C++——map和set的应用总结
目录
- 1. 关联式容器
- 2. 键值对
- 3. 树形结构的关联式容器
- 3.1 set
- 3.1.1 set的介绍
- 3.1.2 set的使用
- 3.2 multiset
- 3.2.1 multiset的介绍
- 3.2.2 multiset的使用
- 3.3 map
- 3.3.1 map的介绍
- 3.3.2 map的使用
- operator[]
- 3.4 multimap
- 3.4.1 multimap的介绍
- 3.4.2 multimap的使用
- 3.5 map和set在OJ中的使用
1. 关联式容器
STL中的部分容器,比如:vector、list、deque、forward_list(C++11)等,这些容器统称为序列式容器,因为其底层为线性序列的数据结构,里面存储的是元素本身。
那什么是关联式容器?它与序列式容器有什么区别?
关联式容器也是用来存储数据的,与序列式容器不同的是,其里面存储的是<key, value>结构的键值对。序列式容器中存储的元素默认都是未经过排序的,而使用关联式容器存储的元素,默认会根据各元素的键值的大小做升序排序,在数据检索时比序列式容器效率更高。
2. 键值对
用来表示具有一一对应关系的一种结构,该结构中一般只包含两个成员变量key和value,key代表键值,value表示与key对应的信息。比如:现在要建立一个英汉互译的字典,那该字典中必然有英文单词与其对应的中文含义,英文单词与其 中文含义是一一对应的关系,即通过该应该单词,在词典中就可以找到与其对应的中文含义。
SGI-STL中关于键值对的定义:
template <class T1, class T2>
struct pair
{typedef T1 first_type;typedef T2 second_type;T1 first;T2 second;pair() : first(T1()), second(T2())//默认构造{}pair(const T1& a, const T2& b) : first(a), second(b)//拷贝构造{}
};
3. 树形结构的关联式容器
根据应用场景的不同,STL总共实现了两种不同结构的管理式容器:树型结构与哈希结构。树型结构的关联式容器主要有四种:map、multimap、set、multiset。这四种容器的共同点是:使用平衡搜索树(即红黑树)作为其底层结果,容器中的元素是一个有序的序列。下面一依次介绍每一个容器。
3.1 set
3.1.1 set的介绍
- set是按照一定次序存储元素的容器
- 在set中,元素的value也标识它(value就是key,类型为T),并且每个value必须是唯一的。set中的元素不能在容器中修改(元素总是const),但是可以从容器中插入或删除它们。
- 在内部,set中的元素总是按照其内部比较对象(类型比较)所指示的特定严格弱排序准则进行排序。
- set容器通过key访问单个元素的速度通常比unordered_set容器慢,但它们允许根据顺序对子集进行直接迭代。
- set在底层是用二叉搜索树(红黑树)实现的。
注意:
- 与map/multimap不同,map/multimap中存储的是真正的键值对<key, value>,set中只放value,但在底层实际存放的是由<value, value>构成的键值对。
- set中插入元素时,只需要插入value即可,不需要构造键值对。
- set中的元素不可以重复(因此可以使用set进行去重)。
- 使用set的迭代器遍历set中的元素,可以得到有序序列(排序)
- set中的元素默认按照小于来比较(升序)
- set中查找某个元素,时间复杂度为:log2nlog_2 nlog2n
- set中的元素不允许修改
- set中的底层使用二叉搜索树(红黑树)来实现。
3.1.2 set的使用
1.set的模板参数列表

T: set中存放元素的类型,实际在底层存储<value, value>的键值对。
Compare:set中元素默认按照小于来比较(升序)
Alloc:set中元素空间的管理方式,使用STL提供的空间配置器管理
2.set的构造
| 函数声明 | 功能介绍 |
|---|---|
| set (const Compare& comp = Compare(), const Allocator& = Allocator() ); | 构造空的set |
| set (InputIterator first, InputIterator last, const Compare& comp = Compare(), const Allocator& =Allocator() ); | 用[first, last)区间中的元素构造set |
| set ( const set<Key,Compare,Allocator>& x); | set的拷贝构造 |
3.set的迭代器
| 函数声明 | 功能介绍 |
|---|---|
| iterator begin() | 返回set中起始位置元素的迭代器 |
| iterator end() | 返回set中最后一个元素后面的迭代器 |
| const_iterator cbegin()const | 返回set中起始位置元素const迭代器 |
| const_iterator cend() const | 返回set中最后一个元素后面的const迭代器 |
| reverse_iterator rbegin() | 返回set第一个元素的反向迭代器,即rend |
| reverse_iterator rend() | 返回set最后一个元素下一个位置的反向迭代器,即rbegin |
| const_reverse_iterator crbegin() const | 返回set第一个元素的反向const迭代器,即crend |
| const_reverse_iterator crend() const | 返回set最后一个元素下一个位置的反向const迭代器,即crbegin |
- set的容量
| 函数声明 | 功能介绍 |
|---|---|
| bool empty ( ) const | 检测set是否为空,空返回true,否则返回true |
| size_type size() const | 返回set中有效元素的个数 |
5.set修改操作
| 函数声明 | 功能介绍 |
|---|---|
| pair<iterator,bool> insert (const value_type& x ) | 在set中插入元素x,实际插入的是<x, x>构成的键值对,如果插入成功,返回<该元素在set中的位置,true>,如果插入失败,说明x在set中已经存在,返回<x在set中的位置,false> |
| void erase ( iterator position ) | 删除set中position位置上的元素 |
| size_type erase ( const key_type& x ) | 删除set中值为x的元素,返回删除的元素的个数 |
| void erase ( iterator first,iterator last ) | 删除set中[first, last)区间中的元素 |
| void swap (set<Key,Compare,Allocator>&st ); | 交换set中的元素 |
| void clear ( ) | 将set中的元素清空 |
| iterator find ( const key_type& x ) const | 找到了,返回set中值为x的元素的位置,没有找到返回end() |
| size_type count ( const key_type& x ) const | 返回set中值为x的元素的个数,在set中不是1就是0,而在multiset中允许插入重复值,就不一定是0或1了 |
其他:
| 函数声明 | 功能介绍 |
|---|---|
| iterator lower_bound (const value_type& val) const; | 返回第一个大于等于val的迭代器 |
| iterator upper_bound (const value_type& val) const; | 返回第一个大于val的迭代器 |
6.set的使用举例
#include <set>
void TestSet()
{// 用数组array中的元素构造setint array[] = { 1, 3, 5, 7, 9, 2, 4, 6, 8, 0, 1, 3, 5, 7, 9, 2, 4, 6, 8, 0 };set<int> s(array, array + sizeof(array) / sizeof(array[0]));cout << s.size() << endl;// 正向打印set中的元素,从打印结果中可以看出:set可去重for (auto& e : s)cout << e << " ";cout << endl;// 使用迭代器逆向打印set中的元素for (auto it = s.rbegin(); it != s.rend(); ++it)cout << *it << " ";cout << endl;// set中值为3的元素出现了几次cout << s.count(3) << endl;
}
运行结果:自动排序+去重

