Mysql高级——索引优化和查询优化(2)
5. 排序优化
5.1 排序优化
问题:在 WHERE 条件字段上加索引,但是为什么在 ORDER BY 字段上还要加索引呢?
优化建议:
-
SQL 中,可以在 WHERE 子句和 ORDER BY 子句中使用索引,目的是在 WHERE 子句中避免全表扫描,在 ORDER BY 子句避免使用 FileSort 排序。当然,某些情况下全表扫描,或者 FileSort 排序不一定比索引慢。但总的来说,我们还是要避免,以提高查询效率。
-
尽量使用 Index 完成 ORDER BY 排序。如果 WHERE 和 ORDER BY 后面是相同的列就使用单索引列;如果不同就使用联合索引。
-
无法使用 Index 时,需要对 FileSort 方式进行调优。
INDEX a_b_c(a,b,c)
order by 能使用索引最左前缀
- ORDER BY a
- ORDER BY a,b
- ORDER BY a,b,c
- ORDER BY a DESC,b DESC,c DESC
如果WHERE使用索引的最左前缀定义为常量,则order by 能使用索引
- WHERE a = const ORDER BY b,c
- WHERE a = const AND b = const ORDER BY c
- WHERE a = const ORDER BY b,c
- WHERE a = const AND b > const ORDER BY b,c
不能使用索引进行排序
- ORDER BY a ASC,b DESC,c DESC /* 排序不一致 */
- WHERE g = const ORDER BY b,c /*丢失a索引*/
- WHERE a = const ORDER BY c /*丢失b索引*/
- WHERE a = const ORDER BY a,d /*d不是索引的一部分*/
- WHERE a in (...) ORDER BY b,c /*对于排序来说,多个相等条件也是范围查询*/
5.2 案例实战
ORDER BY子句,尽量使用Index方式排序,避免使用FileSort方式排序。
执行案例前先清除student上的索引,只留主键:
DROP INDEX idx_age ON student;
DROP INDEX idx_age_classid_stuno ON student;
DROP INDEX idx_age_classid_name ON student;
#或者
call proc_drop_index('atguigudb2','student');
场景:查询年龄为30岁的,且学生编号小于101000的学生,按用户名称排序
mysql> EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE age = 30 AND stuno <101000 ORDER BY-> NAME ;
+----+-------------+---------+------------+------+---------------+------+---------+------+--------+----------+-----------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+---------+------------+------+---------------+------+---------+------+--------+----------+-----------------------------+
| 1 | SIMPLE | student | NULL | ALL | NULL | NULL | NULL | NULL | 498917 | 3.33 | Using where; Using filesort |
+----+-------------+---------+------------+------+---------------+------+---------+------+--------+----------+-----------------------------+
1 row in set, 2 warnings (0.00 sec)
查询结果如下:
mysql> SELECT SQL_NO_CACHE * FROM student WHERE age = 30 AND stuno <101000 ORDER BY-> NAME ;
+-----+--------+--------+------+---------+
| id | stuno | name | age | classId |
+-----+--------+--------+------+---------+
| 695 | 100695 | bXLNEI | 30 | 979 |
| 322 | 100322 | CeOJNY | 30 | 40 |
| 993 | 100993 | DVVPnT | 30 | 340 |
| 983 | 100983 | fmUNei | 30 | 433 |
| 946 | 100946 | iSPxRQ | 30 | 511 |
| 469 | 100469 | LTktoo | 30 | 69 |
| 45 | 100045 | mBZrKC | 30 | 280 |
| 635 | 100635 | nQnUJL | 30 | 732 |
| 16 | 100016 | NzjxKh | 30 | 539 |
| 363 | 100363 | OMuKtM | 30 | 695 |
| 293 | 100293 | qOYywO | 30 | 586 |
| 169 | 100169 | qUElsg | 30 | 526 |
| 798 | 100798 | rhHPdX | 30 | 71 |
| 749 | 100749 | TCgaJe | 30 | 697 |
| 157 | 100157 | TUQtvY | 30 | 22 |
| 580 | 100580 | UHDUOj | 30 | 423 |
| 532 | 100532 | XvmZkc | 30 | 861 |
| 939 | 100939 | yBlCbB | 30 | 320 |
