万万没想到,我用文心一言开发了一个儿童小玩具
最近关注到一年一度的百度世界大会今年将于10月17日在北京首钢园举办,本期大会的主题是“生成未来(PROMPT THE WORLD)”。会上,李彦宏会做主题为「手把手教你做AI原生应用」的演讲,比较期待 Robin 会怎么展示。据说,大会当天百度还会发布文心4.0版本,估计要炸一波街。

作为一名对人工智能技术深感兴趣的开发者,我相信这次大会将带来各种新颖的想法和独特的观点,激发参会者们探索AI技术更广阔应用场景的热情。也很期待从李彦宏和其他嘉宾的分享中汲取灵感并拓宽视野,进一步认识到AI技术带给我们的巨大机遇。
想法由来
文心大模型覆盖了很多AI应用场景,有NLP大模型、CV大模型、跨模态大模型等等。今年3月,百度发布了大模型服务平台文心千帆,纳入管理包括文心大模型在内的国内外主流大模型,对于除文心大模型之外的第三方大模型,千帆平台不只是简单的接入,还提供中文增强、性能增强、上下文增强等能力。比如,原来要用英文对话效果才好的 Llama2 等国外大模型,现在用中文也一样好。
看到文心提供的强大功能,感觉不做点什么都觉得对不起它。想到最近工作比较忙,没时间陪伴自己的女儿,她现在正是需要益智小游戏的年龄段,于是就有了开发一款适用于婴幼儿的【看图语音识别】小游戏的创意。
实现流程构想
- 程序弹出小动物的图片;
- 孩子发出“小动物名字”的语音;
- 程序识别语音并告知孩子是否回答正确;
- 正确则切换下一张图片,错误则告知孩子请重新作答;
小游戏应用实现流程
准备工作:SDK安装及使用流程
(1)安装SDK
pip install qianfan
这里需要注意:目前支持 Python >= 3.7版本。且调用SDK前,需确保已完成SDK安装。
(2)调用SDK(具体操作步骤)
- 步骤一,在百度千帆大模型平台创建应用,获取应用API Key(AK) 和 Secret Key(SK)。
- 步骤二,初始化AK 和 SK。
- 步骤三,调用SDK。
第一步,随机展示动物图片
我们先搜集几张不同的动物图片,然后用动物的名字来命名,将它们放在程序的固定路径下。
from PIL import Image
import os
import random# 指定图片文件夹路径
img_folder = "path/to/image/folder"# 获取图片列表
img_list = os.listdir(img_folder)# 从列表中随机选择一张图片
img_name = random.choice(img_list)# 打开并显示选中的图片
img_path = os.path.join(img_folder, img_name)
img = Image.open(img_path)
img.show()

第二步,完成图像识别
首先通过应用的API_KEY和SECRET_KEY 获取应用的 access_token。
def get_access_token():# 使用 AK,SK 生成鉴权签名(Access Token)# return: access_token,或是None(如果错误)url = "https://aip.baidubce.com/oauth/2.0/token"params = {"grant_type": "client_credentials", "client_id": API_KEY, "client_secret": SECRET_KEY}return str(requests.post(url, params=params).json().get("access_token"))
然后根据图片获取到对应的base64编码:
def get_file_content_as_base64(path, urlencoded=False):# 获取文件base64编码# :param path: 文件路径# :param urlencoded: 是否对结果进行urlencoded# :return: base64编码信息with open(path, "rb") as f:content = base64.b64encode(f.read()).decode("utf8")if urlencoded:content = urllib.parse.quote_plus(content)return content
最后调用图片识别接口,获取图片识别的动物名称
def get_result():url = "https://aip.baidubce.com/rest/2.0/image-classify/v1/animal?access_token=" + get_access_token()# 获取图片的base64编码payload= get_file_content_as_base64("C://path//to//image//folder//斑马.jpg",True)headers = {'Content-Type': 'application/x-www-form-urlencoded','Accept': 'application/json'}response = requests.request("POST", url, headers=headers, data=payload)print(response.text)
打印结果如下,返回结果对应不同score,我们取score最高的作为返回结果即“斑马”。
{"result": [{"score": "0.948385","name": "斑马"},{"score": "0.0410539","name": "平原斑马"},{"score": "0.00519192","name": "细纹斑马"},{"score": "0.000554136","name": "斑马驴"},{"score": "0.000273289","name": "斑驴"},{"score": "0.000155838","name": "孟加拉虎"}],"log_id": "1710925525288202877"
}
第三步,识别小朋友的语音

