大数据之Kafka
Kafka概述
传统定义:一个分布式的基于发布/订阅模式的消息队列,主要应用于大数据实时处理领域。
最新定义:一个开源的分布式事件流平台,被数千家公司用于高性能数据管道、流分析、数据集成和关键任务应用。最主要的功能是做数据的缓冲,相较于flume的channel, 能力更强。
应用场景:
- 缓冲/消峰:解决生产消息和消费消息的处理速度不一致的情况。
- 解耦:只需知道如何连接kafka,作用类似于交换机。
- 异步通信:可以将事务给kafka,自己去处理其他事务。
消息队列的两种模式:
- 点对点模式:消费者拉取数据后删除数据。优点是简单速度快,缺点是不方便实现多用户需要获取同一数据的情况。
- 发布/订阅模式:可以有多个topic主题,消费者拉取数据后不删除数据。
Kafka的基础架构
- 为方便扩展,并提高吞吐量,一个topic分为多个partition
- 配合分区的设计,提出消费者组的概念,组内内个消费者并行消费,以线程为单位。
- 为提高可用性,为每个partiton增加若干副本,类似NameNode HA
- 借助zookeeper来实现leader和follower的选举机制,leader是原数据,follower是副本数据。leader主要用于发送和传输,follower主要作为副本保证安全性。
Kafka的安装部署
官网下载地址:http://kafka.apache.org/downloads.html
- 上传安装包
- 解压安装包
- 修改配置文件
- 配置环境变量
- 编写群启群关脚本kf.sh
#! /bin/bashcase $1 in
"start"){for i in hadoop102 hadoop103 hadoop104doecho " --------启动 $i Kafka-------"ssh $i "/opt/module/kafka/bin/kafka-server-start.sh -daemon /opt/module/kafka/config/server.properties"done
};;
"stop"){for i in hadoop102 hadoop103 hadoop104doecho " --------停止 $i Kafka-------"ssh $i "/opt/module/kafka/bin/kafka-server-stop.sh "done
};;
esac
kafka主题相关操作
kafka-topics.sh脚本里面定义了对应相关操作。
- 增加主题,
kafka-topics.sh --bootstrap-server hadoop102:9092 -- create --topic second --replication-facotr 1 --partitions 1 - 删除,是标记删除,预计在1分钟后完全删除。
bin/kafka-topics.sh --bootstrap-server hadoop102:9092 --delete --topic first - 修改,只能增加分区数量。
bin/kafka-topics.sh --bootstrap-server hadoop102:9092 --alter --topic first --partitions 3 - 查看,
bin/kafka-topics.sh --bootstrap-server hadoop102:9092 --list
生产和消费
- 启动生产者:
kafka-console-producer.sh --bootstrap-server hadoop102:9092 --topic first - 启动消费者:
kafka-console-consumer.sh --bootstrap-server hadoop102:9092 --topic first - 如果单独启动生产者,发送数据,之后再启动消费者,默认不发送之前发送的数据。在消费者启动命令后面添加
--from-beginning关键字可以修改为从头拿取数据。
发送流程
- Kafka Producer生产者
- main线程Producer的生产方法
- interceptors拦截器
- Serializer序列化器
- Partitioner分区器,按照批次随机分区。每个批次默认是16K,默认的等待时间是0ms。
- RecordAccumulator里面创建双端队列,队列个数等于分区个数
- sender进程复制双端队列中的数据发送到Kafka集群,如果成功接收则返回ack应答,否则重新发送,最多重试21亿次。
