Python+Requests+Pytest+YAML+Allure实现接口自动化

本项目实现接口自动化的技术选型:Python+Requests+Pytest+YAML+Allure ,主要是针对之前开发的一个接口项目来进行学习,通过 Python+Requests 来发送和处理HTTP协议的请求接口,使用 Pytest 作为测试执行器,使用 YAML 来管理测试数据,使用 Allure 来生成测试报告
一、项目说明
本项目在实现过程中,把整个项目拆分成请求方法封装、HTTP接口封装、关键字封装、测试用例等模块。
首先利用Python把HTTP接口封装成Python接口,接着把这些Python接口组装成一个个的关键字,再把关键字组装成测试用例,而测试数据则通过YAML文件进行统一管理,然后再通过Pytest测试执行器来运行这些脚本,并结合Allure输出测试报告
当然,如果感兴趣的话,还可以再对接口自动化进行Jenkins持续集成
GitHub项目源码地址:
https://github.com/wintests/pytestDemo
二、项目结构
api ====>> 接口封装层,如封装HTTP接口为Python接口
common ====>> 各种工具类
core ====>> requests请求方法封装、关键字返回结果类
config ====>> 配置文件
data ====>> 测试数据文件管理
operation ====>> 关键字封装层,如把多个Python接口封装为关键字
pytest.ini ====>> pytest配置文件
requirements.txt ====>> 相关依赖包文件
testcases ====>> 测试用例
三、请求方法封装
在 core/rest_client.py 文件中,对 Requests 库下一些常见的请求方法进行了简单封装,以便调用起来更加方便。
class RestClient():def __init__(self, api_root_url):self.api_root_url = api_root_urlself.session = requests.session()def get(self, url, **kwargs):return self.request(url, "GET", **kwargs)def post(self, url, data=None, json=None, **kwargs):return self.request(url, "POST", data, json, **kwargs)def put(self, url, data=None, **kwargs):return self.request(url, "PUT", data, **kwargs)def delete(self, url, **kwargs):return self.request(url, "DELETE", **kwargs)def patch(self, url, data=None, **kwargs):return self.request(url, "PATCH", data, **kwargs)def request(self, url, method, data=None, json=None, **kwargs):url = self.api_root_url + urlheaders = dict(**kwargs).get("headers")params = dict(**kwargs).get("params")files = dict(**kwargs).get("params")cookies = dict(**kwargs).get("params")self.request_log(url, method, data, json, params, headers, files, cookies)if method == "GET":return self.session.get(url, **kwargs)if method == "POST":return requests.post(url, data, json, **kwargs)if method == "PUT":if json:# PUT 和 PATCH 中没有提供直接使用json参数的方法,因此需要用data来传入data = complexjson.dumps(json)return self.session.put(url, data, **kwargs)if method == "DELETE":return self.session.delete(url, **kwargs)if method == "PATCH":if json:data = complexjson.dumps(json)return self.session.patch(url, data, **kwargs)四、HTTP接口 封装为 Python接口
在 api/user.py 文件中,将上面封装好的HTTP接口,再次封装为不同的Python接口。不同的Python接口,会处理不同URL下的请求。
class User(RestClient):def __init__(self, api_root_url, **kwargs):super(User, self).__init__(api_root_url, **kwargs)def list_all_users(self, **kwargs):return self.get("/users", **kwargs)def list_one_user(self, username, **kwargs):return self.get("/users/{}".format(username), **kwargs)def register(self, **kwargs):return self.post("/register", **kwargs)def login(self, **kwargs):return self.post("/login", **kwargs)def update(self, user_id, **kwargs):return self.put("/update/user/{}".format(user_id), **kwargs)def delete(self, name, **kwargs):return self.post("/delete/user/{}".format(name), **kwargs)五、关键字返回结果类
在 core/result_base.py 下,定义了一个空类 ResultBase ,该类主要用于自定义关键字返回结果。
class ResultBase():pass"""
自定义示例:
result = ResultBase()
result.success = False
result.msg = res.json()["msg"]
result.response = res
"""`在多流程的业务场景测试下,通过自定义期望保存的返回数据值,以便更好的进行断言。
六、关键字封装
关键字应该是具有一定业务意义的,在封装关键字的时候,可以通过调用多个Python接口来完成。在某些情况下,比如测试一个充值接口的时候,在充值后可能需要调用查询接口得到最新账户余额,来判断查询结果与预期结果是否一致,那么可以这样来进行测试:
