redis 数据结构(二)
整数集合
整数集合是 Set 对象的底层实现之一。当一个 Set 对象只包含整数值元素,并且元素数量不时,就会使用整数集这个数据结构作为底层实现。
整数集合结构设计
整数集合本质上是一块连续内存空间,它的结构定义如下:
typedef struct intset {//编码方式uint32_t encoding;//集合包含的元素数量uint32_t length;//保存元素的数组int8_t contents[];
} intset;
可以看到,保存元素的容器是一个 contents 数组,虽然 contents 被声明为 int8_t 类型的数组,但是实际上 contents 数组并不保存任何 int8_t 类型的元素,contents 数组的真正类型取决于 intset 结构体里的 encoding 属性的值。比如:
-
如果 encoding 属性值为 INTSET_ENC_INT16,那么 contents 就是一个 int16_t 类型的数组,数组中每一个元素的类型都是 int16_t;
-
如果 encoding 属性值为 INTSET_ENC_INT32,那么 contents 就是一个 int32_t 类型的数组,数组中每一个元素的类型都是 int32_t;
-
如果 encoding 属性值为 INTSET_ENC_INT64,那么 contents 就是一个 int64_t 类型的数组,数组中每一个元素的类型都是 int64_t;
不同类型的 contents 数组,意味着数组的大小也会不同。
整数集合的升级操作
整数集合会有一个升级规则,就是当我们将一个新元素加入到整数集合里面,如果新元素的类型(int32_t)比整数集合现有所有元素的类型(int16_t)都要长时,整数集合需要先进行升级,也就是按新元素的类型(int32_t)扩展 contents 数组的空间大小,然后才能将新元素加入到整数集合里,当然升级的过程中,也要维持整数集合的有序性。
整数集合升级的过程不会重新分配一个新类型的数组,而是在原本的数组上扩展空间,然后在将每个元素按间隔类型大小分割,如果 encoding 属性值为 INTSET_ENC_INT16,则每个元素的间隔就是 16 位。
举个例子,假设有一个整数集合里有 3 个类型为 int16_t 的元素。
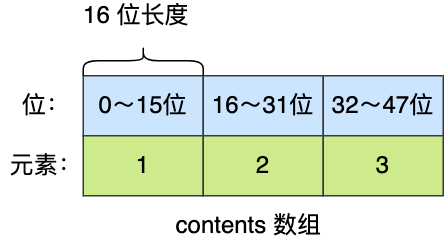
现在,往这个整数集合中加入一个新元素 65535,这个新元素需要用 int32_t 类型来保存,所以整数集合要进行升级操作,首先需要为 contents 数组扩容,在原本空间的大小之上再扩容多 80 位(4x32-3x16=80),这样就能保存下 4 个类型为 int32_t 的元素。