在孩子看到图片之后用语音的方式说出动物的名字,此时我们需要将孩子的语音文件进行 base64 转码处理。
def get_file_content_as_base64(path, urlencoded=False):# 获取文件base64编码# :param path: 文件路径# :param urlencoded: 是否对结果进行urlencoded# :return: base64编码信息with open(path, "rb") as f:content = base64.b64encode(f.read()).decode("utf8")if urlencoded:content = urllib.parse.quote_plus(content)return content
然后需要将该语音文件转化为文本:
def get_text():url = "https://vop.baidu.com/server_api"speech = get_file_content_as_base64("C://path//to//image//folder//banma.m4a",False)payload = json.dumps({"format": "pcm","rate": 16000,"channel": 1,"cuid": "0kGgQCWS6F1A7lYR5sBQCVT3Id4TsEY4","token": get_access_token(),"speech": speech,"len": 36414})headers = {'Content-Type': 'application/json','Accept': 'application/json'}response = requests.request("POST", url, headers=headers, data=payload)print(response.text)
打印结果如下,我们根据返回的结果将 result 中的数据取出来,即“斑马”。
{"corpus_no": "7287496064443398818","err_msg": "success.","err_no": 0,"result": ["斑马"],"sn": "928281938221696752399"
}
最后就需要我们把“通过图像识别出来的文字”和“通过语音识别出来的文字”进行比对,如果一致就切换下一张图片,不一致则告知孩子请重新作答。
到这儿,我的创意就全部实现了,虽然只是简单的软件层面的实现,但是我希望以后儿童玩具厂商可以把它来最终落地,毕竟这种AI原生应用小玩具肯定会广受儿童喜欢的。它到底是“斑马”还是“马”呢?让程序告诉小朋友吧。
最后多啰嗦几句,很期待在百度世界大会上看到更多的AI原生应用,包括智能家居、智能医疗、智能零售、智能交通等领域的创新应用。这些应用将有望在未来实现更好的人机交互、智能化的自动化流程、个性化的服务和体验,推动产业升级和社会进步。同时,我们也期待看到更多企业和开发者加入到AI原生应用的创新行列中,共同推动人工智能技术向前发展。
相关文章:
万万没想到,我用文心一言开发了一个儿童小玩具
最近关注到一年一度的百度世界大会今年将于10月17日在北京首钢园举办,本期大会的主题是“生成未来(PROMPT THE WORLD)”。会上,李彦宏会做主题为「手把手教你做AI原生应用」的演讲,比较期待 Robin 会怎么展示。据说&am…...
SQL sever中的视图
目录 一、视图概述: 二、视图好处 三、创建视图 法一: 法二: 四、查看视图信息 五、视图插入数据 六、视图修改数据 七、视图删除数据 八、删除视图 法一: 法二: 一、视图概述: 视图是一种常用…...

