BD就业复习第四天
1. 布隆过滤器怎么实现去重
布隆过滤器是一种用于快速检查一个元素是否可能存在于一个大集合中的数据结构,但它并不适用于精确去重。因为布隆过滤器具有一定的误判率(可能会将不存在的元素误判为存在),所以不能确保完全的去重。但可以结合其他数据结构来实现近似的去重功能。
以下是使用布隆过滤器进行近似去重的一般步骤:
-
初始化布隆过滤器:首先,你需要选择合适的布隆过滤器大小和哈希函数数量。这些参数的选择会影响误判率和性能。
-
添加元素:当你要向数据集中添加元素时,将元素经过多个哈希函数计算得到多个哈希值,并将这些哈希值对应的位设置为1。这样,元素就被添加到了布隆过滤器中。
-
检查元素是否存在:当你想要检查一个元素是否存在于数据集中时,同样地,将元素经过哈希函数计算得到哈希值,并检查这些位是否都被设置为1。如果有任何一个位不为1,那么元素肯定不存在于数据集中。如果所有位都为1,那么元素可能存在于数据集中,但需要进一步的确认。
-
进一步确认:如果布隆过滤器返回一个元素可能存在于数据集中,你可以进一步查询一个精确的数据结构(如散列表)来确认元素是否真正存在。这个步骤可以用来处理误判情况。
需要注意的是,布隆过滤器的误判率会随着布隆过滤器的大小和哈希函数数量的选择而变化。如果你需要更低的误判率,可能需要增加布隆过滤器的大小和哈希函数的数量,但这也会增加存储和计算成本。
总的来说,布隆过滤器适合用于快速判断元素是否可能存在于一个大数据集中,但不能保证完全去重。如果你需要精确去重,可以考虑使用其他数据结构,如散列表或集合。如果误判率是关键问题,可以考虑使用基于Bloom过滤器的改进算法,如Counting Bloom Filter或Bloomier Filter。
2. map和mapPartition的区别
map 和 mapPartitions 都是分布式计算框架(如Apache Spark)中常见的操作,用于对数据集进行转换和处理。它们在使用场景和行为上有一些区别:
1. map:
- 作用:
map操作用于对数据集中的每个元素进行逐一处理,生成一个新的数据集,其中每个元素都经过了转换。 - 使用场景: 适用于需要对数据集的每个元素进行独立操作的情况,例如对每个元素进行一次映射、筛选或转换等。
- 并行度:
map操作可以并行处理数据集的每个元素,因此适用于数据集中元素间没有依赖关系的情况。
2. mapPartitions:
- 作用:
mapPartitions操作也对数据集中的元素进行处理,但是它以分区为单位进行操作,而不是每个元素单独操作。 - 使用场景: 适用于需要在分区级别进行操作的情况,例如在处理数据集时需要访问分区内的所有元素,或者需要进行分区内的聚合操作。
- 并行度:
mapPartitions操作的并行度比map低,因为它是以分区为单位操作的。通常情况下,一个分区内的元素会在一个任务中处理,因此任务数等于分区数。
区别:
-
粒度不同: 最明显的区别是粒度,
map是元素级别的操作,而mapPartitions是分区级别的操作。 -
性能考虑:
mapPartitions可以减少任务启动和上下文切换的开销,因为它将操作聚合在分区级别,而不是元素级别。这在某些情况下可以提高性能。 -
状态维护: 如果需要在操作中维护一些状态信息(例如累加器),
mapPartitions可能更方便,因为它可以在分区内共享状态信息,而不需要额外的同步操作。
选择使用哪种操作取决于你的具体需求。如果你需要对数据集的每个元素都执行相同的操作,并且元素之间没有依赖关系,那么 map 可能更合适。如果你需要在分区级别进行操作,或者需要在操作中维护状态信息,那么 mapPartitions 可能更适用。通常,合理地选择这两种操作可以提高分布式计算的性能和效率。
3. 实时数据同步方案
实时数据同步是将数据从一个源系统实时地传输到目标系统的过程,以确保目标系统中的数据与源系统保持同步。以下是一些常见的实时数据同步方案:
-
Change Data Capture (CDC):
- 工作原理: CDC 是一种通过捕获源系统中的数据变更来实现实时同步的方法。它可以监测数据库表中的插入、更新和删除操作,并将这些变更事件传递给目标系统。
- 使用场景: 适用于需要保持源系统和目标系统之间数据一致性的情况,如数据仓库同步、数据备份等。
-
消息队列:
- 工作原理: 使用消息队列作为中间件,源系统将数据变更事件发布到消息队列,然后目标系统订阅消息队列以接收这些事件并处理。
- 使用场景: 适用于异构系统之间的实时数据同步,如微服务架构中的组件之间通信、日志收集和处理等。
-
流处理框架:
- 工作原理: 流处理框架如Apache Kafka Streams、Apache Flink等可以用于实时数据处理和同步。它们能够处理高吞吐量的数据流,并支持事件时间处理和状态管理。
- 使用场景: 适用于需要进行实时数据转换、聚合和过滤的场景,如实时报表生成、实时监控等。
-
ETL工具:
- 工作原理: ETL(Extract, Transform, Load)工具可以用于从源系统抽取数据、进行转换和清洗,然后加载到目标系统中。某些ETL工具支持实时数据同步。
- 使用场景: 适用于需要进行数据转换和清洗的实时数据同步任务,如数据仓库集成、数据湖管理等。
-
数据库复制:
- 工作原理: 一些数据库管理系统提供了内置的复制功能,可以将数据实时复制到另一个数据库实例。这种方法通常适用于数据库之间的实时同步。
- 使用场景: 适用于需要保持多个数据库之间数据一致性的场景,如数据库备份、灾备等。
-
API和Webhooks:
- 工作原理: 在某些情况下,源系统和目标系统可以通过API和Webhooks进行实时数据交互。源系统通过API提供数据,目标系统通过Webhooks接收实时通知。
- 使用场景: 适用于Web应用、SaaS应用和云服务之间的实时数据同步,如社交媒体更新、电子商务订单处理等。
