《动手学深度学习 Pytorch版》 6.6 卷积神经网络
import torch
from torch import nn
from d2l import torch as d2l
6.6.1 LeNet
LetNet-5 由两个部分组成:
- 卷积编码器:由两个卷积核组成。
- 全连接层稠密块:由三个全连接层组成。
模型结构如下流程图(每个卷积块由一个卷积层、一个 sigmoid 激活函数和平均汇聚层组成):
| 全连接层(10) |
|---|
↑ \uparrow ↑
| 全连接层(84) |
|---|
↑ \uparrow ↑
| 全连接层(120) |
|---|
↑ \uparrow ↑
| 2 × 2 2\times2 2×2平均汇聚层,步幅2 |
|---|
↑ \uparrow ↑
| 5 × 5 5\times5 5×5卷积层(16) |
|---|
↑ \uparrow ↑
| 2 × 2 2\times2 2×2平均汇聚层,步幅2 |
|---|
↑ \uparrow ↑
| 5 × 5 5\times5 5×5卷积层(6),填充2 |
|---|
↑ \uparrow ↑
| 输入图像( 28 × 28 28\times28 28×28 单通道) |
|---|
net = nn.Sequential(nn.Conv2d(1, 6, kernel_size=5, padding=2), nn.Sigmoid(),nn.AvgPool2d(kernel_size=2, stride=2),nn.Conv2d(6, 16, kernel_size=5), nn.Sigmoid(),nn.AvgPool2d(kernel_size=2, stride=2),nn.Flatten(),nn.Linear(16 * 5 * 5, 120), nn.Sigmoid(),nn.Linear(120, 84), nn.Sigmoid(),nn.Linear(84, 10))X = torch.rand(size=(1, 1, 28, 28), dtype=torch.float32) # 生成测试数据
for layer in net:X = layer(X)print(layer.__class__.__name__,'output shape: \t',X.shape) # 确保模型各层数据正确
Conv2d output shape: torch.Size([1, 6, 28, 28])
Sigmoid output shape: torch.Size([1, 6, 28, 28])
AvgPool2d output shape: torch.Size([1, 6, 14, 14])
Conv2d output shape: torch.Size([1, 16, 10, 10])
Sigmoid output shape: torch.Size([1, 16, 10, 10])
AvgPool2d output shape: torch.Size([1, 16, 5, 5])
Flatten output shape: torch.Size([1, 400])
Linear output shape: torch.Size([1, 120])
Sigmoid output shape: torch.Size([1, 120])
Linear output shape: torch.Size([1, 84])
Sigmoid output shape: torch.Size([1, 84])
Linear output shape: torch.Size([1, 10])
6.6.2 模型训练
batch_size = 256
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size=batch_size) # 仍使用经典的 Fashion-MNIST 数据集
def evaluate_accuracy_gpu(net, data_iter, device=None): #@save"""使用GPU计算模型在数据集上的精度"""if isinstance(net, nn.Module):net.eval() # 设置为评估模式if not device:device = next(iter(net.parameters())).devicemetric = d2l.Accumulator(2) # 生成一个有两个元素的列表,使用 add 将会累加到对应的元素上with torch.no_grad():for X, y in data_iter:# 为了使用 GPU,需要将数据移动到 GPU 上if isinstance(X, list):X = [x.to(device) for x in X]else:X = X.to(device)y = y.to(device)metric.add(d2l.accuracy(net(X), y), y.numel()) # 累加(正确预测的数量,总预测的数量)return metric[0] / metric[1] # 正确率
#@save
def train_ch6(net, train_iter, test_iter, num_epochs, lr, device):"""用GPU训练模型(在第六章定义)"""def init_weights(m): # 使用 Xavier 初始化权重if type(m) == nn.Linear or type(m) == nn.Conv2d:nn.init.xavier_uniform_(m.weight)net.apply(init_weights)print('training on', device)net.to(device) # 移动数据到GPUoptimizer = torch.optim.SGD(net.parameters(), lr=lr)loss = nn.CrossEntropyLoss()animator = d2l.Animator(xlabel='epoch', xlim=[1, num_epochs],legend=['train loss', 'train acc', 'test acc'])timer, num_batches = d2l.Timer(), len(train_iter)for epoch in range(num_epochs):# 训练损失之和,训练准确率之和,样本数metric = d2l.Accumulator(3)net.train()for i, (X, y) in enumerate(train_iter):timer.start()optimizer.zero_grad()X, y = X.to(device), y.to(device)y_hat = net(X)l = loss(y_hat, y)l.backward()optimizer.step()with torch.no_grad():metric.add(l * X.shape[0], d2l.accuracy(y_hat, y), X.shape[0])timer.stop()train_l = metric[0] / metric[2]train_acc = metric[1] / metric[2]if (i + 1) % (num_batches // 5) == 0 or i == num_batches - 1:animator.add(epoch + (i + 1) / num_batches,(train_l, train_acc, None))test_acc = evaluate_accuracy_gpu(net, test_iter)animator.add(epoch + 1, (None, None, test_acc))print(f'loss {train_l:.3f}, train acc {train_acc:.3f}, 'f'test acc {test_acc:.3f}')print(f'{metric[2] * num_epochs / timer.sum():.1f} examples/sec 'f'on {str(device)}')
lr, num_epochs = 0.9, 10
train_ch6(net, train_iter, test_iter, num_epochs, lr, d2l.try_gpu())
loss 0.471, train acc 0.820, test acc 0.815
40056.7 examples/sec on cuda:0

