让照片人物开口说话,SadTalker 安装及使用(避坑指南)
AI技术突飞猛进,不断的改变着人们的工作和生活。数字人直播作为新兴形式,必将成为未来趋势,具有巨大的、广阔的、惊人的市场前景。它将不断融合创新技术和跨界合作,提供更具个性化和多样化的互动体验,成为未来的一种趋势。
SadTalker介绍
西安交通大学开源了人工智能SadTaker模型,通过从音频中学习生成3D运动系数,使用全新的3D面部渲染器来生成头部运动,可以实现图片+音频就能生成高质量的视频。内含多个踩坑的解决办法,值得玩一玩。
SadTalker地址
可以根据一张图片、一段音频,合成面部说这段语音的视频。图片需要真人或者接近真人。目前项目已经支持stable diffusion webui,可以SD出图后,结合一段音频合成面部说话的视频(抖音常见的数字人)

环境准备
Anaconda介绍
Anaconda,中文大蟒蛇,是一个开源的Anaconda是专注于数据分析的Python发行版本,包含了conda、Python等190多个科学包及其依赖项。
Anaconda就是可以便捷获取包且对包能够进行管理,包括了python和很多常见的软件库和一个包管理器conda。常见的科学计算类的库都包含在里面了,使得安装比常规python安装要容易,同时对环境可以统一管理的发行版本。
下载地址:https://repo.anaconda.com/archive/
Index of /anaconda/archive/ | 清华大学开源软件镜像站 | Tsinghua Open Source Mirror
为什么要安装Anaconda?
Anaconda对于python初学者而言及其友好,相比单独安装python主程序,选择Anaconda可以帮助省去很多麻烦,Anaconda里添加了许多常用的功能包,如果单独安装python,这些功能包则需要一条一条自行安装,在Anaconda中则不需要考虑这些,同时Anaconda还附带捆绑了两个非常好用的交互式代码编辑器(Spyder、Jupyter notebook)。
总的来说,在Anaconda中conda可以理解为一个工具,也是一个可执行命令,其核心功能是包管理与环境管理。所以对虚拟环境进行创建、删除等操作需要使用conda命令。
annoconda环境安装
annoconda环境安装与使用详见:环境安装
配置镜像源
conda config --add channels https://pypi.tuna.tsinghua.edu.cn/simple
#豆瓣源
conda config --add channels http://pypi.douban.com/simple/ # 阿里源
conda config --add channels https://mirrors.aliyun.com/pypi/simple/#中科大源
conda config --add channels https://pypi.mirrors.ustc.edu.cn/simple/conda config --remove channels https://pypi.mirrors.ustc.edu.cn/simple/
conda config --remove-key channelsconda install numpy=1.19.2conda create --name myenv python=3.8
conda env list
conda activate myenv
conda deactivate
conda env remove --name myenv
注:给pip添加镜像和给conda添加镜像源是不同的,上述conda config添加的源实测不能用的(上述的是pip的镜像源,不能在conda下用),正确应该是:
给pip添加清华通道:
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple给conda添加清华通道:
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main给conda添加社区通道:
conda config --add channels conda-forgeconda的镜像源也可以直接修改.condarc 的文件,conda 应用程序的配置文件。
Windows 用户无法直接创建名为 .condarc 的文件,可先执行 conda config --set show_channel_urls yes 生成该文件之后再修改。文件的一个示例:
channels:- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main/- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/- https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/conda-forge/
ssl_verify: true
show_channel_urls: true
另附几个常用的镜像源:
# 清华源
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/conda-forge
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/msys2
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/pytorch/
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/r
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free# 中科大源
conda config --add channels https://mirrors.ustc.edu.cn/anaconda/pkgs/main/
conda config --add channels https://mirrors.ustc.edu.cn/anaconda/pkgs/free/
conda config --add channels https://mirrors.ustc.edu.cn/anaconda/cloud/conda-forge/
