Vue3 编译原理
文章目录
- 一、编译流程
- 1. 解读入口文件 packgages/vue/index.ts
- 2. compile函数的运行流程
- 二、AST 解析器
- 1. `ast` 的生成
- 2. 创建`ast`的根节点
- 3. 解析子节点 `parseChildren`(关键)
- 4. 解析模版元素 Element
- 模版元素解析-举例分析
一、编译流程
1. 解读入口文件 packgages/vue/index.ts
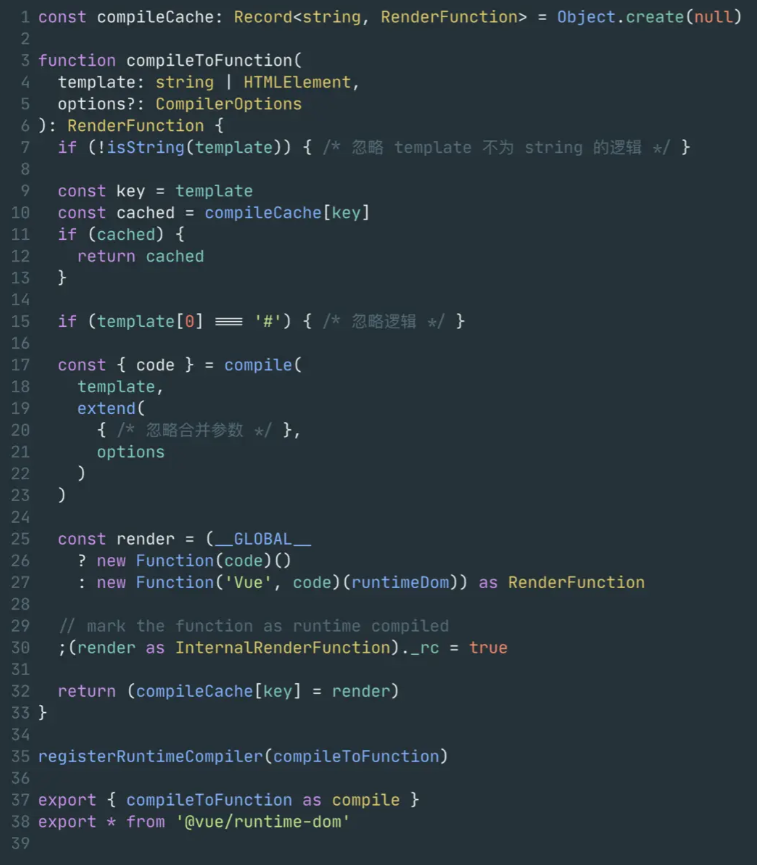
首先从Vue对象的入口开始,packgages/vue/index.ts文件中只有compileToFunction函数:
- 依赖注入编译函数至runtimeregisterRuntimeCompiler(compileToFunction)
- runtime 调用编译函数compileToFunction
- 返回包含code的编译结果
- 将code作为参数传入Function 的构造函数将生成函数赋值给render变量。
- 将render函数作为编译结果返回
下面这个简单的模版,
<template><div>Hello World</div>
</template>
经过编译后,code返回的字符串为:
const _Vue = Vue return function render(_ctx, _cache) {with(_ctx) {const {openBlock: _openBlock, createBlock:_createBlock} = _Vue;return (_openBlock(), _createBlock("div", null, "Hello World")) }
}
- 拿到这个代码字符串的结果后,第25行声明了一个render变量,并将生成的代码字符串code 作为参数传入了new Function 构造函数,生成了render函数。可以将上面的code字符串格式化。
- 这里的render显而易见是一个柯里化的函数,返回了一个函数,函数内部通过with来扩展作用域链。
- 最后,入口文件返回了render变量,并顺手缓存了render函数。
- 在第一行,入口文件创建了一个
compileCache对象,用以缓存compileToFunction函数生成的render函数,将template参数作为缓存的key,并在11行进行if分支做缓存判断,如果该模版之前被缓存过,则不再进行编译,直接返回缓存中的render函数,以此提高性能。
2. compile函数的运行流程
compile函数涉及到compile-dom 和compile-core 两个模块。
compile的运行流程:
baseCompile命名理由:因为compile-core是编译的核心模块,接收外部的参数来按照规则完成编译,而compile-dom是专门处理浏览器场景下的编译,在这个模块下导出的compile函数是入口文件真正接收的编译函数。而compile-dom中的compile函数相对baseCompile也是一个更高阶的编译器。例如:当Vue在weex或iOS或Android这些Native App中工作时,compile-dom可能会被相关的移动端编译库来取代。baseCompile函数:
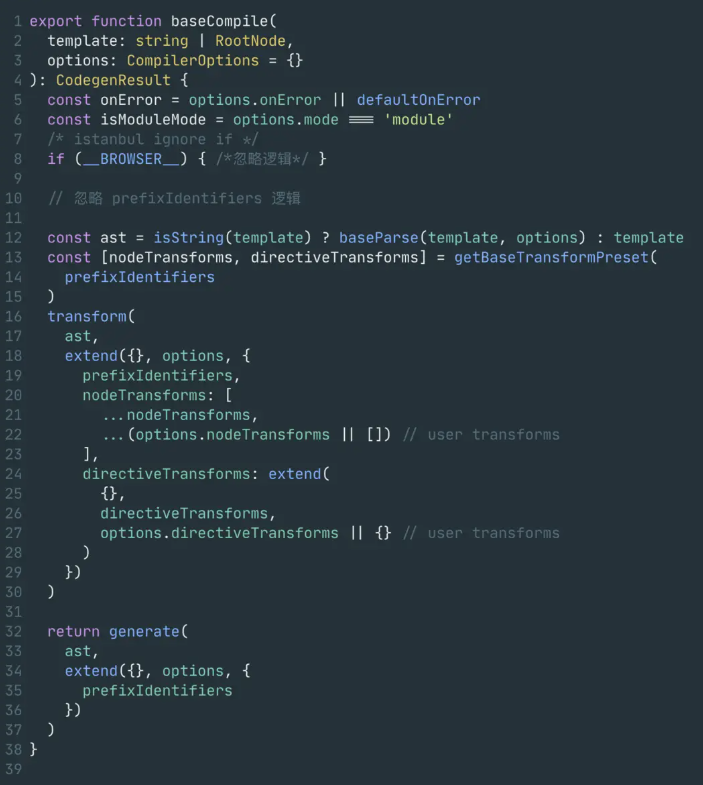
- 从函数声明中看,baseCompile接收template模版以及上层高阶编译器处理过的options编译选项,最终返回一个CodegenResult类型的编译结果。
export interface CodegenResult {code: stringpreamble: stringast: RootNodemap?: RawSourceMap
}
- 看上方源码的第12行,判断template模版是否为字符串,如果是的话,则会对字符串进行解析,否则直接将template作为AST。(我们平时写的vue代码都是以字符串的形式传递进去的。)
- 然后是第16行调用了transform函数,以及传入了指令转换、节点等工具函数,对由模版生成的AST进行转换。
- 最后32行,将转换好的ast传入进generate,生成CodegenResult类型的返回结果。
二、AST 解析器
1. ast 的生成