练习
(1)将平均汇聚层替换为最大汇聚层,会发生什么?
net_Max = nn.Sequential(nn.Conv2d(1, 6, kernel_size=5, padding=2), nn.Sigmoid(),nn.MaxPool2d(kernel_size=2, stride=2),nn.Conv2d(6, 16, kernel_size=5), nn.Sigmoid(),nn.MaxPool2d(kernel_size=2, stride=2),nn.Flatten(),nn.Linear(16 * 5 * 5, 120), nn.Sigmoid(),nn.Linear(120, 84), nn.Sigmoid(),nn.Linear(84, 10))lr, num_epochs = 0.9, 10
train_ch6(net_Max, train_iter, test_iter, num_epochs, lr, d2l.try_gpu())
loss 0.422, train acc 0.844, test acc 0.671
31151.6 examples/sec on cuda:0

几乎无区别
(2)尝试构建一个基于 LeNet 的更复杂网络,以提高其精准性。
a. 调节卷积窗口的大小。
b. 调整输出通道的数量。
c. 调整激活函数(如 ReLU)。
d. 调整卷积层的数量。
e. 调整全连接层的数量。
f. 调整学习率和其他训练细节(例如,初始化和轮数)。
net_Best = nn.Sequential(nn.Conv2d(1, 8, kernel_size=5, padding=2), nn.ReLU(),nn.AvgPool2d(kernel_size=2, stride=2),nn.Conv2d(8, 16, kernel_size=3, padding=1), nn.ReLU(),nn.AvgPool2d(kernel_size=2, stride=2),nn.Conv2d(16, 32, kernel_size=3, padding=1), nn.ReLU(),nn.AvgPool2d(kernel_size=2, stride=2),nn.Flatten(),nn.Linear(32 * 3 * 3, 128), nn.ReLU(),nn.Linear(128, 64), nn.ReLU(),nn.Linear(64, 32), nn.ReLU(),nn.Linear(32, 10)
)
lr, num_epochs = 0.4, 10
train_ch6(net_Best, train_iter, test_iter, num_epochs, lr, d2l.try_gpu())
loss 0.344, train acc 0.869, test acc 0.854
32868.3 examples/sec on cuda:0

(3)在 MNIST 数据集上尝试以上改进后的网络。
import torchvision
from torch.utils import data
from torchvision import transformstrans = transforms.ToTensor()
mnist_train = torchvision.datasets.MNIST(root="../data", train=True, transform=trans, download=True)
mnist_test = torchvision.datasets.MNIST(root="../data", train=False, transform=trans, download=True)
train_iter2 = data.DataLoader(mnist_train, batch_size, shuffle=True,num_workers=d2l.get_dataloader_workers())
test_iter2 = data.DataLoader(mnist_test, batch_size, shuffle=True,num_workers=d2l.get_dataloader_workers())lr, num_epochs = 0.4, 5 # 大约 6 轮往后直接就爆炸
train_ch6(net_Best, train_iter2, test_iter2, num_epochs, lr, d2l.try_gpu())
loss 0.049, train acc 0.985, test acc 0.986
26531.1 examples/sec on cuda:0

