Hadoop-2.5.2平台环境搭建遇到的问题
文章目录
- 一、集群环境
- 二、MySQL
- 2.1 MySQL初始化失败
- 2.2 MySQL启动报错
- 2.3 启动时报不能打开日志错
- 2.4 mysql启动时pid报错
- 二、Hive
- 2.1 mr shuffle不存在
- 2.1.2 查看yarn任务:
- 2.1.3 问题描述:
- 2.1.4 参考文档
一、集群环境
java-1.8.0-openjdk-1.8.0.181-7.b13.el7
hadoop-2.5.2
spark-2.3.3
hbase-1.3.1
hbase-2.1.0
zookeeper-3.5.5-bin
janusgraph-0.2.0-hadoop2-gremlin
mysql-5.7.27
hive-2.1.1
这两天我配置了mysql和hive,本文记录遇到的问题。
二、MySQL
使用了arm架构下的mysql.tar.gz离线安装。
参考文章:ARM架构部署mysql-5.7.27
文章内容:
cd /usr/local将部署包:mysql-5.7.27-aarch64.tar.gz 上传到 /usr/local 下tar xvf mysql-5.7.27-aarch64.tar.gzmv /usr/local/mysql-5.7.27-aarch64 /usr/local/mysqlmkdir -p /usr/local/mysql/logsln -sf /usr/local/mysql/my.cnf /etc/my.cnfcp -rf /usr/local/mysql/extra/lib* /usr/lib64/mv /usr/lib64/libstdc++.so.6 /usr/lib64/libstdc++.so.6.oldln -s /usr/lib64/libstdc++.so.6.0.24 /usr/lib64/libstdc++.so.6groupadd mysqluseradd -g mysql mysqlchown -R mysql:mysql /usr/local/mysqlcp -rf /usr/local/mysql/support-files/mysql.server /etc/init.d/mysqldchmod +x /etc/init.d/mysqldsystemctl enable mysqldvim /etc/profileexport MYSQL_HOME=/usr/local/mysqlexport PATH=$PATH:$MYSQL_HOME/binsource /etc/profilemysqld --initialize-insecure --user=mysql --basedir=/usr/local/mysql --datadir=/usr/local/mysql/datasystemctl start mysqldsystemctl status mysqld移动文件 mv /usr/local/mysql-5.7.27-aarch64 /usr/local/mysql创建logs目录 mkdir -p /usr/local/mysql/logsln -sf a b 建立软连接,b指向a:ln -sf /usr/local/mysql/my.cnf /etc/my.cnfcp是linux里的拷贝命令-r 是用于目录拷贝时的递归操作-f 是强制覆盖:cp -rf /usr/local/mysql/extra/lib* /usr/lib64/创建mysql组:ln -s /usr/lib64/libstdc++.so.6.0.24 /usr/lib64/libstdc++.so.6创建mysql用户添加到mysql组:groupadd mysql && useradd -g mysql mysql将/usr/loca/mysql目录包含所有的子目录和文件,所有者改变为root,所属组改变为mysql:chown -R mysql:mysql /usr/local/mysql设置开机启动:cp -rf /usr/local/mysql/support-files/mysql.server /etc/init.d/mysqldchmod +x /etc/init.d/mysqldsystemctl enable mysqld添加环境变量:vim /etc/profileexport MYSQL_HOME=/usr/local/mysqlexport PATH=PATH:PATH:PATH:MYSQL_HOME/binsource /etc/profile初始化mysql:mysqld --initialize-insecure --user=mysql --basedir=/usr/local/mysql --datadir=/usr/local/mysql/data开启mysql:systemctl start mysqld查看状态:systemctl status mysqld
2.1 MySQL初始化失败
重点检查my.cnf文件,所有目录的创建,权限,初始化命令参数。
关于my.cnf的详细介绍参考:MySQL 配置文件 my.cnf / my.ini 逐行解析
原文内容:
MySQL 配置文件详解
文件位置: Windows、Linux、Mac 有细微区别,Windows 配置文件是 .ini,Mac/linux 是 .cnf[Windows]
MySQL\MySQL Server 5.7\my.ini[Linux / Mac]
/etc/my.cnf
/etc/mysql/my.cnf
当然我们也可以使用命令来查看 MySQL 默认配置文件位置mysql --help|grep 'cnf'[client]
客户端设置。当前为客户端默认参数port = 3306
默认连接端口为 3306socket = /tmp/mysql.sock
本地连接的 socket 套接字default_character_set = utf8
设置字符集,通常使用 uft8 即可[mysqld_safe]
mysqld_safe 是服务器端工具,用于启动 mysqld,也是 mysqld 的守护进程。当 mysql 被 kill 时,mysqld_safe 负责重启启动它。open_files_limit = 8192
此为 MySQL 打开的文件描述符限制,它是 MySQL 中的一个全局变量且不可动态修改。它控制着 mysqld 进程能使用的最大文件描述符数量。默认最小值为 1024需要注意的是这个变量的值并不一定是你在这里设置的值,mysqld 会在系统允许的情况下尽量取最大值。当 open_files_limit 没有被配置时,比较 max_connections*5 和 ulimit -n 的值,取最大值当 open_file_limit 被配置时,比较 open_files_limit 和 max_connections*5 的值,取最大值user = mysql
用户名log-error = error.log
错误 log 记录文件[mysqld]
服务端基本配置port = 3306
mysqld 服务端监听端口socket = /tmp/mysql.sock
MySQL 客户端程序和服务器之间的本地通讯指定一个套接字文件max_allowed_packet = 16M
允许最大接收数据包的大小,防止服务器发送过大的数据包。当发出长查询或 mysqld 返回较大结果时,mysqld 才会分配内存,所以增大这个值风险不大,默认 16M,也可以根据需求改大,但太大会有溢出风险。取较小值是一种安全措施,避免偶然出现但大数据包导致内存溢出。default_storage_engine = InnoDB
创建数据表时,默认使用的存储引擎。这个变量还可以通过 –default-table-type 进行设置max_connections = 512
最大连接数,当前服务器允许多少并发连接。默认为 100,一般设置为小于 1000 即可。太高会导致内存占用过多,MySQL 服务器会卡死。作为参考,小型站设置 100 - 300max_user_connections = 50
用户最大的连接数,默认值为 50 一般使用默认即可。thread_cache_size = 64
线程缓存,用于缓存空闲的线程。这个数表示可重新使用保存在缓存中的线程数,当对方断开连接时,如果缓存还有空间,那么客户端的线程就会被放到缓存中,以便提高系统性能。我们可根据物理内存来对这个值进行设置,对应规则 1G 为 8;2G 为 16;3G 为 32;4G 为 64 等。Query Cache
query_cache_type = 1
设置为 0 时,则禁用查询缓存(尽管仍分配query_cache_size个字节的缓冲区)。
设置为 1 时 ,除非指定SQL_NO_CACHE,否则所有SELECT查询都将被缓存。
设置为 2 时,则仅缓存带有SQL CACHE子句的查询。
请注意,如果在禁用查询缓存的情况下启动服务器,则无法在运行时启用服务器。query_cache_size = 64M
缓存select语句和结果集大小的参数。查询缓存会存储一个select查询的文本与被传送到客户端的相应结果。如果之后接收到一个相同的查询,服务器会从查询缓存中检索结果,而不是再次分析和执行这个同样的查询。如果你的环境中写操作很少,读操作频繁,那么打开query_cache_type=1,会对性能有明显提升。如果写操作频繁,则应该关闭它(query_cache_type=0)。Session variables sort_buffer_size = 2M
MySQL 执行排序时,使用的缓存大小。增大这个缓存,提高 group by,order by 的执行速度。tmp_table_size = 32M
HEAP 临时数据表的最大长度,超过这个长度的临时数据表 MySQL 可根据需求自动将基于内存的 HEAP 临时表改为基于硬盘的 MyISAM 表。我们可通过调整 tmp_table_size 的参数达到提高连接查询速度的效果。read_buffer_size = 128k
MySQL 读入缓存的大小。如果对表对顺序请求比较频繁对话,可通过增加该变量值以提高性能。read_rnd_buffer_size = 256k
用于表的随机读取,读取时每个线程分配的缓存区大小。默认为 256k ,一般在 128 - 256k之间。在做 order by 排序操作时,会用到 read_rnd_buffer_size 空间来暂做缓冲空间。join_buffer_size = 128k
程序中经常会出现一些两表或多表 Join (联表查询)的操作。为了减少参与 Join 连表的读取次数以提高性能,需要用到 Join Buffer 来协助 Join 完成操作。当 Join Buffer 太小时,MySQL 不会将它写入磁盘文件。和 sort_buffer_size 一样,此参数的内存分配也是每个连接独享。table_definition_cache = 400
限制不使用文件描述符存储在缓存中的表定义的数量。table_open_cache = 400
限制为所有线程在内存中打开的表数量。MySQL 错误日志设置
log_error = error.log log_warnings = 2
log_warnings 为0, 表示不记录告警信息。
log_warnings 为1, 表示告警信息写入错误日志。
log_warnings 大于1, 表示各类告警信息,例如有关网络故障的信息和重新连接信息写入错误日志。
慢查询记录
slow_query_log_file = slow.log slow_query_log = 0 log_queries_not_using_indexes = 1 long_query_time = 0.5 min_examined_row_limit = 100
slow_query_log :全局开启慢查询功能。
slow_query_log_file :指定慢查询日志存储文件的地址和文件名。
log_queries_not_using_indexes:无论是否超时,未被索引的记录也会记录下来。
long_query_time:慢查询阈值(秒),SQL 执行超过这个阈值将被记录在日志中。
min_examined_row_limit:慢查询仅记录扫描行数大于此参数的 SQL。
2.2 MySQL启动报错
报错内容:
Job for mysqld.service failed because the control process exited with error code. See “systemctl status mysqld.service” and “journalctl -xe” for details.
解决思路:
mysqld.pid目录权限问题,请把我们组群mysql:mysql给到权限,这个组群是我们安装mysql时创建的。
参考文章:
[1]:关于Job for mysqld.service failed because the control process exited with error code报错解决办法
[2]:启动mysql报错Job for mysqld.service failed because the control process exited with error code.
2.3 启动时报不能打开日志错
报错内容:
ERROR Could not open file ‘***/log/mysql/error.log‘ for error logging: Permission denied
**错误原因:**日志文件夹的权限问题,请重点用chmod检查权限是否够组群用户使用。
参考文档:
[1]:centos系统中MySQL无法启动的问题
[2]:Docker中mysql启动错误Could not open file ‘/var/log/mysqld.log‘ for error logging: Permission denied
2.4 mysql启动时pid报错
报错内容:
Starting MySQL... ERROR The server quit without updating PID file
参考文档:
启动mysql服务时一直提示ERROR The server quit without updating PID file
该文章分析了启动mysql的几个服务脚本源码,非常详细,介绍了用户权限对mysql初始化的影响以及pid文件在此的作用,包括mycnf的配置目录描述。再次重启时可以使用mysql.service或者mysqld_safe来启动mysql。
