阿里云ModelScope 是一个“模型即服务”(MaaS)平台


简介
项目地址:https://github.com/modelscope/modelscope/tree/master
ModelScope 是一个“模型即服务”(MaaS)平台,旨在汇集来自AI社区的最先进的机器学习模型,并简化在实际应用中使用AI模型的流程。ModelScope库使开发人员能够通过丰富的API设计执行推理、训练和评估,从而促进跨不同AI领域的最先进模型的统一体验。
ModelScope Library为模型贡献者提供了必要的分层API,以便将来自 CV、NLP、语音、多模态以及科学计算的模型集成到ModelScope生态系统中。所有这些不同模型的实现都以一种简单统一访问的方式进行封装,用户只需几行代码即可完成模型推理、微调和评估。同时,灵活的模块化设计使得在必要时也可以自定义模型训练推理过程中的不同组件。
除了包含各种模型的实现之外,ModelScope Library还支持与ModelScope后端服务进行必要的交互,特别是与Model-Hub和Dataset-Hub的交互。这种交互促进了模型和数据集的管理在后台无缝执行,包括模型数据集查询、版本控制、缓存管理等。
部分模型和在线体验
ModelScope开源了数百个(当前700+)模型,涵盖自然语言处理、计算机视觉、语音、多模态、科学计算等,其中包含数百个SOTA模型。用户可以进入ModelScope网站(modelscope.cn)的模型中心零门槛在线体验,或者Notebook方式体验模型。