(4)显示不同输入(例如,毛衣和外套)时 LetNet 第一层和第二层的激活值。
for X, y in test_iter:breakx_first_Sigmoid_layer = net[0:2](X)[0:9, 1, :, :]
d2l.show_images(x_first_Sigmoid_layer.reshape(9, 28, 28).cpu().detach(), 1, 9)
x_second_Sigmoid_layer = net[0:5](X)[0:9, 1, :, :]
d2l.show_images(x_second_Sigmoid_layer.reshape(9, 10, 10).cpu().detach(), 1, 9)
d2l.plt.show()


相关文章:
《动手学深度学习 Pytorch版》 6.6 卷积神经网络
import torch from torch import nn from d2l import torch as d2l6.6.1 LeNet LetNet-5 由两个部分组成: - 卷积编码器:由两个卷积核组成。 - 全连接层稠密块:由三个全连接层组成。模型结构如下流程图(每个卷积块由一个卷积层、…...
【微信小程序】项目初始化
| var() CSS 函数可以插入一个自定义属性(有时也被称为“CSS 变量”)的值,用来代替非自定义 属性中值的任何部分。 1.初始化样式与颜色 view,text{box-sizing: border-box; } page{--themColor:#ad905c;--globalColor:#18191b;--focusColor…...
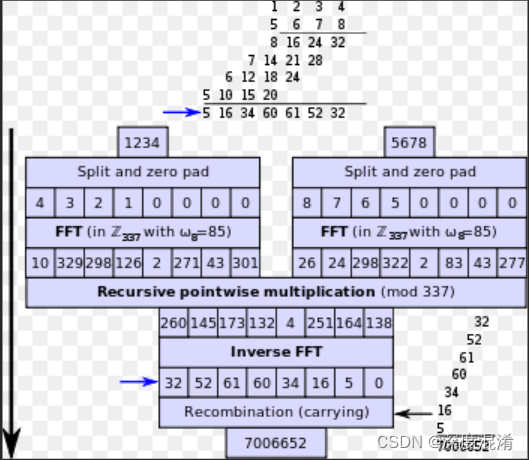
C#,《小白学程序》第二十六课:大数乘法(BigInteger Multiply)的Toom-Cook 3算法及源程序
凑数的,仅供参考。 1 文本格式 /// <summary> /// 《小白学程序》第二十六课:大数(BigInteger)的Toom-Cook 3乘法 /// Toom-Cook 3-Way Multiplication /// </summary> /// <param name"a"></par…...
destoon自定义一个archiver内容文档
在archiver目录建立以下代码: <?php define(DT_REWRITE, true); require ../common.inc.php; $EXT[archiver_enable] or dheader(DT_PATH); //$DT_BOT or dheader(DT_PATH); $N $M $T array(); $mid or $mid 5; $vmid $list 0; foreach($MODULE as $k>…...
5-1 Dataset和DataLoader
Pytorch通常使用Dataset和DataLoader这两个工具类来构建数据管道。 Dataset定义了数据集的内容,它相当于一个类似列表的数据结构,具有确定的长度,能够用索引获取数据集中的元素。 而DataLoader定义了按batch加载数据集的方法,它是…...
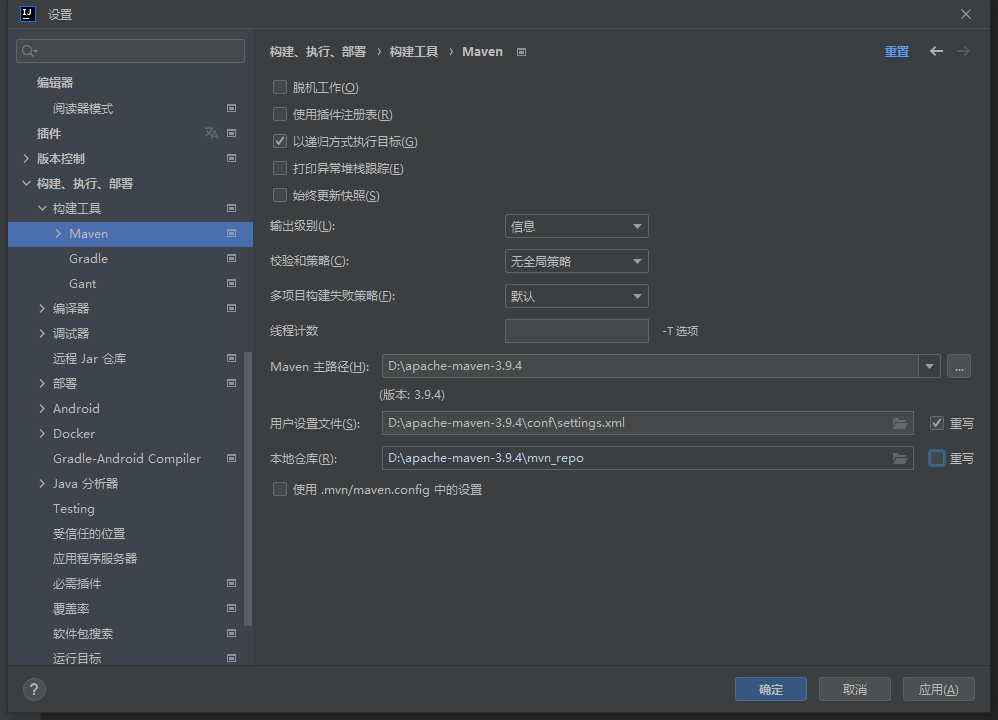
IDEA创建完Maven工程后,右下角一直显示正在下载Maven插件
原因: 这是由于新建的Maven工程,IDEA会用它内置的默认的Maven版本,使用国外的网站下载Maven所需的插件,速度很慢 。 解决方式: 每次创建 Project 后都需要设置 Maven 家目录位置(就是我们自己下载的Mav…...