二、Hive
2.1 mr shuffle不存在
### 2.1.1 报错信息:org.apache.hadoop.yarn.exceptions.InvalidAuxServiceException: The auxService:mapreduce_shuffle does not exist
以下报错日志是我在我的个人集群中更改配置后复现的报错结果,其中运行了mapreduce官方案例的wordcount和pi:
[root@hadoop11 data]# hadoop jar /opt/installs/hadoop3.1.4/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.4.jar wordcount /wc.txt /out3
2023-10-09 15:42:20,213 INFO mapreduce.JobResourceUploader: Disabling Erasure Coding for path: /tmp/hadoop-yarn/staging/root/.staging/job_1696837267350_0001
2023-10-09 15:42:20,536 INFO input.FileInputFormat: Total input files to process : 1
2023-10-09 15:42:20,684 INFO mapreduce.JobSubmitter: number of splits:1
2023-10-09 15:42:20,955 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1696837267350_0001
2023-10-09 15:42:20,959 INFO mapreduce.JobSubmitter: Executing with tokens: []
2023-10-09 15:42:21,212 INFO conf.Configuration: resource-types.xml not found
2023-10-09 15:42:21,213 INFO resource.ResourceUtils: Unable to find 'resource-types.xml'.
2023-10-09 15:42:21,620 INFO impl.YarnClientImpl: Submitted application application_1696837267350_0001
2023-10-09 15:42:21,743 INFO mapreduce.Job: The url to track the job: http://hadoop13:8088/proxy/application_1696837267350_0001/
2023-10-09 15:42:21,745 INFO mapreduce.Job: Running job: job_1696837267350_0001
2023-10-09 15:42:30,000 INFO mapreduce.Job: Job job_1696837267350_0001 running in uber mode : false
2023-10-09 15:42:30,002 INFO mapreduce.Job: map 0% reduce 0%
2023-10-09 15:42:32,053 INFO mapreduce.Job: Task Id : attempt_1696837267350_0001_m_000000_0, Status : FAILED
Container launch failed for container_e50_1696837267350_0001_01_000002 : org.apache.hadoop.yarn.exceptions.InvalidAuxServiceException: The auxService:mapreduce_shuffle does not existat sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method)at sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:62)at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45)at java.lang.reflect.Constructor.newInstance(Constructor.java:423)at org.apache.hadoop.yarn.api.records.impl.pb.SerializedExceptionPBImpl.instantiateExceptionImpl(SerializedExceptionPBImpl.java:171)at org.apache.hadoop.yarn.api.records.impl.pb.SerializedExceptionPBImpl.instantiateException(SerializedExceptionPBImpl.java:182)at org.apache.hadoop.yarn.api.records.impl.pb.SerializedExceptionPBImpl.deSerialize(SerializedExceptionPBImpl.java:106)at org.apache.hadoop.mapreduce.v2.app.launcher.ContainerLauncherImpl$Container.launch(ContainerLauncherImpl.java:163)at org.apache.hadoop.mapreduce.v2.app.launcher.ContainerLauncherImpl$EventProcessor.run(ContainerLauncherImpl.java:394)at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)at java.lang.Thread.run(Thread.java:748)2023-10-09 15:42:33,087 INFO mapreduce.Job: Task Id : attempt_1696837267350_0001_m_000000_1, Status : FAILED
Container launch failed for container_e50_1696837267350_0001_01_000003 : org.apache.hadoop.yarn.exceptions.InvalidAuxServiceException: The auxService:mapreduce_shuffle does not existat sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method)at sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:62)at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45)at java.lang.reflect.Constructor.newInstance(Constructor.java:423)at org.apache.hadoop.yarn.api.records.impl.pb.SerializedExceptionPBImpl.instantiateExceptionImpl(SerializedExceptionPBImpl.java:171)at org.apache.hadoop.yarn.api.records.impl.pb.SerializedExceptionPBImpl.instantiateException(SerializedExceptionPBImpl.java:182)at org.apache.hadoop.yarn.api.records.impl.pb.SerializedExceptionPBImpl.deSerialize(SerializedExceptionPBImpl.java:106)at org.apache.hadoop.mapreduce.v2.app.launcher.ContainerLauncherImpl$Container.launch(ContainerLauncherImpl.java:163)at org.apache.hadoop.mapreduce.v2.app.launcher.ContainerLauncherImpl$EventProcessor.run(ContainerLauncherImpl.java:394)at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)at java.lang.Thread.run(Thread.java:748)2023-10-09 15:42:35,113 INFO mapreduce.Job: Task Id : attempt_1696837267350_0001_m_000000_2, Status : FAILED
Container launch failed for container_e50_1696837267350_0001_01_000004 : org.apache.hadoop.yarn.exceptions.InvalidAuxServiceException: The auxService:mapreduce_shuffle does not existat sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method)at sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:62)at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45)at java.lang.reflect.Constructor.newInstance(Constructor.java:423)at org.apache.hadoop.yarn.api.records.impl.pb.SerializedExceptionPBImpl.instantiateExceptionImpl(SerializedExceptionPBImpl.java:171)at org.apache.hadoop.yarn.api.records.impl.pb.SerializedExceptionPBImpl.instantiateException(SerializedExceptionPBImpl.java:182)at org.apache.hadoop.yarn.api.records.impl.pb.SerializedExceptionPBImpl.deSerialize(SerializedExceptionPBImpl.java:106)at org.apache.hadoop.mapreduce.v2.app.launcher.ContainerLauncherImpl$Container.launch(ContainerLauncherImpl.java:163)at org.apache.hadoop.mapreduce.v2.app.launcher.ContainerLauncherImpl$EventProcessor.run(ContainerLauncherImpl.java:394)at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)at java.lang.Thread.run(Thread.java:748)2023-10-09 15:42:38,147 INFO mapreduce.Job: map 100% reduce 100%
2023-10-09 15:42:39,167 INFO mapreduce.Job: Job job_1696837267350_0001 failed with state FAILED due to: Task failed task_1696837267350_0001_m_000000
Job failed as tasks failed. failedMaps:1 failedReduces:0 killedMaps:0 killedReduces: 02023-10-09 15:42:39,245 INFO mapreduce.Job: Counters: 10Job CountersFailed map tasks=4Killed reduce tasks=1Launched map tasks=4Other local map tasks=3Data-local map tasks=1Total time spent by all maps in occupied slots (ms)=5Total time spent by all reduces in occupied slots (ms)=0Total time spent by all map tasks (ms)=5Total vcore-milliseconds taken by all map tasks=5Total megabyte-milliseconds taken by all map tasks=5120
[root@hadoop11 data]#[root@hadoop11 data]# hadoop jar /opt/installs/hadoop3.1.4/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.4.jar pi 1 10
Number of Maps = 1
Samples per Map = 10
Wrote input for Map #0
Starting Job
2023-10-09 15:45:28,177 INFO mapreduce.JobResourceUploader: Disabling Erasure Coding for path: /tmp/hadoop-yarn/staging/roo t/.staging/job_1696837267350_0002
