如何设计一个网络爬虫?
网络爬虫也被称为机器人或蜘蛛,它被搜索引擎用于发现网络上的新内容或更新内容。内容可以是网页、图片、视频、PDF文件等。网络爬虫开始时会收集一些网页,然后跟随这些网页上的链接收集新的内容。图9-1展示了爬取过程的可视化示例。

爬虫的作用:
- • 搜索引擎索引:这是最常见的用例。爬虫收集网页以为搜索引擎创建本地索引。例如,Googlebot就是Google搜索引擎背后的网络爬虫。
- • 网络归档:这是从网络收集信息以保存数据供未来使用的过程。例如,许多国家的图书馆运行爬虫来归档网站。比如美国国会图书馆 和欧盟网站归档 。
- • 网络挖掘:网络的爆炸性增长为数据挖掘提供了前所未有的机会。网络挖掘有助于从互联网中发现有用的知识。例如,顶级金融公司使用爬虫下载股东会议和年度报告,以了解公司的关键倡议。
- • 网络监控:爬虫有助于在互联网上监控版权和商标侵权。例如,Digimarc 使用爬虫来发现盗版作品并进行报告。
开发网络爬虫的复杂度取决于我们打算支持的规模。它可能是一个只需几个小时就能完成的小项目,或者是需要一个专业工程团队不断改进的巨大项目。因此,我们将在下面探讨需要支持的规模和特性。
第一步 - 理解问题并确定设计范围
网络爬虫的基本算法很简单:
- 1. 给定一组URL,下载由这些URL指向的所有网页。
- 2. 从这些网页中提取URL。
- 3. 将新的URL添加到待下载的URL列表中。重复这三个步骤。
网络爬虫真的像这个基本算法那样简单吗?并非如此。设计一个可扩展的可大规模网络爬虫是一项极其复杂的任务。在面试时间内设计一个大规模的网络爬虫对任何人来说都不太可能。在开始设计之前,我们必须提问以理解需求并确定设计范围:
候选人:爬虫的主要目的是什么?它是用于搜索引擎索引、数据挖掘,还是其他什么?
面试官:搜索引擎索引。
候选人:网络爬虫每月收集多少网页?
面试官:10亿个网页。
候选人:包括哪些内容类型?仅HTML,还是也包括PDF和图片等其他内容类型?
面试官:仅HTML。
候选人:我们应该考虑新添加或编辑过的网页吗?
面试官:是的,我们应该考虑新添加或编辑过的网页。
候选人:我们需要存储从网络爬取的HTML页面吗?
面试官:是的,存储时间长达5年。
候选人:我们如何处理具有重复内容的网页?
面试官:应忽略具有重复内容的页面。
以上是我们向面试官提问的一些样本问题。理解需求和澄清歧义非常重要。即使你被要求设计一个像网络爬虫这样的需求清晰的产品,你和你的面试官可能也会有不同的侧重。
除了需要与面试官澄清的功能,还要注意记录下一个好的网络爬虫的以下特点:
- • 可扩展性:网络非常庞大。那里有数十亿的网页。网络爬取应该并行化并且极其高效。
- • 稳健性:网络充满了陷阱。糟糕的HTML、无响应的服务器、崩溃、恶意链接等都很常见。爬虫必须处理所有的边缘情况。
- • 礼貌性:爬虫在短时间内不应向网站发送太多请求。
- • 可扩展性:系统应该足够灵活,以便在支持新的内容类型时只需要最小的改变。例如,如果我们将来想要爬取图像文件,我们应该不需要重新设计整个系统。
粗略估计
以下估计基于许多假设,与面试官沟通以达成共识非常重要。
- • 假设每个月下载10亿个网页。
- • QPS:1,000,000,000 / 30天 / 24小时 / 3600秒 = 每秒大约400个网页。
- • 峰值QPS = 2 * QPS = 800
- • 假设平均网页大小为500k。
- • 10亿页面 x 500k = 每月需要500TB存储。如果你对数字存储单位不清楚,请回去复习“2的力量”那一篇。
- • 假设数据存储五年,500TB * 12个月 * 5年 = 30PB。存储五年的内容需要30PB的存储空间。
第二步 - 提出高级设计并获得认同
一旦需求明确,我们就可以进行高级设计。受到以往关于网络爬虫的研究的启发,我们提出了如图9-2所示的高级设计。

首先,我们探索每个设计组件以理解他们的功能。然后,我们逐步检查爬虫的工作流程。
种子URL
网络爬虫使用种子URL作为爬行过程的起点。例如,要从大学的网站上爬取所有网页,选择种子URL的直观方式是使用大学的域名。
要爬取整个网络,我们需要在选择种子URL时富有创造性。一个好的种子URL作为一个好的起点,爬虫可以利用它遍历尽可能多的链接。通常的策略是将整个URL空间分割成更小的部分。首先提出的方法是基于区域性,因为不同的国家可能有不同的热门网站。另一种方式是根据主题选择种子URL;例如,我们可以将URL空间划分为购物、体育、健康保健等。种子URL的选择是一个开放性问题。你不需要给出完美的答案。只需给面试官给出你的思考即可。
URL集合
大多数现代网络爬虫将爬行状态分为两种:待下载和已下载。存储待下载URL的组件称为URL集合。你可以将其视为先进先出(FIFO)队列。要获取关于URL集合的详细信息,请参考深入了解部分。
HTML下载器
HTML下载器从互联网上下载网页。这些URL由URL集合提供。
DNS解析器
要下载一个网页,必须将URL转换为IP地址。HTML下载器调用DNS解析器,获取URL对应的IP地址。例如,URL http://www.wikipedia.org 被转换为IP地址198.35.26.96。
内容解析器
下载一个网页后,必须对其进行解析和验证,因为格式不正确的网页可能会引发问题并浪费存储空间。在爬虫服务器中实现内容解析器会减慢爬行过程。因此,内容解析器最好是一个独立的组件。
内容爬过了吗?
在线研究显示,29%的网页是重复内容,这可能导致相同的内容被多次存储。我们引入“内容爬过了吗?”数据结构来消除数据冗余并缩短处理时间。它有助于检测以前存储在系统中的新内容。比较两个HTML文档,我们可以逐字符地比较它们。然而,这种方法慢且耗时,特别是当涉及到数十亿个网页时。一种有效的方法是比较两个网页的哈希值。
内容存储
这是一个用于存储HTML内容的存储系统。存储系统的选择取决于诸如数据类型、数据大小、访问频率、寿命等因素。使用的存储介质包括磁盘和内存。
- • 因为数据集过大,无法全部放入内存,所以大部分内容存储在磁盘上。
- • 受欢迎的内容保留在内存中以减少延迟。
URL提取器
URL提取器从HTML页面中解析并提取链接。图9-3显示了一个链接提取过程。通过添加“https://en.wikipedia.org”前缀,将相对路径转换为绝对URL。