最新清理删除Mac电脑内存空间方法教程
Mac电脑使用的时间越久,系统的运行就会变的越卡顿,这是Mac os会出现的正常现象,卡顿的原因主要是系统缓存文件占用了较多的磁盘空间,或者Mac的内存空间已满。如果你的Mac运行速度变慢,很有可能是因为磁盘内存被过度占用…...

【调试经验】MySQL - fatal error: mysql/mysql.h: 没有那个文件或目录
机器环境: Ubuntu 22.04.3 LTS 报错问题 在编译一个项目时出现了一段SQL报错: CGImysql/sql_connection_pool.cpp:1:10: fatal error: mysql/mysql.h: 没有那个文件或目录 1 | #include <mysql/mysql.h> | ^~~~~~~~~~~~~~~ c…...

腾讯mini项目-【指标监控服务重构】2023-08-12
今日已办 Watermill Handler 将 4 个阶段的逻辑处理定义为 Handler 测试发现,添加的 handler 会被覆盖掉,故考虑添加为 middleware 且 4 个阶段的处理逻辑针对不同 topic 是相同的。 参考https://watermill.io/docs/messages-router/实现不同topic&am…...

kubeadm部署k8sv1.24使用cri-docker做为CRI
目的 测试使用cri-docker做为containerd和docker的中间层垫片。 规划 IP系统主机名10.0.6.5ubuntu 22.04.3 jammymaster01.kktb.org10.0.6.6ubuntu 22.04.3 jammymaster02.kktb.org10.0.6.7ubuntu 22.04.3 jammymaster03.kktb.org 配置 步骤: 系统优化 禁用sw…...
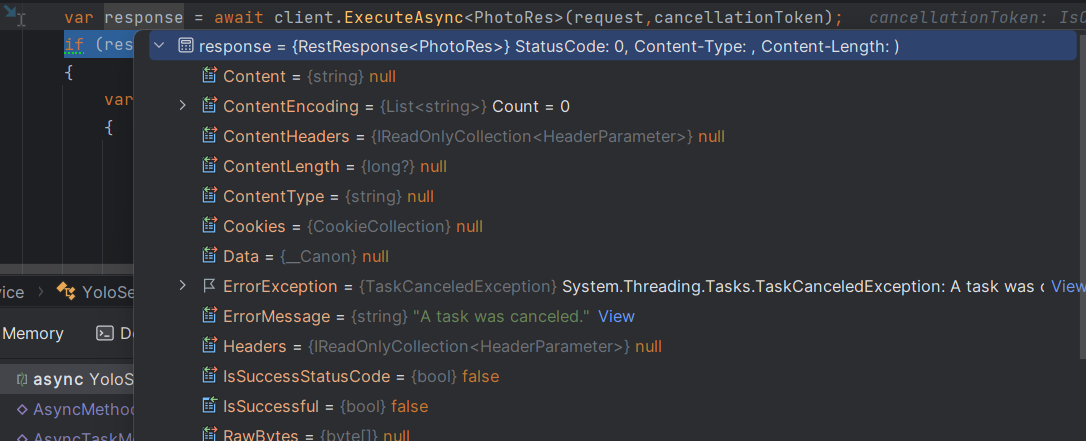
在c#中使用CancellationToken取消任务
