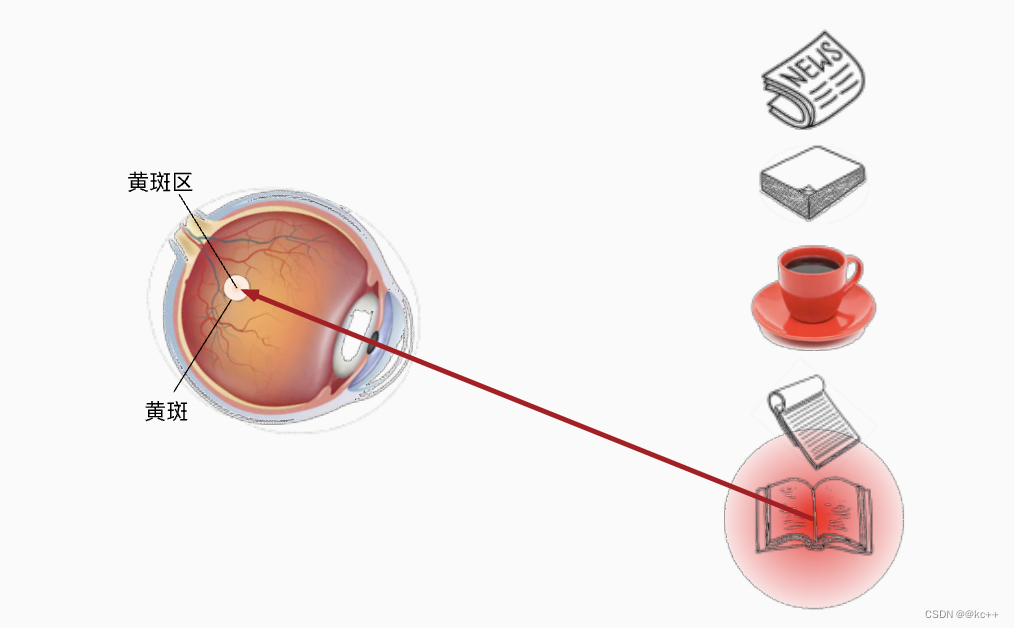
想象一下,假如我们面前有五个物品: 一份报纸、一篇研究论文、一杯咖啡、一本笔记本和一本书。所有纸制品都是黑白印刷的,但咖啡杯是红色的。 换句话说,这个咖啡杯在这种视觉环境中是突出和显眼的, 不由自主地引起人们的注意。 所以我们会把视力最敏锐的地方放到咖啡上
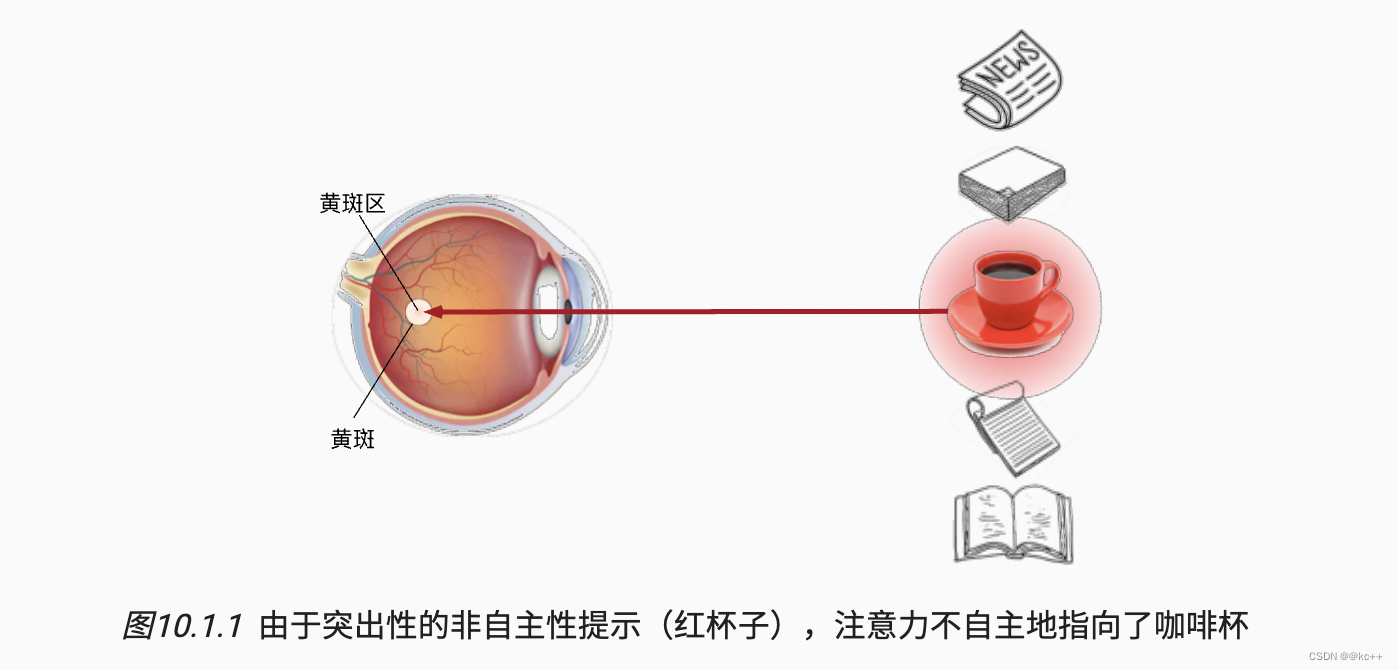
而想读书就成了随意线索
注意力机制
- 在传统的CNN架构中。卷积,池化,全连接层都只考虑不随意线索
- 注意力机制则显示的考虑随意线索
-
- 随意线索被称之为查询(query)
-
- 每个输入是一个值(value)和不随意线索(key)的对(这里可以把输入理解为环境)
-
- 通过注意力池化层来有偏向性的选择某些输入,因为我们加入了一些随意线索,我们可以在这里面有偏向性地选择某些输入。
计算过程
- 点积计算: 对于给定的查询,与每一个键进行点积,用以衡量查询和各个键之间的相似度。
- 缩放: 将点积的结果缩放(通常是除以键向量维度的平方根)。
- 激活函数: 应用Softmax激活函数,使权重和为1且介于0和1之间。
- 加权和: 使用得到的权重对值向量进行加权求和。
- 输出: 将加权和通过一个可选的全连接(Linear)层进行转换,生成该位置的输出。
多头注意力(Multi-Head Attention)
为了更丰富地捕捉不同的依赖关系,通常会使用多头注意力。在多头注意力中,模型维护多组独立的查询、键和值的权重矩阵,并进行并行计算。各个头的输出会被拼接并通过一个全连接层进行整合。
1.2.2 前馈神经网络 (Feed-forward Neural Networks)
前馈神经网络(Feed-forward Neural Networks, FFNNs)是最早的、最简单的神经网络架构。这种网络的特点是数据在网络中只有一个方向进行传播:从输入层,经过隐藏层,最终到输出层。这种单向的数据流动是“前馈”名字的由来。
结构和组件
- 输入层 (Input Layer): 这一层接收原始的输入数据,并将其传递给下一层。
- 隐藏层 (Hidden Layers): 网络可以包含一个或多个隐藏层,每个层由多个神经元组成。这些层捕获输入数据的复杂模式。
- 输出层 (Output Layer): 根据任务的需求(如分类、回归等),输出层生成网络的最终输出。
激活函数
为了引入非线性特性,每个神经元通常会有一个激活函数。常用的激活函数有:
- ReLU (Rectified Linear Unit)
- Sigmoid
- Tanh (Hyperbolic Tangent)
- Leaky ReLU, Parametric ReLU, etc.
训练
前馈神经网络通常使用反向传播(Backpropagation)算法进行训练,这涉及到:
- 前向传播 (Forward Propagation): 从输入层开始,数据通过网络流动,生成预测输出。
- 损失计算 (Loss Calculation): 根据预测输出和实际目标计算损失。
- 反向传播 (Backward Propagation): 计算损失关于每个权重的梯度,并更新网络中的权重。
在Transformer中的应用
虽然Transformer架构主要着重于自注意机制,但它在每个注意力模块之后都有一个前馈神经网络(通常是两层的网络)。这为模型引入了额外的计算能力,并帮助捕获数据的不同特征。
1.2.3 残差连接 (Residual Connections)
在Transformer架构中,残差连接起到了非常关键的作用。它们出现在自注意力(Self-Attention)层和前馈神经网络(Feed-forward Neural Networks)层的后面,通常与层归一化(Layer Normalization)一起使用。
结构与功能
在Transformer中,每一个子层(如多头自注意力或前馈神经网络)的输出都会与该子层的输入相加,形成一个残差连接。这种连接结构可以表示为:
Output=Sublayer(x)+x
或者更一般地:
Output=LayerNorm(Sublayer(x)+x)
这里的Sublayer(x)是子层(例如多头自注意力或前馈神经网络)的输出,而LayerNorm是层归一化。
1.2.4 层标准化 (Layer Normalization)
基本原理
层标准化的核心思想是对每一层的每一个样本独立进行标准化,以便每一层的输出具有大致相同的尺度。在全连接层或者卷积层之后,但通常在激活函数之前应用层标准化。
数学表示为:

在Transformer中的应用
在Transformer架构中,层标准化通常与残差连接(Residual Connections)结合使用。每个残差连接后面都会跟一个层标准化步骤,以稳定模型训练。这种组合有助于模型在训练期间保持数值稳定性,尤其是对于非常深的模型。
class AddNorm(nn.Module):"""残差连接后进行层规范化"""def __init__(self, normalized_shape, dropout, **kwargs):super(AddNorm, self).__init__(**kwargs)self.dropout = nn.Dropout(dropout)self.ln = nn.LayerNorm(normalized_shape)def forward(self, X, Y):return self.ln(self.dropout(Y) + X)
优点
- 数值稳定性: 层标准化有助于防止梯度消失或梯度爆炸问题,从而使模型更容易训练。
- 加速收敛: 通过调整各层的尺度,层标准化可以加速模型的收敛速度。
- 可适应性: 层标准化适用于不同类型和深度的网络架构,包括循环神经网络(RNNs)。
缺点
- 序列长度依赖: 在处理可变长度序列时,层标准化可能不如批标准化(Batch Normalization)有效。
- 模型复杂性: 引入了额外的可学习参数,这可能会增加模型的复杂性。
2. 从CNN到Vision Transformer
卷积神经网络(CNN)和Vision Transformer(ViT)都是用于处理图像任务的流行模型,但它们有着不同的设计哲学和应用范围。下面简要介绍这两者之间的演进。
2.1 CNN的局限性
1. 局部感受野
CNN通过局部感受野(receptive fields)来处理图像,这在某些任务中是一个局限性。虽然这种设计有助于识别图像中的局部结构,但它可能不适合捕捉远距离的依赖关系。
2. 计算成本
当处理高分辨率图像时,卷积操作的计算成本可能会非常高。
3. 空间结构假设
CNN假设输入数据具有某种固有的空间或时间结构。这使得CNN不容易适用于没有明确空间结构的数据。
4. 参数效率
在参数效率方面,即使使用了各种技巧(如批标准化、残差连接等),CNN仍然可能不如Transformer模型。
2.2 Vision Transformer的出现与动机
Vision Transformer是由Google Research在2020年首次提出的,它的设计灵感来自于用于自然语言处理的Transformer模型。
1. 全局注意力
与CNN不同,ViT使用全局自注意力机制,可以更好地处理图像中的远距离依赖关系。
2. 计算效率
ViT通过自注意力和前馈神经网络来实现计算效率,特别是在处理高分辨率图像时。
3. 模块化和可扩展性
ViT具有很好的模块化和可扩展性,可以容易地调整模型大小和复杂性。
4. 参数效率
在大量数据集上进行预训练后,ViT通常表现出高度的参数效率,即在相同数量的参数下,性能比CNN更好。
5. 跨模态应用
由于ViT没有硬编码的空间假设,它也更容易应用于其他类型的数据和任务。
3. Vision Transformer的工作原理
3.1 输入:将图像分割成patches
输入:将图像分割成patches
- 图像分割: Vision Transformer(ViT)首先将输入图像分割成多个固定大小的小块(patches)。这些小块通常是方形的,例如16x16像素。
- 一维化: 每个小块都被拉平成一个一维向量。
- 合并: 所有这些一维向量然后被串联成一个序列,作为Transformer编码器的输入。
3.2 嵌入:linear embedding和位置嵌入
- Linear Embedding: 小块通过一个线性层(通常是一个全连接层)进行嵌入,以将它们转换成合适维度的向量。这相当于通过一个很浅的CNN层进行特征提取。
- 位置嵌入: 由于小块的原始位置信息在一维化过程中丢失了,因此需要添加位置嵌入以帮助模型识别这些小块的相对或绝对位置。
- 合并: 线性嵌入和位置嵌入通常会被加在一起,以生成一个包含位置信息的嵌入序列。
3.3 Transformer编码器
- 自注意力层: 这一层使用自注意力机制来分析输入序列中的每个元素(即每个小块和其对应的位置嵌入),以便更好地表示各个小块之间的关系。
- 前馈神经网络: 自注意力层的输出会被送入一个前馈神经网络(Feed-forward Neural Network)。
- 残差连接与层标准化: 在自注意力层和前馈神经网络之后,都会有残差连接和层标准化操作,以促进模型训练的稳定性和效率。
- 堆叠编码器: 上述所有组件会被堆叠多次(例如,12次或24次等),以形成完整的Transformer编码器。
- 分类头: 对于分类任务,通常会取编码器输出序列的第一个元素(通常对应于一个特殊的“[CLS]”标记)并通过一个全连接层进行分类。
class EncoderBlock(nn.Module):"""Transformer编码器块"""def __init__(self, key_size, query_size, value_size, num_hiddens,norm_shape, ffn_num_input, ffn_num_hiddens, num_heads,dropout, use_bias=False, **kwargs):super(EncoderBlock, self).__init__(**kwargs)self.attention = d2l.MultiHeadAttention(key_size, query_size, value_size, num_hiddens, num_heads, dropout,use_bias)self.addnorm1 = AddNorm(norm_shape, dropout)self.ffn = PositionWiseFFN(ffn_num_input, ffn_num_hiddens, num_hiddens)self.addnorm2 = AddNorm(norm_shape, dropout)def forward(self, X, valid_lens):Y = self.addnorm1(X, self.attention(X, X, X, valid_lens))return self.addnorm2(Y, self.ffn(Y))
Transformer编码器中的任何层都不会改变其输入的形状。
3.4 输出头:分类任务
在Vision Transformer(ViT)模型中,用于分类任务的输出头通常是一个全连接(线性)层,该层将Transformer编码器的输出映射到类别标签的数量。在多数实现中,通常会使用Transformer编码器输出的第一个位置(通常与添加的特殊 [CLS] 标记对应)的特征。
4. ViT的变种和相关工作
随着Vision Transformer(ViT)在图像分类任务中的成功,很多研究者开始探索其变种和改进方案。这里选择一些值得关注的变种和相关工作进行概述解析:
4.1 DeiT (Data-efficient Image Transformer)
4.1.1 概述
- 概念: DeiT关注于如何更有效地使用数据。标准的ViT需要大量的数据和计算资源来进行预训练,但DeiT通过更高效的训练策略,尤其是数据增强和知识蒸馏,来改善这一点。
- 主要特点: 使用知识蒸馏和不同的训练技巧,如学习率调度和数据增强,以减少对大量标签数据的依赖。
import torch
import torch.nn as nn
import torch.nn.functional as F# 分割图像到patch
class PatchEmbedding(nn.Module):def __init__(self, patch_size, in_channels, embed_dim):super().__init__()self.proj = nn.Conv2d(in_channels, embed_dim, kernel_size=patch_size, stride=patch_size)def forward(self, x):x = self.proj(x) # [B, C, H, W]x = x.flatten(2).transpose(1, 2) # [B, num_patches, embed_dim]return x# DeiT 模型主体
class DeiT(nn.Module):def __init__(self, patch_size, in_channels, embed_dim, num_heads, num_layers, num_classes):super().__init__()# 分割图像到patch并嵌入self.patch_embed = PatchEmbedding(patch_size, in_channels, embed_dim)# 特殊的 [CLS] tokenself.cls_token = nn.Parameter(torch.zeros(1, 1, embed_dim))# 位置嵌入num_patches = (224 // patch_size) ** 2self.pos_embed = nn.Parameter(torch.zeros(1, num_patches + 1, embed_dim))# Transformer 编码器encoder_layer = nn.TransformerEncoderLayer(embed_dim, num_heads)self.transformer = nn.TransformerEncoder(encoder_layer, num_layers)# 分类器头self.fc = nn.Linear(embed_dim, num_classes)def forward(self, x):B = x.size(0)# 分割图像到patch并嵌入x = self.patch_embed(x)# 添加 [CLS] tokencls_token = self.cls_token.repeat(B, 1, 1)x = torch.cat([cls_token, x], dim=1)# 添加位置嵌入x += self.pos_embed# 通过 Transformerx = self.transformer(x)# 只取 [CLS] 对应的输出用于分类任务x = x[:, 0]# 分类器x = self.fc(x)return x# 参数