示例如下:
自然语言处理:
-
GPT-3预训练生成模型-中文-2.7B
-
元语功能型对话大模型
-
孟子T5预训练生成模型-中文-base
-
CSANMT连续语义增强机器翻译-英中-通用领域-large
-
RaNER命名实体识别-中文-新闻领域-base
-
BAStructBERT分词-中文-新闻领域-base
-
二郎神-RoBERTa-330M-情感分类
-
SPACE-T表格问答预训练模型-中文-通用领域-base
多模态:
-
CLIP模型-中文-通用领域-base
-
OFA预训练模型-中文-通用领域-base
-
太乙-Stable-Diffusion-1B-中文-v0.1
-
mPLUG视觉问答模型-英文-large
计算机视觉:
-
ControlNet可控图像生成
-
DAMOYOLO-高性能通用检测模型-S
-
DCT-Net人像卡通化
-
读光-文字识别-行识别模型-中英-通用领域
-
人体检测-通用-Base
-
RetinaFace人脸检测关键点模型
-
BSHM人像抠图
-
图像分割-商品展示图场景的商品分割-电商领域
-
万物识别-中文-通用领域
语音:
-
Paraformer语音识别-中文-通用-16k-离线-large-pytorch
-
语音合成-中文-多情感领域-16k-多发音人
-
CTC语音唤醒-移动端-单麦-16k-小云小云
-
WeNet-U2pp_Conformer-语音识别-中文-16k-实时
-
FRCRN语音降噪-单麦-16k
-
DFSMN回声消除-单麦单参考-16k
科学计算:
-
Uni-Fold-Monomer 开源的蛋白质单体结构预测模型
-
Uni-Fold-Multimer 开源的蛋白质复合物结构预测模型
快速上手
我们针对不同任务提供了统一的使用接口, 使用pipeline进行模型推理、使用Trainer进行微调和评估。
对于任意类型输入(图像、文本、音频、视频…)的任何任务,只需3行代码即可加载模型并获得推理结果,如下所示:
>>> from modelscope.pipelines import pipeline
>>> word_segmentation = pipeline('word-segmentation',model='damo/nlp_structbert_word-segmentation_chinese-base')
>>> word_segmentation('今天天气不错,适合出去游玩')
{'output': '今天 天气 不错 , 适合 出去 游玩'}
>>> import cv2
>>> from modelscope.pipelines import pipeline>>> portrait_matting = pipeline('portrait-matting')
>>> result = portrait_matting('https://modelscope.oss-cn-beijing.aliyuncs.com/test/images/image_matting.png')
>>> cv2.imwrite('result.png', result['output_img'])
对于微调和评估模型, 你需要通过十多行代码构建dataset和trainer,调用trainer.train()和trainer.evaluate()即可。
例如我们利用gpt3 1.3B的模型,加载是诗歌数据集进行finetune,可以完成古诗生成模型的训练。
>>> from modelscope.metainfo import Trainers
>>> from modelscope.msdatasets import MsDataset
>>> from modelscope.trainers import build_trainer>>> train_dataset = MsDataset.load('chinese-poetry-collection', split='train'). remap_columns({'text1': 'src_txt'})
>>> eval_dataset = MsDataset.load('chinese-poetry-collection', split='test').remap_columns({'text1': 'src_txt'})
>>> max_epochs = 10
>>> tmp_dir = './gpt3_poetry'>>> kwargs = dict(model='damo/nlp_gpt3_text-generation_1.3B',train_dataset=train_dataset,eval_dataset=eval_dataset,max_epochs=max_epochs,work_dir=tmp_dir)>>> trainer = build_trainer(name=Trainers.gpt3_trainer, default_args=kwargs)
>>> trainer.train()
为什么要用ModelScope library
-
针对不同任务、不同模型抽象了统一简洁的用户接口,3行代码完成推理,10行代码完成模型训练,方便用户使用ModelScope社区中多个领域的不同模型,开箱即用,便于AI入门和教学。
-
构造以模型为中心的开发应用体验,支持模型训练、推理、导出部署,方便用户基于ModelScope Library构建自己的MLOps.
-
针对模型推理、训练流程,进行了模块化的设计,并提供了丰富的功能模块实现,方便用户定制化开发来自定义自己的推理、训练等过程。
-
针对分布式模型训练,尤其是大模型,提供了丰富的训练策略支持,包括数据并行、模型并行、混合并行等。
安装
镜像
ModelScope Library目前支持tensorflow,pytorch深度学习框架进行模型训练、推理, 在Python 3.7+, Pytorch 1.8+, Tensorflow1.15/Tensorflow2.0+测试可运行。
为了让大家能直接用上ModelScope平台上的所有模型,无需配置环境,ModelScope提供了官方镜像,方便有需要的开发者获取。地址如下:
CPU镜像
# py37
registry.cn-hangzhou.aliyuncs.com/modelscope-repo/modelscope:ubuntu20.04-py37-torch1.11.0-tf1.15.5-1.6.1# py38
registry.cn-hangzhou.aliyuncs.com/modelscope-repo/modelscope:ubuntu20.04-py38-torch1.11.0-tf1.15.5-1.6.1
GPU镜像
# py37
registry.cn-hangzhou.aliyuncs.com/modelscope-repo/modelscope:ubuntu20.04-cuda11.3.0-py37-torch1.11.0-tf1.15.5-1.6.1# py38
registry.cn-hangzhou.aliyuncs.com/modelscope-repo/modelscope:ubuntu20.04-cuda11.3.0-py38-torch1.11.0-tf1.15.5-1.6.1
搭建本地Python环境
你也可以使用pip和conda搭建本地python环境,我们推荐使用Anaconda,安装完成后,执行如下命令为modelscope library创建对应的python环境:
conda create -n modelscope python=3.7
conda activate modelscope
接下来根据所需使用的模型依赖安装底层计算框架
- 安装Pytorch 文档链接
- 安装tensorflow 文档链接
安装完前置依赖,你可以按照如下方式安装ModelScope Library。
ModelScope Libarary由核心框架,以及不同领域模型的对接组件组成。如果只需要ModelScope模型和数据集访问等基础能力,可以只安装ModelScope的核心框架:
pip install modelscope
如仅需体验多模态领域的模型,可执行如下命令安装领域依赖:
pip install modelscope[multi-modal]
如仅需体验NLP领域模型,可执行如下命令安装领域依赖(因部分依赖由ModelScope独立host,所以需要使用"-f"参数):
pip install modelscope[nlp] -f https://modelscope.oss-cn-beijing.aliyuncs.com/releases/repo.html
If you want to use cv models:
pip install modelscope[cv] -f https://modelscope.oss-cn-beijing.aliyuncs.com/releases/repo.html
如仅需体验语音领域模型,可执行如下命令安装领域依赖(因部分依赖由ModelScope独立host,所以需要使用"-f"参数):
pip install modelscope[audio] -f https://modelscope.oss-cn-beijing.aliyuncs.com/releases/repo.html
注意:当前大部分语音模型需要在Linux环境上使用,并且推荐使用python3.7 + tensorflow 1.x的组合。
如仅需体验科学计算领域模型,可执行如下命令安装领域依赖(因部分依赖由ModelScope独立host,所以需要使用"-f"参数):
pip install modelscope[science] -f https://modelscope.oss-cn-beijing.aliyuncs.com/releases/repo.html
注:
-
目前部分语音相关的模型仅支持 python3.7,tensorflow1.15.4的Linux环境使用。 其他绝大部分模型可以在windows、mac(x86)上安装使用。.
-
语音领域中一部分模型使用了三方库SoundFile进行wav文件处理,在Linux系统上用户需要手动安装SoundFile的底层依赖库libsndfile,在Windows和MacOS上会自动安装不需要用户操作。详细信息可参考SoundFile 官网。以Ubuntu系统为例,用户需要执行如下命令:
sudo apt-get update sudo apt-get install libsndfile1 -
CV领域的少数模型,需要安装mmcv-full, 如果运行过程中提示缺少mmcv,请参考mmcv安装手册进行安装。 这里提供一个最简版的mmcv-full安装步骤,但是要达到最优的mmcv-full的安装效果(包括对于cuda版本的兼容),请根据自己的实际机器环境,以mmcv官方安装手册为准。
pip uninstall mmcv # if you have installed mmcv, uninstall it pip install -U openmim mim install mmcv-full
更多教程
除了上述内容,我们还提供如下信息:
- 更加详细的安装文档
- 任务的介绍
- 模型推理
- 模型微调
- 数据预处理
- 模型评估
- 贡献模型到ModelScope
License
本项目使用Apache License (Version 2.0).
相关文章:
阿里云ModelScope 是一个“模型即服务”(MaaS)平台
简介 项目地址:https://github.com/modelscope/modelscope/tree/master ModelScope 是一个“模型即服务”(MaaS)平台,旨在汇集来自AI社区的最先进的机器学习模型,并简化在实际应用中使用AI模型的流程。ModelScope库使开发人员能够通过丰富的…...