目录 🚀介绍: 🐤简单举例 🚀IsCancellationRequested 🚀ThrowIfCancellationRequested 🐤在控制器中使用 🚀通过异步方法的参数使用cancellationToken 🚀api结合ThrowIfCancel…...
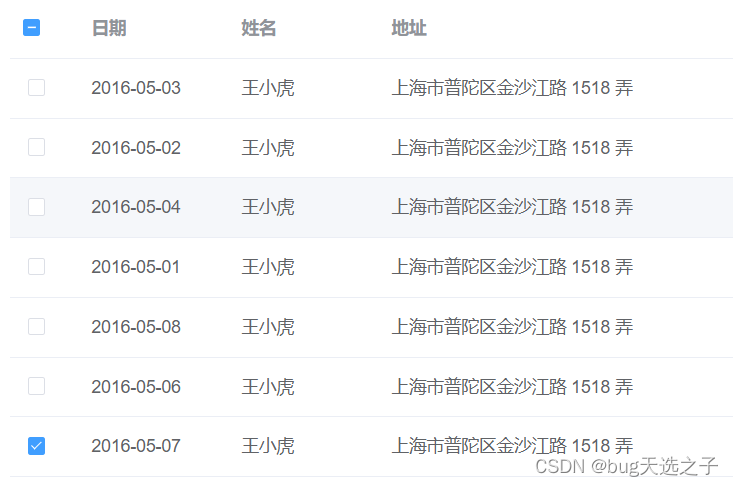
【项目经验】:elementui多选表格默认选中
一.需求 在页面刚打开就默认选中指定项。 二.方法Table Methods toggleRowSelection用于多选表格,切换某一行的选中状态,如果使用了第二个参数,则是设置这一行选中与否(selected 为 true 则选中)row, selected 详细…...

外星人入侵游戏-(创新版)
🌈write in front🌈 🧸大家好,我是Aileen🧸.希望你看完之后,能对你有所帮助,不足请指正!共同学习交流. 🆔本文由Aileen_0v0🧸 原创 CSDN首发🐒 如…...
HTML 学习笔记(基础)
它是超文本标记语言,由一大堆约定俗成的标签组成,而其标签里一般又有一些属性值可以设置。 W3C标准:网页主要三大部分 结构:HTML表现:CSS行为:JavaScript <!DOCTYPE html> <html lang"zh-…...

最小二乘法
Least Square Method 1、相关的矩阵公式2、线性回归3、最小二乘法3.1、损失函数(Loss Function)3.2、多维空间的损失函数3.3、解析法求解3.4、梯度下降法求解 1、相关的矩阵公式 P r e c o n d i t i o n : ξ ∈ R n , A ∈ R n ∗ n i : σ A ξ σ ξ…...

使用stelnet进行安全的远程管理
1. telnet有哪些不足? 2.ssh如何保证数据传输安全? 需求:远程telnet管理设备 用户定义需要在AAA模式下: 开启远程登录的服务:定义vty接口 然后从R2登录:是可以登录的 同理R3登录: 在R1也可以查…...