patch_size = 16
in_channels = 3
embed_dim = 768
num_heads = 12
num_layers = 12
num_classes = 1000 # 假设是一个1000分类问题# 初始化模型
model = DeiT(patch_size, in_channels, embed_dim, num_heads, num_layers, num_classes)# 假数据
x = torch.randn(32, 3, 224, 224) # 32张3通道224x224大小的图片# 模型前向推断
logits = model(x)4.1.2 知识蒸馏
知识蒸馏(Knowledge Distillation, KD)是一种模型压缩技术,用于将一个大型、复杂模型(通常称为“教师模型”)的知识转移到一个更小、更简单的模型(通常称为“学生模型”)中。这样做的目的是在保持与大型模型相近的性能的同时,降低模型大小和推断时间。
工作原理
- 教师模型: 通常是一个预先训练好的大型模型,用于生成软标签(soft labels),即类别概率分布。
- 学生模型: 通常是一个相对较小的模型,需要被训练来模仿教师模型。
- 蒸馏损失: 在最基础的知识蒸馏中,学生模型的训练不仅要最小化与真实标签之间的损失(如交叉熵损失),还要最小化与教师模型预测的软标签之间的损失。
简单的知识蒸馏代码示例
假设我们有一个教师模型(teacher_model)和一个学生模型(student_model),下面是一个使用PyTorch进行知识蒸馏的简单示例:
import torch
import torch.nn.functional as F# 假定 teacher_model 和 student_model 已经定义并初始化
# teacher_model = ...
# student_model = ...# 数据加载器
# data_loader = ...# 优化器
optimizer = torch.optim.Adam(student_model.parameters(), lr=0.001)# 温度参数和软标签权重
temperature = 2.0
alpha = 0.9# 训练循环
for data, labels in data_loader:optimizer.zero_grad()# 正向传播:教师和学生模型teacher_output = teacher_model(data).detach() # 注意:通常不会计算教师模型的梯度student_output = student_model(data)# 计算损失hard_loss = F.cross_entropy(student_output, labels) # 与真实标签的损失soft_loss = F.kl_div(F.log_softmax(student_output/temperature, dim=1),F.softmax(teacher_output/temperature, dim=1)) # 与软标签的损失loss = alpha * soft_loss + (1 - alpha) * hard_loss# 反向传播和优化loss.backward()optimizer.step()应用场景
知识蒸馏不仅适用于模型压缩,在一些特定应用中也能用于提高小型模型的性能,例如在DeiT(Data-efficient Image Transformer)中用于提高数据效率。
4.1.3 利用知识蒸馏进行优化的Transformer模型
以下我们假设有一个已经训练好的大型 Transformer 模型(教师模型),以及一个更小的 Transformer 模型(学生模型)。
注意:这里为了简单,我们使用 nn.Transformer 模块作为 Transformer 的简单实现。你也可以根据需要替换为更复杂的模型。
损失函数包含两部分:一部分是学生模型和实际标签之间的损失,另一部分是学生和教师模型输出之间的 Kullback-Leibler 散度。
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim# 定义简单的 Transformer 模型
class SimpleTransformer(nn.Module):def __init__(self, d_model, nhead, num_layers, num_classes):super(SimpleTransformer, self).__init__()self.encoder = nn.Transformer(d_model, nhead, num_layers)self.classifier = nn.Linear(d_model, num_classes)def forward(self, x):x = self.encoder(x)x = x.mean(dim=1)x = self.classifier(x)return x# 定义损失函数
def distillation_loss(y, labels, teacher_output, T=2.0, alpha=0.5):return nn.CrossEntropyLoss()(y, labels) * (1. - alpha) + (alpha * T * T) * nn.KLDivLoss()(F.log_softmax(y/T, dim=1),F.softmax(teacher_output/T, dim=1))# 假设我们有一些数据
# 注意:这里使用随机数据仅作为示例
N = 100 # 数据点数量
d_model = 32 # 嵌入维度
nhead = 2 # 多头注意力的头数
num_layers = 2 # Transformer 层的数量
num_classes = 10 # 分类数
T = 2.0 # 温度参数
alpha = 0.5 # 蒸馏损失的权重因子x = torch.randn(N, 10, d_model)
labels = torch.randint(0, num_classes, (N,))# 初始化教师和学生模型
teacher_model = SimpleTransformer(d_model, nhead, num_layers, num_classes)
student_model = SimpleTransformer(d_model, nhead, num_layers, num_classes)# 设置优化器
optimizer = optim.Adam(student_model.parameters(), lr=0.001)# 模拟训练过程
for epoch in range(10):# 前向传播teacher_output = teacher_model(x).detach() # 通常来说,教师模型是预先训练好的,因此不需要计算梯度student_output = student_model(x)# 计算损失loss = distillation_loss(student_output, labels, teacher_output, T, alpha)# 反向传播和优化optimizer.zero_grad()loss.backward()optimizer.step()print(f"Epoch {epoch+1}, Loss: {loss.item()}")4.2 Hybrid models (ViT + CNN)
混合模型(Hybrid models)结合了 Vision Transformer(ViT)和卷积神经网络(CNN)的优点,以实现更强大的图像识别能力。这类模型通常使用 CNN 作为特征提取器,将其输出用作 ViT 的输入。
4.2.1 为什么使用混合模型?
- 局部与全局特性: CNN 非常擅长捕获局部特性,而 Transformer 能够处理全局依赖关系。将两者结合可以更全面地理解图像。
- 计算效率: CNN 在处理图像数据方面通常更加高效。通过在模型前端使用 CNN,可以降低 Transformer 的计算复杂性。
- 数据效率: 使用 CNN 的预训练特征可以提高模型的数据效率,这对于训练数据较少的任务特别有用。
4.2.2 基础架构
在一个典型的混合模型中,CNN 通常用作特征提取器,而 ViT 用作特征编码和分类。
- 特征提取: 使用 CNN 层(可能是一个预训练的网络,比如 ResNet 或 VGG)从输入图像中提取特征。
- 图像分块与嵌入: 将 CNN 的输出分块,并通过线性嵌入层(或其他方法)转换为适用于 Transformer 的序列。
- Transformer 编码: 使用 ViT 进行特征的进一步编码。
- 分类头: 最后,使用全连接层进行分类。
4.2.3 示例
import torch
import torch.nn as nn# 假设使用 ResNet 的某个版本作为特征提取器
class FeatureExtractor(nn.Module):def __init__(self, ...):super().__init__()# 定义 CNN 结构,例如一个简化的 ResNet...def forward(self, x):# 通过 CNN 提取特征return x# ViT 作为编码器