ast的生成有一个三目运算符的判断,如果传进来的template模版是一个字符串,那么则调用baseParse解析模版字符串,否则直接将template作为ast对象。
baseParse 函数:
export function baseParse(content: string,options: ParserOptions = {}
): RootNode {const context = createParserContext(content, options) // 创建解析的上下文对象const start = getCursor(context) // 生成记录解析过程的游标信息return createRoot( // 生成并返回 root 根节点parseChildren(context, TextModes.DATA, []), // 解析子节点,作为 root 根节点的 children 属性getSelection(context, start))
}
- 首先会创建解析的上下文,根据上下文获取游标信息,由于还未进行解析,所以游标中的
column、line、offset属性对应的都是template的起始位置。 - 之后就是创建根节点,并返回根节点,至此
ast树生成,解析完成。
2. 创建ast的根节点
export function createRoot(children: TemplateChildNode[],loc = locStub
): RootNode {return {type: NodeTypes.ROOT,children,helpers: [],components: [],directives: [],hoists: [],imports: [],cached: 0,temps: 0,codegenNode: undefined,loc}
}
- 该函数返回了一个
RootNode类型的根节点对象,其中我们传入的children参数会被作为根节点的children参数。
3. 解析子节点 parseChildren(关键)
function parseChildren(context: ParserContext,mode: TextModes,ancestors: ElementNode[]
): TemplateChildNode[] {const parent = last(ancestors) // 获取当前节点的父节点const ns = parent ? parent.ns : Namespaces.HTMLconst nodes: TemplateChildNode[] = [] // 存储解析后的节点// 当标签未闭合时,解析对应节点while (!isEnd(context, mode, ancestors)) {/* 忽略逻辑 */}// 处理空白字符,提高输出效率let removedWhitespace = falseif (mode !== TextModes.RAWTEXT && mode !== TextModes.RCDATA) {/* 忽略逻辑 */}// 移除空白字符,返回解析后的节点数组return removedWhitespace ? nodes.filter(Boolean) : nodes
}
- parseChildren函数接收三个参数,context解析器上下文,mode文本数据类型,ancestors祖先节点数据。
- 函数执行首先会从祖先节点中获取当前节点的父节点,确定命名空间,以及创建一个空数组,用来存储解析后的节点。
- 之后会有一个while循环,判断是否到达了标签的关闭位置,如果不是需要关闭的标签,则在循环体内对源模版字符串进行分类解析。
- 之后会有一段处理空白字符的逻辑,处理完成后返回解析好的nodes数组。
while循环内的逻辑(函数的核心):
- 在while中会判断文本数据的类型,只有当TextModes为DATA或RCDATA时会继续往下解析。
- 第一种情况就是判断是否需要解析Vue模版语法中的
Mustache语法,如果当前上下文中没有v-pre指令来跳过表达式,并且源模版字符串是以我们指定的分隔符开头的,就会进行双大括号的解析。 - 接下来会判断,如果第一个字符是
<并且第二个字符是!,会尝试解析注释标签,<!DOCTYPE>和<!CDATA这三种情况,对于DOCTYPE会进行忽略,解析成注释。 - 之后会判断当第二个字符是
