数据结构与算法:Map和Set的使用
1.搜索树
1.定义
二叉搜索树又称二叉排序树,它或者是一棵空树,或者是具有以下性质的二叉树:
- 若它的左子树不为空,则左子树上所有节点的值都小于根节点的值
- 若它的右子树不为空,则右子树上所有节点的值都大于根节点的值
- 它的左右子树也分别为二叉搜索树
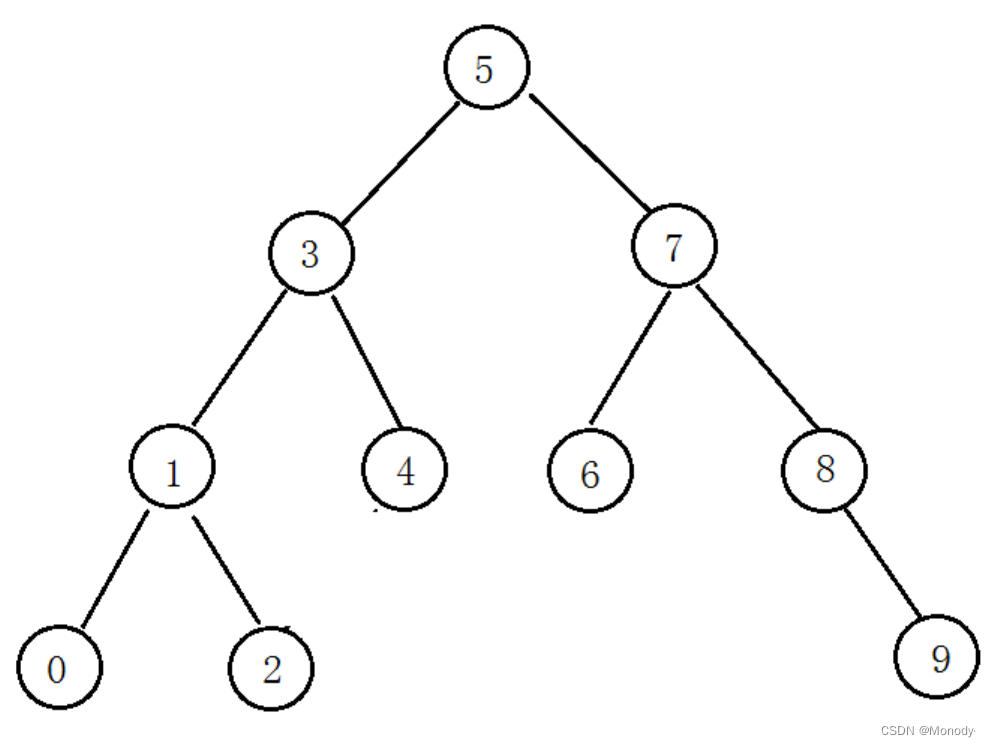
int[] array ={5,3,4,1,7,8,2,6,0,9};
2.基本操作
1.查找
查找过程:
- 拿着待查元素和根节点比较;
- 如果比根节点小,继续在左子树中查找;
- 如果比根节点大,继续在右子树中查找;
- 如果当前元素查找到null也没找到,说明该元素不存在。
2.插入
- 如果树是空树,即根== null,直接插入即可,返回true。
- 如果树不是空树,按照 查找逻辑(大的放左边,小的放右边) 确定插入位置,插入新结点。
注意:最后确定的插入位置一定是叶子节点
3.删除
设待删除结点为 cur, 待删除结点的双亲结点为 parent
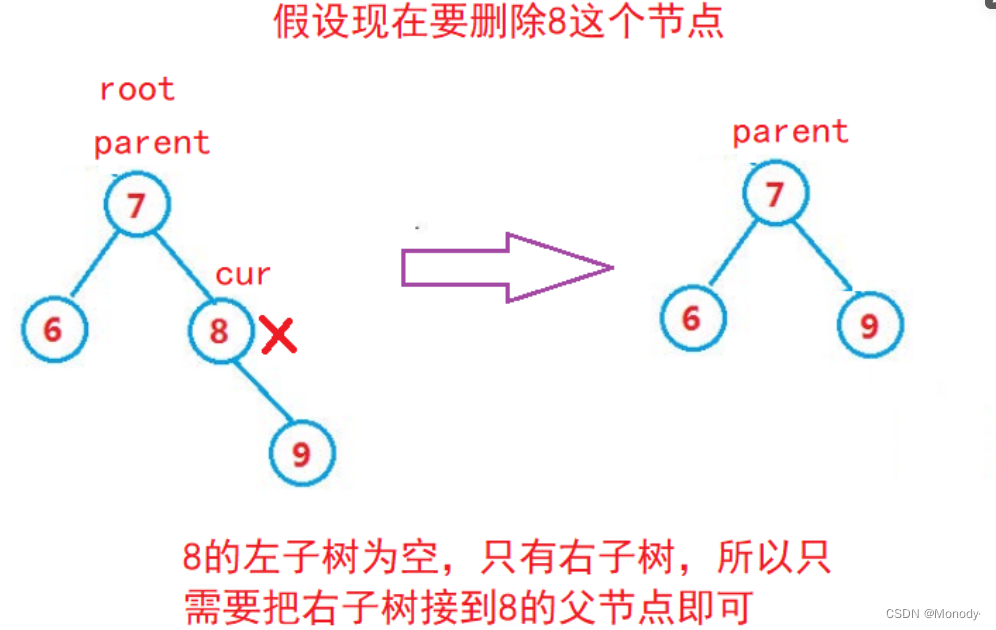
1.cur.left == null
- cur 是 root,则 root = cur.right
- cur 不是 root,cur 是 parent.left,则 parent.left = cur.right
- cur 不是 root,cur 是 parent.right,则 parent.right = cur.right
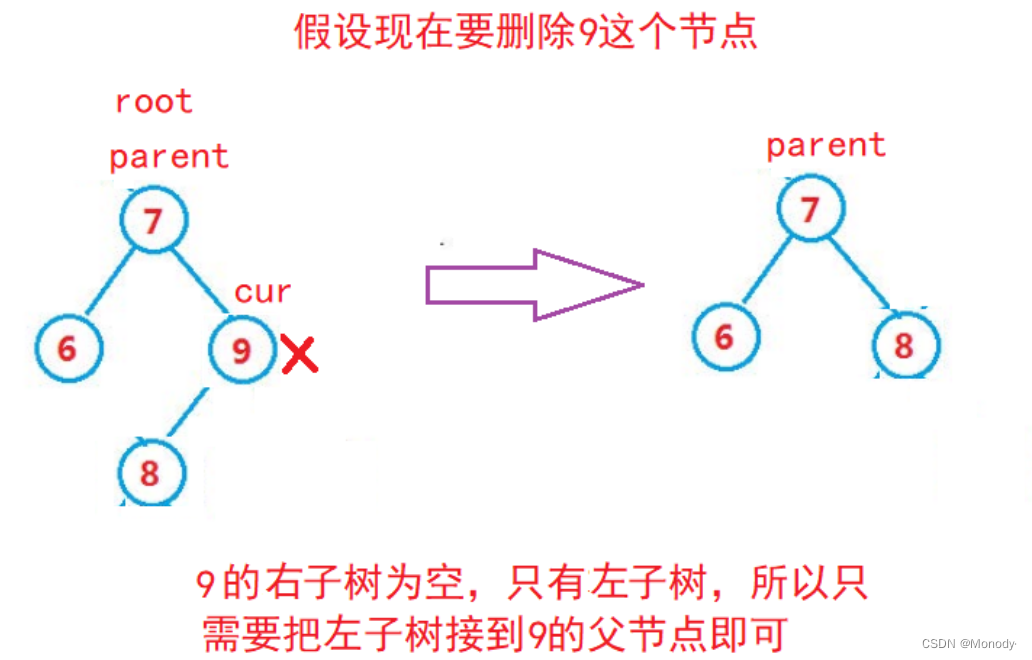
2.cur.right == null
4. cur 是 root,则 root = cur.left
5. cur 不是 root,cur 是 parent.left,则 parent.left = cur.left
6. cur 不是 root,cur 是 parent.right,则 parent.right = cur.left
3. cur.left != null && cur.right != null
需要使用替换法进行删除,即在它的右子树中寻找中序下的第一个结点(关键码最小),用它的值填补到被删除节点中,再来处理该结点的删除问题
4.代码实现
public class BinarySearchTree {static class TreeNode {public int val;public TreeNode right;public TreeNode left;public TreeNode(int val) {this.val = val;}}TreeNode root = null;/*** 查找二叉搜索树中指定的val值* @param val* @return*/public TreeNode find(int val) {TreeNode cur = root;while (cur != null) {if(cur.val > val) {cur = cur.left;}else if(cur.val < val) {cur = cur.right;}else {return cur;}}return null;}/*** 插入一个数据* @param val*/public void insert(int val) {if(root == null) {root = new TreeNode(val);return;}TreeNode cur = root;TreeNode parent = null;while (cur != null) {if (cur.val > val) {parent = cur;cur = cur.left;} else if (cur.val < val) {parent = cur;cur = cur.right;} else {return;}}TreeNode node = new TreeNode(val);if(parent.val < val) {parent.right = node;}else {parent.left = node;}}public void inorder(TreeNode root) {if(root == null) {return;}inorder(root.left);System.out.print(root.val + " ");inorder(root.right);}/*** 删除值为val的节点* @param val*/public void remove(int val) {TreeNode cur = root;TreeNode parent = null;while (cur != null) {if(cur.val == val) {removeNode(parent,cur);return;}else if(cur.val < val) {parent = cur;cur = cur.right;}else {parent = cur;cur = cur.left;}}}private void removeNode(TreeNode parent, TreeNode cur) {if(cur.left == null) {if(cur == root) {root = cur.right;}else if(parent.left == cur) {parent.left = cur.right;}else {parent.right = cur.right;}}else if(cur.right == null) {if(cur == root) {root = cur.left;}else if (parent.left == cur) {parent.left = cur.left;}else {parent.right = cur.left;}}else {TreeNode target = cur.right;TreeNode targetParent = cur;while (cur.left != null) {targetParent = target;target = target.left;}cur.val = target.val;if(target == targetParent.left) {targetParent.left = target.right;}else {targetParent.right = target.right;}}}
}
2.Map和Set的使用
1.简单介绍
Map和set是一种专门用来进行搜索的容器或者数据结构,其搜索的效率与其具体的实例化子类有关。以前常见的搜索方式有:
- 直接遍历,时间复杂度为O(N),元素如果比较多效率会非常慢。
- 二分查找,时间复杂度为 ,但搜索前必须要求序列是有序的。
上述排序比较适合静态类型的查找,即一般不会对区间进行插入和删除操作了,而现实中的查找比如:
- 根据姓名查询考试成绩。
- 通讯录,即根据姓名查询联系方式。
- 不重复集合,即需要先搜索关键字是否已经在集合中。
可能在查找时进行一些插入和删除的操作,即动态查找,那上述两种方式就不太适合了,本节介绍的Map和Set是一种适合动态查找的集合容器。
2.模型
一般把搜索的数据称为关键字(Key),和关键字对应的称为值(Value),将其称之为Key-value的键值对,所以
模型会有两种:
- 纯 key 模型,比如:
- 有一个英文词典,快速查找一个单词是否在词典中
- 快速查找某个名字在不在通讯录中
- Key-Value 模型,比如:
- 统计文件中每个单词出现的次数,统计结果是每个单词都有与其对应的次数:<单词,单词出现的次数>
- 梁山好汉的江湖绰号:每个好汉都有自己的江湖绰号
而Map中存储的就是key-value的键值对,Set中只存储了Key。
3.Map的使用
Map是一个接口类,该类没有继承自Collection,该类中存储的是<K,V>结构的键值对,并且K一定是唯一的,不能重复。
1.关于Map.Entry<K, V>的说明
Map.Entry<K, V> 是Map内部实现的用来存放<key, value>键值对映射关系的内部类,该内部类中主要提供了<key, value>的获取,value的设置以及Key的比较方式。