如何理解数据序列化
数据序列化是一个将数据结构或对象状态转换为一个可以存储或传输的格式的过程。序列化后的数据可以存放在文件中、数据库中或通过网络传输。反序列化是将序列化数据恢复为原始数据结构或对象的过程。 数据序列化格式可以理解为一种约定或规范,它定义了如何表示和编码数据以便…...
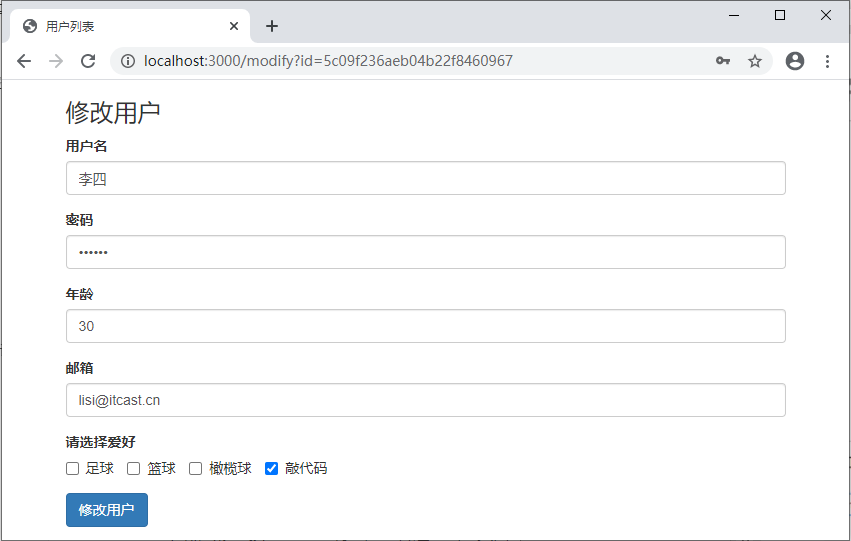
07_项目开发_用户信息列表
1 用户信息列表内容展示 用户信息列表,主要完成用户信息的添加、删除、修改和查找功能。 用户列表页面效果: 单击“添加用户”按钮,进入添加用户页面。 填写正确的信息后,单击“添加用户”按钮,会直接跳转到用户列表…...

flutter ios打包
在 Flutter 中打包 iOS 应用程序分为两步: 生成 iOS 项目文件 在 Flutter 项目根目录下执行以下命令: flutter create --ios-language swift .这个命令会在当前目录下生成 iOS 项目文件,并且默认使用 Swift 语言编写。 使用 Xcode 打包 …...

【无公网IP内网穿透】基于NATAPP搭建Web站点
🎉🎉欢迎来到我的CSDN主页!🎉🎉 🏅我是Java方文山,一个在CSDN分享笔记的博主。📚📚 🌟推荐给大家我的专栏《.内网穿透》。🎯🎯 &#…...
智能AI创作系统ChatGPT详细搭建教程/AI绘画系统/支持GPT联网提问/支持Prompt应用/支持国内AI模型
一、智能AI创作系统 SparkAi创作系统是基于OpenAI很火的ChatGPT进行开发的Ai智能问答系统,支持OpenAI GPT全模型国内AI全模型。本期针对源码系统整体测试下来非常完美,可以说SparkAi是目前国内一款的ChatGPT对接OpenAI软件系统。那么如何搭建部署AI创作…...

【技能树笔记】网络篇——练习题解析(五)
目录 前言 一、应用层的作用 1.1 应用层的作用 二、HTTP协议 2.1 HTTP协议 三、FTP协议 3.1 FTP协议 四、DNS协议 4.1 DNS协议 五、DHCP协议 5.1 DHCP协议 六、邮件协议 6.1 电子邮件协议 总结 前言 本篇文章给出了CSDN网络技能树中的部分练习题解析,…...
--- 集合元素的遍历操作Iterator以及foreach)
Java集合(二)--- 集合元素的遍历操作Iterator以及foreach
文章目录 一、使用迭代器Iterator接口1.说明2.代码 二、foreach循环,用于遍历集合、数组 提示:以下是本篇文章正文内容,下面案例可供参考 一、使用迭代器Iterator接口 1.说明 1.内部的方法: hasNext() 和 next() 2.集合对象每次调iterator…...