实时数据同步方案的选择取决于你的具体需求、系统架构和技术堆栈。在设计和实施实时数据同步方案时,需要考虑数据一致性、性能、可靠性、数据格式转换、错误处理和监控等因素。
4. kafka-flink-clickhouse的端到端一致性怎么保证
实现从Kafka到Flink再到ClickHouse的端到端一致性是一个复杂的任务,需要考虑数据可靠性、流处理应用的Exactly-Once语义、错误处理、监控和幂等性等多个方面。下面是一些关键的实践和方法,以帮助确保一致性:
-
Kafka 数据可靠性:
- 在Kafka中,使用适当的副本因子和ISR(In-Sync Replicas)配置以确保消息的可靠性,这将减少消息丢失的风险。
- 使用Kafka的生产者确认机制来确保消息成功写入Kafka主题。可以使用“all”确认级别,以等待所有ISR中的副本都确认接收消息。
-
Flink 流处理的 Exactly-Once 语义:
- 在Flink中,可以使用Flink的事务性状态来确保处理结果的Exactly-Once语义。Flink使用检查点机制和状态快照来实现这一目标。
- 配置Flink任务以支持仅一次(Exactly-Once)语义,使用可靠的外部存储来保存检查点。
-
错误处理和容错机制:
- 在Flink应用中实施适当的错误处理和容错机制,包括重启策略和故障恢复机制,以确保在处理期间的故障情况下数据一致性不会受到影响。
- 使用Flink的侧输出(Side Outputs)来处理错误数据,以便后续修复或重新处理。
-
ClickHouse 数据加载一致性:
- 当将数据从Flink导入ClickHouse时,使用ClickHouse提供的INSERT查询,这些查询可以以原子方式将数据写入ClickHouse表,确保数据加载的一致性。
- 考虑使用ClickHouse的分布式事务功能来确保多个数据表之间的一致性。
-
Kafka 到 Flink 到 ClickHouse 的监控:
- 配置全面的监控系统,以追踪数据处理和数据流程的健康状况。
- 使用监控工具来监测Kafka、Flink和ClickHouse的性能和状态,以及检测潜在的问题。
-
消费者应用的幂等性:
- 在ClickHouse中的消费者应用程序中,确保应用程序是幂等的,即无论处理多少次相同的消息,结果都是一致的。这可以通过在处理逻辑中引入唯一标识符或版本号来实现。
-
数据版本管理:
- 使用版本控制来管理Kafka、Flink和ClickHouse的应用代码和配置,以确保一致性和可追溯性。
综上所述,端到端一致性的保证需要综合考虑多个环节,包括数据可靠性、Exactly-Once语义、错误处理、监控和幂等性。通过仔细设计和实施每个环节,可以最大程度地确保数据的准确性和一致性,以满足业务需求。此外,定期进行系统的性能和稳定性测试也是保证一致性的重要一环。
5. 定时器的功能和实现思路
定时器是一种用于在预定时间执行特定任务或触发事件的工具。它在计算机编程和应用中具有广泛的应用,用于调度任务、执行定时操作、实现超时处理等。以下是定时器的一般功能和实现思路:
定时器的功能:
-
任务调度: 定时器可以用于调度需要定期执行的任务,例如定期备份数据、定时清理日志、定时发送通知等。
-
事件触发: 定时器可以触发特定的事件,如定时触发定时器事件、闹钟响铃等。
-
超时处理: 定时器可以用于处理超时事件,例如等待一个操作在规定时间内完成,否则触发超时处理。
-
周期性操作: 定时器可以用于执行特定的操作,以周期性地执行某些任务。
定时器的实现思路:
-
使用编程语言提供的定时器库: 大多数编程语言和平台都提供了内置的定时器库,开发人员可以使用这些库来创建和管理定时器。例如,Java中的
java.util.Timer类和ScheduledExecutorService接口,Python中的time.sleep()和threading.Timer等。 -
使用系统定时器: 许多操作系统也提供了系统级别的定时器服务,可以通过系统调用或API来创建和管理定时器。例如,Linux中的
timer_create()和timer_settime()函数。 -
使用第三方定时器库: 有许多第三方定时器库可用,可以根据项目需求选择合适的库。例如,对于JavaScript,可以使用
setTimeout和setInterval,或者使用像node-schedule这样的第三方库。 -
使用硬件定时器: 在嵌入式系统或某些特定应用中,可以使用硬件定时器来实现高精度的定时器功能。
-
使用调度器或任务队列: 在一些分布式系统中,可以使用任务队列或调度器来管理和触发定时任务。例如,使用消息队列(如RabbitMQ、Kafka)或调度框架(如Apache Airflow)来调度任务。
-
使用多线程或多进程: 可以使用多线程或多进程来创建定时器,每个线程或进程负责执行不同的定时任务。
无论选择哪种实现思路,都需要注意处理异常情况、考虑并发问题、处理定时器的取消和暂停、以及管理资源(如线程或进程)的生命周期。此外,还应谨慎处理时区和时间同步问题,以确保定时器的行为与预期一致。
6. 流式计算分组统计的实现思路
流式计算中的分组统计是一种常见的操作,用于对数据流中的元素进行分组,并对每个分组中的元素进行统计。以下是一些实现思路和通用步骤:
1. 数据流的准备: 首先,你需要有一个数据流,可以是从各种数据源获取的实时数据。这个数据流可以是事件流、日志流、传感器数据流等。
2. 数据分组: 下一步是将数据流中的元素按照某个关键属性进行分组。这个关键属性通常是你希望统计的维度,例如时间窗口、地理位置、用户ID等。
3. 统计操作: 对每个分组执行统计操作,通常包括计数、求和、平均值、最大值、最小值等。统计操作的具体内容取决于你的需求。
4. 输出结果: 将每个分组的统计结果输出到合适的目标,这可以是数据库、消息队列、文件、仪表盘等。
以下是一些流式计算中实现分组统计的常见技术和框架:
1. Apache Flink: Flink是一个流式计算引擎,提供了丰富的窗口操作和分组统计功能。你可以使用Flink的KeyBy操作对数据进行分组,然后使用窗口操作(如滚动窗口、滑动窗口)定义统计的范围,最后使用reduce、aggregate等操作来进行统计。
2. Apache Kafka Streams: 如果你的数据流基于Kafka,可以使用Kafka Streams来进行分组统计。Kafka Streams提供了丰富的状态管理和窗口操作,可以方便地实现分组统计。
3. Spark Streaming: 如果你使用Apache Spark作为流式计算框架,可以使用Spark Streaming进行分组统计。你可以使用DStream的reduceByKey、updateStateByKey等操作来进行统计。
4. 自定义流处理应用: 如果你需要更大的灵活性,可以编写自己的流处理应用程序,使用流处理库(如Kafka Consumer、RabbitMQ Consumer)来订阅数据,然后自己实现分组和统计逻辑。
5. 数据库聚合: 如果你需要持久化统计结果,可以将数据流导入数据库,然后使用SQL或存储过程进行分组统计。
需要根据具体的业务需求和数据流特点选择合适的实现方法和工具。同时,流式计算中的分组统计通常需要考虑延迟、时序性、容错性等因素,因此在设计和实现时需要谨慎考虑这些问题。
7. 经纬度坐标转地理位置信息的实现思路
将经纬度坐标转换为地理位置信息通常需要使用地理编码(Geocoding)服务或地理信息数据库。以下是一般的实现思路:
1. 使用地理编码服务:
- **选择地理编码服务:** 选择一家可靠的地理编码服务提供商,如Google Maps Geocoding API、Baidu Map API、OpenStreetMap Nominatim等。注册并获取访问密钥或API令牌。- **构建API请求:** 使用提供的API,构建一个HTTP请求,将经度和纬度作为参数传递。通常,你需要以JSON或XML格式发送请求。- **发送请求:** 发送HTTP请求到地理编码服务的API端点。- **解析响应:** 处理地理编码服务的响应,通常响应中包含了地理位置信息,如地名、国家、城市等。- **存储或使用信息:** 将解析得到的地理位置信息存储在你的应用程序中,或者根据需求进行进一步处理和显示。
2. 使用地理信息数据库:
- **获取地理信息数据库:** 获得一个包含经纬度坐标和地理位置信息的地理信息数据库,如GeoNames、Natural Earth等。- **数据查询:** 根据给定的经纬度坐标,在地理信息数据库中进行查询,以检索对应的地理位置信息。- **解析结果:** 处理查询结果以获取地理位置信息,如地名、国家、城市等。- **存储或使用信息:** 将地理位置信息存储在你的应用程序中,或者根据需求进行进一步处理和显示。
注意事项:
-
不同的地理编码服务提供商可能有不同的定价和使用限制,因此需要根据你的应用需求选择合适的服务提供商。
-
地理编码服务通常需要联网访问,因此需要确保你的应用程序有互联网连接。
-
地理编码服务的准确性和可用性可能因地区而异,需要在选择服务提供商时进行评估。
-
在使用地理信息数据库时,需要考虑数据的更新和维护,以确保信息的准确性。
无论选择地理编码服务还是地理信息数据库,都需要考虑应用的性能和用户体验,以确保地理位置信息的获取和显示是高效和可靠的。
8. 实时任务怎么部署,资源怎么分配?
部署实时任务并分配资源是一个关键的任务,它涉及到确保任务能够在生产环境中稳定高效地运行。下面是部署实时任务和资源分配的详细步骤:
1. 确定部署环境:
- 首先,确定你的实时任务将运行在哪个环境中,是本地服务器、云服务器、容器化环境(如Docker/Kubernetes)还是服务器集群等。
2. 安装运行时环境:
- 在目标环境中安装所需的运行时环境,包括操作系统、虚拟机、容器运行时、编程语言运行时(如Java、Python)、流处理框架(如Apache Flink、Apache Kafka Streams)、数据库和其他依赖项。
3. 部署应用代码:
- 将你的实时任务的代码部署到目标环境中。这可以包括上传可执行文件、容器镜像、应用程序包或脚本。
4. 配置应用程序:
- 配置实时任务的运行参数,包括输入源(如消息队列或数据流)、输出目的地(如数据库或消息队列)、处理逻辑、并行度、检查点设置、错误处理策略等。
5. 资源分配和调整:
-
确定实时任务所需的计算和存储资源。资源分配的具体方式取决于你的应用和部署环境。以下是资源分配和调整的一般步骤:
-
CPU和内存分配: 根据实时任务的计算需求分配CPU和内存资源。你可能需要监控应用的CPU和内存使用情况,以确保不会出现性能瓶颈。
-
并行度调整: 根据实际负载情况,调整任务的并行度。增加并行度可以提高处理能力,但也可能增加资源消耗。
-
存储分配: 确保实时任务所需的存储资源可用,并配置数据存储路径、容量和备份策略。
-
网络带宽: 如果实时任务涉及大量数据传输,确保网络带宽足够,以避免网络延迟和丢包。
6. 监控和日志记录:
- 设置监控系统,用于实时监测任务的性能、运行状态和异常情况。同时,配置详细的日志记录,以便在出现问题时进行故障排除。
7. 安全性设置:
- 针对应用程序和资源进行安全设置,确保数据的机密性和完整性。这可能包括访问控制、身份验证、授权和数据加密。
8. 高可用性和故障恢复:
- 针对关键任务配置高可用性解决方案,以确保任务能够在硬件或软件故障时继续运行。这可能包括备份节点、冗余数据流、自动故障转移等。
9. 测试和性能优化:
- 在生产环境之前进行严格的测试,包括性能测试、负载测试和故障恢复测试。根据测试结果进行性能优化,确保任务能够在生产环境中稳定运行。
10. 自动化和扩展性:
- 考虑自动化任务部署和资源分配过程,以便能够轻松地扩展和管理多个任务实例。
最后,一旦实时任务部署完成,定期监控任务的性能,确保它能够在不同负载情况下持续高效运行,并在必要时进行资源调整和升级。资源的有效分配和监控是保持实时任务稳定性和性能的关键。
相关文章:

BD就业复习第四天
1. 布隆过滤器怎么实现去重 布隆过滤器是一种用于快速检查一个元素是否可能存在于一个大集合中的数据结构,但它并不适用于精确去重。因为布隆过滤器具有一定的误判率(可能会将不存在的元素误判为存在),所以不能确保完全的去重。但…...
数据结构 | 树
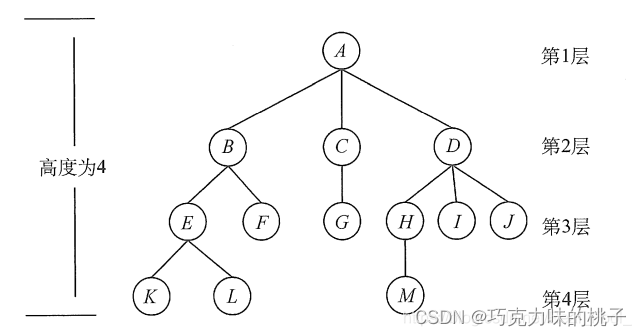
树 树是n(n>0)个结点的有限集。当n 0时,称为空树。在任意一棵非空树中应满足: 有且仅有一个特定的称为根的结点。当n>1时,其余节点可分为m(m>0)个互不相交的有限集T1,T2,…,Tm&#…...
Android11 适配
一、修改targetSdkVersion为30 将build.gradle的目标版本targetSdkVersion修改为30(Android 11) targetSdkVersion 30Android11的改变改变主要影响以Adnroid11 为目标版本的应用(targetSdkVersion>30才有影响),和所…...
UML基础与应用之对象图
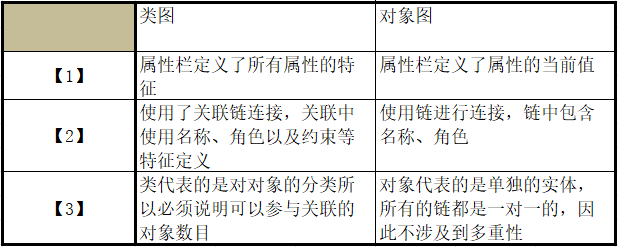
什么是对象图? 对象图表示一组对象及它们之间的关系,是某一时刻系统详细信息的快照,描述系统交互的静态图形,它由协作的对象组成,但不包含在对象之间传递的任何消息。因为对象是类的实例化,所以说某一时刻…...