3.2 multiset
3.2.1 multiset的介绍
- multiset是按照特定顺序存储元素的容器,其中元素是可以重复的。
- 在multiset中,元素的value也会识别它(因为multiset中本身存储的就是<value, value>组成的键值对,因此value本身就是key,key就是value,类型为T). multiset元素的值不能在容器中进行修改(因为元素总是const的),但可以从容器中插入或删除。
- 在内部,multiset中的元素总是按照其内部比较规则(类型比较)所指示的特定严格弱排序准则进行排序。
- multiset容器通过key访问单个元素的速度通常比unordered_multiset容器慢,但当使用迭代器遍历时会得到一个有序序列。
- multiset底层结构为二叉搜索树(红黑树)。
注意:
- multiset中再底层中存储的是<value, value>的键值对
- 需要注意的是由于multiset有允许元素重复,find函数找的时候是中序的第一个位置。例如:多个重复值中序遍历结果是3 3 3,使用find函数会把第一个3的迭代器位置返回。
- mtltiset的插入接口中只需要插入即可
- 与set的区别是,multiset中的元素可以重复,set是中value是唯一的
- 使用迭代器对multiset中的元素进行遍历,可以得到有序的序列
- multiset中的元素不能修改
- 在multiset中找某个元素,时间复杂度为O(log2N)O(log_2 N)O(log2N)
- multiset的作用:可以对元素进行排序
3.2.2 multiset的使用
此处只简单演示set与multiset的不同,其他接口接口与set相同。
#include <set>//头文件和set是一样的
void TestSet()
{int array[] = { 2, 1, 3, 9, 6, 0, 5, 8, 4, 7 };// 注意:multiset在底层实际存储的是<int, int>的键值对multiset<int> s(array, array + sizeof(array) / sizeof(array[0]));for (auto& e : s)cout << e << " ";cout << endl;
}
3.3 map
3.3.1 map的介绍
-
map是关联容器,它按照特定的次序(按照key来比较)存储由键值key和值value组合而成的元素。
-
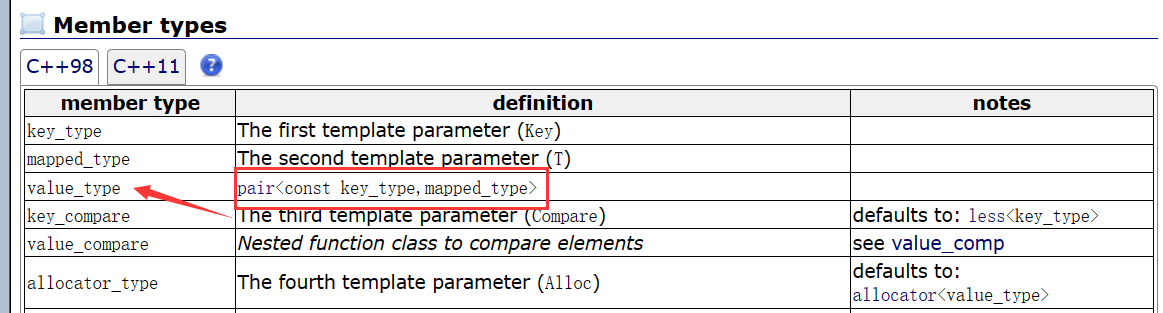
在map中,键值key通常用于排序和唯一的标识元素,而值value中存储与此键值key关联的内容。键值key和值value的类型可以不同。在map的内部,key与value通过成员类型value_type绑定在一起,为其取别名称为 pair即:
typedef pair<const key, T> value_type;。举个例子:map<string,int> My_Map单拿出来My_Map中的每一个元素都是一个一个的pair<string,int>,区分不同的pair时就用pair的first也就是string来区分每一个pair。下图为pair的成员变量first和second,以及对于value_type的定义。

