GIN框架路由的实现原理
文章目录
- 首先回顾一下gin框架的路由如何使用的
- 从源码分析一下gin框架
- gin的路由实现
- 前缀树
- 前缀树的实现
- 压缩前缀树--Radix Trie
- Trie VS Map
首先回顾一下gin框架的路由如何使用的
package mainimport ("fmt""github.com/gin-gonic/gin""net/http"
)func main() {//创建一个gin Engine ,Engine实现了net/http包下Handler接口,本质上是一个http Handlerr := gin.Default()//注册中间件r.Use(middleware1)r.Use(middleware2)//注册一个path为/hello的处理函数,将/hello域名下的get请求路由到后面的handler函数来处理r.GET("/hello", handler)r.Run()}
func middleware1(c *gin.Context) {fmt.Println("Executing middleware1")c.Next() //将控制权传递给下一个中间件或者处理函数//c.Abort() //在请求处理过程中发现错误或异常情况时,立即终止处理并返回错误信息,后续的处理程序或者中间件不在执行//Executing middleware1//middle1 endfmt.Println("middle1 end")
}func middleware2(c *gin.Context) {fmt.Println("Executing middleware2")c.Next()fmt.Println("middle2 end")
}func handler(c *gin.Context) {fmt.Println("Executing handler")fmt.Println("handler end")c.JSON(http.StatusOK, gin.H{"message": "hello word"})}/*
Executing middleware1
Executing middleware2
Executing handler
handler end
middle2 end
middle1 end*/运行程序
在浏览器输入“http://127.0.0.1:8080/hello”可以看到
http的请求有9种,GET\HEAD\POST\PUT\PATCH\DELETE\CONNECT\OPTIONS\TRACE
从源码分析一下gin框架
首先通过“gin.Default()”创建一个Engine实例并附带有“Logger\Recovery”中间件
// Default returns an Engine instance with the Logger and Recovery middleware already attached.
func Default() *Engine {debugPrintWARNINGDefault()engine := New()engine.Use(Logger(), Recovery())return engine
}
Default()实际上是调用了New(),并使用use注册“Logger\Recovery”两个中间件
func New() *Engine {debugPrintWARNINGNew()engine := &Engine{RouterGroup: RouterGroup{Handlers: nil,basePath: "/",root: true,},FuncMap: template.FuncMap{},RedirectTrailingSlash: true,RedirectFixedPath: false,HandleMethodNotAllowed: false,ForwardedByClientIP: true,RemoteIPHeaders: []string{"X-Forwarded-For", "X-Real-IP"},TrustedPlatform: defaultPlatform,UseRawPath: false,RemoveExtraSlash: false,UnescapePathValues: true,MaxMultipartMemory: defaultMultipartMemory,trees: make(methodTrees, 0, 9),delims: render.Delims{Left: "{{", Right: "}}"},secureJSONPrefix: "while(1);",trustedProxies: []string{"0.0.0.0/0", "::/0"},trustedCIDRs: defaultTrustedCIDRs,}engine.RouterGroup.engine = engineengine.pool.New = func() any {return engine.allocateContext(engine.maxParams)}return engine
}
New()函数初始化Engine实例并返回,接下来看一下Engine struct都有些什么
type Engine struct {RouterGroup// RedirectTrailingSlash enables automatic redirection if the current route can't be matched but a// handler for the path with (without) the trailing slash exists.// For example if /foo/ is requested but a route only exists for /foo, the// client is redirected to /foo with http status code 301 for GET requests// and 307 for all other request methods.RedirectTrailingSlash bool// RedirectFixedPath if enabled, the router tries to fix the current request path, if no// handle is registered for it.