1, 首先,可以把 充值-查询 的操作封装为一个关键字,在这个关键字中依次调用充值和查询的接口,并可以自定义关键字的返回结果。
2, 接着,在编写测试用例的时候,直接调用关键字来进行测试,这时就可以拿到关键字返回的结果,那么断言的时候,就可以直接对关键字返回结果进行断言。
七、测试用例层
根据用例名分配测试数据
测试数据位于 data 文件夹下,在这里使用 YAML 来管理测试数据,同时要求测试数据中第一层的名称,需要与测试用例的方法名保持一致,如 test_get_all_user_info 、test_delete_user。
test_get_all_user_info:# 期望结果,期望返回码,期望返回信息# except_result, except_code, except_msg- [True, 0, "查询成功"]
省略
test_delete_user:# 删除的用户名,期望结果,期望返回码,期望返回信息# username, except_result, except_code, except_msg- ["测试test", True, 0, "删除用户信息成功"]- ["wintest3", False, 3006, "该用户不允许删除"]这里借助 fixture 方法,我们就能够通过 request.function.__name__ 自动获取到当前执行用例的函数名 testcase_name ,当我们传入测试数据 api_data 之后,接着便可以使用 api_data.get(testcase_name) 来获取到对应用例的测试数据。
import pytest
from testcases.conftest import api_data@pytest.fixture(scope="function")
def testcase_data(request):testcase_name = request.function.__name__return api_data.get(testcase_name)`数据准备和清理
在接口自动化中,为了保证用例可稳定、重复地执行,我们还需要有测试前置操作和后置操作,即数据准备和数据清理工作。
@pytest.fixture(scope="function")
def delete_register_user():"""注册用户前,先删除数据,用例执行之后,再次删除以清理数据"""del_sql = base_data["init_sql"]["delete_register_user"]db.execute_db(del_sql)logger.info("注册用户操作:清理用户--准备注册新用户")logger.info("执行前置SQL:{}".format(del_sql))yield # 用于唤醒 teardown 操作db.execute_db(del_sql)logger.info("注册用户操作:删除注册的用户")logger.info("执行后置SQL:{}".format(del_sql))在这里,以用户注册用例为例。对于前置操作,我们应该准备一条删除SQL,用于将数据库中已存在的相同用户删除,对于后置操作,我们应该再执行删除SQL,确保该测试数据正常完成清理工作。
在测试用例中,我们只需要在用例上传入 fixture 的函数参数名 delete_register_user ,这样就可以调用 fixture 实现测试前置及后置操作。当然,也可以使用pytest装饰器 @pytest.mark.usefixtures() 来完成,如:
@pytest.mark.usefixtures("delete_register_user")` Allure用例描述
在这里,我们结合 Allure 来实现输出测试报告,同时我们可以使用其装饰器来添加一些用例描述并显示到测试报告中,以便报告内容更加清晰、直观、可读。如使用 @allure.title() 自定义报告中显示的用例标题,使用 @allure.description() 自定义用例的描述内容,使用 @allure.step() 可在报告中显示操作步骤,使用 @allure.issue() 可在报告中显示缺陷及其链接等。
@allure.step("步骤1 ==>> 注册用户")
def step_1(username, password, telephone, sex, address):logger.info("步骤1 ==>> 注册用户 ==>> {}, {}, {}, {}, {}".format(username, password, telephone, sex, address))@allure.severity(allure.severity_level.NORMAL)
@allure.epic("针对单个接口的测试")
@allure.feature("用户注册模块")
class TestUserRegister():"""用户注册"""@allure.story("用例--注册用户信息")@allure.description("该用例是针对获取用户注册接口的测试")@allure.issue("https://www.cnblogs.com/wintest", name="点击,跳转到对应BUG的链接地址")@allure.testcase("https://www.cnblogs.com/wintest", name="点击,跳转到对应用例的链接地址")@allure.title("测试数据:【 {username},{password},{telephone},{sex},{address},{except_result},{except_code},{except_msg}】")@pytest.mark.single@pytest.mark.parametrize("username, password, telephone, sex, address, except_result, except_code, except_msg",api_data["test_register_user"])@pytest.mark.usefixtures("delete_register_user")def test_delete_user(self, login_fixture, username, except_result, except_code, except_msg):
省略七、项目部署
首先,下载项目源码后,在根目录下找到 requirements.txt 文件,然后通过 pip 工具安装 requirements.txt 依赖,执行命令:
pip3 install -r requirements.txt` 接着,修改 config/setting.ini 配置文件,在Windows环境下,安装相应依赖之后,在命令行窗口执行命令:
pytest注意:因为我这里是针对自己的接口项目进行测试,如果想直接执行我的测试用例来查看效果,需要提前部署上面提到的接口项目。
八、测试报告效果展示
在命令行执行命令:pytest 运行用例后,会得到一个测试报告的原始文件,但这个时候还不能打开成HTML的报告,还需要在项目根目录下,执行命令启动 allure 服务:
# 需要提前配置allure环境,才可以直接使用命令行
allure serve ./report`最终,可以看到测试报告的效果图如下:

最后感谢每一个认真阅读我文章的人,礼尚往来总是要有的,虽然不是什么很值钱的东西,如果你用得到的话可以直接拿走:
这些资料,对于【软件测试】的朋友来说应该是最全面最完整的备战仓库,这个仓库也陪伴上万个测试工程师们走过最艰难的路程,希望也能帮助到你!
相关文章:

Python+Requests+Pytest+YAML+Allure实现接口自动化
本项目实现接口自动化的技术选型:PythonRequestsPytestYAMLAllure ,主要是针对之前开发的一个接口项目来进行学习,通过 PythonRequests 来发送和处理HTTP协议的请求接口,使用 Pytest 作为测试执行器,使用 YAML 来管理测…...
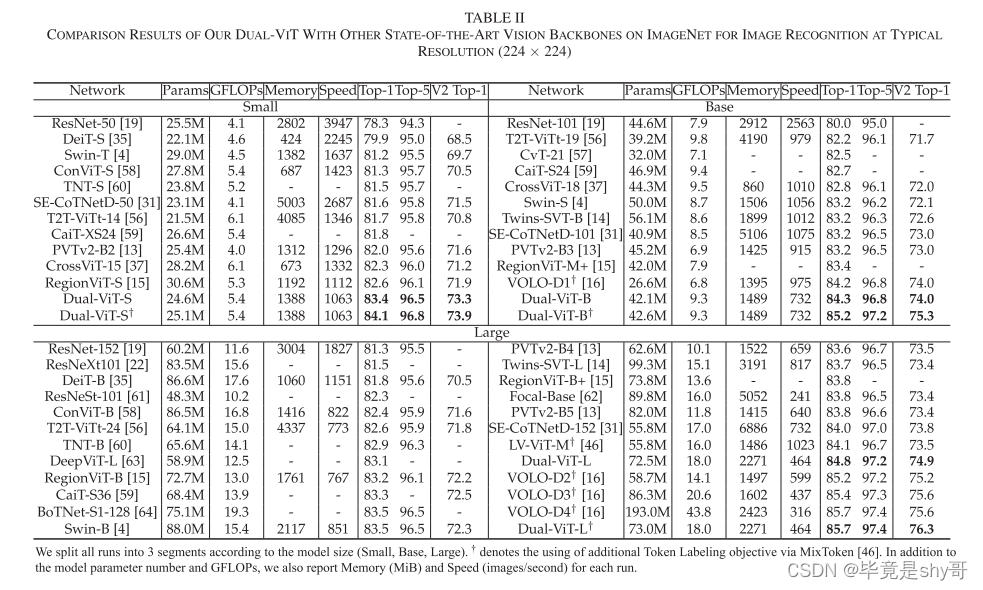
双视觉Transformer(Dual Vision Transformer)
摘要 已经提出了几种策略来减轻具有高分辨率输入的自注意机制的计算:比如将图像补丁上的全局自注意过程分解成区域和局部特征提取过程,每个过程都招致较小的计算复杂度。尽管效率良好,这些方法很少探索所有补丁之间的整体交互,因…...