扩容完 contents 数组空间大小后,需要将之前的三个元素转换为 int32_t 类型,并将转换后的元素放置到正确的位上面,并且需要维持底层数组的有序性不变,整个转换过程如下:
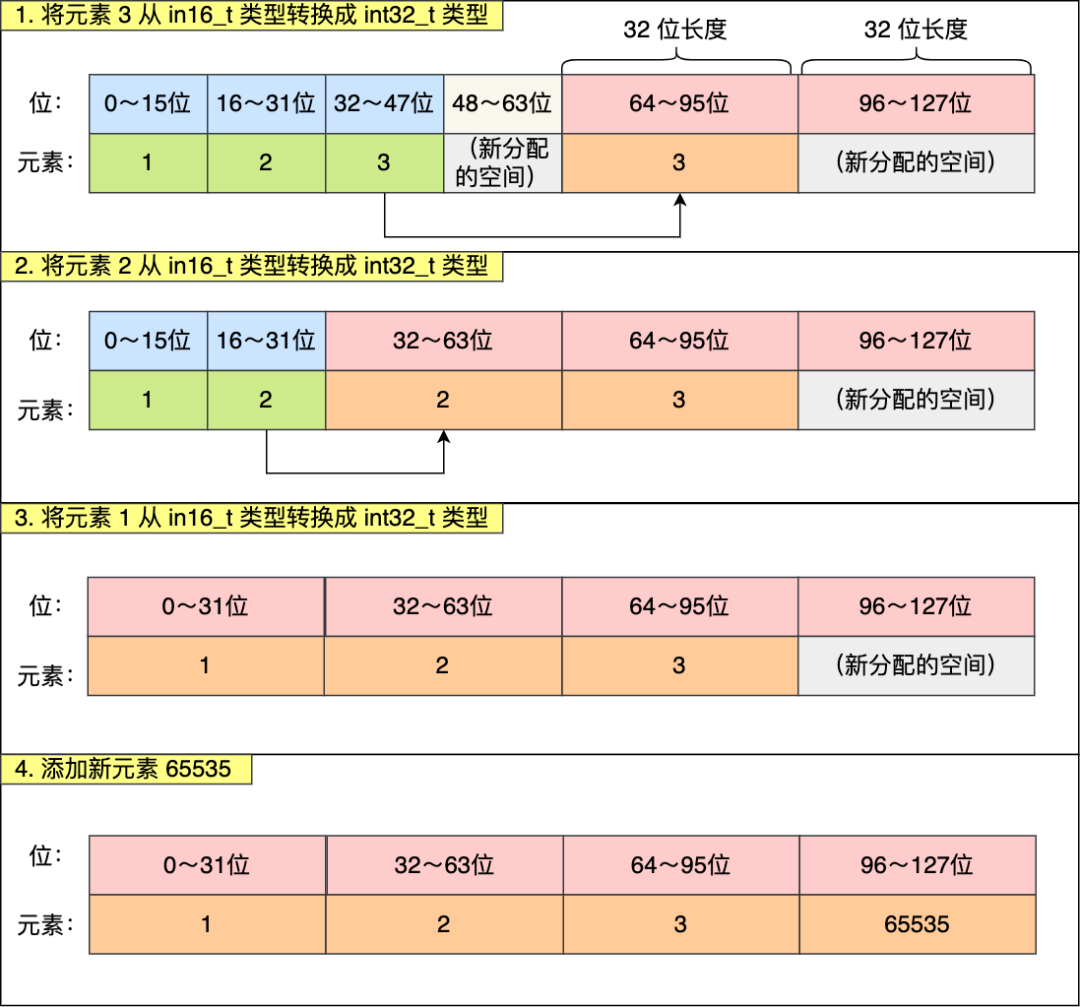
整数集合升级有什么好处呢?
如果要让一个数组同时保存 int16_t、int32_t、int64_t 类型的元素,最简单做法就是直接使用 int64_t 类型的数组。不过这样的话,当如果元素都是 int16_t 类型的,就会造成内存浪费的情况。
整数集合升级就能避免这种情况,如果一直向整数集合添加 int16_t 类型的元素,那么整数集合的底层实现就一直是用 int16_t 类型的数组,只有在我们要将 int32_t 类型或 int64_t 类型的元素添加到集合时,才会对数组进行升级操作。
因此,整数集合升级的好处是节省内存资源。
整数集合支持降级操作吗?
不支持降级操作,一旦对数组进行了升级,就会一直保持升级后的状态。比如前面的升级操作的例子,如果删除了 65535 元素,整数集合的数组还是 int32_t 类型的,并不会因此降级为 int16_t 类型。
跳表
Redis 只有在 Zset 对象的底层实现用到了跳表,跳表的优势是能支持平均 O(logN) 复杂度的节点查找。
Zset 对象是唯一一个同时使用了两个数据结构来实现的 Redis 对象,这两个数据结构一个是跳表,一个是哈希表。这样的好处是既能进行高效的范围查询,也能进行高效单点查询。
typedef struct zset {dict *dict;zskiplist *zsl;
} zset;
Zset 对象能支持范围查询(如 ZRANGEBYSCORE 操作),这是因为它的数据结构设计采用了跳表,而又能以常数复杂度获取元素权重(如 ZSCORE 操作),这是因为它同时采用了哈希表进行索引。
跳表结构设计
链表在查找元素的时候,因为需要逐一查找,所以查询效率非常低,时间复杂度是O(N),于是就出现了跳表。跳表是在链表基础上改进过来的,实现了一种「多层」的有序链表,这样的好处是能快读定位数据。
那跳表长什么样呢?我这里举个例子,下图展示了一个层级为 3 的跳表。
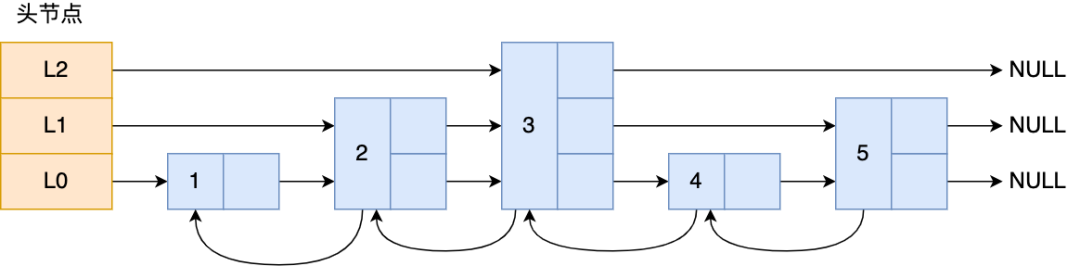
图中头节点有 L0~L2 三个头指针,分别指向了不同层级的节点,然后每个层级的节点都通过指针连接起来:
-
L0 层级共有 5 个节点,分别是节点1、2、3、4、5;
-
L1 层级共有 3 个节点,分别是节点 2、3、5;
-
L2 层级只有 1 个节点,也就是节点 3 。
如果我们要在链表中查找节点 4 这个元素,只能从头开始遍历链表,需要查找 4 次,而使用了跳表后,只需要查找 2 次就能定位到节点 4,因为可以在头节点直接从 L2 层级跳到节点 3,然后再往前遍历找到节点 4。
可以看到,这个查找过程就是在多个层级上跳来跳去,最后定位到元素。当数据量很大时,跳表的查找复杂度就是 O(logN)。
那跳表节点是怎么实现多层级的呢?这就需要看「跳表节点」的数据结构了,如下:
typedef struct zskiplistNode {//Zset 对象的元素值sds ele;//元素权重值double score;//后向指针struct zskiplistNode *backward;//节点的level数组,保存每层上的前向指针和跨度struct zskiplistLevel {struct zskiplistNode *forward;unsigned long span;} level[];
} zskiplistNode;
Zset 对象要同时保存元素和元素的权重,对应到跳表节点结构里就是 sds 类型的 ele 变量和 double 类型的 score 变量。每个跳表节点都有一个后向指针,指向前一个节点,目的是为了方便从跳表的尾节点开始访问节点,这样倒序查找时很方便。
跳表是一个带有层级关系的链表,而且每一层级可以包含多个节点,每一个节点通过指针连接起来,实现这一特性就是靠跳表节点结构体中的zskiplistLevel 结构体类型的 level 数组。
level 数组中的每一个元素代表跳表的一层,也就是由 zskiplistLevel 结构体表示,比如 leve[0] 就表示第一层,leve[1] 就表示第二层。zskiplistLevel 结构体里定义了「指向下一个跳表节点的指针」和「跨度」,跨度时用来记录两个节点之间的距离。
比如,下面这张图,展示了各个节点的跨度。