| 710 | 100710 | yhmRvD | 30 | 219 |
| 266 | 100266 | YueogP | 30 | 524 |
+-----+--------+--------+------+---------+
20 rows in set, 1 warning (0.16 sec)
结论:type 是 ALL,即最坏的情况。Extra 里还出现了 Using filesort,也是最坏的情况。优化是必须的。
优化思路:
方案一: 为了去掉filesort我们可以把索引建成
#创建新索引
CREATE INDEX idx_age_name ON student(age,NAME);
方案二: 尽量让where的过滤条件和排序使用上索引
建一个三个字段的组合索引:
DROP INDEX idx_age_name ON student;
CREATE INDEX idx_age_stuno_name ON student (age,stuno,NAME);
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE age = 30 AND stuno <101000 ORDER BY NAME;
mysql> EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE age = 30 AND stuno <101000 ORDER BY NAME;
+----+-------------+---------+------------+-------+--------------------+--------------------+---------+------+------+----------+---------------------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+---------+------------+-------+--------------------+--------------------+---------+------+------+----------+---------------------------------------+
| 1 | SIMPLE | student | NULL | range | idx_age_stuno_name | idx_age_stuno_name | 9 | NULL | 20 | 100.00 | Using index condition; Using filesort |
+----+-------------+---------+------------+-------+--------------------+--------------------+---------+------+------+----------+---------------------------------------+
1 row in set, 2 warnings (0.00 sec)
mysql> SELECT SQL_NO_CACHE * FROM student-> WHERE age = 30 AND stuno <101000 ORDER BY NAME ;
+-----+--------+--------+------+---------+
| id | stuno | name | age | classId |
+-----+--------+--------+------+---------+
| 695 | 100695 | bXLNEI | 30 | 979 |
| 322 | 100322 | CeOJNY | 30 | 40 |
| 993 | 100993 | DVVPnT | 30 | 340 |
| 983 | 100983 | fmUNei | 30 | 433 |
| 946 | 100946 | iSPxRQ | 30 | 511 |
| 469 | 100469 | LTktoo | 30 | 69 |
| 45 | 100045 | mBZrKC | 30 | 280 |
| 635 | 100635 | nQnUJL | 30 | 732 |
| 16 | 100016 | NzjxKh | 30 | 539 |
| 363 | 100363 | OMuKtM | 30 | 695 |
| 293 | 100293 | qOYywO | 30 | 586 |
| 169 | 100169 | qUElsg | 30 | 526 |
| 798 | 100798 | rhHPdX | 30 | 71 |
| 749 | 100749 | TCgaJe | 30 | 697 |
| 157 | 100157 | TUQtvY | 30 | 22 |
| 580 | 100580 | UHDUOj | 30 | 423 |
| 532 | 100532 | XvmZkc | 30 | 861 |
| 939 | 100939 | yBlCbB | 30 | 320 |
| 710 | 100710 | yhmRvD | 30 | 219 |
| 266 | 100266 | YueogP | 30 | 524 |
+-----+--------+--------+------+---------+
20 rows in set, 1 warning (0.00 sec)
结果竟然有 filesort的 sql 运行速度, 超过了已经优化掉 filesort的 sql ,而且快了很多,几乎一瞬间就出现了结果。
结论:
- 两个索引同时存在,mysql自动选择最优的方案。(对于这个例子,mysql选择idx_age_stuno_name)。但是, 随着数据量的变化,选择的索引也会随之变化的。
- 当【范围条件】和【group by 或者 order by】的字段出现二选一时,优先观察条件字段的过滤数量,如果过滤的数据足够多,而需要排序的数据并不多时,优先把索引放在范围字段上。反之,亦然。
5.3 filesort算法:双路排序和单路排序
双路排序 (慢)
-
MySQL 4.1之前是使用双路排序,字面意思就是两次扫描磁盘,最终得到数据, 读取行指针和order by列,对他们进行排序,然后扫描已经排序好的列表,按照列表中的值重新从列表中读取对应的数据输出