MES系统成为工业4.0首选,制造业真正数字化车间你看过吗?
在日益激烈的市场竞争中,MES管理系统已经成为企业提升生产效率、降低成本、提高竞争力的关键。通过MES管理系统实现数据集成和分析,能够对产品制造过程的各个环节进行可视化控制,从设计、制造、质量、物流等环节全面掌控信息,实现…...

Vuex有几种属性以及它们的意义
有五种,分别是 State、 Getter、Mutation 、Action、 Module。 一、State Vuex 使用单一状态树——是的,用一个对象就包含了全部的应用层级状态。至此它便作为一个“唯一数据源 (SSOT)”而存在。这也意味着,每个应用将仅仅包含一个 store 实…...

PRBP20P-10/250C-EB、PRDP6G-10/30-CB电液比例直动式先导减压阀放大板
PRDP6P-10/30-CB、PRDP6R-10/50-DC、PRDP6G-10/30-CC、PRDP6P-10/50-CB、PRDP6R-10/30-CC、PRDP6G-10/30-CB电液比例直动式先导减压阀 PRBP10P-10/50C-EB、PRBP20P-10/100C-EC、PRBP30P-10/150C-EB、PRBP20P-10/250C-EB、PRBP10P-10/315C-EC、PRBP30P-10/350C-EB电液比例柱塞平…...

GDB之常见缩写命令(十九)
简介: CSDN博客专家,专注Android/Linux系统,分享多mic语音方案、音视频、编解码等技术,与大家一起成长! 优质专栏:Audio工程师进阶系列【原创干货持续更新中……】🚀 人生格言: 人生…...
)
MarkText快捷键(随时补充中)
MarkText快捷键 ctrl1:一号标题 (需要手动在【左上角】-【file】-【preferences】-【Key Bindings】-【 Transform into Heading 1】手动调整,先将【Switch tab to the 1st】占用快捷键删除才能在下面添加) ctrlg:添加…...
)
每日一题 1601最多可达成的换楼请求数目(子集模版)
题目 1601 我们有 n 栋楼,编号从 0 到 n - 1 。每栋楼有若干员工。由于现在是换楼的季节,部分员工想要换一栋楼居住。 给你一个数组 requests ,其中 requests[i] [fromi, toi] ,表示一个员工请求从编号为 fromi 的楼搬到编号为…...
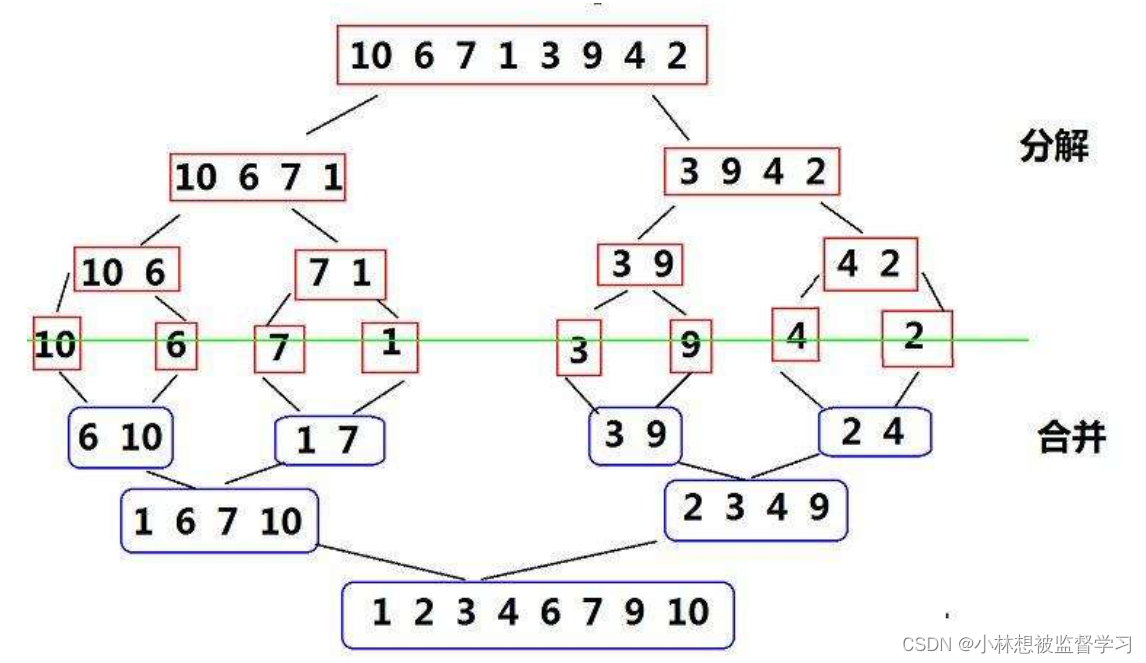
排序算法-归并排序
属性 归并排序(MERGE-SORT)是建立在归并操作上的一种有效的排序算法,该算法是采用分治法(Divide and Conquer)的一个非常典型的应用。将已有序的子序列合并,得到完全有序的序列;即先使每个子序列有序&#…...