注意:Map.Entry<K,V>并没有提供设置Key的方法
2.Map 的常用方法说明
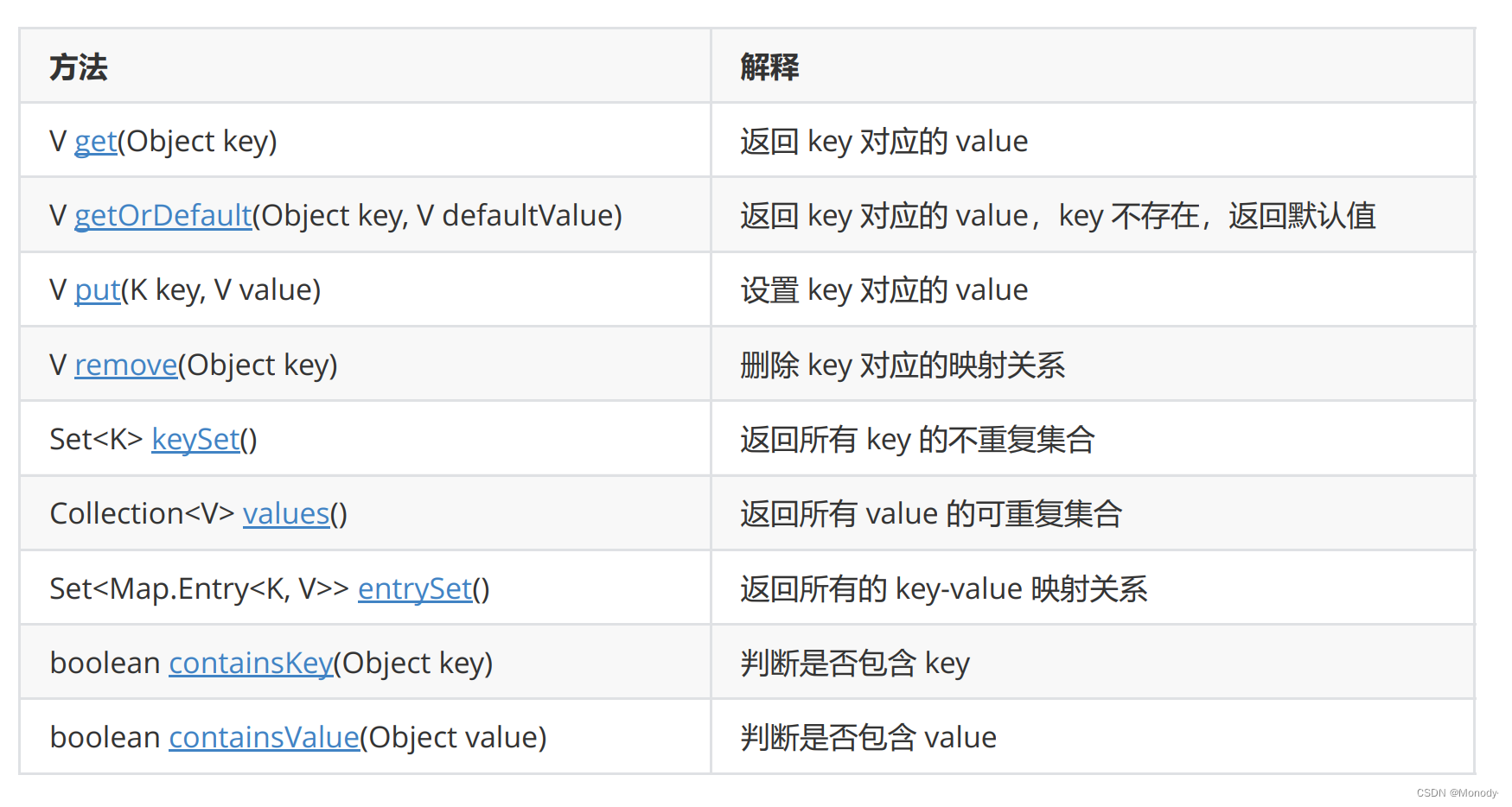
注意:
- Map是一个接口,不能直接实例化对象,如果要实例化对象只能实例化其实现类TreeMap或者HashMap。
- Map中存放键值对的Key是唯一的,value是可以重复的。
- 在TreeMap中插入键值对时,key不能为空,否则就会抛NullPointerException异常,value可以为空。但是HashMap的key和value都可以为空。
- Map中的Key可以全部分离出来,存储到Set中来进行访问(因为Key不能重复)。
- Map中的value可以全部分离出来,存储在Collection的任何一个子集合中(value可能有重复)。
- Map中键值对的Key不能直接修改,value可以修改,如果要修改key,只能先将该key删除掉,然后再来进行重新插入。
4.Set的使用
Set与Map主要的不同有两点:Set是继承自Collection的接口类,Set中只存储了Key。
1.Set的常见方法说明
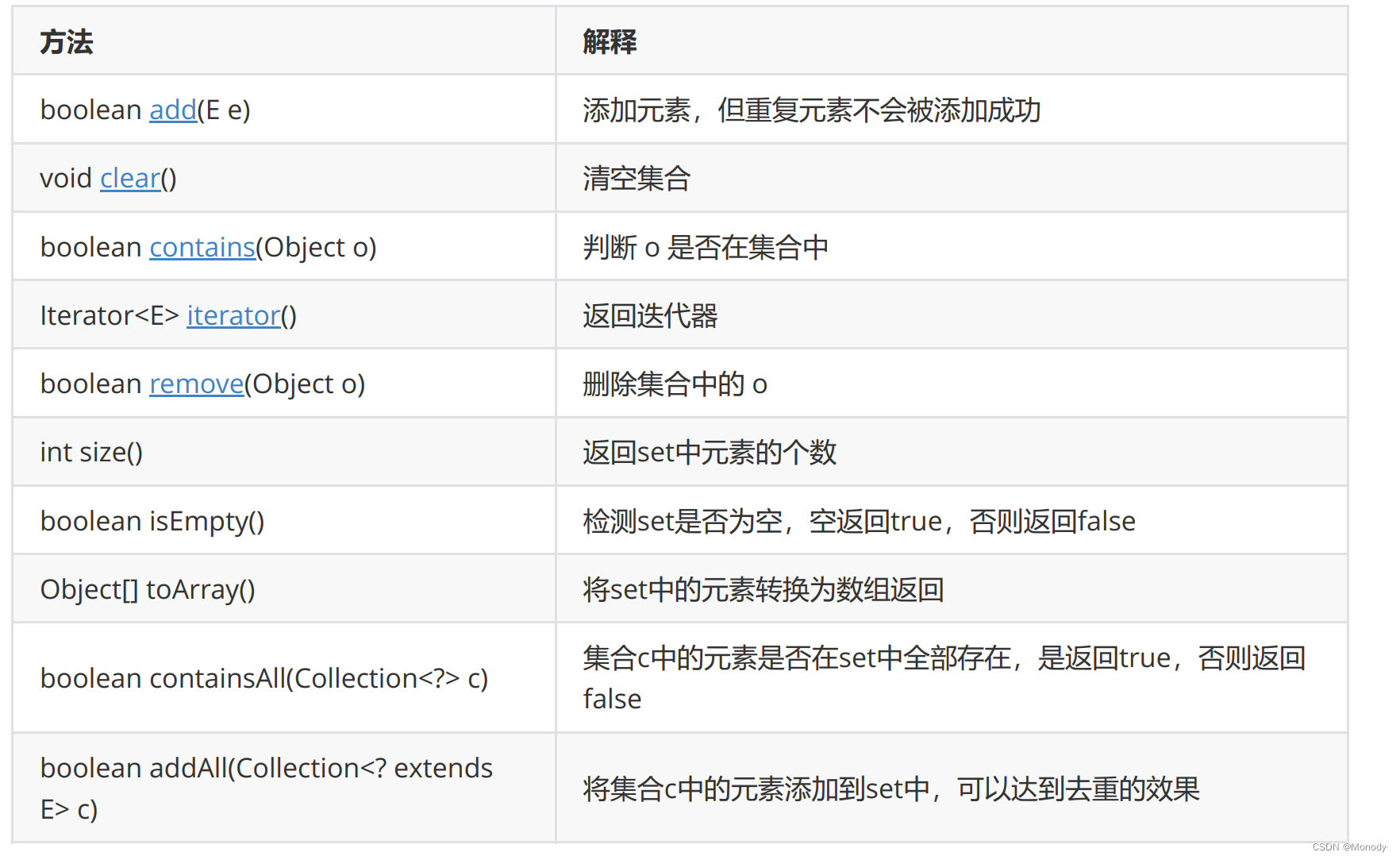
注意:
- Set是继承自Collection的一个接口类。
- Set中只存储了key,并且要求key一定要唯一。
- TreeSet的底层是使用Map来实现的,其使用key与Object的一个默认对象作为键值对插入到Map中的。
- Set最大的功能就是对集合中的元素进行去重。
- 实现Set接口的常用类有TreeSet和HashSet,还有一个LinkedHashSet,LinkedHashSet是在HashSet的基础上维护了一个双向链表来记录元素的插入次序。
- Set中的Key不能修改,如果要修改,先将原来的删除掉,然后再重新插入。
- TreeSet中不能插入null的key,HashSet可以。
3.哈希表
1.概念
顺序结构以及平衡树中,元素关键码与其存储位置之间没有对应的关系,因此在**查找一个元素时,必须要经过关键码的多次比较。顺序查找时间复杂度为O(N),平衡树中为树的高度,即O( logn),**搜索的效率取决于搜索过程中元素的比较次数。
理想的搜索方法:可以不经过任何比较,一次直接从表中得到要搜索的元素。 如果构造一种存储结构,通过某种函数(hashFunc)使元素的存储位置与它的关键码之间能够建立一一映射的关系,那么在查找时通过该函数可以很快找到该元素。
当向该结构中:
- 插入元素
根据待插入元素的关键码,以此函数计算出该元素的存储位置并按此位置进行存放
- 搜索元素
