使用Puppeteer构建博客内容的自动标签生成器

导语
标签是一种用于描述和分类博客内容的元数据,它可以帮助读者快速找到感兴趣的主题,也可以提高博客的搜索引擎优化(SEO)。然而,手动为每篇博客文章添加合适的标签是一件费时费力的工作,有时候也容易遗漏或重复。本文将介绍如何使用Puppeteer这个强大的Node.js库来构建一个博客内容的自动标签生成器,它可以根据博客文章的标题和正文内容,自动提取出最相关的标签,并保存到数据库中。
概述
Puppeteer是一个Node.js库,它提供了一个高级API来控制Chrome或Chromium浏览器。使用Puppeteer,我们可以实现各种浏览器自动化任务,例如网页抓取、网页截图、网页测试、PDF生成等。Puppeteer的核心功能是创建一个Browser对象,它代表了一个浏览器实例,然后通过Browser对象创建一个或多个Page对象,它代表了一个浏览器标签页。通过Page对象,我们可以对网页进行各种操作,例如导航、点击、输入、等待等。
为了构建一个博客内容的自动标签生成器,我们需要使用Puppeteer来完成以下步骤:
- 启动一个浏览器实例,并设置代理IP和User-Agent等选项,以提高爬虫效果和防止被目标网站屏蔽。
- 创建一个浏览器标签页,并打开目标博客网站的首页。
- 获取首页上所有博客文章的链接,并保存到一个数组中。
- 遍历数组中的每个链接,打开对应的博客文章页面,并获取文章的标题和正文内容。
- 使用一个第三方API(例如[Text Analysis API])来对文章的标题和正文内容进行自然语言处理(NLP),并返回最相关的标签。
- 将文章的链接、标题、正文内容和标签保存到数据库中(例如[MongoDB])。
- 关闭浏览器实例,并结束程序。
正文
下面我们来具体看看如何使用Puppeteer来实现上述步骤。
1. 启动浏览器实例
首先,我们需要安装Puppeteer这个Node.js库,可以使用npm命令:
npm install puppeteer
然后,在我们的JavaScript文件中,我们需要引入Puppeteer模块,并使用puppeteer.launch()方法来启动一个浏览器实例。这个方法接受一个可选的配置对象作为参数,我们可以在这里设置代理IP等选项。例如,我们可以使用亿牛云提供的爬虫代理IP服务,它可以帮助我们隐藏真实IP地址,并提供不同地区和运营商的IP资源。我们只需要在亿牛云爬虫代理官网注册一个账号,并获取相应的域名、端口、用户名和密码,然后在puppeteer.launch()方法中设置args属性和headless属性即可。args属性是一个数组,用于传递给浏览器进程的命令行参数。其中--proxy-server参数用于设置代理服务器地址,格式为protocol://username:password@host:port。headless属性是一个布尔值,用于设置是否以无头模式运行浏览器,即是否显示浏览器界面。如果设置为false,则可以看到浏览器的操作过程,方便调试。我们还可以设置userAgent属性,用于设置浏览器的用户标识字符串,以模拟不同的浏览器和设备类型。例如,我们可以使用[User-Agent Switcher]这个Chrome扩展程序来获取不同的用户标识字符串,并随机选择一个作为参数。下面是一个示例代码:
// 引入Puppeteer模块
const puppeteer = require('puppeteer');// 定义亿牛云爬虫代理的域名、端口、用户名和密码
const proxyHost = 'http://www.16yun.cn';
const proxyPort = '8100';
const proxyUser = '16YUN';
const proxyPass = '16IP';// 定义一个用户标识字符串数组
const userAgents = ['Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36','Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/14.1.2 Safari/605.1.15','Mozilla/5.0 (iPhone; CPU iPhone OS 14_7_1 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/14.0 Mobile/15E148 Safari/604.1','Mozilla/5.0 (Linux; Android 11; SM-G998B) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Mobile Safari/537.36'