URL过滤器
URL过滤器排除某些内容类型,文件扩展名,错误链接和“黑名单”网站中的URL。
URL爬过了吗?
“URL爬过了吗?”是一个跟踪之前访问过的URL或已经在前沿的URL的数据结构。“URL爬过了吗?”有助于避免多次添加同一URL,因为这可能会增加服务器负载并可能导致潜在的无限循环。
布隆过滤器和哈希表是实现“URL爬过了吗?”组件的常见技术。我们在这里不会详细介绍布隆过滤器和哈希表的实现。
URL存储
URL存储存放已经访问过的URL。
到目前为止,我们已经讨论了每个系统组件。接下来,我们将它们组合在一起,以解释工作流程。
网络爬虫工作流程
为了更好地逐步解释工作流程,我们在设计图中添加了序列号,如图9-4所示。

步骤1:将种子URL添加到URL集合。
步骤2:HTML下载器从URL集合获取URL列表。
步骤3:HTML下载器从DNS解析器获取URL的IP地址并开始下载。
步骤4:内容解析器解析HTML页面并检查页面是否有误。
步骤5:在内容被解析和验证后,它被传递到“内容已爬过?”组件。
步骤6:“内容已爬过”组件检查HTML页面是否已经在存储中。
- • 如果在存储中,这意味着不同URL中的相同内容已经被处理过。在这种情况下,HTML页面被丢弃。
- • 如果不在存储中,系统之前没有处理过相同的内容。内容被传递到链接提取器。
步骤7:链接提取器从HTML页面中提取链接。
步骤8:提取的链接被传递给URL过滤器。
步骤9:链接被过滤后,它们被传递给“URL已爬过?”组件。
步骤10:“URL已爬过”组件检查URL是否已经在存储中,如果是,那么它已经被处理过,无需做任何事情。
步骤11:如果URL之前没有被处理过,那么它被添加到URL集合。
第三步 - 深入设计
到现在为止,我们已经讨论了高层设计。接下来,我们将深入讨论最重要的构建组件和技术:
- • 深度优先搜索(DFS)与广度优先搜索(BFS)
- • URL集合
- • HTML下载器
- • 健壮性
- • 可扩展性
- • 检测并避免问题内容
DFS与BFS
你可以将网络视为一个有向图,其中网页作为节点,超链接(URL)作为边。爬取过程可以被看作是从一个网页到其他网页的有向图遍历。两种常见的图遍历算法是DFS和BFS。然而,DFS通常不是一个好的选择,因为在网络爬虫的场景下DFS的深度可能非常深。
网络爬虫常用的是BFS,它通过一个先进先出(FIFO)队列来实现。在一个FIFO队列中,URL按照他们入队的顺序出队。然而,这种实现有两个问题:
- • 大多数来自同一网页的链接都链接回同一host。在图9-5中,wikipedia.com中的所有链接都是内部链接,使得爬虫忙于处理来自同一主机(wikipedia.com)的URL。当爬虫试图并行下载网页时,维基百科的服务器将被请求淹没。这被认为是“不礼貌的”。