对元素的关键码进行同样的计算,把求得的函数值当做元素的存储位置,在结构中按此位置取元素比较,若关键码相等,则搜索成功
该方式即为哈希(散列)方法,哈希方法中使用的转换函数称为哈希(散列)函数,构造出来的结构称为哈希表(HashTable)(或者称散列表)
2.哈希冲突
对于两个数据元素的关键字 和 (i != j),有 != ,但有:Hash( ) == Hash( ),即:不同关键字通过相同哈希哈数计算出相同的哈希地址,该种现象称为哈希冲突或哈希碰撞。
把具有不同关键码而具有相同哈希地址的数据元素称为“同义词”.
3.哈希函数
引起哈希冲突的一个原因可能是:哈希函数设计不够合理。 哈希函数设计原则:
- 哈希函数的定义域必须包括需要存储的全部关键码,而如果散列表允许有m个地址时,其值域必须在0到m-1之间
- 哈希函数计算出来的地址能均匀分布在整个空间中
- 哈希函数应该比较简单
常见哈希函数
1. 直接定制法–(常用)
取关键字的某个线性函数为散列地址:Hash(Key)= A*Key + B 优点:简单、均匀 缺点:需要事先知道关键字的分布情况 使用场景:适合查找比较小且连续的情况 面试题:字符串中第一个只出现一次字符
2. 除留余数法–(常用)
设散列表中允许的地址数为m,取一个不大于m,但最接近或者等于m的质数p作为除数,按照哈希函数:
Hash(key) = key% p(p<=m),将关键码转换成哈希地址
3. 平方取中法–(了解)
假设关键字为1234,对它平方就是1522756,抽取中间的3位227作为哈希地址; 再比如关键字为4321,对它平方就是18671041,抽取中间的3位671(或710)作为哈希地址 平方取中法比较适合:不知道关键字的分布,而位数又不是很大的情况
4. 折叠法–(了解)
折叠法是将关键字从左到右分割成位数相等的几部分(最后一部分位数可以短些),然后将这几部分叠加求和,并按散列表表长,取后几位作为散列地址。
折叠法适合事先不需要知道关键字的分布,适合关键字位数比较多的情况
5. 随机数法–(了解)
选择一个随机函数,取关键字的随机函数值为它的哈希地址,即H(key) = random(key),其中random为随机数函数。
通常应用于关键字长度不等时采用此法
6. 数学分析法–(了解)
设有n个d位数,每一位可能有r种不同的符号,这r种不同的符号在各位上出现的频率不一定相同,可能在某些位上分布比较均匀,每种符号出现的机会均等,在某些位上分布不均匀只有某几种符号经常出现。可根据散列表的大小,选择其中各种符号分布均匀的若干位作为散列地址。
数字分析法通常适合处理关键字位数比较大的情况,如果事先知道关键字的分布且关键字的若干位分布较均匀的情况
注意:哈希函数设计的越精妙,产生哈希冲突的可能性就越低,但是无法避免哈希冲突
4.负载因子调节