vue3 整合 springboot 打完整jar包
前端 .env.developmen VITE_APP_BASE_URL/api.env.production VITE_APP_BASE_URL/axios 配置 axios.defaults.baseURL import.meta.env.VITE_APP_BASE_URLpackage.json "scripts": {"dev": "vite --mode development","build": &…...

依赖倒转原则是什么?
依赖倒转原则(Dependency Inversion Principle)是面向对象设计中的另一个基本原则,它是由Robert C. Martin提出的,它的中心思想是面向接口编程,该原则指出高层模块不应该依赖于低层模块,两者都应该依赖于抽…...

什么是GPT与MBR
GPT(GUID Partition Table)和MBR(Master Boot Record)是两种不同的磁盘分区表格式。 MBR是一种较早的磁盘分区表格式,它使用512字节的扇区作为存储空间。MBR分区表可以定义最多4个主分区,每个主分区都可以…...

前后端开发接口联调对接参数
前言 一个完整的互联网系统项目,需要前后端配合,进行上线,针对前端开发者,现在互联网主流的项目都是前后端分离 也就是后端负责提供数据接口,前端负责UI界面数据渲染 凡是在前台数据展示与用户交互的,都是由前端来实现的,而数据来源是由后台服务提供的 在浏览器c端能够发送后端…...