-
从磁盘取排序字段,在buffer进行排序,再从磁盘取其他字段。
取一批数据,要对磁盘进行两次扫描,众所周知,IO是很耗时的,所以在mysql4.1之后,出现了第二种改进的算法,就是单路排序。
单路排序 (快)
从磁盘读取查询需要的所有列,按照order by列在buffer对它们进行排序,然后扫描排序后的列表进行输出, 它的效率更快一些,避免了第二次读取数据。并且把随机IO变成了顺序IO,但是它会使用更多的空间, 因为它把每一行都保存在内存中了。
结论及引申出的问题
- 由于单路是后出的,总体而言好过双路
- 但是用单路有问题
6. GROUP BY优化
- by 使用索引的原则几乎跟order by一致 ,group by 即使没有过滤条件用到索引,也可以直接使用索引。
- group by 先排序再分组,遵照索引建的最佳左前缀法则
- 当无法使用索引列,增大max_length_for_sort_data 和sort_buffer_size 参数的设置
- where效率高于having,能写在where限定的条件就不要写在having中了
- 减少使用order by,和业务沟通能不排序就不排序,或将排序放到程序端去做。Order by、groupby、distinct这些语句较为耗费CPU,数据库的CPU资源是极其宝贵的。
- 包含了order by、group by、distinct这些查询的语句,where条件过滤出来的结果集请保持在1000行以内,否则SQL会很慢。
7. 优化分页查询
优化思路一
在索引上完成排序分页操作,最后根据主键关联回原表查询所需要的其他列内容
mysql> EXPLAIN SELECT * FROM student t,(SELECT id FROM student ORDER BY id LIMIT 2000000,10)-> a-> WHERE t.id = a.id;
+----+-------------+------------+------------+--------+---------------+---------+---------+------+--------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+------------+------------+--------+---------------+---------+---------+------+--------+----------+-------------+
| 1 | PRIMARY | <derived2> | NULL | ALL | NULL | NULL | NULL | NULL | 498917 | 100.00 | NULL |
| 1 | PRIMARY | t | NULL | eq_ref | PRIMARY | PRIMARY | 4 | a.id | 1 | 100.00 | NULL |
| 2 | DERIVED | student | NULL | index | NULL | PRIMARY | 4 | NULL | 498917 | 100.00 | Using index |
+----+-------------+------------+------------+--------+---------------+---------+---------+------+--------+----------+-------------+
3 rows in set, 1 warning (0.00 sec)
优化思路二
该方案适用于主键自增的表,可以把Limit 查询转换成某个位置的查询 。
mysql> EXPLAIN SELECT * FROM student WHERE id > 2000000 LIMIT 10;
+----+-------------+---------+------------+-------+---------------+---------+---------+------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+---------+------------+-------+---------------+---------+---------+------+------+----------+-------------+
| 1 | SIMPLE | student | NULL | range | PRIMARY | PRIMARY | 4 | NULL | 1 | 100.00 | Using where |
+----+-------------+---------+------------+-------+---------------+---------+---------+------+------+----------+-------------+
1 row in set, 1 warning (0.00 sec)
8. 优先考虑覆盖索引
8.1 什么是覆盖索引?
理解方式一:索引是高效找到行的一个方法,但是一般数据库也能使用索引找到一个列的数据,因此它不必读取整个行。毕竟索引叶子节点存储了它们索引的数据;当能通过读取索引就可以得到想要的数据,那就不需要读取行了。一个索引包含了满足查询结果的数据就叫做覆盖索引。
理解方式二:非聚簇复合索引的一种形式,它包括在查询里的SELECT、JOIN和WHERE子句用到的所有列
(即建索引的字段正好是覆盖查询条件中所涉及的字段)。简单说就是, 索引列+主键 包含 SELECT 到 FROM之间查询的列。
8.2 覆盖索引的利弊
好处:
-
避免Innodb表进行索引的二次查询(回表)
-
可以把随机IO变成顺序IO加快查询效率
弊端:
索引字段的维护总是有代价的。因此,在建立冗余索引来支持覆盖索引时就需要权衡考虑了。这是业务DBA,或者称为业务数据架构师的工作。
相关文章:
)
Mysql高级——索引优化和查询优化(2)
5. 排序优化 5.1 排序优化 问题:在 WHERE 条件字段上加索引,但是为什么在 ORDER BY 字段上还要加索引呢? 优化建议: SQL 中,可以在 WHERE 子句和 ORDER BY 子句中使用索引,目的是在 WHERE 子句中避免全表…...

