FPGA:卷积编码及维特比译码仿真
FPGA:卷积编码及维特比译码仿真
本篇记录一下在FPGA中完成卷积编码和维特比译码的过程,通过代码解释编码的过程和译码的过程,便于理解,同时也方便移植到其他工程中。
1. 准备工作
- 卷积编译码IP核—
convolutionIP核和viterbiIP核 - 卷积编码原理知识—网上有很多关于原理性的解释
- 卷积编码对照仿真过程—可以对照之前的MATLAB仿真程序便于更好的理解编译码的过程,但是有一点不同,在FPGA仿真代码中利用自然数编码,最后译码回自然数,方便对照正确性。
2. 编码过程
首先添加convolutionIP核,可以看到首先有如下的需要配置的参数。

按照上图的设置方式为2,1,7形式的卷积编码器,这个没有什么需要注意的,按照常规设置就可以了。
然后添加viterbiIP核,打开之后可以看到如下的设置参数。

在第一个Viterbi Type栏中可以可以选择Standard,然后约束长度和编码过程的设置一致,回溯深度可以利用公式计算5*(约束长度-1),这个是最小的设置的值,回溯深度至少要大于这个值。

在第二个配置页中,按照如下的参数进行设置,这个可以参考MATLAB仿真。

这个页面配置的传入的bit数据,因为编码设置的是2,1,7所以这个设置为2,
3. 仿真过程
整个仿真过程利用0-15的自然数循环,对其进行卷积编码,然后通过viterbi译码还原出原来的自然数。
程序的设置流程思路:
- 为了方便移植到其他的工程中,同时为了转换数据速率,在自然数信源和卷积编码中间添加了一个fifo
- 同样的操作,在译码结束之后添加了一个fifo,与前一个fifo对称。
- 在利用译码的过程中,有一点注意事项:编码之后的2bit数据输入到viterbi译码的IP核中时,需要在第0位和第8位填充,构成两bit。这个技术手册中有说明。