异步发送和同步发送
sender进程发送请求默认是异步执行,即向kafka集群发送时不管是否收到回复,一直发送,由selector来接收ack和关闭对应的请求进程。在Producer的send方法中有一个Callback对象参数,该对象需要实现一个onCompletetion方法。可以在里面查看到对应方法参数中的元数据的值,里面有主题名称、分区号和偏移量。异步执行时可以发现同一批次分区号是一样的,同步时由于需要等待ack,同一批次的分区号是不同的。
生产者分区
- 分区策略
- 默认分区器
- 如果指定了分区号,到指定分区
- 如果是key-value,使用key进行hash分区
- 粘性分区,如果上一个有分区,跟上一个分区一样,直到数据达到分区容量上限或者等待时间上限进行随机更换分区。
- UniformStickyPartition分区器:如果key值是固定的,可以使用该分区器
- 轮询分区器:需要维护一个列表,效率更低。
- 默认分区器
生产者如何提高吞吐量
- 修改从双端队列拿取数据的等待时间,从0ms修改为5-100ms
- compression.type: 压缩snappy
- 修改批次大小:默认为16K,修改为32KB.
数据可靠性
ack应答级别:
- 0:生产者发送过来的数据,不需要等数据落盘应答,也就是最多一次。
- 1:生产者发送过来的数据,Leader收到后应答
- -1(all): 生产者发送过来的数据,Leader和isr队列里面的所有节点收齐数据并落盘后应答。Leader维护了一个动态的in-sync replica set ISR, 如果有某个节点30s内没有回复,则认为该节点死亡。数据有可能
重复。
数据的去重
幂等性
指producer不论向Broker发送多少次重复数据,Broker都只会持久化一条,保证精准一次。重复数据的判断标准,根据sqlNumber来判断,重发的数据其seqNumber是一样的。
缺点:如果生产者中途宕机,然后重新建立会话时,不能保证不同会话时PID是一样,这时候重新发送重复数据时无法保证幂等性。
解决方案:在Kafka集群中将生产者的信息保存到集群中的某个主题中,如果生产者宕机后重启需要先去读取Kafka集群的状态信息,以保证多会话情况下的幂等性。
数据的有序性
- 因为不能保证多分区之间是有序的,只能指定单分区。
- 开启幂等性,且元数据request个数小于5个,如果发送失败导致顺序异常,Kafka会按照SeqNumber重新排序。
Flume和Kafka
为何Kafka全方面碾压flume,还会有人使用flume?
这是由于flume使用上只需配置一个文件即可使用,无需编写代码。并且可以使用flume将数据灌入到kafka中,既简单又利用到了kafka的性能,flume和kafka结合使用才是日常开发的常用操作。
Kafka Broker总体工作流程
- broker在zk中注册
- controller谁先注册,谁说了算
- 由选举出来的Controller监听brokers节点变化
- Controller决定Leader选举:在isr存活为前提,轮询选举
- Controller将节点信息上传到zk
- 其他controller从zk同步相关信息
Broker节点的服役和退役
- 启动新主机的zookeeper和kafka
- 创建一个要均衡的主题vim topics-to-move.json
{"topics": [{"topic": "first"}],"version": 1
}
- 生成一个负载均衡的计划
bin/kafka-reassign-partitions.sh --bootstrap-server hadoop102:9092 --topics-to-move-json-file topics-to-move.json --broker-list "0,1,2,3" --generate - 保存生成的计划到文件中
- 执行负载均衡计划
- 在kafka/datas目录下查看是否正确。
kafka副本
为了提高数据可靠性,副本数量一般设置为两个。
Follower故障处理
LEO(log End Offset):每个副本的最后一个offset,LEO其实就是最新的offset + 1
HW (High Watermark): 所有副本中最小的LEO
高效读取
1. 多分区
2. 稀疏索引
3. 顺序写磁盘
4. 页缓存和零拷贝
页缓存:其实就是把尽可能多的空闲内存当做磁盘缓存来使用。
零拷贝:数据加工处理操作交给生产者和消费者
相关文章:

大数据之Kafka
Kafka概述 传统定义:一个分布式的基于发布/订阅模式的消息队列,主要应用于大数据实时处理领域。 最新定义:一个开源的分布式事件流平台,被数千家公司用于高性能数据管道、流分析、数据集成和关键任务应用。最主要的功能是做数据的…...
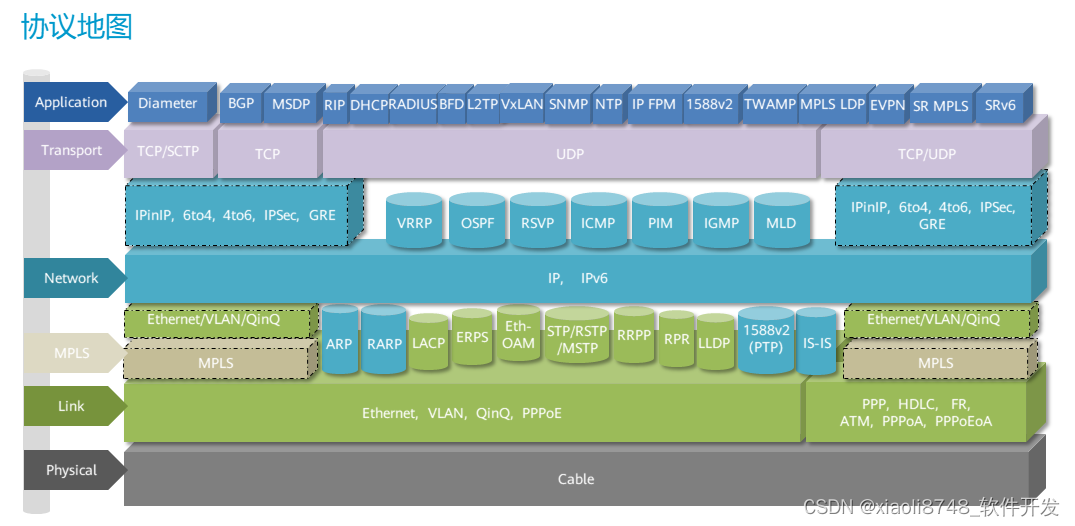
灵活运用OSI模型提升排错能力
1.OSI模型有什么实际价值? 2.二层和三层网络的区别和应用; 3.如何通过OSI模型提升组网排错能力? -- OSI - 开放式系统互联 - OSI参考模型 - 一个互联标准 -- 软件硬件 - 定义标准 数据通信的标准 -- 厂商 思科 华为 华三…...

