使用 Hue 玩转 Amazon EMR(SparkSQL, Phoenix) 和 Amazon Redshift
现状
Apache Hue 是一个基于 Web 的交互式 SQL 助手,通过它可以帮助大数据从业人员(数仓工程师,数据分析师等)与数据仓库进行 SQL 交互。在 Amazon EMR 集群启动时,通过勾选 Hue 进行安装。在 Hue 启用以后,将原先需要登录主节点进行 SQL 编写及提交的工作转移到 web 前端,不仅方便统一管理日常开发需求,而且保证了集群的接入安全性。另一方面 Hue 自己独特的优势可以使用 SparkSQL 进行 Spark 任务的远程提交,相比于额外为 Amazon EMR 集群配置 Hive on Spark,或者使用代码进行 Livy 远程提交这两种方式而言,大大的提升了开发和运维效率。本文也介绍了如何通过 Hue 整合 Amazon Redshift 数仓, 以及远程提交 Phoenix 任务同 HBase 交互,将 Hue 打造为数据仓库的统一 SQL 访问平台。
| 亚马逊云科技开发者社区为开发者们提供全球的开发技术资源。这里有技术文档、开发案例、技术专栏、培训视频、活动与竞赛等。帮助中国开发者对接世界最前沿技术,观点,和项目,并将中国优秀开发者或技术推荐给全球云社区。如果你还没有关注/收藏,看到这里请一定不要匆匆划过,点这里让它成为你的技术宝库! |
方案架构总览
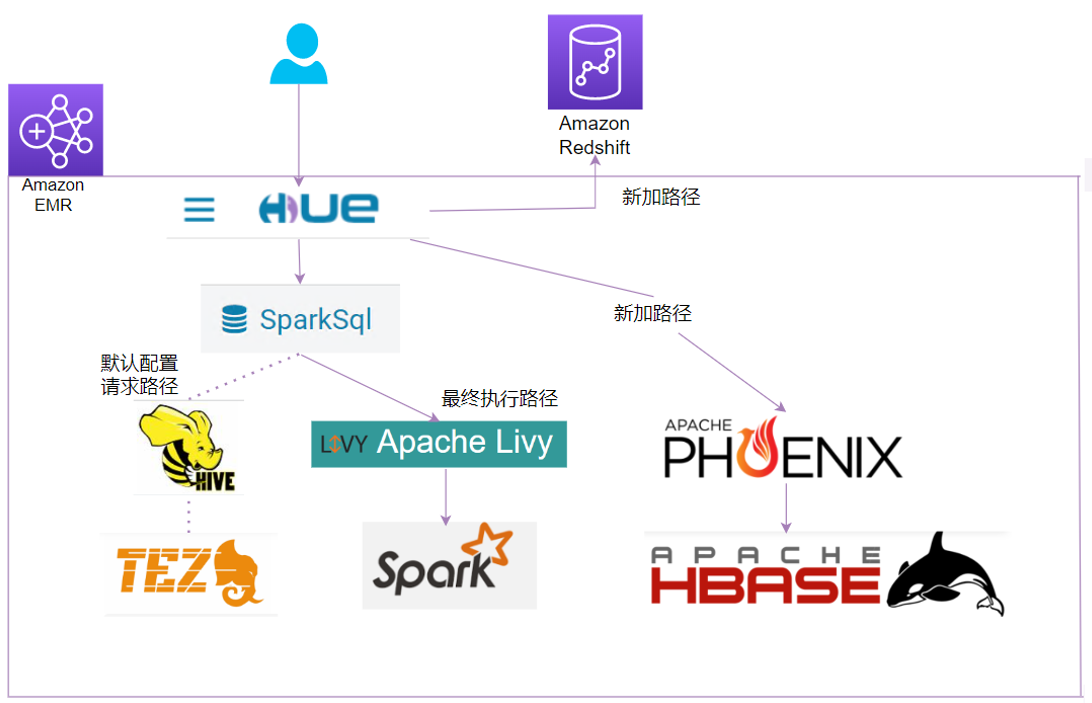
方案介绍
通过 Livy 提交 SparkSQL Job
执行引擎现状
首先,我们简单比对一下几种流行的执行引擎的现状:
- 由于处理客户查询需要高磁盘 IO,Apache MapReduce 是最慢的查询执行引擎。
- 在保持磁盘 IO 不变的情况下,Apache Tez 明显快于 Apache MapReduce。
- Apache Spark 比没有 IO 阻塞的 Apache Tez 稍快,和Apache Tez 一样以 DAG 方式处理数据,Spark 更加通用,提供内存计算,实时流处理,机器学习等多种计算方式,适合迭代计算。