class ViTEncoder(nn.Module):def __init__(self, ...):super().__init__()# 定义 Transformer 结构...def forward(self, x):# 通过 Transformer 编码特征return x# 混合模型
class HybridModel(nn.Module):def __init__(self, ...):super().__init__()self.feature_extractor = FeatureExtractor(...)self.vit_encoder = ViTEncoder(...)self.classifier = nn.Linear(...)def forward(self, x):x = self.feature_extractor(x) # CNN 特征提取x = self.vit_encoder(x) # Transformer 编码x = self.classifier(x) # 分类头return x4.3 Swin Transformer
Swin Transformer 是一种用于计算机视觉任务的 Transformer 架构,提出了一种基于滑窗(sliding window)的自注意机制。这种方法结合了卷积神经网络(CNN)和 Transformer 的优点,旨在实现更高的模型效率和性能。
4.3.1 主要特点
- 分层特征提取: 与 CNN 类似,Swin Transformer 进行多层特征提取,每一层都会降采样,但是这里是通过 Transformer 实现的。
- 滑窗自注意: Swin Transformer 使用了滑窗自注意机制,该机制只考虑局部的上下文信息,而不是传统 Transformer 中的全局上下文信息。这减少了计算复杂性。
- 分块与合并: 在多个层级中,Swin Transformer 通过分块和合并的方式,逐步减少序列的长度,并增加特征维度,以达到更高级别的特征提取。
- 灵活性: Swin Transformer 可以被用于多种计算机视觉任务,如图像分类、目标检测和语义分割等。
4.3.2 基础架构
- Patch Embedding: 将图像分割成多个小块(patches),然后用线性嵌入层进行嵌入。
- Swin Transformer Blocks: 包括多个 Swin Transformer 层,每一层都有一个或多个滑窗自注意机制和前馈神经网络。
- Head: 根据具体任务(如分类、检测等),在 Swin Transformer 的最后一层添加不同的头部结构。
4.3.3 代码示例
- PatchEmbedding: 这部分负责将输入图像切割成小块并进行嵌入。
- WindowAttention: 这是 Swin Transformer 特有的,用于在局部窗口内进行自注意力计算。
- SwinBlock: 包括一个窗口注意力层和一个多层感知机(MLP)。
- SwinTransformer: 最终的模型架构。
import torch
import torch.nn as nn
import torch.nn.functional as F# 切分图像为patches
class PatchEmbedding(nn.Module):def __init__(self, in_channels, out_dim, patch_size):super().__init__()self.conv = nn.Conv2d(in_channels, out_dim, kernel_size=patch_size, stride=patch_size)def forward(self, x):x = self.conv(x)x = x.flatten(2).transpose(1, 2)return x# 滑窗注意力
class WindowAttention(nn.Module):def __init__(self, dim, heads, window_size):super().__init__()self.dim = dimself.heads = headsself.window_size = window_sizeself.query = nn.Linear(dim, dim)self.key = nn.Linear(dim, dim)self.value = nn.Linear(dim, dim)def forward(self, x):# 假设 x 的形状为 [batch_size, num_patches, dim]# 分割为多个窗口windows = x.view(x.size(0), self.window_size, self.window_size, self.dim)# 计算 q, k, vq = self.query(windows)k = self.key(windows)v = self.value(windows)# 注意力计算attn = torch.einsum('bqhd,bkhd->bhqk', q, k)attn = F.softmax(attn, dim=-1)# 输出out = torch.einsum('bhqk,bkhd->bqhd', attn, v)out = out.contiguous().view(x.size(0), self.window_size * self.window_size, self.dim)return out# Swin Transformer Block
class SwinBlock(nn.Module):def __init__(self, dim, heads, window_size):super().__init__()self.norm1 = nn.LayerNorm(dim)self.attn = WindowAttention(dim, heads, window_size)self.norm2 = nn.LayerNorm(dim)self.mlp = nn.Sequential(nn.Linear(dim, dim),nn.GELU(),nn.Linear(dim, dim))def forward(self, x):x = x + self.attn(self.norm1(x))x = x + self.mlp(self.norm2(x))return x# Swin Transformer 模型
class SwinTransformer(nn.Module):def __init__(self, in_channels, out_dim, patch_size, num_classes):super().__init__()self.patch_embedding = PatchEmbedding(in_channels, out_dim, patch_size)# 假设我们有 4 个 Swin Blocks 和窗口大小为 8self.blocks = nn.ModuleList([SwinBlock(out_dim, 8, 8) for _ in range(4)])self.global_avg_pool = nn.AdaptiveAvgPool1d(1)self.fc = nn.Linear(out_dim, num_classes)def forward(self, x):x = self.patch_embedding(x)for block in self.blocks:x = block(x)x = self.global_avg_pool(x.mean(dim=1))x = self.fc(x.squeeze(-1))return x# 测试模型
if __name__ == '__main__':model = SwinTransformer(3, 128, 4, 10)x = torch.randn(16, 3, 32, 32) # 假设有 16 张 32x32 的图像y = model(x)print(y.shape) # 应该输出 torch.Size([16, 10])5. ViT的优点与缺点
5.1 与CNN相比的优点
- 更好的长距离依赖处理: Transformer 架构设计初衷就是用来捕捉长距离依赖,这在某些复杂的图像识别任务中是非常有用的。
- 参数效率: ViT 有潜力以较少的参数量达到与 CNN 相同的性能。
- 可解释性: 自注意力机制的输出可用于分析模型对于图像各部分的关注程度,有助于模型解释。
- 灵活性和泛化: Transformer 不依赖于固定大小的滤波器或局部区域,因此有潜力更好地泛化到不同类型和结构的视觉数据。
- 端到端训练: 与某些需要特别设计的 CNN 架构相比,ViT 可以从头到尾用一个统一的架构进行训练。
5.2 ViT的挑战和限制
- 计算复杂性: 对于大型图像,全局自注意力机制的计算复杂性可能非常高。这也是为什么一开始 ViT 主要用在 NLP 领域的原因之一。
- 数据依赖: ViT 通常需要大量的标注数据来进行有效训练。这在没有大量带标签数据的场景下可能是一个问题。
- 训练不稳定: Transformer 架构通常比 CNN 更难训练,尤其是在没有充足计算资源和数据的情况下。
- 局部特征处理不如 CNN: 由于没有内置的卷积操作,ViT 可能在某些依赖于局部特征的任务(例如纹理识别)中不如专门设计的 CNN。
- 内存消耗: 尤其是在大图像或长序列上,Transformer 模型(包括 ViT)通常需要更多的内存。
- 过拟合风险: 由于模型复杂性和参数量通常较大,ViT 更容易过拟合,尤其是在数据量较少的情况下。
相关文章:
Vision Transformer(VIT 网络架构)
论文下载链接:https://arxiv.org/abs/2010.11929 文章目录 引言1. VIT与传统CNN的比较2. 为什么需要Transformer在图像任务中? 1. 深入Transformer1.1 Transformer的起源:NLP领域的突破1.2 Transformer的基本组成1.2.1 自注意机制 (Self-Atte…...

