华为数据管理——《华为数据之道》
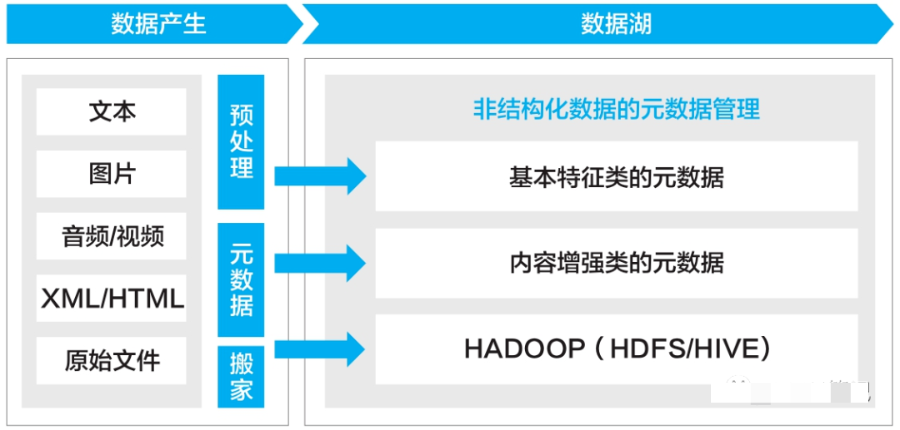
数据分析与开发
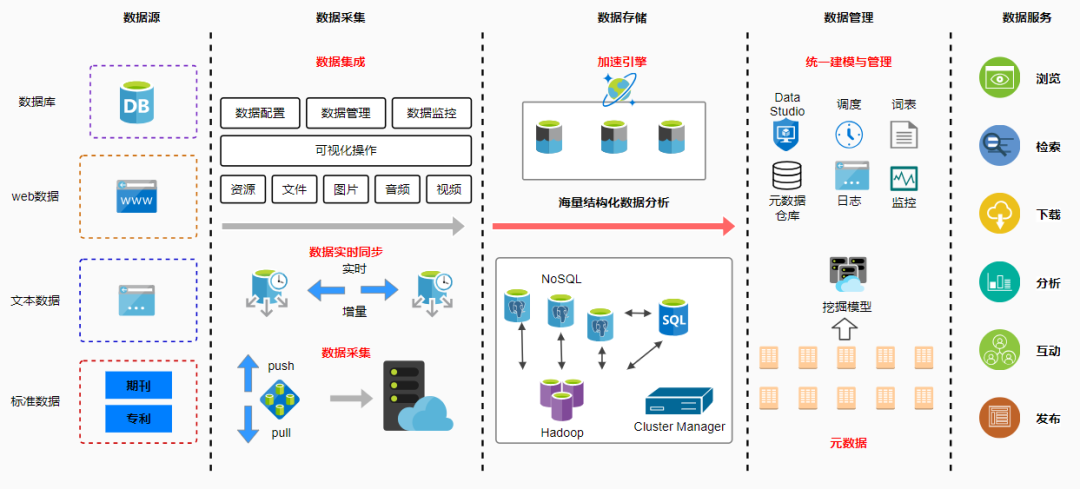
元数据是描述数据的数据,用于打破业务和IT之间的语言障碍,帮助业务更好地理解数据。
元数据是数据中台的重要的基础设施,元数据治理贯彻数据产生、加工、消费的全过程,沉淀了数据资产,搭建了技术和业务的桥梁。
本文目录:
一、华为数据分类管理框架
二、元数据治理面临的挑战
三、元数据管理架构及策略
四、元数据与一体化建模管理
五、元数据与数据湖管理
六、元数据与数据服务管理
七、元数据与构建数据地图
一、 华为数据分类管理框架
华为根据数据特性及治理方法的不同对数据进行了分类定义:
(1) 内部数据和外部数据
(2) 结构化数据和非结构化数据。结构化数据又进一步划分为基础数据、主数据、事务数据、报告数据、观测数据和规则数据。
(3) 元数据
华为数据分类管理框架如图所示:
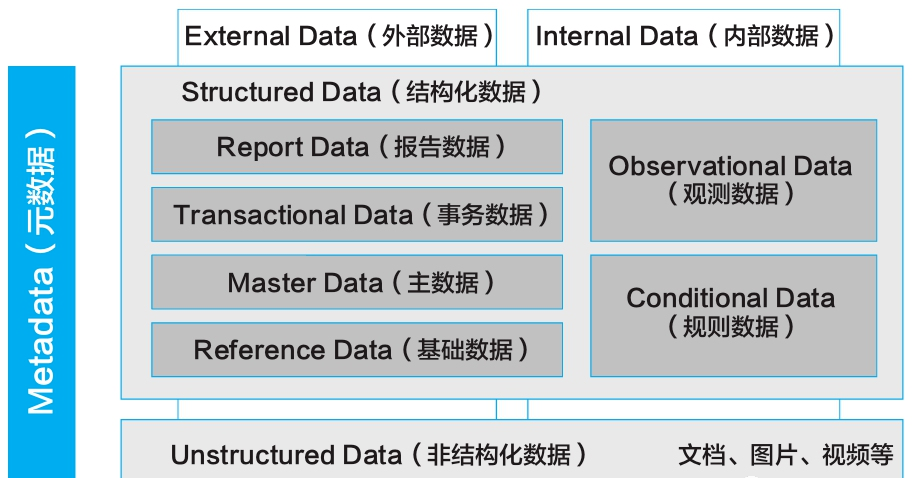
无论结构化数据,还是非结构化数据,或者内部数据还是外部数据,最终都会通过元数据治理落地。
华为将元数据治理贯穿整个数据价值流,覆盖从数据产生、汇聚、加工到消费的全生命周期。
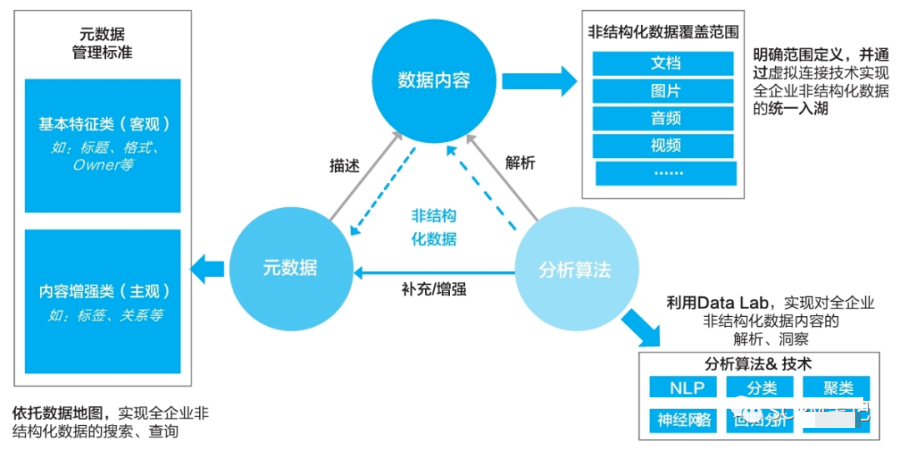
相较于结构化数据,非结构化元数据管理除了需要管理文件对象的标题、格式、Owner等基本特征和定义外,还需对数据内容的客观理解进行管理,如标签、相似性检索、相似性连接等,以便于用户搜索和消费使用。因此,非结构化数据的治理核心是对其基本特征与内容进行提取,并通过元数据落地来开展的。
非结构化数据的管理模型如图所示
二、 元数据治理面临的挑战
华为在进行元数据治理以前,遇到的元数据问题主要表现为数据找不到、读不懂、不可信,数据分析师们往往会陷入数据沼泽中,例如以下常见的场景:
● 某子公司需要从发货数据里对设备保修和维保进行区分,用来不对过保设备进行服务场景分析。为此,数据分析师需面对几十个IT系统,不知道该从哪里拿到合适的数据。
● 因盘点内部要货的研发领料情况,需要从IT系统中获取研发内部的要货数据,面对复杂的数据存储结构(涉及超过40个物理表和超过1000个字段)、物理层和业务层脱离的情况,业务部门的数据分析师无法读懂物理层数据,只能提出需求向IT系统求助。
● 某子公司存货和收入管理需要做繁重的数据收集与获取工作,运行一次计划耗时超过20个小时。同时,由于销售、供应、交付各领域计划的语言不通,还需要数据分析师进行大量人工转换与人工校验。
以上场景频繁出现在公司日常运营的各个环节,极大地阻碍了公司数字化转型的进行,其根本原因就在于:
1) 业务元数据与技术元数据未打通,导致业务读不懂IT系统中的数据。
2) 缺乏面向普通业务人员的准确、高效的数据搜索工具,业务人员无法快速获取可信数据。
元数据管理的痛点如图所示
为解决以上痛点,华为建立了公司级的元数据管理机制:
-
制定了统一的元数据管理方法、机制和平台,拉通业务语言和机器语言。
-
确保数据“入湖有依据,出湖可检索”成为华为元数据管理的使命与目标。
-
基于高质量的元数据,通过数据地图就能在企业内部实现方便的数据搜索。
元数据通常分为业务、技术和操作三类:
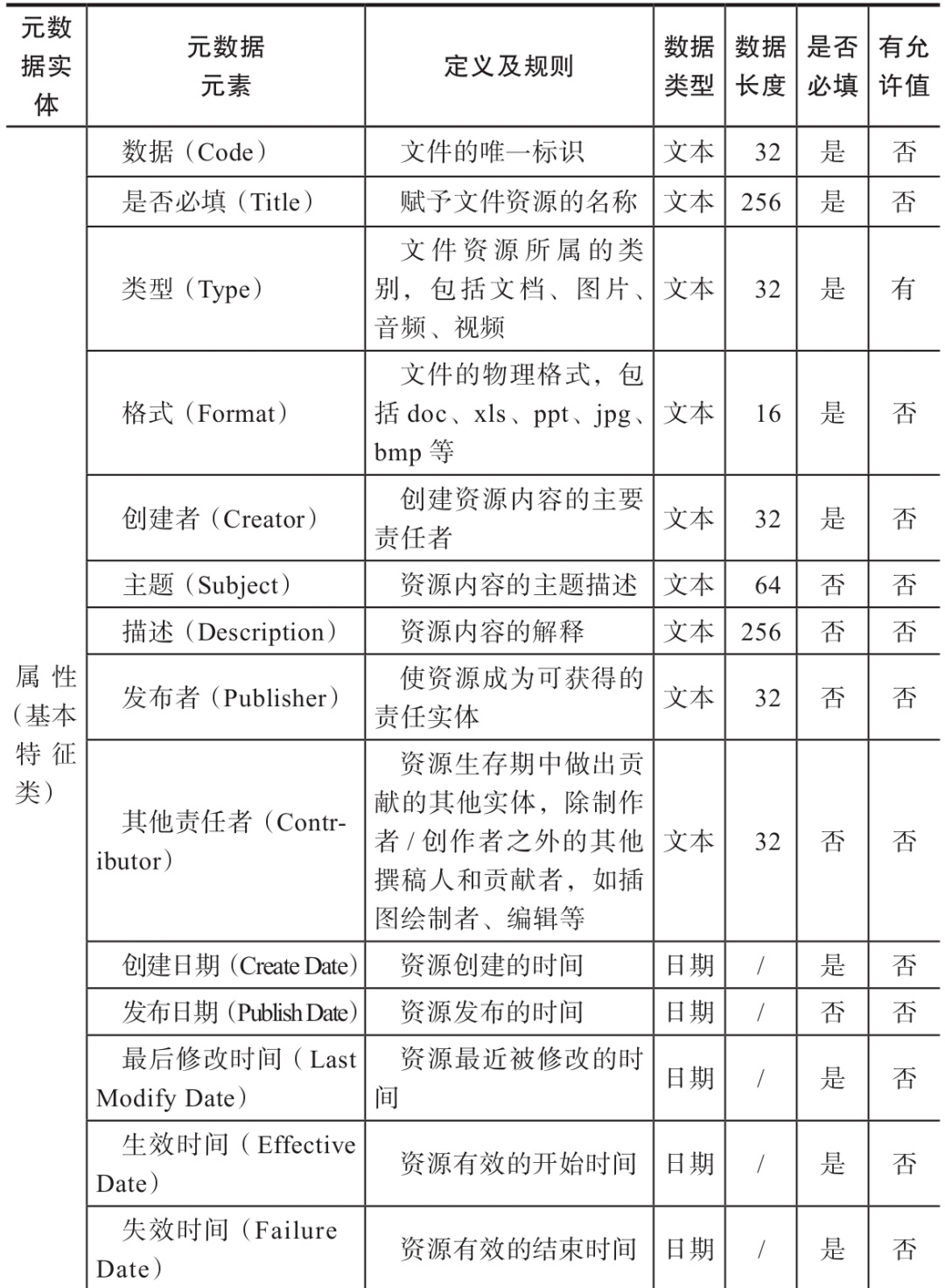
1) 业务元数据:用户访问数据时了解业务含义的途径,包括资产目录、Owner、数据密级等。
2) 技术元数据:实施人员开发系统时使用的数据,包括物理模型的表与字段、ETL规则、集成关系等。
3) 操作元数据:数据处理日志及运营情况数据,包括调度频度、访问记录等。
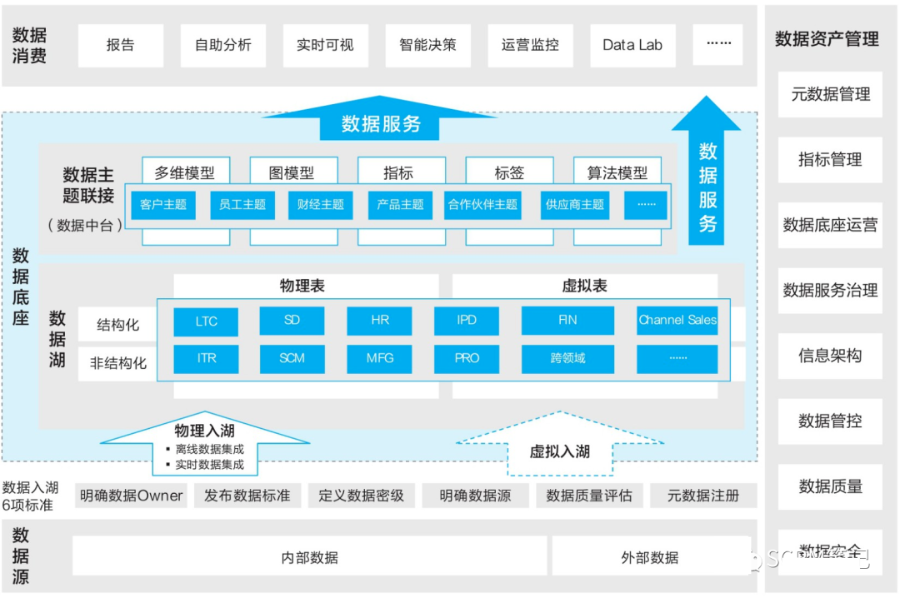
在企业的数字化运营中,元数据作用于整个价值流,在从数据源到数据消费的五个环节中都能充分体现元数据管理的价值:
(1) 数据消费侧:元数据能支持企业指标、报表的动态构建。
(2) 数据服务侧:元数据支持数据服务的统一管理和运营,并实现利用元数据驱动IT敏捷开发。
(3) 数据主题侧:元数据统一管理分析模型,敏捷响应井喷式增长的数据分析需求,支持数据增值、数据变现。
(4) 数据湖侧:元数据能实现暗数据的透明化,增强数据活性,并能解决数据治理与IT落地脱节的问题。
(5) 数据源侧:元数据支撑业务管理规则有效落地,保障数据内容合格、合规。
三、 元数据管理架构及策略
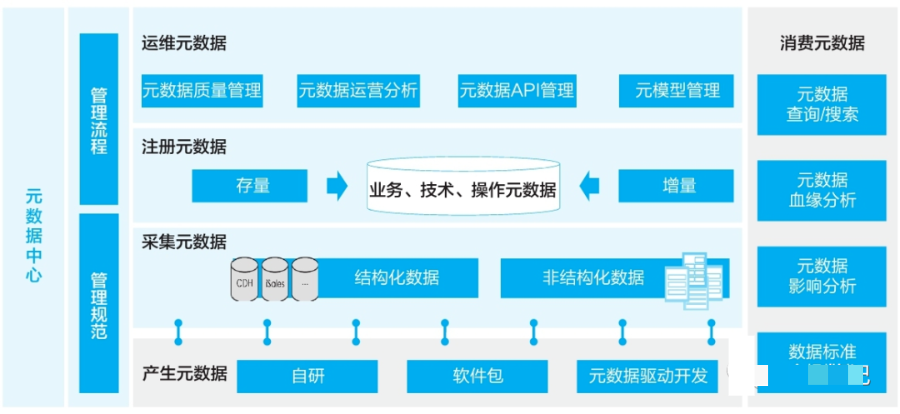
元数据管理架构包括产生元数据、采集元数据、注册元数据和运维元数据:
1) 产生元数据:制定元数据管理相关流程与规范的落地方案,在IT产品开发过程中实现业务元数据与技术元数据的连接。