];// 随机选择一个用户标识字符串
const userAgent = userAgents[Math.floor(Math.random() * userAgents.length)];// 启动一个浏览器实例,并设置亿牛云爬虫代理
(async () => {const browser = await puppeteer.launch({args: [`--proxy-server=${proxyUser}:${proxyPass}@${proxyHost}:${proxyPort}`],headless: false,userAgent: userAgent});
})();
2. 创建浏览器标签页,并打开目标博客网站的首页
启动浏览器实例后,我们可以使用browser.newPage()方法来创建一个新的浏览器标签页,并返回一个Page对象。然后,我们可以使用page.goto()方法来打开目标博客网站的首页,并等待页面加载完成。这个方法接受一个URL字符串作为参数,以及一个可选的配置对象,其中可以设置waitUntil属性,用于指定何时认为页面导航完成。我们可以设置为networkidle2,表示当网络连接数小于等于2时,认为页面导航完成。下面是一个示例代码:
// 创建一个新的浏览器标签页,并返回一个Page对象
const page = await browser.newPage();// 定义目标博客网站的首页URL
const blogUrl = 'https://example.com';// 打开目标博客网站的首页,并等待页面加载完成
await page.goto(blogUrl, {waitUntil: 'networkidle2'});
3. 获取首页上所有博客文章的链接,并保存到一个数组中
打开目标博客网站的首页后,我们可以使用page.$$eval()方法来获取首页上所有博客文章的链接,并保存到一个数组中。这个方法接受两个参数,第一个参数是一个选择器字符串,用于指定要匹配的元素;第二个参数是一个回调函数,用于对匹配到的元素进行操作,并返回结果。例如,我们可以使用CSS选择器a.post-link来匹配所有包含博客文章链接的a元素;然后在回调函数中,我们可以使用Array.from()方法来将匹配到的元素转换为数组
4. 遍历数组中的每个链接,打开对应的博客文章页面,并获取文章的标题和正文内容
获取到首页上所有博客文章的链接后,我们可以使用for...of循环来遍历数组中的每个链接,然后使用page.goto()方法来打开对应的博客文章页面,并等待页面加载完成。然后,我们可以使用page.$eval()方法来获取文章的标题和正文内容,并保存到一个对象中。这个方法接受两个参数,第一个参数是一个选择器字符串,用于指定要匹配的元素;第二个参数是一个回调函数,用于对匹配到的元素进行操作,并返回结果。例如,我们可以使用CSS选择器h1.post-title来匹配文章的标题元素;然后在回调函数中,我们可以使用element.textContent属性来获取元素的文本内容,并返回结果。同理,我们可以使用CSS选择器div.post-content来匹配文章的正文内容元素,并返回结果。下面是一个示例代码:
// 定义一个空数组,用于存放所有博客文章的信息
const posts = [];// 遍历数组中的每个链接
for (const link of links) {// 打开对应的博客文章页面,并等待页面加载完成await page.goto(link, {waitUntil: 'networkidle2'});// 获取文章的标题和正文内容,并保存到一个对象中const post = await page.$eval('h1.post-title', element => {return {title: element.textContent, // 获取元素的文本内容content: element.nextElementSibling.textContent // 获取元素的下一个兄弟元素(正文内容元素)的文本内容};});// 将对象添加到数组中posts.push(post);