2023-10-09 15:45:28,335 INFO input.FileInputFormat: Total input files to process : 1
2023-10-09 15:45:28,441 INFO mapreduce.JobSubmitter: number of splits:1
2023-10-09 15:45:28,629 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1696837267350_0002
2023-10-09 15:45:28,631 INFO mapreduce.JobSubmitter: Executing with tokens: []
2023-10-09 15:45:28,856 INFO conf.Configuration: resource-types.xml not found
2023-10-09 15:45:28,857 INFO resource.ResourceUtils: Unable to find 'resource-types.xml'.
2023-10-09 15:45:28,939 INFO impl.YarnClientImpl: Submitted application application_1696837267350_0002
2023-10-09 15:45:29,009 INFO mapreduce.Job: The url to track the job: http://hadoop13:8088/proxy/application_1696837267350_ 0002/
2023-10-09 15:45:29,011 INFO mapreduce.Job: Running job: job_1696837267350_0002
2023-10-09 15:45:36,147 INFO mapreduce.Job: Job job_1696837267350_0002 running in uber mode : false
2023-10-09 15:45:36,149 INFO mapreduce.Job: map 0% reduce 0%
2023-10-09 15:45:37,190 INFO mapreduce.Job: Task Id : attempt_1696837267350_0002_m_000000_0, Status : FAILED
Container launch failed for container_e50_1696837267350_0002_01_000002 : org.apache.hadoop.yarn.exceptions.InvalidAuxServic eException: The auxService:mapreduce_shuffle does not existat sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method)at sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:62)at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45)at java.lang.reflect.Constructor.newInstance(Constructor.java:423)at org.apache.hadoop.yarn.api.records.impl.pb.SerializedExceptionPBImpl.instantiateExceptionImpl(SerializedExceptio nPBImpl.java:171)at org.apache.hadoop.yarn.api.records.impl.pb.SerializedExceptionPBImpl.instantiateException(SerializedExceptionPBI mpl.java:182)at org.apache.hadoop.yarn.api.records.impl.pb.SerializedExceptionPBImpl.deSerialize(SerializedExceptionPBImpl.java: 106)at org.apache.hadoop.mapreduce.v2.app.launcher.ContainerLauncherImpl$Container.launch(ContainerLauncherImpl.java:16 3)at org.apache.hadoop.mapreduce.v2.app.launcher.ContainerLauncherImpl$EventProcessor.run(ContainerLauncherImpl.java: 394)at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)at java.lang.Thread.run(Thread.java:748)2023-10-09 15:45:39,235 INFO mapreduce.Job: Task Id : attempt_1696837267350_0002_m_000000_1, Status : FAILED
Container launch failed for container_e50_1696837267350_0002_01_000003 : org.apache.hadoop.yarn.exceptions.InvalidAuxServic eException: The auxService:mapreduce_shuffle does not existat sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method)at sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:62)at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45)at java.lang.reflect.Constructor.newInstance(Constructor.java:423)at org.apache.hadoop.yarn.api.records.impl.pb.SerializedExceptionPBImpl.instantiateExceptionImpl(SerializedExceptio nPBImpl.java:171)at org.apache.hadoop.yarn.api.records.impl.pb.SerializedExceptionPBImpl.instantiateException(SerializedExceptionPBI mpl.java:182)at org.apache.hadoop.yarn.api.records.impl.pb.SerializedExceptionPBImpl.deSerialize(SerializedExceptionPBImpl.java: 106)at org.apache.hadoop.mapreduce.v2.app.launcher.ContainerLauncherImpl$Container.launch(ContainerLauncherImpl.java:16 3)at org.apache.hadoop.mapreduce.v2.app.launcher.ContainerLauncherImpl$EventProcessor.run(ContainerLauncherImpl.java: 394)at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)at java.lang.Thread.run(Thread.java:748)2023-10-09 15:45:41,260 INFO mapreduce.Job: Task Id : attempt_1696837267350_0002_m_000000_2, Status : FAILED
Container launch failed for container_e50_1696837267350_0002_01_000004 : org.apache.hadoop.yarn.exceptions.InvalidAuxServic eException: The auxService:mapreduce_shuffle does not existat sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method)at sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:62)at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45)at java.lang.reflect.Constructor.newInstance(Constructor.java:423)at org.apache.hadoop.yarn.api.records.impl.pb.SerializedExceptionPBImpl.instantiateExceptionImpl(SerializedExceptio nPBImpl.java:171)at org.apache.hadoop.yarn.api.records.impl.pb.SerializedExceptionPBImpl.instantiateException(SerializedExceptionPBI mpl.java:182)at org.apache.hadoop.yarn.api.records.impl.pb.SerializedExceptionPBImpl.deSerialize(SerializedExceptionPBImpl.java: 106)at org.apache.hadoop.mapreduce.v2.app.launcher.ContainerLauncherImpl$Container.launch(ContainerLauncherImpl.java:16 3)at org.apache.hadoop.mapreduce.v2.app.launcher.ContainerLauncherImpl$EventProcessor.run(ContainerLauncherImpl.java: 394)at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)at java.lang.Thread.run(Thread.java:748)2023-10-09 15:45:44,293 INFO mapreduce.Job: map 100% reduce 100%
2023-10-09 15:45:44,307 INFO mapreduce.Job: Job job_1696837267350_0002 failed with state FAILED due to: Task failed task_16 96837267350_0002_m_000000
Job failed as tasks failed. failedMaps:1 failedReduces:0 killedMaps:0 killedReduces: 02023-10-09 15:45:44,387 INFO mapreduce.Job: Counters: 10Job CountersFailed map tasks=4Killed reduce tasks=1Launched map tasks=4Other local map tasks=3Data-local map tasks=1Total time spent by all maps in occupied slots (ms)=5Total time spent by all reduces in occupied slots (ms)=0Total time spent by all map tasks (ms)=5Total vcore-milliseconds taken by all map tasks=5Total megabyte-milliseconds taken by all map tasks=5120
Job job_1696837267350_0002 failed!
[root@hadoop11 data]#
2.1.2 查看yarn任务:
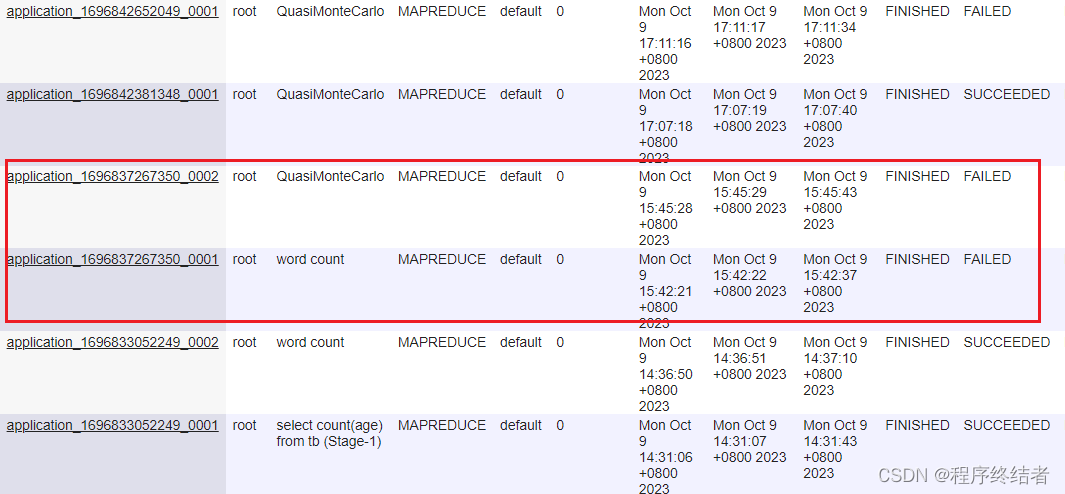
2.1.3 问题描述:
最开始发现这个mr shuffle的报错是在beeline中执行走mr的查询代码时,发现程序不走mr,经过测试发现是hadoop中yarn的mr配置原因,因为我们服务器之前装hadoop的哥们只用spark,在服务器的yarn中只有spark的成功任务,从没跑过mr。问题已经很明确,环境配置缺少。
2.1.4 参考文档
AWS EMR S3DistCp: The auxService:mapreduce_shuffle does not exist
网上有比较多的方案,这一篇的配置方法提到了spark的shuffle。
相关文章:
Hadoop-2.5.2平台环境搭建遇到的问题
文章目录 一、集群环境二、MySQL2.1 MySQL初始化失败2.2 MySQL启动报错2.3 启动时报不能打开日志错2.4 mysql启动时pid报错 二、Hive2.1 mr shuffle不存在2.1.2 查看yarn任务:2.1.3 问题描述:2.1.4 参考文档 一、集群环境 java-1.8.0-openjdk-1.8.0.181…...
基于WTMM算法的图像多重分形谱计算matlab仿真
目录 1.算法运行效果图预览 2.算法运行软件版本 3.部分核心程序 4.算法理论概述 4.1、WTMM算法概述 4.2、WTMM算法原理 4.2.1 二维小波变换 4.2.2 模极大值检测 4.2.3 多重分形谱计算 5.算法完整程序工程 1.算法运行效果图预览 2.算法运行软件版本 matlab2022a 3.部…...