conda config --add channels https://mirrors.ustc.edu.cn/anaconda/cloud/msys2/
conda config --add channels https://mirrors.ustc.edu.cn/anaconda/cloud/bioconda/
conda config --add channels https://mirrors.ustc.edu.cn/anaconda/cloud/menpo/SadTalker安装
SadTalker安装倒不复杂,但是安装成功非常的不容易。所以这里给出了避坑指南。主要是依赖和需要下载的东西太多太大了,光pytouch都需要2.1G,模型文件又是几个G。
这里有个坑是:最好使用conda来安装需要的包,且指定python的版本为3.8才行。如果指定版本为3.10,最后老半天来个个别pytouch的包找不到安装失败的尴尬,又得重来一遍,很耗时。
还有需要注意的是,一定要提前设置好镜像源啊,否则几天都别想安装成功,需要下载好几个G的东西。
conda create -n sadtalker python=3.8conda activate sadtalker
网上给出的安装步骤如下:
conda create -n sadtalker python=3.8conda activate sadtalkerpip install torch==1.12.1+cu113 torchvision==0.13.1+cu113 torchaudio==0.12.1 --extra-index-url https://download.pytorch.org/whl/cu113conda install ffmpegpip install -r requirements.txt其实也可以直接执行webui.bat脚本即可,会自动的下载所有的依赖包(注:这种方式pytouch和下载的包都在venv的目录里,不支持指定下载pytorch的版本,默认的下载内容在launcher.py文件种能查看到)。
E:\test\python\SadTalker> .\webui.bat如果以上成功,仅代表环境安装ok,但是仍然是无法使用的,需要下载模型。在 sadtalker项目根目录下新建两个目录checkpoints 和gfpgan,下载好的模型分别放在这两个文件夹。模型比较大,checkpoints内的文件就有3.3G大小,gfpgan下的文件大小600M左右。不建议从github上下载,那样下载太慢了。
这里给出百度云盘地址:
- 模型checkpoints, 提取码: sadt.
- gfpgan, 提取码: sadt.
另外下载github上的资源,推荐使用镜像站点的方式下载。
这里推荐一个:GitHub Proxy 代理加速
再推荐几个快速访问和下载github资源的站点:
#通过代理网站下载
#Release、Code(ZIP) 文件加速:
https://gh.api.99988866.xyz
https://github.rc1844.workers...
https://ghgo.feizhuqwq.worker...
https://git.yumenaka.net
https://github.com.cnpmjs.org
https://mirror.ghproxy.com/
https://ghproxy.com/
https://toolwa.com/github/#Git Clone 加速:
https://github.do
https://gitclone.com
https://hub.fastgit.xyz
https://ghproxy.com
https://hub.0z.gs具体哪个速度快,请自行找一些大文件来测速。我常使用的是ghproxy.com下载github上的文件,因为名字好记,速度也不错,比百度网盘快很多。
如何使用
启动UI的方式生成
E:\test\python\SadTalker> .\webui.bat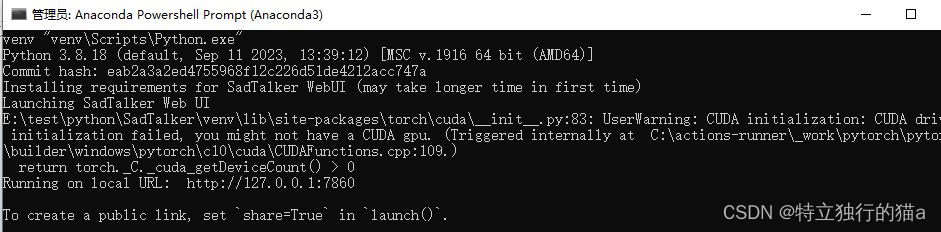
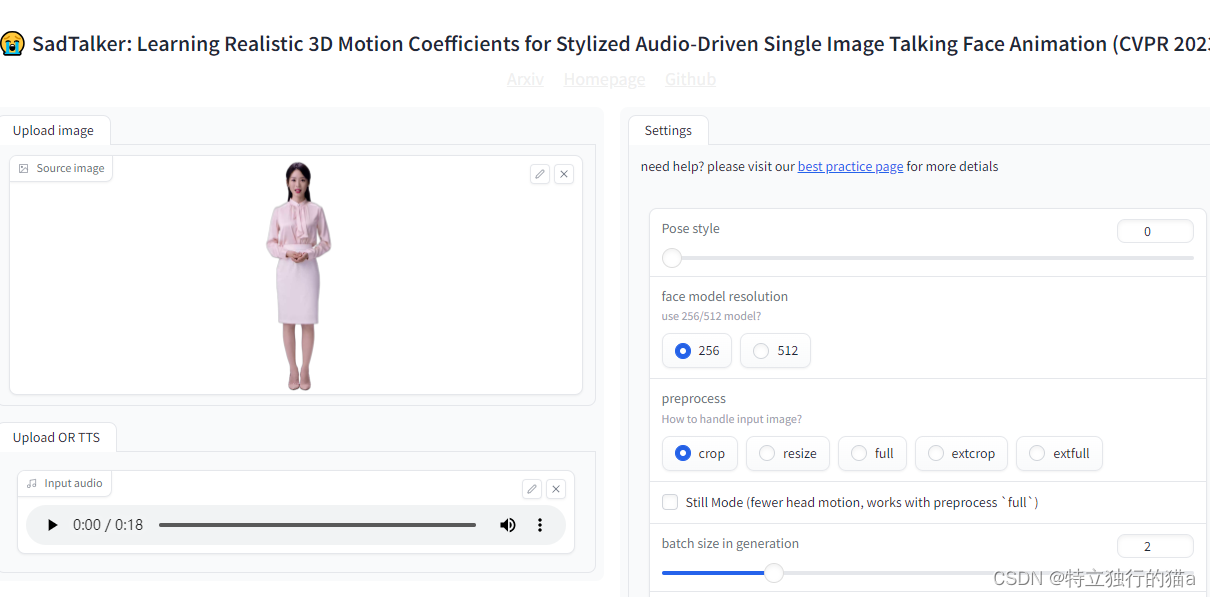
命令行方式视频生成
通过图片+语音生成视频:
python inference.py --driven_audio data/sample.wav --source_image data/sample.png通过视频片段+语音生成视频:
python inference.py --driven_audio data/sample.wav --source_image data/sample.mp4通过参数对生成的视频进行控制:
--preprocess full 表示完整图片--still 可以减少头部运动--enhancer gfpgan参数1是保留全身,如果不加这个参数,则视频中只剩头部
参数2是减少头部晃动,头部晃动是会和脖子的连接部位脱节
参数3是基于gfpgan对视频进行增强
查看webui.bat文件内容可知,如果是直接执行webui.bat,默认会把pytorch下载到SadTalker项目的venv目录下,这样如果直接执行上述命令行方式的话是不行的,会提示pytorch和其它一些未安装。如果确实需命令行下执行,可参考webui.bat文件内容,临时更改环境变量。
call .\venv\Scripts\activate.batset PYTHON="venv\Scripts\Python.exe"$PYTHON inference.py --driven_audio data/sample.wav --source_image data/sample.pngwebui.bat文件内容如下:
@echo offIF NOT EXIST venv (
python -m venv venv
) ELSE (
echo venv folder already exists, skipping creation...
)
call .\venv\Scripts\activate.batset PYTHON="venv\Scripts\Python.exe"
echo venv %PYTHON%%PYTHON% Launcher.pyecho.
echo Launch unsuccessful. Exiting.
pause最终测试效果:
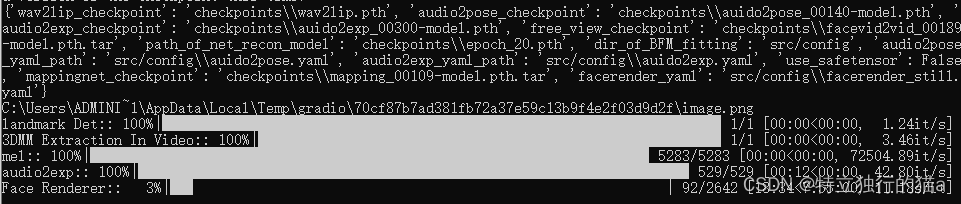
成功生成视频:

可以完美跑起来,就是生成视频的速度太慢太慢啦,要等一会儿才完成。这也跟语音文件大小有关系,平均十多秒才处理一张图片。另外一个原因,cmd窗口提示:
Launching SadTalker Web UI
E:\test\python\SadTalker\venv\lib\site-packages\torch\cuda\__init__.py:83: UserWarning: CUDA initialization: CUDA driver initialization failed, you might not have a CUDA gpu. (Triggered internally at C:\actions-runner\_work\pytorch\pytorch\builder\windows\pytorch\c10\cuda\CUDAFunctions.cpp:109.)return torch._C._cuda_getDeviceCount() > 0电脑没有安装cuda,没利用GPU的运算能力。
关于cuda
2006年,NVIDIA公司发布了CUDA(Compute Unified Device Architecture),是一种新的操作GPU计算的硬件和软件架构,是建立在NVIDIA的GPUs上的一个通用并行计算平台和编程模型,它提供了GPU编程的简易接口,基于CUDA编程可以构建基于GPU计算的应用程序,利用GPUs的并行计算引擎来更加高效地解决比较复杂的计算难题。它将GPU视作一个数据并行计算设备,而且无需把这些计算映射到图形API。操作系统的多任务机制可以同时管理CUDA访问GPU和图形程序的运行库,其计算特性支持利用CUDA直观地编写GPU核心程序。
CUDA提供了对其它编程语言的支持,如C/C++,Python,Fortran等语言。只有安装CUDA才能够进行复杂的并行计算。主流的深度学习框架也都是基于CUDA进行GPU并行加速的,几乎无一例外。还有一个叫做cudnn,是针对深度卷积神经网络的加速库。
CUDA在软件方面组成有:一个CUDA库、一个应用程序编程接口(API)及其运行库(Runtime)、两个较高级别的通用数学库,即CUFFT和CUBLAS。CUDA改进了DRAM的读写灵活性,使得GPU与CPU的机制相吻合。另一方面,CUDA提供了片上(on-chip)共享内存,使得线程之间可以共享数据。应用程序可以利用共享内存来减少DRAM的数据传送,更少的依赖DRAM的内存带宽。
cuda解决办法
首先检查显卡驱动,CUDA,cudnn,以及pytorch的版本是否匹配,如果不匹配,需要卸载之后重装对应的版本。
如何查看CUDA版本?
1.搜索栏输入cmd回车(进入cmd)
2.输入下面语句
nvidia-smi或者:
PS C:\Program Files\NVIDIA Corporation\NVSMI> .\nvidia-smi.exe能看到类似以下内容,其中就有CUDA版本信息:
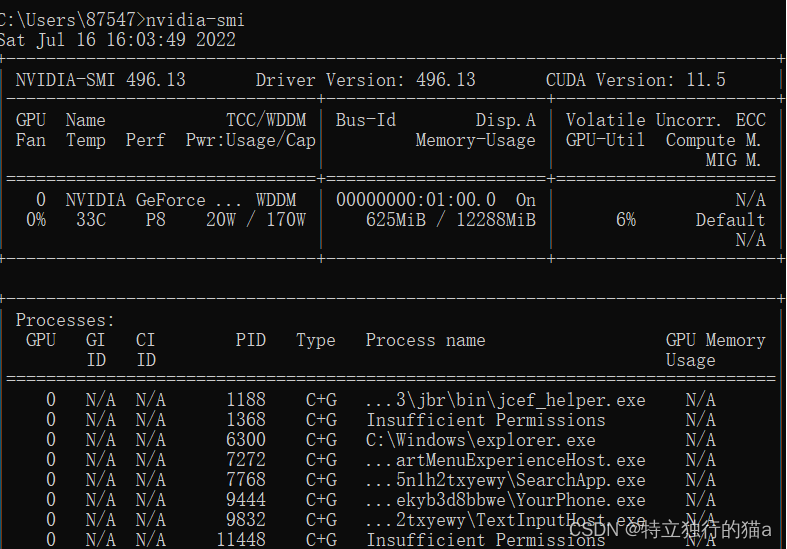
如果C盘的Program Files目录下就没有NVIDIA GPU Computing Toolkit文件夹,nvdia没有安装成功,需要安装CUDA Toolkit。
在设备管理器(此电脑–右键–属性)的显示适配器中可以查看自己的显卡型号,去官网下载对应的CUDA Toolkit 。
其他资源
还是搞不懂Anaconda是什么?读这一篇文章就够了-CSDN博客
annoconda安装使用及镜像源的添加,提高软件下载速度_conda镜像安装-CSDN博客
Anaconda安装教程(带图文)及使用、配置指南含编辑器对比 - 知乎
conda常用命令详解_conda显示所有环境-CSDN博客
annoconda安装使用及镜像源的添加,提高软件下载速度_conda镜像安装-CSDN博客
深度学习环境安装 - 知乎
Anaconda 中使用 conda 配置虚拟环境与管理安装包 - 知乎
如何判断自己的电脑里有没有cuda以及查看cuda版本_CheCacao的博客-CSDN博客
八、让照片说话之SadTalk_vandh的博客-CSDN博客
手把手教安装SadTalker教程_think_张大彪的博客-CSDN博客
stable-diffussion-webui+sd-webui-text2video+SadTalker数字人生产力工具安装配置教程(Linux Ubuntu,避坑帖)_水无月繁星的博客-CSDN博客
四元数(Quaternions)
彻底搞懂“旋转矩阵/欧拉角/四元数”,让你体会三维旋转之美_欧拉角判断动作-CSDN博客
【实战】体验SadTalker-CSDN博客
SadTalker项目上手教程_Alphathur的博客-CSDN博客
SadTalker 学习笔记-CSDN博客
SadTalker(CVPR2023)-音频驱动视频生成_‘Atlas’的博客-CSDN博客
SadTalker:Stylized Audio-Driven Single Image Talking Face Animation(CVPR2023)_c2a2o2的博客-CSDN博客
MakeItTalk:让你的人物图片或者动画动起来(学习笔记)_一名不想学习的学渣的博客-CSDN博客
MakeItTalk用一段语音让一张照片动起来-CSDN博客
faceswap换脸程序安装及使用-CSDN博客
AI数字人:换脸模型Faceswap_智慧医疗探索者的博客-CSDN博客
AI数字人:最强声音驱动面部表情模型VideoReTalking_智慧医疗探索者的博客-CSDN博客
Faceswap使用教程_face swap-CSDN博客
AI换脸软件DeepFaceLab本地安装使用教程,AI视频换脸详细步骤 - 知乎
最强的AI视频去码&图片修复模型:CodeFormer-CSDN博客
Pytorch 最全入门介绍,Pytorch入门看这一篇就够了 - 知乎
【深度学习】PyTorch基础入门(爆肝2万字)_柒筱暮的博客-CSDN博客
https://download.csdn.net/download/qq_30920479/88059273?spm=1001.2014.3001.5506
相关文章:
让照片人物开口说话,SadTalker 安装及使用(避坑指南)
AI技术突飞猛进,不断的改变着人们的工作和生活。数字人直播作为新兴形式,必将成为未来趋势,具有巨大的、广阔的、惊人的市场前景。它将不断融合创新技术和跨界合作,提供更具个性化和多样化的互动体验,成为未来的一种趋…...