Apache Livy 简介
Apache Livy 是一项服务,可通过 REST API 与 Spark 集群轻松交互。此方案中的配置方式可将 Hue 页面编写的 SparkSQL 通过 Livy 接口提交到 EMR 集群。
EMR Hue 处理 SparkSQL 默认行为
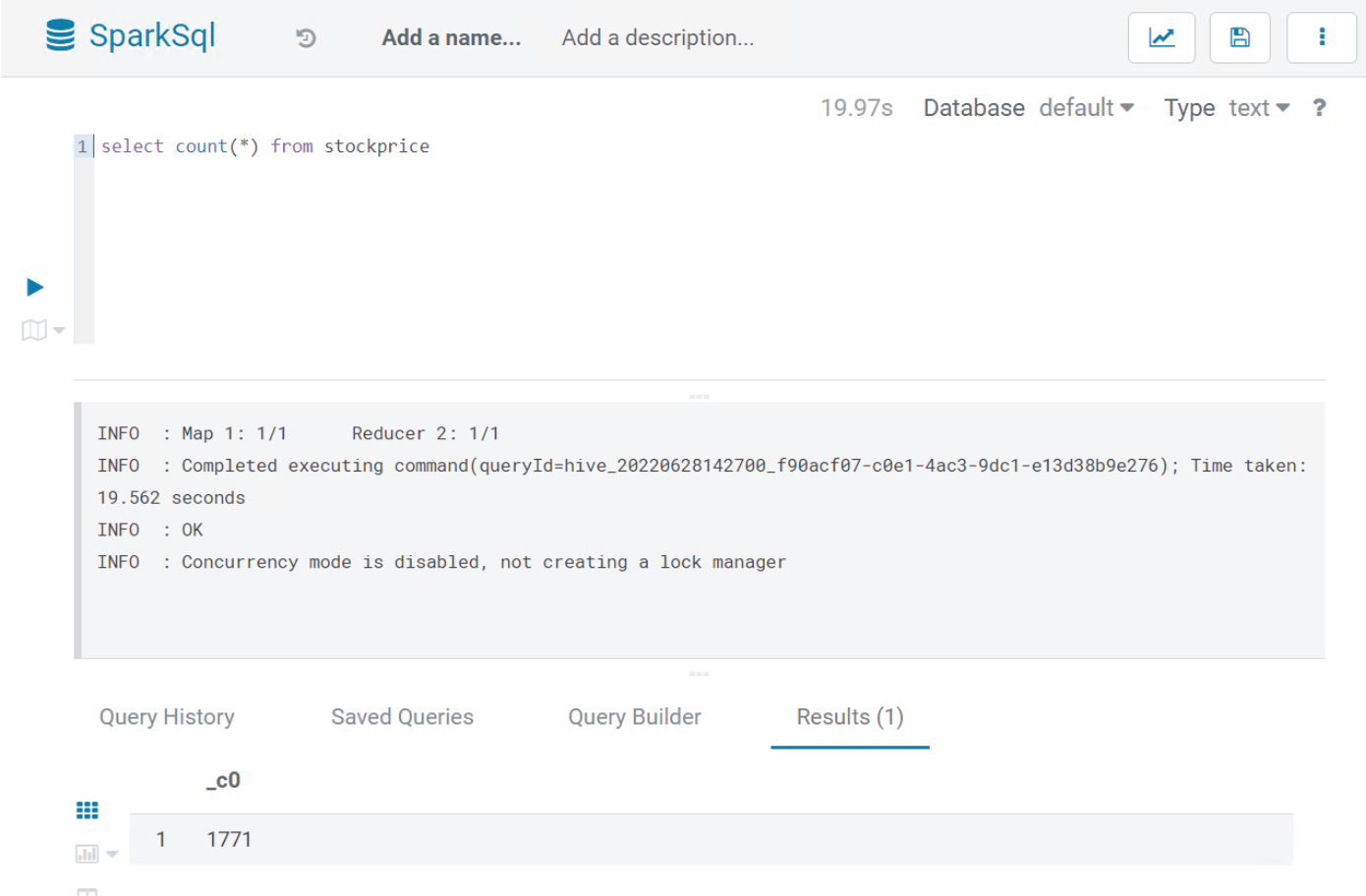
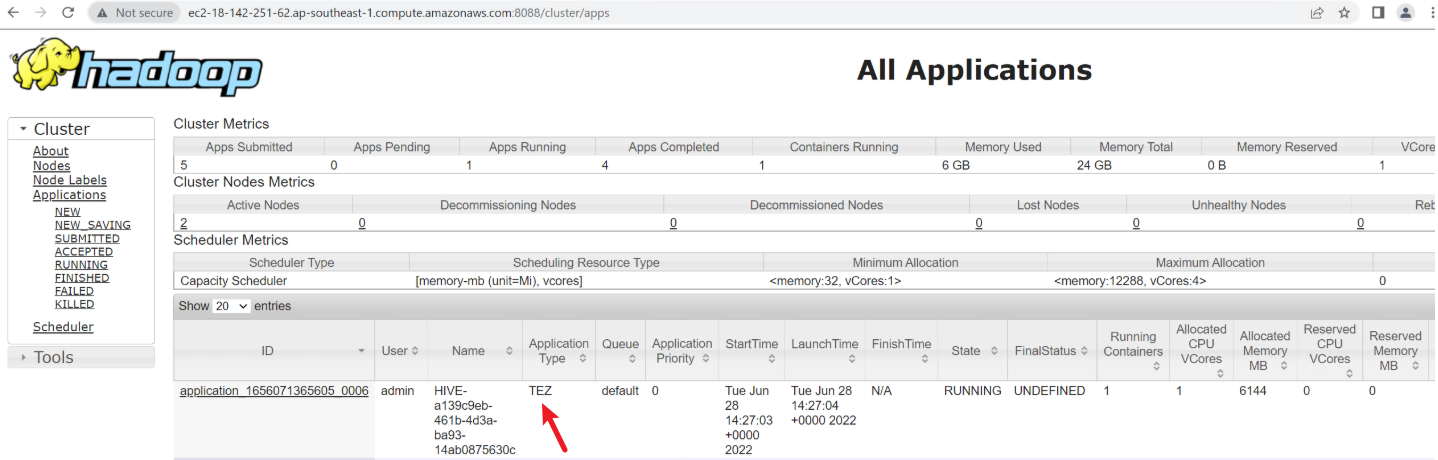
当在 Hue 的面板上 Editor 选择 SparkSQL 并提交 SQL 任务时,我们根据 application_id((Executing on YARN cluster with App id application_1656071365605_0006))去 Resource Manager 控制台上查询到对应的 Application Type 是 Tez:
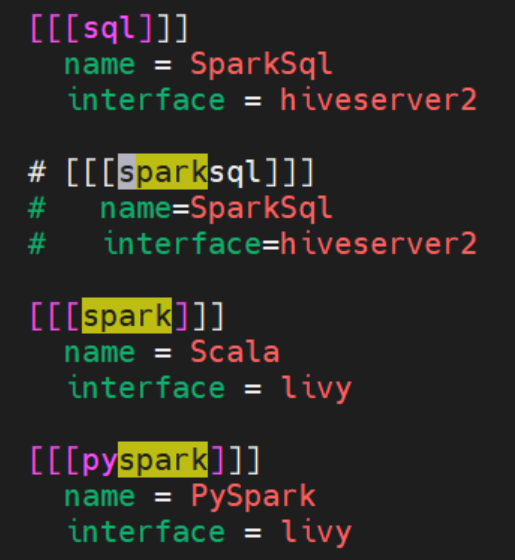
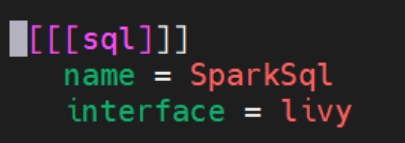
当我们打开 hue 的配置文件(/etc/hue/conf/hue.ini)看到[[[sql]]] 处配置如下图,interface 配置的是 hiveserver2 便知道了此时的 SparkSQL 走的仍是 hiveserver2,因此使用的是 Tez 引擎(EMR上的Hive执行引擎默认是Tez),这代表着并未真的使用 Spark 执行引擎在运行上述的 Query。
在 EMR Hue 中通过 Livy 提交 SparkSQL 任务
(1)修改 Hue 配置文件(/etc/hue/conf/hue.ini)中的执行引擎,并重启 Hue 服务
sudo systemctl restart hue.service
sudo systemctl status hue.service
重新提交 SparkSQL 任务后,看到该 Application 的 ApplicationType 已经为 SPARK。

