python爬虫爬取电影数据并做可视化
思路:
1、发送请求,解析html里面的数据
2、保存到csv文件
3、数据处理
4、数据可视化
需要用到的库:
import requests,csv #请求库和保存库
import pandas as pd #读取csv文件以及操作数据
from lxml import etree #解析html库
from pyecharts.charts import * #可视化库注意:后续用到分词库jieba以及词频统计库nltk
环境:
python 3.10.5版本
编辑器:vscode -jupyter
使用ipynb文件的扩展名 vscode会提示安装jupyter插件
一、发送请求、获取html
#请求的网址
url='https://ssr1.scrape.center/page/1'#请求头
headers={"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36"
}#发起请求,获取文本数据
reponse=requests.get(url,url,headers=headers)
print(reponse)
二、使用xpath提取html里面的数据并存到csv
#创建csv文件
with open('电影数据.csv',mode='w',encoding='utf-8',newline='') as f:#创建csv对象csv_save=csv.writer(f)#创建标题csv_save.writerow(['电影名','电影上映地','电影时长','上映时间','电影评分'])for page in range(1,11): #传播关键1到10页的页数#请求的网址url='https://ssr1.scrape.center/page/{}'.format(page)print('当前请求页数:',page)#请求头headers={"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36"}response=requests.get(url,url,headers=headers,verify=False)print(response)html_data=etree.HTML(response.text)#获取电影名title=html_data.xpath('//div[@class="p-h el-col el-col-24 el-col-xs-9 el-col-sm-13 el-col-md-16"]/a/h2/text()')#获取电影制作地gbs=html_data.xpath('//div[@class="p-h el-col el-col-24 el-col-xs-9 el-col-sm-13 el-col-md-16"]/div[2]/span[1]/text()')#获取电影时长time=html_data.xpath('//div[@class="m-v-sm info"]/span[3]/text()')#获取电影上映时间move_time=html_data.xpath('//div[@class="p-h el-col el-col-24 el-col-xs-9 el-col-sm-13 el-col-md-16"]/div[3]/span/text()')#电影评分numder=html_data.xpath('//p[@class="score m-t-md m-b-n-sm"]/text()')for name,move_gbs,times,move_times,numders in zip(title,gbs,time,move_time,numder):print('电影名:',name,' 电影上映地址:',move_gbs,' 电影时长:',times,' 电影上映时间:',move_times,' 电影评分:',numders)#name,move_gbs,times,move_times,numders#写入csv文件csv_save.writerow([name,move_gbs,times,move_times,numders])效果:
三、使用pandas打开爬取的csv文件
data=pd.read_csv('电影数据.csv',encoding='utf-8')
print(data)四、对电影名进行分词以及词频统计
注意:使用jieba分词,nltk分词
这里的停用此表可以自己创建一个 里面放无意义的字,比如:的、不是、不然这些
每个字独占一行即可
import jiebatitle_list=[]for name in data['电影名']:#进行精准分词lcut=jieba.lcut(name,cut_all=False)
# print(lcut)for i in lcut :
# print(i)#去除无意义的词#打开停用词表文件file_path=open('停用词表.txt',encoding='utf-8')#将读取的数据赋值给stop_words变量stop_words=file_path.read()#遍历后的值 如果没有在停用词表里面 则添加到net_data列表里面if i not in stop_words:title_list.append(i)
# print(title_list)#计算词语出现的频率
from nltk import FreqDist #该模块提供了计算频率分布的功能#FreqDist对象将计算net_data中每个单词的出现频率,,并将结果存储在freq_list中
freq_list=FreqDist(title_list)