VR全景展示带来旅游新体验,助力旅游业发展!
引言: VR(虚拟现实)技术正以惊人的速度改变着各行各业,在旅游业中,VR全景展示也展现了其惊人的影响力,为景区带来了全新的宣传机会和游客体验。 一.什么是VR全景展示? VR全景展示是…...
Xcode 15 编译出错问题解决
正常升级xcode 15以后发现原来没有出现报错的代码,现在出现了编译错误。(如果没有出现请忽略)下面教你如何解决这个问题。 1、pod update更新cocoapods,因为其根据xcode15做了很多的更新,保证cocoapods是最新的。 千…...
基于指数趋近律的机器人滑模轨迹跟踪控制算法及MATLAB仿真
机械手是工业制造领域中应用最广泛的自动化机械设备,广泛应用于工业制造、医疗、军工、半导体制造、太空探索等领域。它们虽然形式不同,但都有一个共同的特点,即能够接受指令,并能准确定位到三维(或二维)空间的某一点进行工作。由…...
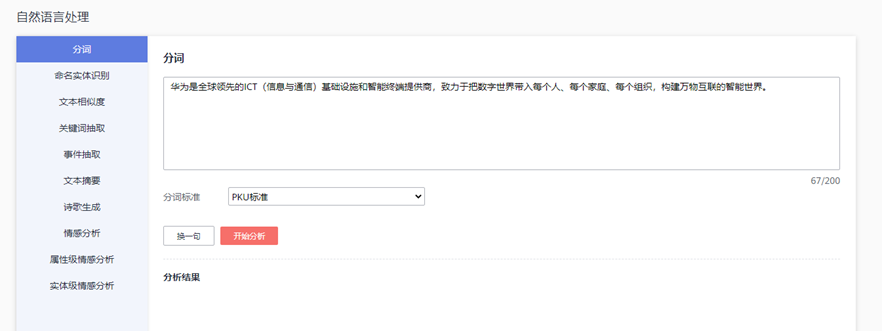
华为云API自然语言处理的魅力—AI情感分析、文本分析
云服务、API、SDK,调试,查看,我都行 阅读短文您可以学习到:人工智能AI自言语言的情感分析、文本分词、文本翻译 1 IntelliJ IDEA 之API插件介绍 API插件支持 VS Code IDE、IntelliJ IDEA等平台、以及华为云自研 CodeArts IDE&a…...