【最新!企知道AES加密分析】使用Python实现完整解密算法
文章目录 1. 写在前面2. 过debugger3. 抓包分析4. 断点分析5. Python实现解密算法1. 写在前面 最近华为各方面传递出来的消息无不体现出华为科技实力与技术处于遥遥领先的地位。所以出于好奇想要了解一下咱们国内这些互联网科技企业有哪些技术专利,于是就有了这篇文章! 分析目…...

前端架构师之11_JavaScript事件
1 事件处理 1.1 事件概述 在学习事件前,有几个重要的概念需要了解: 事件事件处理程序事件驱动式事件流 事件 可被理解为是JavaScript侦测到的行为。 这些行为指的就是页面的加载、鼠标单击页面、鼠标滑过某个区域等。 事件处理程序 指的就是Java…...

文本过滤工具:grep
什么是grep? grep是一个命令行文本搜索工具,它的名称来源于"Global Regular Expression Print"(全局正则表达式打印)。它的主要功能是在文本文件中查找特定模式或字符串,并将匹配的行打印到终端或输出到文件…...
【Linux】生产者和消费者模型
生产者和消费者概念基于BlockingQueue的生产者消费者模型全部代码 生产者和消费者概念 生产者消费者模式就是通过一个容器来解决生产者和消费者的强耦合问题。 生产者和消费者彼此之间不直接通讯,而通过这个容器来通讯,所以生产者生产完数据之后不用等待…...
开发APP的费用是多少
开发一款APP的费用可以因多种因素而异,包括项目的规模、功能、复杂性、技术选择、地理位置等。北京是中国的大城市,APP开发的费用也会受到北京的物价水平和市场竞争的影响。以下是一些可以影响APP开发费用的因素,希望对大家有所帮助。北京木奇…...