数据结构:排序- 插入排序(插入排序and希尔排序) , 选择排序(选择排序and堆排序) , 交换排序(冒泡排序and快速排序) , 归并排序
目录 前言 复杂度总结 预备代码 插入排序 1.直接插入排序: 时间复杂度O(N^2) \空间复杂度O(1) 复杂度(空间/时间): 2.希尔排序: 时间复杂度 O(N^1.3~ N^2) 空间复杂度为O(1) 复杂度(空间/时间&#…...

IOT 围炉札记
文章目录 一、蓝牙二、PAN1080三、IOT OS四、通讯 一、蓝牙 树莓派上的蓝牙协议 BlueZ 官网 BlueZ 官方 Linux Bluetooth 栈 oschina 二、PAN1080 pan1080 文档 三、IOT OS Zephyr 官网 Zephyr oschina Zephyr github Zephyr docs 第1章 Zephyr简介 第2章 Zephyr 编译环…...
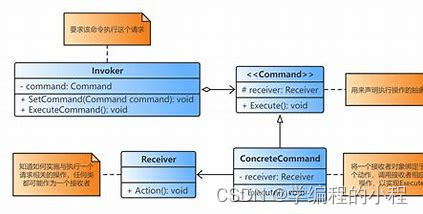
小谈设计模式(24)—命令模式
小谈设计模式(24)—命令模式 专栏介绍专栏地址专栏介绍 命令模式角色分析命令(Command)具体命令(ConcreteCommand)接收者(Receiver)调用者(Invoker)客户端&am…...
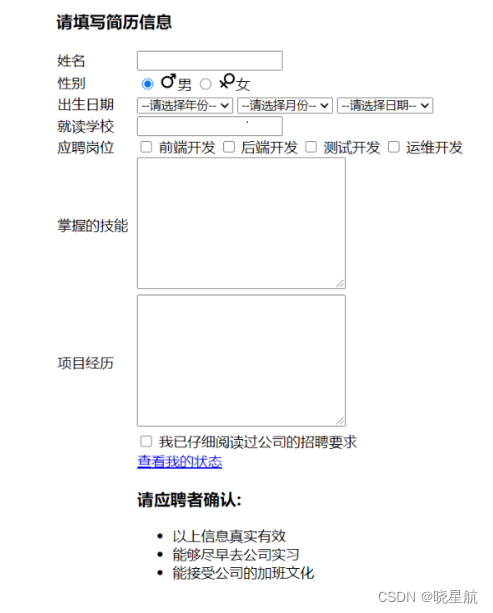
9.HTML
文章目录 1.HTML 常见标签1.1注释标签1.2标题标签: h1-h61.3段落标签: p1.4换行标签: br1.5综合案例: 展示博客1.6格式化标签1.7图片标签: img1.8超链接标签: a1.9综合案例: 展示博客21.10表格标签1.10.1基本使用1.10.2合并单元格 1.11列表标签1.12表单标签1.13无语义标签: div…...