}
5. 使用一个第三方API来对文章的标题和正文内容进行自然语言处理,并返回最相关的标签
获取到所有博客文章的标题和正文内容后,我们可以使用一个第三方API来对文章的标题和正文内容进行自然语言处理,并返回最相关的标签。这里我们可以使用[Text Analysis API]这个免费的API服务,它提供了多种自然语言处理功能,例如情感分析、关键词提取、实体识别、摘要生成等。我们可以使用它提供的关键词提取功能,来根据文章的标题和正文内容,自动提取出最相关的标签,并返回一个数组。为了使用这个API服务,我们需要先在[Text Analysis API]官网注册一个账号,并获取一个API密钥(API Key)。然后,我们可以使用Node.js内置的[http]模块来发送HTTP请求,并处理响应结果。下面是一个示例代码:
// 引入http模块
const http = require('http');// 定义Text Analysis API的URL和API密钥
const apiUrl = 'http://api.meaningcloud.com/topics-2.0';
const apiKey = '0123456789abcdef0123456789abcdef';// 定义一个函数,用于发送HTTP请求,并返回一个Promise对象
function request(options, data) {return new Promise((resolve, reject) => {// 创建一个HTTP请求对象const req = http.request(options, res => {// 定义一个空字符串,用于存放响应数据let body = '';// 监听data事件,将响应数据拼接到字符串中res.on('data', chunk => {body += chunk;});// 监听end事件,将字符串转换为JSON对象,并调用resolve函数res.on('end', () => {resolve(JSON.parse(body));});});// 监听error事件,调用reject函数req.on('error', err => {reject(err);});// 将请求数据写入请求对象中req.write(data);// 结束请求req.end();});
}// 定义一个函数,用于对文章的标题和正文内容进行自然语言处理,并返回最相关的标签
async function getTags(title, content) {// 定义请求选项,包括请求方法、请求头和请求路径const options = {method: 'POST',headers: {'Content-Type': 'application/x-www-form-urlencoded'},path: apiUrl};// 定义请求数据,包括API密钥、语言、文章标题和文章正文内容const data = `key=${apiKey}&lang=en&txt=${title} ${content}&tt=a`;// 发送HTTP请求,并等待响应结果const response = await request(options, data);// 定义一个空数组,用于存放最相关的标签const tags = [];// 判断响应结果的状态码是否为0,表示成功if (response.status.code === '0') {// 遍历响应结果中的实体数组,提取每个实体的名称,并添加到标签数组中for (const entity of response.entity_list) {tags.push(entity.form);}}// 返回标签数组return tags;
}
6. 将文章的链接、标题、正文内容和标签保存到数据库中
获取到所有博客文章的链接、标题、正文内容和标签后,我们可以将它们保存到数据库中,以便后续的使用和分析。这里我们可以使用[MongoDB]这个免费的开源数据库,它是一种基于文档的数据库,适合存储JSON格式的数据。为了使用[MongoDB],我们需要先在[MongoDB]官网注册一个账号,并创建一个云数据库集群(Cluster)。然后,我们可以使用[MongoDB Node.js Driver]这个Node.js库来连接和操作数据库。为了使用这个库,我们需要先安装它,可以使用npm命令:
npm install mongodb
然后,在我们的JavaScript文件中,我们需要引入MongoDB模块,并使用MongoClient类来创建一个客户端对象。然后,我们可以使用client.connect()方法来连接数据库,并返回一个Promise对象。这个方法接受一个URL字符串作为参数,用于指定数据库的地址和配置选项。我们可以在[MongoDB]官网获取到这个URL字符串,并替换其中的用户名和密码。然后,在Promise对象的回调函数中,我们可以使用client.db()方法来获取一个数据库对象,并指定数据库的名称;然后使用db.collection()方法来获取一个集合对象,并指定集合的名称。集合相当于关系型数据库中的表,用于存储文档(Document)。然后,我们可以使用collection.insertMany()方法来将所有博客文章的信息作为文档插入到集合中,并返回一个Promise对象。这个方法接受一个数组作为参数,数组中的每个元素都是一个文档对象。最后,在Promise对象的回调函数中,我们可以打印出插入结果,并关闭数据库连接。下面是一个示例代码:
// 引入MongoDB模块
const { MongoClient } = require('mongodb');// 定义MongoDB的URL字符串
const mongoUrl = 'mongodb+srv://username:password@cluster0.example.com/mydb';// 创建一个客户端对象
const client = new MongoClient(mongoUrl);// 连接数据库,并返回一个Promise对象
client.connect().then(() => {// 获取一个数据库对象,并指定数据库名称const db = client.db('mydb');// 获取一个集合对象,并指定集合名称const collection = db.collection('posts');// 将所有博客文章的信息作为文档插入到集合中,并返回一个Promise对象collection.insertMany(posts).then(result => {// 打印出插入结果console.log(result);// 关闭数据库连接client.close();});
});
7. 关闭浏览器实例,并结束程序
完成所有操作后,我们可以使用browser.close()方法来关闭浏览器实例,并结束程序。
结语
本文介绍了如何使用Puppeteer这个强大的Node.js库来构建一个博客内容的自动标签生成器,它可以根据博客文章的标题和正文内容,自动提取出最相关的标签,并保存到数据库中。这样,我们就可以省去手动为每篇博客文章添加合适的标签的工作,也可以提高博客的搜索引擎优化(SEO)。
相关文章:
使用Puppeteer构建博客内容的自动标签生成器
导语 标签是一种用于描述和分类博客内容的元数据,它可以帮助读者快速找到感兴趣的主题,也可以提高博客的搜索引擎优化(SEO)。然而,手动为每篇博客文章添加合适的标签是一件费时费力的工作,有时候也容易遗漏…...
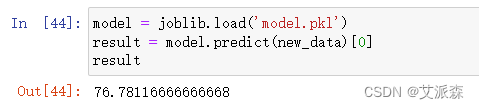
大数据分析案例-基于随机森林算法构建二手房价格预测模型
🤵♂️ 个人主页:艾派森的个人主页 ✍🏻作者简介:Python学习者 🐋 希望大家多多支持,我们一起进步!😄 如果文章对你有帮助的话, 欢迎评论 💬点赞Ǵ…...
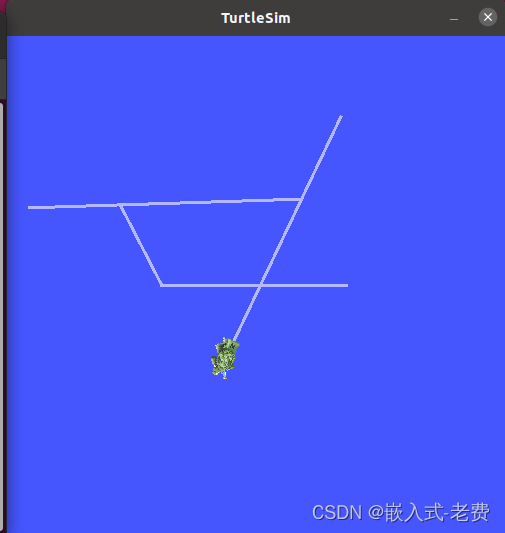
SLAM从入门到精通(ROS安装)
【 声明:版权所有,欢迎转载,请勿用于商业用途。 联系信箱:feixiaoxing 163.com】 ROS科研上面用的多,实际生产其实用的也不少。它本身还是很好的应用框架。当然,它对于很多初学的同学来说还是很友好的。学完…...
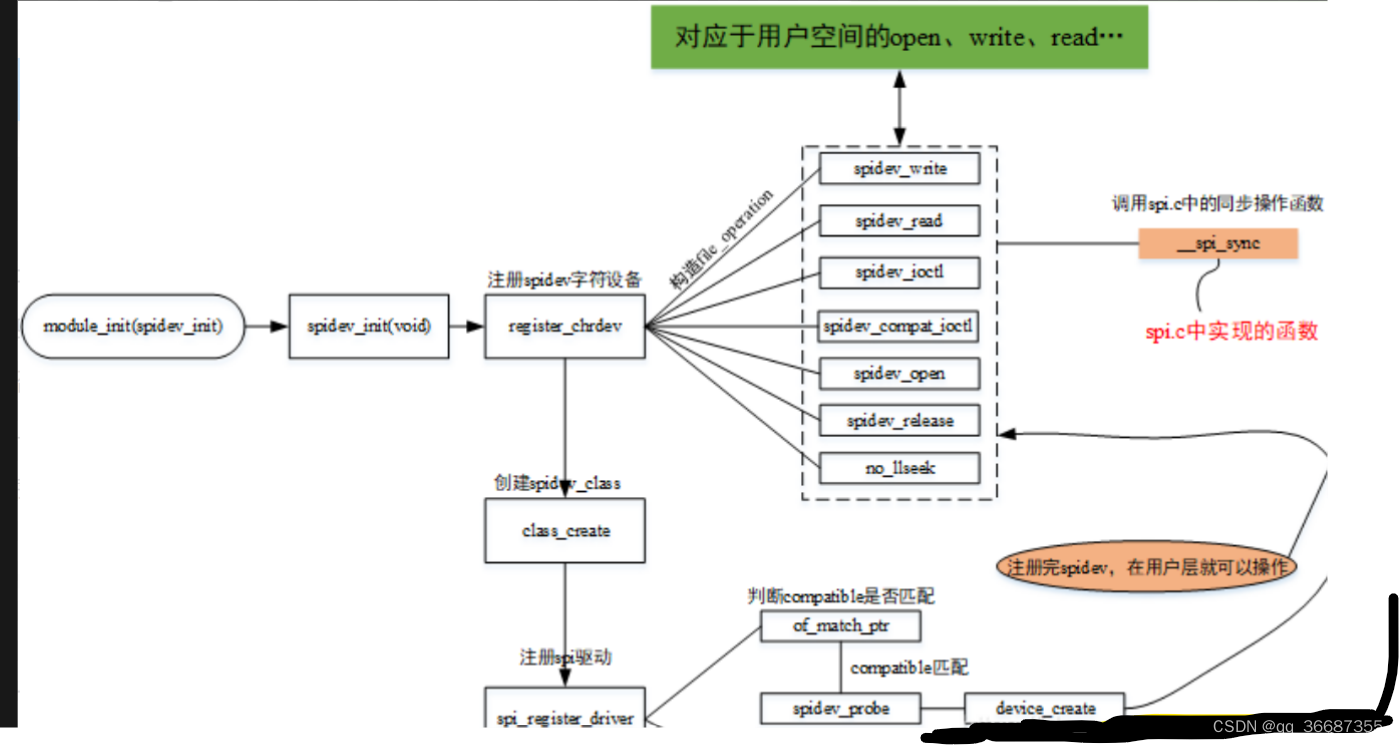
Linux 下spi设备驱动
参考: Linux kernel 有关 spi 设备树参数解析 Linux kernel 有关 spi 设备树参数解析 - 走看看 Linux SPI驱动框架(1)——核心层 Linux SPI驱动框架(1)——核心层_linux spi驱动模型_绍兴小贵宁的博客-CSDN博客 Linux SPI驱动框架(2)——控制器驱动层 Linux SPI驱…...