2) 采集元数据:通过统一的元模型从各类IT系统中自动采集元数据。
3) 注册元数据:基于增量与存量两种场景,制定元数据注册方法,完成底座元数据注册工作。
4) 运维元数据:打造公司元数据中心,管理元数据产生、采集、注册的全过程,实现元数据运维。
5) 元数据管理方案:通过制定元数据标准、规范、平台与管控机制,建立企业级元数据管理体系,并推动其在公司各领域落地,支撑数据底座建设与数字化运营。
华为元数据管理整体方案如图所示
(一) 产生元数据
1、明确业务元数据、技术元数据和操作元数据之间的关系,定义华为公司元数据模型,如图所示。
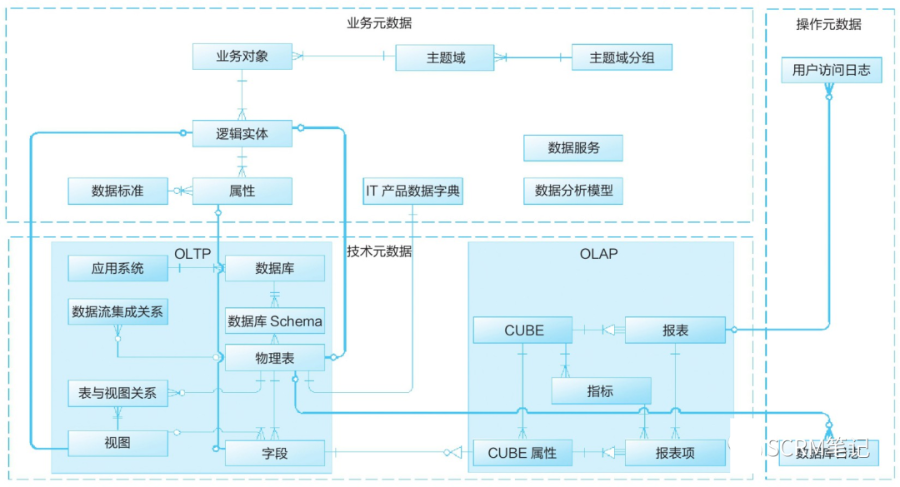
2、针对找数据及获取数据难的痛点,明确业务元数据、技术元数据、操作元数据的设计原则。
1)业务元数据设计原则
● 一个主题域分组下有多个主题域,一个主题域下有多个业务对象,一个业务对象下有多个逻辑实体,一个逻辑实体下有多个属性,一个属性有一个数据标准。
● 每个数据标准可被一个或多个属性引用,每个属性归属于一个逻辑实体,每个逻辑实体归属于一个业务对象,每个业务对象归属于一个主题域,每个主题域归属于一个主题域分组。
2)技术元数据设计原则
● 物理表设计须满足三范式,如为了降低系统的总体资源消耗,提高查询效率,可反范式设计。
● 物理表、视图和字段的设计须基于用途进行分类。
● 承载业务用途的物理表、虚拟表、视图必须与逻辑实体一一对应,承载业务用途的字段必须与属性一一对应。
● 系统间的数据传递须优先采用数据服务。
3)操作元数据设计原则
日志目的不同的进行分类设计,日志目的相同的进行相同设计(非自研场景按软件包适配)。
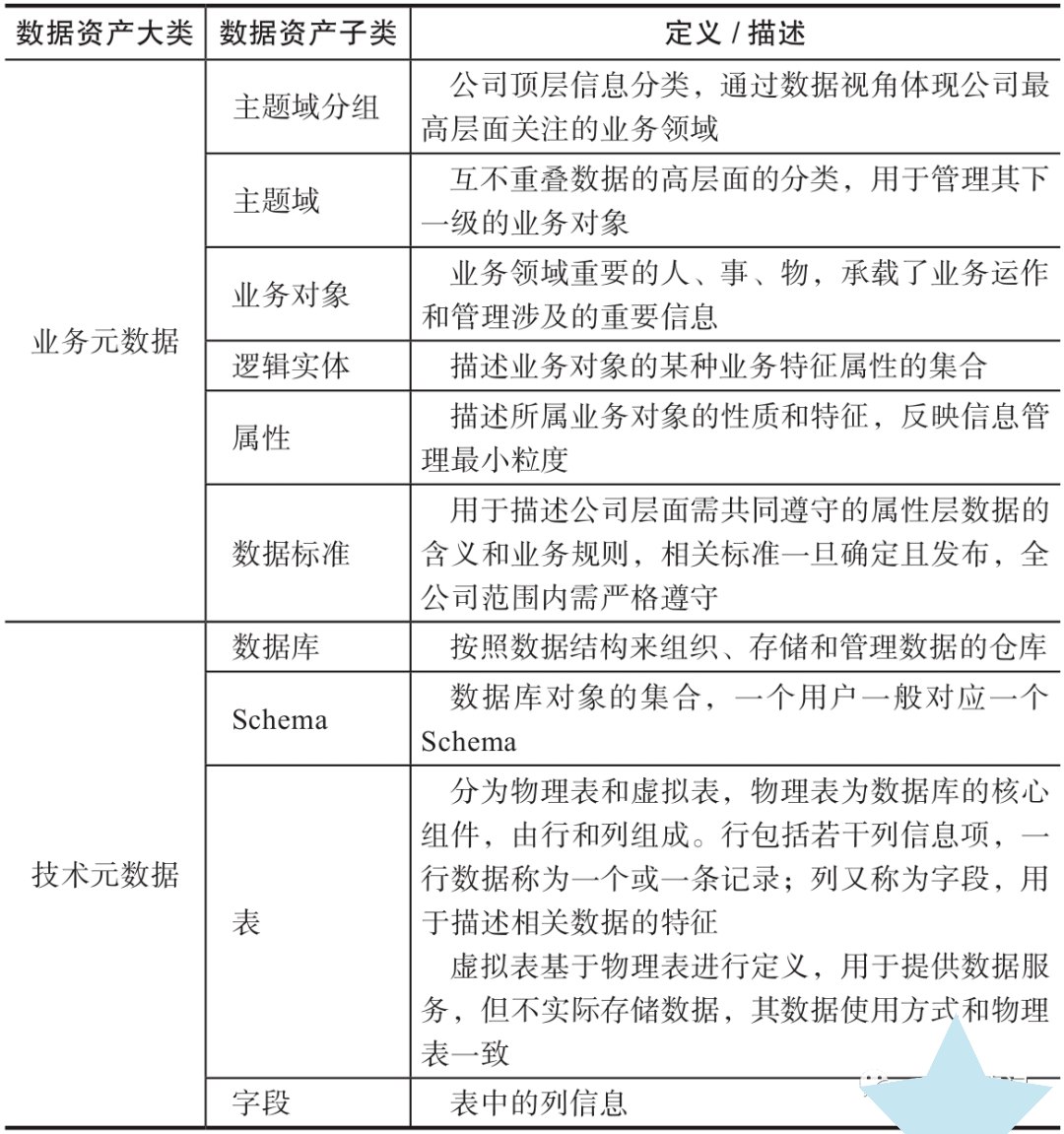
3、规范数据资产管理,设计数据资产编码规范
1)数据资产编码规范
华为数据资产编码的主要包括业务元数据和技术元数据两大类,其中业务元数据包含主题域分组、主题域、业务对象、逻辑实体、属性、数据标准;技术元数据包含物理数据库、Schema、表、字段。
具体的定义与描述如表所示
2)数据资产编码原则
数据资产编码(DAN)是通过一组数字、符号等组成的字符串去唯一标识华为公司内部每一个数据资产,基于此唯一标识,保证各业务领域对同一数据资产的理解和使用一致,它的设计遵循以下原则。
● 统一性原则:华为公司内部只能使用一套数据资产编码,以方便不同业务部门之间的沟通和IT应用之间的数据交换。
● 唯一性原则:每一个数据资产只能用唯一的数据资产编码进行标识,不同数据资产的编码不允许重复,同一个编码也只能对应到一个数据资产上。
● 可读性原则:数据资产编码作为数据资产分类、检索的关键词和索引,需要具备一定的可读性,让用户通过编码就能初步判断其对应的数据资产类型。
● 扩展性原则:数据资产的编码要从数据管理角度适当考虑未来几年的业务发展趋势,其编码长度要能适当扩展,同时不影响整个编码体系。
3)业务元数据资产编码规则
业务元数据资产编码规则主要包含三个部分:第一部分为主题域
分组的编码规则,主题域分组的编码由公司统一分配;第二部分为主
题域、业务对象、逻辑实体、属性的编码规则,这部分主要由数据治
理平台按照编码规则自动生成;第三部分主要为业务元数据包含的子
类对应的数据资产类型代码。
(二) 采集元数据
元数据采集是指从生产系统、IT设计平台等数据源获取元数据,对元数据进行转换,然后写入元数据中心的过程。
元数据的来源可分为如表所示的六类:
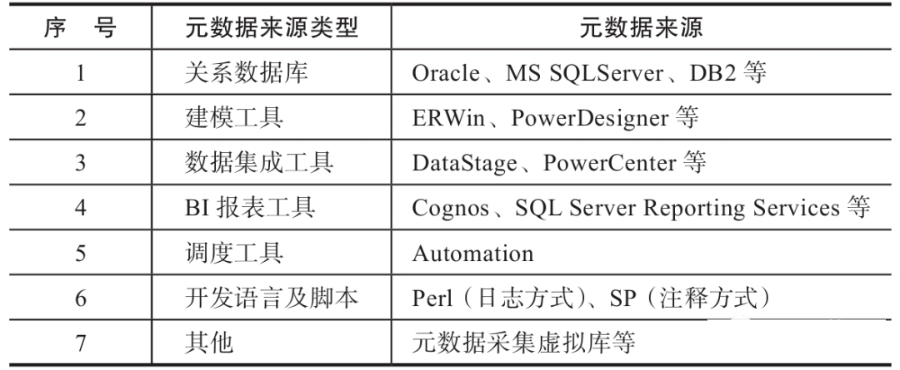
1)选择适配器
适配器是指针对不同的元数据来源,采用相应的采集方式获取元数据的程序,元数据的来源种类繁多,因而须选择相对应的适配器及元模型。
2)配置数据源
配置数据源是采集元数据的关键,在确定数据源所选择的适配器类型、适配器版本、元模型的基础上,配置数据源的名称、连接参数和描述。
3)配置采集任务
采集任务为自动调度的工作单元,为元数据的采集提供自动化的、周期性的、定时的触发机制。
(三) 注册元数据
大多数企业的数字化建设都存在增量和存量两种场景,如何同时有效地管理这两种场景下的元数据就成了问题的关键。华为通过标准的元数据注册规范和统一的元数据注册方法,实现了两种场景下业务元数据和技术元数据的高效连接,使业务人员能看懂数据、理解数据,并通过数据底座实现数据的共享与消费。
(1)元数据注册原则
元数据注册的原则包括如下三点:
● 数据Owner负责,是谁的数据就由谁负责业务元数据和技术元数据连接关系的建设和注册发布;
● 按需注册,各领域数据管理部根据数据搜索、共享的需求,推进元数据注册;
● 注册的元数据的信息安全密级为内部公开。
(2)元数据注册规范
通过“元数据注册三步法”完成元数据注册,如图所示:
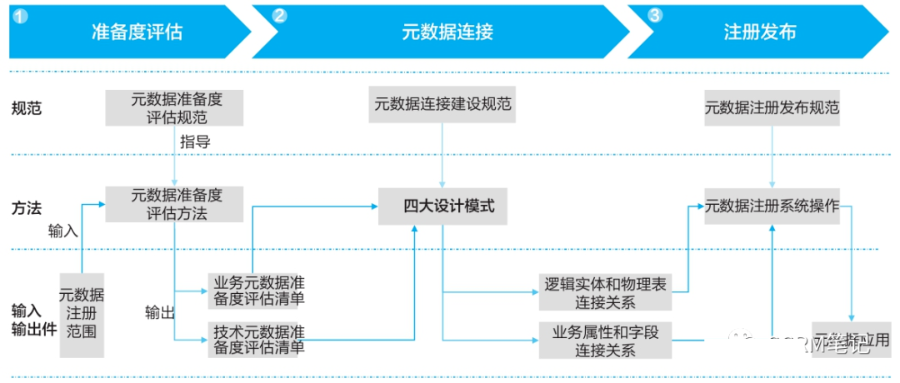
1)准备度评估项包括如下检查要点:
● IT系统名称必须是公司标准名称;
● 数据资产目录是否经过评审并正式发布;
● 数据Owner是否确定数据密级;
● 物理表/虚拟表/视图名。
2)元数据连接需遵从以下规范
● 逻辑实体和物理表/虚拟表/视图一对一连接规范:在业务元数据与技术元数据连接的过程中,必须遵从逻辑实体和物理表/虚拟表/视图一对一的连接原则,如果出现一对多、多对一或多对多的情况,各领域需根据实际场景,参照元数据连接的设计模式进行调整。
● 业务属性与字段一对一连接规范:除了逻辑实体与物理表/虚拟表/视图要求一一对应外,属性和非系统字段(具备业务含义)也要求遵从一对一的连接原则,如出现属性与字段匹配不上的情况,可参考元数据关联的设计模式进行调整。
(3)元数据注册方法
元数据注册分为增量元数据注册和存量元数据注册两种场景。
-
增量场景相对容易,在IT系统的设计与开发过程中,落实元数据的相关规范,确保系统上线时即完成业务元数据与技术元数据连接,通过元数据采集器实现元数据自动注册。
-
针对存量场景,华为设计了元数据注册的四大模式。在符合元数据设计规范的前提下,进行业务元数据与技术元数据的连接及注册。
模式一:一对一模式
适用场景:
适用于数据已发布信息架构和数据标准且物理落地,架构、标准与物理落地能一一对应的场景。
解决方案:
● 将逻辑实体和物理表一对一连接。
● 逻辑实体属性和物理表字段一对一连接。
应用实例:
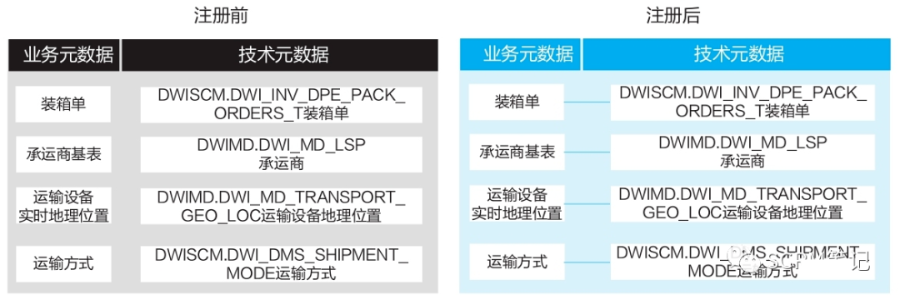
模式二:主从模式
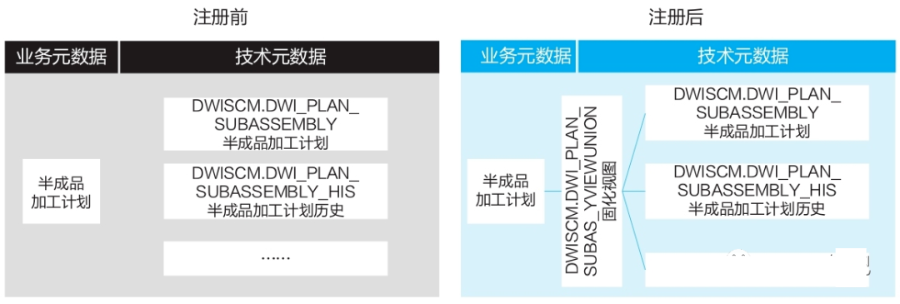
适用场景:
适用于主表和从表结构一致,但数据内容基于某种维度分别存储在不同物理表中的场景。例如,按时间或项目归档,或按区域进行分布式存储。
解决方案:
● 识别主物理表和从属物理表。
● 以主物理表为核心,纵向UNION所有从属物理表,并固化为视图。
● 将视图、逻辑实体、字段和业务属性一对一连接。
应用实例:
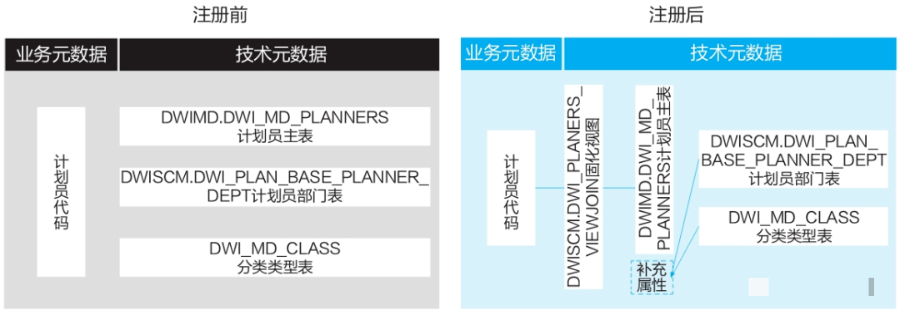
模式三:主扩模式
适用场景:
适用于逻辑实体的大部分业务属性在主物理表,少数属性在其他物理表中的场景。
解决方案:
● 识别主物理表和扩展物理表。
● 以主物理表为核心,横向JOIN所有扩展物理表,完成扩展属性与主表的映射,并固化为视图。
● 将视图、逻辑实体、字段和业务属性一对一连接。
应用实例:
具体应用实例如图所示
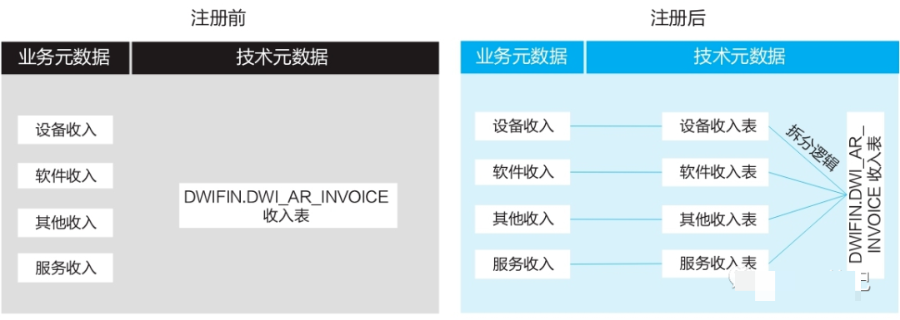
模式四:父子模式
适用场景:
适用于多个逻辑实体业务属性完全相同,按不同场景区分逻辑实体名称,但落地在同一张物理表的场景。
解决方案:
● 识别一张物理表和对应的多个逻辑实体。
● 将物理表按场景拆分和多个逻辑实体一对一连接。
● 将物理表字段和多个逻辑实体属性一对一连接。
应用实例:
完成元数据注册后,通过元数据中心自动发布。
(四) 运维元数据
运维元数据是为了通过对元数据进行分析,发现数据注册、设计、使用的现状及问题,确保元数据的完整、准确。
-
通过数据资产分析,了解各区域/领域的数据注册情况,进而发现数据在各信息系统使用过程中存在的问题。
-
通过业务元数据与技术元数据的关联分析,反向校验架构设计与落地的实施情况,检查公司数据管理政策的执行情况。
主要分为如下四个场景:
● 场景一:基于数据更新发现,数据源上游创建,下游更新;
● 场景二:通过数据调用次数发现,某数据源上游调用次数<下游调用次数;
● 场景三:虽制定了架构标准,但不知落地情况,比如某个属性建立了数据标准,但是却找不到对应落地的物理表字段;
● 场景四:通过物理表的字段分析,发现很多字段缺少数据标准。
四、 元数据与一体化建模管理
华为公司过去长期存在信息架构与IT开发实施“两张皮”的现象,数据人员和IT开发实施人员缺乏统一和协同,数据架构遵从无法进行实质、有效管理,信息架构资产和产品实现的物理表割裂、不匹配,同时各种数据模型资产缺失。
针对应用系统设计应遵从信息架构设计的政策要求,在相关项目、产品的流程中,缺乏显性化的且有实操指导的角色和活动。
信息架构设计大多集中在变革项目层的设计输出和领域层的例行刷新,未与系统落地有效拉通。
IT产品聚焦在版本交付,产品级的数据模型与数据字典缺少有效看护和及时维护。
为了解决这个问题,华为推行了一体化模型设计,不仅在工具上实现了一体化设计和开发,而且在机制上形成了信息架构设计与IT开发实施的有效协同。
通过一体化设计不仅确保了元数据验证、发布和注册的一致性,而且实现了产品数据模型管理和资产可视。
同时,由于促成了产品元数据的持续运营,进而能够持续对物理模型进行规范,如整改、清理各类作废表等。