/的情况,</已经满足了一个闭合标签的条件了,所以会尝试匹配闭合标签。当第三个标签是>,缺少了标签名字,会报错,并让解析器的进度前进三个字符,跳过</>。 - 如果是
</,并且第三个字符是小写英文字符,解析器会解析结束标签。 - 如果源模版字符串的第一个字符是
<,第二个字符是小写英文字符开头,会调用parseElement函数来解析对应的标签。 - 当这个判断字符串字符的分支条件结束,并且没有解析出任何node节点,则会将node作为文本类型,调用parseText进行解析。
- 最后将生成的节点添加进nodes数组,在函数结束时返回。
- 第一种情况就是判断是否需要解析Vue模版语法中的
while循环的源码如下:
while (!isEnd(context, mode, ancestors)) {const s = context.sourcelet node: TemplateChildNode | TemplateChildNode[] | undefined = undefinedif (mode === TextModes.DATA || mode === TextModes.RCDATA) {if (!context.inVPre && startsWith(s, context.options.delimiters[0])) {/* 如果标签没有 v-pre 指令,源模板字符串以双大括号 `{{` 开头,按双大括号语法解析 */node = parseInterpolation(context, mode)} else if (mode === TextModes.DATA && s[0] === '<') {// 如果源模板字符串的第以个字符位置是 `!`if (s[1] === '!') {// 如果以 '<!--' 开头,按注释解析if (startsWith(s, '<!--')) {node = parseComment(context)} else if (startsWith(s, '<!DOCTYPE')) {// 如果以 '<!DOCTYPE' 开头,忽略 DOCTYPE,当做伪注释解析node = parseBogusComment(context)} else if (startsWith(s, '<![CDATA[')) {// 如果以 '<![CDATA[' 开头,又在 HTML 环境中,解析 CDATAif (ns !== Namespaces.HTML) {node = parseCDATA(context, ancestors)}}// 如果源模板字符串的第二个字符位置是 '/'} else if (s[1] === '/') {// 如果源模板字符串的第三个字符位置是 '>',那么就是自闭合标签,前进三个字符的扫描位置if (s[2] === '>') {emitError(context, ErrorCodes.MISSING_END_TAG_NAME, 2)advanceBy(context, 3)continue// 如果第三个字符位置是英文字符,解析结束标签} else if (/[a-z]/i.test(s[2])) {parseTag(context, TagType.End, parent)continue} else {// 如果不是上述情况,则当做伪注释解析node = parseBogusComment(context)}// 如果标签的第二个字符是小写英文字符,则当做元素标签解析} else if (/[a-z]/i.test(s[1])) {node = parseElement(context, ancestors)// 如果第二个字符是 '?',当做伪注释解析} else if (s[1] === '?') {node = parseBogusComment(context)} else {// 都不是这些情况,则报出第一个字符不是合法标签字符的错误。emitError(context, ErrorCodes.INVALID_FIRST_CHARACTER_OF_TAG_NAME, 1)}}}// 如果上述的情况解析完毕后,没有创建对应的节点,则当做文本来解析if (!node) {node = parseText(context, mode)}// 如果节点是数组,则遍历添加进 nodes 数组中,否则直接添加if (isArray(node)) {for (let i = 0; i < node.length; i++) {pushNode(nodes, node[i])}} else {pushNode(nodes, node)}