一:图形的位置和尺寸测量
绘制的基本要素: onDraw(Canvas):是用来重写的 Canvas:实际执行绘制的 Paint:调整粗细和颜色等 坐标系:以屏幕左上角为原点,向右、向下为正向数值的坐标系 尺寸单位:在绘制过程中所有的尺寸单位都是px…...
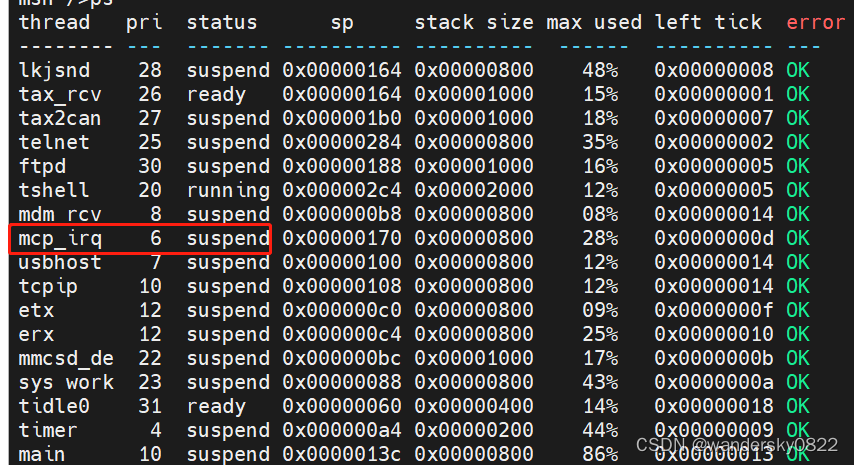
rtthread下基于spi device架构MCP25625驱动
1.CAN驱动架构 由于采用了RTT的spi device架构,不能再随心所遇的编写CAN驱动 了,之前内核虽然采用了RTT内核,但是驱动并没有严格严格按RTT推荐的架构来做,这次不同了,上次是因为4个MCP25625挂在了4路独立的SPI总线上&…...
)
Open3D 点云投影到圆柱(python详细过程版)
目录 一、算法原理1、圆柱方程2、投影原理二、代码实现三、结果展示1、原始点云2、投影结果四、参考链接一、算法原理 1、圆柱方程 圆柱方程可以表示为: ( x − x...
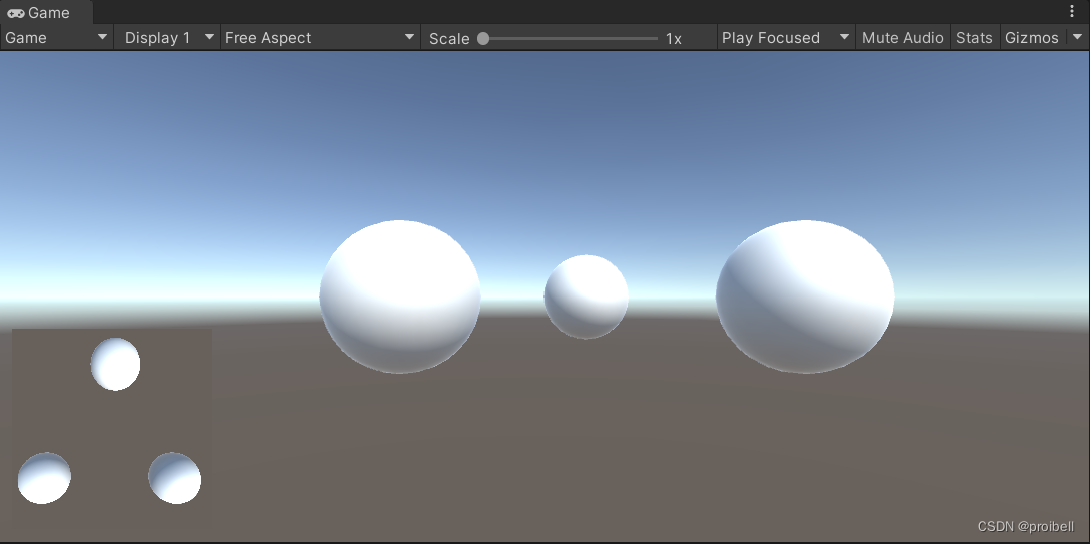
Unity实战(10):如何将某个相机的画面做成贴图(RenderTexture)
目录 前言 一、创建物体、材质与相机 二、将RenderTexture赋给材质 2.1 修改rt1的一些属性 2.2 将rtMat1材质的shader改为Unlit/Texture,并将rt1赋给这个材质 三、效果呈现 前言 本文记录如何将某个相机的画面做成贴图,即游戏某些场景中小地图做法…...