基于良好的一体化建模架构,不仅可以打通设计和物理实现,而且能够对设计、发布、管理运营等完整生命周期进行融合管理,包括:
● 产品逻辑模型和物理模型一体化设计,元数据管理和数据模型管理融合;
● 构建数据标准池,实体属性只能从数据标准池选择;
● 产品元数据和数据库自动比对和验证;
● 产品元数据发布认证和信息资产打通;
● 基于交易侧产品元数据自助入湖。
五、 元数据与数据湖管理
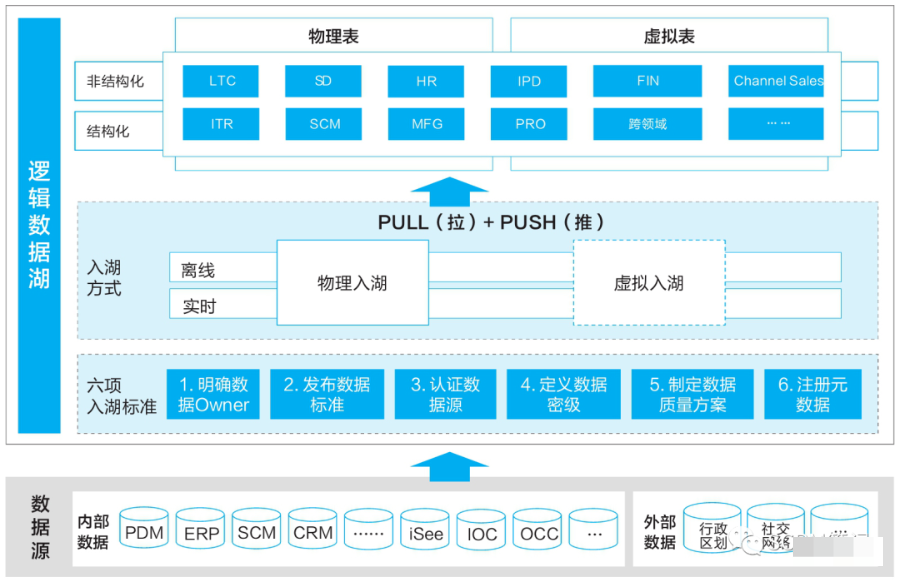
(一) 统一的元数据语义层管理数据湖
华为数据湖是逻辑上对内外部的结构化、非结构化的原始数据的逻辑汇聚。
数据入湖要遵从6项入湖标准,基于6项标准保证入湖的质量,同时面向不同的消费场景提供两种入湖方式,满足数据消费的要求。经过近两年的数据湖建设,目前已经完成1.2万个逻辑数据实体、28万个业务属性的入湖,同时数据入湖在华为公司也形成了标准的流程规范,每个数据资产都要入湖成为数据工作的重要标准。
华为数据湖不是一个单一的物理存储,而是根据数据类型、业务区域等由多个不同的物理存储构成,并通过统一的元数据语义层进行定义、拉通和管理。
(二) 元数据与数据入湖
数据入湖是数据消费的基础,需要严格满足入湖的6项标准,包括明确数据Owner、发布数据标准、定义数据密级、明确数据源、数据质量评估、元数据注册。通过这6项标准保证入湖的数据都有明确的业务责任人,各项数据都可理解,同时都能在相应的信息安全保障下进行消费。
是逻辑上各种原始数据的集合,除了“原始”这一特征外,还具有“海量”和“多样”(包含结构化、非结构化数据)的特征。数据湖保留数据的原格式,原则上不对数据进行清洗、加工,但对于数据资产多源异构的场景需要整合处理,并进行数据资产注册。数据入湖必须要遵循6项标准,共同满足数据联接和用户数据消费需求。
1、 结构化数据入湖
结构化数据是指由二维表结构来逻辑表达和实现的数据,严格遵循数据格式与长度规范,主要通过关系型数据库进行存储和管理。
触发结构化数据入湖的场景有两种:
第一,企业数据管理组织基于业务需求主动规划和统筹;
第二,响应数据消费方的需求。
结构化数据入湖过程包括:数据入湖需求分析及管理、检查数据入湖条件和评估入湖标准、实施数据入湖、注册元数据。
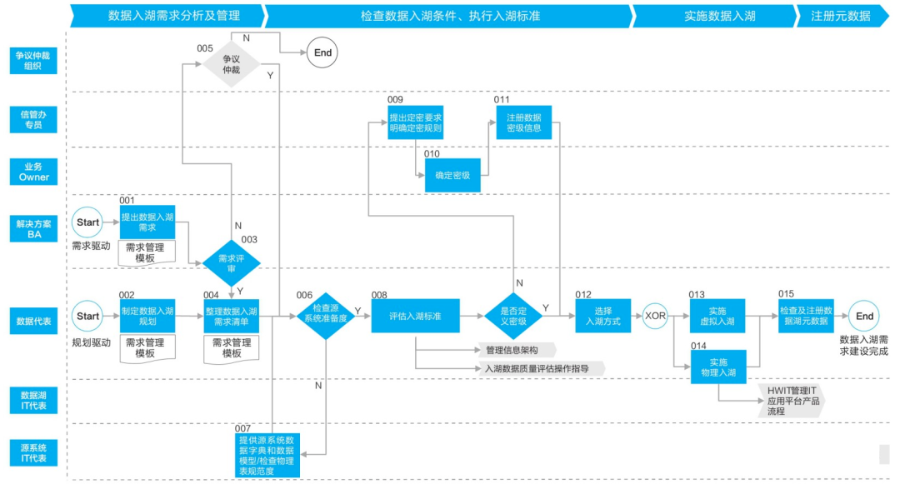
(1) 数据入湖需求分析及管理
对于规划驱动入湖场景而言,由对应的数据代表基于数据湖的建设规划,输出入湖规划清单,清单包含主题域分组、主题域、业务对象、逻辑实体、业务属性、源系统物理表和物理字段等信息。
对于需求驱动入湖场景而言,由数据消费方的业务代表提出入湖需求,并提供数据需求的业务元数据和技术元数据的信息,包括业务对象、逻辑实体、业务属性对应界面的截图。
(2) 评估入湖标准
入湖标准包括以下几点。
● 明确数据Owner:为保证入湖数据的管理责任清晰,在数据入湖前应明确数据Owner。
● 发布数据标准:入湖数据应有数据标准,数据标准定义了数据属性的业务含义、业务规则等,是正确理解和使用数据的重要依据,也是业务元数据的重要组成部分。
(3) 注册元数据
元数据是公司的重要资产,是数据共享和消费的前提,为数据导航和数据地图建设提供关键输入。对元数据进行有效注册是实现上述目的的前提。
虚拟表部署完成后或IT实施完成后,由数据代表检查并注册元数据,元数据注册应遵循企业元数据注册规范。
2、 非结构化数据入湖
(1) 非结构化数据管理的范围
非结构化数据包括无格式的文本、各类格式的文档、图像、音频、视频等多样异构的格式文件。相较于结构化数据,非结构化数据更难标准化和理解,因而非结构化数据的管理不仅包括文件本身,而且包括对文件的描述属性,也就是非结构化的元数据信息。
这些元数据信息包括文件对象的标题、格式、Owner等基本特征,还包括对数据内容的客观理解信息,如标签、相似性检索、相似性连接等。这些元数据信息便于用户对非结构化数据进行搜索和消费。
非结构化数据的元数据实体如图所示:
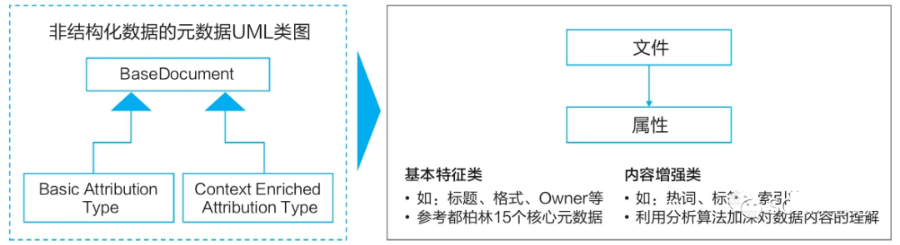
都柏林核心元数据是一个致力于规范Web资源体系结构的国际性元数据解决方案,它定义了一个所有Web资源都应遵循的通用核心标准。
基本特征类属性由公司进行统一管理,内容增强类属性由承担数据分析工作的项目组自行设计,但其分析结果都应由公司元数据管理平台自动采集后进行统一存储。
(2) 非结构化数据入湖的4种方式
非结构化数据入湖包括基本特征元数据入湖、文件解析内容入湖、文件关系入湖和原始文件入湖4种方式,其中基本特征元数据入湖是必选内容,后面三项内容可以根据分析诉求选择性入湖和延后入湖。
1)基本特征元数据入湖
主要通过从源端集成的文档本身的基本信息入湖。入湖的过程中,数据内容仍存储在源系统,数据湖中仅存储非结构化数据的基本特征元数据。基本特征元数据入湖需同时满足如下条件。
● 已经设计了包含基本特征元数据的索引表。
● 已经设计了信息架构,如业务对象和逻辑实体。
● 已经定义了索引表中每笔记录对应文件的Owner、标准、密级,认证了数据源并满足质量要求。
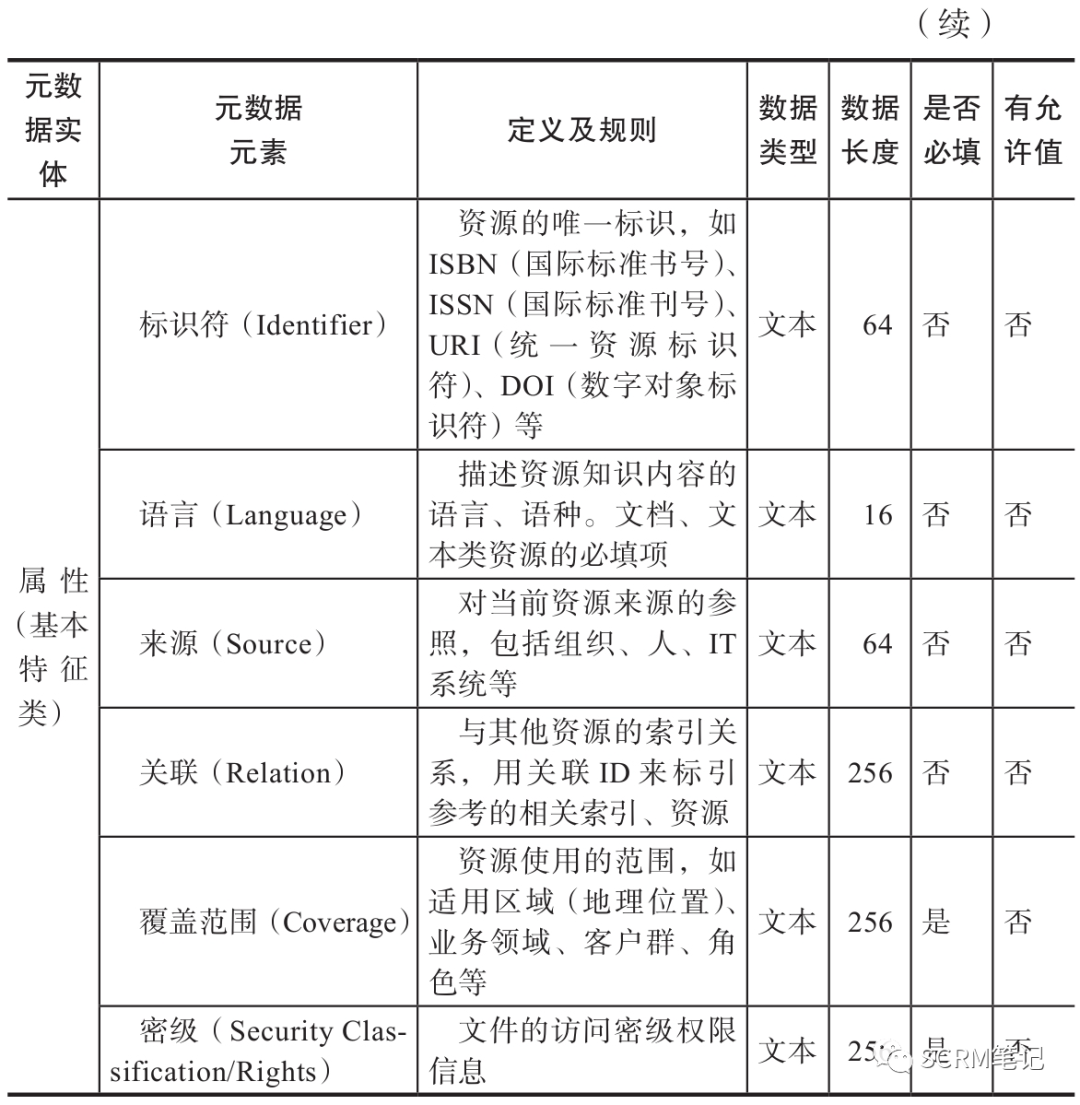
参考都柏林核心元数据,非结构化数据的基本特征类属性元数据规范如表所示。
2)文件解析内容入湖
对数据源的文件内容进行文本解析、拆分后入湖。入湖的过程中,原始文件仍存储在源系统,数据湖中仅存储解析后的内容增强元数据。内容解析入湖需同时满足如下条件。
● 已经确定解析后的内容对应的Owner、密级和使用的范围。
● 已经获取了解析前对应原始文件的基本特征元数据。
● 已经确定了内容解析后的存储位置,并保证至少一年内不会迁移。
3)文件关系入湖
根据知识图谱等应用案例在源端提取的文件上下文关系入湖。入湖的过程中,原始文件仍存储在源系统,数据湖中仅存储文件的关系等内容增强元数据。文件关系入湖需同时满足如下条件:
● 已经确定文件对应的Owner、密级和使用的范围。
● 已经获取了文件的基本特征元数据。
● 已经确定了关系实体的存储位置,并保证至少一年内不会迁移。
4)原始文件入湖
根据消费应用案例从源端把原始文件搬入湖。数据湖中存储原始文件并进行全生命周期管理。原始文件入湖需同时满足如下条件。
● 已经确定原始文件对应的Owner、密级和使用的范围。
● 已经获取了基本特征元数据。
● 已经确定了存储位置,并保证至少一年内不会迁移
六、 元数据与数据服务管理
针对数据需求,规范数据服务识别过程,列出数据服务识别过程需要了解的关键内容,明确数据服务的实现方式和准入条件,提高数据服务的可复用性,减少重复建设,如图所示。
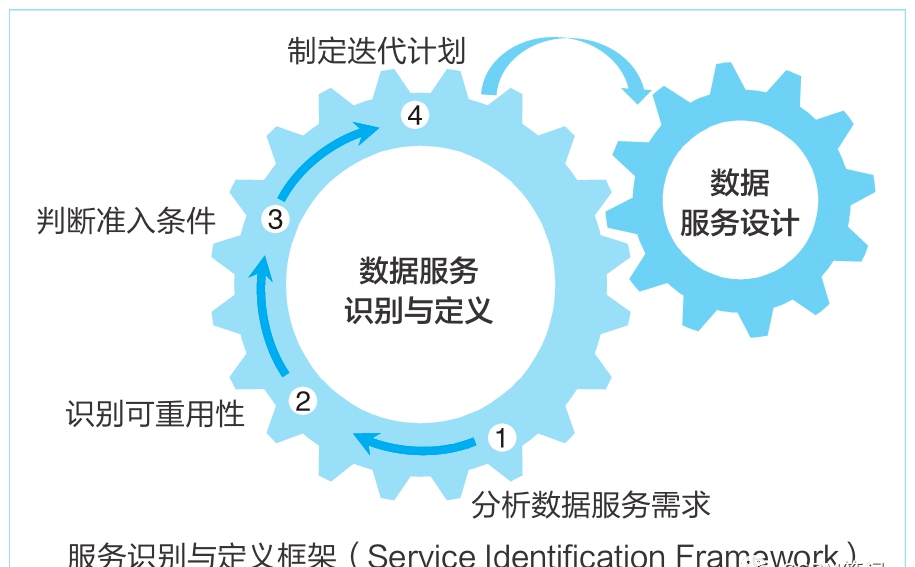
1)分析数据服务需求:通过数据需求调研与需求交接,判断数据服务类型(面向系统或面向消费)、数据内容(指标/维度/范围/报表项)、数据源与时效性要求。
2)识别可重用性:结合数据需求分析,通过数据服务中心匹配已有的数据服务,判断以哪种方式(新建服务、直接复用、服务变更)满足业务需求。对于已有数据服务,必须使用服务化方式满足需求,减少数据“搬家”。
3)判断准入条件:判断服务设计条件是否已具备,包括数据Owner是否明确、元数据是否定义、业务元数据和技术元数据是否建立联接、数据是否已入湖等。
七、 元数据与构建数据地图
在解决数据的“可供应性”之后,企业应该帮助业务更便捷、更准确地找到它们所需要的数据,这就需要打造一个能够满足用户体验的“数据地图”。
(一) 数据地图的核心价值
数据供应者与消费者之间往往存在一种矛盾:供应者做了大量的数据治理工作、提供了大量的数据,但数据消费者却仍然不满意,他们始终认为在使用数据之前存在两个重大困难。
1)找数难
企业的数据分散存储在上千个数据库、上百万张物理表中,已纳入架构、经过质量、安全有效管理的数据资产也会超过上万个,并且还在持续增长中。例如,用户需要从发货数据里对设备保修和维保进行区分,以便为判断哪类设备已过保(无法继续服务)提供准确依据,但生成和关联的交易系统有几十个,用户不知道应该从哪里获取这类数据,也不清楚获取的数据是否正确。
2)读不懂
企业往往会面对数据库物理层和业务层脱离的现状,数据的最终消费用户无法直接读懂物理层数据,无法确认数据是否能满足需求,只能寻求IT人员支持,经过大量转换和人工校验,才最终确认可消费的数据,而熟悉物理层结构的IT人员,并不是数据的最终消费者。例如,当需要盘点研发内部要货情况的时候,就需要从供应链系统获取研发内部的要货数据,但业务用户不了解该系统复杂的数据存储结构(涉及超过40个表、1000余个字段),也不清楚每个字段名称下所包含的业务的含义和规则。
企业在经营和运营过程中产生了大量数据,但只有让用户“找得到”“读得懂”,能够准确地搜索、便捷地订阅这些数据,数据才能真正发挥价值。数据地图(DMAP)是华为公司面向数据的最终消费用户针对数据“找得到”“读得懂”的需求而设计的,基于元数据应用,以数据搜索为核心,通过可视化方式,综合反映有关数据的来源、数量、质量、分布、标准、流向、关联关系,让用户高效率地找到数据,读懂数据,支撑数据消费。
数据地图作为数据治理成果的集散地,需要提供多种数据,满足多类用户、多样场景的数据消费需求,所以华为公司结合实际业务制定了如图所示的数据地图框架。
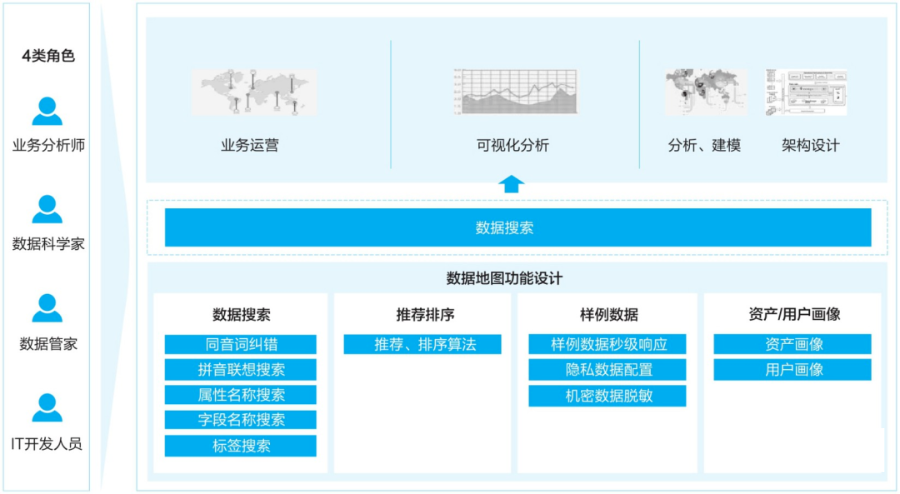
(二) 设计质量度量与元数据
为确保设计质量标准稳定,从信息架构的四个角度(数据资产目录、数据标准、数据模型、数据分布)进行综合评估,其范围覆盖度量期间内已通过IA-SAG评审发布的所有数据资产。当实际业务有例外场景时,可向IA-SAG专业评审团申请仲裁,若评审通过,则可采用白名单的方式进行管理。
(1)数据资产目录
1)业务对象需有明确、唯一的数据Owner,并对该业务对象全流程端到端质量负责,如是否有定义数据质量目标、是否有数据质量工作规划等。
2)业务对象的元数据质量,如数据分类是否完整、业务定义是否准确、数据管家是否有效等。
3)资产目录完整性。
(2)数据标准
1)数据标准元数据质量,如数据标准是否唯一、业务用途及定义是否准确、各责任主体是否有效等。
2)所有业务对象应准确关联数据标准。
3)数据标准在IT系统及其对应的业务流程中应得到应用和遵从。
相关文章:
华为数据管理——《华为数据之道》
数据分析与开发 元数据是描述数据的数据,用于打破业务和IT之间的语言障碍,帮助业务更好地理解数据。 元数据是数据中台的重要的基础设施,元数据治理贯彻数据产生、加工、消费的全过程,沉淀了数据资产,搭建了技术和业务…...