系统架构设计:6 论软件质量保证及其应用
目录 一 软件质量保证SQA 1 制定SQA计划 2 参与但不负责开发项目的软件过程描述 3 评审...
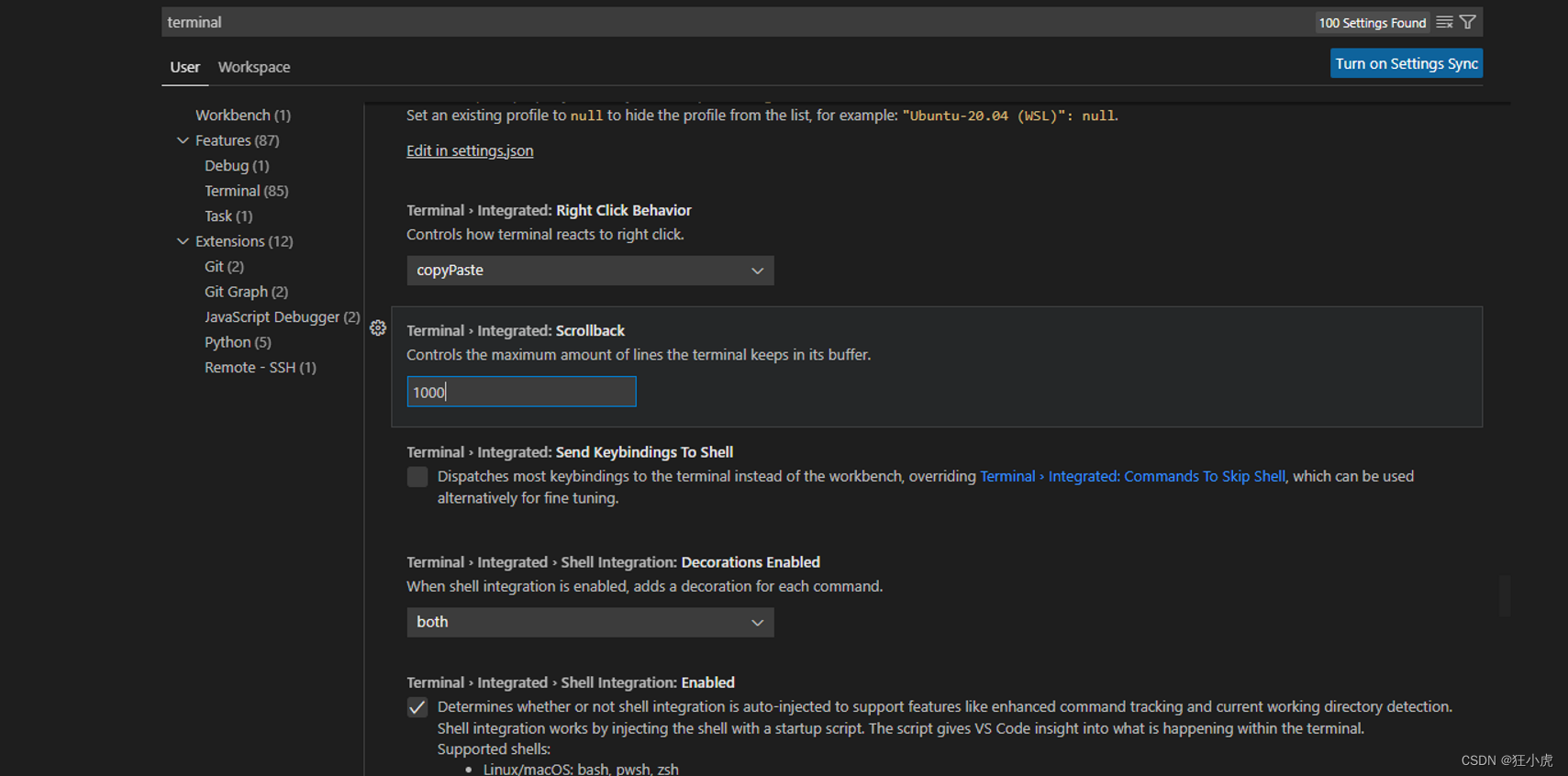
vscode的窗口下拉显示行数不够
这是为了减少程序的空间占用而存在的一个设置。设置一下即可。 设置方法 在左上角文件,个人设置,设置中,(或者用Ctrl,打开) 输入terminal,找到bell duration,设置成1000。 参考…...
)
Linux UWB Stack实现——MCPS调度接口(数据结构)
MCPS(MAC Common Part Sublayer,媒介访问控制(Medium Access Control)公共部分子层)调度接口,文件:include\net\mcps802154_schedule.h。 MCPS访问方法 // MCPS 802154 访问方法 enum mcps8021…...