英码科技精彩亮相火爆的IOTE 2023,多面赋能AIoT产业发展!
9月20日至22日,在这金秋飒爽的季节,为期三天的IOTE 2023第二十届国际物联网展深圳站在深圳国际会展中心盛大举行。英码科技精彩亮相本届展会,并在同期举办的AIoT视觉物联产业生态大会发表了主题演讲,与生态伙伴们共同探讨AIoT产业…...
400G QSFP-DD FR4 与 400G QSFP-DD FR8光模块:哪个更适合您的网络需求?
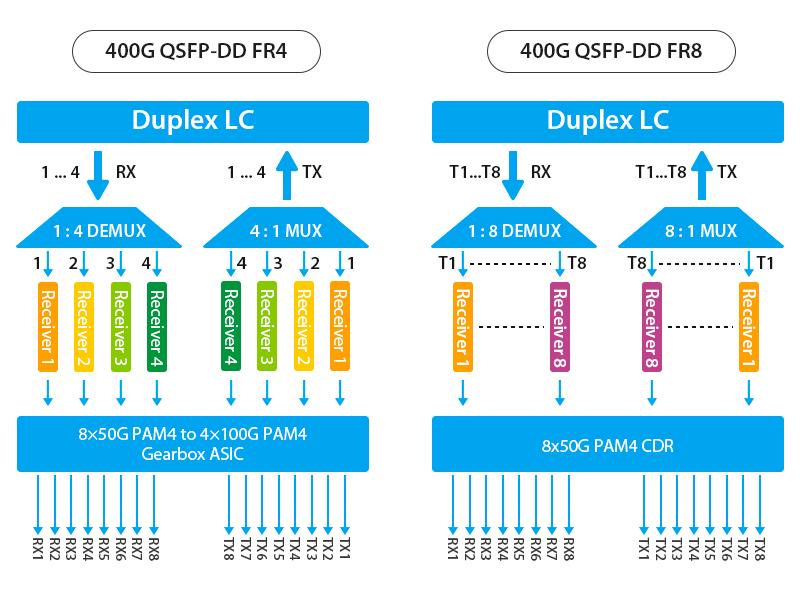
QSFP-DD 光模块随着光通信市场规模的不断增长已成为400G市场中客户需求量最高的产品。其中400G QSFP-DD FR4和400G QSFP-DD FR8光模块都是针对波分中距离传输(2km)的解决方案,它们之间有什么不同?应该如何选择应用?飞速…...
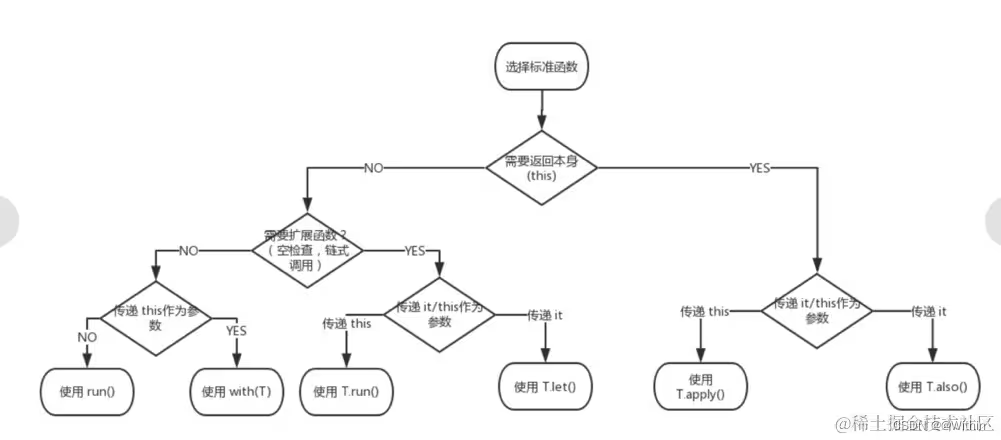
【Android】Kotlin 中的 apply、let、with、also、run 到底有啥区别?
一、图示 二、apply apply 函数接收一个对象并返回该对象本身。它允许您在对象上执行一些操作,同时仍然返回原始对象。 这个函数的语法为: fun <T> T.apply(block: T.() -> Unit): T 其中,T 是对象的类型,block 是一…...