}
4. 解析模版元素 Element
parseElement精简源码如下:
function parseElement(context: ParserContext,ancestors: ElementNode[]
): ElementNode | undefined {// 解析起始标签const parent = last(ancestors)const element = parseTag(context, TagType.Start, parent)// 如果是自闭合的标签或者是空标签,则直接返回。voidTag例如: `<img>`, `<br>`, `<hr>`if (element.isSelfClosing || context.options.isVoidTag(element.tag)) {return element}// 递归的解析子节点ancestors.push(element)const mode = context.options.getTextMode(element, parent)const children = parseChildren(context, mode, ancestors)ancestors.pop()element.children = children// 解析结束标签if (startsWithEndTagOpen(context.source, element.tag)) {parseTag(context, TagType.End, parent)} else {emitError(context, ErrorCodes.X_MISSING_END_TAG, 0, element.loc.start)if (context.source.length === 0 && element.tag.toLowerCase() === 'script') {const first = children[0]if (first && startsWith(first.loc.source, '<!--')) {emitError(context, ErrorCodes.EOF_IN_SCRIPT_HTML_COMMENT_LIKE_TEXT)}}}// 获取标签位置对象element.loc = getSelection(context, element.loc.start)return element
}
- 首先会获取当前节点的父节点,再调用
parseTag()函数解析。
parseTag()函数执行流程:- 匹配标签名
- 解析元素中的attribute属性,存储至props属性
- 检测是否存在v-pre属性,如果存在,则修改context上下文中的inVPre属性为true。
- 检测自闭合标签,如果是自闭合,则将isSelfClosing属性置为true。
- 判断tagType,是Element还是component组件,或slot插槽。
- 返回生成的element对象
- 获取到 element对象后,会判断element是否是自闭合标签,或空标签,例如
<img>、<br>、<hr>,如果是这种情况,直接返回element对象。 - 然后解析element的子节点,把element压入栈中,然后递归调用parseChildren来解析子节点。
const parent = last(ancestors)
在将element入栈后,拿到的父节点就是当前节点。
- 解析完毕后,调用
ancestors.pop(),让当前解析完子节点的element对象出栈,将解析后的children对象赋值给element的children属性,完成element的子节点解析。 - 最后匹配结束标签,设置element的Ioc位置信息,返回解析完毕的 element 对象。
模版元素解析-举例分析
<div><p>Hello World</p>
</div>
相关文章:
Vue3 编译原理
文章目录 一、编译流程1. 解读入口文件 packgages/vue/index.ts2. compile函数的运行流程 二、AST 解析器1. ast 的生成2. 创建ast的根节点3. 解析子节点 parseChildren(关键)4. 解析模版元素 Element模版元素解析-举例分析 一、编译流程 1. 解读入口文…...