2023Q3数据安全政策、法规、标准及报告汇总(附下载)
数据安全处罚事件逐年升高,2023年呈爆发式增长。 截至2023年8月31日,南都大数据研究院通过各地行政执法公示平台、媒体报道等公开渠道收集到146起依据《数据安全法》作出行政处罚决定的案例。2021年公示5起,2022年公示11起,2023年…...

Ceph入门到精通-iptables 限制多个ip 的多个端口段访问
要使用iptables限制多个IP的多个端口范围的访问,可以使用以下命令: iptables -A INPUT -p tcp -m multiport --dports 端口段 -m iprange --src-range 起始IP-结束IP -j DROP上面的命令将添加一条规则到INPUT链中,该规则将禁止指定IP范围访问…...
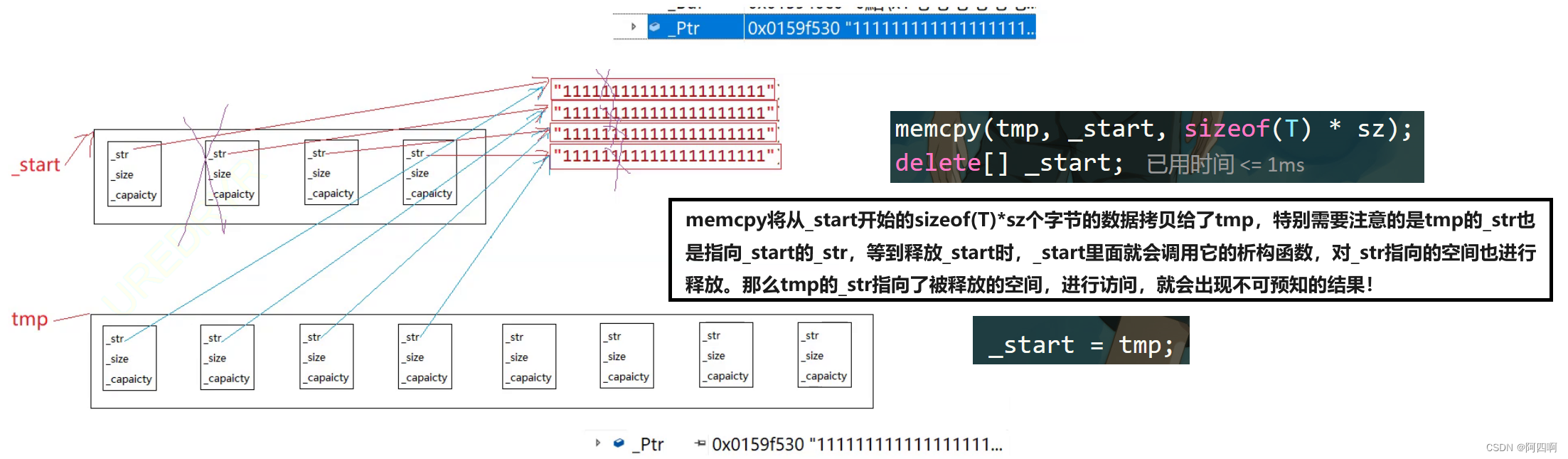
【C/C++】STL——深度剖析vector容器
👻内容专栏: C/C编程 🐨本文概括:vector的介绍与使用、深度剖析及模拟实现。 🐼本文作者: 阿四啊 🐸发布时间:2023.10.8 一、vector的介绍与使用 1. vector的介绍 像string的学习…...
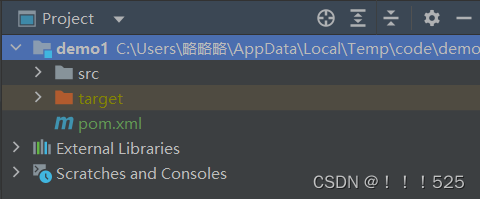