python 二手车数据分析以及价格预测
二手车交易信息爬取、数据分析以及交易价格预测 引言一、数据爬取1.1 解析数据1.2 编写代码爬1.2.1 获取详细信息1.2.2 数据处理 二、数据分析2.1 统计分析2.2 可视化分析 三、价格预测3.1 价格趋势分析(特征分析)3.2 价格预测 引言 本文着眼于车辆信息,结合当下较…...
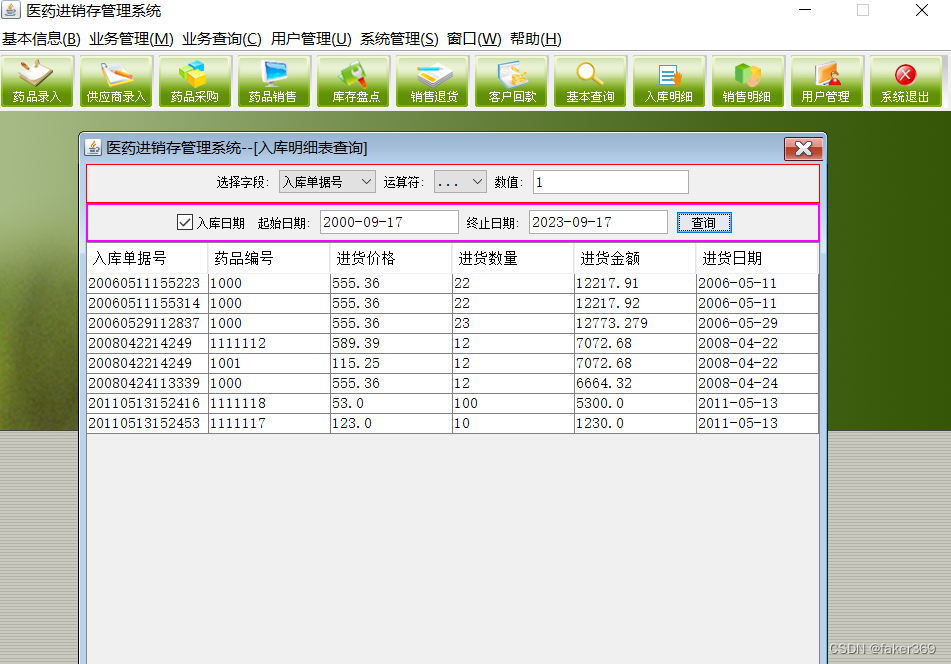
JAVA医药进销存管理系统(附源码+调试)
JAVA医药进销存管理系统 功能描述 (1)登录模块:登录信息等存储在数据库中 (2)基本信息模块:分为药品信息模块、客户情况模块、供应商情况模块; (3)业务管理模块&#x…...

H5 <blockquote> 标签
主要应用于:内容引用 标签定义及使用说明 <blockquote> 标签定义摘自另一个源的块引用。 浏览器通常会对 <blockquote> 元素进行缩进。 提示和注释 提示:如果标记是不需要段落分隔的短引用,请使用 <q>。 HTML 4.01 与 H…...
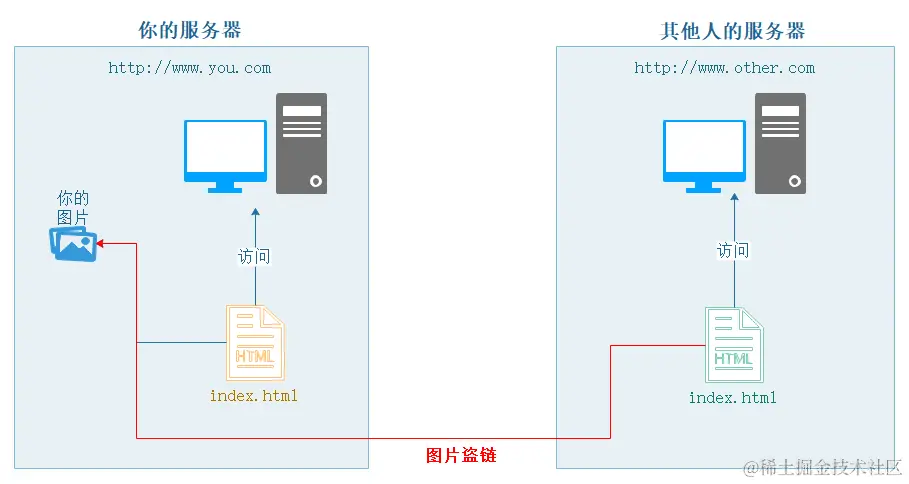
nginx配置指南
nginx.conf配置 找到Nginx的安装目录下的nginx.conf文件,该文件负责Nginx的基础功能配置。 配置文件概述 Nginx的主配置文件(conf/nginx.conf)按以下结构组织: 配置块功能描述全局块与Nginx运行相关的全局设置events块与网络连接有关的设置http块代理…...