spring boot整合Minio
MinIO 安装MinIo # 先创建minio 文件存放的位置 mkdir -p /opt/docker/minio/data# 启动并指定端口 docker run \-p 9000:9000 \-p 5001:5001 \--name minio \-v /opt/docker/minio/data:/data \-e "MINIO_ROOT_USERminioadmin" \-e "MINIO_ROOT_PASSWORDmini…...
Hadoop----Azkaban的使用与一些报错问题的解决
1.因为官方只放出源码,并没有放出其tar包,所以需要我们自己编译,通过查阅资料我们可以使用gradlew对其进行编译,还是比较简单,然后将里面需要用到的服务文件夹进行拷贝,完善其文件夹结构,通常会…...
「新房家装经验」客厅电视高度标准尺寸及客厅电视机买多大尺寸合适?
客厅电视悬挂高度标准尺寸是多少? 客厅电视悬挂高度通常在90~120厘米之间,电视挂墙高度也可以根据个人的喜好和实际情况来调整,但通常不宜过高,以坐在沙发上观看时眼睛能够平视到电视中心点或者中心稍微往下一点的位置为适宜。 客…...

ArduPilot开源飞控之AP_Baro_DroneCAN
ArduPilot开源飞控之AP_Baro_DroneCAN 1. 源由2. back-end抽象类3. 方法实现3.1 probe3.2 update3.3 subscribe_msgs3.4 handle_pressure/handle_temperature3.5 CAN port 4. 参考资料 1. 源由 鉴于ArduPilot开源飞控之AP_Baro中涉及Sensor Driver有以下总线类型: …...
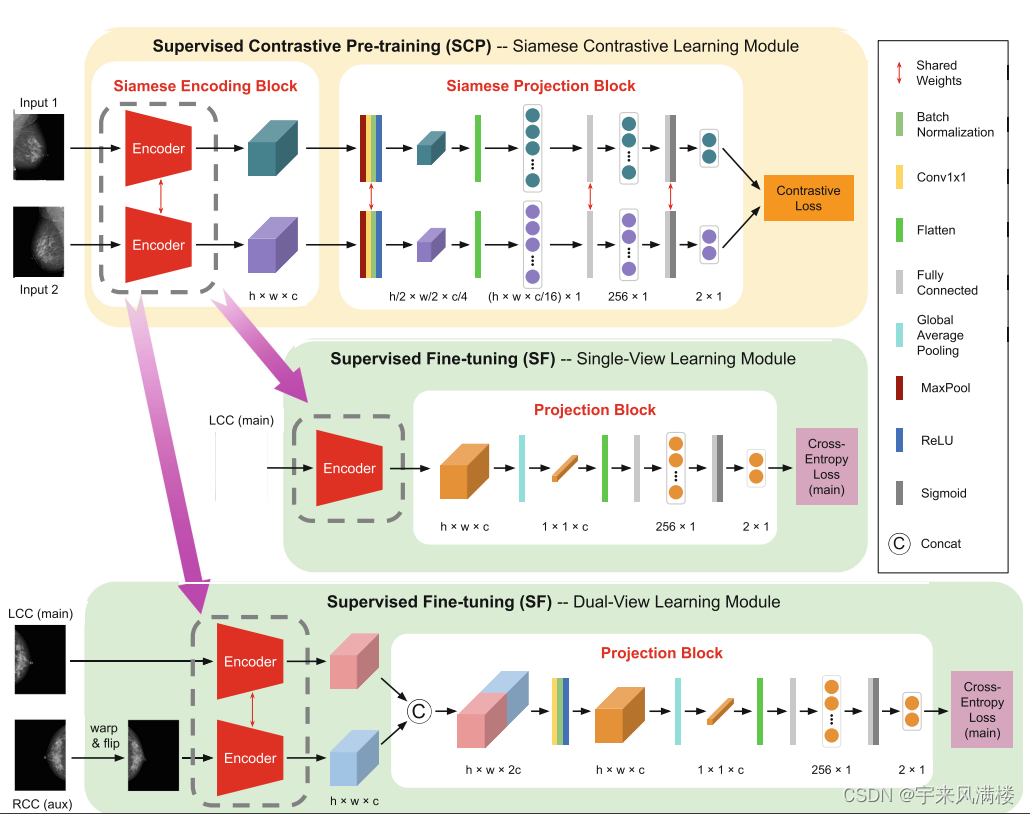
Supervised Contrastive Pre-training for Mammographic Triage Screening Model
方法 品红色箭头表示将生成的孪生编码器分别迁移到单视角学习模块和双视角学习模块...