Nodejs内置模块process
文章目录 内置模块process写在前面1. arch()2. cwd()3. argv4. memoryUsage()5. exit()6. kill()7. env【最常用】 内置模块process 写在前面 process是Nodejs操作当前进程和控制当前进程的API,并且是挂载到globalThis下面的全局API。 下面是process的一些常用AP…...

Vue2 修改了数组哪些方法,为什么
1、Vue2 修改了以下数组方法 push()、pop()、shift()、unshift()、splice()、sort()、reverse() 这些方法都是可以改变原数组的。 为了实现数据响应式更新,Vue2 在这些方法中添加了特定的代码,以便通知 Vue 视图更新数据 举个例子,当我们…...

均值滤波算法及例程
均值滤波算法是一种简单的图像滤波方法,它使用一个固定大小的滤波器来平滑图像。该滤波器由一个矩形的窗口组成,窗口中的像素值取平均值作为中心像素的新值。以下是均值滤波算法的步骤: 定义滤波器的大小(窗口大小)&a…...

拥抱产业发展机遇 兑现5G商业价值
[阿联酋,迪拜,2023年10月10日] 今天,以“将5G-A带入现实”为主题的2023全球移动宽带论坛在迪拜举行。本次大会上,华为轮值董事长胡厚崑与GSMA总干事Mats Granryd围绕“5G产业进程与发展”连线对话。胡厚崑指出,“技术发…...