SpringMVC的拦截器和JSR303的使用
目录 一、JSR303 二、拦截器(interceptor) 一、JSR303 1.1.什么是JSR303 JSR 303,它是Java EE(现在称为Jakarta EE)规范中的一部分。JSR 303定义了一种用于验证Java对象的标准规范,也称为Bean验证。 Bean验…...
servlet中doGet方法无法读取body中的数据
servlet中doGet方法不支持读取body中的数据。...

Ubuntu MongoDB账户密码设置
1.创建用户 在MongoDB中,可以使用db.createUser()方法来创建用户。该方法接受一个包含用户名、密码和角色等信息的文档作为参数。 // 连接到MongoDB数据库 mongo// 切换到admin数据库 use admin// 创建用户 db.createUser({user: "admin",pwd: "adm…...
)
指针进阶(3)
9. 模拟实现排序函数 这里我们使用冒泡排序算法,模拟实现一个排序函数,可以排序任意类型的数据。 这段代码可以排序整型数据,我们需要在这段代码的基础上进行改进,使得它可以排序任意类型的数据。 #define _CRT_SECURE_NO_WARN…...
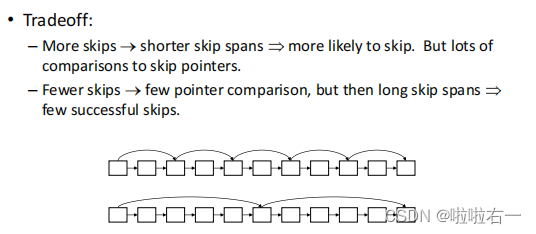
信息检索与数据挖掘 | (二)布尔检索与倒排索引
文章目录 📚词项-文档关联矩阵🐇相关名词🐇词项-文档关联矩阵的布尔查询处理 📚倒排索引🐇关于索引🐇建立索引🐇基于倒排索引的布尔查询处理🐇查询优化 📚字典数据结构&a…...