设计模式——职责链模式
职责链模式 职责链模式职责链模式解决什么问题?职责链模式实现 职责链模式 使多个对象都有机会处理请求,从而避免请求的发送者和接收者之间的耦合关系。将这个对象练成一条链,并沿着这条链传递该请求,知道有一个对象处理它为止 …...

小程序自定义tabbar,中间凸起
微信小程序自带tabbar,但无法实现中间按钮凸起样式和功能,因此按照设计重新自定义一个tabbar 1、创建tabbar文件,与pages同级创建一个文件夹,custom-tab-bar,里面按照设计图将底部tabbar样式编写 <view class"tab-bar&q…...

数据结构-顺序栈C++示例
栈(stack)是限定仅在表尾进行插入或删除操作的线性表。 对栈来说,表尾端称为栈顶(top), 表头端称为栈底(bottom),不含元素的空表称为空栈。 假设栈 S ( a 1 , a 2 , a 3 , ⋯ , a n ) S(a_1,a_2,a_3,\cdots,a_n) S(a1,a2,a3,⋯,an…...
若依cloud -【 100 ~ 103 】
100 分布式日志介绍 | RuoYi 分布式日志就相当于把日志存储在不同的设备上面。比如若依项目中有ruoyi-modules-file、ruoyi-modules-gen、ruoyi-modules-job、ruoyi-modules-system四个应用,每个应用都部署在单独的一台机器里边,应用对应的日志的也单独存…...