-
在内部,map中的元素总是按照键值key进行比较排序的。
-
map中通过键值访问单个元素的速度通常比unordered_map容器慢,但map允许根据顺序对元素进行直接迭代(即对map中的元素进行迭代时,可以得到一个有序的序列)。
-
map支持下标访问符,即在[]中放入key,就可以找到与key对应的value。
-
map通常被实现为二叉搜索树(更准确的说:平衡二叉搜索树(红黑树))。
3.3.2 map的使用
1.map的模板参数说明
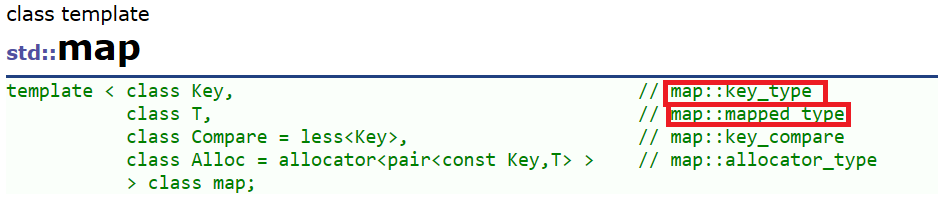
key: 键值对中key的类型
T: 键值对中value的类型
Compare: 比较器的类型,map中的元素是按照key来比较的,缺省情况下按照小于来比较,一般情况下(内置类型元素)该参数不需要传递,如果无法比较时(自定义类型),需要用户自己显式传递比较规则(一般情况下按照函数指针或者仿函数来传递)
Alloc:通过空间配置器来申请底层空间,不需要用户传递,除非用户不想使用标准库提供的空间配置器。
注意:在使用map时,需要包含头文件。
- map的构造
| 函数声明 | 功能介绍 |
|---|---|
| map (const key_compare& comp = key_compare(),const allocator_type& alloc = allocator_type()); | 构造一个空的map |
| map (InputIterator first, InputIterator last,const key_compare& comp = key_compare(),const allocator_type& alloc = allocator_type()); | 用[first, last)区间中的元素构造map |
| map (const map& x); | map的拷贝构造 |
- map的迭代器
| 函数声明 | 功能介绍 |
|---|---|
| begin()和end() | begin:首元素的位置,end最后一个元素的下一个位置 |
| cbegin()和cend() | 与begin和end意义相同,但cbegin和cend所指向的元素不能修改 |
| rbegin()和rend() | 反向迭代器,rbegin在end位置,rend在begin位置,其++和–操作与begin和end操作移动相反 |
| crbegin()和crend() | 与rbegin和rend位置相同,操作相同,但crbegin和crend所指向的元素不能修改 |
- map的容量与元素访问
| 函数声明 | 功能简介 |
|---|---|
| bool empty ( ) const | 检测map中的元素是否为空,是返回true,否则返回false |
| size_type size() const | 返回map中有效元素的个数 |
| mapped_type& operator[] (const key_type& k) | 返回去key对应的value |
- map中元素的修改
| 函数声明 | 功能简介 |
|---|---|
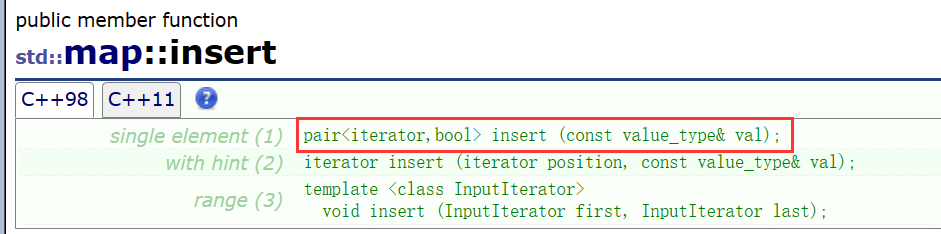
| pair<iterator,bool> insert (const value_type& x ) | 在map中插入键值对x,注意x是一个键值对,返回值也是键值对:iterator代表新插入元素的位置,bool代表释放插入成功 |
| void erase ( iterator position ) | 删除position位置上的元素 |
| size_type erase ( const key_type& x ) | 删除键值为x的元素 |
| void erase ( iterator first,iterator last ) | 删除[first, last)区间中的元素 |
| void swap (map<Key,T,Compare,Allocator>&mp ) | 交换两个map中的元素 |
| void clear ( ) | 将map中的元素清空 |
| iterator find ( const key_type& x) | 在map中插入key为x的元素,找到返回该元素的位置的迭代器,否则返回end |
| const_iterator find ( const key_type& x ) const | 在map中插入key为x的元素,找到返回该元素的位置的const迭代器,否则返回cend |
| size_type count ( const key_type& x ) const | 返回key为x的键值在map中的个数,注意map中key是唯一的,因此该函数的返回值要么为0,要么为1,因此也可以用该函数来检测一个key是否在map中 |
operator[]
insert函数的返回值:

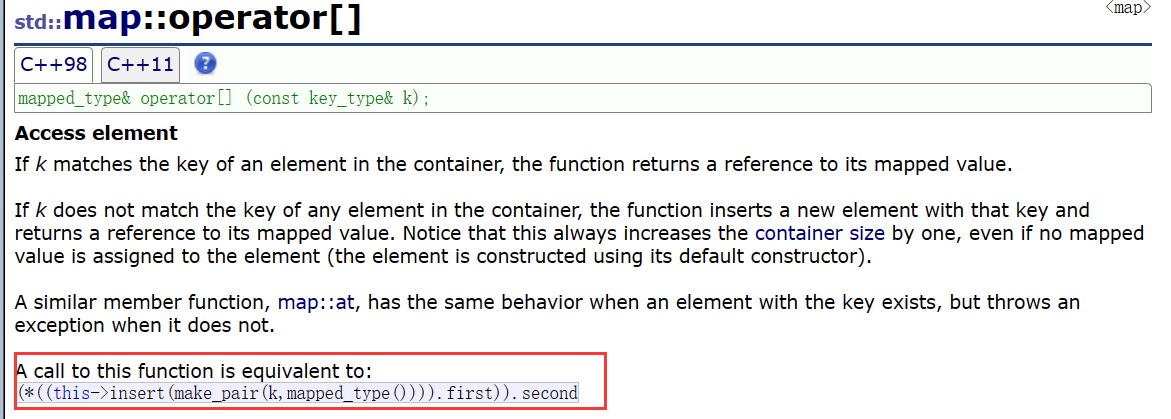
//将上面蓝框的内容化简可得
V& operatort[](const K& k)
{pair<iterator,bool> ret = insert(make_pair(k,V()));return ret.first->second;
}
operator[]的原理是:
用<key, T()>构造一个键值对,然后调用insert()函数将该键值对插入到map中,
如果key已经存在,插入失败,insert函数返回该key所在位置的迭代器。
如果key不存在,插入成功,insert函数返回新插入元素所在位置的迭代器,operator[]函数最后将insert返回值键值对中的value返回。
注意:在元素访问时,有一个与operator[]类似的操作at()(该函数不常用)函数,
都是通过key找到与key对应的value,然后返回value的引用(返回引用表示可以对value进行写和读),
不同的是:当key不存在时,operator[]调用 value的默认构造 与 key的构造 二者组成键值对然后插入,返回该 默认value,而at()函数直接抛异常。
来咱用一用,请看使用示例代码:
#include<iostream>
#include<string>
#include <map>
using namespace std;int main()
{///operate[]的不同使用场景map<string, string> dict;dict.insert(pair<string, string>("排序", "sort"));dict.insert(pair<string, string>("左边", "left"));dict.insert(pair<string, string>("右边", "right"));dict.insert(make_pair("字符串", "string")); dict["迭代器"] = "iterator"; // 插入+修改dict["insert"]; // 插入 key不在就是插入// 插入失败,搜索树只比较keydict.insert(pair<string, string>("左边", "xxx")); dict["insert"] = "插入"; //修改cout << dict["左边"] << endl; // 查找 key在就是查找//map<string, string>::iterator it = dict.begin();auto it = dict.begin();while (it != dict.end()){//cout << (*it).first<<":"<<(*it).second << endl;cout << it->first << ":" << it->second << endl;++it;}cout << endl;for (const auto& kv : dict){cout << kv.first << ":" << kv.second << endl;}// 统计水果出现的次数/string arr[] = { "苹果", "西瓜", "香蕉", "草莓", "苹果", "西瓜", "苹果", "苹果", "西瓜", "苹果", "香蕉", "苹果", "香蕉" };map<string, int> countMap;//for (auto& e : arr)//{// //map<string, int>::iterator it = countMap// auto it = countMap.find(e);// if (it == countMap.end())// {// countMap.insert(make_pair(e, 1));// }// else// {// it->second++;// }//}for (auto& e : arr){countMap[e]++;}for (const auto& kv : countMap){cout << kv.first << ":" << kv.second << endl;}return 0;
}
向map中插入元素的方式(insert、operator[]、erase的使用举例):
#include <string>
#include <map>
void TestMap()
{map<string, string> m;// 将键值对<"peach","桃子">插入map中,用pair直接来构造键值对m.insert(pair<string, string>("peach", "桃子"));// 将键值对<"peach","桃子">插入map中,用make_pair函数来构造键值对m.insert(make_pair("banan", "香蕉"));// 借用operator[]向map中插入元素// 将<"apple", "">插入map中,插入成功,返回value的引用,将“苹果”赋值给该引用结果,m["apple"] = "苹果";// key不存在时抛异常//m.at("waterme") = "水蜜桃";cout << m.size() << endl;// 用迭代器去遍历map中的元素,可以得到一个按照key排序的序列for (auto& e : m)cout << e.first << "--->" << e.second << endl;cout << endl;// map中的键值对key一定是唯一的,如果key存在将插入失败auto ret = m.insert(make_pair("peach", "桃色"));if (ret.second)cout << "<peach, 桃色>不在map中, 已经插入" << endl;elsecout << "键值为peach的元素已经存在:" << ret.first->first << "--->"<< ret.first->second << " 插入失败" << endl;// 删除key为"apple"的元素m.erase("apple");if (1 == m.count("apple"))cout << "apple还在" << endl;elsecout << "apple被吃了" << endl;}
【总结】
- map中的的元素是键值对
- map中的key是唯一的,并且不能修改
- 默认按照小于的方式对key进行比较
- map中的元素如果用迭代器去遍历,可以得到一个有序的序列
- map的底层为平衡搜索树(红黑树),查找效率比较高O(log2N)O(log_2 N)O(log2N)
- 支持[]操作符,operator[]中实际进行 插入 查找 修改。
3.4 multimap
3.4.1 multimap的介绍
- Multimaps是关联式容器,它按照特定的顺序,存储由key和value映射成的键值对<key,value>,其中多个键值对之间的key是可以重复的。
- 在multimap中,通常按照key排序和唯一的标识元素,而映射的value存储与key关联的内容。key和value的类型可能不同,通过multimap内部的成员类型value_type组合在一起,value_type是组合key和value的键值对:
typedef pair<const Key, T> value_type; - 在内部,multimap中的元素总是通过其内部比较对象,按照指定的特定严格弱排序标准对key进行排序的。
- multimap通过key访问单个元素的速度通常比unordered_multimap容器慢,但是使用迭代器直接遍历multimap中的元素可以得到关于key有序的序列。
- multimap在底层用二叉搜索树(红黑树)来实现。
注意:multimap和map的唯一不同就是:map中的key是唯一的,而multimap中key是可以重复的。
3.4.2 multimap的使用
multimap中的接口可以参考map,功能都是类似的。
注意:
- multimap中的key是可以重复的。
- multimap中的元素默认将key按照小于来比较
- multimap中没有重载operator[]操作,因为这里是一对多的结构。
- 使用时与map包含的头文件相同。
3.5 map和set在OJ中的使用
1、前K个高频单词
题目链接
思路:定义一个 map<string,int>类型的map,将vector<string>& words中的元素利用operator[]插入到map中,此时已经自动将所有字符串按字典序排序 并在int中记录出现次数。
然后转移到 vector<pair<string,int>> v方便下一步对于出现次数的排序,排序时要对int进行排序,但是题中又说 如果不同的单词有相同出现频率, 按字典顺序排序。
面临的问题有两个
1、pair默认的比较大小方式并不适合此题,需要自己写仿函数
2、sort排序是不稳定的排序,对于出现次数相同的两个单词,可能会把它们的字典序也打乱,所以要使用稳定的排序stable_sort。