• 标准的BFS并没有考虑到URL的优先级。网络很大,不是每个页面的质量和重要性都一样。因此,我们可能希望根据他们的页面排名,网页流量,更新频率等来对URL进行优先排序。
URL集合
URL集合有助于解决这些问题。URL集合是一个存储待下载URL的数据结构。URL集合是确保礼貌、URL优先级和新鲜度的重要组件。
礼貌
通常,网络爬虫应避免在短时间内向同一主机服务器发送过多的请求。发送过多的请求被视为“不礼貌的”,甚至被视为拒绝服务(DOS)攻击。例如,如果没有任何限制,爬虫可以每秒向同一网站发送数千个请求。这可能会压垮网络服务器。
实施礼貌的一般思想是一次从同一主机下载一个页面。并且在两个下载任务之间添加延迟。礼貌约束是通过维护从网站主机名到下载(工作线程)的映射来实现的。每个下载线程都有一个独立的FIFO队列,并且只从该队列下载URL。图9-6显示了管理礼貌的设计。
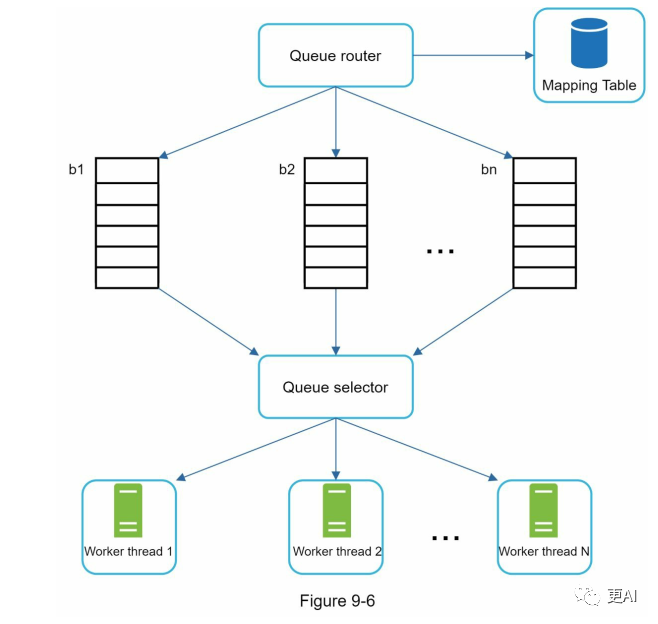
- • 队列路由器:确保每个队列(b1,b2,... bn)只包含来自同一主机的URL。
- • 映射表:将每个主机映射到一个队列。
- • FIFO队列b1,b2至bn:每个队列包含来自同一主机的URL。
- • 队列选择器:每个工作线程映射到一个FIFO队列,它只从该队列下载URL。队列选择逻辑由队列选择器完成。
- • 工作线程1到N。工作线程一次从同一主机下载一个网页。可以在两个下载任务之间添加延迟。
优先级
论坛上的随机帖子与首页上的帖子具有不同的权重。尽管它们都包含“Apple”关键字,但爬虫优先爬取Apple首页是更成熟的做法。
我们根据有用性对URL进行优先级排序,这可以通过PageRank ,网站流量,更新频率等来衡量。"优先级处理器"是处理URL优先级的组件。有关这个概念的深入信息,请参考参考资料。
图9-7显示了管理URL优先级的设计。
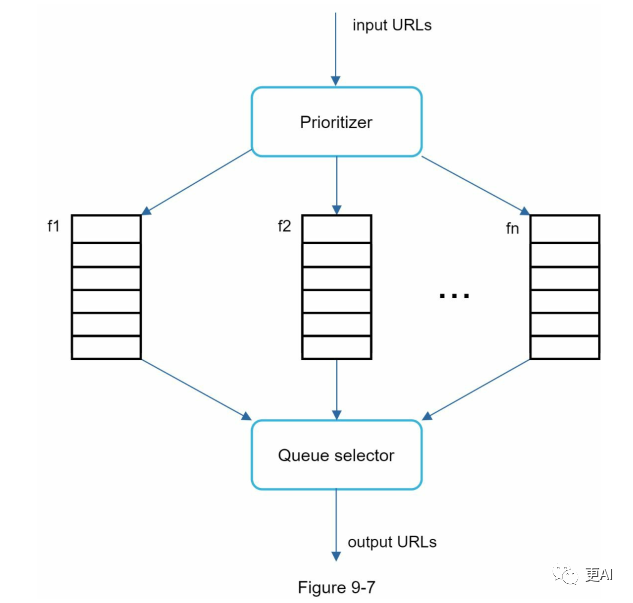
- • 优先级处理器:它接受URL作为输入并计算优先级。
- • 队列f1至fn:每个队列都有一个分配的优先级。具有高优先级的队列具有更高的被选择概率。
- • 队列选择器:随机选择一个队列,偏向于具有较高优先级的队列。
图9-8展示了URL集合设计,它包含两个模块:
- • 前队列:管理优先级
- • 后队列:管理礼貌性