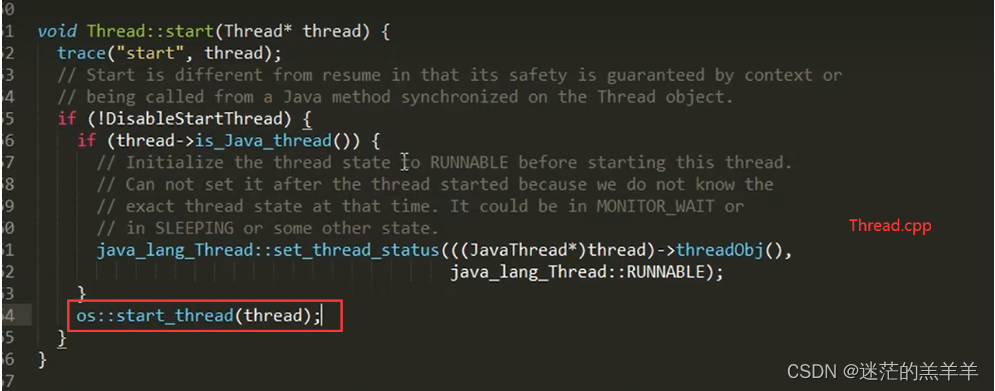
start()方法源码分析
当我们创建好一个线程之后,可以调用.start()方法进行启动,start()方法的内部其实是调用本地的start0()方法, 其实Thread.java这个类中的方法在底层的Thread.c文件中都是一一对应的,在Thread.c中start0方法的底层调用了jvm.cpp文件…...

VUE_history模式下页面404错误
uniapp 的history 把#去掉了,但是当刷新页面的时候出现404错误 解决方案:需要服务端支持 如果 URL 匹配不到任何静态资源,则应该返回同一个 index.html 页面 Apache <IfModule mod_rewrite.c>RewriteEngine OnRewriteBase /RewriteRu…...
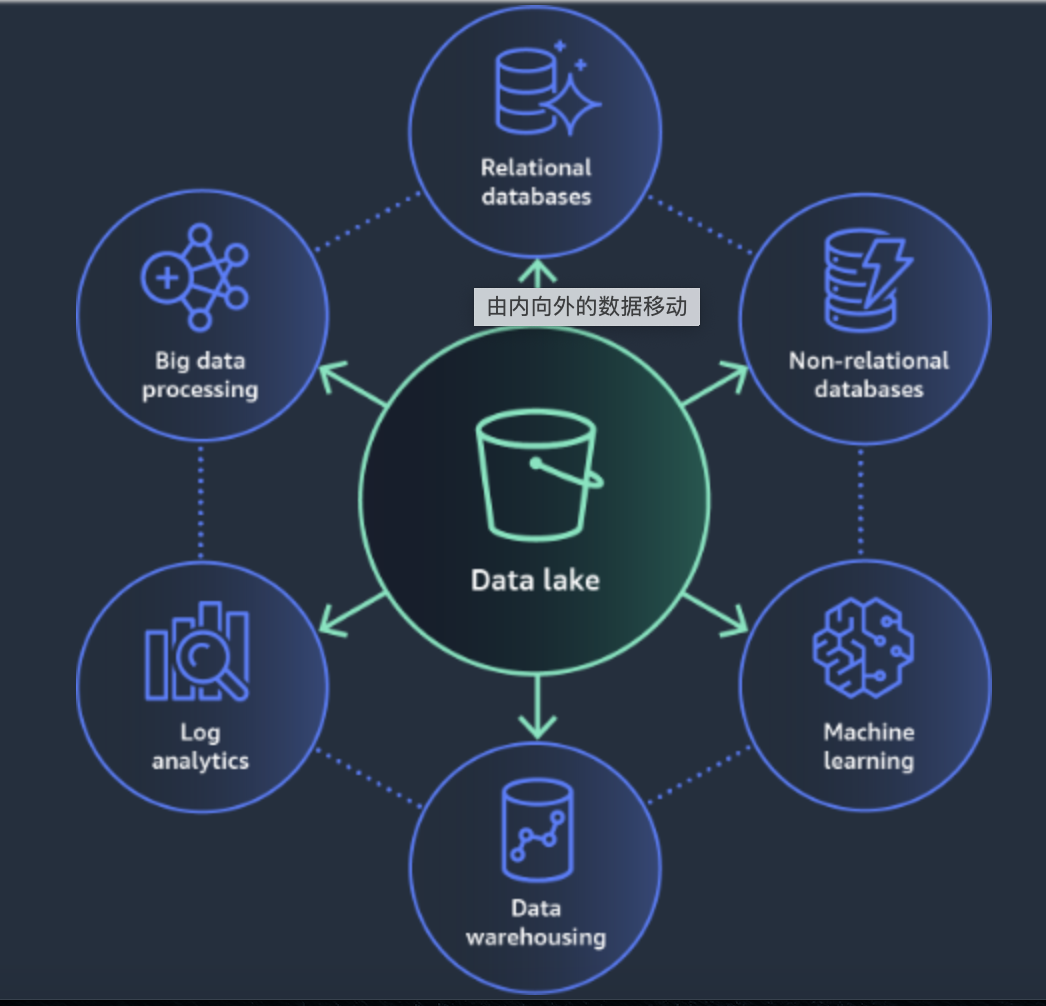
现代数据架构-湖仓一体
当前的数据架构已经从数据库、数据仓库,发展到了数据湖、湖仓一体架构,本篇文章从头梳理了一下数据行业发展的脉络。 上世纪,最早出现了关系型数据库,也就是DBMS,有商业的Oracle、 IBM的DB2、Sybase、Informix、 微软…...
最新AI写作系统ChatGPT源码/支持GPT4.0+GPT联网提问/支持ai绘画Midjourney+Prompt应用+MJ以图生图+思维导图生成
一、智能创作系统 SparkAi创作系统是基于国外很火的ChatGPT进行开发的Ai智能问答系统。本期针对源码系统整体测试下来非常完美,可以说SparkAi是目前国内一款的ChatGPT对接OpenAI软件系统。那么如何搭建部署AI创作ChatGPT?小编这里写一个详细图文教程吧&…...