第一眼看到跨度的时候,以为是遍历操作有关,实际上并没有任何关系,遍历操作只需要用前向指针就可以完成了。
跨度实际上是为了计算这个节点在跳表中的排位。具体怎么做的呢?因为跳表中的节点都是按序排列的,那么计算某个节点排位的时候,从头节点点到该结点的查询路径上,将沿途访问过的所有层的跨度累加起来,得到的结果就是目标节点在跳表中的排位。
举个例子,查找图中节点 3 在跳表中的排位,从头节点开始查找节点 3,查找的过程只经过了一个层(L3),并且层的跨度是 3,所以节点 3 在跳表中的排位是 3。
另外,图中的头节点其实也是 zskiplistNode 跳表节点,只不过头节点的后向指针、权重、元素值都会被用到,所以图中省略了这部分。
问题来了,由谁定义哪个跳表节点是头节点呢?这就介绍「跳表」结构体了,如下所示:
typedef struct zskiplist {struct zskiplistNode *header, *tail;unsigned long length;int level;
} zskiplist;
跳表结构里包含了:
-
跳表的头尾节点,便于在O(1)时间复杂度内访问跳表的头节点和尾节点;
-
跳表的长度,便于在O(1)时间复杂度获取跳表节点的数量;
-
跳表的最大层数,便于在O(1)时间复杂度获取跳表中层高最大的那个节点的层数量;
跳表节点查询过程
查找一个跳表节点的过程时,跳表会从头节点的最高层开始,逐一遍历每一层。在遍历某一层的跳表节点时,会用跳表节点中的 SDS 类型的元素和元素的权重来进行判断,共有两个判断条件:
-
如果当前节点的权重「小于」要查找的权重时,跳表就会访问该层上的下一个节点。
-
如果当前节点的权重「等于」要查找的权重时,并且当前节点的 SDS 类型数据「小于」要查找的数据时,跳表就会访问该层上的下一个节点。
如果上面两个条件都不满足,或者下一个节点为空时,跳表就会使用目前遍历到的节点的 level 数组里的下一层指针,然后沿着下一层指针继续查找,这就相当于跳到了下一层接着查找。
举个例子,下图有个 3 层级的跳表。