// First superfluous path elements like ../ or // are removed.// Afterwards the router does a case-insensitive lookup of the cleaned path.// If a handle can be found for this route, the router makes a redirection// to the corrected path with status code 301 for GET requests and 307 for// all other request methods.// For example /FOO and /..//Foo could be redirected to /foo.// RedirectTrailingSlash is independent of this option.RedirectFixedPath bool// HandleMethodNotAllowed if enabled, the router checks if another method is allowed for the// current route, if the current request can not be routed.// If this is the case, the request is answered with 'Method Not Allowed'// and HTTP status code 405.// If no other Method is allowed, the request is delegated to the NotFound// handler.HandleMethodNotAllowed bool// ForwardedByClientIP if enabled, client IP will be parsed from the request's headers that// match those stored at `(*gin.Engine).RemoteIPHeaders`. If no IP was// fetched, it falls back to the IP obtained from// `(*gin.Context).Request.RemoteAddr`.ForwardedByClientIP bool// AppEngine was deprecated.// Deprecated: USE `TrustedPlatform` WITH VALUE `gin.PlatformGoogleAppEngine` INSTEAD// #726 #755 If enabled, it will trust some headers starting with// 'X-AppEngine...' for better integration with that PaaS.AppEngine bool// UseRawPath if enabled, the url.RawPath will be used to find parameters.UseRawPath bool// UnescapePathValues if true, the path value will be unescaped.// If UseRawPath is false (by default), the UnescapePathValues effectively is true,// as url.Path gonna be used, which is already unescaped.UnescapePathValues bool// RemoveExtraSlash a parameter can be parsed from the URL even with extra slashes.// See the PR #1817 and issue #1644RemoveExtraSlash bool// RemoteIPHeaders list of headers used to obtain the client IP when// `(*gin.Engine).ForwardedByClientIP` is `true` and// `(*gin.Context).Request.RemoteAddr` is matched by at least one of the// network origins of list defined by `(*gin.Engine).SetTrustedProxies()`.RemoteIPHeaders []string// TrustedPlatform if set to a constant of value gin.Platform*, trusts the headers set by// that platform, for example to determine the client IPTrustedPlatform string// MaxMultipartMemory value of 'maxMemory' param that is given to http.Request's ParseMultipartForm// method call.MaxMultipartMemory int64// UseH2C enable h2c support.UseH2C bool// ContextWithFallback enable fallback Context.Deadline(), Context.Done(), Context.Err() and Context.Value() when Context.Request.Context() is not nil.ContextWithFallback booldelims render.DelimssecureJSONPrefix stringHTMLRender render.HTMLRenderFuncMap template.FuncMapallNoRoute HandlersChainallNoMethod HandlersChainnoRoute HandlersChainnoMethod HandlersChainpool sync.Pooltrees methodTreesmaxParams uint16maxSections uint16trustedProxies []stringtrustedCIDRs []*net.IPNet