【学习笔记】EC-Final 2022 K. Magic
最近的题都只会抄题解😅 首先,操作顺序会影响答案,因此不能直接贪心。其次,因为是求贡献最大,所以可以考虑枚举最终哪些位置对答案产生了贡献,进而转化为全局贡献。 1.1 1.1 1.1 如果 [ l 1 , r 1 ) ⊆ [ …...
MySQL数据库笔记
文章目录 一、初识MySQL1.1、什么是数据库1.2、数据库分类1.3、MySQL简介 二、操作数据库2.1、操作数据库(了解)2.2、数据库的列类型2.3、数据库的字段属性(重点)2.4、创建数据库表(重点)2.5、数据表的类型…...
)
大数据之Hive(三)
分区表 概念和常用操作 将一个大表的数据按照业务需要分散存储到多个目录,每个目录称为该表的一个分区。一般来说是按照日期来作为分区的标准。在查询时可以通过where子句来选择查询所需要的分区,这样查询效率会提高很多。 ①创建分区表 hive (defau…...

让高分辨率的相机芯片输出低分辨率的图片对于像素级的值有什么影响?
很多图像传感器可以输出多个分辨率的图像,如果选择低分辨率格式的图像输出,对于图像本身会有什么影响呢? 传感器本身还是使用全部像素区域进行感光,但是在像素数据输出时会进行所谓的降采样(down-sampling)…...
FastGPT 接入飞书(不用写一行代码)
FastGPT V4 版本已经发布,可以通过 Flow 可视化进行工作流编排,从而实现复杂的问答场景,例如联网谷歌搜索,操作数据库等等,功能非常强大,还没用过的同学赶紧去试试吧。 飞书相比同类产品算是体验非常好的办…...
蓝桥杯 题库 简单 每日十题 day6
01 删除字符 题目描述 给定一个单词,请问在单词中删除t个字母后,能得到的字典序最小的单词是什么? 输入描述 输入的第一行包含一个单词,由大写英文字母组成。 第二行包含一个正整数t。 其中,单词长度不超过100&#x…...

使用Arduino简单测试HC-08蓝牙模块
目录 模块简介模块测试接线代码测试现象 总结 模块简介 HC-08 蓝牙串口通信模块是新一代的基于 Bluetooth Specification V4.0 BLE 蓝牙协议的数传模块。无线工作频段为 2.4GHz ISM,调制方式是 GFSK。模块最大发射功率为4dBm,接收灵度-93dBm,…...

如何在 CentOS 8 上安装 OpenCV?
OpenCV( 开源计算机视觉库)是一个开放源代码计算机视觉库,支持所有主要操作系统。它可以利用多核处理的优势,并具有 GPU 加速功能以实现实时操作。 OpenCV 的用途非常广泛,包括医学图像分析,拼接街景图像,监视视频&am…...

一台主机外接两台显示器
一台主机外接两台显示器 写在最前面双屏配置软件双屏跳转 写在最前面 在使用电脑时需要运行多个程序,时不时就要频繁的切换,很麻烦 但就能用双屏显示来解决这个问题,用一台主机控制,同时外接两台显示器并显示不同画面。 参考&a…...