print(freq_list) #结果:FreqDist 有1321个样本和5767个结果 #该方法返回一个包含最常出现单词及其出现频率的列表。将该列表赋值给most_common_words变量。
most_common_words=freq_list.most_common()
print(most_common_words) #结果:('The这个词',出现185次)效果:
五、词云可视化
# 创建一个 WordCloud类(词云) 实例
word_cloud = WordCloud() # 添加数据和词云大小范围 add('标题', 数据, word_size_range=将出现频率最高的单词添加到词云图中,并设置单词的大小范围为 20 到 100。)
word_cloud.add('词云图', most_common_words, word_size_range=[20, 100]) # 设置全局选项,包括标题
word_cloud.set_global_opts(title_opts=opts.TitleOpts(title='电影数据词云图')) # 在 Jupyter Notebook 中渲染词云图
word_cloud.render_notebook()#也可以生成html文件观看
word_cloud.render('result.html')运行效果:
六、对电影时长进行统计并做柱形图可视化
#电影时长 去除分钟和,号这个 转为int 然后再转为列表 只提取20条数据,总共100条
move_time=data['电影时长'].apply(lambda x: x.replace('分钟', '').replace(',', '')).astype('int').tolist()[0:20]
# print(move_time)#电影名 只提取20条数据
move_name=data['电影名'].tolist()[0:20]
# print(move_name)#创建Bar实例
Bar_obj=Bar()#添加x轴数据标题
Bar_obj.add_xaxis(move_name)#添加y轴数据
Bar_obj.add_yaxis('电影时长数据(单位:分钟)',move_time)#设置标题
Bar_obj.set_global_opts(title_opts={'text': '电影时长数据柱形图可视化'})# 显示图表
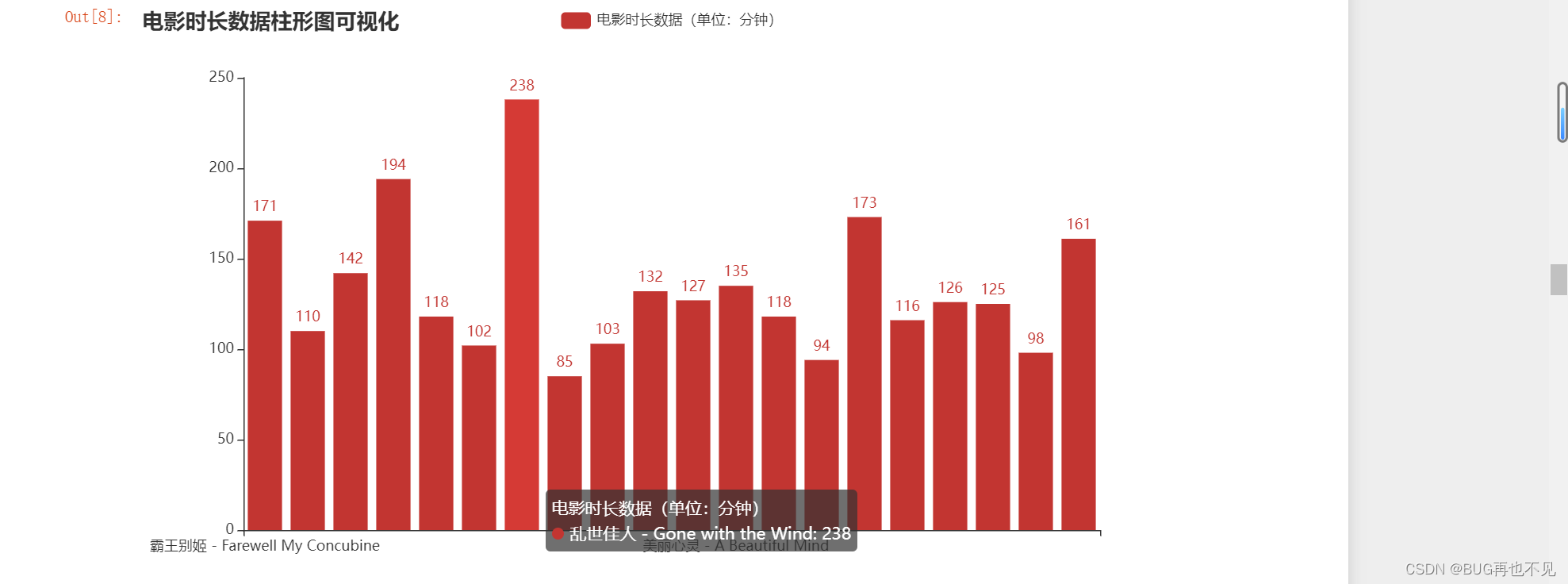
Bar_obj.render_notebook()
效果:
七、电影时长折线图可视化
#去除分钟和,号这个 转为int 然后再转为列表 只提取25条数据
move_time=data['电影时长'].apply(lambda x: x.replace('分钟', '').replace(',', '')).astype('int').tolist()[0:25]
# print(move_time)#电影名 只提取25条数据
move_name=data['电影名'].tolist()[0:25]
# print(move_name)#创建Bar实例
Bar_obj=Line()#添加x轴数据标题
Bar_obj.add_xaxis(move_name)#添加y轴数据
Bar_obj.add_yaxis('电影时长数据(单位:分钟)',move_time)#设置标题
Bar_obj.set_global_opts(title_opts={'text': '电影时长数据折线图可视化'})# 显示图表
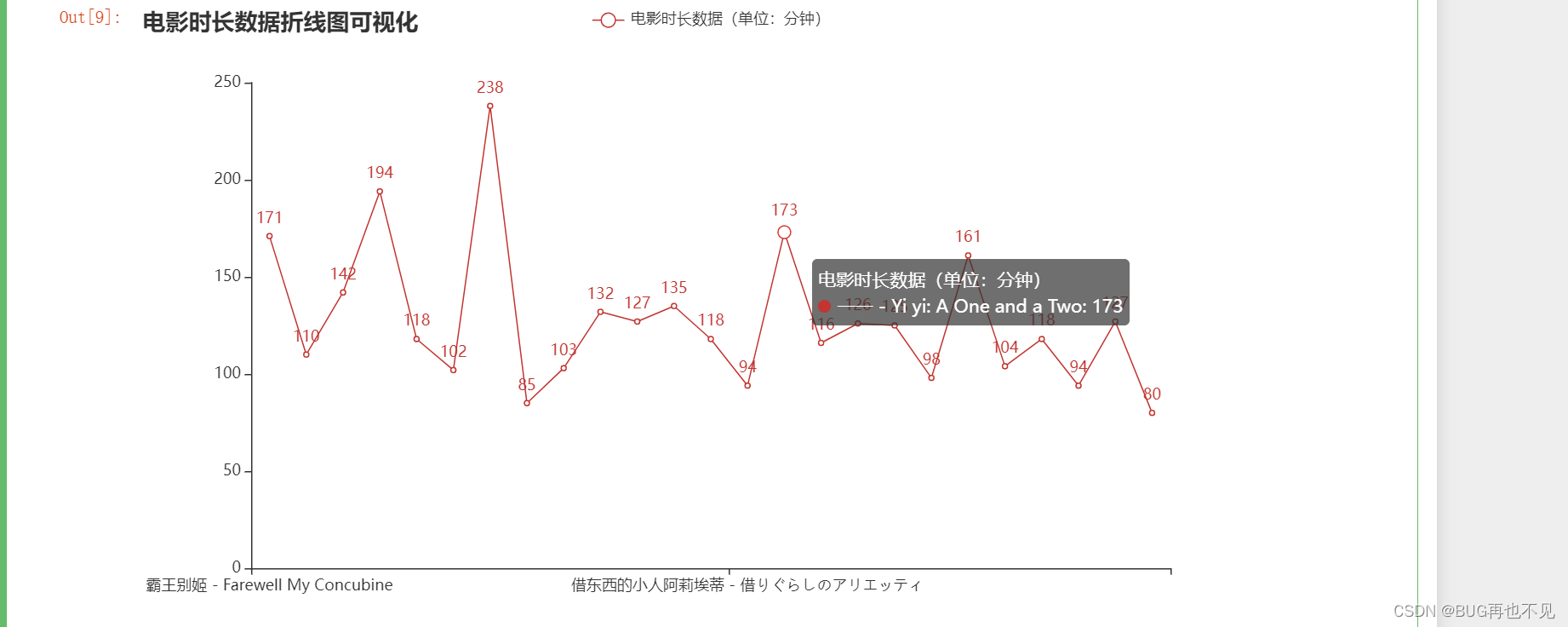
Bar_obj.render_notebook()效果:
八、统计每个国家电影上映的数量
import jiebatitle_list=[]#遍历电影上映地这一列
for name in data['电影上映地']:#进行精准分词lcut=jieba.lcut(name,cut_all=False)
# print(lcut)for i in lcut :
# print(i)#去除无意义的词#打开停用词表文件file_path=open('停用词表.txt',encoding='utf-8')#将读取的数据赋值给stop_words变量stop_words=file_path.read()#遍历后的值 如果没有在停用词表里面 则添加到net_data列表里面if i not in stop_words:title_list.append(i)
# print(title_list)#计算词语出现的频率
from nltk import FreqDist #该模块提供了计算频率分布的功能#FreqDist对象将计算net_data中每个单词的出现频率,,并将结果存储在freq_list中
freq_list=FreqDist(title_list)
print(freq_list) #结果:FreqDist 有1321个样本和5767个结果 #该方法返回一个包含最常出现单词及其出现频率的列表。将该列表赋值给most_common_words变量。
most_common_words=freq_list.most_common()
print(most_common_words) #结果:('单人这个词',出现185次)#电影名 使用列表推导式来提取most_common_words中每个元素中的第一个元素,即出现次数,然后将它们存储在一个新的列表中
map_data_title = [count[0] for count in most_common_words]
print(map_data_title)#电影数
map_data=[count[1] for count in most_common_words]
print(map_data)效果:

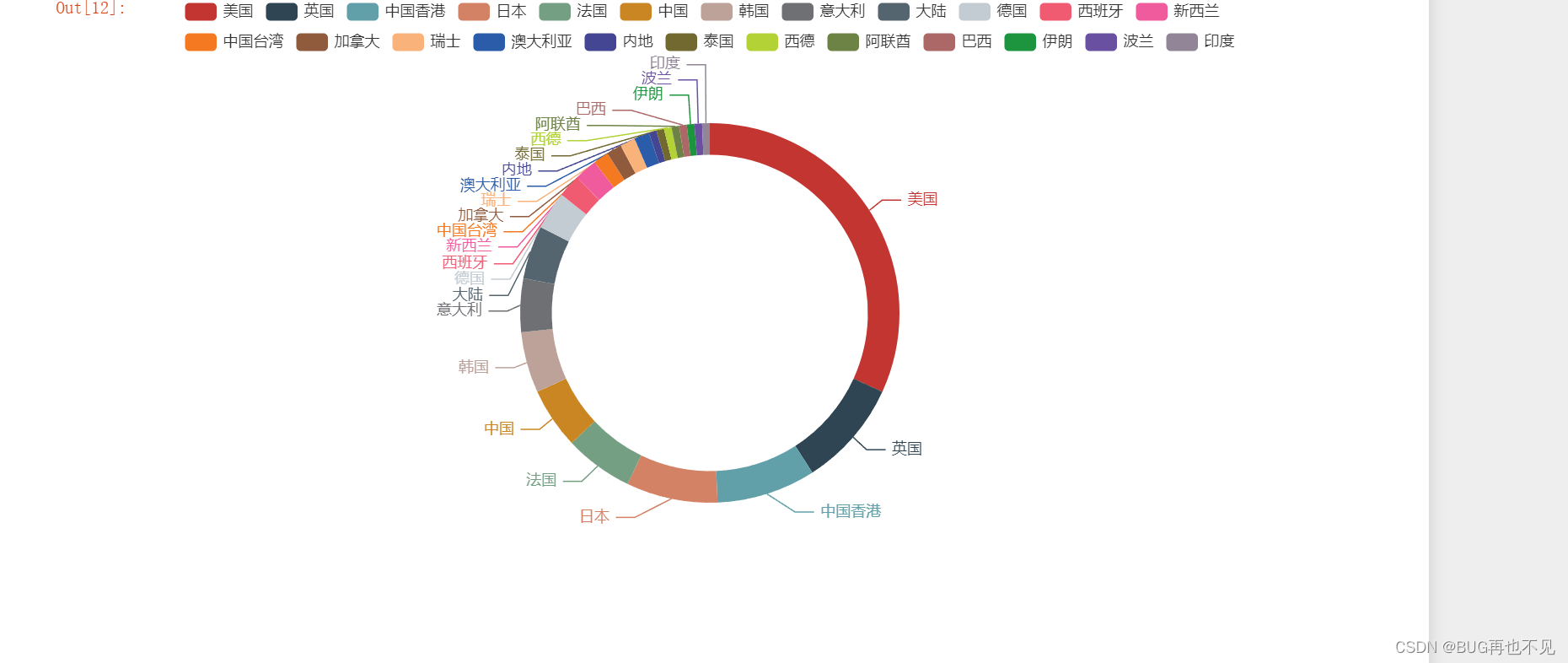
九、对每个国家电影上映数量饼图可视化
#获取map_data_title的长度,决定循环次数,赋值给遍历i 在通过下标取值
result = [[map_data_title[i], map_data[i]] for i in range(len(map_data_title))]
print(result)# 创建Pie实例
chart=Pie()#添加标题和数据 radius=['圆形空白处百分比','色块百分比(大小)'] 可不写
chart.add('电影上映数饼图(单位:个)',result,radius=['50%','60%'])#显示
chart.render_notebook()效果:
觉得有帮助的话,点个赞!
相关文章:
python爬虫爬取电影数据并做可视化
思路: 1、发送请求,解析html里面的数据 2、保存到csv文件 3、数据处理 4、数据可视化 需要用到的库: import requests,csv #请求库和保存库 import pandas as pd #读取csv文件以及操作数据 from lxml import etree #解析html库 from …...
哈希及哈希表的实现
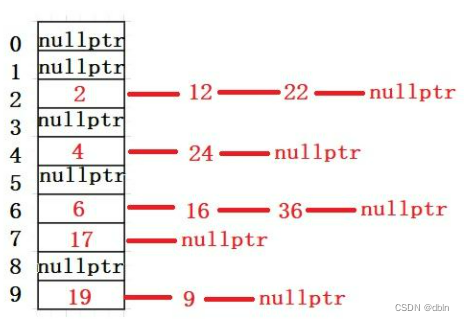
目录 一、哈希的引入 二、概念 三、哈希冲突 四、哈希函数 常见的哈希函数 1、直接定址法 2、除留余数法 五、哈希冲突的解决 1、闭散列 2、开散列 一、哈希的引入 顺序结构以及平衡树中,元素关键码与其存储位置之间没有对应的关系,因此在查找…...
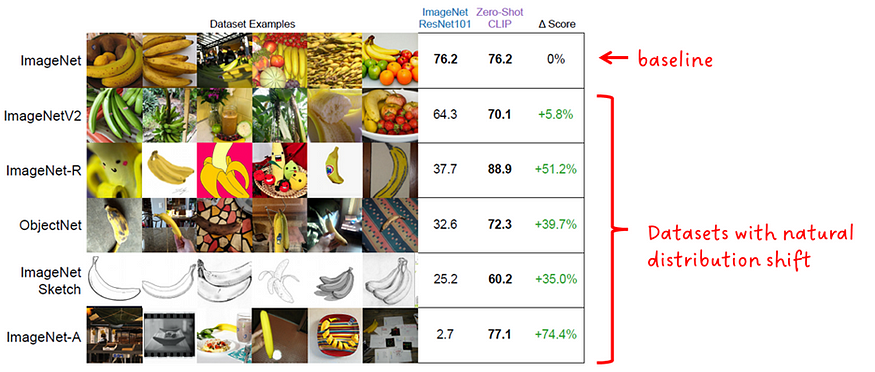
CLIP 基础模型:从自然语言监督中学习可转移的视觉模型
一、说明 在本文中,我们将介绍CLIP背后的论文(Contrastive Language-I mage Pre-Training)。我们将提取关键概念并分解它们以使其易于理解。此外,还对图像和数据图表进行了注释以澄清疑问。 图片来源: 论文:…...