定时任务框架-xxljob
1.定时任务 spring传统的定时任务Scheduled,但是这样存在这一些问题 : 做集群任务的重复执行问题 cron表达式定义在代码之中,修改不方便 定时任务失败了,无法重试也没有统计 如果任务量过大,不能有效的分片执行 …...
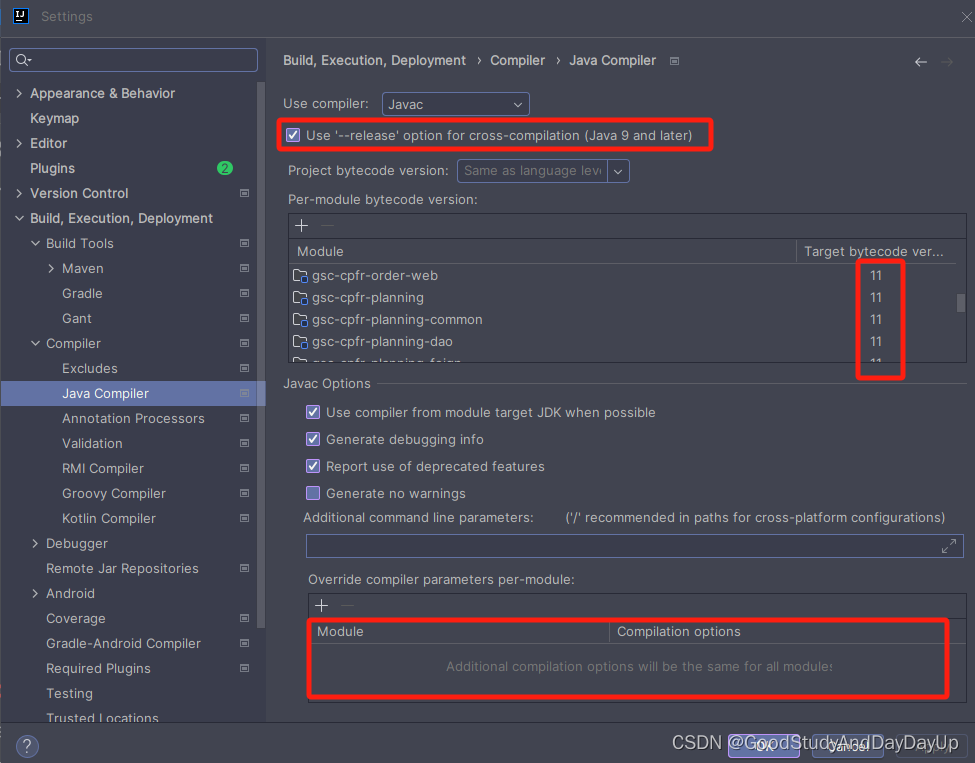
idea项目配置三大步
场景: 使用 idea 打开一个新项目的时候,想让项目迅速跑起来, 其实只需要下面简单三步: 1. 首先,配maven 2. 其次,配置 jdk 这里配置 project 就行了,不用管Modules中的配置。 3. 最后&#…...

学会SpringMVC之自定义注解各种场景应用,提高开发效率及代码质量
目录 一、简介 ( 1 ) 是什么 ( 2 ) 分类 ( 3 ) 作用 二、自定义注解 ( 1 ) 如何自定义注解 ( 2 ) 场景演示 场景一(获取类与方法上的注解值) 场景二( 获取类属性上的注解属性值 ) 场景三( 获取参数修…...
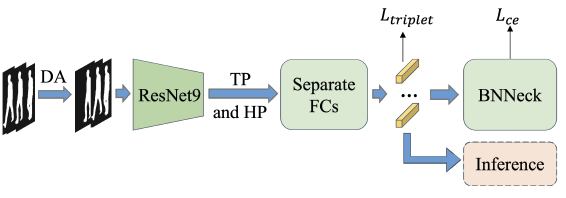
步态识别常见模块解读及代码实现:基于OpenGait框架
步态识别常见模块解读及代码实现:基于OpenGait框架 最近在看步态识别相关论文,但是因为记忆力下降的原因,老是忘记一些内容。因此记录下来方便以后查阅,仅供自己学习参考,没有背景知识和论文介绍。 目录 步态识别常见…...

前端八股文之“闭包”
一、定义 一句话概括闭包:能够访问函数内部变量的函数与这个变量的组合构成了闭包结构。如下代码 function fuc1(){let num 999return function fuc2(){console.log(num)}}fuc1()(); 如代码所示,fuc2和父级变量num构成了一个闭包环境。 二、原理 子…...