数学建模--蒙特卡洛模型的Python实现
目录 1.算法思想简介 2.算法应用1:问题一阐述 3.算法应用1:问题一解决 4.算法应用2:问题二阐述 5.算法应用2:问题二解决 1.算法思想简介 #蒙特卡洛算法思想 """ 蒙特卡洛方法的理论其实很类似于概率论中一个比较重…...
MySQL访问和配置
目录 1.使用MySQL自带的客户端工具访问 2.使用DOS访问(命令行窗口WinR → cmd) 3.连接工具(SQLyog或其它) MySQL从小白到总裁完整教程目录:https://blog.csdn.net/weixin_67859959/article/details/129334507?spm1001.2014.3001.5502 1.使用MySQL自…...

note_前端框架Vue的安装和简单入门(Windows 11)
1. Vue安装 (1) 下载安装node.js和npm # 下载msi安装包 https://nodejs.org/en# 点击安装包,按提示安装 # 默认安装nodejs, npm, 在线文档; PATH配置# 确认安装是否成功,在dos中输入 node -v # 验证nodejs是否安装成功 npm -v # 验证nodejs包管…...

SILERGY(矽力杰)功率电子开关 SY6280AAC
SILERGY(矽力杰)功率电子开关 SY6280AAC Low Loss Power Distribution Switch SOT-5 Pacakge 2.4V ~ 5.5V (<6V) 0.6W Max. Current 2A Reverse blocking (no body diode) Programmable current limit ( Ilimits(A) 6800 / Rset(ohm). ) Application Circuit (Reco…...

mysql char 和varchar的区别?
char 和varchar的区别 1、 char 一定会使用指定的空间,varchar是根据数据来定空间 2、 char的插入数据效率理论上比varchar高:varchar是需要通过后面的记录数来计算 使用哪一种类型? 如果确定数据一定是占指定长度,那么使用char类…...

HttpClient默认重试机制
分析&回答 只有发生IOExecetion时才会发生重试InterruptedIOException、UnknownHostException、ConnectException、SSLException,发生这4中异常不重试get方法可以重试3次,post方法在socket对应的输出流没有被write并flush成功时可以重试3次。读/写超…...
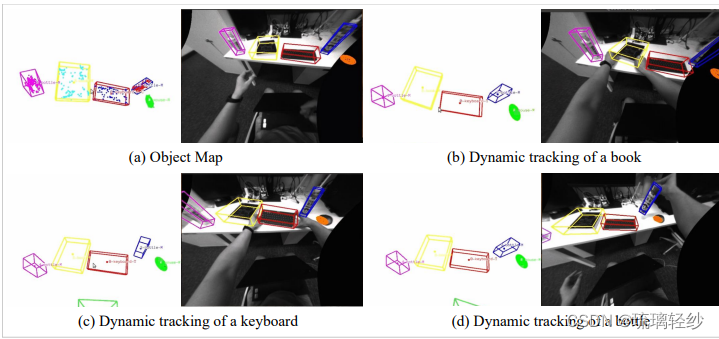
论文于祥读及复现——《Multi-level Map Construction for Dynamic Scenes》
论文祥读之——动态场景的多层次地图构建 0. 出发点(暨摘要)1. 引言2. 相关工作3.主要内容概括3.1 几何地图的构建3.1.1 密集点云地图和八叉图的构建3.1.2 平面地图的构建 3.2 对象地图的构建3.2.1 对象参数化和数据关联3.2.2 对象的更新与优化 4. 实验4…...
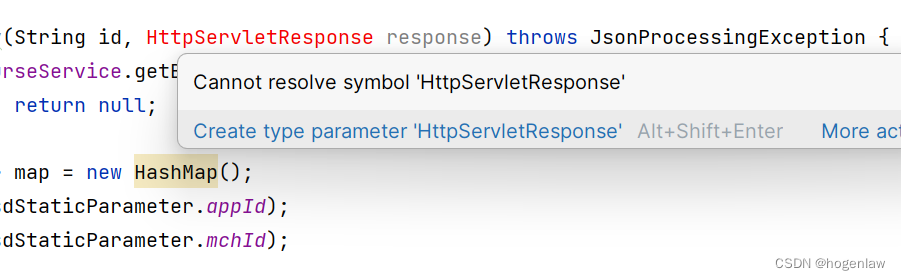
IDEA 报 Cannot resolve symbol ‘HttpServletResponse‘ 解决
springboot2版本换成springboot3之后,代码这里突然报红了, 首先要淡定,把原先Import的引入删掉,重新引入试试呢,是不是很简单哈哈。 原来,springboot3的路径是: import jakarta.servlet.http…...
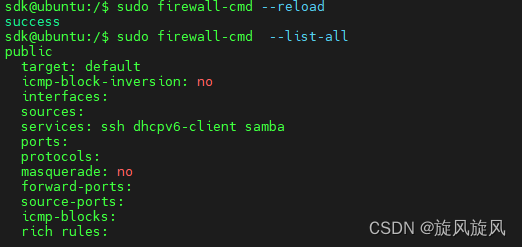
linux-samba-window登不上
登不上查了很久发现是防火墙导致的 sudo firewall-cmd --list-all //查看所有的防火墙信息sudo firewall-cmd --permanent --zonepublic --add-servicesamba //service里添加sambafirewall-cmd --reload //重启 便可以登录了,小问题...