image-
新鲜度
网页一直处于不断地添加、删除和编辑的状态。网络爬虫必须定期重新爬取已下载的页面,以保持我们的数据集新鲜。重新爬取所有的URL既耗时又资源密集。以下列出了一些优化新鲜度的策略:
- • 基于网页的更新历史进行重新爬取。
- • 对URL进行优先级排序,并更频繁地重新爬取重要的页面。
URL Frontier的存储
在现实世界中为搜索引擎进行爬取时,集合中的URL数量可能达到几亿。把所有东西都放在内存中既不持久也不可扩展。但是磁盘速度慢,我们也不希望把所有东西都存储在磁盘中;并且它很容易成为爬取的瓶颈。
我们采取了一种混合方法。大部分URL存储在磁盘上,因此存储空间不是问题。为了减少从磁盘读取和写入磁盘的成本,我们在内存中维护用于入队/出队操作的缓冲区。缓冲区中的数据会定期写入磁盘。
HTML下载器
HTML下载器使用HTTP协议从互联网下载网页。在讨论HTML下载器之前,我们先看一下机器人排除协议。
Robots.txt
Robots.txt,也被称为机器人排除协议,是网站用来与爬虫交流的一种标准。它指定了爬虫允许下载的页面。在尝试爬取一个网站之前,爬虫应该先检查其对应的robots.txt文件,并遵循其规则。
为了避免重复下载robots.txt文件,我们将文件的结果缓存在内存中。该文件会定期下载并保存到缓存中。这是从https://www.amazon.com/robots.txt获取的一部分robots.txt文件。像creatorhub这样的目录对于Google bot来说是禁止访问的。
User-agent: Googlebot Disallow: /creatorhub/* Disallow: /rss/people//reviews Disallow: /gp/pdp/rss//reviews Disallow: /gp/cdp/member-reviews/ Disallow: /gp/aw/cr/
除了robots.txt,性能优化是我们将要涉及到的HTML下载器的另一个重要概念。
性能优化
以下是HTML下载器的性能优化列表。
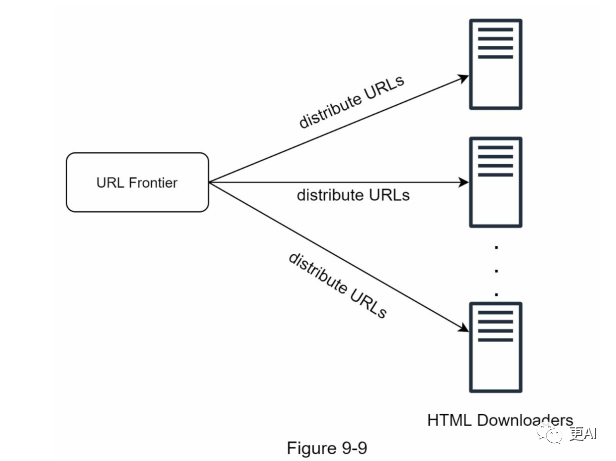
1. 分布式爬取
为了达到高性能,爬取工作分布在多个服务器上,并且每个服务器运行多个线程。URL空间被划分为更小的片段,因此,每个下载器负责URL的一个子集。图9-9展示了分布式爬取的一个例子。
2. 缓存DNS解析器
由于许多DNS接口的同步性质,DNS请求可能需要一些时间,这使得DNS解析器成为爬虫的瓶颈。DNS响应时间范围从10ms到200ms。一旦一个爬虫线程进行了对DNS的请求,其他线程就会被阻塞,直到第一个请求完成。为了避免频繁调用DNS,维护我们自己的DNS缓存是一种有效的速度优化技术。我们的DNS缓存保存域名到IP地址的映射,并由定时任务定期更新。
3. 区域性
地理分布爬取服务器。当爬取服务器更接近网站主机时,可以缩短下载时间。区域性设计适用于大多数系统组件:爬取服务器、缓存、队列、存储等。
4. 短超时
一些网页服务器响应慢或者可能根本不响应。为了避免长时间等待,我们设定了最大等待时间。如果一个主机在预定的时间内没有响应,爬虫将停止该任务并爬取其他页面。
鲁棒性
除了性能优化外,鲁棒性也是一个重要的考虑因素。我们提出了几种提高系统鲁棒性的方法:
- • 一致性哈希:这有助于在下载器之间分配负载。新的下载服务器可以通过一致性哈希被添加或删除。详细信息请参前面的文章:设计一致性哈希。
- • 保存爬取状态和数据:为了防止故障,爬取状态和数据被写入到存储系统。通过加载保存的状态和数据,可以轻松地重新启动中断的爬取。
- • 异常处理:在大规模系统中,错误是不可避免且常见的。爬虫必须优雅地处理异常,而不是让系统崩溃。
- • 数据验证:这是防止系统错误的重要手段。
可扩展性
几乎每个系统都会发展,所以我们的一个设计目标是使系统足够灵活,以支持新的内容类型。爬虫可以通过插入新的模块来扩展。图9-10显示了如何添加新的模块。
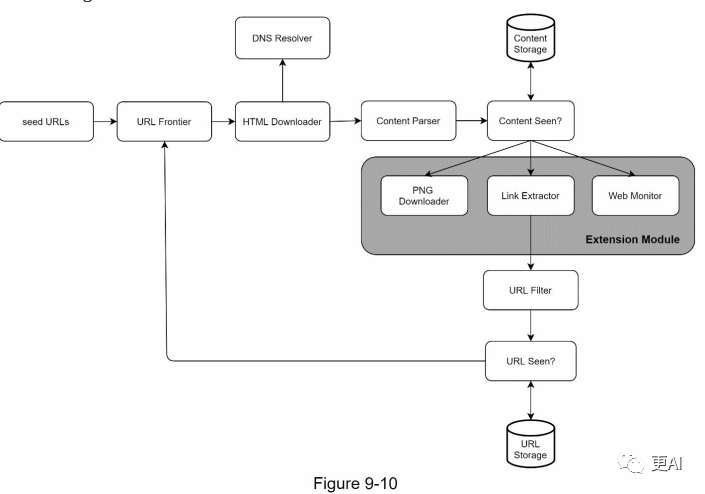
- • PNG下载器模块被插入以下载PNG文件。
- • 添加了网页监视模块,以监控网络并防止侵犯版权和商标。
检测并避免问题内容
本节讨论了冗余、无意义或有害内容的检测和防止。
1. 冗余内容
如前所述,近30%的网页是重复的。哈希或校验和有助于检测重复内容。
2. 蜘蛛陷阱
蜘蛛陷阱是一个会导致爬虫陷入无限循环的网页。例如,一个无限深的目录结构如下所示: http://www.spidertrapexample.com/foo/bar/foo/bar/foo/bar/...
通过设置URL的最大长度,可以避免这样的蜘蛛陷阱。然而,没有一种万全之策可以检测蜘蛛陷阱。包含蜘蛛陷阱的网站很容易识别,因为在这些网站上发现的网页数量异常大。开发自动避免蜘蛛陷阱的算法很难;但是,用户可以手动验证并识别蜘蛛陷阱,并将这些网站从爬虫中排除或应用一些自定义的URL过滤器。
3. 数据噪声
有些内容的价值很小或者没有价值,如广告、代码片段、垃圾URL等。这些内容对爬虫无用,如果可能,应该被排除。
步骤4 - 总结
在本章中,我们首先讨论了好的爬虫的特点:可扩展性、礼貌性、可扩展性和鲁棒性。然后,我们提出了一个设计并讨论了关键组件。构建一个可扩展的网页爬虫并非易事,因为网页数量庞大且充满陷阱。尽管我们已经涵盖了许多话题,但我们仍然遗漏了许多相关的讨论点:
- • 服务器端渲染:许多网站使用如JavaScript、AJAX等脚本在加载中生成链接。如果我们直接下载和解析网页,我们将无法获取动态生成的链接。为了解决这个问题,我们在解析页面之前首先进行服务器端渲染(也称为动态渲染)。
- • 过滤掉不需要的页面:由于存储容量和爬取资源有限,反垃圾组件在过滤低质量和垃圾页面方面是很有用也是很有必有得。
- • 数据库复制和分片:使用复制和分片等技术来提高数据层的可用性、可扩展性和可靠性。
- • 水平扩展:对于大规模爬取,需要数百甚至数千台服务器来执行下载任务。关键是保持服务器无状态。
- • 可用性、一致性和可靠性:这些概念是任何大型系统成功的核心。我们在第前面的文章细讨论了这些概念。忘了的话可以翻回去看看。
- • 分析:收集和分析数据是任何系统的重要部分
相关文章:
如何设计一个网络爬虫?
网络爬虫也被称为机器人或蜘蛛,它被搜索引擎用于发现网络上的新内容或更新内容。内容可以是网页、图片、视频、PDF文件等。网络爬虫开始时会收集一些网页,然后跟随这些网页上的链接收集新的内容。图9-1展示了爬取过程的可视化示例。 爬虫的作用ÿ…...