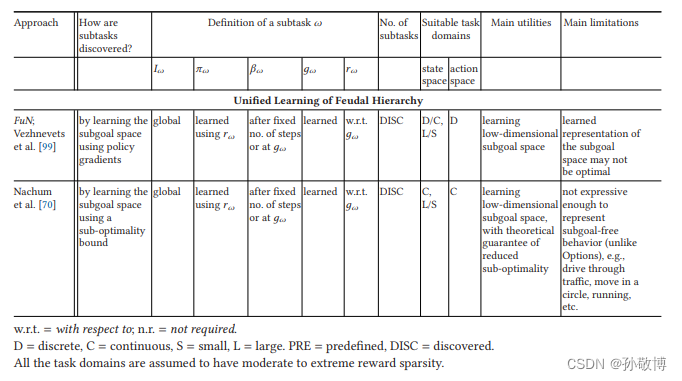
分层强化学习 综述论文阅读 Hierarchical Reinforcement Learning: A Comprehensive Survey
分层强化学习 综述论文阅读 Hierarchical Reinforcement Learning: A Comprehensive Survey 摘要一、介绍二、基础知识回顾2.1 强化学习2.2 分层强化学习2.2.1 子任务符号2.2.2 基于半马尔可夫决策过程的HRL符号 2.3 通用项定义 三、分层强化学习方法3.1 学习分层策略 (LHP)3.1…...
TensorFlow入门(十五、数据读取机制(2))
使用Dataset创建和读取数据集,作为TensorFlow模型创建输入管道的新方式,使用性能比使用feed_dict或队列式管道的性能高很多,使用也更加简洁容易。也是google强烈推荐的数据读取方式,对于TensorFlow而言,十分重要。 Dataset是什么? Dataset的定义 : 它是一个含有相同类型元素且…...
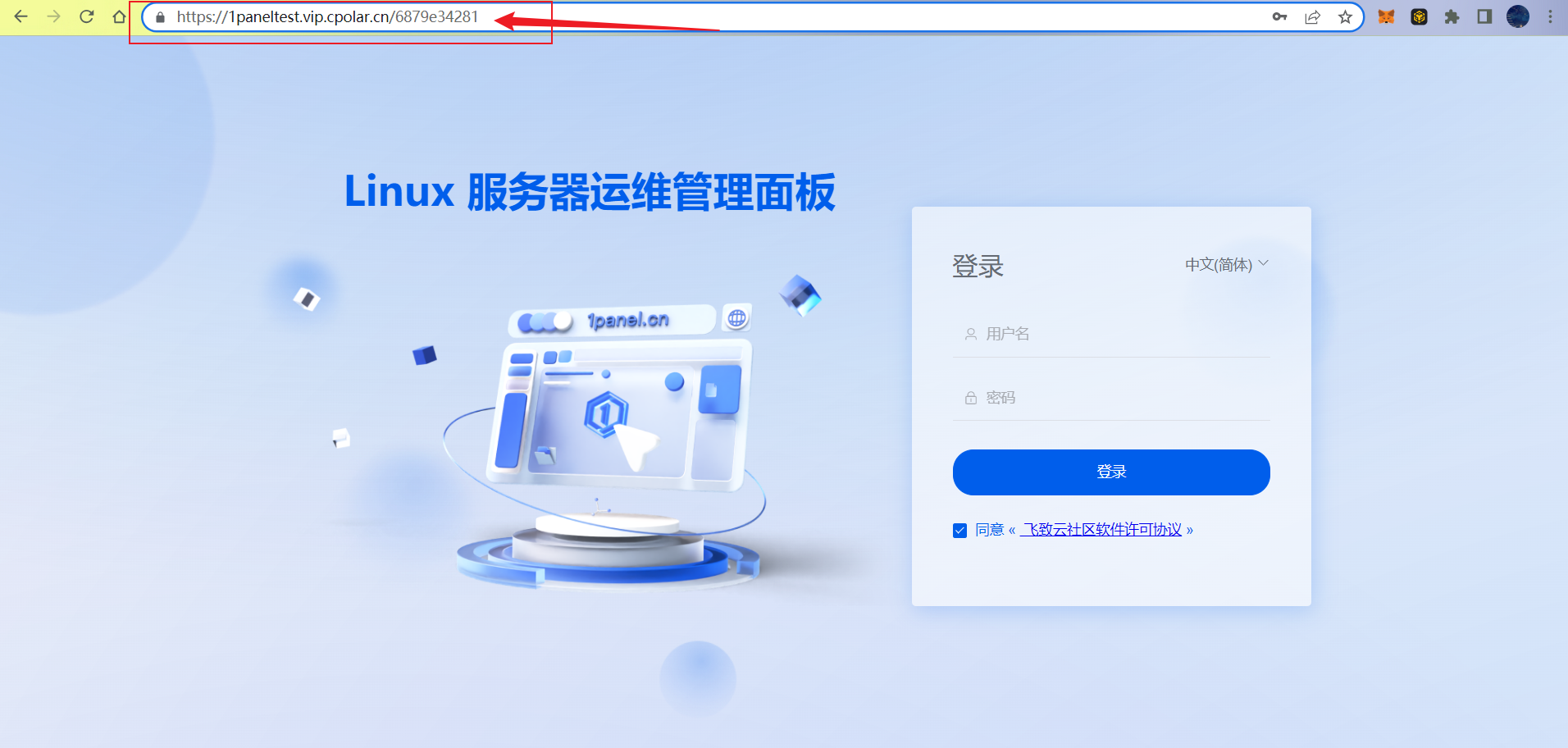
Linux系统中实现便捷运维管理和远程访问的1Panel部署方法
文章目录 前言1. Linux 安装1Panel2. 安装cpolar内网穿透3. 配置1Panel公网访问地址4. 公网远程访问1Panel管理界面5. 固定1Panel公网地址 前言 1Panel 是一个现代化、开源的 Linux 服务器运维管理面板。高效管理,通过 Web 端轻松管理 Linux 服务器,包括主机监控、…...