Java Web3J :使用web3j监听、查询、订阅智能合约的事件
前面有文章写如何使用Docker-compose方式部署blockscout浏览器+charts图表,区块链浏览器已经部署成功了,同时我们在链上增加了治理投票流程,如何实时的把治理事件快速同步到浏览器呢?这时就想到了Web3J来监听智能合约的事件,来达到同步事件的效果 目录 Web3J简介功能简介m…...
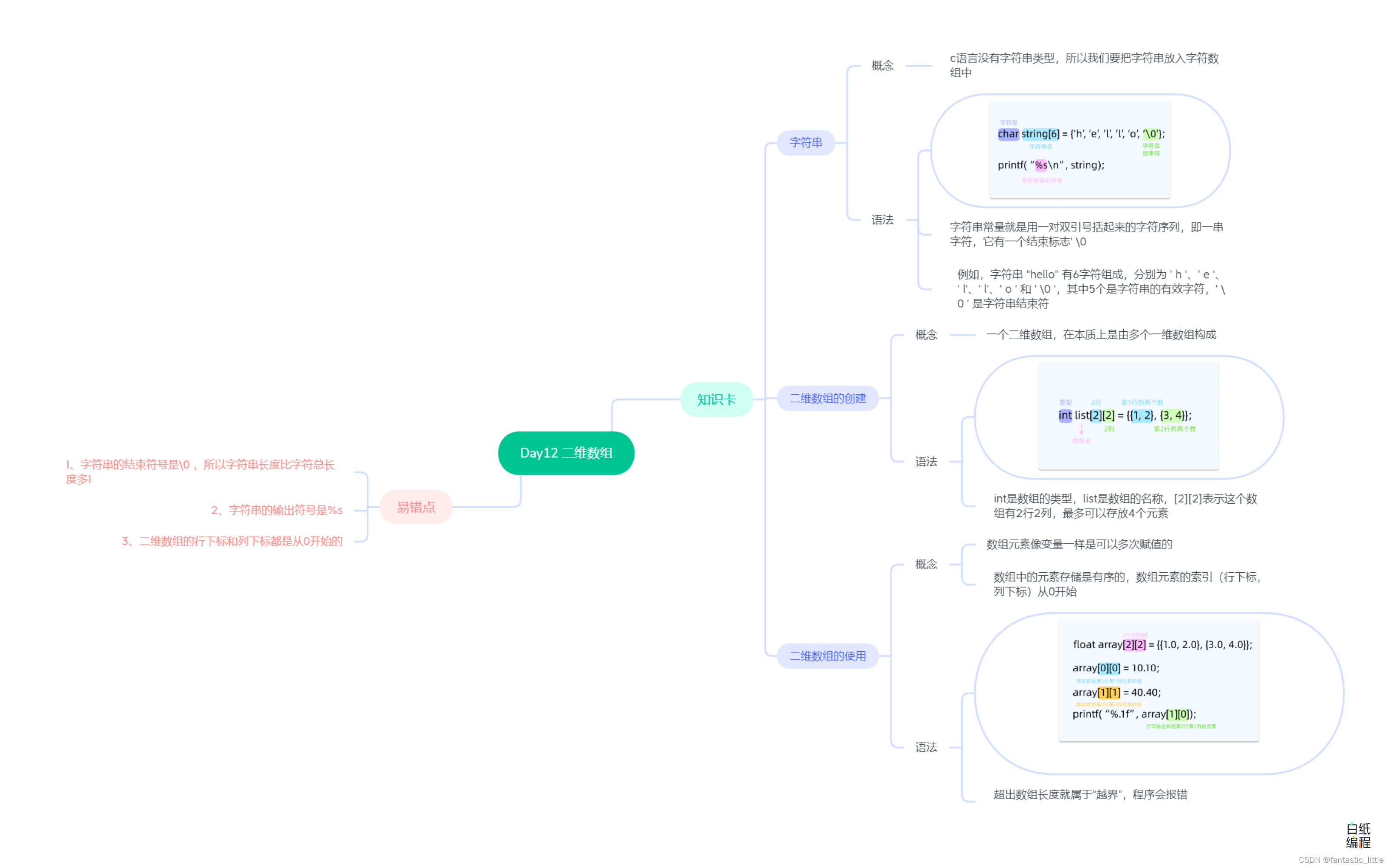
C语言入门 Day_13 二维数组
目录 前言: 1.字符串 2.创建二维数组 3.使用二维数组 4.易错点 5.思维导图 前言: 我们学习了字符类型char,我们可以用char来表示一个大写或者小写的字母,但真实应用中我们往往使用的是多个字符组成的一个单词或者句子。 …...