}
从结构体中发现,Engine有一个“sync.Pool”类型的pool变量:
sync.Pool是sync包下的一个内存池组件用来实现对象的复用,避免重复创建相同的对象,造成频繁的内存分配和gc,以达到提升程序性能的目的,虽然池子中的对象可以被复用,
但是sync.Pool并不会永久保存这个对象,池子中的对象会在一定时间后被gc回收,这个时间是随机的。所以用sync.Pool持久化存储对象不可取
sync.Pool本身是线程安全的,支持多个goroutine并发的往sync.Pool存取数据
sync.Pool的使用例子
package main
import ("fmt""sync"
)type Student struct {Name stringAge int
}func main() {pool := sync.Pool{New: func() interface{} {return &Student{Name: "zhangsan",Age: 23,}},}st := pool.Get().(*Student)fmt.Println(st.Age, st.Name)fmt.Printf("%p\n", &st)pool.Put(st)st = pool.Get().(*Student)fmt.Println(st.Age, st.Name)fmt.Printf("%p\n", &st)}
//23 zhangsan
//0xc00000a028
//23 zhangsan
//0xc00000a028
Engine结构RouterGroup结构体,接下来看一下“RouterGroup”结构体
type RouterGroup struct {//HandlersChain defines a HandlerFunc slice//HandlerFunc defines the handler used by gin middleware as return valueHandlers HandlersChainbasePath stringengine *Engineroot bool
}
Engine中还有一个“methodTrees”类型的变量trees
trees methodTrees
type methodTrees []methodTree
type methodTree struct{method stringroot *node
}
type node struct {path stringindices stringwildChild boolnType nodeTypepriority uint32children []*node // child nodes, at most 1 :param style node at the end of the arrayhandlers HandlersChainfullPath string
}
node 中最重要的两个结构就是
type node struct{wildChild boolchildren []*node
}
//其实这个就是前缀树实现的比较重要的两个数据变量
gin的路由实现
gin的每种请求,都是一个域名对应着一个路由处理函数,就是一种映射关系;直观上可以使用map存储这种映射关系,key存储域名,value存储域名对应的处理函数;
但实际上,gin路由底层实现这个映射使用的是压缩前缀树,首先介绍一下前缀树
前缀树
前缀树就是trie树,是一种树形结构,用于高效地存储和检索字符串集合。基本思想就是将字符串中的每个字符作为树的一个节点,从根节点开始,每个节点代表代表字符串中的一个前缀。在Trie树,每个节点都包含一个指向子节点的指针数组,数组的大小等于字符集的大小。如果某个节点代表的字符串是一个单词的结尾,可以在该节点上做一个标记。
以下是前缀树的一些特性:
- 前缀匹配。前缀树可以高效地实现前缀匹配。给定一个前缀,可以在O(k)的时间复杂度内找到所有以该前缀开头的字符串,k是前缀的长度
- 高效存储和检索。前缀树可以高效地存储和检索字符串集合。在插入和查找字符串时,时间复杂度为O(k),k是字符串的长度。相比于哈希表和二叉搜索树,前缀树在字符串存储和检索方面具有更好的性能
- 消耗较大的空间。空间复杂度较高,每个节点都需要存储指向子节点的指针数组,节点的数量可能会非常多。空间复杂度为O(n*m)其中n为字符串集合中字符串的平均长度,m为字符串数量
- 支持删除操作。删除操作相对比较复杂,删除一个字符串需要同时删除相应的节点,需要处理节点合并的情况。
- 应用场景。单词查询,自动补全,模糊匹配
前缀树的实现
前缀树的实现可以参考力扣上的一道代码题
题目链接
大致的思路就是
go 语言实现
type Trie struct {trie [26]*Trieflag bool
}func Constructor() Trie {return Trie{}
}func (this *Trie) Insert(word string) {tr:= thisfor i:=0;i<len(word);i++{if tr.trie[word[i]-'a']==nil{tr.trie[word[i]-'a'] = &Trie{}}tr=tr.trie[word[i]-'a']}tr.flag=true
}func (this *Trie) Search(word string) bool {tr:=this.startpre(word)return tr!=nil && tr.flag
}func (this *Trie) StartsWith(prefix string) bool {return this.startpre(prefix)!=nil