STL- 函数对象
1 函数对象 1.1 函数对象概念 概念: 重载函数调用操作符的类,其对象常称为函数对象函数对象使用重载的()时,行为类似函数调用,也叫仿函数 本质: 函数对象(仿函数)是一个类,不是一个函数 1.2 函数对象…...
前端 JS 经典:上传文件
重点:multipart/form-data 后端识别上传类型必填 1. form 表单上传 <!-- enctype"multipart/form-data" 这个必填 --> <form action"http://127.0.0.1:8080/users/avatar" method"post" enctype"multipart/form-data…...

数据分析面试
数据分析相关的职位面试可以拆解为以下三块: 1)技术基础 2)项目经验提问 3)业务问题 【数据分析与挖掘(二)】面试题汇总(附答案)_数据分析面试常见问题及答案_youthlost的博客-CSDN博客 我裸辞去面试p…...

Open3D(C++) 整体最小二乘拟合平面
目录 一、算法原理1、算法过程2、参考文献二、代码实现三、结果展示本文由CSDN点云侠原创,原文链接。 一、算法原理 1、算法过程 最小二乘拟合平面认为点云数据系数矩阵不存在误差,然而由于观测条件的限制,观测向量、系数矩阵都有可能存在误差,那么最小二乘方法就不再是最…...

【android12-linux-5.1】【ST芯片】【RK3588】【LSM6DSR】HAL源码分析
一、环境介绍 RK3588主板搭载Android12操作系统,内核是Linux5.10,使用ST的六轴传感器LSM6DSR芯片。 二、芯片介绍 LSM6DSR是一款加速度和角速度(陀螺仪)六轴传感器,还内置了一个温度传感器。该芯片可以选择I2C,SPI通讯,还有可编程终端,可以后置摄像头等设备,功能是很…...

MT8788安卓核心板详细参数_MTK安卓主板开发板智能通讯模块
MT8788安卓核心板集成了一个高效的12nm SoC,内置4G LTE调制解调器,将强大的硬件与到处可连接的全面功能设计相结合。 MTK8788智能终端具备许多功能,包括4G、2.4G/5G双频WiFi、蓝牙4.2BLE、2.5W功放、USB、mipi屏接口、三路摄像头接口、GPS和…...