Layui合计自定义列
需求:第四列通过计算:27除以220 正常的汇总,增加这个属性就行 特殊的列,需要特殊处理 获取合计行:$(".layui-table-total div.layui-table-cell"); 获取某列的值:$($(".layui-table-total …...
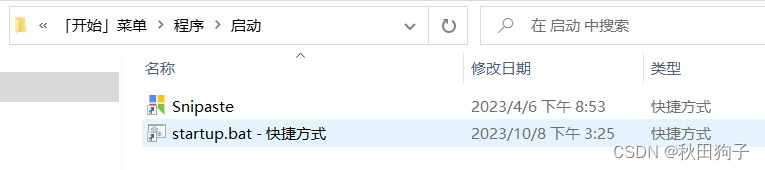
Tomcat自启动另一种方法
Tomcat自启动另一种方法 问题: 不知道怎么回事,好几台电脑都可以开机自启动tomcat,正常运行项目。一样的配置一样的操作流程,偏偏要运行的机器开机自启动后,项目不能运行,手动重启tomcat又可以用了。网上…...
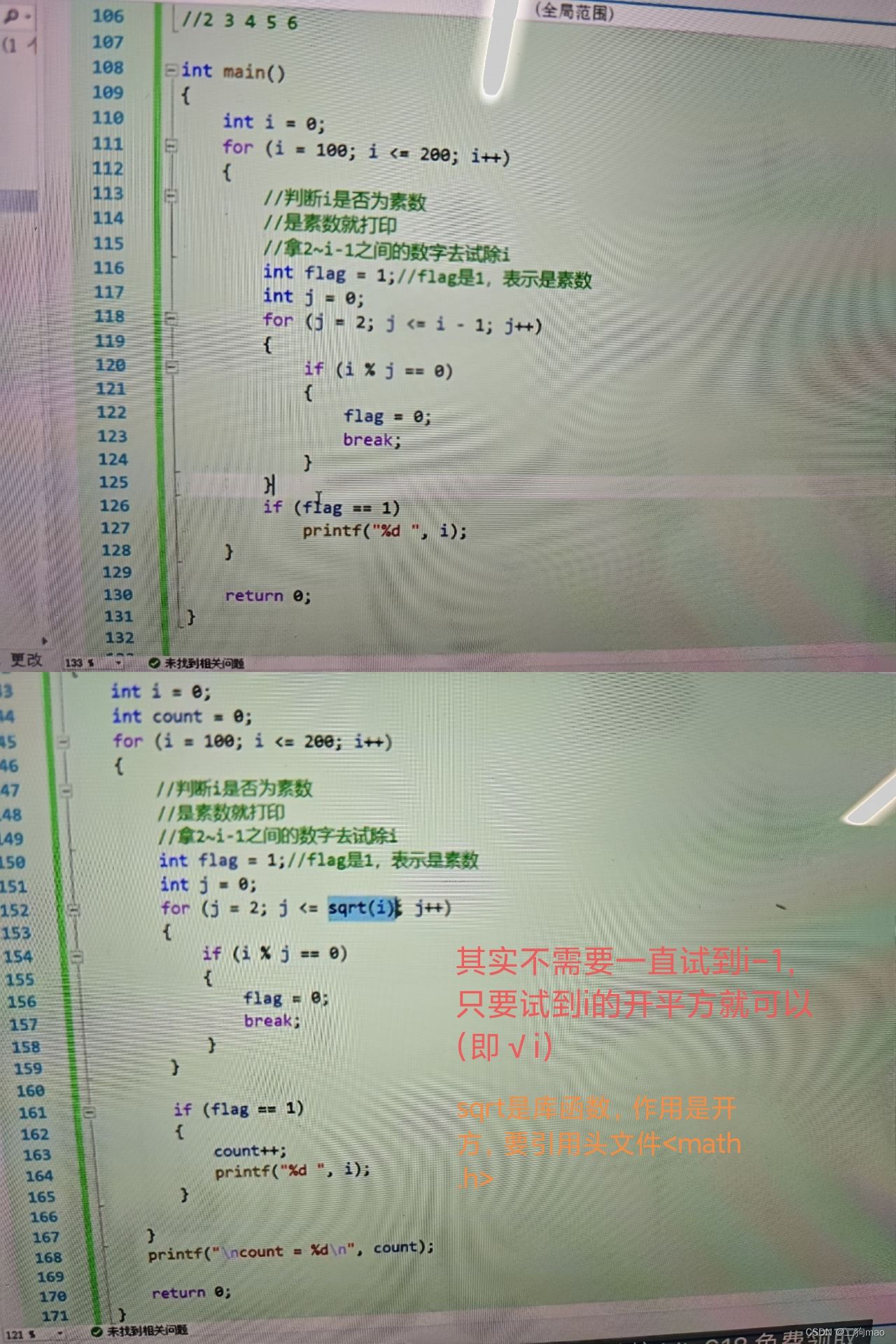
C语言,标志法
标志法通常用来检查或者进行过程中一些状态变化。 有一些是为了观察变化,举出一些以往代码的例子: 1.找出一串数字中没有重复出现过的数字 #include <stdio.h> int main() {int arr[1000] { 0 };int n 0;scanf("%d", &n);int i…...