解读性能指标TP50、TP90、TP99、TP999
TP指标说明 TP指标: 指在一个时间段内,统计该方法每次调用所消耗的时间,并将这些时间按从小到大的顺序进行排序, 并取出结果为:总次数*指标数对应TP指标的值,再取出排序好的时间。 TPTop Percentile,Top百分数&#…...

【无标题】mysql 截取两个,之间字符串
截取两个,之间字符串 select area,SUBSTRING_INDEX(et.area,,,1) as XZQH1,if(length(et.area)-length(replace(et.area,,,))>1,SUBSTRING_INDEX(SUBSTRING_INDEX(et.area,,,2),,,-1),NULL) AS XZQH2,if(length(et.area)-length(replace(et.area,,,))>2,SUBS…...

全局的键盘监听事件
一、设定全局键盘监听事件 放在vue 的created()或者mounted ()中,可对整个文档进行键盘事件监听。 new Vue({ created() { window.addEventListener(keydown, this.handleKeydown); }, beforeDestroy() { window.removeEventListener(keydown, this.handleK…...
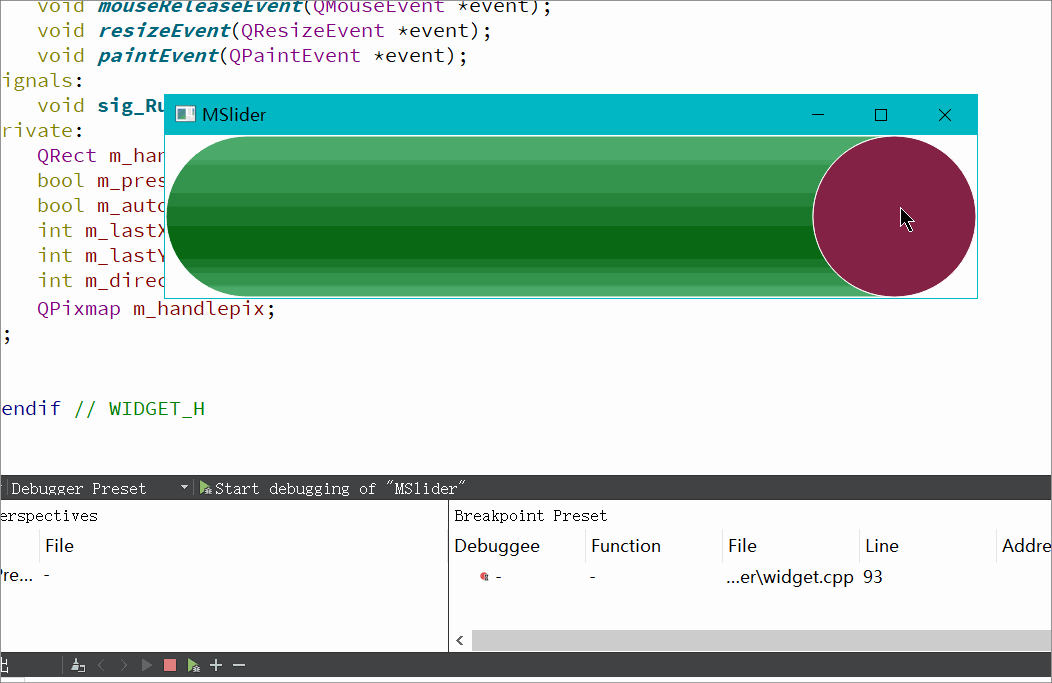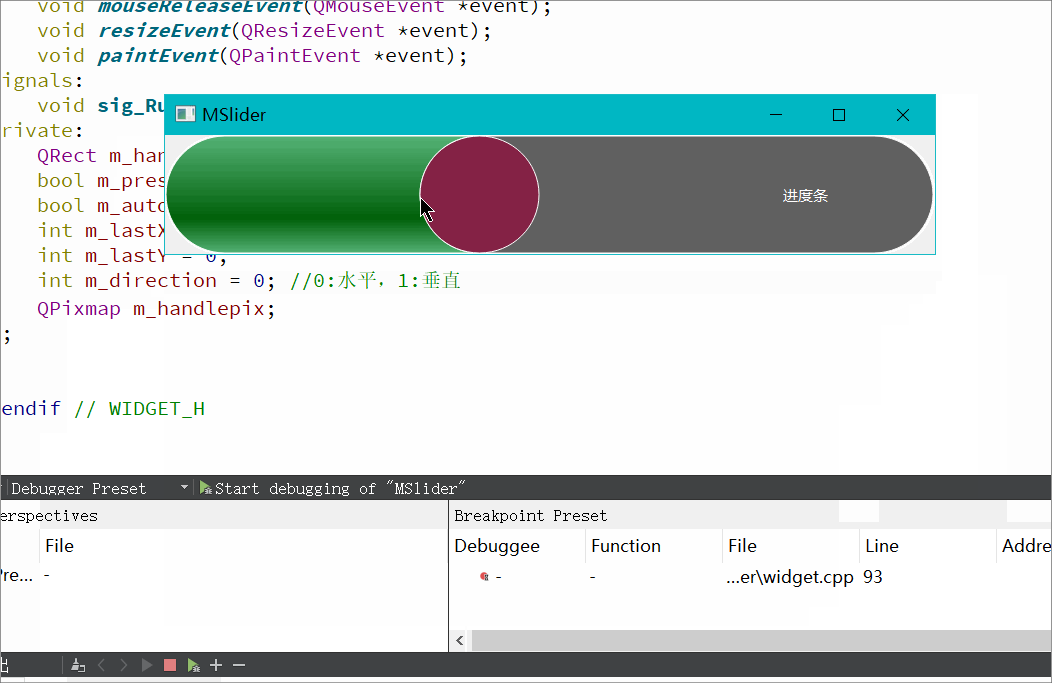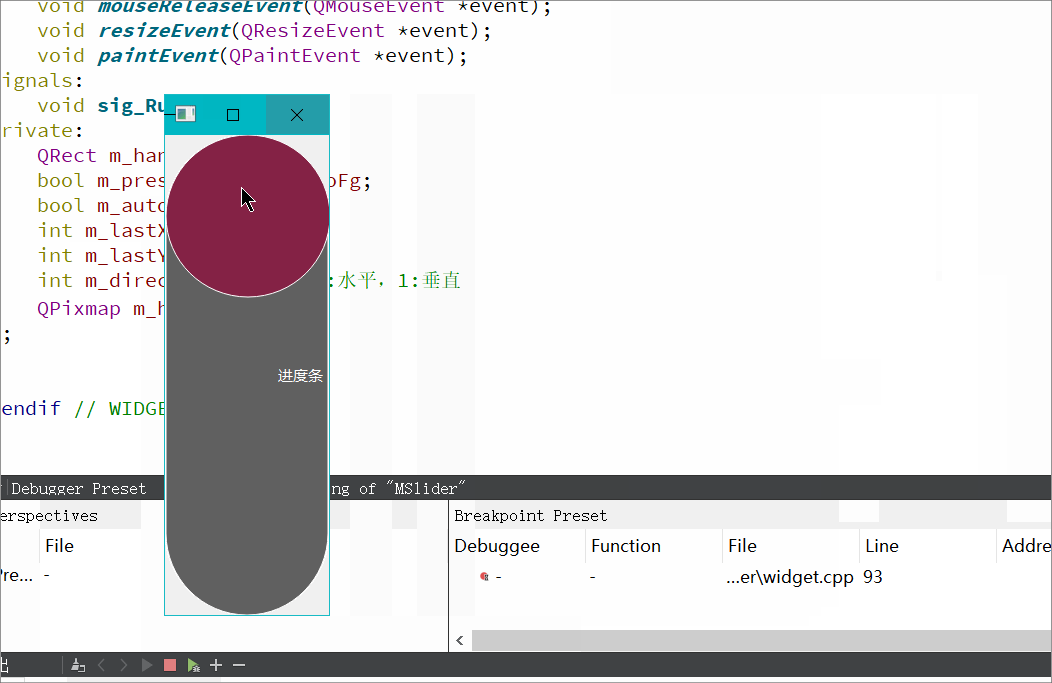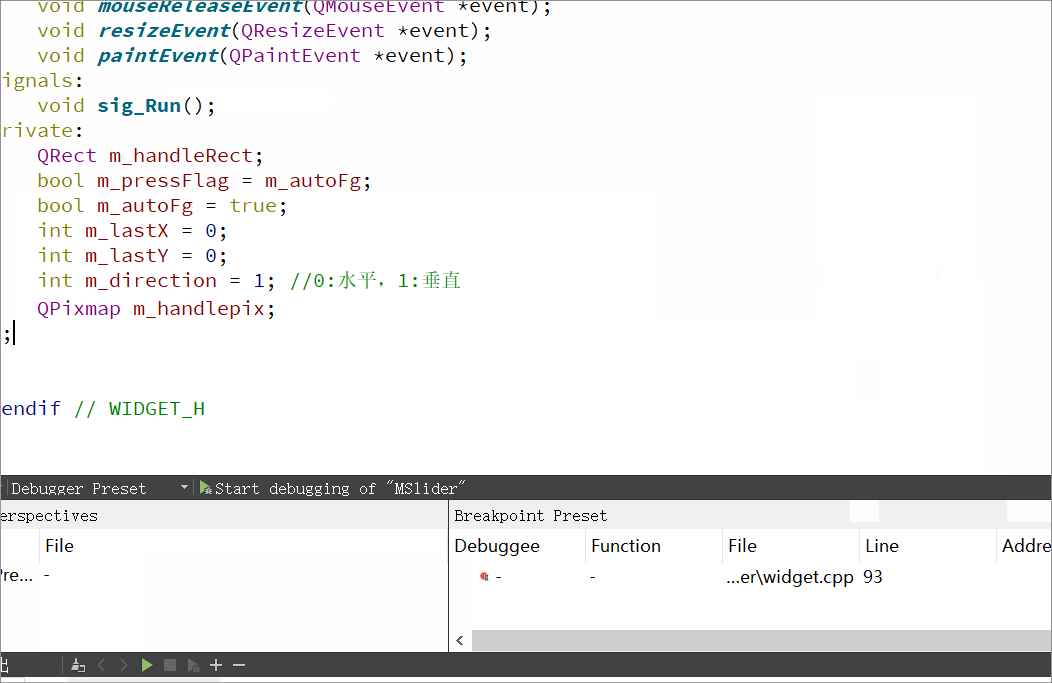
Qt自定义QSlider(支持水平垂直)
实现背景: Qt本身有自己的QSlider,为什么我们还要自定义实现呢,因为Qt自带的QSlider存在一个问题,当首尾为圆角时,滑动滚动条到首尾时会出现圆角变成矩形的问题。当然如果QSS之间的margin和滑动条的圆角控制的好的话是…...