如果要查找「元素:abcd,权重:4」的节点,查找的过程是这样的:
-
先从头节点的最高层开始,L2 指向了「元素:abc,权重:3」节点,这个节点的权重比要查找节点的小,所以要访问该层上的下一个节点;
-
但是该层上的下一个节点是空节点,于是就会跳到「元素:abc,权重:3」节点的下一层去找,也就是 leve[1];
-
「元素:abc,权重:3」节点的 leve[1] 的下一个指针指向了「元素:abcde,权重:4」的节点,然后将其和要查找的节点比较。虽然「元素:abcde,权重:4」的节点的权重和要查找的权重相同,但是当前节点的 SDS 类型数据「大于」要查找的数据,所以会继续跳到「元素:abc,权重:3」节点的下一层去找,也就是 leve[0];
-
「元素:abc,权重:3」节点的 leve[0] 的下一个指针指向了「元素:abcd,权重:4」的节点,该节点正是要查找的节点,查询结束。
跳表节点层数设置
跳表的相邻两层的节点数量的比例会影响跳表的查询性能。
举个例子,下图的跳表,第二层的节点数量只有 1 个,而第一层的节点数量有 6 个。

这时,如果想要查询节点 6,那基本就跟链表的查询复杂度一样,就需要在第一层的节点中依次顺序查找,复杂度就是 O(N) 了。所以,为了降低查询复杂度,我们就需要维持相邻层结点数间的关系。
跳表的相邻两层的节点数量最理想的比例是 2:1,查找复杂度可以降低到 O(logN)。
下图的跳表就是,相邻两层的节点数量的比例是 2 : 1。

那怎样才能维持相邻两层的节点数量的比例为 2 : 1 呢?
如果采用新增节点或者删除节点时,来调整跳表节点以维持比例的方法的话,会带来额外的开销。
Redis 则采用一种巧妙的方法是,跳表在创建节点的时候,随机生成每个节点的层数,并没有严格维持相邻两层的节点数量比例为 2 : 1 的情况。
具体的做法是,跳表在创建节点时候,会生成范围为[0-1]的一个随机数,如果这个随机数小于 0.25(相当于概率 25%),那么层数就增加 1 层,然后继续生成下一个随机数,直到随机数的结果大于 0.25 结束,最终确定该节点的层数。
这样的做法,相当于每增加一层的概率不超过 25%,层数越高,概率越低,层高最大限制是 64。
quicklist
在 Redis 3.0 之前,List 对象的底层数据结构是双向链表或者压缩列表。然后在 Redis 3.2 的时候,List 对象的底层改由 quicklist 数据结构实现。
其实 quicklist 就是「双向链表 + 压缩列表」组合,因为一个 quicklist 就是一个链表,而链表中的每个元素又是一个压缩列表。
在前面讲压缩列表的时候,我也提到了压缩列表的不足,虽然压缩列表是通过紧凑型的内存布局节省了内存开销,但是因为它的结构设计,如果保存的元素数量增加,或者元素变大了,压缩列表会有「连锁更新」的风险,一旦发生,会造成性能下降。
quicklist 解决办法,通过控制每个链表节点中的压缩列表的大小或者元素个数,来规避连锁更新的问题。因为压缩列表元素越少或越小,连锁更新带来的影响就越小,从而提供了更好的访问性能。
quicklist 结构设计
quicklist 的结构体跟链表的结构体类似,都包含了表头和表尾,区别在于 quicklist 的节点是 quicklistNode。
typedef struct quicklist {//quicklist的链表头quicklistNode *head; //quicklist的链表头//quicklist的链表头quicklistNode *tail; //所有压缩列表中的总元素个数unsigned long count;//quicklistNodes的个数unsigned long len; ...
} quicklist;
接下来看看,quicklistNode 的结构定义:
typedef struct quicklistNode {//前一个quicklistNodestruct quicklistNode *prev; //前一个quicklistNode//下一个quicklistNodestruct quicklistNode *next; //后一个quicklistNode//quicklistNode指向的压缩列表unsigned char *zl; //压缩列表的的字节大小unsigned int sz; //压缩列表的元素个数unsigned int count : 16; //ziplist中的元素个数 ....
} quicklistNode;
可以看到,quicklistNode 结构体里包含了前一个节点和下一个节点指针,这样每个 quicklistNode 形成了一个双向链表。但是链表节点的元素不再是单纯保存元素值,而是保存了一个压缩列表,所以 quicklistNode 结构体里有个指向压缩列表的指针 *zl。
我画了一张图,方便你理解 quicklist 数据结构。
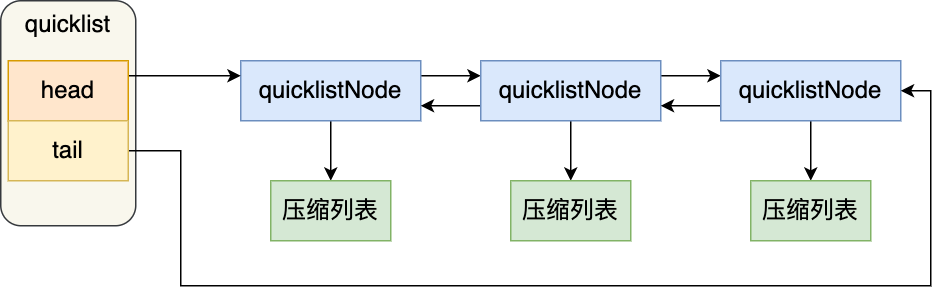
在向 quicklist 添加一个元素的时候,不会像普通的链表那样,直接新建一个链表节点。而是会检查插入位置的压缩列表是否能容纳该元素,如果能容纳就直接保存到 quicklistNode 结构里的压缩列表,如果不能容纳,才会新建一个新的 quicklistNode 结构。
quicklist 会控制 quicklistNode 结构里的压缩列表的大小或者元素个数,来规避潜在的连锁更新的风险,但是这并没有完全解决连锁更新的问题。
listpack
quicklist 虽然通过控制 quicklistNode 结构里的压缩列表的大小或者元素个数,来减少连锁更新带来的性能影响,但是并没有完全解决连锁更新的问题。
因为 quicklistNode 还是用了压缩列表来保存元素,压缩列表连锁更新的问题,来源于它的结构设计,所以要想彻底解决这个问题,需要设计一个新的数据结构。
于是,Redis 在 5.0 新设计一个数据结构叫 listpack,目的是替代压缩列表,它最大特点是 listpack 中每个节点不再包含前一个节点的长度了,压缩列表每个节点正因为需要保存前一个节点的长度字段,就会有连锁更新的隐患。
listpack 结构设计
listpack 采用了压缩列表的很多优秀的设计,比如还是用一块连续的内存空间来紧凑地保存数据,并且为了节省内存的开销,listpack 节点会采用不同的编码方式保存不同大小的数据。
我们先看看 listpack 结构:

listpack 头包含两个属性,分别记录了 listpack 总字节数和元素数量,然后 listpack 末尾也有个结尾标识。图中的 listpack entry 就是 listpack 的节点了。
每个 listpack 节点结构如下:
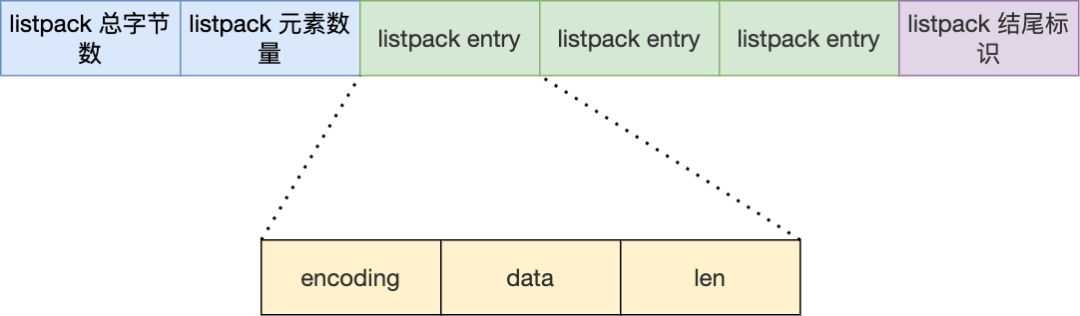
主要包含三个方面内容:
-
encoding,定义该元素的编码类型,会对不同长度的整数和字符串进行编码;
-
data,实际存放的数据;
-
len,encoding+data的总长度;
可以看到,listpack 没有压缩列表中记录前一个节点长度的字段了,listpack 只记录当前节点的长度,当我们向 listpack 加入一个新元素的时候,不会影响其他节点的长度字段的变化,从而避免了压缩列表的连锁更新问题。
相关文章:
redis 数据结构(二)
整数集合 整数集合是 Set 对象的底层实现之一。当一个 Set 对象只包含整数值元素,并且元素数量不时,就会使用整数集这个数据结构作为底层实现。 整数集合结构设计 整数集合本质上是一块连续内存空间,它的结构定义如下: typed…...
Hadoop依赖环境配置与安装部署
目录 什么是Hadoop?一、Hadoop依赖环境配置1.1 设置静态IP地址1.2 重启网络1.3 再克隆两台服务器1.4 修改主机名1.5 安装JDK1.6 配置环境变量1.7 关闭防火墙1.8 服务器之间互传资料1.9 做一个host印射1.10 免密传输 二、Hadoop安装部署2.1 解压hadoop的tar包2.2 切换…...
[C++网络协议] I/O复用
具有代表性的并发服务器端实现模型和方法: 多进程服务器:通过创建多个进程提供服务。 多路复用服务器:通过捆绑并统一管理I/O对象提供服务。✔ 多线程服务器:通过生成与客户端等量的线程提供服务。 目录 1. I/O复用 2. select函…...
3D数据导出工具HOOPS Publish:3D数据查看、生成标准PDF或HTML文档!
HOOPS中文网http://techsoft3d.evget.com/ 一、3D导出SDK HOOPS Publish是一款功能强大的SDK,可以创作丰富的工程数据并将模型文件导出为各种行业标准格式,包括PDF、STEP、JT和3MF。HOOPS Publish核心的3D数据模型是经过ISO认证的PRC格式(ISO 14739-1:…...
[羊城杯 2023] web
文章目录 D0nt pl4y g4m3!!! D0n’t pl4y g4m3!!! 打开题目,可以判断这里为php Development Server 启动的服务 查询得知,存在 PHP<7.4.21 Development Server源码泄露漏洞(参考文章) 抓包,构造payload 得到源码 class Pro{private $ex…...