适合自学的网络安全基础技能“蓝宝书”:《CTF那些事儿》
CTF比赛是快速提升网络安全实战技能的重要途径,已成为各个行业选拔网络安全人才的通用方法。但是,本书作者在从事CTF培训的过程中,发现存在几个突出的问题: 1)线下CTF比赛培训中存在严重的 “最后一公里”问题 &#…...

软件设计师学习笔记12-数据库的基本概念+数据库的设计过程+概念设计+逻辑设计
1.数据库的基本概念 1.1数据库的体系结构 1.1.1常见数据库 ①集中式数据库 数据是集中的;数据管理是集中的 ②C/S结构 客户端负责数据表服务;服务器负责数据库服务;系统分前后端;ODBC、JDBC ③分布式数据库 物理上分布、逻…...
distcc分布式编译
distcc https://gitee.com/bison-fork/distcc.git 下载工具链 mingw,https://www.mingw-w64.org/downloads/#w64devkitperl,https://strawberryperl.com/releases.html免安装zip版本,autoconf等脚本依赖perlautoconf、automake,…...

Java面试题-0919
集合篇 Java面试题-集合篇HashMap底层实现原理概述javaSE进阶-哈希表 为了满足hashmap集合的不重复存储,为什么要重写hashcode和equals方法? 首先理解一下hashmap的插入元素的前提: hashmap会根据元素的hashcode取模进行比较,当…...

WPF列表性能提高技术
WPF列表性能提高技术 WPF数据绑定系统不仅需要绑定功能,还需要能够处理大量数据而不会降低显示速度和消耗大量内存,WPF提供了相关的控件以提高性能,所有继承自ItemsControl的控件都支持该技术。 虚拟化 UI虚拟化是列表仅仅为当前显示项创建…...
 从初级到高级的综合指南(2))
掌握 BERT:自然语言处理 (NLP) 从初级到高级的综合指南(2)
BERT的先进技术 当您精通 BERT 后,就该探索先进技术以最大限度地发挥其潜力。在本章中,我们将深入研究微调、处理词汇外单词、领域适应,甚至从 BERT 中提取知识的策略。 微调策略:掌握适应 微调 BERT 需要仔细考虑。您不仅可以微调…...
【算法优选】 二分查找专题——贰
文章目录 😎前言🌲[山脉数组的峰顶索引](https://leetcode.cn/problems/peak-index-in-a-mountain-array/)🚩题目描述:🚩算法思路🚩代码实现: 🌴[寻找峰值](https://leetcode.cn/pro…...

SQL 的优化
SQL 优化是指对数据库查询语句进行优化,以提高查询性能和效率。下面列出了一些常见的 SQL 优化技巧: 1、索引优化 (1)使用适当的索引来加速查询操作。在频繁用于查询的列上创建索引,特别是在 WHERE 条件、JOIN 条件和…...

华为云云耀云服务器L实例评测|华为云上的CentOS性能监测与调优指南
目录 引言 编辑1 性能调优的基本要素 2 性能监控功能 2.1 监控数据指标 2.2 数据历史记录 2.3 多种统计指标 3 性能优化策略 3.1 资源分配 3.2 磁盘性能优化 3.3 网络性能优化 3.4 操作系统参数和内核优化 结论 引言 在云计算时代,性能优化和调优对于…...

Go If流程控制与快乐路径原则
Go if流程控制与快乐路径原则 文章目录 Go if流程控制与快乐路径原则一、流程控制基本介绍二、if 语句2.1 if 语句介绍2.2 单分支结构的 if 语句形式2.3 Go 的 if 语句的特点2.3.1 分支代码块左大括号与if同行2.3.2 条件表达式不需要括号 三、操作符3.1 逻辑操作符3.2 操作符的…...

yolov8 strongSORT多目标跟踪工具箱BOXMOT
1 引言 多目标跟踪MOT项目在Github中比较完整有:BOXMOT , 由mikel brostrom提供。在以前的版本中,有yolov5deepsort(版本v3-v5), yolov8strongsort(版本v6-v9),直至演变…...