Flink CDC 菜鸟教程 -环境篇
本教程将介绍如何使用 Flink CDC 来实现这个需求, 在 Flink SQL CLI 中进行,只涉及 SQL,无需一行 Java/Scala 代码,也无需安装 IDE。 系统的整体架构如下图所示: 环境篇 1、 准备一台Linux 2、准备教程所需要的组件 下载 flink-1.13.2 并将其解压至目录 flink-1.13.2 …...
)
【线上问题】linux部署docker应用docker-compose启动报端口占用问题(感觉上没有被占用)
目录 一、问题说明二、排查过程 一、问题说明 1.linux服务器使用的不是root用户权限 2.docker应用服务没有关闭的情况下,做了些重装docker,重启docker等操作 3.docker-compose up -d然后docker logs查看日志报端口被占用 4.netstat -ntpl | grep 端口 也…...
解决虚拟机克隆后IP和命名冲突问题
目录 解决IP冲突问题 解决命名冲突 解决IP冲突问题 克隆后的虚拟机和硬件地址和ip和我们原虚拟机的相同,我们需要重新生成硬件地址和定义ip,步骤如下: (1)进入 /etc/sysconfig/network-scripts/ifcfg-ens33 配置文件…...

分享一个python基于数据可视化的智慧社区服务平台源码
💕💕作者:计算机源码社 💕💕个人简介:本人七年开发经验,擅长Java、Python、PHP、.NET、Node.js、微信小程序、爬虫、大数据等,大家有这一块的问题可以一起交流! …...