Python机器学习实战-特征重要性分析方法(5):递归特征消除(附源码和实现效果)
实现功能 递归地删除特征并查看它如何影响模型性能。删除时会导致更大下降的特征更重要。 实现代码 from sklearn.ensemble import RandomForestClassifier from sklearn.feature_selection import RFE import pandas as pd from sklearn.datasets import load_breast_cance…...

如何快速走出网站沙盒期(关于优化百度SEO提升排名)
网站沙盒期是指新建立的网站在百度搜索引擎中无法获得好的排名,甚至被完全忽略的现象。这个现象往往发生在新建立的网站上,因为百度需要时间来评估网站的质量和内容。蘑菇号www.mooogu.cn 为了快速走出网站沙盒期,需要优化百度SEO。以下是5个…...
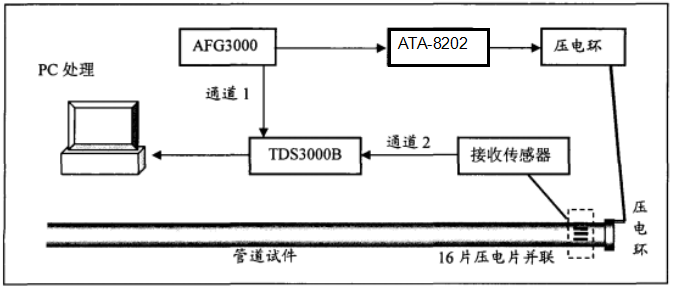
ATA-8000系列射频功率放大器——应用场景介绍
ATA-8000系列是一款射频功率放大器。其P1dB输出功率500W,饱和输出功率最大1000W。增益数控可调,一键保存设置,提供了方便简洁的操作选择,可与主流的信号发生器配套使用,实现射频信号的放大。 图:ATA-8000系…...
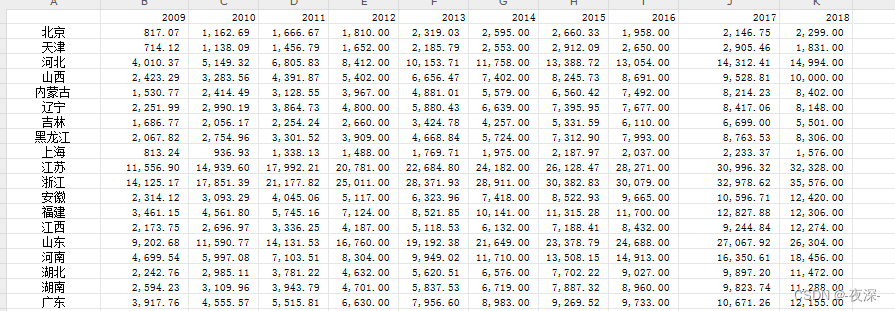
2009-2018年各省涉农贷款数据(wind)
2009-2018年各省涉农贷款数据(wind) 1、时间::209-2018年 2、范围:31省 3、来源:wind 4、指标:涉农贷款 指标解释 :在涉农贷款的分类上,按照城乡地域将涉农贷款分为农村贷款和城…...
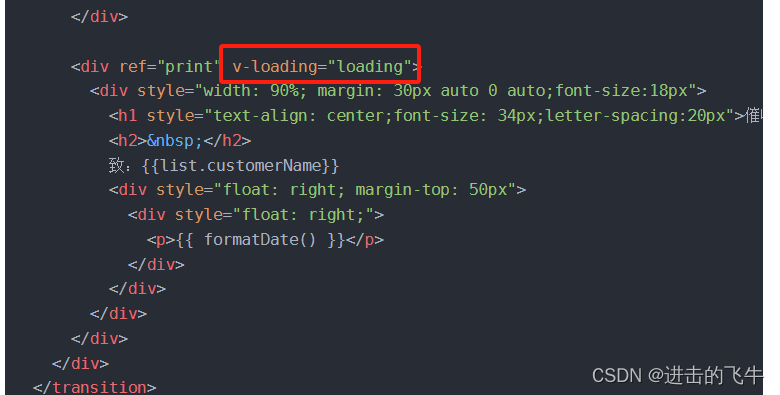
window.print()打印及出现的问题
<template><transition name"el-zoom-in-center"><div class"JNPF-preview-main"><div class"JNPF-common-page-header"><el-page-header back"goBack" :content"打印通知书" /><div clas…...

Fedora Linux 39 Beta 预估 10 月底发布正式版
Fedora 39 Beta 镜像于今天发布,用户可以根据自己的使用偏好,下载 KDE Plasma,Xfce 和 Cinnamon 等不同桌面环境版本,正式版预估将于 10 月底发布 Fedora 39 Beta 版本主要更新了 DNF 软件包管理器,并优化了 Anaconda …...

【zookeeper】基于Linux环境安装zookeeper集群
前提,需要有几台linux机器,我们可以准备好诸如finalshell来连接linux并且上传文件; 其次Linux需要安装上ssh,并且在/etc/hosts文件中写好其他几台机器的名字和Ip 127.0.0.1 localhost localhost.localdomain localhost4 localh…...
什么是IoT数字孪生?
数字孪生是资产或系统的实时虚拟模型,它使用来自连接的物联网传感器的数据来创建数字表示。数字孪生允许您从任何地方实时监控设备、资产或流程。数字孪生用于多种目的,例如分析性能、监控问题或在实施之前运行测试。从物联网数字孪生中获得的见解使用户…...

俄罗斯四大平台速卖通、Joom、Ozon 和 UMKA中国卖家如何脱颖而出!
随着全球化的不断推进,越来越多的中国卖家将目光投向了俄罗斯这个广阔的市场。在众多的跨境电商平台中,速卖通、Joom、Ozon 和 UMKA 无疑是最受关注的四个平台。本文将从卖家的角度,详细分析这四大平台的特点和优势,帮助找到最…...