风储联合系统的仿真模型研究
摘要 风能是目前国内外应用较为广泛的一种绿色可再生能源,近几年我国风电产业的发展十分迅速。然后,越来越多的风力发电系统建并网,风力发电产生的电能受外界因素影响较大,具有一定的随机性和波动性,给并网后的电力系统…...

JS VUE 用 canvas 给图片加水印
最近写需求,遇到要给图片加水印的需求。 刚开始想的方案是给图片上覆盖一层水印照片,但是这样的话用户直接下载图片水印也会消失。 后来查资料发现用 canvas 就可以给图片加水印,下面是处理过程。 首先我们要确认图片的格式,我们通…...
主动配电网故障恢复的重构与孤岛划分matlab程序
微❤关注“电气仔推送”获得资料(专享优惠) 参考文档: A New Model for Resilient Distribution Systems by Microgrids Formation; 主动配电网故障恢复的重构与孤岛划分统一模型; 同时考虑孤岛与重构的配电网故障…...

2023C语言暑假作业day6
1.选择题 1 1、以下叙述中正确的是( ) A: 只能在循环体内和switch语句体内使用break语句 B: 当break出现在循环体中的switch语句体内时,其作用是跳出该switch语句体,并中止循环体的执行 C: continue语句的作用是:在执…...

java try 自动关闭流
Java Try自动关闭流实现步骤 在开始之前,我们先来了解一下整个实现过程的流程。下面的表格展示了实现"try自动关闭流"的步骤: 步骤 描述 1 创建需要操作的流对象 2 在try语句块中使用流对象 3 在try语句块中自动关闭流对象 接下来…...

WebDAV之π-Disk派盘 + 元思笔记
元思笔记是一款面向大众的卡片笔记软件,解决了笔记类软件的一个痛点:绝大多数人都很难坚持每天记一点东西。任何笔记工具,不论是纸笔还是电子,能够让人坚持记录就是好工具。 元思笔记是一款基于卢曼卡片盒的移动端卡片笔记软件;隐私优先,本地存储数据且支持云备份;丰富的…...

electron自定义标题栏,并监听双击以及右键改变窗口大小。
1、前言 当需要在标题栏添加一些额外的操作时候,比如添加 帮助 菜单,自带的标题栏开发起来比较困难(没了解不知道能不能实现),这时候,自己写一个标题栏就比较方便。 2、实现 首先是禁止掉原先的标题栏&a…...
Beam Focusing for Near-Field Multi-User MIMO Communications阅读笔记
abstract 大天线阵列和高频段是未来无线通信系统的两个关键特征。大规模天线与高传输频率的组合通常导致通信设备在近场(菲涅耳)区域中操作。在本文中,我们研究了潜在的波束聚焦,可行的近场操作,在促进高速率多用户下…...
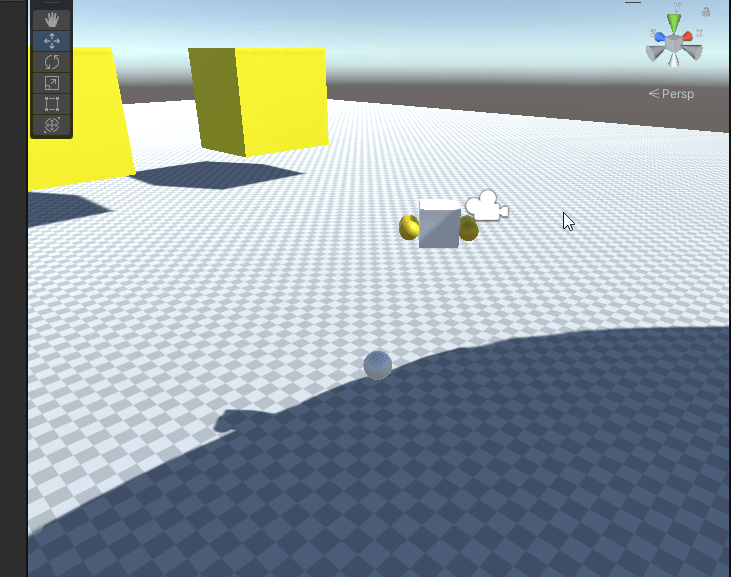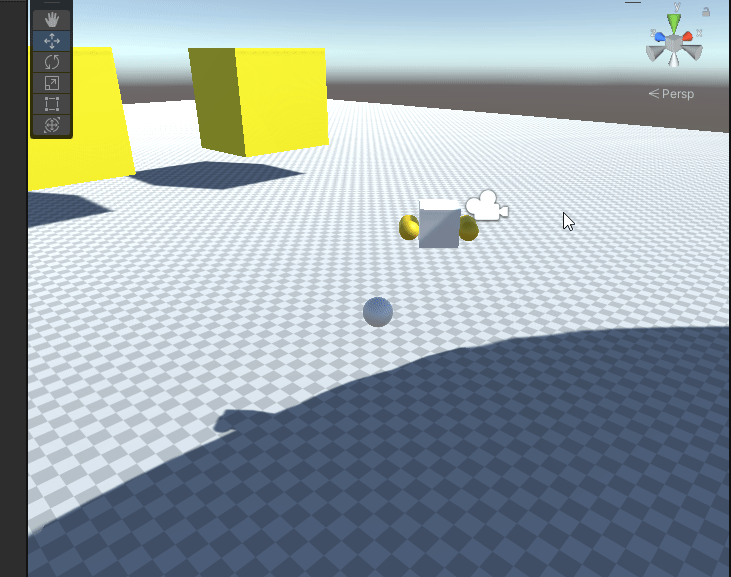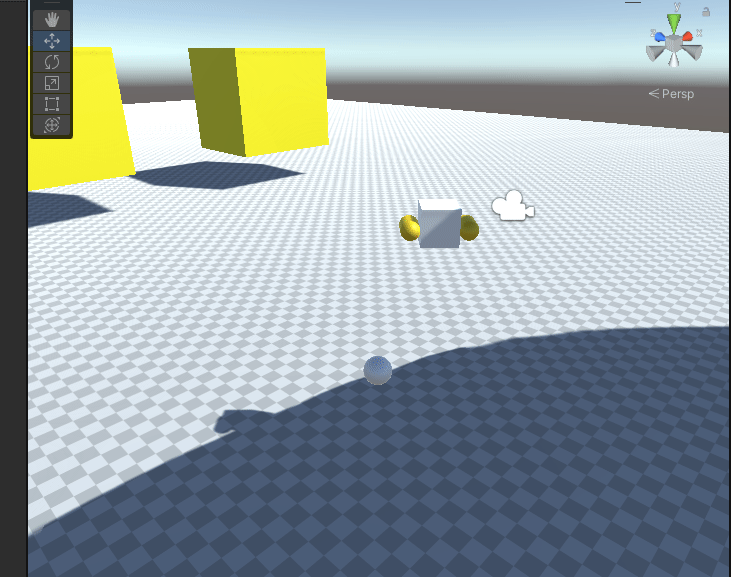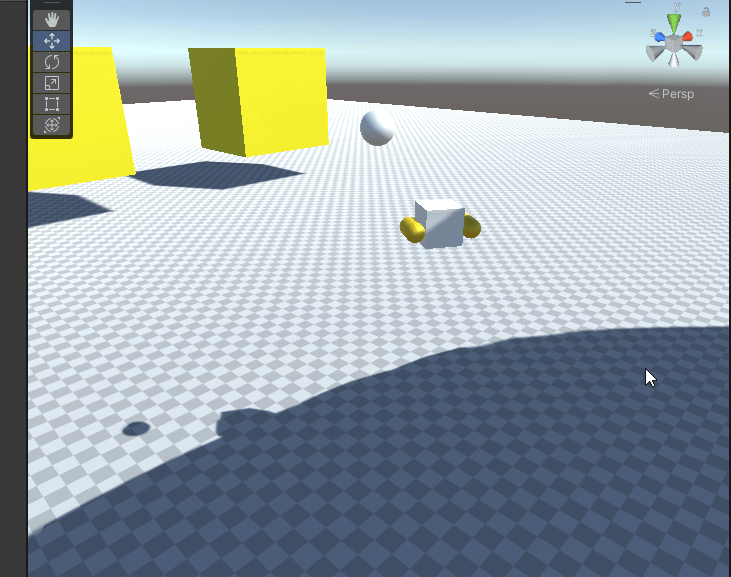
Unity基础课程之物理引擎6-关于物理材质的使用和理解
每个物体都有着不同的摩擦力。光滑的冰面摩擦力很小,而地毯表面的摩擦力则很大。另外每种材料也有着不同的弹性,橡皮表面的弹性大,硬质地面的弹性小。在Unity中这些现象都符合日常的理念。虽然从原理上讲,物体的摩擦力和弹性有着更…...