JVM技术文档--JVM优化思路以及问题定位--JVM可调整参数汇总
阿丹: 一个优秀的程序员,是因为在线上的排查以及遇到的线上、生产事故较多所以定位问题以及解决问题会比普通程序员快很多,所以一个优秀的程序员要逐渐形成自己的方法论,来完善和解决问题。 我们是如何发现问题的呢? …...

Oracle10g数据库迁移方案
试验了很多次Oracle数据库迁移才成功,贴出来给大家参考一下,我看到有的地方写迁移之后还需要重新建立temp表空间,这个还没有研究。另外说一点的是两个数据库的版本一定要一致,之前失败过一次,就是因为两个数据库的版本…...

备忘录模式:对象状态的保存与恢复
欢迎来到设计模式系列的第十八篇文章,本篇将介绍备忘录模式。备忘录模式是一种行为型设计模式,它允许在不破坏封装性的前提下捕获一个对象的内部状态,并在之后恢复该状态。这种模式通常用于需要提供撤销操作的情况。 什么是备忘录模式&#…...

C# InvokeRequired线程安全
C# InvokeRequired线程安全 为了保证新家的线程可能要对主界面的控件元素的属性发生一些改变,此时防止此操作对于主线程的影响,就提出了 InvokeRequired方法,保证主线程的安全,同时新加的线程也可以改变主页面中元素的值。 定义…...
pdf怎么转成jpg图片格式
pdf怎么转成jpg图片格式?对于大家平时在工作或者生活中的图片使用习惯,经常需要将各种格式的文件转换成易于浏览和使用的JPG格式图片以便保存。如今,因为pdf文件具有更强的稳定性和设备兼容性,PDF文件在平时的电脑使用过程中可以说…...
React +ts + babel+webpack
babel babel/preset-typescript 专门处理ts "babel/cli": "^7.17.6", "babel/core": "^7.17.8", "babel/preset-env": "^7.16.11", "babel/preset-react": "^7.16.7", "babel/preset…...
红队专题-REVERSE二进制逆向反编译
红队专题 招募六边形战士队员IDA pro安装python2加入环境变量py2安装pip安装IDA 7.0 proIDAPython: importing "site" failed. 招募六边形战士队员 一起学习 代码审计、安全开发、web攻防、逆向等。。。 私信联系 IDA pro 安装python2 python-2.7.3.msi 加入环…...