}
func (this *Trie)startpre(pre string)*Trie{tr:=this for i:=0;i<len(pre);i++{if tr.trie[pre[i]-'a']==nil{return nil}tr=tr.trie[pre[i]-'a']}return tr
}/*** Your Trie object will be instantiated and called as such:* obj := Constructor();* obj.Insert(word);* param_2 := obj.Search(word);* param_3 := obj.StartsWith(prefix);*/
C++实现版本,由于C++没有回收内存的机制所以需要手动释放内存
class Trie {
public:~Trie(){//析构函数释放内存del(this);}Trie():trie(26),flag(false){}void insert(string word) {Trie *tr = this;for(const char&c:word){if(!tr->trie[c-'a']) tr->trie[c-'a'] = new Trie();tr=tr->trie[c-'a'];}tr->flag=true;}bool search(string word) {Trie *tr = this;for(const char&c:word){if(!tr->trie[c-'a']) return false;tr=tr->trie[c-'a'];}return tr->flag;}bool startsWith(string prefix) {Trie *tr = this;for(const char&c:prefix){if(!tr->trie[c-'a']) return false;tr=tr->trie[c-'a'];}return true;}
private:vector<Trie*> trie;bool flag;
private:void del(Trie *tr){for(int i=0;i<26;++i){delete(tr->trie[i]);tr->trie[i]=nullptr;}}
};/*** Your Trie object will be instantiated and called as such:* Trie* obj = new Trie();* obj->insert(word);* bool param_2 = obj->search(word);* bool param_3 = obj->startsWith(prefix);*/
解释一下其中的关键代码,del
void del(Trie *tr){//由于每个Trie节点都有一个长度为26的指向子节点的指针数组,所以写了一个长度为26的for循环for(int i=0;i<26;++i){//由于tr->trie[i]是一个Trie的数据类型变量,所以在delete tr->trie[i]的时候会触发tr-trie[i]的析构函数,往下递归的进行内存释放delete(tr->trie[i]);//释放完之后为了防止野指针,将tr->trie[i]设置为nullptrtr->trie[i]=nullptr;}}
压缩前缀树–Radix Trie
从上述的分析和代码实现可以看出,前缀树占用的空间特别大。那么为了优化空间的利用率,gin的路由采用了“压缩前缀树”。
使用如下方法进行压缩:
- 合并相邻的只有一个子节点的节点:遍历前缀树,当发现一个节点只有一个子节点时,将该节点与其子节点合并。合并时,将子节点的字符添加到父节点的字符中,形成新的字符
- 递归地压缩子树,在合并节点后,可能会出现新的节点也只有一个子节点的情况,可以递归的对子树进行压缩,直到无法压缩为止
- 使用特殊字符表示合并,为了在压缩前缀树中表示节点的合并,可以使用一些特殊的字符进行标记。例如可以使用$表示节点的合并
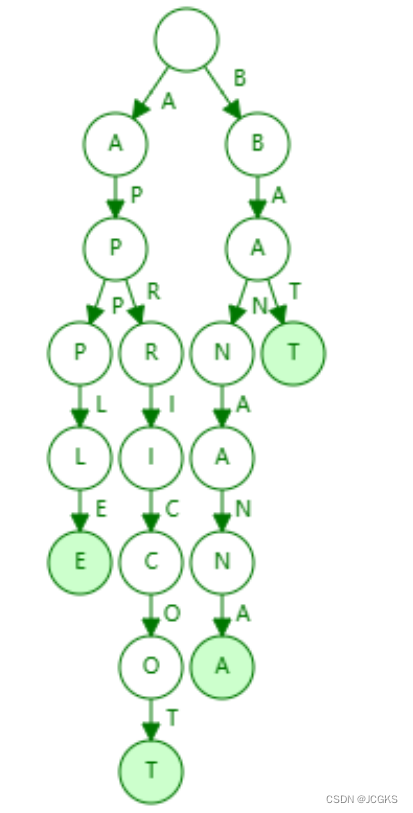
接下来,利用数据结构可视化工具查看两个结构的不同
依次插入[“apple”,“apricot”,“banana”,“bat”]
前缀树的结构如下
压缩前缀树的结构如下
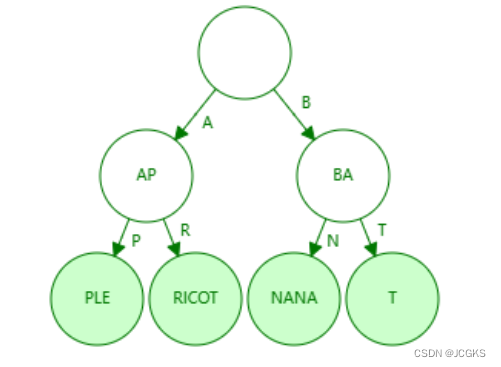
从两图可以看出,Radix Trie对Trie进行了压缩:遍历Trie发现某个节点只有一个子节点,就与子节点进行合并,减少指针数组的占用,优化空间
Trie VS Map
接下来说一下为什么不用map实现路径和路由函数之间的映射。
- map并不支持模糊匹配和参数提取;前缀树可以根据前缀进行参数提取,而使用map进行参数提取需要额外的步骤
- 前缀树可以根据前缀进行分组管理,而map不行
相关文章:
GIN框架路由的实现原理
文章目录 首先回顾一下gin框架的路由如何使用的从源码分析一下gin框架gin的路由实现前缀树前缀树的实现压缩前缀树--Radix TrieTrie VS Map 首先回顾一下gin框架的路由如何使用的 package mainimport ("fmt""github.com/gin-gonic/gin""net/http&quo…...
Android Studio版本升级后的问题 gradle降级、jdk升级
Cannot use TaskAction annotation on method IncrementalTask.taskAction$gradle_core() because interface org.gradle.api.tasks.incremental.IncrementalTaskInputs is not a valid parameter to an action method. 修改下面两处地方分别为7.0.3、7.3.3Android Gradle plu…...
浏览器插件开发爬虫记录
常用爬虫有各种各样的反爬限制,而如果是小数据量并且该网站反爬手段非常厉害的前提下,可以考虑使用浏览器插件作为爬虫手段 基本代码来源于这位博主分享的插件代码, 主要在他的基础上加了 请求代理、管理面板、脚本注入拦截到的请求数据和管…...