Redisson—独立节点模式和集群管理工具
一、集群管理工具 Redisson集群管理工具提供了通过程序化的方式,像redis-trib.rb脚本一样方便地管理Redis集群的工具。 1、 创建集群 以下范例展示了如何创建三主三从的Redis集群。 ClusterNodes clusterNodes ClusterNodes.create() .master("127.0.0.1:…...
基于RabbitMQ的模拟消息队列之五——虚拟主机设计
文章目录 一、创建VirtualHost类二、初始化三、API1.创建交换机2.删除交换机3.创建队列4.删除队列5.创建绑定6.删除绑定7.发送消息转发规则 8.订阅消息1.消费者管理2.推送消息给消费者 3.添加一个消费者管理ConsumerManager9.确认消息 创建VirtualHost类。 1.串起内存和硬盘的数…...
Hadoop的概述与安装
Hadoop的概述与安装 一、Hadoop内部的三个核心组件1、HDFS:分布式文件存储系统2、YARN:分布式资源调度系统3、MapReduce:分布式离线计算框架4、Hadoop Common(了解即可) 二、Hadoop技术诞生的一个生态圈数据采集存储数…...
进程、线程与构造方法
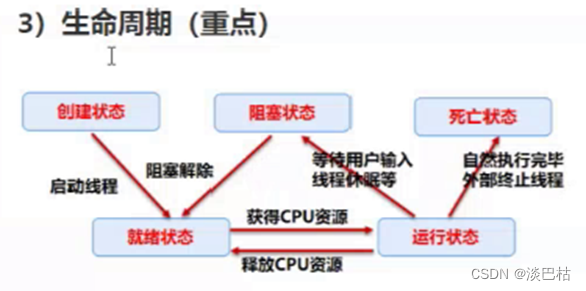
进程、线程与构造方法 目录 一. 进程与线程1. 通俗解释2. 代码实现3. 线程生命周期(图解) 二. 构造方法 一. 进程与线程 1. 通俗解释 进程:就像电脑上运行的软件,例如QQ等。 线程:…...
04 Linux补充|C/C++
目录 Linux补充 C语⾔ C语言中puts和printf的区别? Linux补充 (1)ubuntu安装ssh服务端openssh-server命令: ubuntu安装后默认只有ssh客户端,只能去连其它ssh服务器;其它客户端想要连接这个ubuntu系统,需要安装部署…...
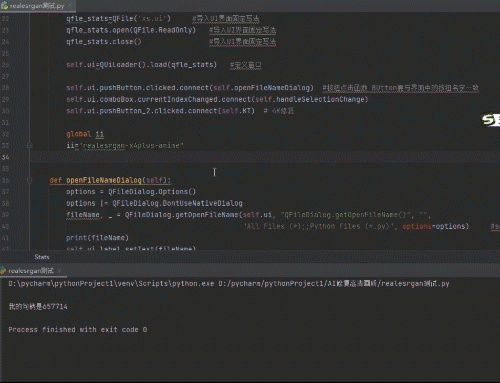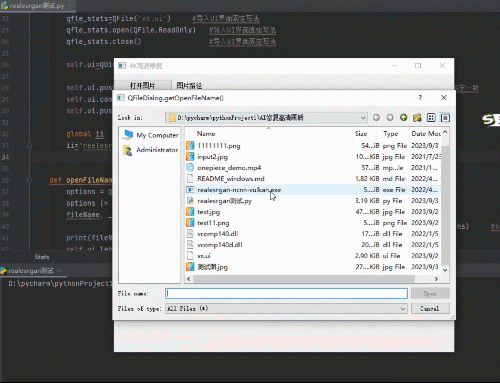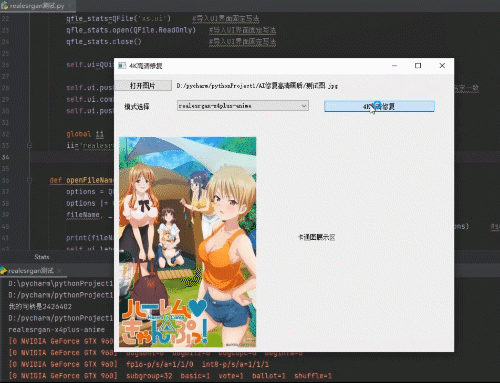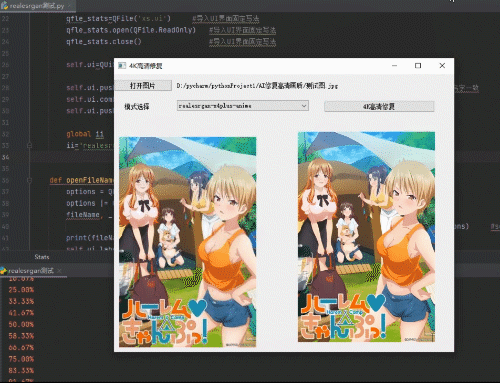
利用python制作AI图片优化工具
将模糊图片4K高清化效果如下: 优化前的图片 优化后如下图: 优化后图片变大变清晰了效果很明显 软件界面如下: 所用工具和代码: 1、所需软件包 网盘链接:https://pan.baidu.com/s/1CMvn4Y7edDTR4COfu4FviA提取码&…...