如何在idea中隐藏文件或文件夹
例如我想要隐藏如下文件 只需要点击file->settings editor->file types->ignores Files and Folders-> 然后按照图片点击顺序操作即可 添加完毕点击apply->ok 隐藏成功后效果如下:...
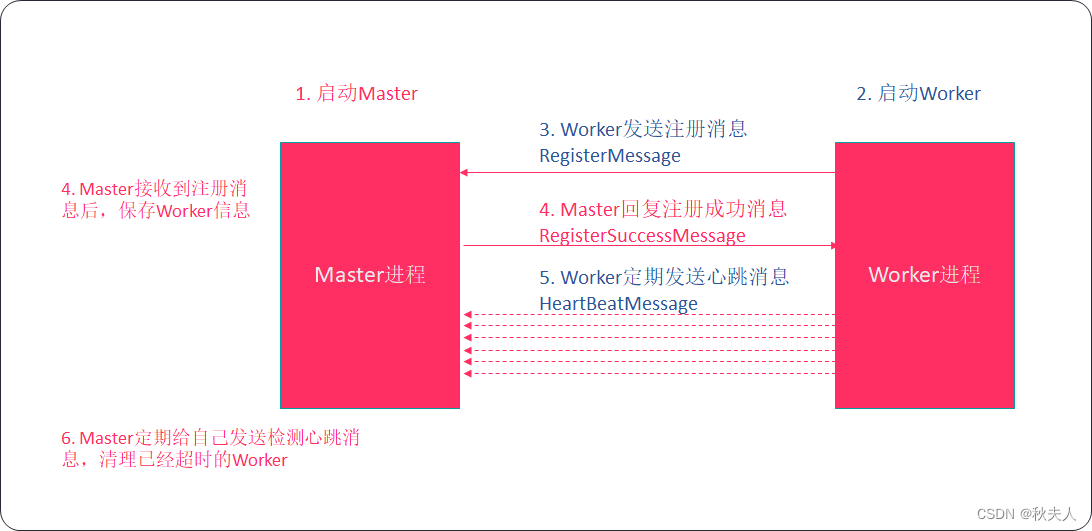
Scala第二十章节
Scala第二十章节 scala总目录 文档资料下载 章节目标 理解Akka并发编程框架简介掌握Akka入门案例掌握Akka定时任务代码实现掌握两个进程间通信的案例掌握简易版spark通信框架案例 1. Akka并发编程框架简介 1.1 Akka概述 Akka是一个用于构建高并发、分布式和可扩展的基于事…...
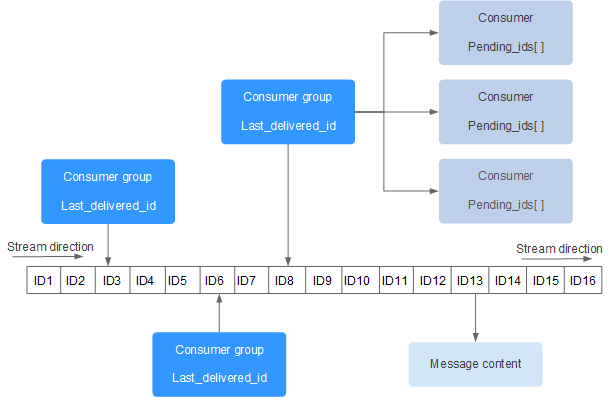
redis的持久化消息队列
Redis Stream Redis Stream 是 Redis 5.0 版本新增加的数据结构。 Redis Stream 主要用于消息队列(MQ,Message Queue),Redis 本身是有一个 Redis 发布订阅 (pub/sub) 来实现消息队列的功能,但它有个缺点就是消息无法…...