万万没想到,我用文心一言开发了一个儿童小玩具
最近关注到一年一度的百度世界大会今年将于10月17日在北京首钢园举办,本期大会的主题是“生成未来(PROMPT THE WORLD)”。会上,李彦宏会做主题为「手把手教你做AI原生应用」的演讲,比较期待 Robin 会怎么展示。据说&am…...
SQL sever中的视图
目录 一、视图概述: 二、视图好处 三、创建视图 法一: 法二: 四、查看视图信息 五、视图插入数据 六、视图修改数据 七、视图删除数据 八、删除视图 法一: 法二: 一、视图概述: 视图是一种常用…...

如何理解数据序列化
数据序列化是一个将数据结构或对象状态转换为一个可以存储或传输的格式的过程。序列化后的数据可以存放在文件中、数据库中或通过网络传输。反序列化是将序列化数据恢复为原始数据结构或对象的过程。 数据序列化格式可以理解为一种约定或规范,它定义了如何表示和编码数据以便…...
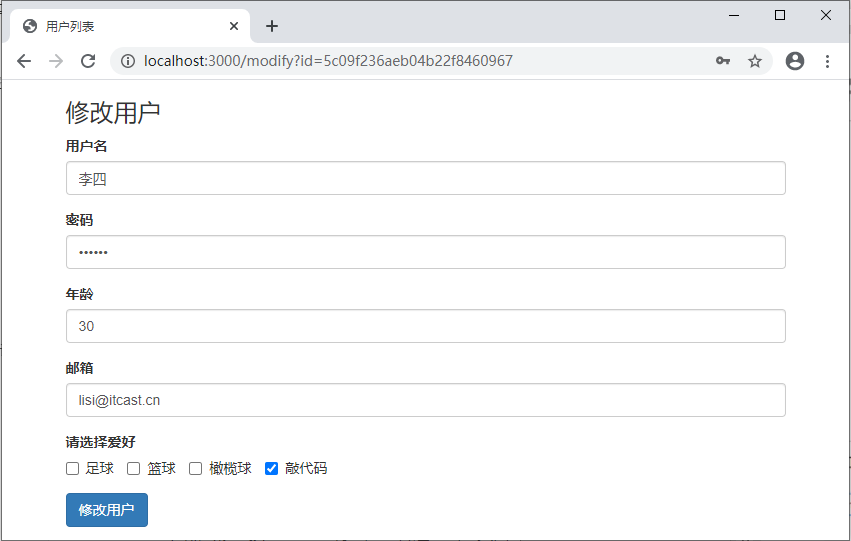
07_项目开发_用户信息列表
1 用户信息列表内容展示 用户信息列表,主要完成用户信息的添加、删除、修改和查找功能。 用户列表页面效果: 单击“添加用户”按钮,进入添加用户页面。 填写正确的信息后,单击“添加用户”按钮,会直接跳转到用户列表…...