下面给出两个fifo的参数设置,自然数位宽为[0:3],首先是信源和编码之间的fifo。

然后是译码之后的fifo。

4. 完整代码
`timescale 1ns / 1psmodule conv_encoder(input clk, //时钟input rst_n // 复位 高电平复位);parameter K = 1; // 对应MATLAB仿真中的k和n的值,这个在IP核设置中已经有体现
parameter N = 2; //
parameter L = 7; // 编码之后的数据长度reg [5:0] datain_num; // 每一组编码的原始数据个数
reg [3:0] datain;
//reg [5:0] dataout_num; //输出编码数据的个数// 定义viterbi IP核需要用到的信号
wire vit_datain_valid; // 当vit ip的ready信号有效同时 conv的输出有效的时候,这个信号有效
wire vit_datain_ready; //
wire vit_dataout_valid;
wire vit_dataout_ready;
wire vit_data_out; // 译码结果输出// 信源处fifo的相关信号线,该fifo是用来把多位数转为比特流传入到卷积编码中。
wire fifo_encode_empty;
wire fifo_encode_full;
wire fifo_encode_out;
wire fifo_decode_empty;
wire fifo_decode_full;
wire [3:0] fifo_decode_out;wire rd_en; //第一个fifo的读写控制信号
wire wr_en;
reg wren;always@(posedge clk)beginif(~rst_n)beginwren <= 1'b0;endelse beginif(fifo_encode_full==1'b1)beginwren <= 1'b0;endelse beginwren <= 1'b1;endend
end
assign wr_en = wren & (!fifo_encode_full); // fifo没有满就往fifo中写数据
wire rd_en2; // 第二个fifo的读写控制信号
wire wr_en2;assign rd_en2 = !fifo_decode_empty; // 最后一个fifo 非空就可以读数据
assign wr_en2 = (!fifo_decode_full) & vit_dataout_valid;
assign vit_dataout_ready = 1'b1; // 最后直接进fifo了,这里不做特殊控制了,直接常为1,就可以仅看vit_dataout_valid信号了// 编码信号的控制型号 valid 和 ready
wire conv_datain_ready;
reg conv_datain_valid;
wire [1:0] conv_dataout;
wire conv_dataout_valid;
wire conv_dataout_ready;// 设计输入数据 这里面需要对输入的数据转化弄成位的形式,
// 这个和卷积编码的参数设置有关,2,1,7,接受一个输入bit生成两个bitalways@(posedge clk)beginif(~rst_n)begindatain <= 4'b0;datain_num <= 6'b0;endelse beginif(wr_en == 1'b1)begin // 数据只在wr_en有效的情况下才逐渐累加,这个是为了通过连续的数值检验译码正确性datain <= datain + 4'b1;datain_num <= datain_num + 6'b1;endelse begindatain <= datain;datain_num <= datain_num;endend
end// 在这里添加转换bit 可以用fifo实现,同时能够控制速率 assign rd_en = conv_datain_ready;
fifo_encode u1 (.clk(clk), // input wire clk.srst(~rst_n), // input wire srst.din(datain), // input wire [3 : 0] din.wr_en(wr_en), // input wire wr_en.rd_en(rd_en), // input wire rd_en.dout(fifo_encode_out), // output wire [0 : 0] dout.full(fifo_encode_full), // output wire full.empty(fifo_encode_empty)
);always@(posedge clk)beginif(~rst_n)beginconv_datain_valid <= 1'b0;endelse beginconv_datain_valid <= rd_en;end
endassign conv_dataout_ready = 1'b1;convolution_0 conv (.aclk(clk), // input wire aclk.aresetn(rst_n), // input wire aresetn.s_axis_data_tdata(fifo_encode_out), // input wire [7 : 0] s_axis_data_tdata 注意这个只能接受1bit有效数据.s_axis_data_tvalid(conv_datain_valid), // input wire s_axis_data_tvalid.s_axis_data_tready(conv_datain_ready), // output wire s_axis_data_tready.m_axis_data_tdata(conv_dataout), // output wire [7 : 0] m_axis_data_tdata.m_axis_data_tvalid(conv_dataout_valid), // output wire m_axis_data_tvalid.m_axis_data_tready(conv_dataout_ready) // input wire m_axis_data_tready
);assign vit_datain_valid = conv_dataout_valid & conv_dataout_ready;// 编码完成后进行译码过程
viterbi_0 viterbi (.aclk(clk), // input wire aclk.aresetn(rst_n), // input wire aresetn.s_axis_data_tdata({7'b0,conv_dataout[1],7'b0,conv_dataout[0]}), // input wire [15 : 0] s_axis_data_tdata 这个经过编码之后的数据需要按照此种方式输入。.s_axis_data_tvalid(vit_datain_valid), // input wire s_axis_data_tvalid.s_axis_data_tready(vit_datain_ready), // output wire s_axis_data_tready.m_axis_data_tdata(vit_data_out), // output wire [7 : 0] m_axis_data_tdata.m_axis_data_tvalid(vit_dataout_valid), // output wire m_axis_data_tvalid.m_axis_data_tready(vit_dataout_ready) // input wire m_axis_data_tready
);// 添加一个把数据恢复成自然数的fifo
fifo_decode u2 (.clk(clk), // input wire clk.srst(~rst_n), // input wire srst.din(vit_data_out), // input wire [3 : 0] din.wr_en(wr_en2), // input wire wr_en.rd_en(rd_en2), // input wire rd_en.dout(fifo_decode_out), // output wire [0 : 0] dout.full(fifo_decode_full), // output wire full.empty(fifo_decode_empty) // output wire empty
);endmodule下面为tb文件:
`timescale 1ns / 1psmodule conv_tb();reg l_clk;
reg rst_n;conv_encoder conv_test_ins(.clk(l_clk), //时钟.rst_n(rst_n) // 复位 高电平复位
// input [7:0] data_in, // 输入的待编码数据
// output [7:0] dataout // 输出的解码数据);initial l_clk = 1;
always #5 l_clk= !l_clk; //15.625 initial beginrst_n <= 0;#40;rst_n <= 1;#320;//#50000000;#320;
// $stop;
end
endmodule5. 结果分析
以下为仿真结果图:

最下面的红色线是译码之后经过fifo速率转换之后的结果,可以看到是从0依次递增的自然数,一直到15,然后循环下去。这个有效是和rd_en2这个信号保持一致的,但是看这组红线,译码的结果是两个0,这是因为fifo读数据的时候是有一个clk的时钟延时的,这也是为什么在给出fifo参数设置的时候把latency=1用红线框起来。所以把rd_en2延迟一个系统时钟对照fifo_decode_out看数据就正确了。在使用的时候看接下来数据处理的过程需求,采用合适的操作,这里只做简单的仿真验证。
相关文章:
FPGA:卷积编码及维特比译码仿真
FPGA:卷积编码及维特比译码仿真 本篇记录一下在FPGA中完成卷积编码和维特比译码的过程,通过代码解释编码的过程和译码的过程,便于理解,同时也方便移植到其他工程中。 1. 准备工作 卷积编译码IP核—convolutionIP核和viterbiIP核…...
MySQL学习笔记4
客户端工具的使用: MySQL: mysql命令行工具,一般用来连接访问mysql的数据。 案例:使用mysql客户端工具连接服务器端(用户名:root;密码:123456). [rootmysql-server ~]#…...

JavaFX:窗体显示状态,模态非模态
程序窗体显示一般有3中模式。非模态和模态,其中模态又分为程序模态和窗体模态。 非模态可以理解为窗体之间没有任何限制,可以用鼠标、键盘等工具在窗体间切换。 程序模态是窗体打开后,该程序的所有窗体都被冻结,无法切换&#x…...
C++17中std::filesystem::path的使用
C17引入了std::filesystem库(文件系统库, filesystem library)。这里整理下std::filesystem::path的使用。 std::filesystem::path,文件系统路径,提供了对文件系统及其组件(例如路径、常规文件和目录)执行操作的工具。此path类主要用法包括&#x…...

命令模式简介
概念: 命令模式是一种行为设计模式,它将请求封装成一个对象,从而允许您将不同的请求参数化、队列化,并且能够在不同的时间点执行。通过引入命令对象(Command)来解耦发送者(Invoker)…...