React v6(仅支持函数组件,不支持类组件)与v5版本路由使用详情和区别(详细版)
1.路由安装(默认安装最新版本6.15.0) npm i react-router-dom 2.路由模式 有常用两种路由模式可选:HashRouter 和 BrowserRouter。 ①HashRouter:URL中采用的是hash(#)部分去创建路由。 ②BrowserRouter:URL采用真实的URL资源,…...
(数字图像处理MATLAB+Python)第十二章图像编码-第一、二节:图像编码基本理论和无损编码
文章目录 一:图像编码基本理论(1)图像压缩的必要性(2)图像压缩的可能性A:编码冗余B:像素间冗余C:心理视觉冗余 (3)图像压缩方法分类A:基于编码前后…...

【Unity编辑器扩展】| 顶部菜单栏扩展 MenuItem
前言【Unity编辑器扩展】 | 顶部菜单栏扩展 MenuItem一、创建多级菜单二、创建可使用快捷键的菜单项三、调节菜单显示顺序和可选择性四、创建可被勾选的菜单项五、右键菜单扩展5.1 Hierarchy 右键菜单5.2 Project 右键菜单5.3 Inspector 组件右键菜单六、AddComponentMenu 特性…...

golang读取键盘功能按键输入
golang读取键盘功能按键输入 需求 最近业务上需要做一个终端工具,能够直接连到docker容器中进行交互。 技术选型 docker官方提供了python sdk、go sdk和remote api。 https://docs.docker.com/engine/api/sdk/ 因为我们需要提供命令行工具,因此采用g…...

用sklearn实现线性回归和岭回归
此文为ai创作,今天写文章的时候发现创作助手限时免费,想测试一下,于是就有了这篇文章,看的出来,效果还可以,一行没改。 线性回归 在sklearn中,可以使用线性回归模型做多变量回归。下面是一个示…...

结构型模式-桥接模式
用于把抽象化与实现化解耦,使得二者可以独立变化。这种类型的设计模式属于结构型模式,它通过提供抽象化和实现化之间的桥接结构,来实现二者的解耦。 这种模式涉及到一个作为桥接的接口,使得实体类的功能独立于接口实现类…...