flutter ios打包
在 Flutter 中打包 iOS 应用程序分为两步: 生成 iOS 项目文件 在 Flutter 项目根目录下执行以下命令: flutter create --ios-language swift .这个命令会在当前目录下生成 iOS 项目文件,并且默认使用 Swift 语言编写。 使用 Xcode 打包 …...

【无公网IP内网穿透】基于NATAPP搭建Web站点
🎉🎉欢迎来到我的CSDN主页!🎉🎉 🏅我是Java方文山,一个在CSDN分享笔记的博主。📚📚 🌟推荐给大家我的专栏《.内网穿透》。🎯🎯 &#…...
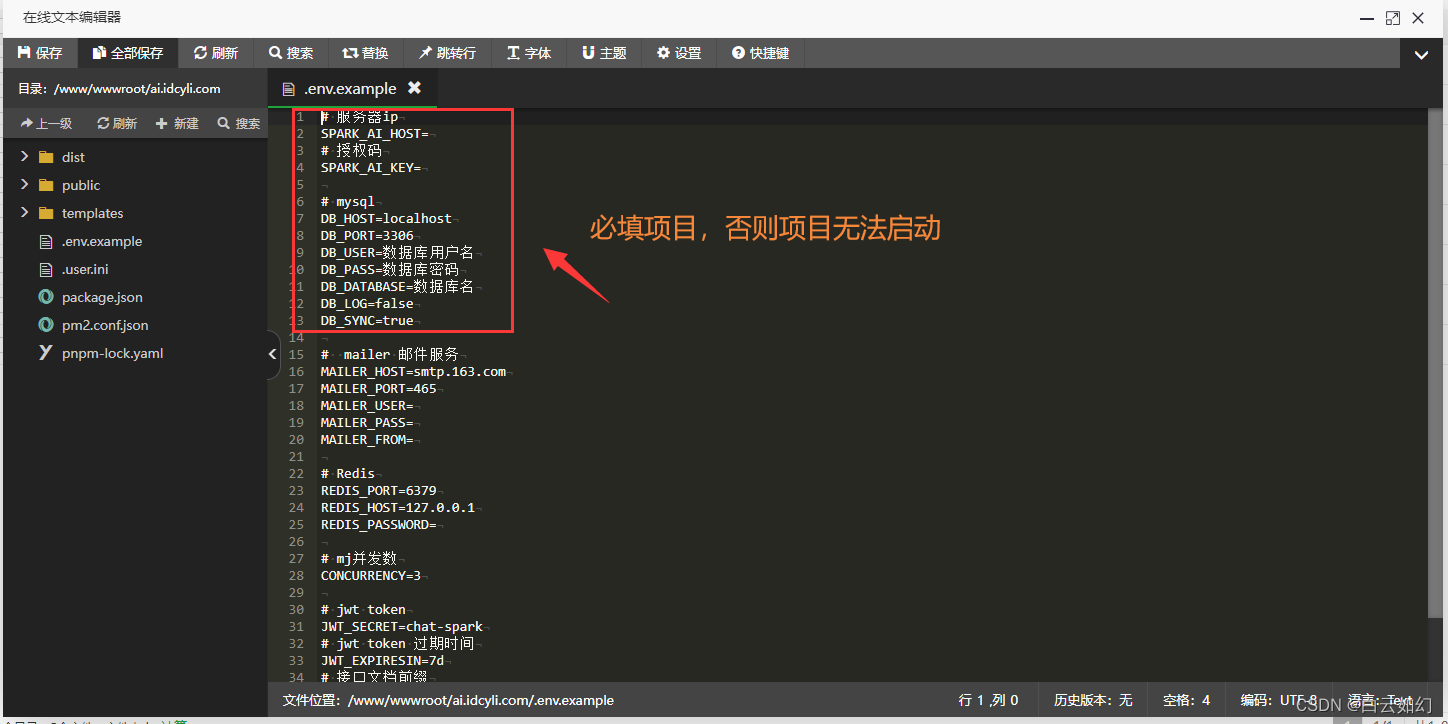
智能AI创作系统ChatGPT详细搭建教程/AI绘画系统/支持GPT联网提问/支持Prompt应用/支持国内AI模型
一、智能AI创作系统 SparkAi创作系统是基于OpenAI很火的ChatGPT进行开发的Ai智能问答系统,支持OpenAI GPT全模型国内AI全模型。本期针对源码系统整体测试下来非常完美,可以说SparkAi是目前国内一款的ChatGPT对接OpenAI软件系统。那么如何搭建部署AI创作…...