通过HFS低成本搭建NAS,并内网穿透实现公网访问
文章目录 前言1.下载安装cpolar1.1 设置HFS访客1.2 虚拟文件系统 2. 使用cpolar建立一条内网穿透数据隧道2.1 保留隧道2.2 隧道名称2.3 成功使用cpolar创建二级子域名访问本地hfs 总结 前言 云存储作为一个新概念,在前些年炒的火热,虽然伴随一系列黑天鹅…...
【SpringMVC】工作流程及入门案例
目录 前言 回顾MVC三层架构 1. SpringMVC简介 …...
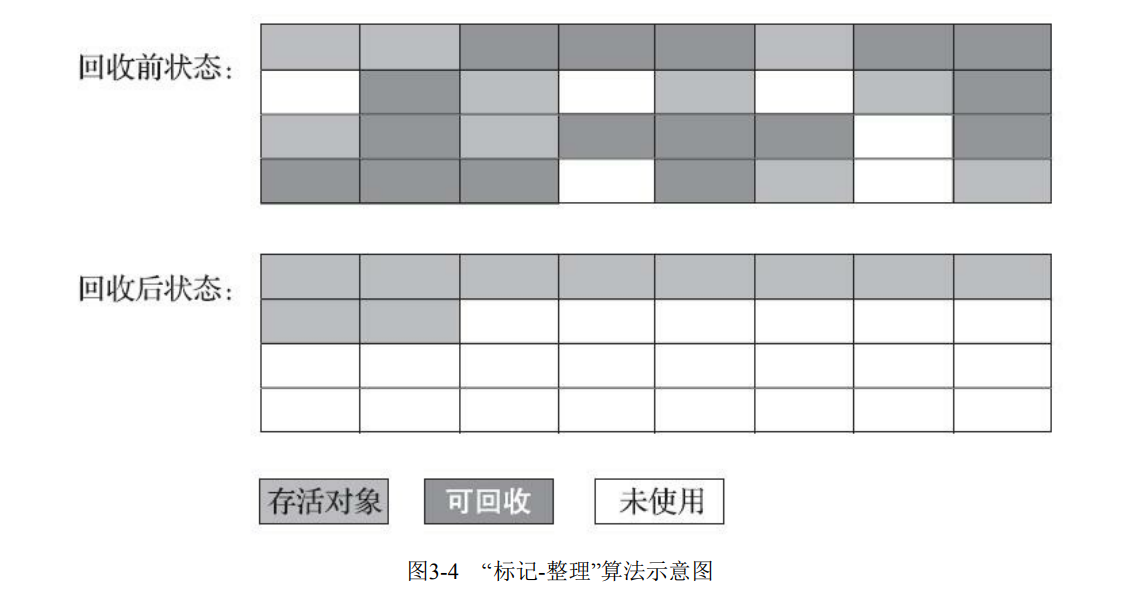
【JVM】垃圾收集算法
文章目录 分代收集理论标记-清除算法标记-复制算法标记-整理算法 分代收集理论 当前商业虚拟机的垃圾收集器,大多数都遵循了“分代收集”(Generational Collection)[1]的理论进 行设计,分代收集名为理论,实质是一套符…...
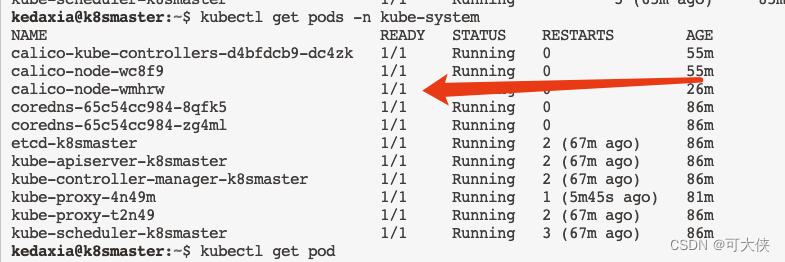
K8s的Pod出现Init:ImagePullBackOff问题的解决(以calico为例)
对于这类问题的解决思路应该都差不多,本文以calico插件安装为例,发现有个Pod的镜像没有pull成功 第一步:查看这个pod的描述信息 kubectl describe pod calico-node-wmhrw -n kube-system 从上图发现是docker拉取"calico/cni:v3.15.1&q…...
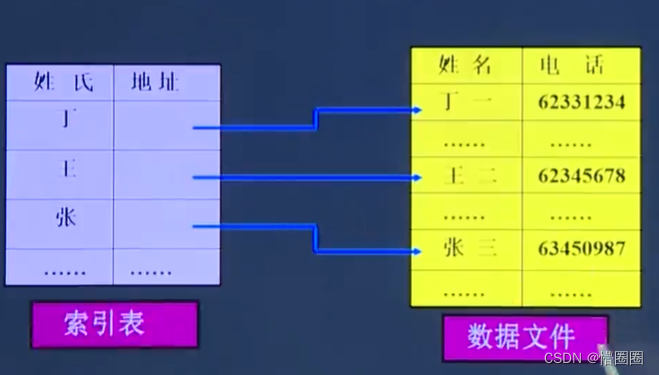
数据结构 -作用及基本概念
为什么要使用数据结构 学习数据结构是计算机科学和软件工程领域中非常重要的一门课程。以下是学习数据结构的几个重要原因: 组织和管理数据:数据结构提供了一种组织和管理数据的方式。通过学习不同的数据结构,你可以了解如何有效地存储和操作…...
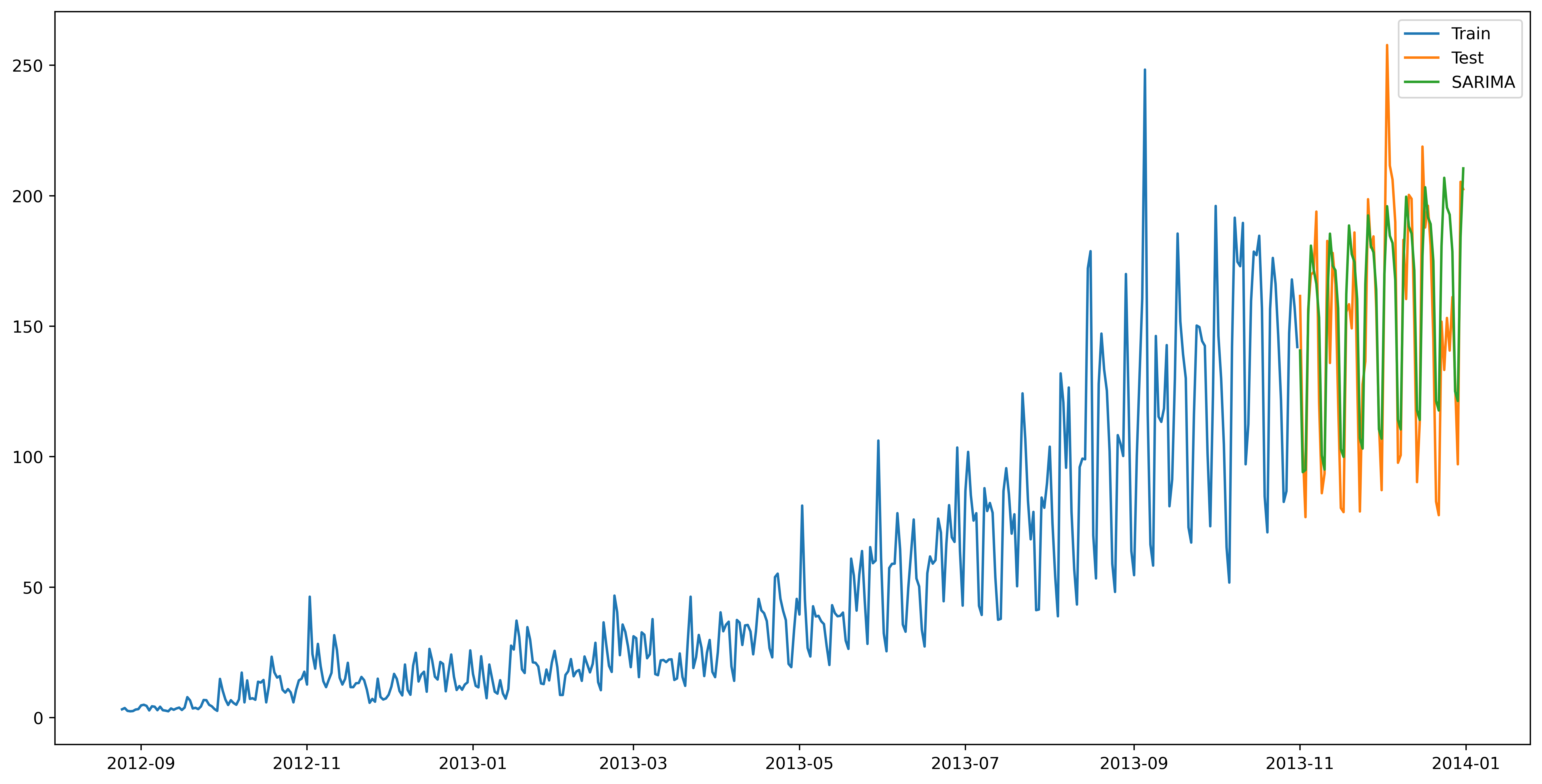
数学建模--时间序列预测模型的七种经典算法的Python实现
目录 1.开篇版权提示 2.时间序列介绍 3.项目数据处理 4.项目数据划分可视化 5.时间预测序列经典算法1:朴素法 6.时间预测序列经典算法2: 简单平均法 7.时间预测序列经典算法3:移动平均法 8.时间预测序列经典算法4:简单指…...
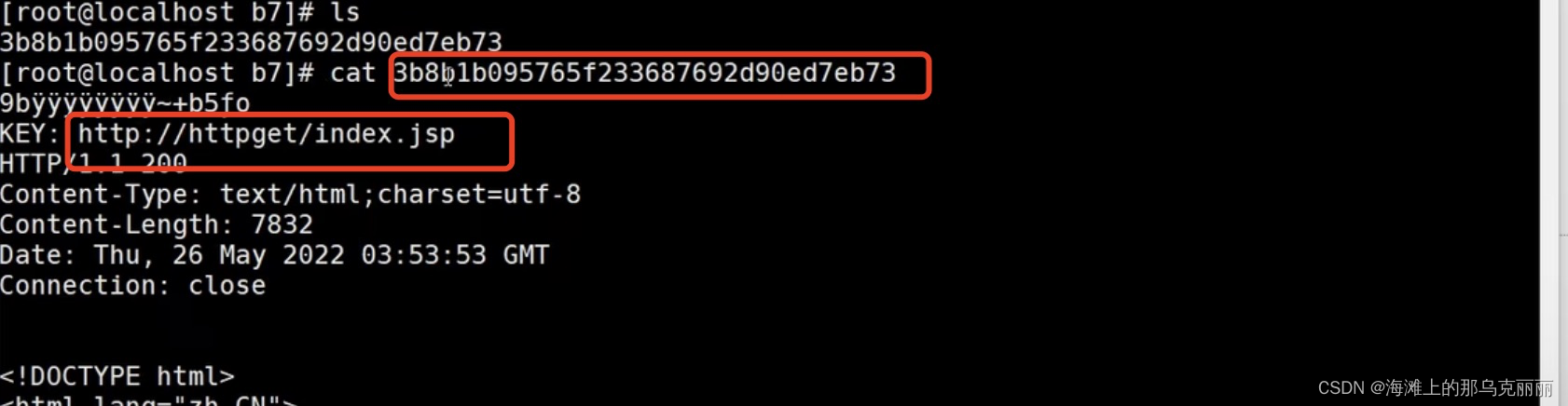
nginx-反向代理缓存
反向代理缓存相当于自动化动静分离。 将上游服务器的资源缓存到nginx本地,当下次再有相同的资源请求时,直接讲nginx缓存的资源返回给客户端。 本地缓存资源有一个过期时间,当超过过期时间,则重新向上游服务器重新请求获取资源。…...