笔记-搭建和使用docker-registry私有镜像仓库
笔记-搭建和使用docker-registry私有镜像仓库 拉取/安装registry镜像 和 对应的ui镜像 如果有网络可以直接拉取镜像 docker pull registry docker pull hyper/docker-registry-web没有网络可以使用我导出好的离线镜像tar包, 下载地址https://wwzt.lanzoul.com/i3im1194z12d …...
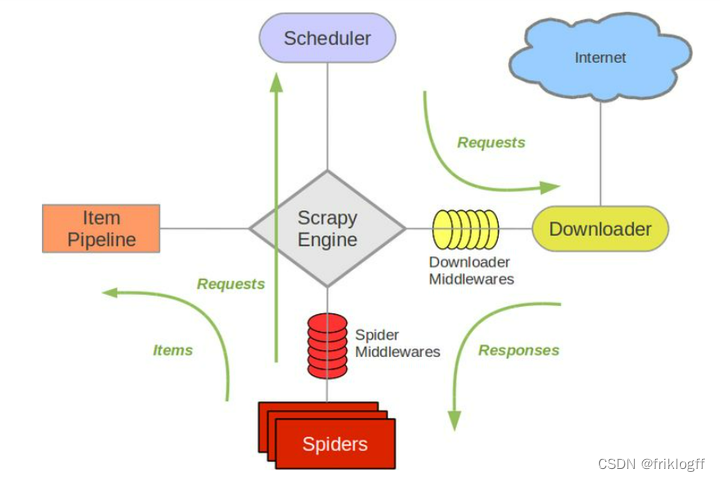
爬虫框架Scrapy学习笔记-2
前言 Scrapy是一个功能强大的Python爬虫框架,它被广泛用于抓取和处理互联网上的数据。本文将介绍Scrapy框架的架构概览、工作流程、安装步骤以及一个示例爬虫的详细说明,旨在帮助初学者了解如何使用Scrapy来构建和运行自己的网络爬虫。 爬虫框架Scrapy学…...
6.1 使用scikit-learn构建模型
6.1 使用scikit-learn构建模型 6.1.1 使用sklearn转换器处理数据6.1.2 将数据集划分为训练集和测试集6.1.3 使用sklearn转换器进行数据预处理与降维1、数据预处理2、PCA降维算法 代码 scikit-learn(简称sklearn)库整合了多种机器学习算法,可以…...
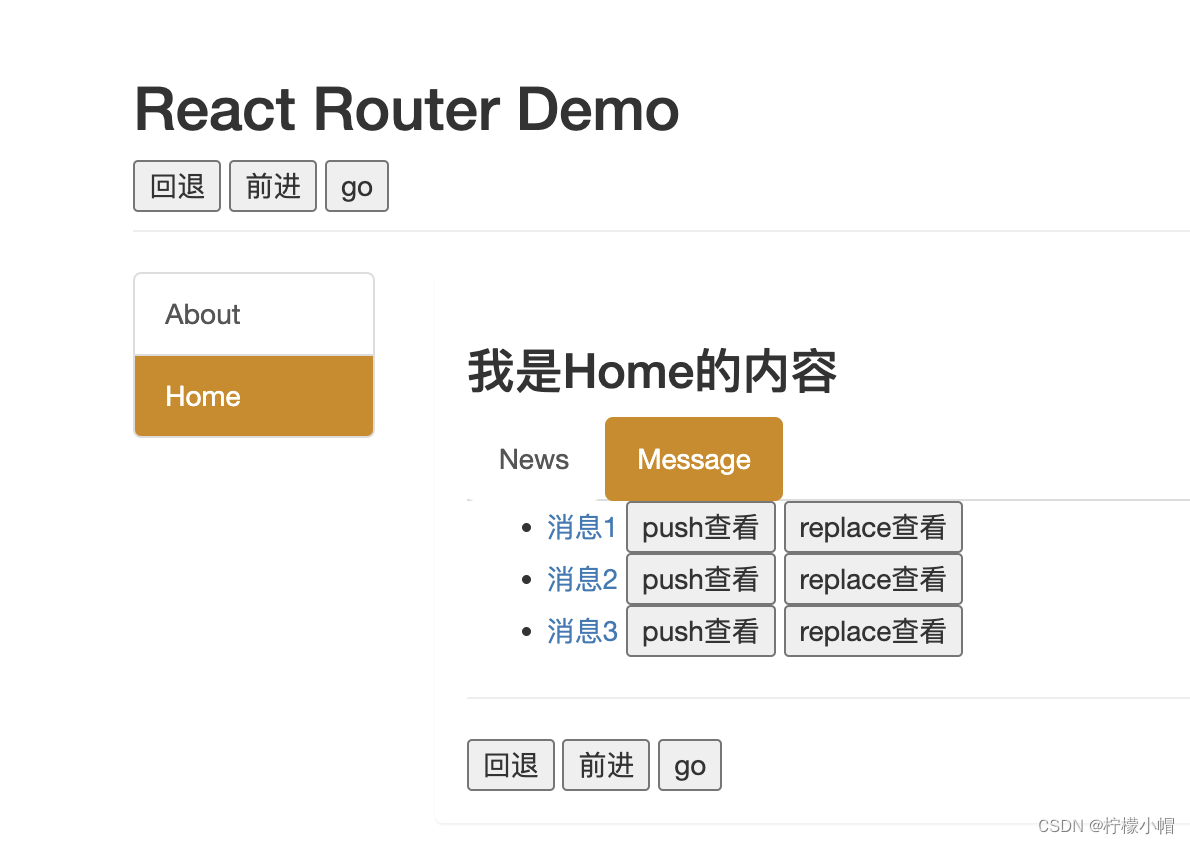
React 全栈体系(十一)
第五章 React 路由 五、向路由组件传递参数数据 1. 效果 2. 代码 - 传递 params 参数 2.1 Message /* src/pages/Home/Message/index.jsx */ import React, { Component } from "react"; import {Link, Route} from react-router-dom import Detail from ./Detai…...
AI 时代的向量数据库、关系型数据库与 Serverless 技术丨TiDB Hackathon 2023 随想
TiDB Hackathon 2023 刚刚结束,我仔细地审阅了所有的项目。 在并未强调项目必须使用人工智能(AI)相关技术的情况下,引人注目的项目几乎一致地都使用了 AI 来构建自己的应用。 大规模语言模型(LLM)的问世使得…...