可转债实战与案例分析——成功的和失败的可转债投资案例、教训与经验分享
实战与案例分析——投资案例研究 股票量化程序化自动交易接口 一、成功的可转债投资案例 成功的可转债投资案例提供了有价值的经验教训,以下是一个典型的成功案例: 案例:投资者B的成功可转债投资 投资者B是一位懂得风险管理的投资者&#…...
@NotNull注解不生效,全局异常处理
1.引入依赖 <dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-validation</artifactId><version>3.1.2</version> </dependency> 2:实体类 实体类属性加上NotNull注解…...

【办公自动化】使用Python一键往Word文档的表格中填写数据(文末送书)
🤵♂️ 个人主页:艾派森的个人主页 ✍🏻作者简介:Python学习者 🐋 希望大家多多支持,我们一起进步!😄 如果文章对你有帮助的话, 欢迎评论 💬点赞Ǵ…...
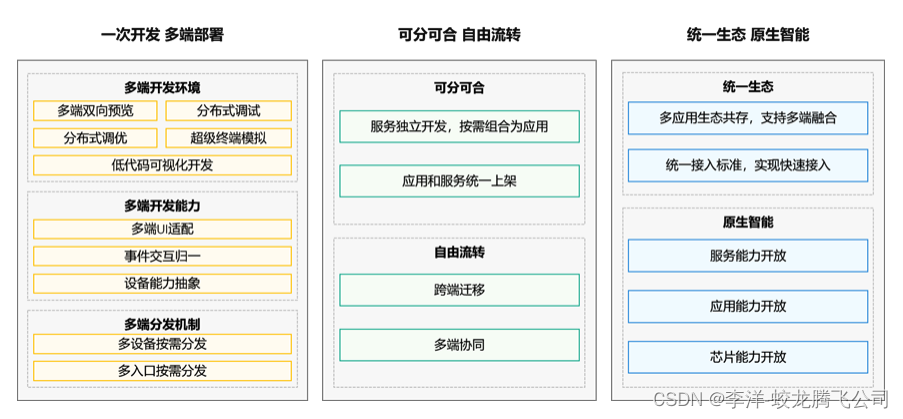
OpenHarmony应用核心技术理念与需求机遇简析
一、核心技术理念 图片来源:OpenHarmony官方网站 二、需求机遇简析 新的万物互联智能世界代表着新规则、新赛道、新切入点、新财富机会;各WEB网站、客户端( 苹果APP、安卓APK)、微信小程序等上的组织、企业、商户等;OpenHarmony既是一次机遇、同时又是一次大的挑战&…...

让Pegasus天马座开发板实现超声波测距
在完成《让Pegasus天马座开发板用上OLED屏》后,我觉得可以把超声波测距功能也在Pegasus天马座开发板上实现。于是在箱子里找到了,Grove - Ultrasonic Ranger 这一超声波测传感器。 官方地址: https://wiki.seeedstudio.com/Grove-Ultrasonic_Ranger 超声…...

C++11 多线程学习
C11学习 一、多线程 1、模板线程是以右值传递的 template <class Fn, class... Args> explicit thread(Fn&& fn, Args&&... args)则需要使用到std::ref和std::cref很好地解决了这个问题,std::ref 可以包装按引用传递的值。 std::cref 可以…...

数学公式测试
MVP变换 MVP变换用来描述视图变换的任务,即将虚拟世界中的三维物体映射(变换)到二维坐标中。 MVP变换分为三步: 模型变换(model tranformation):将模型空间转换到世界空间(找个好的地方,把所…...