分类预测 | MATLAB实现KOA-CNN开普勒算法优化卷积神经网络数据分类预测
分类预测 | MATLAB实现KOA-CNN开普勒算法优化卷积神经网络数据分类预测 目录 分类预测 | MATLAB实现KOA-CNN开普勒算法优化卷积神经网络数据分类预测分类效果基本描述程序设计参考资料 分类效果 基本描述 1.MATLAB实现KOA-CNN开普勒算法优化卷积神经网络数据分类预测࿰…...

用 Pytorch 自己构建一个Transformer
一、说明 用pytorch自己构建一个transformer并不是难事,本篇使用pytorch随机生成五千个32位数的词向量做为源语言词表,再生成五千个32位数的词向量做为目标语言词表,让它们模拟翻译过程,transformer全部用pytorch实现,具备一定实战意义。 二、论文和概要 …...

Docker安装ActiveMQ
ActiveMQ简介 官网地址:https://activemq.apache.org/ 简介: ActiveMQ 是Apache出品,最流行的,能力强劲的开源消息总线。ActiveMQ 是一个完全支持JMS1.1和J2EE 1.4规范的 JMS Provider实现,尽管JMS规范出台已经是很久的事情了,…...
【二】spring boot-设计思想
spring boot-设计思想 简介:现在越来越多的人开始分析spring boot源码,拿到项目之后就有点无从下手了,这里介绍一下springboot源码的项目结构 一、项目结构 从上图可以看到,源码分为两个模块: spring-boot-project&a…...

系统架构设计:7 论企业集成架构设计及应用
目录 一 企业集成 1 企业集成分类:按照集成点分 (1)界面集成(表示集成)...

【pytorch】多GPU同时训练模型
文章目录 1. 基本原理单机多卡训练教程——DP模式 2. Pytorch进行单机多卡训练步骤1. 指定GPU2. 更改模型训练方式3. 更改权重保存方式 摘要:多GPU同时训练,能够解决单张GPU显存不足问题,同时加快模型训练。 1. 基本原理 单机多卡训练教程—…...
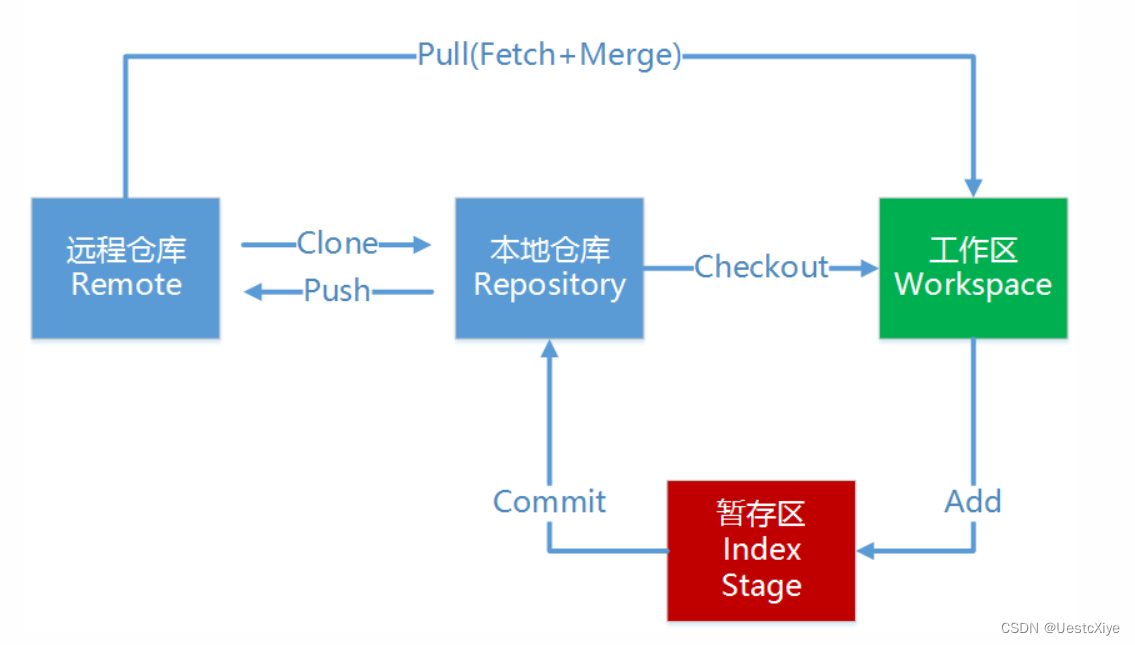
Git 学习笔记 | Git 基本理论
Git 学习笔记 | Git 基本理论 Git 学习笔记 | Git 基本理论Git 工作区域Git 工作流程 Git 学习笔记 | Git 基本理论 在开始使用 Git 创建项目前,我们先学习一下 Git 的基础理论。 Git 工作区域 Git本地有三个工作区域:工作目录(Working Di…...