代码:
class Solution {
public:class compare{public://需要自己按照题目要求定义一个仿函数bool operator()(const pair<string,int>& x, const pair<string,int>& y) const{return x.second > y.second;}};vector<string> topKFrequent(vector<string>& words, int k) {map<string,int> CountMap;for(const auto& one_words:words){CountMap[one_words]++;//关键的第一步}//然后转移到vector中vector<pair<string,int>> v;for(auto sp:CountMap){v.push_back(sp);}//使用稳定排序,对pair的second也就是int进行排序——关键的第二步stable_sort(v.begin(),v.end(),compare());vector<string> ret;for(int i=0;i<k;i++){ret.push_back(v[i].first);}return ret;}
};
2、两个数组的交集
题目链接
思路:创建两个set< int >类型的对象s1和s2分别来“装”num1和num2,以此达到对num1和num2实现排序+去重的目的,然后就是遍历s1和s2。
- 相等就是交集值,插入到要返回的vector< int >中,同时让s1和s2的迭代器++
- 不相等,对应的值小的 迭代器 ++,有一个set到结尾end了,那么就结束统计了。
代码:
class Solution {
public:vector<int> intersection(vector<int>& nums1, vector<int>& nums2) {set<int> s1,s2;//自动排序+去重for(auto n1:nums1){s1.insert(n1);}for(auto n2:nums2){s2.insert(n2);}vector<int> ret;auto it1=s1.begin();auto it2=s2.begin();while(it1!=s1.end()&&it2!=s2.end())//遍历s1和s2{if(*it1==*it2){ret.push_back(*it1);it1++;it2++;}else if(*it1>*it2){it2++;}else{it1++;}}return ret;}
};
相关文章:
C++——map和set的应用总结
目录1. 关联式容器2. 键值对3. 树形结构的关联式容器3.1 set3.1.1 set的介绍3.1.2 set的使用3.2 multiset3.2.1 multiset的介绍3.2.2 multiset的使用3.3 map3.3.1 map的介绍3.3.2 map的使用operator[]3.4 multimap3.4.1 multimap的介绍3.4.2 multimap的使用3.5 map和set在OJ中的…...