生产场景中的性能调优:
上述 Application 通过 Spark 管理界面查看 Environment 细节:

看到 spark.driver.memory 和 spark.executor.memory 均设置为1G

这是因为 Hue 源码中直接将上述两个参数的值设定为1G:
https://github.com/cloudera/hue/blob/bd6324a79c2e6b6d002ddd6767b0e63883373320/desktop/libs/notebook/src/notebook/connectors/spark_shell.py
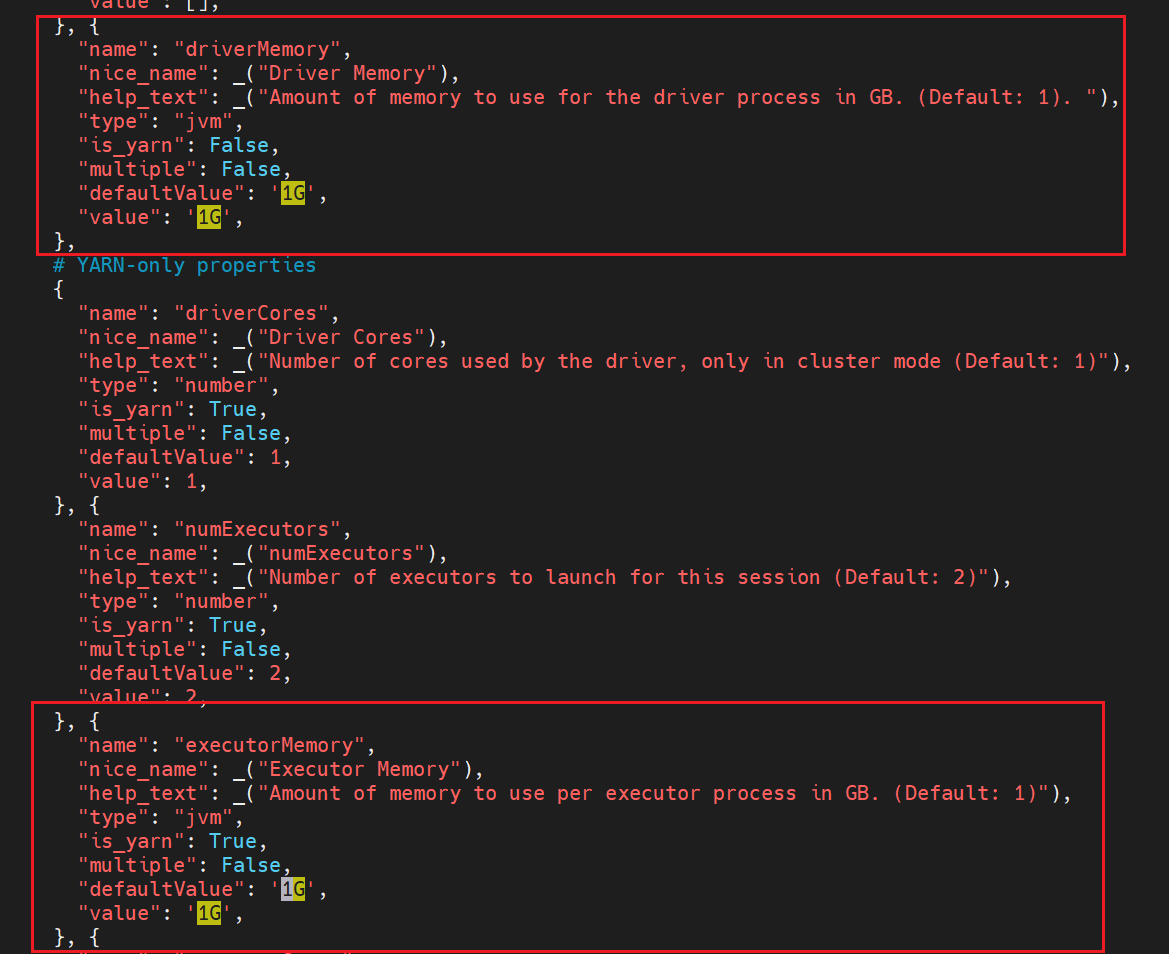
{"name": "driverMemory","nice_name": _("Driver Memory"),"help_text": _("Amount of memory to use for the driver process in GB. (Default: 1). "),"type": "jvm","is_yarn": False,"multiple": False,"defaultValue": '1G',"value": '1G',},
…
{"name": "executorMemory","nice_name": _("Executor Memory"),"help_text": _("Amount of memory to use per executor process in GB. (Default: 1)"),"type": "jvm","is_yarn": True,"multiple": False,"defaultValue": '1G',"value": '1G',}
如果用默认参数值容易在任务执行中触发 OOM 异常,导致任务运行失败,我们可选择通过以下方法进行调优:
cp /usr/lib/hue/desktop/libs/notebook/src/notebook/connectors/spark_shell.py /usr/lib/hue/desktop/libs/notebook/src/notebook/connectors/spark_shell.py.bak
sudo vi /usr/lib/hue/desktop/libs/notebook/src/notebook/connectors/spark_shell.py
将 ‘driverMemory’ 和 ‘executorMemory’ 的配置删除,重启 Hue 服务
sudo systemctl restart hue.service
sudo systemctl status hue.service
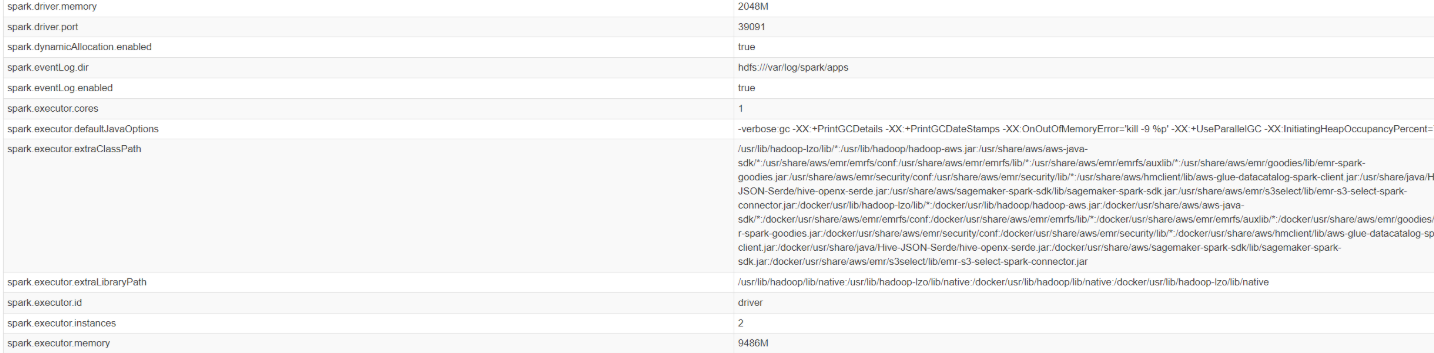
再次运行 SparkSQL,从 Environment 看到两个内存参数已经更新,和 /etc/spark/conf/spark-defaults.conf 内定义一致:

Hue 配置 Phoenix 提交 HBase 任务
Apache Phoenix 简介
Apache Phoenix 是一个开源的,大规模并行的关系数据库引擎,支持使用 Apache HBase 作为其后备存储的 OLTP for Hadoop。Phoenix 提供了一个 JDBC 驱动程序,该驱动程序隐藏了 noSQL 存储的复杂性,使用户能够创建,删除和更改 SQL 表,视图,索引和序列。
配置 Phoenix
(1)准备 Hue Python Virtual Environment
sudo /usr/lib/hue/build/env/bin/pip install phoenixdb
(2)修改 Hue 配置文件:
在 /etc/hue/conf/hue.ini的[notebook] [[interpreters]]部分加入:
[[[phoenix]]]
name=HBase Phoenix
interface=sqlalchemy
options='{"url": "phoenix:// ip-172-31-37-125.ap-southeast-1.compute.internal:8765/"}'
重启 Hue 服务
sudo systemctl restart hue.service
sudo systemctl status hue.service
(3) Hue 页面提交 Phoenix 任务:
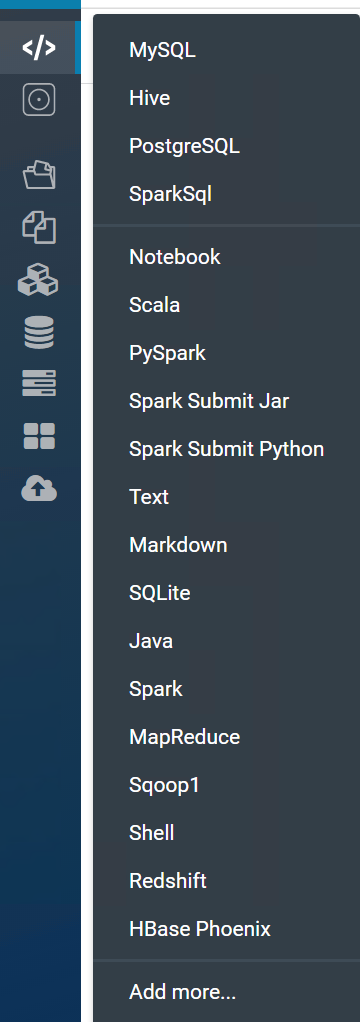
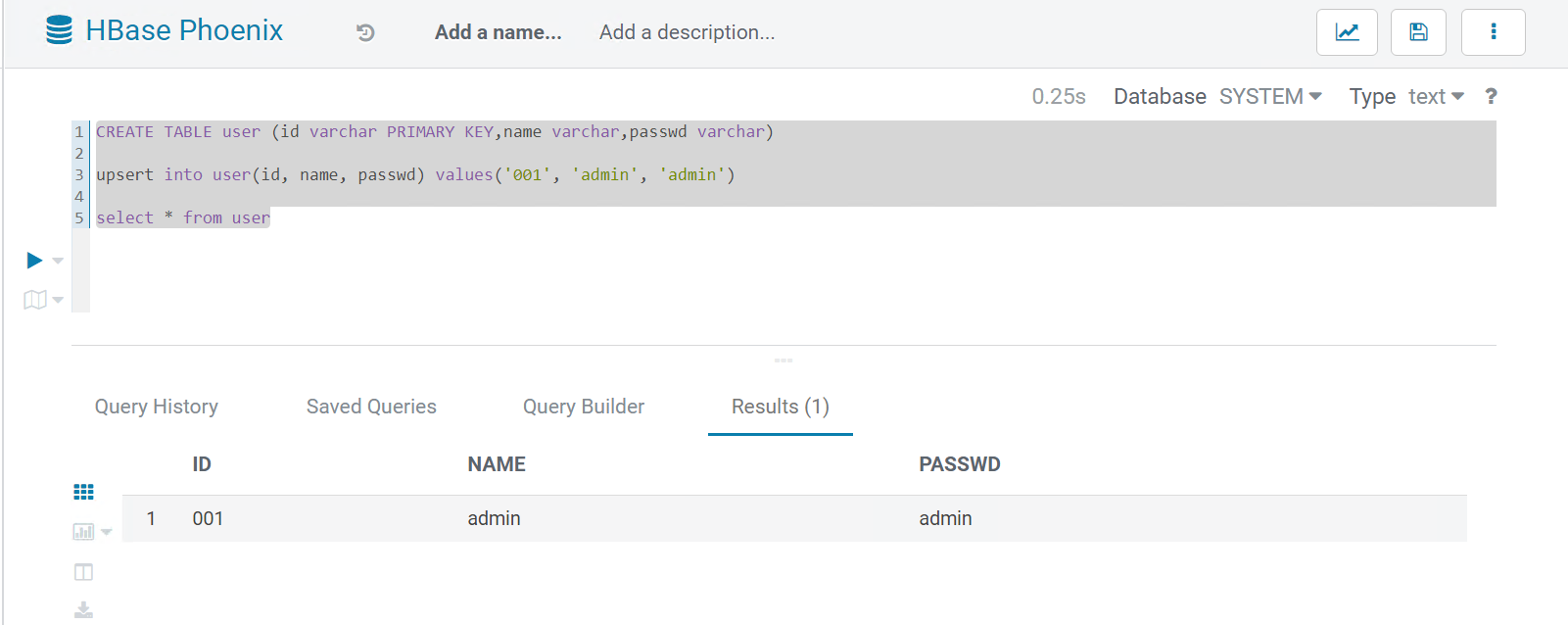
Hue – Editor 部分因为配置文件的更新,出现了 HBase Phoenix 的选项, 创建和查询 Table :
CREATE TABLE user (id varchar PRIMARY KEY,name varchar,passwd varchar)
upsert into user(id, name, passwd) values('001', 'admin', 'admin')
select * from user
HBase 显示列名乱码修正
(1)当完成上述操作时,回到 HBase Shell 查看表内容,发现列名为乱码:

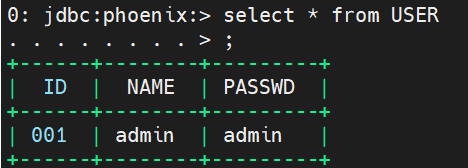
使用 Phoenix 命令行(/usr/lib/phoenix/bin/sqlline.py, 不透过Hue)创建表仍能重现该问题,且乱码不会在 Phoenix JDBC 连接中出现:
(2)在 Phoenix 创建表时最后加上 COLUMN_ENCODED_BYTES= 0可规避该问题:
CREATE TABLE user02 (id varchar PRIMARY KEY,name varchar,passwd varchar) COLUMN_ENCODED_BYTES= 0
upsert into user02(id, name, passwd) values('002', 'admin', 'admin')
select * from user02
HBase Shell 查看结果,列名已经显示正常:

Hue 连接 Redshift 提交任务
当数仓平台中涉及 Amazon EMR 和 Amazon Redshift 等多种服务时,通过 Hue 丰富的 Connectors 扩展种类,可以轻松实现统一交互的功能。
(1)准备 Hue Python Virtual Environment
cd /usr/lib/hue/
sudo ./build/env/bin/pip install sqlalchemy-redshift
sudo /usr/lib/hue/build/env/bin/pip2.7 install psycopg2-binary
(2)修改 Hue 配置文件:
在/etc/hue/conf/hue.ini的[notebook] [[interpreters]]部分加入:
[[[redshift]]]
name = Redshift
interface=sqlalchemyoptions='{"url": "redshift+psycopg2://username:password@host.amazonaws.com:5439/database"}'
重启 Hue 服务
sudo systemctl restart hue.service
sudo systemctl status hue.service
(3) Hue 页面提交 Redshift 任务:
Hue – Editor 部分因为配置文件的更新,出现了 Reshift 的选项:
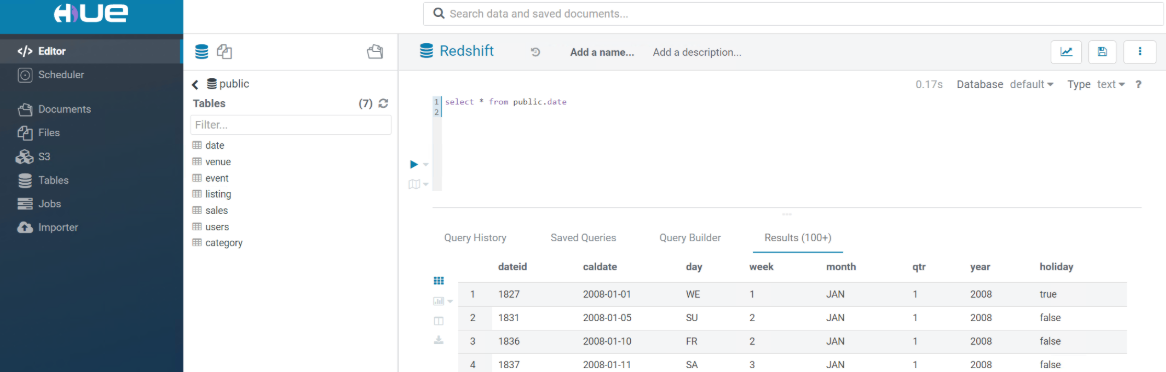
提交 SQL 查询,轻松获取 Amazon Redshift 数仓数据:
总结
本文主要帮助使用 Amazon EMR 的用户,通过 Hue 实现统一数仓平台开发工具,一方面集中管理数仓 SQL 开发任务,另一方面为其它部门提供自主分析的平台,对数仓建设有一定的推动作用。
本篇作者