负载因子和冲突率的关系粗略演示
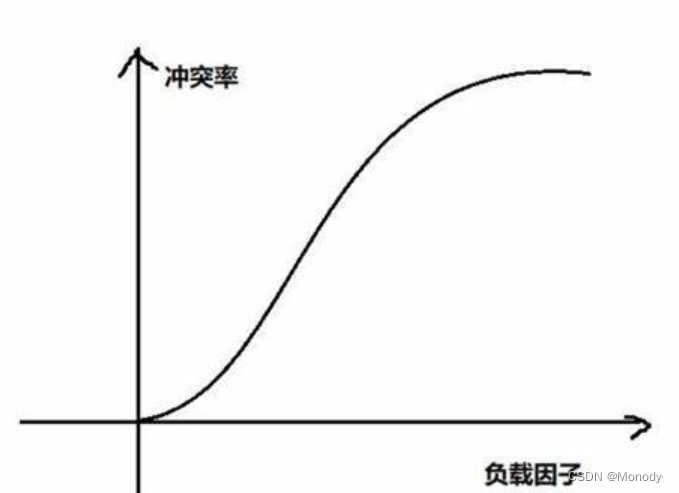
所以当冲突率达到一个无法忍受的程度时,我们需要通过降低负载因子来变相的降低冲突率。
已知哈希表中已有的关键字个数是不可变的,那我们能调整的就只有哈希表中的数组的大小。
5.解决哈希冲突两种常见的方法:闭散列和开散列
1.闭散列
闭散列:也叫开放定址法,当发生哈希冲突时,如果哈希表未被装满,说明在哈希表中必然还有空位置,那么可以把key存放到冲突位置中的“下一个” 空位置中去。那如何寻找下一个空位置呢?
1. 线性探测
比如现在需要插入元素44,先通过哈希函数计算哈希地址,下标为4,因此44理论上应该插在该位置,但是该位置已经放了值为4的元素,即发生哈希冲突。
线性探测:从发生冲突的位置开始,依次向后探测,直到寻找到下一个空位置为止。
-
插入
-
- 通过哈希函数获取待插入元素在哈希表中的位置
-
- 如果该位置中没有元素则直接插入新元素,如果该位置中有元素发生哈希冲突,使用线性探测找到下一个空位置,插入新元素
-
- 采用闭散列处理哈希冲突时,不能随便物理删除哈希表中已有的元素,若直接删除元素会影响其他元素的搜索。比如删除元素4,如果直接删除掉,44查找起来可能会受影响。因此线性探测采用标记的伪删除法来删除一个元素。
2. 二次探测
线性探测的缺陷是产生冲突的数据堆积在一块,这与其找下一个空位置有关系,因为找空位置的方式就是挨着往后逐个去找,因此二次探测为了避免该问题,找下一个空位置的方法为: = ( + )% m, 或者:= ( - )% m。其中:i = 1,2,3…, 是通过散列函数Hash(x)对元素的关键码 key 进行计算得到的位置,m是表的大小。
研究表明:当表的长度为质数且表装载因子a不超过0.5时,新的表项一定能够插入,而且任何一个位置都不会被探查两次。因此只要表中有一半的空位置,就不会存在表满的问题。在搜索时可以不考虑表装满的情况,但在插入时必须确保表的装载因子a不超过0.5,如果超出必须考虑增容。
因此:比散列最大的缺陷就是空间利用率比较低,这也是哈希的缺陷。
2.开散列
开散列法又叫链地址法(开链法),首先对关键码集合用散列函数计算散列地址,具有相同地址的关键码归于同一子集合,每一个子集合称为一个桶,各个桶中的元素通过一个单链表链接起来,各链表的头结点存储在哈希表中。
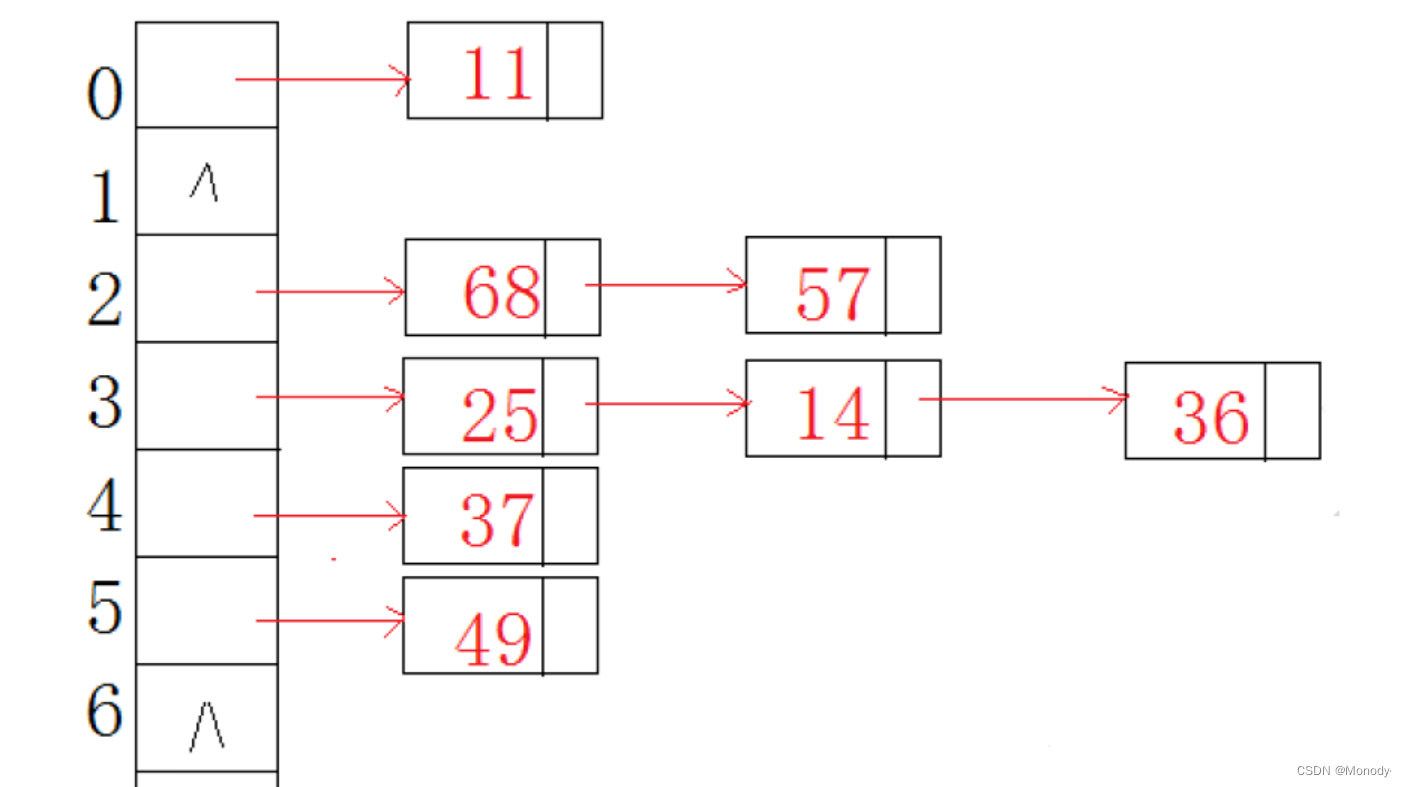
开散列,可以认为是把一个在大集合中的搜索问题转化为在小集合中做搜索了。
刚才我们提到了,哈希桶其实可以看作将大集合的搜索问题转化为小集合的搜索问题了,那如果冲突严重,就意味着小集合的搜索性能其实也时不佳的,这个时候我们就可以将这个所谓的小集合搜索问题继续进行转化,例如:
- 每个桶的背后是另一个哈希表
- 每个桶的背后是一棵搜索树
具体实现:
public class HashBuck {static class Node {public int key;public int val;public Node next;public Node(int key, int val) {this.key = key;this.val = val;}}public Node[] arr;public int usedSize;public static final double LOAD_FACTOR = 0.75;public HashBuck() {arr = new Node[10];}public void put(int key,int val) {int index = key % arr.length;Node cur = arr[index];while (cur != null) {if(cur.key == key) {cur.val = val;return;}cur = cur.next;}//采用头插法进行插入Node node = new Node(key,val);node.next = arr[index];arr[index] = node;usedSize++;if (calculateLoadFactor() >= LOAD_FACTOR) {//扩容resize();}}//如果要扩容每个元素到要进行重新的哈希计算private void resize() {Node[] newArray = new Node[2 * arr.length];for (int i = 0; i < arr.length; i++) {Node cur = arr[i];while (cur != null) {Node curNext = cur.next;int index = cur.key % newArray.length;//找到了在新的数组当中的位置cur.next = newArray[index];newArray[index] = cur;cur = curNext;}}arr = newArray;}//计算负载因子private double calculateLoadFactor() {return usedSize * 1.0 / arr.length;}public int get(int key) {int index = key % arr.length;Node cur = arr[index];while (cur != null) {if(cur.key == key) {return cur.val;}cur = cur.next;}return -1;}
}
6.性能分析
通常情况下我们认为哈希表的插入/删除/查找时间复杂度是O(1) 。
相关文章:
数据结构与算法:Map和Set的使用
1.搜索树 1.定义 二叉搜索树又称二叉排序树,它或者是一棵空树,或者是具有以下性质的二叉树: 若它的左子树不为空,则左子树上所有节点的值都小于根节点的值若它的右子树不为空,则右子树上所有节点的值都大于根节点的值它的左右子…...
C语言——动态内存管理
目录0. 思维导图:1. 为什么存在动态内存分配2. 动态内存函数介绍2.1 malloc和free2.2 calloc2.3 realloc3. 常见的动态内存错误3.1 对NULL指针的解引用操作3.2 对动态内存开辟的空间越界访问3.3 对非动态开辟内存使用free释放3.4 使用free释放一块动态开辟内存的一部…...