学习Python可以做什么工作?
一: 1、web开发:Python拥有非常完善与web服务器交互的库,大量的免费网页模板,相对于更具有优势,同时还具有非常优秀的Django框架,功能齐全。目前国内的豆瓣网、果壳网等,国外的Google、YouTube等…...
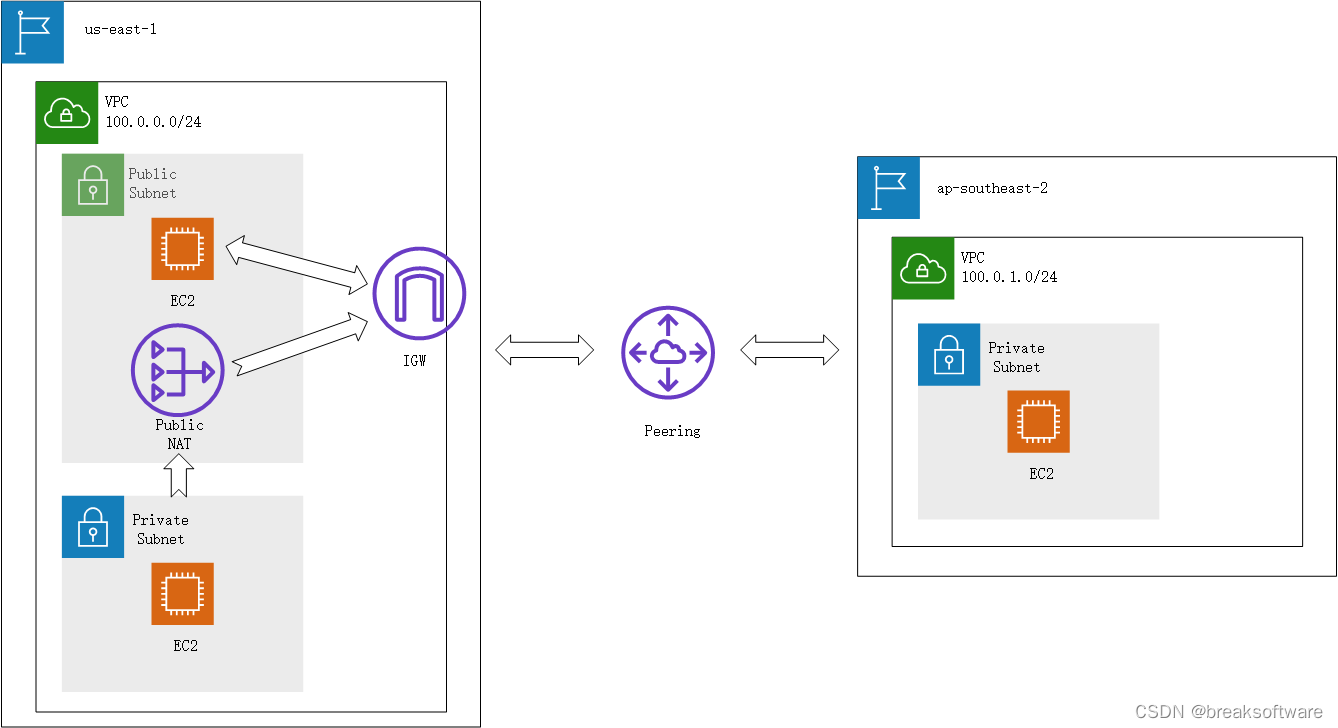
AWS攻略——Peering连接VPC
文章目录创建IP/CIDR不覆盖的VPC创建VPC创建子网创建密钥对创建EC2创建Peering接受Peering邀请修改各个VPC的路由表修改美东us-east-1 pulic subnet的路由修改悉尼ap-southeast-2路由测试知识点我们回顾下《AWS攻略——VPC初识》中的知识: 一个VPC只能设置在一个Re…...

程序员遇到人生低谷期怎么做?
每个人的一生都是起起伏伏的,你不会天天高潮,总会经历一段又一段的不如意,你怎么把握这一段段时间,如何掌控人生节奏,都源于对人生低谷期的回答。 尤其是2022年,程序员受到的冲击并不小,从年初…...

理解IM消息“可靠性”和“一致性”问题,以及解决方案探讨
试想如果一个IM连发出的消息都不知道对方到底能不能收到、发出的聊天内容对方看到的到底是不是“胡言乱语”(严重乱序问题),这样的APP用户肯定不会让他在手机上过夜(肯定第一时间卸载了),因为最基本的聊天逻…...

2021-08-29
服务器 主:172.17.0.2 master 备:172.17.0.3 slave1 lvs虚拟IP:172.17.0.100 #nginx下载地址 http://nginx.org/download/ 本地文件路径 1.dockerfile构建nginx FROM centos:7 ADD nginx-1.6.0.tar.gz /usr/local COPY nginx_install.sh /usr/local RUN sh …...