会话控制学习
文章目录 介绍cookieexpress中使用cookie获取cookie session配置区别 介绍 cookie express中使用cookie 退出登录就是删除cookie 获取cookie 添加中间键后,直接获取 session 配置 区别...

dweb-browser阅读
dweb-browser阅读 核心模块js.browser.dwebjmm.browser.dwebmwebview.browser.dwebnativeui.browser.dweb.sys.dweb plaoc插件 核心模块 js.browser.dweb 它是一个 javascript-runtime,使用的是 WebWorker 作为底层实现。它可以让您在 dweb-browser 中运行 javasc…...

ChatGPT:使用fastjson读取JSON数据问题——如何使用com.alibaba.fastjson库读取JSON数据的特定字段
ChatGPT:使用fastjson读取JSON数据问题——如何使用com.alibaba.fastjson库读取JSON数据的特定字段 有一段Json字符串: {"code": 200,"message": "success","data": {"total": "1","l…...
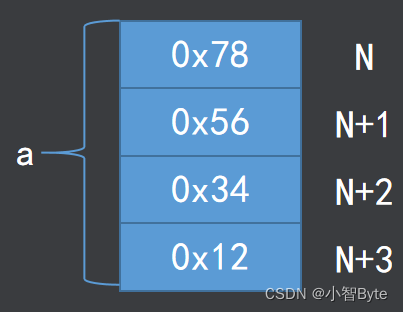
2、ARM处理器概论
一、ARM处理器概述 1、ARM的含义 ARM(Advanced RISC Machines)有三种含义,一个公司的名称、一类处理器的通称、一种技术 ARM公司: 成立于1990年11月,前身为Acorn计算机公司主要设计ARM系列RISC处理器内核授权ARM内…...
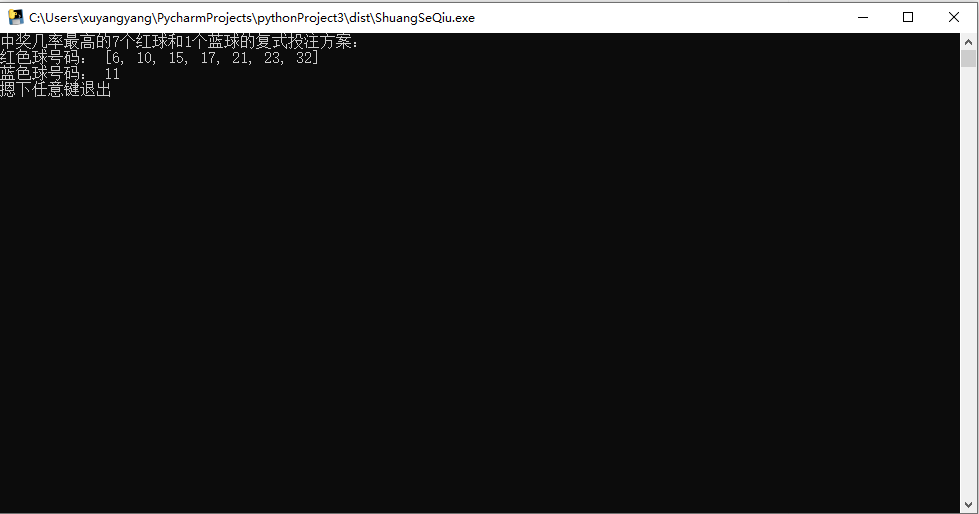
【Python】福利彩票复式模拟选号程序
【效果】 【注意】 逻辑是用Random模拟10000次复试彩票选号,然后给出最大可能性一组。但是模拟终究是模拟,和现实彩票结果没有任何联系,下载下来玩就是了,没人能保证模拟出中奖号码,不要投机,不要投机! 【修改】 代码很简单,如果想改成不是复式的,自行修改即可。 如…...