Docker安装Grafana
文章目录Grafana介绍拉取镜像准备相关挂载目录及文件启动容器访问测试添加 Prometheus 数据源常见问题看板配置Grafana介绍 上篇博客介绍了prometheus的安装: Docker部署Prometheus 在获取应用或基础设施运行状态、资源使用情况,以及服务运行状态等直观…...
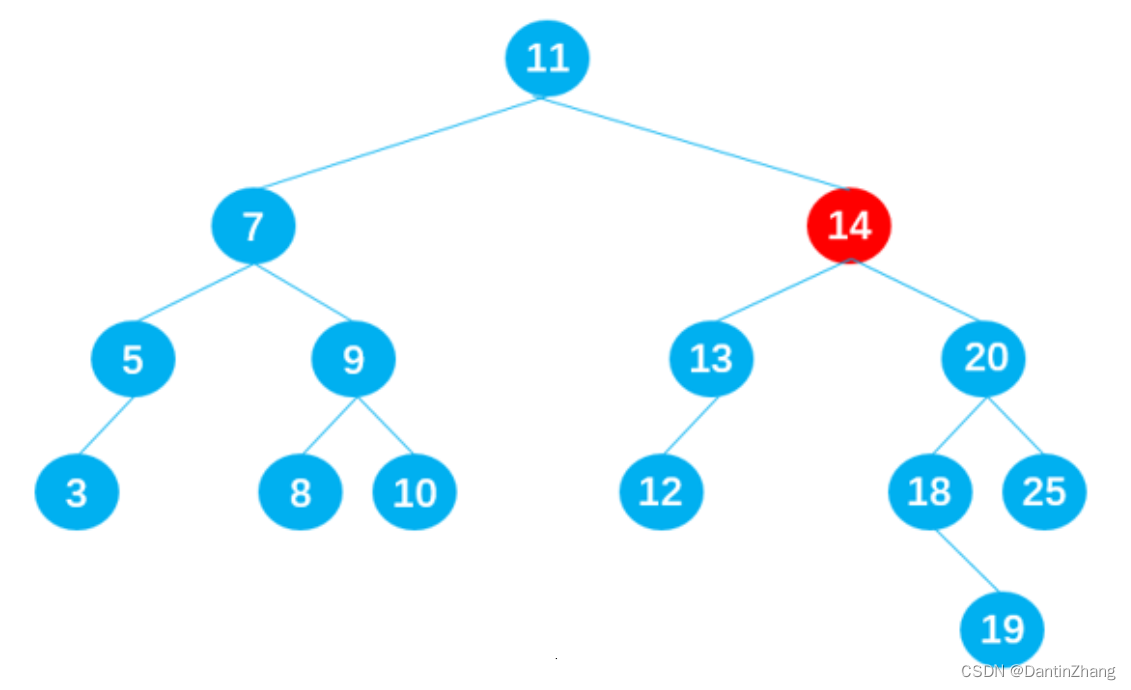
数据结构(四):树、二叉树、二叉搜索树
数据结构(四)一、树1.树结构2.树的常用术语二、二叉树1.什么是二叉树2.二叉树的数据存储(1)使用数组存储(2)使用链表存储三、二叉搜索树1.这是什么东西2.封装二叉搜索树:结构搭建3. insert插入节…...
)
040、动态规划基本技巧(labuladong)
动态规划基本技巧 一、动态规划解题套路框架 基于labuladong的算法网站,动态规划解题套路框架; 1、基本介绍 基本套路框架: 动态规划问题的一般形式是求最值;核心如下: 穷举;明确base case;…...