Boost序列化指针
Boost.Serialization 还能序列化指针和引用。 由于指针存储对象的地址,序列化对象的地址没有什么意义,而是在序列化指针和引用时,对象的引用被自动地序列化。 代码 #include <boost/archive/text_oarchive.hpp> #include <boost/…...
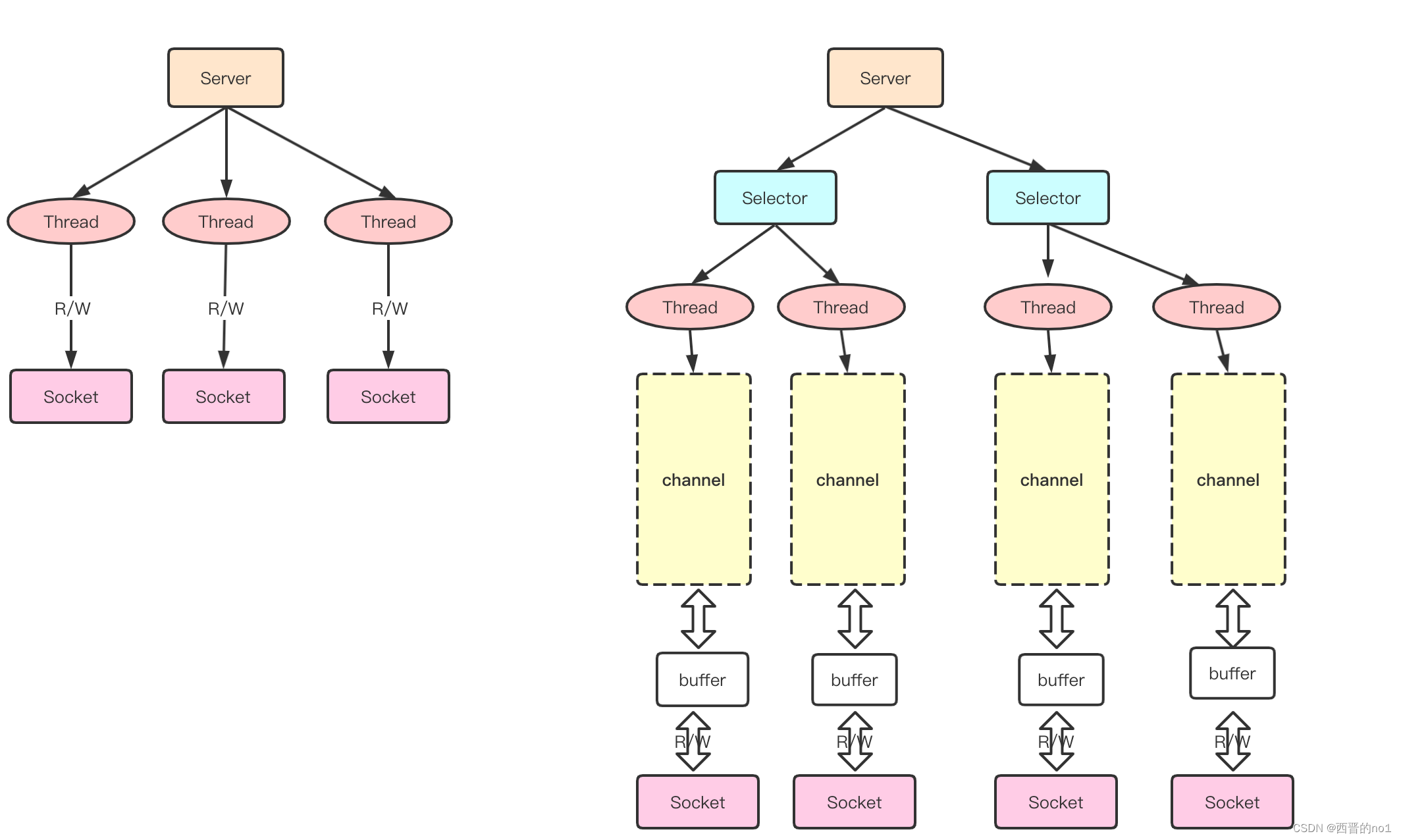
NIO简单介绍
一、什么是NIO 1、Java NIO全称java non-blocking IO, 是指JDK提供的新API。从JDK1.4开始,Java提供了一系列改进的输入/输出的新特性,被统称为NIO(即New IO),是同步非阻塞的 2、NIO有三大核心部分: Channel(通道), Buf…...
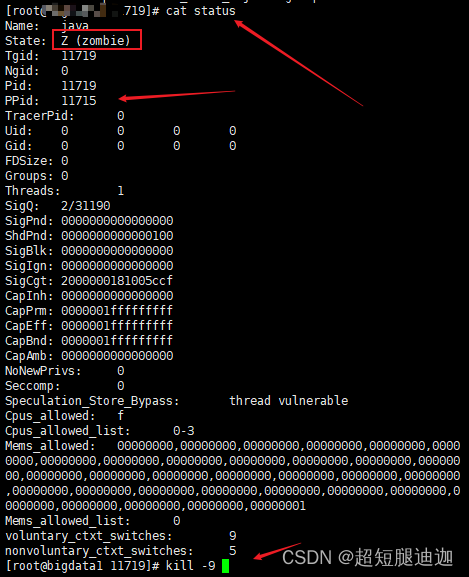
linux进程杀不死
项目场景: 虚拟机 问题描述 linux进程杀不死 无反应 原因分析: 进程僵死zombie 解决方案: 进proc或者find命令找到进程所在地址 cat status查看进程杀死子进程...

5分钟带你搞懂RPA到底是什么?RPA能做什么?
一、RPA的定义 RPA,全称Robotic Process Automation,即机器人流程自动化,是一种软件解决方案,能够模拟人类在计算机上执行的操作,以实现重复性、繁琐任务的自动化。它与传统的计算机自动化有所不同,因为它…...
毫米波雷达 TI IWR1443 在 ROS 中进行 octomap 建图
个人实验记录 /mmwave_ti_ros/ros_driver/src/ti_mmwave_rospkg/launch/1443_multi_3d_0.launch <launch><!-- Input arguments --><arg name"device" value"1443" doc"TI mmWave sensor device type [1443, 1642]"/><arg…...