微擎小程序获取不到头像和昵称解决方案
这是一个使用微擎小程序的代码示例,其中包含了获取用户头像和昵称的功能。以下是解决方案: 首先,在<button>标签上添加open-type"chooseAvatar"属性,并绑定bindchooseavatar事件: <button class&qu…...
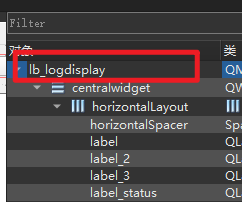
Qt 对界面类重命名的步骤
有些时候因为一些原因,需要修改Qt中创建的界面类,修改的地方比较多,一定要留意有没有修改完全,否则会出现各种奇怪报错。 比如,将MainWindow界面类名修改为lb_logdisplay 修改步骤: 修改文件名:…...
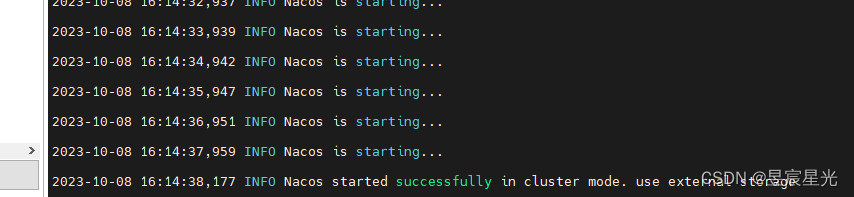
使用docker搭建nacos单机、集群 + mysql
单机搭建 1 拉取mysql镜像 docker pull mysql:5.7.40 2 启动mysql容器 docker run -d --namemysql-server -p 3306:3306 -v mysql-data:/var/lib/mysql -e MYSQL_ROOT_PASSWORD123456 mysql:5.7.40 3 执行nacos的数据库脚本 /* * Copyright 1999-2018 Alibaba Group Holding L…...
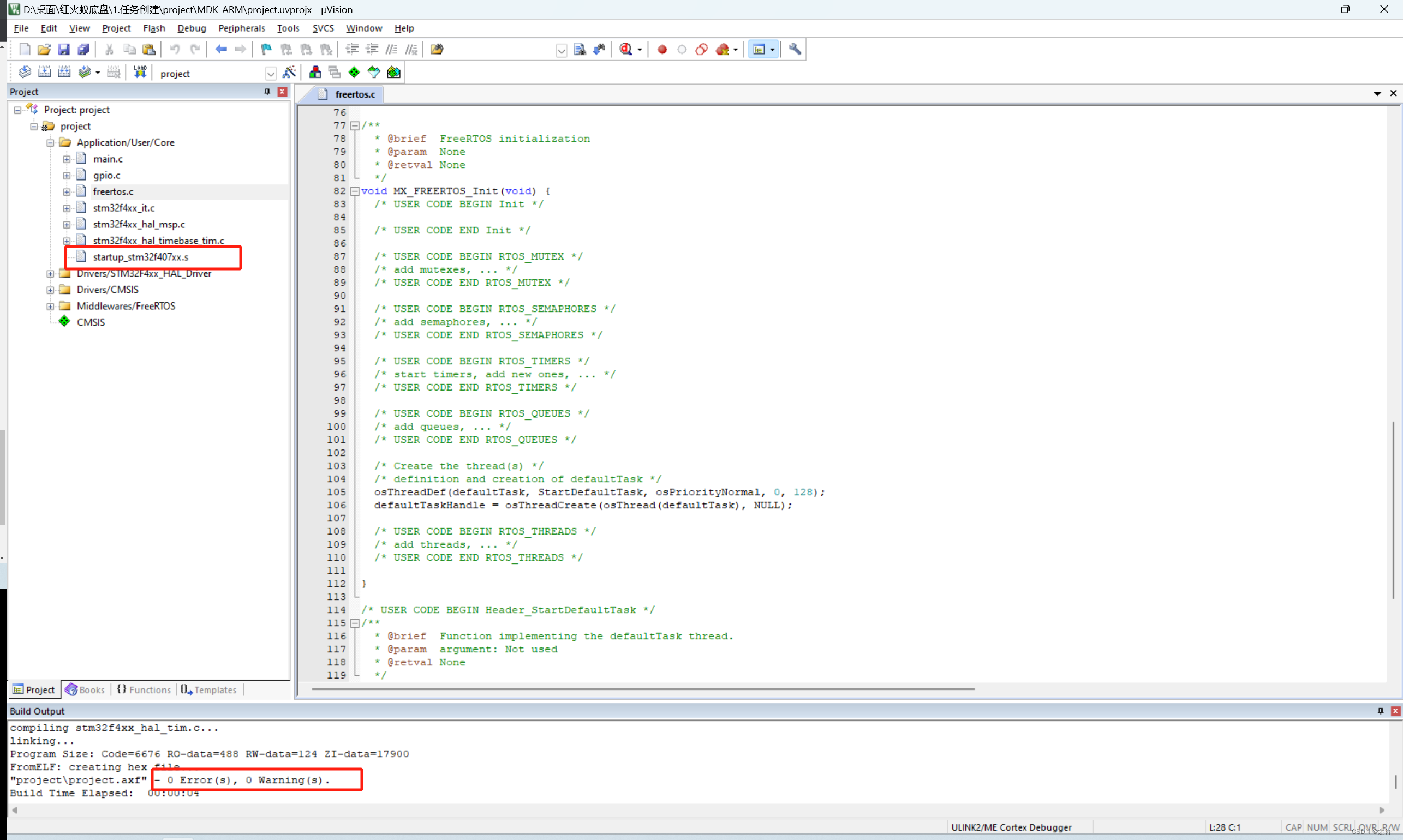
FreeRTOS自我救赎2之基本工程建立
System Core 1.System Core >SYS 2.System Core >RCC 3.System Core >NVIC Middleware Middleware >FREERTOS Clock configuration Project Manager 在编译生成的代码前需要找一个与芯片对应的启动文件,启动文件添加进来,编译就没问题了...
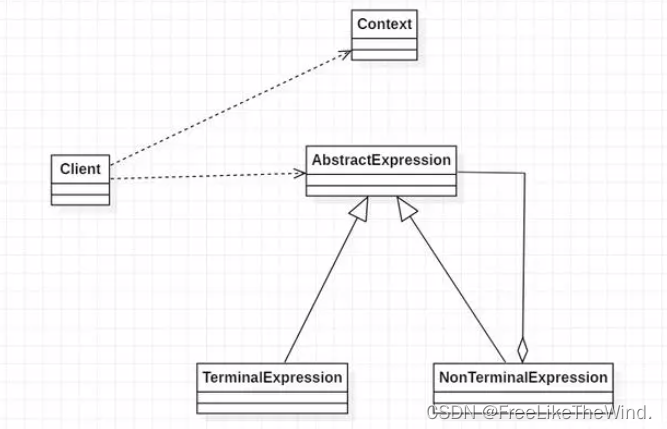
【C++设计模式之解释器模式:行为型】分析及示例
简介 解释器模式(Interpreter Pattern)是一种行为型设计模式,它提供了一种解决问题的方法,通过定义语言的文法规则,解释并执行特定的语言表达式。 解释器模式通过使用表达式和解释器,将文法规则中的句子逐…...
35 WEB漏洞-逻辑越权之找回机制及接口安全
目录 找回重置机制接口调用乱用演示案例绑定手机验证码逻辑-Rep状态值篡改-实例某APP短信轰炸接口乱用-实例接口调用发包 文章分享:https://www.cnblogs.com/zhengna/p/15655691.html 有支付接口、短信发送接口,邮箱的发送接口等等,在接口这…...