C++String模拟实现
实际上string没什么可讲,主要是对string函数的运用与理解,与其写库函数如何用,不如直接去看c库函数来得好。 以下是自己实现string功能函数。但没对string库中的全部函数进行实现,而是实现主要使用的。 .cpp内是用来测试函数功能…...
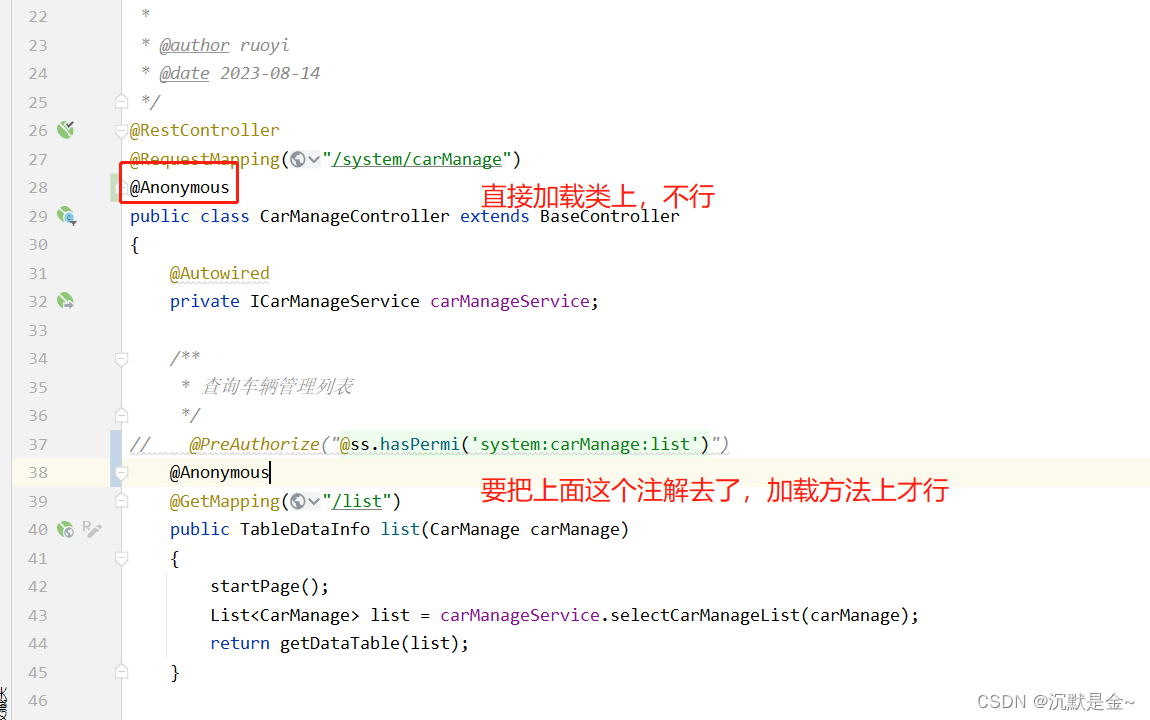
Java 设置免登录请求接口被拦截问题
1、在设置免登录时,前端将请求的路由添加到白名单后,请求接口还是被拦截到了,将请求接口也设置后还是会被拦截跳转到登录页面 通过JAVA 注解 Anonymous 进行设置匿名访问就可以了...
(其他) 剑指 Offer 67. 把字符串转换成整数 ——【Leetcode每日一题】
❓ 剑指 Offer 67. 把字符串转换成整数 难度:中等 写一个函数 StrToInt,实现把字符串转换成整数这个功能。不能使用 atoi 或者其他类似的库函数。 首先,该函数会根据需要丢弃无用的开头空格字符,直到寻找到第一个非空格的字符为…...

【MySQL】一文详解MySQL,从基础概念到调优
作者简介 前言 博主之前写过一个MySQL的系列,从基础概念、SQL到底层原理、优化,专栏地址: https://blog.csdn.net/joker_zjn/category_12305262.html?spm1001.2014.3001.5482 本文会是这个系列的清单,拉通来聊一聊Mysql从基础概…...
机器学习——boosting之提升树
提升树和adaboost基本流程是相似的 我看到提升树的时候,懵了 这…跟adaboost有啥区别??? 直到看到有个up主说了,我才稍微懂 相当于,我在adaboost里的弱分类器,换成CART决策树就好了呗࿱…...