[密码学入门]凯撒密码
单表代换 单表:英文26字母的顺序 代换:替换为别的字母并保证解密的唯一性 假如我们让加密方式为所有字母顺序移动3位 import stringstring.ascii_lowercase abcdefghijklmnopqrstuvwxyz b3 加密算法y(xb)mod26 解密算法为x(y-b)mod26 密钥空间26 …...
博客之QQ登录功能(一)
流程图 上图spring social 封装了1-8步需要的工作 1、新建包和书写配置文件 public class QQProperties {//App唯一标 识private String appId "100550231";private String appSecret "69b6ab57b22f3c2fe6a6149274e3295e";//QQ供应商private String…...
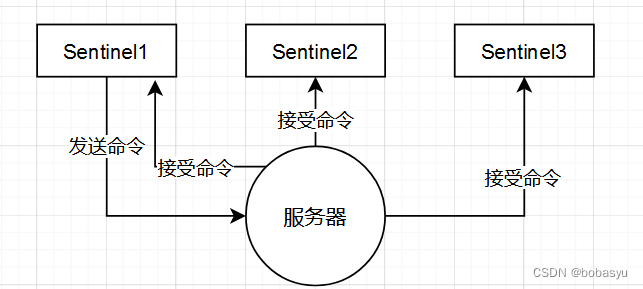
Redis多机数据库实现
Redis多机数据库实现 为《Redis设计与实现》笔记 复制 客户端可以使用SLAVEOF命令将指定服务器设置为该服务器的主服务器 127.0.0.1:12345> SLAVEOF 127.0.0.1 6379127.0.0.1:6379将被设置为127.0.0.1:123456的主服务器 旧版复制功能的实现 Redis的复制功能分为同步&a…...
Leangoo领歌 -敏捷任务管理软件,任务管理更轻松更透明
任务管理,简单易懂,就是对任务进行管理。那怎么可以更好进行任务管理呢?怎么样样可以让任务进度可视化,一目了然呢?有效的管理可以让我们事半功倍。 接下来我们看一下如何借助任务管理软件高效的做任务管理。 首先…...
go的iris框架进行本地资源映射到服务端
我这里使用的是HandleDirapi,有其他的请补充 package mainimport ("github.com/kataras/iris/v12" )type Hello struct{Status int json:"status"Message string json:"message" }func main(){app : iris.New()//第一个api:相当于首页app.Get(&q…...