Rancher清理节点
本节介绍如何从一个 Rancher 创建的 Kubernetes 集群中断开一个节点,并从该节点中删除所有 Kubernetes 组件。此过程允许您将释放节点资源,将节点用于其他用途。 当您使用 Rancher 创建集群节点 时,将创建资源(容器/虚拟网络接口)和配置项(证…...
C++-Mongoose(1)-http-server
Mongoose is a network library for C/C. It implements event-driven non-blocking APIs for TCP, UDP, HTTP, WebSocket, MQTT. mongoose很小巧,只有两个文件mongoose.h/cpp,拿来就可以用. 下载地址: https://github.com/cesanta/mongoo…...

Linux中openvswitch配置网桥详解
以下是对给出的命令进行逐行解释和注释: # 安装openvswitch软件包,并自动确认所有提示信息使用默认值(-y参数) dnf install openvswitch -y# 启动openvswitch服务 systemctl start openvswitch# 设置openvswitch服务开机启动 sys…...
Python自动化测试框架pytest的详解安装与运行
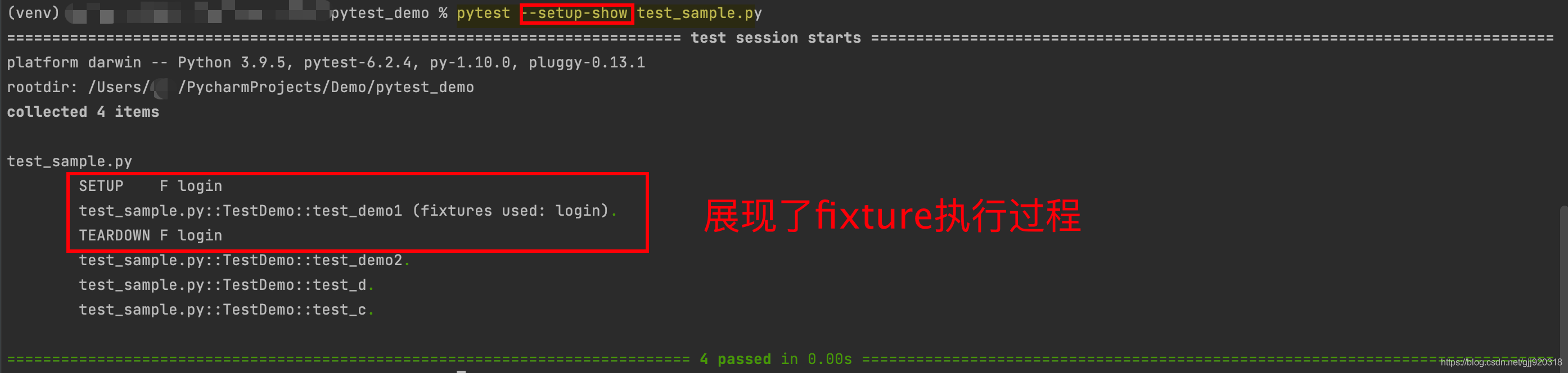
这篇文章主要为大家介绍了Python自动化测试框架pytest的简介以及安装与运行,有需要的朋友可以借鉴参考下希望能够有所帮助,祝大家多多进步 1. pytest的介绍 pytest是一个非常成熟的全功能的python测试工具,它主要有以下特征: 简…...