Spring技术原理之Bean生命周期原理解析
Spring技术原理之Bean生命周期原理解析 Spring作为Java领域中的优秀框架,其核心功能之一是依赖注入和生命周期管理。其中,Bean的生命周期管理是Spring框架中一个重要的概念。在本篇文章中,我们将深入探讨Spring技术原理中的Bean生命周期原理…...
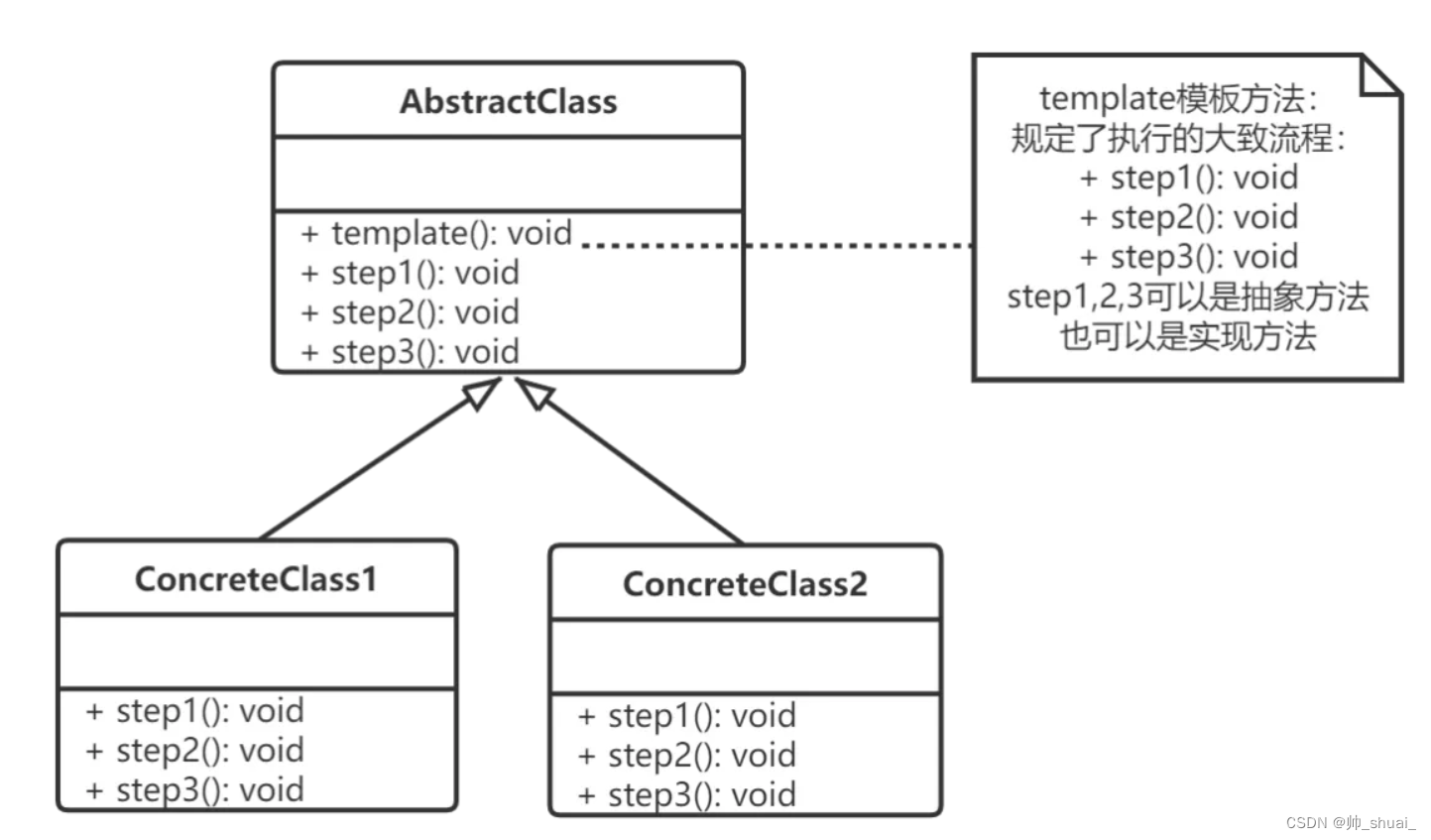
Unity实现设计模式——模板方法模式
Unity实现设计模式——模板方法模式 模板模式(Template Pattern), 指在一个抽象类公开定义了执行它的方法的模板。它的子类可以按需要重写方法实现,但调用将以抽象类中定义的方式进行。 简单说, 模板方法模式定义一个操作中的算法的骨架&…...
)
C++实现高性能内存池(二)
文章目录 一、设计内存池二、实现MemoryPool::construct() 实现MemoryPool::deallocate() 实现MemoryPool::~MemoryPool() 实现MemoryPool::allocate() 实现三、与 std::vector 的性能对比一、设计内存池 在上节中,我们在模板链表栈中使用了默认构造器来管理栈操作中的元素内…...

沪深300期权一个点多少钱?
经中国证监会批准,深圳证券交易所于2019年12月23日上市嘉实沪深300ETF期权合约品种。该产品是以沪深300为标的物的嘉实沪深300ETF交易型指数基金为标的衍生的标准化合约,下文介绍沪深300期权一个点多少钱?本文来自:期权酱 一、沪深300期权涨…...
怎么防止重要文件夹丢失?文件夹安全如何保护?
我们在使用电脑的过程中,会将重要数据放在文件夹中,那么,我们该怎么防止重要文件夹丢失呢?下面我们就一起来了解一下。 EFS加密 EFS加密可以对于NTFS卷上的文件夹进行加密,加密后的文件夹将只允许加密时登录系统的用户…...

用于物体识别和跟踪的下游任务自监督学习-1-引言
一:引言: 图像和视频理解是计算机视觉应用中的基本问题,旨在使机器能够像人类一样解释和理解视觉数据。这些问题涉及识别图像和视频中的对象、人物、动作、事件和场景。如图1.1-(a)所示的图像识别任务包括对象检测[1]…...