滚动表格封装
滚动表格封装 我们先设定接收的参数 需要表头内容columns,表格数据data,需要currentSlides来控制当前页展示几行 const props defineProps({// 表头内容columns: {type: Array,default: () > [],required: true,},// 表格数据data: {type: Array,d…...

【LeetCode高频SQL50题-基础版】打卡第3天:第16~20题
文章目录 【LeetCode高频SQL50题-基础版】打卡第3天:第16~20题⛅前言 平均售价🔒题目🔑题解 项目员工I🔒题目🔑题解 各赛事的用户注册率🔒题目🔑题解 查询结果的质量和占比🔒题目&am…...

系统压力测试:保障系统性能与稳定的重要措施
压力测试简介 在当今数字化时代,各种系统和应用程序扮演着重要角色,从企业的核心业务系统到在线服务平台,都需要具备高性能和稳定性,以满足用户的需求。然而,随着用户数量和业务负载的增加,系统可能会面临…...

ChatGPT资源宝库:从提示工程到项目实践的完整指南
1. 项目概述:一份关于ChatGPT的“Awesome”清单意味着什么?如果你最近在GitHub上搜索过任何与ChatGPT、AI或提示工程相关的内容,那么你大概率见过一个以“awesome-”开头的仓库。而sindresorhus/awesome-chatgpt无疑是这个领域里最知名、最常…...

HS2-HF_Patch终极指南:一键为Honey Select 2安装完整增强补丁
HS2-HF_Patch终极指南:一键为Honey Select 2安装完整增强补丁 【免费下载链接】HS2-HF_Patch Automatically translate, uncensor and update HoneySelect2! 项目地址: https://gitcode.com/gh_mirrors/hs/HS2-HF_Patch HS2-HF_Patch是专为《Honey Select 2》…...

Qdrant Python客户端全解析:从向量数据库连接到AI应用开发实战
1. 项目概述:从向量数据库到客户端,现代AI应用落地的关键拼图如果你最近在折腾大语言模型应用,或者想给自己的产品加上一个“智能大脑”,那你大概率已经听过“向量数据库”这个词了。简单来说,它就像一个专门为AI模型设…...

OpenSpire:开源贡献者协作平台的设计理念与实战指南
1. 项目概述:一个面向开源贡献者的协作平台最近在和一些刚接触开源的朋友交流时,发现一个挺普遍的现象:很多人对参与开源项目充满热情,但第一步“如何找到合适的项目并上手”就卡住了。GitHub上项目浩如烟海,一个新手面…...

ncmdumpGUI:3步解决网易云音乐ncm格式播放限制的终极方案
ncmdumpGUI:3步解决网易云音乐ncm格式播放限制的终极方案 【免费下载链接】ncmdumpGUI C#版本网易云音乐ncm文件格式转换,Windows图形界面版本 项目地址: https://gitcode.com/gh_mirrors/nc/ncmdumpGUI 你是否曾经在网易云音乐下载了心爱的歌曲…...

构建通用Docker工具镜像:从设计到实践的全流程指南
1. 项目概述:一个“反重力”的Docker镜像?看到这个镜像名runzhliu/docker-antigravity,很多人的第一反应可能是好奇和疑惑。在Docker Hub上,以“antigravity”(反重力)命名的镜像并不常见,它不像…...

揭秘GPT超级提示工程:从原理到实战,打造高效AI协作指南
1. 项目概述:当“Awesome”遇见“Super Prompting”最近在GitHub上闲逛,发现了一个挺有意思的仓库,叫“CyberAlbSecOP/Awesome_GPT_Super_Prompting”。光看这名字,就透着一股“硬核”和“集大成”的味道。作为一个长期和各类大语…...

Cursor与Figma通过MCP协议实现AI辅助设计与开发同步
1. 项目概述:当代码编辑器与设计工具“开口说话”最近在开发者社区里,一个名为“cursor-talk-to-figma-mcp”的项目引起了我的注意。这个由开发者“hamadoun1760”开源的仓库,名字直译过来就是“Cursor与Figma对话的MCP”。乍一看,…...

ITK-SNAP医学图像分割:破解三维解剖结构提取的工程难题
ITK-SNAP医学图像分割:破解三维解剖结构提取的工程难题 【免费下载链接】itksnap ITK-SNAP medical image segmentation tool 项目地址: https://gitcode.com/gh_mirrors/it/itksnap 当我们面对复杂的脑部MRI数据、肿瘤CT扫描或心血管影像时,最大…...

开源容器镜像仓库cc-hub:从协议兼容到生产部署的完整实践指南
1. 项目概述:一个面向容器化应用的开源镜像仓库最近在整理团队内部的容器镜像管理方案时,我重新审视了开源镜像仓库这个领域。虽然市面上有 Harbor、Docker Registry 等成熟方案,但总有一些场景,比如轻量级内网部署、特定架构&…...