解决Spring Boot启动错误的技术指南
🌷🍁 博主猫头虎(🐅🐾)带您 Go to New World✨🍁 🦄 博客首页——🐅🐾猫头虎的博客🎐 🐳 《面试题大全专栏》 🦕 文章图文…...

浏览器标签页管理新思路:基于服务化架构的TabStack-OpenClaw实践
1. 项目概述与核心价值最近在整理浏览器标签页时,我又一次陷入了那种熟悉的焦虑:几十个标签页像一堵墙一样堆在浏览器顶部,每个都代表着一个“稍后阅读”的承诺,但最终它们都变成了数字垃圾。我尝试过各种标签页管理扩展ÿ…...

DuClaw智能体:使用手册
学习并使用技能DuClaw 在创建时已为您预置部分常用技能,可根据任务需求自动匹配调用。查看已有技能1.进入对话界面,单击“技能平台”按钮,并在弹窗中单击“查看我的技能”。2.DuClaw会回复您当前已安装的技能以及相应的技能信息。安装并使用技…...

金融数据分析实战:从Python工具链到量化策略回测全流程解析
1. 项目概述:为什么我们需要一个“金融技能”仓库?在金融行业摸爬滚打了十几年,我见过太多聪明人因为工具和方法的缺失,在数据分析和决策上走了弯路。无论是刚入行的分析师,还是希望提升个人理财能力的职场人ÿ…...

【多智能体】多智能体多视角三维空间定位的神经动力学方法【含Matlab源码 15447期】
💥💥💥💥💥💥💥💥💞💞💞💞💞💞💞💞💞Matlab武动乾坤博客之家💞…...

Win11Debloat:一键打造纯净高效的Windows 11终极优化指南
Win11Debloat:一键打造纯净高效的Windows 11终极优化指南 【免费下载链接】Win11Debloat A simple, lightweight PowerShell script that allows you to remove pre-installed apps, disable telemetry, as well as perform various other changes to declutter and…...

基于MCP协议构建AI驱动的企业安全自动化平台
1. 项目概述:一个连接AI与安全工具的桥梁最近在折腾AI助手(比如Claude Desktop、Cursor)的扩展能力时,发现了一个挺有意思的项目:sanyambassi/thales-cdsp-crdp-mcp-server。乍一看这个仓库名,又是Thales&a…...

为什么你的赛博朋克2077需要Cyber Engine Tweaks?5个关键优化场景解析
为什么你的赛博朋克2077需要Cyber Engine Tweaks?5个关键优化场景解析 【免费下载链接】CyberEngineTweaks Cyberpunk 2077 tweaks, hacks and scripting framework 项目地址: https://gitcode.com/gh_mirrors/cy/CyberEngineTweaks Cyber Engine Tweaks是专…...

Flowframes:3分钟掌握Windows平台AI视频插帧完整指南
Flowframes:3分钟掌握Windows平台AI视频插帧完整指南 【免费下载链接】flowframes Flowframes Windows GUI for video interpolation using DAIN (NCNN) or RIFE (CUDA/NCNN) 项目地址: https://gitcode.com/gh_mirrors/fl/flowframes 你是否曾经观看24帧视频…...

API Key认证系统设计:企业级API开放平台实践
API Key认证系统设计:企业级API开放平台实践 摘要:当AI应用从内部工具转向对外开放时,如何确保接口安全、防止滥用并实现精细化权限控制?本文基于一个真实的跑步教练AI项目,详细解析如何构建一套生产级的API Key认证系…...

揭秘qmc-decoder:三步解锁QQ音乐加密音频的终极指南
揭秘qmc-decoder:三步解锁QQ音乐加密音频的终极指南 【免费下载链接】qmc-decoder Fastest & best convert qmc 2 mp3 | flac tools 项目地址: https://gitcode.com/gh_mirrors/qm/qmc-decoder 你是否曾经下载了心爱的QQ音乐歌曲,却发现只能在…...