数据可视化:掌握数据领域的万金油技能
⭐️⭐️⭐️⭐️⭐️欢迎来到我的博客⭐️⭐️⭐️⭐️⭐️ 🐴作者:秋无之地 🐴简介:CSDN爬虫、后端、大数据领域创作者。目前从事python爬虫、后端和大数据等相关工作,主要擅长领域有:爬虫、后端、大数据开发、数据分析等。 🐴欢迎小伙伴们点赞👍🏻、收藏⭐️、…...
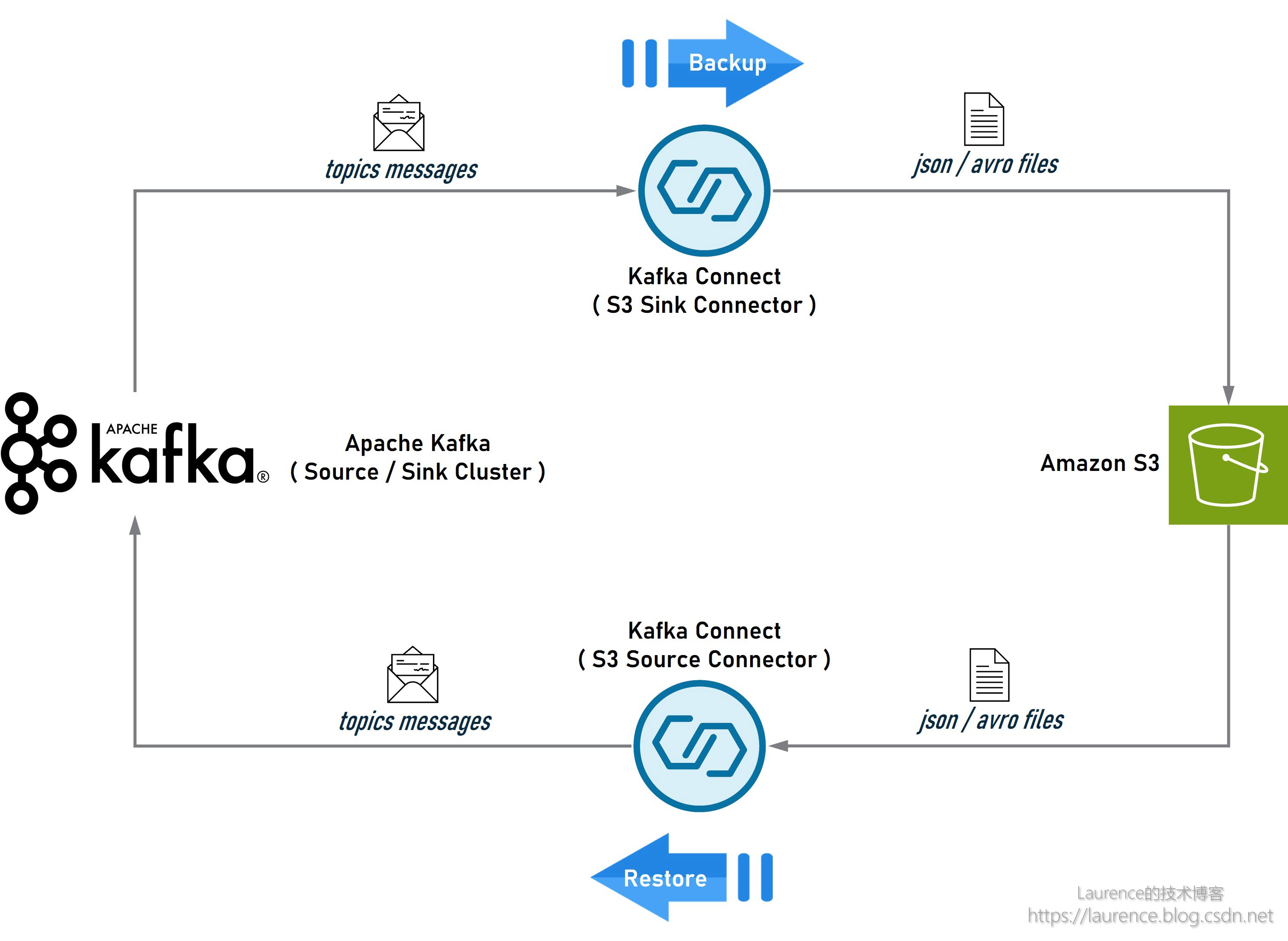
Apache Kafka 基于 S3 的数据导出、导入、备份、还原、迁移方案
在系统升级或迁移时,用户常常需要将一个 Kafka 集群中的数据导出(备份),然后在新集群或另一个集群中再将数据导入(还原)。通常,Kafka集群间的数据复制和同步多采用 Kafka MirrorMaker࿰…...