用c语言写一个剪刀石头布小游戏
用简单的生成随机数,来对电脑进行的选择。再用if else和swtich语句实现输出和输赢的判断 test.c: #define _CRT_SECURE_NO_WARNINGS#include "game.h"void menu() {printf("There can be choose for you,type:\n");printf("0 for rock\n&…...

【MySQL入门到精通-黑马程序员】MySQL基础篇-DCL
文章目录 前言一、DCL-介绍二、DCL-管理用户二、DCL-权限控制总结 前言 本专栏文章为观看黑马程序员《MySQL入门到精通》所做笔记,课程地址在这。如有侵权,立即删除。 一、DCL-介绍 DCL英文全称是Data Control Language(数据控制语言&#x…...
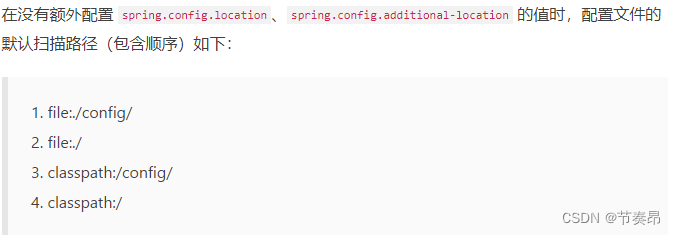
SpringBoot配置文件加载顺序
结论 参考文章: 链接: SpringBoot配置加载顺序 证明 下面是自己本地做的测试 每个配置里面是不同的端口号, 然后启动项目依次输入不同端口号看哪个能访问成功, 或者看启动日志的端口号是哪一个。 最终结果是 8204 —> 8205 —> 8202…...
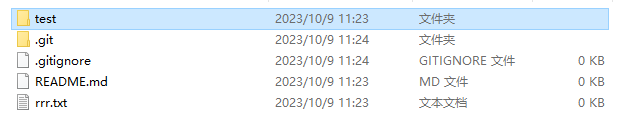
github小记(一):清除github在add或者commit之后缓存区
github清除在add或者commit之后缓存区 前言1. 第一步之后想要撤销2. 第二步之后想要撤销a. 改变一下rrr.txt的内容b. 想提交本地文件的test文件夹c. 我后悔了突然不想提交了 前言 github自用 一般github上代码提交顺序: 第一步: git add . or git ad…...