黑豹程序员-架构师学习路线图-百科:JSON替代XML
文章目录 1、数据交换之王2、XML的起源3、JSON诞生4、什么是JSON 1、数据交换之王 最早多个软件之间使用txt进行信息交互,缺点:纯文本,无法了解其结构;之后使用信令,如:电话的信令(拨号、接听、…...
)
考研人考研魂——英语单词篇(20231009)
下一站,上岸 consoleconsistentconsistconstituteconstitutionconstituentconstructdistinctdistinguishdistinctionconstantconstrainfruitfulfulfillfundfunctionfrustrateevidencefundamentalevilevidentenvironmententertainmententertainenterprisemonotonousm…...
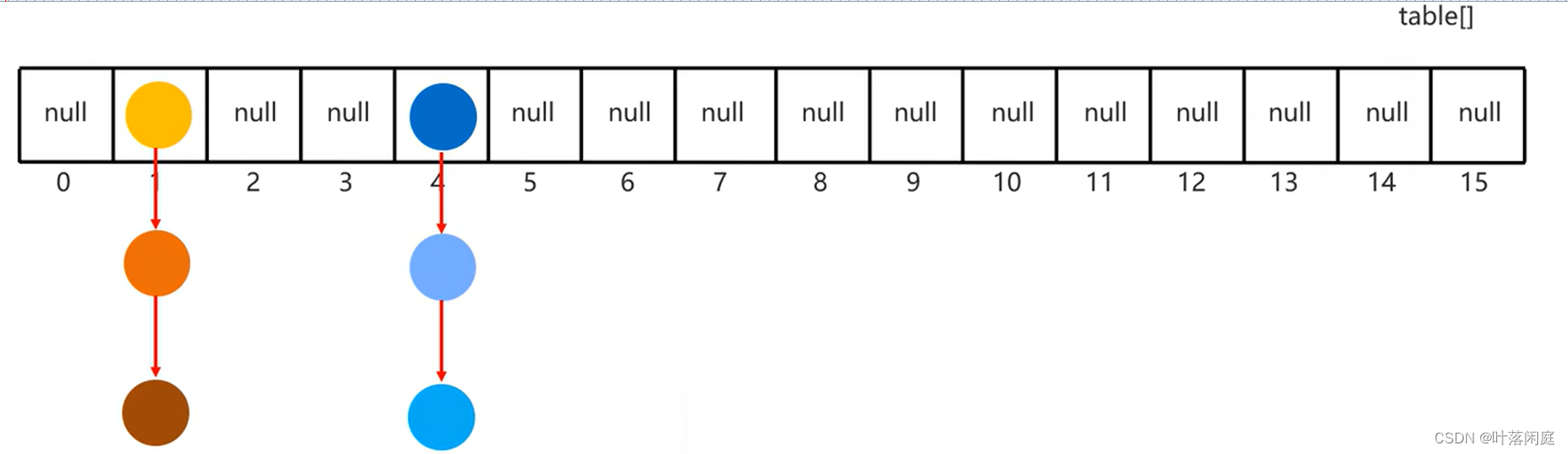
【数据结构】HashSet的底层数据结构
🐌个人主页: 🐌 叶落闲庭 💨我的专栏:💨 c语言 数据结构 javaEE 操作系统 Redis 石可破也,而不可夺坚;丹可磨也,而不可夺赤。 HashSet 一、 HashSet 集合的底层数据结构二…...
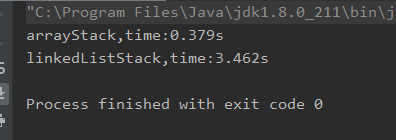
数据结构与算法(七)--使用链表实现栈
一、前言 之前我们已经学习了链表的所有操作及其时间复杂度分析,我们可以了解到对于链表头的相关操作基本都是O(1)的,例如链表头增加、删除元素,查询元素等等。那我们其实有一个数据结构其实可以完美利用到这些操作的特点,都是在…...