第八题、哈夫曼编码大全
题目: 哈夫曼编码大全 描述: 关于哈夫曼树的建立,编码,解码。 输入 第一行输入数字N,代表总共有多少个字符以及权值 第二第三行分别是一行字符串,以及每个字符对应的权值 接下来输入一个数M,表…...
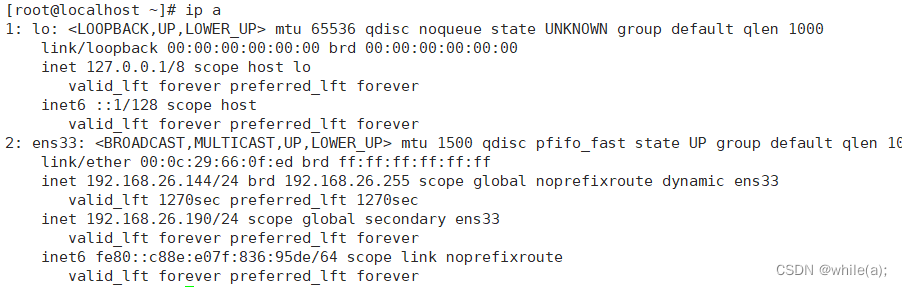
linux集群技术(二)--keepalived(高可用集群)(二)
案例1--keepalived案例2--keepalived Lvs集群1.案例1--keepalived 1.1 环境 初识keepalived,实现web服务器的高可用集群。 Server1: 192.168.26.144 Server2: 192.168.26.169 VIP: 192.168.26.190 1.2 server1 创建etc下的…...
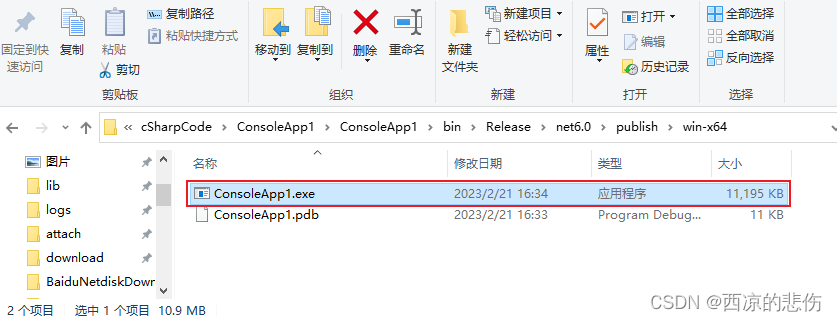
C# 控制台程序的开发和打包为一个exe文件
目录前言一、我的第一个C#控制台程序二、发布为一个exe文件前言 本文通过C#编写一个简单的示例计算器,来演示C#的使用和使用 Visual Studio 打包为一个 exe 文件。 一、我的第一个C#控制台程序 所谓控制台程序,就是没有界面,运行程序后只有…...
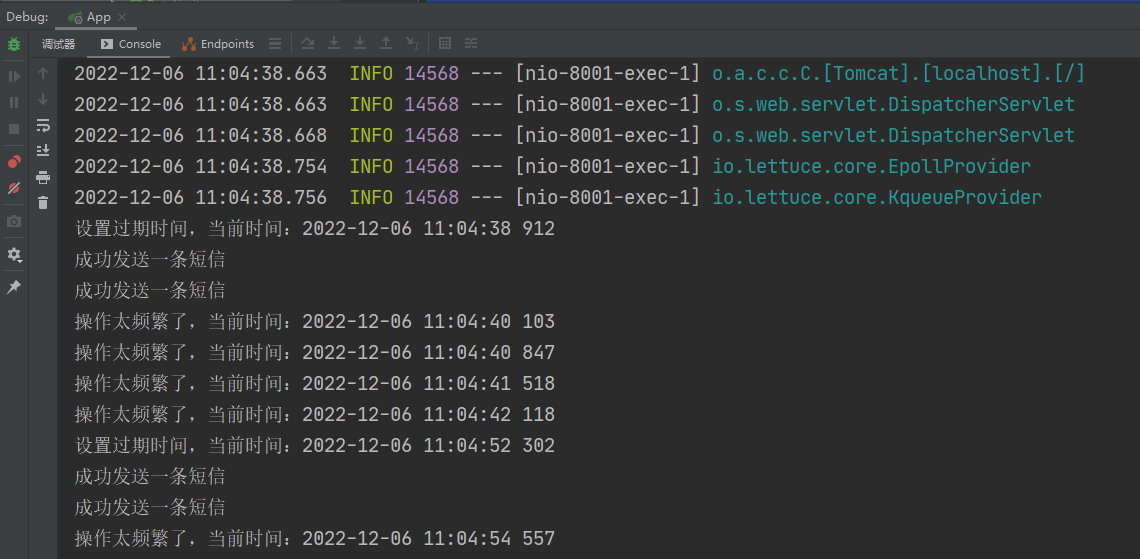
Redis实战案例
文章目录1、SpringBoot整合Redis1.1、新建项目1.2、接口编写1.3、集成Redis1.3、测试1.4、序列化问题2、Redis实现分布式缓存2.1、背景介绍2.2、代码编写2.3、缓存改造2.4、小结3、RedisAOP自定义注解,优雅实现分布式缓存3.1、自定义注解3.2、AOP切面类3.3、测试3.4…...

slice和splice区别
slice和splice区别 splice和slice是数组中的两个重要的方法。 slicesplice不会改变原数组改变原数组返回原数组中的部分元素返回原数组中被删除的元素组成的新数组用来选择数组中的元素用于在数组中插入或者删除元素 1.splice的语法 array.splice(index,howmany,item1,…,ite…...

动态规划从入门到精通-蓝桥杯
一、了解动态规划1.简单来说动态规划是一种状态转移与递推2.例题引入——最少硬币问题有多个不同面值的硬币(任意面值); 数量不限; 输入金额S,输出最少硬币组合。 (回顾用贪心求解硬币问题。)贪心法硬币面值1、2、5。支…...

Docker部署Prometheus
文章目录Prometheus相关介绍Docker部署Prometheus说明安装Prometheus搜索镜像拉取镜像配置启动容器进入容器遇到的问题Are you trying to mount a directory onto a file (or vice-versa)?其他可能的错误Prometheus相关介绍 官方介绍,非常的清楚: http…...

JavaScript的执行顺序
前言 在说 JavaScript 的执行顺序之前,我们先回答一下以下几组程序的输出结果 第 1 组 const output (v) > {console.log(v); };setTimeout(() > {console.log(1); }, 0); output(2); console.log(3);// 2 3 1第 2 组 new Promise((resolve) > {conso…...
C++11智能指针std::shared_ptr介绍及使用
介绍 shared_ptr是一种智能指针(smart pointer),作用有如同指针,但会记录有多少个shared_ptrs共同指向一个对象。这便是所谓的引用计数(reference counting),比如我们把只能指针赋值给另外一个对象,那么对象多了一个智能指针指向它,所以这个时候引用计数…...
 | 机试题+算法思路+考点+代码解析 【2023】)
华为OD机试 - 数字的排列(Python) | 机试题+算法思路+考点+代码解析 【2023】
数字的排列 题目 小华是个很有对数字很敏感的小朋友, 他觉得数字的不同排列方式有特殊的美感。 某天,小华突发奇想,如果数字多行排列, 第一行1个数, 第二行2个, 第三行3个, 即第n行n个数字,并且奇数行正序排列, 偶数行逆序排列,数字依次累加。 这样排列的数字一定很…...
-常见面试题)
Android 事件分发机制(4)-常见面试题
目录 1.你了解过Android的事件分发机制吗?请大致介绍一下 2、如果父view中不拦截down事件,拦截move,up事件,在子view中设置了requestDisallowInterceptTouchEvent(true);(请求父view不拦截事件)这个标志后,…...