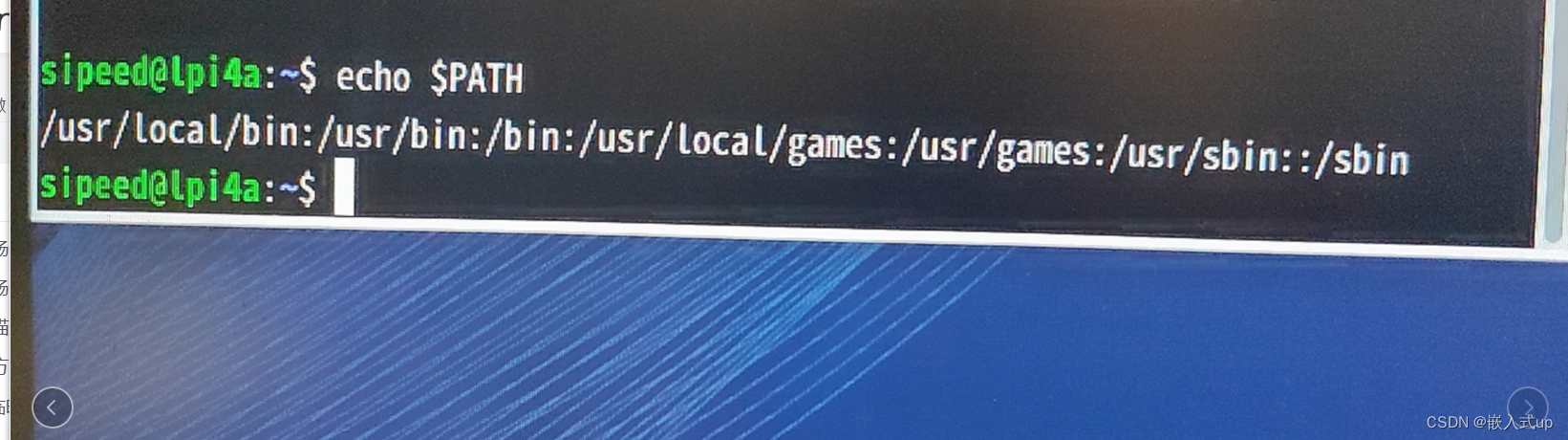
【Debian系统】:安装debian系统之后,很多命令找不到,需要添加sudo之后才能使用,以下解决方法
项目场景: 问题描述 解决方案: 1.临时解决方案 2.永久解决方案 1.首先打开编辑: 2.打开之后最后一行添加代码: 3.最后运行一遍 .bashrc 4.已经可以了,可以试试reboot,重启一下机子 一点一滴才能成长 …...
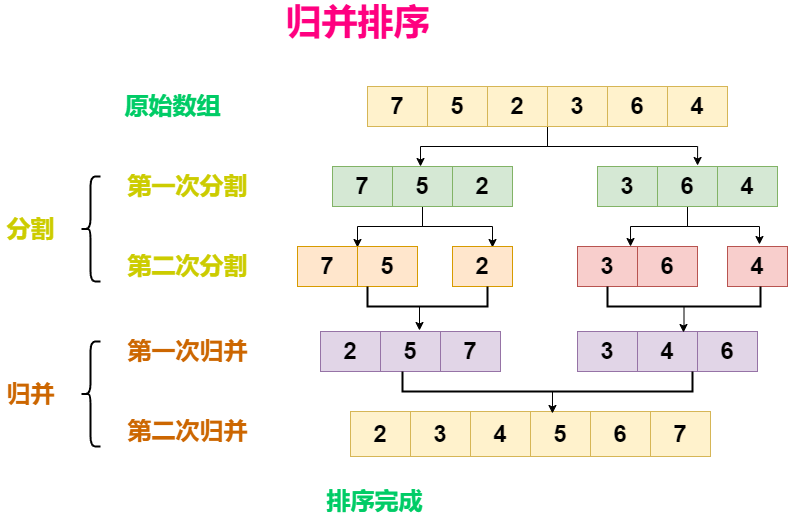
深入了解归并排序:原理、性能分析与 Java 实现
归并排序(Merge Sort)是一种高效且稳定的排序算法,其优雅的分治策略使它成为排序领域的一颗明珠。它的核心思想是将一个未排序的数组分割成两个子数组,然后递归地对子数组进行排序,最后将这些排好序的子数组合并起来。…...

docker stop了一个docker exec容器,要怎么再启动呢
docker restart <容器ID>...
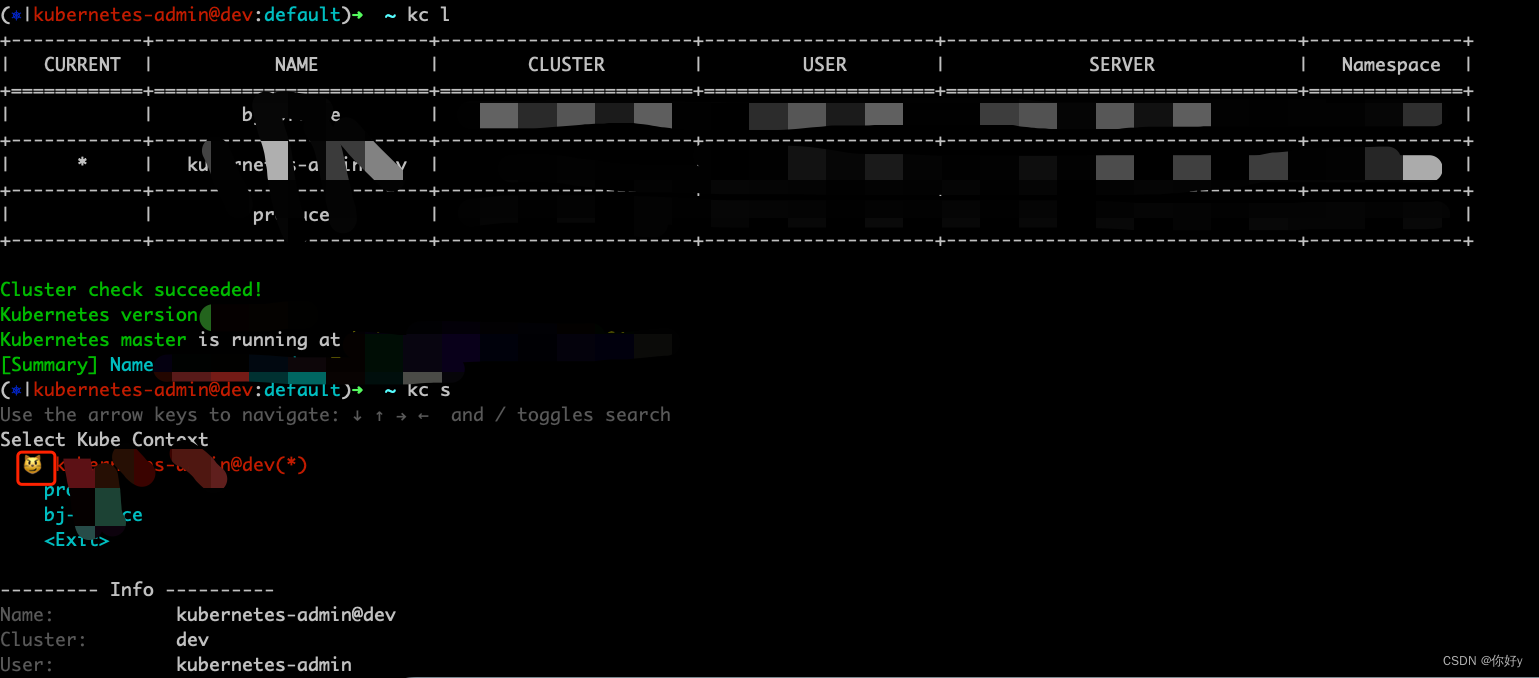
【总结】kubernates 插件工具总结
在此记录工作中用到的关于 kubernates 的插件小工具,以防以后忘记 1、能显示 kubernates 所处上下文的插件 kube-ps1 github 地址: https://github.com/jonmosco/kube-ps1 效果 2、能方便切换 kubernates 上下文的插件 kubecm github 地址࿱…...