html笔记(一)
一、html简介 什么是HTML? Hyper Text Markup Language 超文本标记语言 超文本?超级文本,例如流媒体,声音、视频、图片等。 标记语言?这种语言是由大量的标签组成。 任何一个标签都有开始标签和结束标签&…...

索引的情况
select * from A left join B on A.c B.c where A.employee_id 3 1.一句sql中 是可能走多次索引的,具体的 一般 表连接 ,或者说生成临时表的时候,会走索引 然后条件过滤的时候也会走索引,具体的 还是要具体分析 2.表连接 字段…...
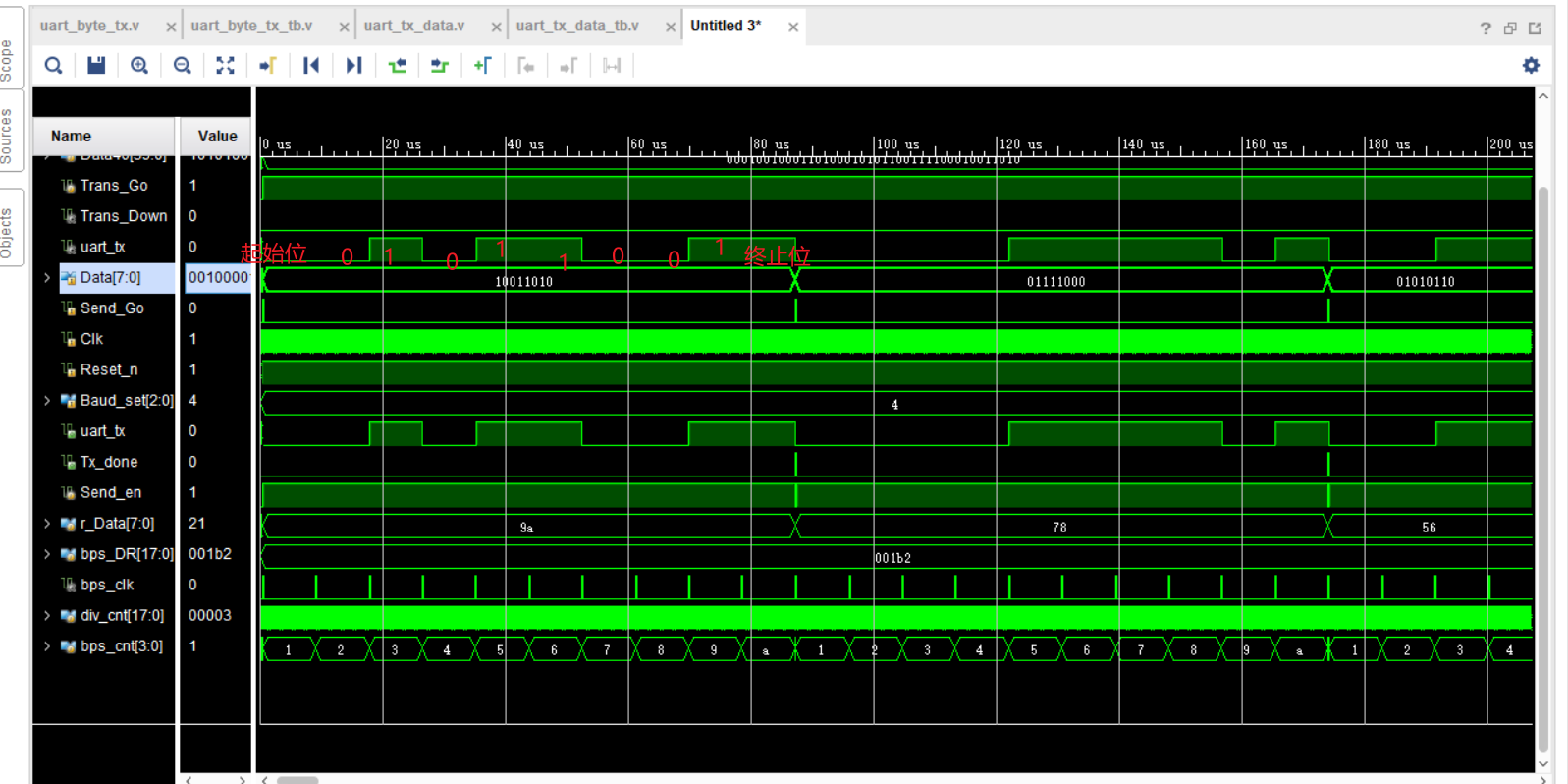
Verilog 学习第五节(串口发送部分)
小梅哥串口部分学习part1 串口通信发送原理串口通信发送的Verilog设计与调试串口发送应用之发送数据串口发送应用之采用状态机实现多字节数据发送串口通信发送原理 1:串口通信模块设计的目的是用来发送数据的,因此需要有一个数据输入端口 2:…...