AI提示词工程:用Claude+Cursor构建高效创意工作流
1. 项目概述:当创意遇上AI,一个提示词库如何改变工作流如果你是一位创意工作者——无论是设计师、插画师、文案策划还是视频创作者,最近几个月,你的工作流里可能多了一个新伙伴:Claude。这个由Anthropic推出的AI助手&a…...

Awesome BigData实时数据集成平台:CDC连接器与数据同步工具终极指南
Awesome BigData实时数据集成平台:CDC连接器与数据同步工具终极指南 【免费下载链接】awesome-bigdata A curated list of awesome big data frameworks, ressources and other awesomeness. 项目地址: https://gitcode.com/gh_mirrors/aw/awesome-bigdata G…...

2026 最稳 AI 论文工具合集:好用不踩雷
毕业季的论文关卡,早已不是 “单打独斗” 的时代。从选题迷茫、大纲混乱,到文献难找、格式崩溃,再到查重超标、AI 率预警,每一个卡点都在消耗本科生的时间与精力。随着 AI 技术深度渗透学术场景,一批专注毕业论文写作的…...

芯片原型开发实战指南:从虚拟原型到FPGA的决策与调试
1. 原型决策前的核心考量:一份来自一线的深度清单在硬件和系统设计领域,原型开发是连接构想与现实的桥梁,但这座桥怎么搭、用什么材料、何时能通车,每一步都充满了抉择。很多团队在项目启动时,满腔热情地喊着“先做个原…...

3分钟让你的Windows桌面焕然一新:NoFences开源分区神器
3分钟让你的Windows桌面焕然一新:NoFences开源分区神器 【免费下载链接】NoFences 🚧 Open Source Stardock Fences alternative 项目地址: https://gitcode.com/gh_mirrors/no/NoFences 你是否每天都要在杂乱无章的桌面图标中寻找需要的文件&…...

技术深度解析:5大核心要点掌握Sunshine开源游戏串流服务器实战部署
技术深度解析:5大核心要点掌握Sunshine开源游戏串流服务器实战部署 【免费下载链接】Sunshine Self-hosted game stream host for Moonlight. 项目地址: https://gitcode.com/GitHub_Trending/su/Sunshine Sunshine是一款功能强大的自托管开源游戏串流服务器…...

为OpenClaw智能体工作流配置Taotoken作为核心模型提供商
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 为OpenClaw智能体工作流配置Taotoken作为核心模型提供商 OpenClaw是一个流行的智能体开发框架,它允许开发者构建和编排…...
)
WinForm弹窗进阶:手把手教你封装一个通用的MessageBoxHelper工具类(.NET Framework/C#)
WinForm弹窗进阶:打造高复用性的MessageBoxHelper工具类 在WinForm开发中,MessageBox.Show()就像空气一样无处不在——从简单的操作确认到复杂的错误处理,这个基础组件承担了太多交互职责。但当你第20次写下MessageBox.Show("操作成功&q…...

Cursor Pro功能解锁:3步实现免费无限制使用AI编辑器完整指南
Cursor Pro功能解锁:3步实现免费无限制使用AI编辑器完整指南 【免费下载链接】cursor-free-vip [Support 0.45](Multi Language 多语言)自动注册 Cursor Ai ,自动重置机器ID , 免费升级使用Pro 功能: Youve reached yo…...

Audacity音频编辑完全手册:从零开始制作专业音频作品
Audacity音频编辑完全手册:从零开始制作专业音频作品 【免费下载链接】audacity Audio Editor 项目地址: https://gitcode.com/GitHub_Trending/au/audacity 想制作播客却不知道如何剪辑?需要为视频添加背景音乐但找不到合适的工具?或…...