RK3588平台产测之ArmSoM-W3 DDR带宽监控
1. 简介 专栏总目录 ArmSoM团队在产品量产之前都会对产品做几次专业化的功能测试以及性能压力测试,以此来保证产品的质量以及稳定性 优秀的产品都要进行多次全方位的功能测试以及性能压力测试才能够经得起市场的检验 2. 环境介绍 硬件环境: ArmSoM-W…...
基于SpringBoot的作业管理系统设计与实现
目录 前言 一、技术栈 二、系统功能介绍 学生管理 教师管理 班级管理 作业管理 作业提交管理 作业点评管理 教师作业发布 学生作业提交 学生作业点评 三、核心代码 1、登录模块 2、文件上传模块 3、代码封装 前言 使用旧方法对作业管理信息进行系统化管理已经不再…...

5步搭建Sunshine游戏串流服务器:打造你的私人云游戏平台
5步搭建Sunshine游戏串流服务器:打造你的私人云游戏平台 【免费下载链接】Sunshine Self-hosted game stream host for Moonlight. 项目地址: https://gitcode.com/GitHub_Trending/su/Sunshine Sunshine是一款功能强大的自托管游戏串流服务器,专…...
Pandas reset_index() 实战解析:从数据混乱到索引清晰)
(Python)Pandas reset_index() 实战解析:从数据混乱到索引清晰
1. 为什么你的Pandas数据总是乱糟糟? 每次处理完数据,看着那个乱七八糟的索引是不是特别头疼?我刚开始用Pandas的时候,经常遇到这样的问题:合并几个表格后索引重复了,分组统计后多出来一堆莫名其妙的层级&a…...

30ms低延迟投屏终极指南:用QtScrcpy实现专业级手游直播
30ms低延迟投屏终极指南:用QtScrcpy实现专业级手游直播 【免费下载链接】QtScrcpy Android实时投屏软件,此应用程序提供USB(或通过TCP/IP)连接的Android设备的显示和控制。它不需要任何root访问权限 项目地址: https://gitcode.com/barry-ran/QtScrcpy…...

【鸿蒙 HarmonyOS】从零到一:Node.js 环境配置与 DevEco Studio 无缝对接指南
1. 为什么需要Node.js环境? 如果你刚刚接触鸿蒙开发,可能对DevEco Studio里弹出的"Node.js not found"提示感到困惑。其实Node.js在鸿蒙生态中扮演着重要角色——它不仅是npm包管理器的运行环境,更是鸿蒙应用编译工具链的基础依赖。…...

SLO-Warden:基于错误预算的智能SLO守护平台设计与实践
1. 项目概述:一个面向SLO的智能守护者在云原生和微服务架构成为主流的今天,服务的稳定性和可靠性不再是“锦上添花”,而是“生死攸关”的底线。作为一线的运维工程师或SRE,我们每天都在和各种监控指标、告警风暴作斗争。传统的监控…...

小米路由器R3G刷机实战:从官方固件到蜜罐版MT工具箱的保姆级避坑指南
小米路由器R3G深度改造指南:解锁第三方固件的完整路线图 当你盯着家里那台性能日渐吃紧的小米路由器R3G时,是否想过它其实蕴藏着未被发掘的潜力?这款发布于数年前的中端路由器,凭借MT7621双核芯片和128MB内存的硬件基础࿰…...

怎样快速恢复损坏视频:3步实用MP4修复方案
怎样快速恢复损坏视频:3步实用MP4修复方案 【免费下载链接】untrunc Restore a truncated mp4/mov. Improved version of ponchio/untrunc 项目地址: https://gitcode.com/gh_mirrors/un/untrunc 你是否经历过相机突然断电导致视频文件损坏?或者传…...

从芯片选型到PCB布线:手把手拆解基于Zynq-7100的10Gbps雷达数据采集卡硬件设计
从芯片选型到PCB布线:Zynq-7100雷达数据采集卡硬件设计实战 在高速数据采集领域,10Gbps量级的实时信号处理对硬件设计提出了严苛挑战。当我们面对雷达回波、医学影像或工业检测等场景时,传统采集方案往往在吞吐量、延迟和同步精度上捉襟见肘。…...
)
Midjourney波普艺术风格生成失效真相(92%用户踩中的5个prompt结构陷阱)
更多请点击: https://intelliparadigm.com 第一章:Midjourney波普艺术风格生成失效的底层归因 波普艺术(Pop Art)风格在 Midjourney 中曾可通过 --style raw 配合关键词如 Andy Warhol, Ben-Day dots, bold outline, flat color …...

BEAGLE库终极指南:如何快速实现高性能系统发育分析
BEAGLE库终极指南:如何快速实现高性能系统发育分析 【免费下载链接】beagle-lib general purpose library for evaluating the likelihood of sequence evolution on trees 项目地址: https://gitcode.com/gh_mirrors/be/beagle-lib 你是否在系统发育分析中遇…...