Sunny Fang Amazon 技术客户经理,主要支持金融,互联网行业客户的架构优化、成本管理、技术咨询等工作,并专注在大数据和容器方向的技术研究和实践。在加入 Amazon 之前,曾就职于 Citrix 和微软等科技公司,拥有8年虚拟化与公有云领域的架构优化和支持经验。

张尹 Amazon 技术客户经理,负责企业级客户的架构和成本优化、技术支持等工作。有多年的大数据架构设计,数仓建模等实战经验。在加入 Amazon 之前,长期负责头部电商大数据平台架构设计、数仓建模、运维等相关工作。
文章来源:https://dev.amazoncloud.cn/column/article/630b3f0176658473a3220015?sc_medium=regulartraffic&sc_campaign=crossplatform&sc_channel=CSDN
相关文章:
使用 Hue 玩转 Amazon EMR(SparkSQL, Phoenix) 和 Amazon Redshift
现状 Apache Hue 是一个基于 Web 的交互式 SQL 助手,通过它可以帮助大数据从业人员(数仓工程师,数据分析师等)与数据仓库进行 SQL 交互。在 Amazon EMR 集群启动时,通过勾选 Hue 进行安装。在 Hue 启用以后࿰…...

Unity中神秘的Transform和transform(小写)的关系
1.为什么Transform类是保护的不能通过new 来实例化对象,也没有静态函数,而Rotate()这种方法却属于它,该如何访问? Transform 类还是被保护的不允许用户修改! protected Transform(); 是一个受保护的构造函数,不能直接实例化 Transform 类。 2.为甚么transform可以访问Tr…...

【LeetCode-中等题】78. 子集
文章目录 题目方法一:动态规划方法二:递归加回溯(关键----startIndex) 题目 注意:这里的nums数组里面的元素是各不相同的,所以不存在去重操作 方法一:动态规划 public List<List<Integer>> subsets(int[]…...

学习设计模式之代理模式,但是宝可梦
前言 作者在准备秋招中,学习设计模式,做点小笔记,用宝可梦为场景举例,有错误欢迎指出。 代码同步更新到 github ,要是点个Star您就是我的神 目录 前言代理模式1.情景模拟1.1静态代理优点局限 1.2 动态代理 2.应用3.局限4.解决方…...
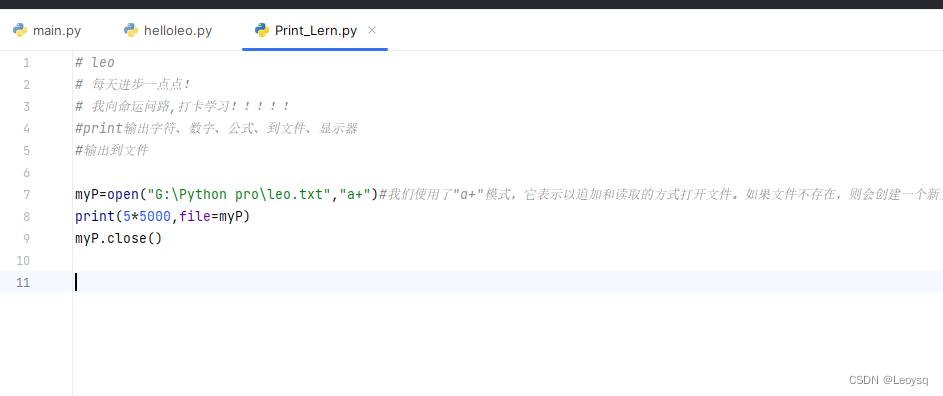
自学Python01-创建文件写入内容
此处省去安装和前言,需要两个东西 一个去下载安装python官方库 Welcome to Python.org 一个是编译器pycharm PyCharm 安装教程(Windows) | 菜鸟教程 PyCharm: the Python IDE for Professional Developers by JetBrains 第一节 练习print…...
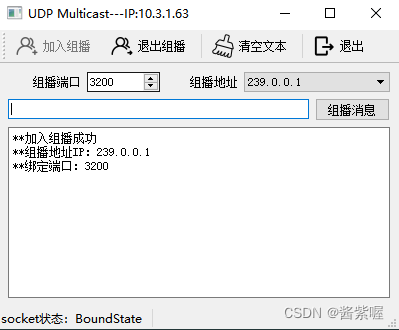
Qt —UDP通信QUdpSocket 简介 +案例
1. UDP通信概述 UDP是无连接、不可靠、面向数据报(datagram)的协议,可以应用于对可靠性要求不高的场合。与TCP通信不同,UDP通信无需预先建立持久的socket连接,UDP每次发送数据报都需要指定目标地址和端口。 QUdpSocket…...
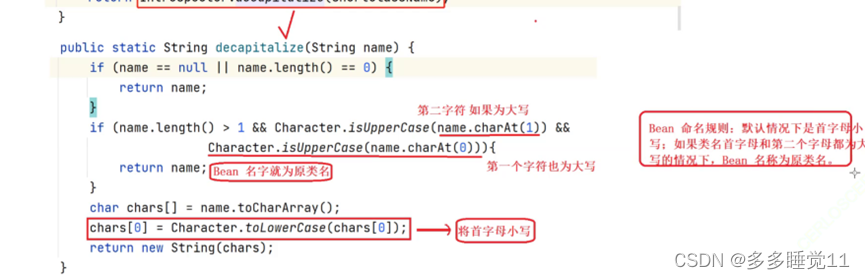
五大类注解和方法注解详解
五大类注解为Controller,Service,Repository,Configuration,Component,方法注解为Bean。 需要注意的是:Bean注解必须要在类注解修饰的类内才能正常使用。 一、与配置文件的关系 在spring原生项目中 如果你使用的spri…...