如何为永久在线的CRM网站接入稳定的大模型API服务
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 如何为永久在线的CRM网站接入稳定的大模型API服务 对于需要7x24小时提供智能客服或数据分析的CRM网站而言,后台服务的稳…...

Dev-GPT部署指南:简单三步将你的微服务推向Jina云平台
Dev-GPT部署指南:简单三步将你的微服务推向Jina云平台 【免费下载链接】dev-gpt Your Virtual Development Team 项目地址: https://gitcode.com/gh_mirrors/de/dev-gpt Dev-GPT是一款强大的虚拟开发团队工具,能够帮助开发者快速构建和部署微服务…...

Speechless:一键永久保存你的微博记忆,免费导出高质量PDF
Speechless:一键永久保存你的微博记忆,免费导出高质量PDF 【免费下载链接】Speechless 把新浪微博的内容,导出成 PDF 文件进行备份的 Chrome Extension。 项目地址: https://gitcode.com/gh_mirrors/sp/Speechless 在数字记忆日益珍贵…...

UHP驱动器热管理:Flotherm仿真与优化实践
1. UHP高电流驱动器热设计挑战在投影仪用超高压(UHP)灯驱动器的开发中,热管理始终是制约产品小型化和功率提升的关键瓶颈。飞利浦工业技术中心的案例显示,当驱动器体积从150x73x32mm缩减到120x41x24mm时,功率密度从0.02mW/mm激增至0.18mW/mm—…...

告别纯视觉:如何将DEM高程数据喂给你的CNN模型提升滑坡识别准确率?
异构数据融合实战:当卫星影像遇见DEM高程的深度学习革命 滑坡识别一直是地质灾害监测领域的痛点问题。传统纯视觉方法依赖光学卫星影像(RGB)分析,但复杂地形条件下的误报率居高不下——直到数字高程模型(DEM࿰…...

避开这些坑,你的STM32四足机器人才能走得更稳:从步态调试到电源选择的完整避坑指南
STM32四足机器人实战避坑指南:从步态优化到系统稳定的全流程解决方案 当第一台自制的四足机器人颤颤巍巍地迈出第一步时,那种成就感无与伦比——直到它突然失去平衡翻倒在地。这个场景揭示了四足机器人开发中最真实的挑战:让机器人"能动…...

pkrelay:轻量级端口转发工具的设计原理与生产实践
1. 项目概述:一个轻量级、高可用的端口转发与流量中继工具在分布式系统、微服务架构以及混合云部署的日常运维和开发调试中,我们经常会遇到一个经典问题:如何安全、便捷地将一个网络环境中的服务端口,暴露给另一个网络环境访问&am…...

系统架构设计-①软件架构风格
目的: 软件体系结构,另一个名叫软件架构(Software Architecture,SA),所以下文中提到的“体系结构”“架构”。 软件体系结构设计的一个重要核心目标是达到体系结构级的复用,所以需要研究透彻各个…...

通过 TaoToken CLI 工具一键配置开发环境接入大模型聚合服务
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 通过 TaoToken CLI 工具一键配置开发环境接入大模型聚合服务 对于开发者而言,接入不同的大模型服务往往意味着需要处理…...

建议科技部与教育部聘请耿同学做学术打假工作
目前,学术界和社会公众正在热议的有一个核心话题:学术打假。“耿同学”(B站科普博主“耿同学讲故事”)近期在学术打假领域的表现确实堪称“降维打击”。作为一名退学博士,他仅凭个人力量和一些开源AI工具,在…...