分布式事务详解
摘要 分布式事务主要包括2pc、3pc、消息事务。 2pc指两阶段提交: 第一阶段是准备阶段:所有事务参与者检查执行能力并锁定对应资源,准备完成后将状态告知协调者。第二集段是提交状态:事务参与者全部准备好后,协调者发…...

车载通信架构 —— DDS协议介绍
车载通信架构 —— DDS协议介绍 我是穿拖鞋的汉子,魔都中坚持长期主义的汽车电子工程师。 老规矩,分享一段喜欢的文字,避免自己成为高知识低文化的工程师: 屏蔽力是信息过载时代一个人的特殊竞争力,任何消耗你的人和…...

nginx根据不同的客户端设备进行转发请求——筑梦之路
这里主要介绍七层负载方式实现。 环境说明: pc端 web-1 苹果ios端 web-2 安卓Android端 web-3 负载均衡 web-lb 配置示例: pc端: server {listen 9000; #监听9000server_name pc.xxx.com;charset utf-8;location / {root /…...
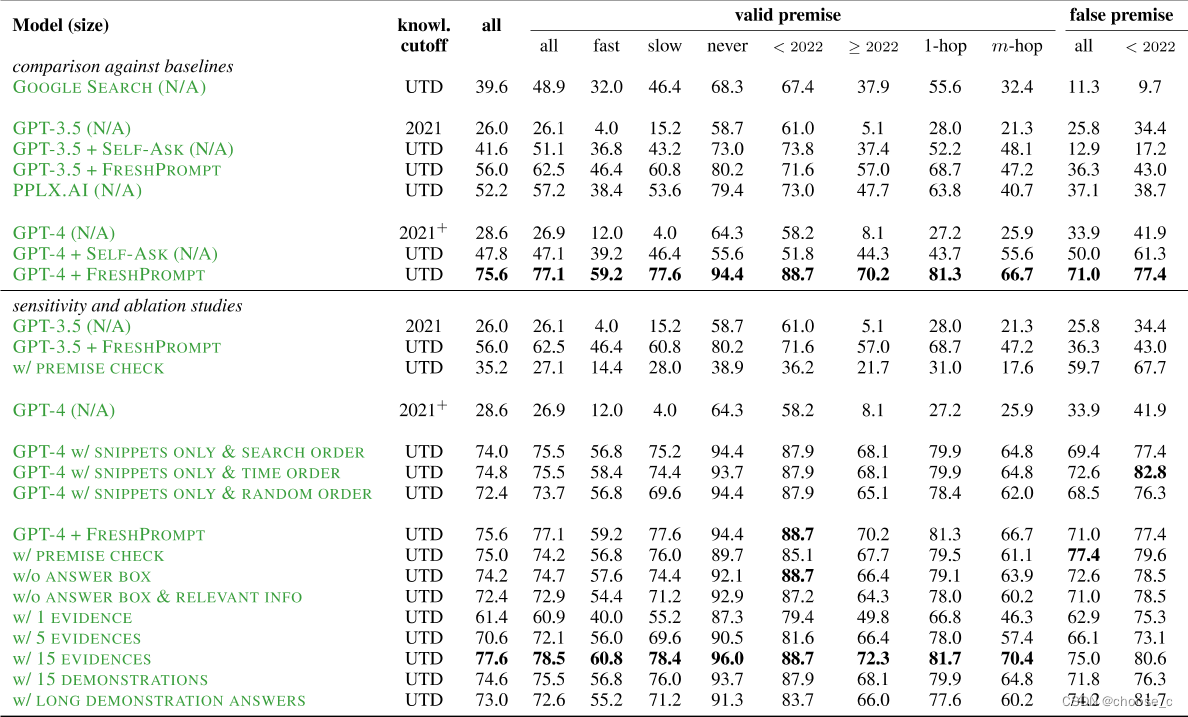
增强LLM:使用搜索引擎缓解大模型幻觉问题
论文题目:FRESHLLMS:REFRESHING LARGE LANGUAGE MODELS WITH SEARCH ENGINE AUGMENTATION 论文地址:https://arxiv.org/pdf/2310.03214.pdf 论文由Google、University of Massachusetts Amherst、OpenAI联合发布。 大部分大语言模型只会训练一次&#…...
:Agentic RAG——让 Agent 主导检索过程)
RAG 系列(十七):Agentic RAG——让 Agent 主导检索过程
Pipeline RAG 的沉默失败 前面十几篇一直在优化一件事:怎么让检索结果更好。更好的分块、更精准的排序、更聪明的问法、CRAG 纠偏、Graph RAG 关系遍历…… 但有一件事始终没变:无论检索结果好不好,都会被传给 LLM 生成答案。 Pipeline RAG 的流程是线性的、固定的: 问…...