113双周赛
题目列表 2855. 使数组成为递增数组的最少右移次数 2856. 删除数对后的最小数组长度 2857. 统计距离为 k 的点对 2858. 可以到达每一个节点的最少边反转次数 一、使数组成为递增数组的最少右移次数 这题可以直接暴力求解,枚举出每种右移后的数组,将…...
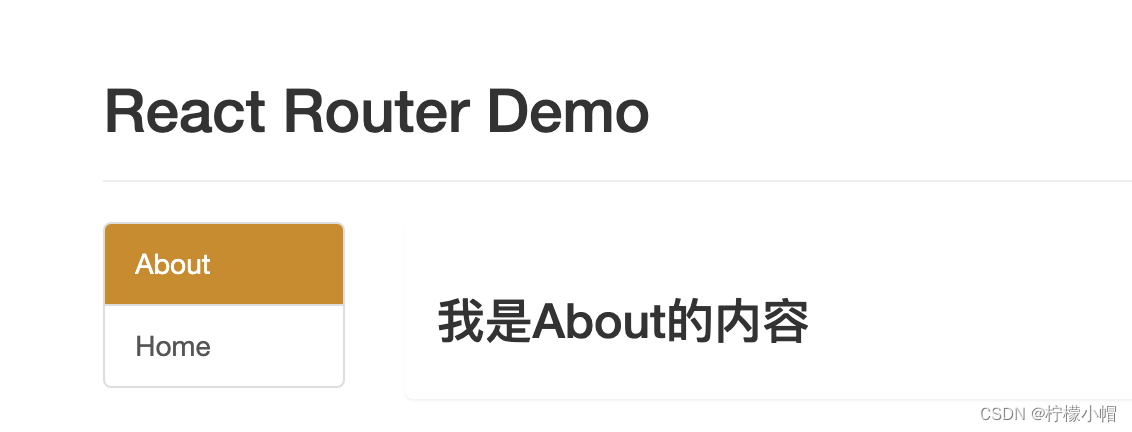
React 全栈体系(九)
第五章 React 路由 一、相关理解 1. SPA 的理解 单页 Web 应用(single page web application,SPA)。整个应用只有一个完整的页面。点击页面中的链接不会刷新页面,只会做页面的局部更新。数据都需要通过 ajax 请求获取, 并在前端…...

阈值化分割,对灰度级图像进行二值化处理(数字图像处理大题复习 P8)
文章目录 画出表格求出灰度直方图 & 山谷画出结果图 画出表格 有几个0就写几,有几个1就写几,如图 求出灰度直方图 & 山谷 跟前面求灰度直方图的方法一样,找出谷底,发现结果为 4 画出结果图 最终的结果就是…...

vue3中withDefaults是什么
问: const props withDefaults(defineProps<{// 数据列表lotteryList: { pic: string; name?: string }[];// 中奖idwinId: number;// 抽奖初始转动速度initSpeed: number;// 抽奖最快转动速度fastSpeed: number;// 抽奖最慢转动速度slowSpeed: number;// 基本圈数baseCi…...
Android进阶之路 - 盈利、亏损金额格式化
在金融类型的app中,关于金额、数字都相对敏感和常见一些,在此仅记录我在金融行业期间学到的皮毛,如后续遇到新的场景也会加入该篇 该篇大多采用 Kotlin 扩展函数的方式进行记录,尽可能熟悉 Kotlin 基础知识 兄弟 Blog StringUti…...
工业蒸汽量预测(速通一)
工业蒸汽量预测(一) 赛题理解1、评估指标2、赛题模型3、解题思路 理论知识1、变量识别2、变量分析3、缺失值处理4、异常值处理5、变量转换6、新变量生成 数据探索1、导包2、读取数据3、查看数据4、可视化数据分布4.1箱型图4.2获取异常数据并画图4.3直方图…...

机器学习的主要内容
分类任务 回归任务 有一些算法只能解决回归问题有一些算法只能解决分类问题有一些算法的思路既能解决回归问题,又能解决分类问题 一些情况下, 回归任务可以转化为分类任务, 比如我们预测学生的成绩,然后根据学生的成绩划分为A类、…...
)
华为OD机试真题-分积木-2023年OD统一考试(B卷)
题目描述: Solo和koko是两兄弟,妈妈给了他们一大堆积木,每块积木上都有自己的重量。现在他们想要将这些积木分成两堆。哥哥Solo负责分配,弟弟koko要求两个人获得的积木总重量“相等”(根据Koko的逻辑),个数可以不同,不然就会哭,但koko只会先将两个数转成二进制再进行加…...

SpringBoot自动装配原理及分析
一、什么是自动装配 在使用SpringBoot的时候,会自动将Bean装配到IoC容器中。例如我们在使用Redis数据库的时候,会引入依赖spring-boot-starter-data-redis。在引入这个依赖后,服务初始化的时候,会将操作Redis需要的组件注入到IoC…...
Android开发笔记 :理解Fragment
Android开发笔记:理解Fragment 导言 本篇文章产生的原因很简单,就是我在了解Android Jetpack中的Lifecycle框架时发现Lifecycle具体时间和状态的更新都是由一个名为ReportFragment的Fragment来跟踪的,为了更好的了解Fragment是如何追踪Activ…...