【技能树笔记】网络篇——练习题解析(五)
目录 前言 一、应用层的作用 1.1 应用层的作用 二、HTTP协议 2.1 HTTP协议 三、FTP协议 3.1 FTP协议 四、DNS协议 4.1 DNS协议 五、DHCP协议 5.1 DHCP协议 六、邮件协议 6.1 电子邮件协议 总结 前言 本篇文章给出了CSDN网络技能树中的部分练习题解析,…...
--- 集合元素的遍历操作Iterator以及foreach)
Java集合(二)--- 集合元素的遍历操作Iterator以及foreach
文章目录 一、使用迭代器Iterator接口1.说明2.代码 二、foreach循环,用于遍历集合、数组 提示:以下是本篇文章正文内容,下面案例可供参考 一、使用迭代器Iterator接口 1.说明 1.内部的方法: hasNext() 和 next() 2.集合对象每次调iterator…...

数据结构:排序- 插入排序(插入排序and希尔排序) , 选择排序(选择排序and堆排序) , 交换排序(冒泡排序and快速排序) , 归并排序
目录 前言 复杂度总结 预备代码 插入排序 1.直接插入排序: 时间复杂度O(N^2) \空间复杂度O(1) 复杂度(空间/时间): 2.希尔排序: 时间复杂度 O(N^1.3~ N^2) 空间复杂度为O(1) 复杂度(空间/时间&#…...

IOT 围炉札记
文章目录 一、蓝牙二、PAN1080三、IOT OS四、通讯 一、蓝牙 树莓派上的蓝牙协议 BlueZ 官网 BlueZ 官方 Linux Bluetooth 栈 oschina 二、PAN1080 pan1080 文档 三、IOT OS Zephyr 官网 Zephyr oschina Zephyr github Zephyr docs 第1章 Zephyr简介 第2章 Zephyr 编译环…...
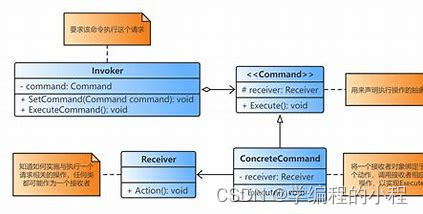
小谈设计模式(24)—命令模式
小谈设计模式(24)—命令模式 专栏介绍专栏地址专栏介绍 命令模式角色分析命令(Command)具体命令(ConcreteCommand)接收者(Receiver)调用者(Invoker)客户端&am…...
9.HTML
文章目录 1.HTML 常见标签1.1注释标签1.2标题标签: h1-h61.3段落标签: p1.4换行标签: br1.5综合案例: 展示博客1.6格式化标签1.7图片标签: img1.8超链接标签: a1.9综合案例: 展示博客21.10表格标签1.10.1基本使用1.10.2合并单元格 1.11列表标签1.12表单标签1.13无语义标签: div…...
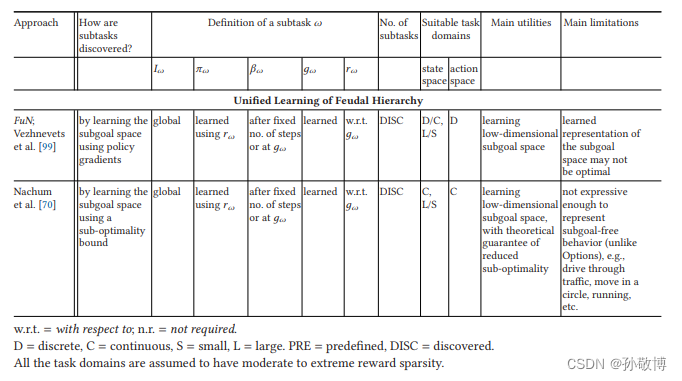
分层强化学习 综述论文阅读 Hierarchical Reinforcement Learning: A Comprehensive Survey
分层强化学习 综述论文阅读 Hierarchical Reinforcement Learning: A Comprehensive Survey 摘要一、介绍二、基础知识回顾2.1 强化学习2.2 分层强化学习2.2.1 子任务符号2.2.2 基于半马尔可夫决策过程的HRL符号 2.3 通用项定义 三、分层强化学习方法3.1 学习分层策略 (LHP)3.1…...
TensorFlow入门(十五、数据读取机制(2))
使用Dataset创建和读取数据集,作为TensorFlow模型创建输入管道的新方式,使用性能比使用feed_dict或队列式管道的性能高很多,使用也更加简洁容易。也是google强烈推荐的数据读取方式,对于TensorFlow而言,十分重要。 Dataset是什么? Dataset的定义 : 它是一个含有相同类型元素且…...
Linux系统中实现便捷运维管理和远程访问的1Panel部署方法
文章目录 前言1. Linux 安装1Panel2. 安装cpolar内网穿透3. 配置1Panel公网访问地址4. 公网远程访问1Panel管理界面5. 固定1Panel公网地址 前言 1Panel 是一个现代化、开源的 Linux 服务器运维管理面板。高效管理,通过 Web 端轻松管理 Linux 服务器,包括主机监控、…...