代码随想录day46|139. 单词拆分
139. 单词拆分 class Solution:def wordBreak(self, s: str, wordDict: List[str]) -> bool:dp [False]*(len(s)1)dp[0]Truefor i in range(len(s)1):for j in wordDict:if i>len(j) and (s[i-len(j):i] in wordDict) and dp[i-len(j)]:dp[i] Truereturn dp[len(s)]多…...
MATLAB实现函数拟合
目录 一.理论知识 1.拟合与插值的区别 2.几何意义 3.误差分析 二.操作实现 1.数据准备 2.使用cftool——拟合工具箱 三.函数拟合典例 四.代码扩展 一.理论知识 1.拟合与插值的区别 通俗的说,插值的本质是根据现有离散点的信息创建出更多的离散点…...
vue优化首屏加载时间优化-cdn引入第三方包
前言 为什么要进行首屏加载优化,因为随着我们静态资源和第三方包和代码增加,压缩之后包会越来越大 随着网络的影响,在我们第一输入url请求资源时候,网络阻塞,加载时间长,用户体验不好 仔细观察后就会发现…...

lv4 嵌入式开发-3 标准IO的读写
目录 1 标准I/O – 读写流 2 标准I/O – 按字符输入 3 标准I/O – 按字符输出 4 标准I/O – 思考和练习 5 标准I/O – 按行输入 6 标准I/O – 按行输出 7 标准I/O – 思考和练习 1 标准I/O – 读写流 流支持不同的读写方式: 读写一个字符:fgetc()/fputc()一…...

iOS UIDevice设备信息
识别设备和操作系统 //获得共享设备实例 open class var current: UIDevice { get }//识别设备的名称 open var name: String { get } // e.g. "My iPhone"//设备类型 open var model: String { get } // e.g. "iPhone", "iPod touch"//本地化设…...
编译安装)
SLAM ORB-SLAM2(2)编译安装
SLAM ORB-SLAM2(2)编译安装 1. 软件包依赖安装2. 依赖安装2.1. Eigen2.2. Pangolin2.3. OpenCV3. ORB-SLAM23.1. 源码下载3.2. 文件修改3.3. 扩大交换空间3.4. 编译1. 软件包依赖安装 以一个纯净的ubuntu20.04桌面版为例 1.首先设置软件源为清华源 2.安装必要依赖 sudo ap…...