机器人中的数值优化(十)——线性共轭梯度法
本系列文章主要是我在学习《数值优化》过程中的一些笔记和相关思考,主要的学习资料是深蓝学院的课程《机器人中的数值优化》和高立编著的《数值最优化方法》等,本系列文章篇数较多,不定期更新,上半部分介绍无约束优化,…...
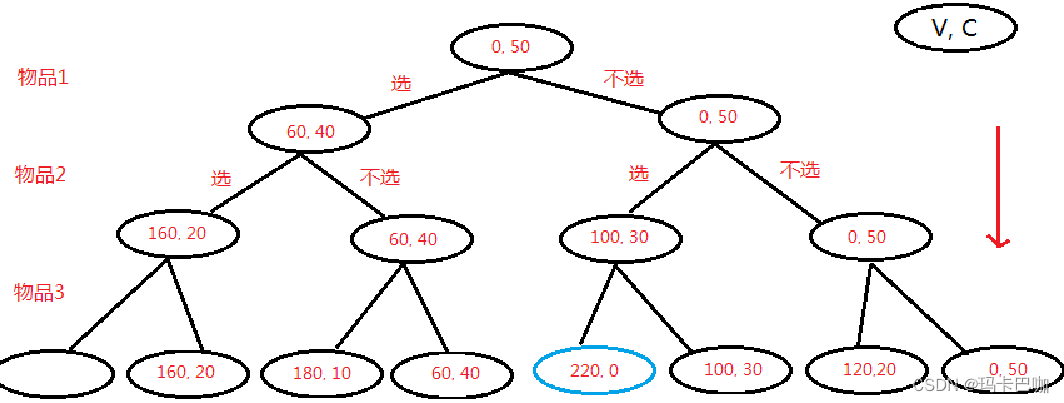
数据结构与算法之贪心动态规划
一:思考 1.某天早上公司领导找你解决一个问题,明天公司有N个同等级的会议需要使用同一个会议室,现在给你这个N个会议的开始和结束 时间,你怎么样安排才能使会议室最大利用?即安排最多场次的会议?电影的话 那…...

【网络编程】网络基础概念
(꒪ꇴ꒪ ),Hello我是祐言QAQ我的博客主页:C/C语言,数据结构,Linux基础,ARM开发板,网络编程等领域UP🌍快上🚘,一起学习,让我们成为一个强大的攻城狮࿰…...
连接虚拟机报错 Could not connect to ‘192.168.xxx.xxx‘ (port 22): Connection failed.
使用xshell连接虚拟机报错 Connecting to 192.168.204.129:22… Could not connect to ‘192.168.204.129’ (port 22): Connection failed. Type help’ to learn how to use Xshell prompt. 按网上的方法 是否能ping通内外网 ping www.baidu.com防火墙是否关闭 firewal…...
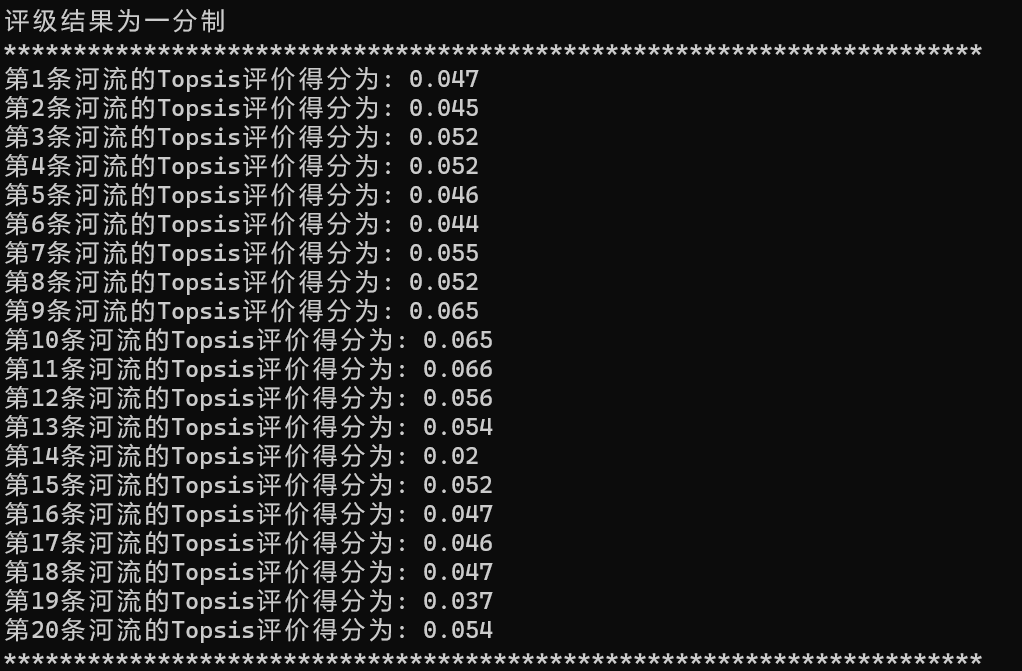
数学建模--Topsis评价方法的Python实现
目录 1.算法流程简介 2.算法核心代码 3.算法效果展示 1.算法流程简介 """ TOPSIS(综合评价方法):主要是根据根据各测评对象与理想目标的接近程度进行排序. 然后在现有研究对象中进行相对优劣评价。 其基本原理就是求解计算各评价对象与最优解和最劣解的距离…...