大模型重塑区域人才培养,飞桨(重庆)人工智能教育创新中心正式启动
2023年8月22日,重庆市高校人工智能产教融合院长研讨会暨飞桨(重庆)人工智能教育创新中心启动仪式在重庆大学成功召开。会上,由百度飞桨、重庆大学组织重庆市二十一所高校共建的飞桨(重庆)人工智能教育创新中…...

CSP认证202305-1题保姆级攻略:用C++的map轻松搞定国际象棋局面去重
CSP认证202305-1题深度解析:从字符串处理到STL高效去重 国际象棋对局中的局面重复判定是一个经典的字符串处理问题,也是CSP认证考试中常见的题型。这道题看似简单,却蕴含了算法选择与数据结构应用的核心思想。本文将带您从题目分析、解法对比…...

电脑突然‘哑巴’了?保姆级排查指南:从服务、驱动到系统修复,一步步搞定Win10音频问题
电脑突然‘哑巴’了?保姆级排查指南:从服务、驱动到系统修复,一步步搞定Win10音频问题 右下角的小喇叭突然打上红叉,视频会议开到一半突然失声,游戏打到关键处却没了音效——这些场景恐怕每个Windows 10用户都遭遇过。…...

Taotoken API Key管理功能实现团队权限与访问控制
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken API Key管理功能实现团队权限与访问控制 在团队协作开发或项目管理中,如何安全、可控地分发大模型调用资源是…...

Bilibili视频转文字完整指南:一键将B站视频转为可编辑文字稿
Bilibili视频转文字完整指南:一键将B站视频转为可编辑文字稿 【免费下载链接】bili2text Bilibili视频转文字,一步到位,输入链接即可使用 项目地址: https://gitcode.com/gh_mirrors/bi/bili2text 你是否曾为观看Bilibili视频时需要做…...

GIFT高级技巧:图像组合、并行处理和性能优化的终极指南
GIFT高级技巧:图像组合、并行处理和性能优化的终极指南 【免费下载链接】gift Go Image Filtering Toolkit 项目地址: https://gitcode.com/gh_mirrors/gi/gift GIFT(Go Image Filtering Toolkit)是一个强大的Go语言图像处理库&#x…...

Lawnicons入门教程:从下载安装到启用主题化图标的完整流程
Lawnicons入门教程:从下载安装到启用主题化图标的完整流程 【免费下载链接】lawnicons Monochrome outlined brand icons for Android launchers. 项目地址: https://gitcode.com/gh_mirrors/la/lawnicons Lawnicons是一款由Lawnchair团队开发并由社区支持的…...

开发智能客服系统时利用 Taotoken 实现模型降级与容灾路由的策略
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 开发智能客服系统时利用 Taotoken 实现模型降级与容灾路由的策略 在构建面向真实用户的智能客服系统时,服务的连续性与…...

auditd:Linux 系统审计日志,记录谁动了你的服务器
auditd:Linux 系统审计日志,记录谁动了你的服务器 服务器被入侵后,管理员面临的第一个问题往往不是"怎么修复",而是"到底发生了什么"——攻击者登录了哪个账号?修改了哪些文件?执行了什…...

怎么远程操作另一台手机 手机能远程控制别的手机吗
想远程操作另一台手机应急?不管是忘带工作机需回复客户消息,还是手游玩家用备用机远程控制主力机挂机领福利,都需要好用的工具。市面上能远程操作另一台手机的软件不少,但是却多有短板,难以适配需求。推荐无界趣连2.0&…...
)
从C++代码到机器指令:用OD和IDA手把手拆解一个简单的main函数(附寄存器图解)
从C代码到机器指令:用OD和IDA手把手拆解一个简单的main函数(附寄存器图解) 在逆向工程的世界里,理解高级语言如何转化为底层机器指令是一项基础而关键的技能。本文将以一个最简单的C main 函数为例,带你一步步追踪其从…...