缓存的放置时间和删除时间
缓存的放置时间和删除时间是指缓存中存储的数据的生命周期。这两个时间点非常重要,因为它们决定了缓存数据的有效期和何时应该从缓存中删除。 缓存的放置时间(Cache Put Time):这是指数据首次放入缓存的时间点。当数据被放入缓存时…...
内网穿透实战应用-如何通过内网穿透实现远程发送个人本地搭建的hMailServer的邮件服务
文章目录 1. 安装hMailServer2. 设置hMailServer3. 客户端安装添加账号4. 测试发送邮件5. 安装cpolar6. 创建公网地址7. 测试远程发送邮件8. 固定连接公网地址9. 测试固定远程地址发送邮件 hMailServer 是一个邮件服务器,通过它我们可以搭建自己的邮件服务,通过cpolar内网映射工…...
)
ensp基础命令大全(华为设备命令)
路漫漫其修远兮,吾将上下而求索 今天写一些曾经学习过的网络笔记,希望对您的学习有所帮助。 OSPF,BGP,IS-IS的命令笔记没有写上来,计划单独写,敬请期待,或者您可以在这个网站查查 : 万能查询网站 …...

SQLMesh社区贡献指南:如何参与开源项目开发
SQLMesh社区贡献指南:如何参与开源项目开发 【免费下载链接】sqlmesh Scalable and efficient data transformation framework - backwards compatible with dbt. 项目地址: https://gitcode.com/gh_mirrors/sq/sqlmesh SQLMesh是一个可扩展且高效的数据转换…...

容器编排:Docker Compose与Kubernetes的适用场景
容器编排:Docker Compose与Kubernetes的适用场景 在容器化技术蓬勃发展的今天,容器编排工具的选择直接影响着应用的部署效率、运维复杂度和系统稳定性。Docker Compose与Kubernetes作为两大主流工具,分别在单机环境与分布式集群领域展现出独特优势。本文将结合真实项目经验…...

微信聊天记录数据自救指南:WeChatMsg完全解决方案
微信聊天记录数据自救指南:WeChatMsg完全解决方案 【免费下载链接】WeChatMsg 提取微信聊天记录,将其导出成HTML、Word、CSV文档永久保存,对聊天记录进行分析生成年度聊天报告 项目地址: https://gitcode.com/GitHub_Trending/we/WeChatMsg…...

Onekey:Steam游戏清单获取的自动化解决方案
Onekey:Steam游戏清单获取的自动化解决方案 【免费下载链接】Onekey Onekey Steam Depot Manifest Downloader 项目地址: https://gitcode.com/gh_mirrors/one/Onekey 在游戏资源管理领域,获取和管理Steam游戏清单一直是一项技术门槛较高的任务。…...

如何为Windows系统安装macOS风格的高清光标主题包
如何为Windows系统安装macOS风格的高清光标主题包 【免费下载链接】macOS-cursors-for-Windows Tested in Windows 10 & 11, 4K (125%, 150%, 200%). With 2 versions, 2 types and 3 different sizes! 项目地址: https://gitcode.com/gh_mirrors/ma/macOS-cursors-for-W…...

为什么国内还没有出现网络安全巨头公司
国内坐拥广阔市场、政策持续加码,却始终没能诞生一家具备全球话语权、真正统领行业的龙头企业。看似热闹的产业图景背后,并非技术实力缺位,而是从需求逻辑、商业模式到市场生态,全链条深陷结构性困局,从根源上锁死了网…...

FastAdmin自定义Excel导入功能:从数据读取到灵活处理
1. 为什么需要自定义Excel导入功能 FastAdmin自带的Excel导入功能虽然开箱即用,但在实际项目中经常会遇到各种限制。最常见的问题就是系统强制要求Excel表头必须与数据库字段备注完全一致,这种强耦合的设计会导致三个主要痛点: 首先ÿ…...

实战演练:基于快马AI打造Ubuntu OpenClaw颜色分拣机器人应用
实战演练:基于快马AI打造Ubuntu OpenClaw颜色分拣机器人应用 最近在研究机器人抓取和分拣的应用场景,正好用InsCode(快马)平台尝试了一个OpenClaw颜色分拣机器人的项目。整个过程比我预想的要顺利很多,特别是平台提供的AI辅助功能࿰…...

【AHC】async-http-client 的请求队列是在哪里维护的?排队机制如何工作?
async-http-client 的请求队列是在哪里维护的?排队机制如何工作? 作者:九师兄 发布时间:2026年02月05日 问题引入:Flink 作业因“隐形队列”堆积导致 OOM 某日,我们负责的 实时埋点日志上报系统(基于 Flink 1.17 + async-http-client 3.0.5)突然出现 容器内存溢出(O…...

主动配电网短期负荷预测与网络重构优化分析:基于IEEE33节点的实证研究
主动配电网短期负荷预测重构 以IEEE33节点为算例,有迭代图,各个节点在重构前的电压幅值及重构前后电压幅值的对比图,优化前后网络损耗数值对比,重构优化开断支路具体情况,以及在具体某节点处接入分布式电源的容量。 有…...