破解遗留系统快速重构的5步心法(附实例)
前两天和一个架构师朋友闲聊,说到了 「重构」 这个话题,他们公司早年间上线的项目系统,因一直没专人在演进过程中为代码质量负责,导致现在代码越来越混乱,逐渐堆积成“屎山”,目前的维护成本已远高于重新开…...
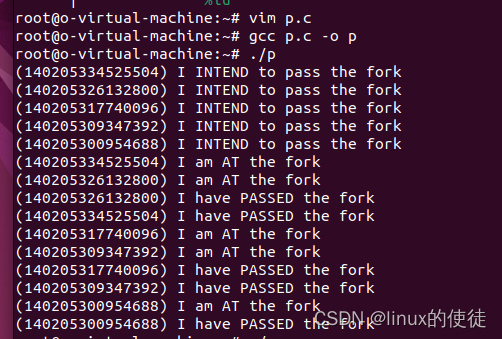
信号量(上)实验
实验1:解决订票终端的临界区管理 订票终端是解决冲突问题,所以信号量的值是1 #include <stdio.h> #include <pthread.h> #include <unistd.h> #include <semaphore.h> int ticketAmout 2; // 票的数量: 全局变量 sem_t mutex…...
阿里5年,一个女工对软件测试的理解
成为一个优秀的测试工程师需要具备哪些知识和经验? 针对这个问题,可以直接拆分以下三个小问题来详细说明: 1、优秀软件测试工程师的标准是什么? 2、一个合格的测试工程师需要具备哪些专业知识? 3、一个合格的测试工程…...

前端练习项目
30 Web Projects 30 多个带有 HTML、CSS 和 JavaScript 的 Web 项目,由 Packt Publishing 提供 https://github.com/PacktPublishing/30-Web-Projects-with-HTML-CSS-and-JavaScript Small projects https://github.com/WebDevVikramChoudhary/small_projects_for_…...

sql复习(set运算符、高级子查询)
一、set运算符 union:得到两个查询结果的并集,并且⾃动去掉重复⾏。不会排序 union all:得到两个查询结果的并集,不会去掉重复⾏。也不会排序 intersect:得到两个查询结果的交集,并且按照结果集的第⼀个列进…...

整车电源的几种模式:OFF/ACC/RUN/CRANK
本文框架1.前言2. 四种电源模式2.1 OFF模式2.2 ACC模式2.3 ON模式2.4 CRANK模式3. KL15/KL301.前言 在诊断或者网络管理相关模块开发对客户的需求进行梳理时,经常会看到客户对不同车辆模式下处理策略的需求,如果前期没接触过这几种模式,可能…...