Rancher清理节点
本节介绍如何从一个 Rancher 创建的 Kubernetes 集群中断开一个节点,并从该节点中删除所有 Kubernetes 组件。此过程允许您将释放节点资源,将节点用于其他用途。 当您使用 Rancher 创建集群节点 时,将创建资源(容器/虚拟网络接口)和配置项(证…...

DownKyi完全指南:三步解锁B站8K视频下载的终极方案
DownKyi完全指南:三步解锁B站8K视频下载的终极方案 【免费下载链接】downkyi 哔哩下载姬downkyi,哔哩哔哩网站视频下载工具,支持批量下载,支持8K、HDR、杜比视界,提供工具箱(音视频提取、去水印等ÿ…...

手把手教你用三菱FX3U PLC的RS指令和RS2指令与电脑串口调试助手‘对话’
三菱FX3U PLC串口通信实战:从零搭建RS485数据收发系统 第一次接触工业控制系统的串口通信时,我被那些密密麻麻的接线和晦涩的协议参数弄得晕头转向。直到在自动化生产线上亲眼看到PLC通过两根电线与十几台设备稳定通信,才意识到串口技术的精妙…...

终极指南:使用Python开源工具破解百度网盘限速,实现高速免费下载
终极指南:使用Python开源工具破解百度网盘限速,实现高速免费下载 【免费下载链接】baidu-wangpan-parse 获取百度网盘分享文件的下载地址 项目地址: https://gitcode.com/gh_mirrors/ba/baidu-wangpan-parse 还在为百度网盘几十KB的下载速度而烦恼…...

CircuitPython Web Workflow实战:无线开发Yoto Mini与I2C硬件验证
1. 项目概述与核心价值如果你玩过像树莓派Pico或者ESP32这类微控制器,肯定对“插拔-编程-调试”这个循环不陌生。每次改几行代码,就得拔下USB线,重新上电,然后盯着串口监视器看输出。这个过程在项目初期调试硬件时,尤其…...

构建个人代码仓库:提升开发效率的实践指南
1. 项目概述:一个面向21世纪开发者的代码仓库最近在GitHub上看到一个挺有意思的项目,叫“21st-dev/1code”。光看这个名字,你可能觉得有点抽象,但点进去之后,我发现它其实是一个挺有想法的代码仓库。这个项目没有复杂的…...
、连读规则注入与敬语语调开关(内测白名单已开放))
仅限菲律宾本地团队使用的ElevenLabs隐藏功能:Tagalog重音标记语法(`[ˈba.ka]`)、连读规则注入与敬语语调开关(内测白名单已开放)
更多请点击: https://intelliparadigm.com 第一章:ElevenLabs菲律宾文语音能力的本地化演进背景 菲律宾语(Filipino)作为以他加禄语(Tagalog)为基础的国家官方语言,拥有约1.05亿母语及第二语言…...

AI编程助手安全规则实战:从SQL注入防御到团队安全基线构建
1. 项目概述:当AI编程助手遇上安全红线最近在GitHub上看到一个挺有意思的项目,叫“cursor-security-rules”。光看名字,你大概能猜到它和Cursor这个AI编程工具有关,而且重点是“安全规则”。没错,这个项目本质上是一个…...

Python数据聚合抓取工具:从配置化引擎到实战避坑指南
1. 项目概述:一个多功能的“聚合爪”工具最近在GitHub上闲逛,发现了一个名字挺有意思的项目:al1enjesus/polyclawster。这个名字拆开看,“poly”代表多,“clawster”听起来像是“claw”(爪子)和…...

从零构建现代化工作流引擎:架构、实战与生产级部署指南
1. 项目概述:一个为专业开发者打造的现代化工作流引擎最近在GitHub上看到一个挺有意思的项目,叫rohitg00/pro-workflow。光看名字,你可能觉得这又是一个“工作流”工具,市面上这类工具已经多如牛毛了。但当我深入去研究它的源码、…...

【2024最新】ElevenLabs日语模型v2.4深度评测:对比VoiceLab、OpenJTalk与Azure Custom Neural TTS的MOS分与实时吞吐数据
更多请点击: https://intelliparadigm.com 第一章:ElevenLabs日语模型v2.4的核心演进与技术定位 ElevenLabs 日语模型 v2.4 并非简单语音合成能力的迭代,而是面向高保真、低延迟、多语境日语语音生成的一次系统性重构。其底层架构从基于 Gri…...