基于ChatGPT与Next.js的React组件自然语言生成器开发实战
1. 项目概述:一个由ChatGPT驱动的React组件实时生成器 作为一名在React生态里摸爬滚打了多年的前端开发者,我深知从零开始构建一个UI组件,尤其是那些需要反复调整样式和交互逻辑的组件,是多么耗时耗力。我们常常在Figma里画好了设…...

E-Hentai下载器:免费漫画批量下载工具完整指南
E-Hentai下载器:免费漫画批量下载工具完整指南 【免费下载链接】E-Hentai-Downloader Download E-Hentai archive as zip file 项目地址: https://gitcode.com/gh_mirrors/eh/E-Hentai-Downloader 你是否曾经为了收藏喜欢的漫画而一页一页手动保存࿱…...

02数据模型与单词仓库-鸿蒙PC端Electron开发
欢迎加入开源鸿蒙PC社区 https://harmonypc.csdn.net/ 源码仓库 https://atomgit.com/qq_33247427/englishProject.git 效果截图 第2篇:数据模型与单词仓库 系列教程导航 篇号 标题 状态 01 环境搭建与项目创建 ✅ 已完成 02 数据模型与单词仓库 本篇 …...

收藏!AI时代程序员转型指南:从纯编码到人机协同高手
本文揭示了AI对程序员行业的深刻变革:初级编码岗需求锐减,而AI协作、架构师等高端岗位需求激增。文章提出两个阶段提升竞争力:第一阶段掌握AI工具栈(编码助手、调试工具等)并遵循人机协同法则;第二阶段构建…...

基于RAG与向量数据库的本地化个人知识库构建实践
1. 项目概述:一个为个人量身定制的知识库构建引擎 如果你和我一样,每天在浏览器、笔记软件、PDF文档和各种聊天记录之间疲于奔命,试图抓住那些一闪而过的灵感和零散的知识点,那么你肯定理解“知识碎片化”的痛苦。我们收藏了无数…...

阴阳师百鬼夜行AI自动化:3分钟配置实现全智能碎片收集
阴阳师百鬼夜行AI自动化:3分钟配置实现全智能碎片收集 【免费下载链接】OnmyojiAutoScript Onmyoji Auto Script | 阴阳师脚本 项目地址: https://gitcode.com/gh_mirrors/on/OnmyojiAutoScript 还在为手动刷百鬼夜行而烦恼吗?每天重复点击、熬夜…...

repo2txt:从Git仓库到结构化文本的自动化提取工具详解
1. 项目概述:从代码仓库到纯文本的自动化提取最近在整理个人技术笔记和搭建内部知识库时,我遇到了一个挺普遍但有点烦人的问题:如何把分散在多个Git仓库里的代码、文档和配置文件,快速、完整地转换成结构清晰的纯文本文件…...

5个场景告诉你:为什么你需要这款免费的窗口分辨率神器
5个场景告诉你:为什么你需要这款免费的窗口分辨率神器 【免费下载链接】SRWE Simple Runtime Window Editor 项目地址: https://gitcode.com/gh_mirrors/sr/SRWE 你是否曾遇到过这些困扰?游戏内分辨率选项有限,无法满足你对极致画质的…...

实战配置指南:5个技巧让PlayStation手柄在Windows上发挥专业级性能
实战配置指南:5个技巧让PlayStation手柄在Windows上发挥专业级性能 【免费下载链接】DS4Windows Like those other ds4tools, but sexier 项目地址: https://gitcode.com/gh_mirrors/ds/DS4Windows DS4Windows是一款功能强大的开源控制器兼容工具,…...

别再微调模型了!Claude 3.5 Sonnet新增3类零样本指令模板:Prompt工程师的最后护城河正在崩塌?
更多请点击: https://intelliparadigm.com 第一章:Claude 3.5 Sonnet零样本指令能力的范式跃迁 Claude 3.5 Sonnet 在零样本(zero-shot)场景下展现出前所未有的指令理解与泛化能力,标志着大模型从“模式复现”向“意图…...