告别showSoftInput失效:一文读懂Android 11+的WindowInsetsController输入法控制
Android输入法控制演进:从InputMethodManager到WindowInsetsController的深度解析 在移动应用开发中,输入法交互是最基础却又最容易被忽视的细节之一。许多开发者都曾遇到过这样的场景:精心设计的登录界面,光标在输入框闪烁&#…...

dotai:将AI大模型无缝集成到Shell终端的智能助手工具
1. 项目概述:当AI遇上你的终端如果你是一个重度命令行用户,每天在终端里敲击着ls、cd、git commit这些命令,有没有那么一瞬间,希望有个助手能帮你自动补全、解释命令,甚至直接帮你写出复杂的管道操作?dotai…...

零基础实操:小龙虾 AI OpenClaw 接入 Kimi 详细步骤
前置准备 获取小龙虾open claw一键安装包(www.totom.top)并安装电脑端已成功安装并正常运行OpenClaw客户端,顶部 Gateway 状态保持在线设备网络通畅,可正常访问 Kimi 开放平台拥有可正常登录的 Kimi 月之暗面 Moonshot 账号账号提…...

怎么找到一个行业的源头工厂、绕开中间商?一套五步识别流程
你下了单,货到了,质量也还行。但心里一直有个疙瘩:这家供应商到底是自己在生产,还是从别处转手赚了你一道差价? 这个问题对采购方和跨境卖家不是洁癖,是真金白银。同一款产品,源头工厂和中间商的…...

ARM Cortex-X4/X925处理器仿真模型与指令集详解
1. ARM Cortex-X4/X925处理器仿真模型概述处理器仿真模型在现代芯片设计中扮演着至关重要的角色,特别是在Arm架构的生态系统中。作为Arm最新一代高性能核心,Cortex-X4和X925的Iris仿真组件提供了完整的指令集和微架构行为建模,使开发者能够在…...

C# AI开发实战:BotSharp框架构建企业级NLP应用指南
1. 项目概述:当C#开发者遇上AI应用开发如果你是一名长期深耕.NET生态的开发者,最近看着Python在AI领域风生水起,心里是不是有点痒,又有点不甘?总觉得为了跑个模型、搭个智能对话,就得切到另一个完全不同的技…...

ARM Jazelle技术:硬件加速Java字节码执行详解
1. ARM Jazelle技术概述Jazelle技术是ARM架构中用于硬件加速Java字节码执行的关键扩展,最早出现在ARMv5TE架构中。这项技术通过在处理器内部集成Java字节码执行单元,实现了Java虚拟机(JVM)功能的硬件化。与传统的软件解释器相比,Jazelle能够将…...

Excalidraw草图AI技能:从图形解析到自动化代码生成实战
1. 项目概述:一个能“读懂”你草图的AI技能如果你经常用Excalidraw画流程图、架构图或者UI草图,那你一定遇到过这样的场景:画完一张图,想把它整理成文档,或者想基于这张图生成一些代码,又或者想让它自己动起…...

基于Stellar的智能体经济安全与效率优化框架解析
1. 项目概述:一个面向智能体经济的安全与效率优化框架最近在探索智能体(Agent)应用生态时,我遇到了一个普遍存在的痛点:如何在一个去中心化、多智能体协作的网络中,既保证交互的安全与可信,又能…...