第11节-PhotoShop基础课程-索套工具
文章目录 前言1.索套工具 选中后按Ctrl 可以移动2.加,减,交叉 shift alt 2.多边形索套工具 手动首尾相连 或者双击空地1.单击绘制直线选区2.双击结束绘制3.加,减,交叉4. delete可以删除节点 3.磁性索套工具1.沿着边缘自动吸附2.可…...
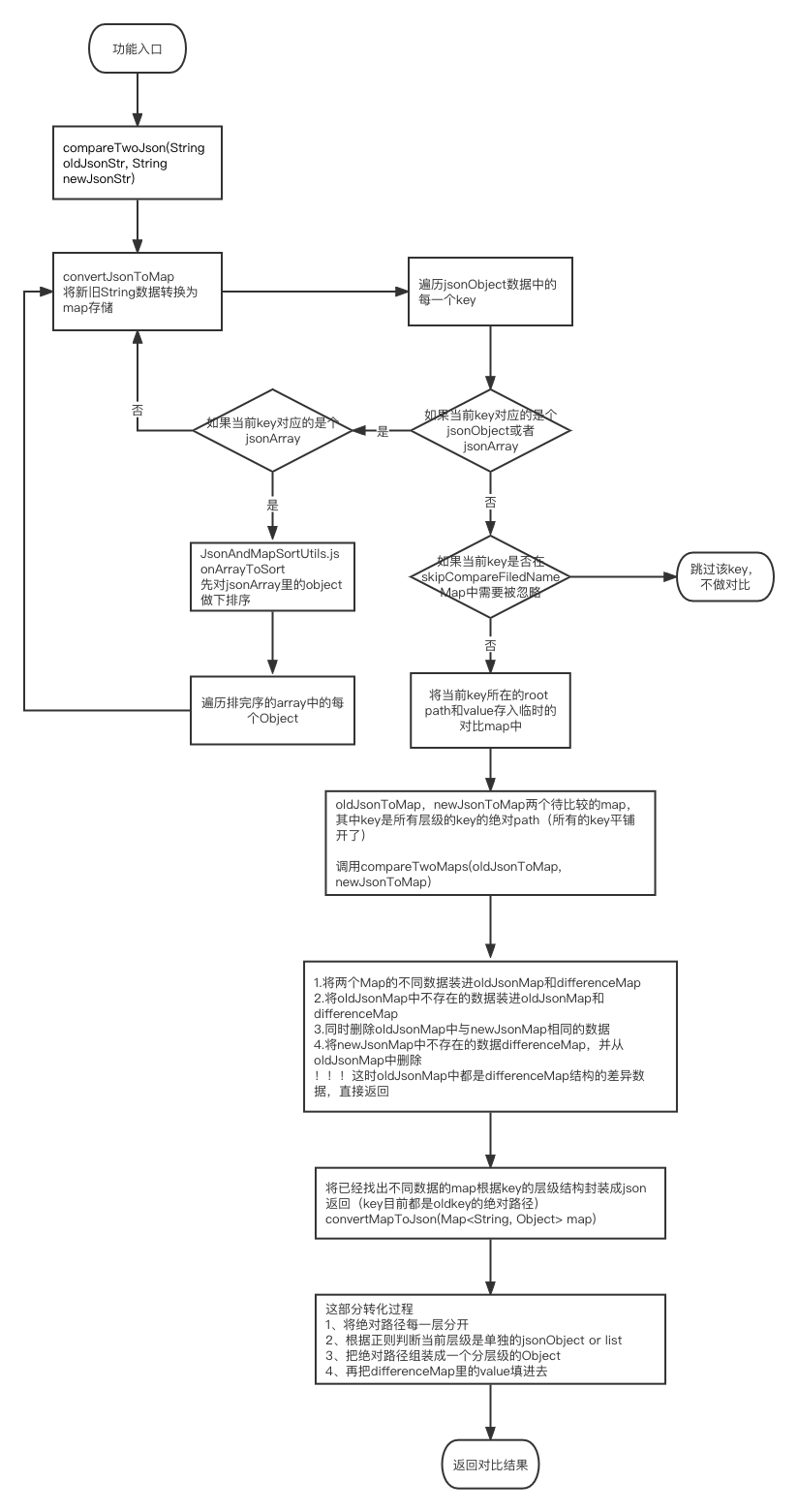
Json字符串内容比较-超实用版
背景 之前有类似接口diff对比,数据对比的测试需求,涉及到json格式的数据对比,调研了几个大神们分享的代码,选了一个最符合自己需求的研究了下。 说明 这个对比方法,支持JsonObject和JsonArray类型的数据对比&#x…...

Redis系列之客户端Redisson
概述 官方推荐的客户端,支持Redis单实例、Redis哨兵、Redis Cluster、Redis master-slave等各种部署架构。 GitHub, 功能: 分布式锁 分布式锁 使用Redisson提供的分布式锁的一个最常见场景,应用部署为多个节点,然…...

centos 端口被占用的快速排查方式
问题笔记 centos 端口被占用的快速排查方式 centos 端口被占用的快速排查方式 这里说一个我刚刚遇到的问题,解决步骤用来记录,方便以后自己查询。 nginx配置完index.html测试文件,发现一直显示的404页面。 我跑到服务器上想重启一下nginx …...

Wan2.1 VAE模型蒸馏与轻量化部署探索
Wan2.1 VAE模型蒸馏与轻量化部署探索 最近在折腾一些生成模型的实际落地,发现一个挺普遍的问题:模型效果是真好,但体积也是真的大,推理起来对硬件的要求不低。特别是想把模型搬到一些资源有限的边缘设备,或者希望降低…...

3分钟掌握MicroPython WebREPL:浏览器直接控制嵌入式设备
3分钟掌握MicroPython WebREPL:浏览器直接控制嵌入式设备 【免费下载链接】webrepl WebREPL client and related tools for MicroPython 项目地址: https://gitcode.com/gh_mirrors/we/webrepl 想要用浏览器直接控制你的MicroPython开发板吗?WebR…...
)
想入门脑机接口?这5个免费EEG数据集帮你从理论到实战(含Python处理示例)
想入门脑机接口?这5个免费EEG数据集帮你从理论到实战(含Python处理示例) 当你第一次听说脑机接口(BCI)时,脑海中浮现的可能是科幻电影中那些炫酷的场景——用意念控制机械臂、通过思维与计算机交互。但现实…...

Windows环境下SpringBoot Jar包热更新实战:从配置文件到Class文件的动态替换
1. Windows下SpringBoot Jar包热更新核心原理 SpringBoot应用打包成Jar后,本质上是个压缩文件。在Windows环境下,我们可以利用JDK自带的jar命令直接操作这个压缩包。热更新的本质就是在不重启服务的情况下,通过替换Jar包内部文件来实现配置或…...

GeoServer发布PostGIS数据时,那个容易忽略的SQL注入风险点,你检查了吗?
GeoServer动态SQL视图的安全实践:如何规避PostGIS数据发布中的SQL注入风险 在GIS服务部署的日常工作中,GeoServer与PostGIS的组合堪称黄金搭档。但当我们陶醉于SQL视图带来的灵活性时,一个潜伏的安全威胁往往被忽视——SQL注入漏洞。这种漏洞…...

Qwen3-ASR-1.7B语音转文字实战:播客剪辑→静音段自动切除+有效语音精准切分
Qwen3-ASR-1.7B语音转文字实战:播客剪辑→静音段自动切除有效语音精准切分 1. 引言:播客剪辑的痛点与解决方案 做播客的朋友都知道,剪辑是最耗时的工作之一。一段60分钟的录音,真正有价值的内容可能只有40分钟,剩下的…...
到底怎么选?)
别再混着用了!Matplotlib的两种画图接口(plt.plot vs. ax.plot)到底怎么选?
Matplotlib接口选择指南:何时用plt.plot,何时用ax.plot? 在数据可视化领域,Matplotlib无疑是Python生态中最强大的工具之一。但许多用户在使用过程中常常困惑:为什么有的代码用plt.plot(),有的却用ax.plot(…...

【信号处理实战】从原理到代码:手把手实现三次样条插值
1. 三次样条插值:从数学定义到生活场景 想象你正在用一根柔软的弹性尺子连接一组图钉,这些图钉固定在木板上代表你的数据点。这根尺子需要光滑地穿过每一个图钉,同时保持自然的弯曲形态——这就是三次样条插值要解决的问题。作为信号处理中最…...

高精度运放在电流传感器中的设计与应用
高精度运算放大器在电流传感器中的应用设计1. 电流传感器概述1.1 电流传感器类型与特性电流传感器是用于测量电路电流的关键元件,根据测量原理主要分为以下几种类型:传感器类型测量范围典型应用场景分流电阻式μA~100A电池监测、电机控制磁感应式10mA~1k…...

VINS-Fusion 实战指南:从环境搭建到多传感器融合部署
1. VINS-Fusion入门:为什么选择这个多传感器融合方案 第一次接触VINS-Fusion是在做一个无人机定位项目时,当时试过各种开源SLAM方案,最后发现这个来自香港科技大学团队的工具在传感器融合方面确实有两把刷子。简单来说,它就像个聪…...