踩了大坑:wordpress后台 无法将上传的文件移动至wp-content
一、问题描述 今天迁移了wordpress站点至新服务器,结果上传图片出现“无法将上传的文件移动至wp-content/uploads”的提示,这是怎么回事,为什么会这样。 报错如下: 2023/02/20 08:57:48 [error] 9861#9861: *79624 FastCGI sen…...

page cache设计及实现
你好,我是安然无虞。 page cache的设计及实现 page cache 本质上也是一个哈希桶, 它是按照页的数量进行映射的. 当 central cache 向 page cache 申请内存时, page cache 先检查对应位置是否有span, 如果没有则向更大页去寻找一个span, 如果找到则分裂成两个. 比如…...
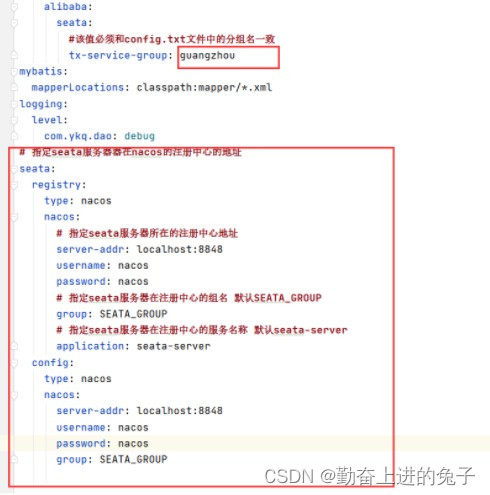
使用seata来解决分布式事务
文章目录 目录 文章目录 前言 一、Seata的执行流程如下 二、使用步骤 三、配置微服务客户端 总结 前言 Seata部署指南 Seata 是一款开源的分布式事务解决方案,致力于提供高性能和简单易用的分布式事务服务。Seata 将为用户提供了 AT、TCC、SAGA 和 XA 事务模…...

推荐一款新的自动化测试框架:DrissionPage
今天给大家推荐一款基于Python的网页自动化工具:DrissionPage。这款工具既能控制浏览器,也能收发数据包,甚至能把两者合而为一,简单来说:集合了WEB浏览器自动化的便利性和 requests 的高效率。 一、DrissionPage产生背…...

MQ系列面试
先来说说什么是MQ,MQ与多线程之间的区别MQ是消息中间件 可以实现异步 多线程也可以实现异步使用传统http协议方式调用接口存在的缺点如果服务器端没有及时的响应给客户端的时候,容易造成客户端阻塞等待。服务器响应超时 客户端发送重试机制 需要考虑避免…...

一句话设计模式2:原型模式
原型模式:每次得到一个新对象。 文章目录 原型模式:每次得到一个新对象。前言一、原型模式和new的区别二、如何实现原型模式1. 什么clone接口2. 开始使用,并验证浅clone效果3. 深度clone(也就是address也要复制一份)总结前言 原型模式可以说是目前接触的设计模式中,比较无用的…...

T型翼/尾板导向的穿浪双体船姿态控制【附代码】
✨ 长期致力于穿浪双体船、T型翼、尾板、多自由度姿态控制、舒适性评估研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,点击《获取方式》 (1)动态水翼升力模型与耦合运动方…...

基于双T振荡器的正弦波LED调光电路设计与实践
1. 项目概述:用双T振荡器实现正弦波LED调光最近在捣鼓一些氛围灯项目,总感觉用单片机PWM做的呼吸灯效果有点“硬”,那种线性的明暗变化看久了难免审美疲劳。于是翻出以前模拟电路的老本行,琢磨着能不能用纯硬件的方式,…...

如何在3分钟内为任何活动搭建专业级滚动抽奖系统?Magpie-LuckyDraw全平台开源方案深度解析
如何在3分钟内为任何活动搭建专业级滚动抽奖系统?Magpie-LuckyDraw全平台开源方案深度解析 【免费下载链接】Magpie-LuckyDraw 🏅A fancy lucky-draw tool supporting multiple platforms💻(Mac/Linux/Windows/Web/Docker) 项目地址: https…...

3分钟掌握JetBrains IDE试用期重置:终极完整指南
3分钟掌握JetBrains IDE试用期重置:终极完整指南 【免费下载链接】ide-eval-resetter 项目地址: https://gitcode.com/gh_mirrors/id/ide-eval-resetter JetBrains IDE试用期重置工具(ide-eval-resetter)是一个开源项目,专…...

别再只比参数了!从插件生态到中文优化,聊聊ChatGPT和文心一言的“隐形”差异
超越参数之争:ChatGPT与文心一言的生态与本土化实战解析 当技术评测文章还在反复比较模型参数量与发布时间时,真正影响日常工作效率的往往是那些未被量化的"软实力"。本文将从插件生态构建与中文场景优化两个维度,带您重新认识这两…...

UE4SS终极指南:从零开始掌握虚幻引擎脚本系统
UE4SS终极指南:从零开始掌握虚幻引擎脚本系统 【免费下载链接】RE-UE4SS Injectable LUA scripting system, SDK generator, live property editor and other dumping utilities for UE4/5 games 项目地址: https://gitcode.com/gh_mirrors/re/RE-UE4SS UE4S…...

深度解析:JetBrains IDE试用期重置机制的技术实现
深度解析:JetBrains IDE试用期重置机制的技术实现 【免费下载链接】ide-eval-resetter 项目地址: https://gitcode.com/gh_mirrors/id/ide-eval-resetter 在软件开发工作流中,JetBrains IDE试用期管理是一个常见的技术挑战,尤其是在多…...

模拟电路实现自主循线机器人:无MCU的硬件逻辑设计
1. 项目概述:用最纯粹的模拟电路,造一台会“思考”的机器人每次看到那些在赛道上灵巧穿梭的循线小车,你是不是也手痒,想自己动手做一个?但一听到“单片机”、“编程”、“Arduino”这些词,又觉得门槛太高&a…...

红外信号逆向工程:破解电磁炉协议实现抽油烟机智能联动
1. 项目概述:当电磁炉与抽油烟机“对话”厨房里的自动化,听起来像是未来智能家居的专属,但其实很多乐趣和便利就藏在身边已有的设备里。我最近给家里的厨房换上了一台新的电磁炉,在翻阅说明书时,偶然发现了一个名为“h…...

Unity动态植被系统:实时天气与自然现象耦合方案
1. 这不是“贴图堆砌”,而是一套可交互的自然系统你有没有试过在Unity里拖进几棵树、铺点草地,结果运行起来——风一吹,所有树叶像被钉在空中一样纹丝不动;下雨时,雨滴垂直砸进地面,连个水花都没有…...