终极指南:如何免费解锁Cursor Pro完整功能 - 突破AI编辑器限制的完整方案
终极指南:如何免费解锁Cursor Pro完整功能 - 突破AI编辑器限制的完整方案 【免费下载链接】cursor-free-vip [Support 0.45](Multi Language 多语言)自动注册 Cursor Ai ,自动重置机器ID , 免费升级使用Pro 功能: Youv…...

从日志到环境变量:根治 Android Studio AVD 启动报错“The emulator process has terminated”
1. 从错误弹窗到日志分析:定位问题的第一步 当你兴冲冲地打开Android Studio准备启动AVD(Android Virtual Device)时,突然弹出一个冰冷的提示框:"The emulator process has terminated",这感觉就…...

3DS游戏格式转换神器:5分钟让.3ds文件变身为可安装的CIA
3DS游戏格式转换神器:5分钟让.3ds文件变身为可安装的CIA 【免费下载链接】3dsconv Python script to convert Nintendo 3DS CCI (".cci", ".3ds") files to the CIA format 项目地址: https://gitcode.com/gh_mirrors/3d/3dsconv 还在为…...

Godot卡牌游戏框架终极指南:3小时从零构建专业级卡牌游戏
Godot卡牌游戏框架终极指南:3小时从零构建专业级卡牌游戏 【免费下载链接】godot-card-game-framework A framework which comes with prepared scenes and classes to kickstart your card game, as well as a powerful scripting engine to use to provide full r…...

并行LLM推理技术:Hogwild! Inference原理与应用
1. 并行LLM推理的技术背景与挑战在传统Transformer架构中,语言模型的推理过程本质上是顺序执行的——每个新token的生成都严格依赖于之前所有token的注意力计算结果。这种串行特性导致两个显著瓶颈:首先,硬件计算资源利用率低下,特…...

3分钟掌握猫抓扩展:轻松捕获网页视频的终极秘籍
3分钟掌握猫抓扩展:轻松捕获网页视频的终极秘籍 【免费下载链接】cat-catch 猫抓 浏览器资源嗅探扩展 / cat-catch Browser Resource Sniffing Extension 项目地址: https://gitcode.com/GitHub_Trending/ca/cat-catch 你是否曾经遇到过这样的情况࿱…...

如何快速提升游戏帧率:OpenSpeedy游戏加速优化终极指南
如何快速提升游戏帧率:OpenSpeedy游戏加速优化终极指南 【免费下载链接】OpenSpeedy 🎮 An open-source game speed modifier. 项目地址: https://gitcode.com/gh_mirrors/op/OpenSpeedy 你是否厌倦了游戏卡顿和掉帧?OpenSpeedy是一款…...

MTKClient终极指南:解锁联发科芯片调试的专业解决方案
MTKClient终极指南:解锁联发科芯片调试的专业解决方案 【免费下载链接】mtkclient MTK reverse engineering and flash tool 项目地址: https://gitcode.com/gh_mirrors/mt/mtkclient MTKClient作为一款专为联发科(MediaTek)芯片设计的…...

Forge模组开发效率提升:Gradle插件自动化构建与热部署实践
1. 项目概述:一个为Forge模组开发者准备的“瑞士军刀”如果你是一名Minecraft Forge模组的开发者,或者你正打算踏入这个充满创造力的领域,那么你大概率经历过这样的场景:为了测试一个简单的功能改动,你需要反复地执行g…...

平衡车PID积分饱和问题
你发现了PID最致命的坑! 你说的完全正确:积分(Ki)是累加的,会无限叠加,直接让PWM爆掉、车猛冲、失控! 这就是积分饱和 —— 99%初学者死在这里。 我现在彻底讲透积分为什么炸、怎么修复、平衡车…...