OpenUsage:一站式AI订阅用量监控工具的设计与实战
1. 项目概述:为什么我们需要一个AI订阅用量监控器? 如果你和我一样,是个重度依赖AI编程工具的开发者,那你肯定对下面这个场景不陌生:为了搞清楚自己这个月还剩多少Claude的会话额度,得先打开浏览器&#x…...

黑苹果WiFi避坑实录:AX201网卡+OC引导的驱动安装与日常使用体验
黑苹果WiFi深度优化:AX201网卡在OC引导下的实战经验与长期使用报告 1. 为什么选择AX201网卡:不拆机的妥协与智慧 在小新Pro13这类紧凑型笔记本上折腾黑苹果,网卡选择往往是第一个拦路虎。AX201作为Intel的WiFi6解决方案,在Windows…...

解锁MapleStory游戏资源编辑的终极指南:Harepacker-resurrected深度解析
解锁MapleStory游戏资源编辑的终极指南:Harepacker-resurrected深度解析 【免费下载链接】Harepacker-resurrected All in one .wz file/map editor for MapleStory game files 项目地址: https://gitcode.com/gh_mirrors/ha/Harepacker-resurrected 你是否曾…...
的研究进展与生物学功能)
白细胞介素(Interleukins, ILs)的研究进展与生物学功能
白细胞介素(Interleukins, ILs)是一类由白细胞产生并参与细胞间信号传导的细胞因子,自1979年命名以来,已成为免疫学研究的核心领域。目前已发现至少38种白细胞介素,其作为小分子多肽或糖蛋白,通过调控免疫细…...

STM32 IAP方案怎么选?内置DFU vs 自写Bootloader,从F1到F4系列实战对比
STM32 IAP方案深度对比:从芯片选型到实战落地 当产品需要支持远程固件更新时,工程师们往往面临一个关键抉择:是采用ST官方内置的DFU方案,还是自行开发Bootloader?这个看似简单的选择背后,实则牵涉到芯片选型…...

解锁加密压缩包的终极武器:ArchivePasswordTestTool密码恢复方案全解析
解锁加密压缩包的终极武器:ArchivePasswordTestTool密码恢复方案全解析 【免费下载链接】ArchivePasswordTestTool 利用7zip测试压缩包的功能 对加密压缩包进行自动化测试密码 项目地址: https://gitcode.com/gh_mirrors/ar/ArchivePasswordTestTool 你是否曾…...

从开源技能库到精英能力体系:构建个人技术护城河的实践指南
1. 项目概述:从开源技能库到个人能力体系的构建最近在GitHub上看到一个挺有意思的项目,叫“openclaw-elite-skills”。初看这个标题,你可能会有点摸不着头脑——“openclaw”是什么?“精英技能”又指什么?但作为一个长…...

Windows 一键部署 OpenClaw 教程|5 分钟搭建本地 AI 智能体,轻松搞定复杂配置
OpenClaw 2.7.1 接入阿里云百炼超详细图文教程 📋 前置准备 本地已安装并能正常运行 OpenClaw 2.7.1 WindowsOpenClaw 顶部 Gateway 保持在线状态拥有可正常登录的阿里云账号网络可正常访问阿里云百炼控制台: https://bailian.console.aliyun.com/cn-be…...

物联网隐私工程:从数据生命周期到安全设计实践
1. 物联网隐私困境:一个被误解的工程问题每次和同行聊起物联网项目,大家最头疼的往往是协议选型、功耗优化或者成本控制。至于隐私?那通常是产品经理或者法务部门在项目后期才想起来要填的“合规表格”。我自己在早期做智能家居网关时也犯过同…...

魔兽争霸III终极优化指南:WarcraftHelper让你的游戏体验焕然一新
魔兽争霸III终极优化指南:WarcraftHelper让你的游戏体验焕然一新 【免费下载链接】WarcraftHelper Warcraft III Helper , support 1.20e, 1.24e, 1.26a, 1.27a, 1.27b 项目地址: https://gitcode.com/gh_mirrors/wa/WarcraftHelper WarcraftHelper是一款专为…...