如何开发一款跑酷游戏?
跑酷游戏(Parkour Game)是一种流行的视频游戏类型,玩家需要在游戏中控制角色进行极限动作、跳跃、爬墙和各种动作,以完成各种挑战和任务。如果你有兴趣开发一款跑酷游戏,以下是一些关键步骤和考虑事项: 游…...

UE5 3D Widget 渲染优化:告别动态模糊与重影困扰
1. 3D Widget动态模糊问题的根源剖析 第一次在UE5项目中使用3D Widget展示动态角色动画时,我被那些飘忽不定的睫毛重影彻底搞懵了。明明在静态预览时一切正常,但只要角色开始眨眼或做表情,睫毛和发丝边缘就会出现诡异的拖影效果,就…...

B站API数据采集终极指南:5个高效反爬虫策略与实战技巧
B站API数据采集终极指南:5个高效反爬虫策略与实战技巧 【免费下载链接】bilibili-api 哔哩哔哩常用API调用。支持视频、番剧、用户、频道、音频等功能。原仓库地址:https://github.com/MoyuScript/bilibili-api 项目地址: https://gitcode.com/gh_mirr…...

5个技巧快速掌握Fire Dynamics Simulator:从零到火灾模拟专家的完整指南
5个技巧快速掌握Fire Dynamics Simulator:从零到火灾模拟专家的完整指南 【免费下载链接】fds Fire Dynamics Simulator 项目地址: https://gitcode.com/gh_mirrors/fd/fds 你是否曾好奇,当火灾发生时,烟雾如何在建筑中扩散࿱…...

MSP430铁电超值系列MCU:25美分实现25种外设的嵌入式设计实战
1. 项目概述:为什么是MSP430铁电超值系列?在嵌入式开发的广阔世界里,选型往往是项目成败的第一步。面对琳琅满目的微控制器(MCU),工程师们常常在性能、成本、功耗和开发便利性之间反复权衡。今天我想和大家…...

书成紫微动,律定凤凰驯:别信 “阿紫受控” 的鬼话,海棠山铁哥才是这句诗的正主
“书成紫微动,律定凤凰驯”本是华夏文德盛世的正统谶语, 却在流量的漩涡里被篡改成权谋剧本。 剥离谣言滤镜,回归文本与现世, 世人终将看清: “阿紫受控”纯属无稽, 海棠山铁哥,才是这句古辞唯一…...

实战指南:深度掌握5大梯度下降优化器的可视化秘籍
实战指南:深度掌握5大梯度下降优化器的可视化秘籍 【免费下载链接】gradient_descent_viz interactive visualization of 5 popular gradient descent methods with step-by-step illustration and hyperparameter tuning UI 项目地址: https://gitcode.com/gh_mi…...

大语言模型记忆增强框架:LightMem原理、实现与工程实践
1. 项目概述:当大模型遇上“记忆”瓶颈最近在折腾大语言模型(LLM)应用开发的朋友,估计都遇到过同一个头疼的问题:模型记不住事儿。你精心设计了一个对话系统,希望它能记住用户的历史偏好,比如“…...

希伯来文语音上线倒计时72小时!ElevenLabs生产环境紧急修复清单:DNS预热、SSL证书SNI兼容、以及3个必须禁用的默认voice preset
更多请点击: https://intelliparadigm.com 第一章:希伯来文语音上线倒计时72小时:全局技术态势与交付承诺 希伯来文语音合成(Hebrew TTS)系统已进入最终验证阶段,核心引擎完成全链路压力测试,平…...

ITK-SNAP医学图像分割:精准医疗影像分析的利器
ITK-SNAP医学图像分割:精准医疗影像分析的利器 【免费下载链接】itksnap ITK-SNAP medical image segmentation tool 项目地址: https://gitcode.com/gh_mirrors/it/itksnap 面对复杂的医学影像数据,如何快速准确地进行三维解剖结构分割ÿ…...

ROFL-Player:基于C的多版本英雄联盟回放文件解析技术实现
ROFL-Player:基于C#的多版本英雄联盟回放文件解析技术实现 【免费下载链接】ROFL-Player (No longer supported) One stop shop utility for viewing League of Legends replays! 项目地址: https://gitcode.com/gh_mirrors/ro/ROFL-Player ROFL-Player是一款…...