机器学习——SVM(支持向量机)
0、前言: SVM应用:主要针对小样本数据进行学习、分类和回归(预测),能解决神经网络不能解决的过学习问题,有很好的泛化能力。(注意:SVM算法的数学原理涉及知识点比较多,所…...

【李沐深度学习笔记】基础优化方法
课程地址和说明 基础优化方法p2 本系列文章是我学习李沐老师深度学习系列课程的学习笔记,可能会对李沐老师上课没讲到的进行补充。 基础优化方法 在讲具体的线性回归实现之前,要先讲一下基础的优化模型的方法 梯度下降 当模型没有显示解(…...

HarmonyOS ArkWeb 系列之用户一复制,我就知道——剪贴板事件监听实战
文章目录 剪贴板事件有哪几个ArkTS 侧配置H5 侧的事件监听实现流程图:copy 事件拦截修改三种事件的使用场景对比一个实用的"只允许粘贴纯文本"方案踩坑记录写在最后 上一篇讲了怎么用代码主动读写剪贴板。但有时候需求不是主动操作,而是监听—…...

CATCCOS核心组件深度解析:从Host到Device的分层架构设计原理
CATCCOS核心组件深度解析:从Host到Device的分层架构设计原理 【免费下载链接】catccos CATCCOS昇腾计算-通信融合算子模板库,是一个聚焦于提供高性能计算通信融合类算子基础模板的代码库。 项目地址: https://gitcode.com/cann/catccos CATCCOS昇…...

CANN/cannbot-skills模型推理融合算子优化
【免费下载链接】cannbot-skills CANNBot 是面向 CANN 开发的用于提升开发效率的系列智能体,本仓库为其提供可复用的 Skills 模块。 项目地址: https://gitcode.com/cann/cannbot-skills name: model-infer-fusion description: 基于 PyTorch 框架的昇腾 NPU…...

深入解析Arm Cortex-A53 Cache架构:从原理到多核一致性与性能优化实践
1. 项目概述:为什么我们需要深入理解A53的Cache?在嵌入式系统和移动计算领域,Arm Cortex-A53处理器是一个绕不开的名字。作为Armv8-A架构下的“小核”常青树,它以其出色的能效比,广泛存在于从智能手表到智能电视&#…...

②Allegro PCB转Altium Designer PCB转Pads Layout PCB
在工作中,难免会遇到主流画板EDA软件(Pads、Altium Designer、Cadence allegeo、嘉立创EDA等)文件格式相互间转换的问题。下面来介绍一下Allegro PCB转Pads Layout PCB的详细操作步骤,前面已经介绍过allegro不用经过Altium Designer软件直接转PADS格式pc…...

Taotoken助力边缘计算场景下的智能应用开发与模型调用
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken助力边缘计算场景下的智能应用开发与模型调用 在工业控制、物联网网关或移动机器人等边缘计算场景中,开发者常…...
)
别再只跑测试了!用KAIR库从零训练你自己的SwinIR超分模型(附DIV2K/Flickr2K数据集处理避坑指南)
从测试到训练:SwinIR超分模型实战进阶指南 当你第一次用SwinIR的预训练模型将模糊照片变得清晰时,那种惊艳感可能让你跃跃欲试想训练自己的模型。但面对几十GB的数据集和复杂的训练配置,很多开发者停在了"只跑测试"的阶段。本文将带…...
)
【STM32入门教程】将`printf`重定向到USART串口(以USB转串口为例)
【STM32入门教程】将printf重定向到USART串口(以USB转串口为例) 在STM32开发中,printf是一个非常方便的调试工具。但默认情况下,printf会输出到标准输出设备(如屏幕),而在嵌入式系统中ÿ…...

终极QR二维码修复工具:QRazyBox完整指南与高效恢复技巧
终极QR二维码修复工具:QRazyBox完整指南与高效恢复技巧 【免费下载链接】qrazybox QR Code Analysis and Recovery Toolkit 项目地址: https://gitcode.com/gh_mirrors/qr/qrazybox 还在为损坏的二维码无法扫描而烦恼吗?QRazyBox是一款专业的免费…...

3个高效方法解决抖音素材管理难题:从零散文件到有序素材库
3个高效方法解决抖音素材管理难题:从零散文件到有序素材库 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallback s…...