Pytorch 机器学习专业基础知识+神经网络搭建相关知识
文章目录 一、三种学习方式二、机器学习的一些专业术语三、模型相关知识四、常用的保留策略五、数据处理六、解决过拟合与欠拟合七、成功的衡量标准 一、三种学习方式 有监督学习: 1、分类问题 2、回归问题 3、图像分割 4、语音识别 5、语言翻译 无监督学习 1、聚类…...

torch 和paddle 的GPU版本可以放在同一个conda环境下吗
新建conda 虚拟环境,python 版本3.8.17 虚拟机,系统centos 7,内核版本Linux fastknow 3.10.0-1160.92.1.el7.x86_64 ,显卡T4,nvidia-smi ,460.32.03,对应cuda 11.2,安装cuda 11.2和cudnn,conda…...

MYBATIS-PLUS入门使用、踩坑记录
转载: mybatis-plus入门使用、踩坑记录 - 灰信网(软件开发博客聚合) 首先引入MYBATIS-PLUS依赖: SPRING BOOT项目: <dependency><groupId>com.baomidou</groupId><artifactId>mybatis-plus…...
的区别)
C# 静态类和sealed类(密封类)的区别
网上看到很多文章写静态类,和密封类,但是鲜有它们的对比总结,在此简单总结一下: 静态类(Static Class): 静态类不能被实例化,其成员都是静态的,可以通过类名直接访问。静…...

el-table如何实现自动缩放,提示隐藏内容
前提问题:大屏展示中某一个区域是表格内容,当放大或缩小网页大小时,表格宽度随之缩放,但表格内容未进行缩放,需要表格内容与网页大小同时进行缩放,且表头和表格内容宽度不够未显示全时,需要进行…...
CRM客户管理软件对出海企业的帮助与好处
2023我们走出了疫情的阴霾,经济下行压力大,面对内需的不足,国内企业纷纷选择出海,拓展海外业务增加企业营收。企业出海不是一件易事,有了CRM系统可以让公司事半功倍,下面就来说一说CRM客户管理软件能为出海…...
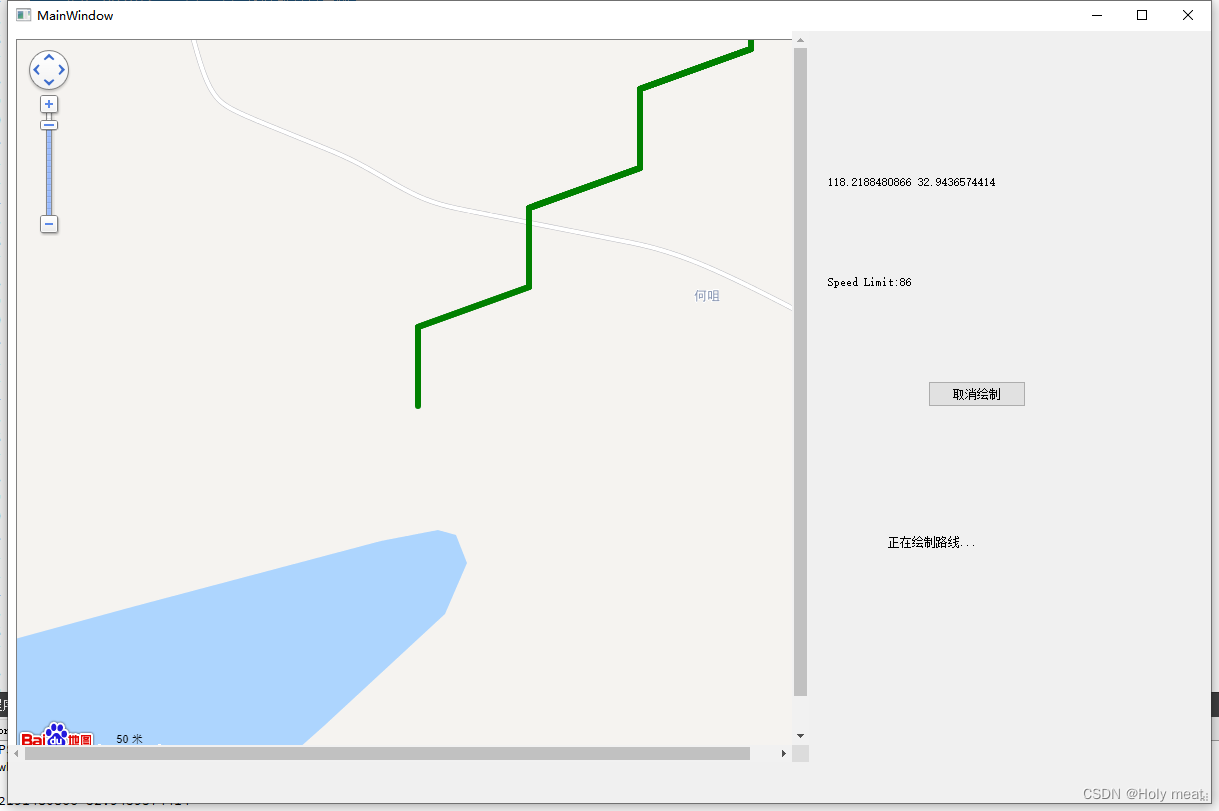
【QT--使用百度地图API显示地图并绘制路线】
QT--使用百度地图API显示地图并绘制路线 前言准备工作申请百度地图密钥(AK)安装开发环境 开发过程新建项目ui界面GPSManager类主窗口Map 效果展示 前言 先吐槽一下下,本身qt学的就不咋滴,谁想到第一件事就是让写一个上位机工具,根据CAN总线传…...