网盘下载新革命:九大平台一键直链,告别客户端束缚
网盘下载新革命:九大平台一键直链,告别客户端束缚 【免费下载链接】Online-disk-direct-link-download-assistant 一个基于 JavaScript 的网盘文件下载地址获取工具。基于【网盘直链下载助手】修改 ,支持 百度网盘 / 阿里云盘 / 中国移动云盘…...
Translumo:5分钟掌握Windows实时屏幕翻译终极指南
Translumo:5分钟掌握Windows实时屏幕翻译终极指南 【免费下载链接】Translumo Advanced real-time screen translator for games, hardcoded subtitles in videos, static text and etc. 项目地址: https://gitcode.com/gh_mirrors/tr/Translumo 你是否在玩外…...
)
别再死记硬背了!用MATLAB手把手教你画根轨迹图(附代码与避坑指南)
MATLAB实战:从零绘制根轨迹图的完整指南与避坑技巧 在控制系统的设计与分析中,根轨迹图是理解系统动态特性的重要工具。传统教学中,学生往往被要求死记硬背绘制规则,却难以理解其实际应用价值。本文将彻底改变这一现状——通过MAT…...

告别标题栏!在RK3568 Buildroot固件上,让你的Qt应用开机全屏显示的保姆级教程
RK3568嵌入式全屏实战:从Weston配置到Qt应用独占显示的完整指南 在嵌入式Linux系统开发中,GUI应用的全屏显示往往成为工程师面临的第一个"拦路虎"。当你在RK3568平台上精心开发的Qt应用启动后,却发现屏幕顶部顽固地挂着Weston窗口管…...

Obsidian智能模板终极指南:3步打造高效笔记自动化系统
Obsidian智能模板终极指南:3步打造高效笔记自动化系统 【免费下载链接】Templater A template plugin for obsidian 项目地址: https://gitcode.com/gh_mirrors/te/Templater Templater插件是Obsidian生态系统中功能最强大的智能模板解决方案,它能…...

移动端AI助手开发实战:混合架构、模型部署与性能优化
1. 项目概述:一个移动端AI助手的诞生 最近在移动端AI应用开发圈子里,一个名为 copaw-mobile 的项目开始引起不少同行的注意。这个由 xmingai 团队开源的项目,定位非常清晰——它要做的,就是将一个功能强大的AI助手,…...

手把手带你激活Matlab2016b:Windows 64位系统下的完整许可配置指南
1. 准备工作:确保激活环境完整 在开始激活Matlab2016b之前,我们需要做好充分的准备工作。首先确认你已经按照官方流程完成了基础安装,并且安装目录下存在完整的文件结构。我遇到过不少朋友因为安装不完整导致后续激活失败的情况,所…...

ITK-SNAP医学图像分割:破解三维解剖结构提取的工程难题
ITK-SNAP医学图像分割:破解三维解剖结构提取的工程难题 【免费下载链接】itksnap ITK-SNAP medical image segmentation tool 项目地址: https://gitcode.com/gh_mirrors/it/itksnap 当我们面对复杂的脑部MRI数据、肿瘤CT扫描或心血管影像时,最大…...

从“客户匿名”到“可验证”:技术服务案例的工程化写法
在撰写技术服务案例时,我们经常面临一个挑战:客户要求匿名,但案例又需要让潜在客户相信效果。如何平衡?结合文澜天下科技在AI搜索优化项目中的实践,分享一种“可验证”的案例写法。一、定位具体行业和场景 不写“某教育…...

降AI率软件越便宜越好吗?实测5个主流降AI工具,首选嘎嘎降!
一、前言:2026 年毕业必须通过 aigc 检测 2026 年各高校对学术论文的 AIGC 疑似度的审查全面变严, 均发布了具体 AIGC 检测报告和数值要求,211 和 985 高校规定本科论文 AI 率要低于 20%, 硕士要求 AI 率不高于 15%。普通高校一般要求 AI 率控制在 30% 以内。AIGC 检测率超标的…...