计算机四级 [操作系统] | 选择题 2 重点标注版
1.某一个单道批处理系统几乎同时依次到达4个作业,这4个作业的预计运行时间分别为8、4、4和4分钟,按照短作业优先的调度算法运行,请问该批作业的平均周转时间为多少 B A. 14分钟 B. 11分钟 C. 20分钟 D. 10分钟 2.下列与进程具有一一对应的关…...

想玩好ChatGPT?不妨看看这篇文章
相信点进来的铁汁,此时已经对 ChatGPT 有所了解,并想上手体验一番 首先大伙儿要注意,不要被骗了。 现在很多商家提供的 ChatGPT 服务,不仅价格奇高,而且据我所知,有些压根不是 ChatGPT 。 想玩最好去官网注册,具体方法大伙自个儿查一查嗷。 怎么用好 ChatGPT 虽然 …...
day31 IO流
文章目录回顾collectionArrayTestListHashSetTsetHashMapTestPropertiesTreeSetTestIO流FileInputStreamTest01 文件流初步FileInputStreamTest02 循环读FileStreamTest03FileInputStreamTes04 需要掌握FiLeInputStreamTest5FileOutputStreamTest01Copy1 文件拷贝FileReaderTes…...

CANN-昇腾NPU-RAG推理-检索增强生成怎么部署
RAG(Retrieval-Augmented Generation)是 LLM 知识库的组合:先检索相关文档,再让 LLM 基于文档回答。昇腾NPU 上部署 RAG 需要两个组件:Embedding 模型(做向量检索)和 LLM(做生成&am…...

WarcraftHelper:魔兽争霸III现代兼容性问题的终极解决方案指南
WarcraftHelper:魔兽争霸III现代兼容性问题的终极解决方案指南 【免费下载链接】WarcraftHelper Warcraft III Helper , support 1.20e, 1.24e, 1.26a, 1.27a, 1.27b 项目地址: https://gitcode.com/gh_mirrors/wa/WarcraftHelper 魔兽争霸III作为经典即时战…...

如何快速集成 react-native-bottom-sheet-behavior:5 分钟搞定 Android 底部弹窗
如何快速集成 react-native-bottom-sheet-behavior:5 分钟搞定 Android 底部弹窗 【免费下载链接】react-native-bottom-sheet-behavior react-native wrapper for android BottomSheetBehavior 项目地址: https://gitcode.com/gh_mirrors/re/react-native-bottom…...

defx.nvim 安装与配置完全教程:从零开始搭建高效文件管理系统 [特殊字符]
defx.nvim 安装与配置完全教程:从零开始搭建高效文件管理系统 🚀 【免费下载链接】defx.nvim :file_folder: The dark powered file explorer implementation for neovim/Vim8 项目地址: https://gitcode.com/gh_mirrors/de/defx.nvim defx.nvim …...

yolo视频识别 车辆速度估计识别 yolo11视频实时速度测量与测速估计
文章目录YOLOv11:视频实时速度测量与测速估计一、YOLOv11概述二、速度测量原理三、距离测量方法四、应用场景五、实践案例以下是关于使用YOLOv11进行视频实时速度测量与测速估计的介绍: YOLOv11:视频实时速度测量与测速估计 随着计算机视觉…...

DAIR-V2X-V数据集深度评测:与KITTI、nuScenes比,它到底强在哪?
DAIR-V2X-V数据集深度评测:与KITTI、nuScenes比,它到底强在哪? 当技术团队着手开发面向中国道路的自动驾驶系统时,数据集的选择往往成为第一个关键决策点。过去十年间,KITTI和nuScenes等国际数据集一直是行业标杆&…...
)
用ESP32-C3的PWM做个RGB呼吸灯吧:从配置结构体到色彩渐变(乐鑫ESP-IDF实战)
ESP32-C3 RGB呼吸灯实战:从PWM配置到色彩渐变算法 当智能家居的灯光不再只是简单的开关控制,而是能像呼吸般自然渐变时,整个空间的氛围立刻变得生动起来。ESP32-C3凭借其出色的LED PWM控制器(LEDC)外设,为开…...

Unity中MMD初音资源导入与动画落地全流程指南
1. 这不是普通模型包:初音跳舞资源在Unity中的真实价值定位“Unity初音跳舞精品模型动画资源分享”——看到这个标题,很多刚接触Unity的美术向开发者第一反应是:“哇,能直接放进项目里做Demo了!”但我在带三个独立游戏…...

从零开始构建个人知识库:kepano-obsidian笔记模板完整指南
从零开始构建个人知识库:kepano-obsidian笔记模板完整指南 【免费下载链接】kepano-obsidian My personal Obsidian vault template. A bottom-up approach to note-taking and organizing things I am interested in. 项目地址: https://gitcode.com/gh_mirrors/…...

如何在5分钟内免费搭建工业级OpenPLC虚拟控制器
如何在5分钟内免费搭建工业级OpenPLC虚拟控制器 【免费下载链接】OpenPLC Software for the OpenPLC - an open source industrial controller 项目地址: https://gitcode.com/gh_mirrors/op/OpenPLC OpenPLC是一款功能强大的开源虚拟PLC(可编程逻辑控制器&a…...