C数据结构二.练习题
一.求级数和 2.求最大子序列问题:设给定一个整数序列 ai.az..,a,(可能有负数).设计一个穷举算法,求a 的最大值。例如,对于序列 A {1,-1,1,-1,-1,1,1,1,1.1,-1,-1.1,-1,1,-1},子序列 A[5..9](1,1,1,1,1)具有最大值5 3.设有两个正整数 m 和n,编写一个算法 gcd(m,n),求它们的最大公…...

深圳SEO公司为什么要定期优化网站
深圳SEO公司为什么要定期优化网站 在当今数字化时代,拥有一个优秀的网站已经不再足以满足企业的需求。随着互联网市场的竞争日益激烈,深圳SEO公司认识到定期优化网站的重要性,并将其作为持续提升网站流量和业务发展的核心策略之一。为什么深…...

GHelper:重构华硕笔记本硬件控制的颠覆式开源方案
GHelper:重构华硕笔记本硬件控制的颠覆式开源方案 【免费下载链接】g-helper Lightweight, open-source control tool for ASUS laptops and ROG Ally. Manage performance modes, fans, GPU, battery, and RGB lighting across Zephyrus, Flow, TUF, Strix, Scar, …...

英雄联盟身份定制完全指南:3步打造专属游戏形象
英雄联盟身份定制完全指南:3步打造专属游戏形象 【免费下载链接】LeaguePrank 项目地址: https://gitcode.com/gh_mirrors/le/LeaguePrank 想在英雄联盟中展示与众不同的游戏形象吗?LeaguePrank正是你寻找的解决方案!这个开源工具通过…...

协议解析CPU飙升85%?从Wireshark抓包到JFR火焰图的全链路诊断闭环,立即生效!
第一章:协议解析CPU飙升85%?从Wireshark抓包到JFR火焰图的全链路诊断闭环,立即生效!当线上服务突发CPU使用率飙升至85%以上,且无明显GC压力或线程阻塞时,协议层异常解析往往是隐藏元凶。我们曾在线上Java服…...

C++ 异常安全与 RAII 模式结合
C异常安全与RAII模式结合:构建健壮资源管理体系 在C开发中,异常处理与资源管理是保证程序健壮性的核心挑战。传统的手动资源释放容易因异常抛出导致泄漏,而RAII(资源获取即初始化)模式通过对象生命周期自动化管理资源…...

OpenClaw自动化边界:gemma-3-12b-it不适合处理的5类任务分析
OpenClaw自动化边界:gemma-3-12b-it不适合处理的5类任务分析 1. 为什么需要明确自动化边界? 上周我在本地部署了OpenClawgemma-3-12b-it组合,本想让它帮我完成一些重复性工作。结果在测试过程中,一个简单的"整理桌面截图并…...

工业冷水机控制程序西门子1200plc含压缩机,电子膨胀阀控制策略,饱和温度计算公式
工业冷水机控制程序西门子1200plc含压缩机,电子膨胀阀控制策略,饱和温度计算公式凌晨三点钟的冷水机组房,设备轰鸣声中闪烁着PLC运行指示灯。手指划过TP1200触摸屏的瞬间,压缩机启动电流曲线在屏幕上划出漂亮的爬坡轨迹——这就是…...

OpenClaw开发环境配置:千问3.5-9B辅助的IDE插件管理
OpenClaw开发环境配置:千问3.5-9B辅助的IDE插件管理 1. 为什么需要AI辅助的IDE管理 作为一个长期在多个项目间切换的全栈开发者,我深受开发环境配置问题的困扰。每次换新电脑或者重装系统,光是配置VSCode插件和项目依赖就要耗费大半天时间。…...

聊着天把虾队管了:用 HiClaw 正确打开多智能体协作方式【限时领 PPT】
作者:戴靖泽(静择) 本文整理自 DataWhale x HiClaw 直播分享,聊聊多 Agent 协作背后的工程思考。 点击此处,查看分享! 你有没有试过让一个 AI 同时写前端和后端?聊到后面它把自己定好的 API …...