超越时间与人力的软件开发智慧:《人月神话》
目录 1、写在前面2、沟通!沟通!沟通!3、“银弹论”4、“人月神话”不能成立的原因5、影响力6、图书推荐 1、写在前面 《人月神话》是由计算机科学家弗雷德里克布鲁克斯所著的一本经典著作,首次出版于1975年。这本书以一个个小故事…...

Java Stream 流对象(实用技巧)
目录 一、InputStream & OutputStream 1.1、InputStream 和 OutputStream 一般使用 1.2、特殊使用 1.2.1、如何表示文件读取完毕?(DataInputStream) 1.2.2、字符读取/文本数据读取(Scanner) 1.2.3、文件的随机…...

【用unity实现100个游戏之8】用Unity制作一个炸弹人游戏
文章目录 前言素材开始一、绘制地图二、玩家设置三、玩家移动四、玩家四方向动画运动切换 五、放置炸弹六、生成爆炸效果七、墙壁和可破坏障碍物的判断八、道具生成和效果九、玩家死亡十、简单的敌人AI十一、简单敌人AI十二、随机绘制地图十三、虚拟摇杆 最终效果待续源码完结 …...

简易版人脸识别qt opencv
1、配置文件.pro #------------------------------------------------- # # Project created by QtCreator 2023-09-05T19:00:36 # #-------------------------------------------------QT core guigreaterThan(QT_MAJOR_VERSION, 4): QT widgetsTARGET 01_face TEMP…...

如何系统地学习 JavaScript?
前言 在学习JavaScript前需要先将Html和Css的相关知识点弄清楚,Js的很多操作是要结合Html和Css,下面我总结了Html、Css和Js的相关学习知识点供参考,希望对你有所帮助喔~ Html 文档学习 【HTML 】w3school教程 :https://www.w3school.com.…...
)
对称二叉树(Leetcode 101)
题目 101. 对称二叉树 思路 使用层序遍历,遍历当前层的节点时,如该节点的左(右)孩子为空,在list中添加null,否则加入左(右)孩子的值。每遍历完一层则对当前list进行判断,…...
-3.5 图像分类数据集)
动手学深度学习(2)-3.5 图像分类数据集
文章目录 引言正文图像分类数据集主要包介绍主要流程具体代码练习 总结 引言 这里主要是看一下如何加载数据集,并且生成批次训练的数据。最大的收获是,知道了如何在训练阶段提高模型训练的性能 增加batch_size增加num_worker数据预加载 正文 图像分类…...

C标准输入与标准输出——stdin,stdout
🔗 《C语言趣味教程》👈 猛戳订阅!!! —— 热门专栏《维生素C语言》的重制版 —— 💭 写在前面:这是一套 C 语言趣味教学专栏,目前正在火热连载中,欢迎猛戳订阅&#…...

Yokogawa ADV551数字输出模块
Yokogawa ADV551 数字输出模块是横河 CENTUM VP/CS 3000 系统的核心输出组件,具备以下 15 条特点:提供 32 路独立数字量输出通道。额定电压 24V DC,每通道负载能力充足。输出类型为电流吸收型(Current Sink)。支持状态…...

基于DS18B20与WipperSnapper的无代码物联网温度监测方案
1. 项目概述:当经典传感器遇上无代码物联网 在物联网和智能硬件的世界里,温度监测是一个永恒的基础需求。无论是想监控家里的温室环境、记录鱼缸水温,还是追踪服务器机柜的热量变化,你都需要一个可靠、精确且易于集成的温度传感器…...

地下水数值模拟中稳态与瞬态模型的构建机理及参数率定方法指南
概述在地下水流数值模拟(如基于有限差分法的 MODFLOW 平台)中,稳态(Steady-State)与瞬态(Transient)模拟是揭示地下水流场特征、评估水资源量以及预测流场演变的核心阶段。然而,在实…...

Microsoft大规模取消 Claude Code 授权,内部强制向 Copilot CLI 迁移
2.8 万行遗留系统重构实战 | Claude Code / Cursor / Copilot 横向对比最近AI Coding工具圈子直接打起来了。Microsoft开始大规模取消Claude Code授权,把内 部开发者往Copilot CLI上推(5月14日左右The Verge等媒体报道);几乎同时O…...

3步高效部署AutoJs6:Android自动化开发实战指南
3步高效部署AutoJs6:Android自动化开发实战指南 【免费下载链接】AutoJs6 安卓平台 JavaScript 自动化工具 (Auto.js 二次开发项目) 项目地址: https://gitcode.com/gh_mirrors/au/AutoJs6 AutoJs6作为Android平台领先的JavaScript自动化工具,为开…...

C语言状态模式实战:从设计思想到嵌入式状态机实现
1. 项目概述:从“状态”到“模式”的思维跃迁在嵌入式开发、游戏逻辑、网络协议解析乃至日常的业务流程控制中,我们常常会面对一个核心挑战:如何优雅地管理一个对象随着内部条件改变而表现出的不同行为?比如,一个自动售…...


AssetRipper完整指南:快速掌握Unity游戏资源提取的终极方法
AssetRipper完整指南:快速掌握Unity游戏资源提取的终极方法 【免费下载链接】AssetRipper GUI Application to work with engine assets, asset bundles, and serialized files 项目地址: https://gitcode.com/GitHub_Trending/as/AssetRipper 在游戏开发和逆…...

企业内训场景如何利用Taotoken搭建统一的AI应用开发实验环境
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 企业内训场景如何利用Taotoken搭建统一的AI应用开发实验环境 应用场景类,大型企业开展内部AI技术培训时,需…...

数字人能给短视频带来什么?这4点说出了真相
数字人能给短视频带来什么?这4点说出了真相 “数字人能给短视频带来什么?”“AI时代短视频创作有什么变化?”"数字人为什么是2026年博主的必备工具?"这些问题困扰着无数想要在短视频领域有所突破的创作者。今天一次说清…...