式子表达ds类——多用位置/值域表示未知数+区间覆盖转区间加:CF407E
https://www.luogu.com.cn/problem/CF407E 多用位置/值域表示未知数 推出的式子中 n n n 表示长度,应该直接换成 r − l 1 r-l1 r−l1 区间覆盖转区间加 推出的式子有 m x , m n mx,mn mx,mn,朴素思路是用单调队列区间覆盖维护 那样就不能很方便…...

Python视频自动化处理:基于FFmpeg与OpenCV的编程式剪辑框架实践
1. 项目概述与核心价值最近在折腾视频剪辑自动化流程,发现了一个挺有意思的开源项目AmitDigga/fabric-video-editor。这名字一看就带着点“缝合怪”的味道,fabric这个词在编程领域通常指代一个框架或结构,而video-editor则直指视频编辑。简单…...

LLM资源库:大语言模型开发者的高效导航与实战指南
1. 项目概述:一个汇聚LLM资源的“藏宝图”在人工智能,特别是大语言模型(LLM)领域,技术迭代的速度快得让人眼花缭乱。每天都有新的模型发布、新的工具开源、新的论文发表。对于开发者、研究者甚至是刚入门的学习者来说&…...
)
从聊天到拿Shell:一个Netcat命令的‘黑白’两面实战指南(含正向/反向Shell演示)
从聊天到拿Shell:Netcat命令的双面实战手册 在网络安全领域,很少有工具能像Netcat这样同时扮演"天使"与"恶魔"的双重角色。这个被称为"网络瑞士军刀"的轻量级工具,既能帮助管理员快速排查网络问题,…...

解锁B站高清与会员视频:基于you-get与EditThisCookie的自动化下载方案
1. 为什么需要you-get与EditThisCookie组合方案 每次在B站看到喜欢的视频想保存下来,你是不是也遇到过这样的烦恼?用普通下载工具要么画质模糊得像打了马赛克,要么遇到会员专属内容直接提示"无权限"。作为常年混迹技术社区的老司机…...

RK3568网关实战:如何用1TOPS NPU在智慧农业里做实时虫情监测?
RK3568网关实战:如何用1TOPS NPU在智慧农业里做实时虫情监测? 在智慧农业的浪潮中,虫害监测一直是困扰农户的核心问题。传统依赖人工巡查的方式不仅效率低下,还容易错过最佳防治时机。而基于RK3568边缘计算网关的实时虫情监测方案…...

基于规则引擎的自动化文件管理工具smartcat实战指南
1. 项目概述:一个智能化的文件分类与归档工具最近在整理个人电脑和服务器上的文件时,我又一次陷入了混乱。下载文件夹里塞满了各种格式的文档、图片、压缩包,项目目录下混杂着不同版本的代码、设计稿和会议记录。手动分类不仅耗时,…...

ARM Cortex-M3位带操作原理与W55MH32 GPIO实战应用
1. 从51到ARM:为什么我们需要“位带操作”?如果你是从51单片机转过来玩ARM Cortex-M3内核的,比如WIZnet这颗W55MH32,那你肯定对sbit P1_0 P1^0;这种写法再熟悉不过了。在51上,想单独控制一个IO口的高低电平࿰…...

刚刚!西安推拉雨棚厂家测评出炉,陕西中顺雨篷质量优但价格略
本次测评聚焦西安推拉雨棚厂家,旨在为对西安推拉雨棚感兴趣的人群提供客观、真实的数据和信息,帮助大家了解不同厂家的特点。参与本次测评的厂家为陕西中顺雨篷商贸有限公司以及其他西安推拉雨棚厂家。本次测评均基于真实数据与体验,无商业倾…...
AlphaAvatar:从单目视频重建可驱动3D数字人的混合表示框架
1. 项目概述:从“数字人”到“阿尔法化身”的进化最近在数字人、虚拟形象生成这个圈子里,AlphaAvatar这个名字开始被频繁提及。它不是一个简单的换脸工具,也不是一个预设的3D模型库,而是一个旨在从单目视频中,高质量、…...

Python-ADB协议实现原理:深入理解ADB和Fastboot通信机制
Python-ADB协议实现原理:深入理解ADB和Fastboot通信机制 【免费下载链接】python-adb Python ADB Fastboot implementation 项目地址: https://gitcode.com/gh_mirrors/py/python-adb Python-ADB是一个强大的开源项目,提供了ADB(Andr…...