AlphaPose Pytorch 代码详解(一):predict
前言
代码地址:AlphaPose-Pytorch版
本文以图像 1.jpg(854x480)为例对整个预测过程的各个细节进行解读并记录
python demo.py --indir examples/demo --outdir examples/res --save_img

1. YOLO
1.1 图像预处理
- cv2读取BGR图像
img [480,854,3] (h,w,c) - 按参数
inp_dim=608,将图像保持长宽比缩放至[341,608,3],并以数值为128做padding至[608,608,3] - BGR转RGB、维度处理、转tensor、数据类型转float、数值除以255做归一化,
[1,3,608,608] (b,c,h,w)
输出:
img: [1,3,608,608] (yolo输入图像)
orig_img: [480,854,3] (原始BGR图像)
im_name: 'examples/demo/1.jpg'
im_dim_list:[854,480,854,480](原图尺寸, 用于把yolo的输出坐标转换到原图坐标系)
1.2 yolo 模型推理
输入:img[1,3,608,608]
输出:pred[1,22743,85]
1 = b a t c h s i z e \mathrm{1=batchsize} 1=batchsize
22743 = [ ( 608 / 32 ) 2 + ( 608 / 16 ) 2 + ( 608 / 8 ) 2 ] × 3 22743=[(608/32)^2+(608/16)^2+(608/8)^2]\times3 22743=[(608/32)2+(608/16)2+(608/8)2]×3
85 = [ x , y , w , h , c o n f , 80 c l a s s e s ] \mathrm{85=[x,y,w,h,conf,80classes]} 85=[x,y,w,h,conf,80classes]
1.3 输出后处理
(1)第一阶段
- 坐标
xywh转xyxy - 对
batchsize循环,[22743,85]转[22743,7], 7 = [ x , y , x , y , c o n f , c l a s s s c o r e , c l a s s ] \mathrm{7=[x,y,x,y,conf,class\ score,class]} 7=[x,y,x,y,conf,class score,class],即80类得分转换为得分最高的类别索引及其得分 - 去除 c o n f ≤ 0.05 \mathrm{conf\le0.05} conf≤0.05 的项
[37,7] - 保留类别为人的项,并且按
conf从高到低排序,得到结果img_pred[19,7] - nms去除重复目标
[19,7]->[6,7] - 添加
batch_idx这里batchsize为1所以都是0,[6,7]->[6,8], 8 = [ b a t c h i d x , x , y , x , y , c o n f , c l a s s s c o r e , c l a s s ] \mathrm{8=[batch\ idx, x,y,x,y,conf,class\ score,class]} 8=[batch idx,x,y,x,y,conf,class score,class] - 坐标数值转换,从
[608,608]转到原图坐标[854,480],并把坐标clamp在[0,w] [0,h]之间
输出:
orig_img:[480,854,3] (原始BGR图像)
im_name:'examples/demo/1.jpg'
boxes: [6,4] (x,y,x,y)(原图坐标系)
scores: [6,1] (conf)
NMS 细节
nms_conf=0.6- 将
img_pred中的第一项放到结果中 - 剩余所有项与结果中的最后一项计算iou,保留
iou<nms_conf的项作为新的img_pred - 循环直到
img_pred中没有目标 - 当经过nms后的目标数量大于100个,会把
nms_conf-0.05,从最初的img_pred开始重新进行nms
(2)第二阶段
- 原始图像
orig_img [480,854,3]BGR转RGB、维度处理、转tensor、数据类型转float、数值除以255做归一化,得到inp [3,480,854] - 对三通道做处理
inp[0].add_(-0.406), inp[1].add_(-0.457), inp[2].add_(-0.480) - 扩大
boxes中目标框的范围,并把左上角坐标存入pt1,右下角坐标存入pt2 - 根据
boxes把每个目标从图中抠出来,通过保比例缩放+zero padding,统一成[3,320,256]大小的图像存入inps
输出:
inps: [6,3,320,256] (检测目标的子图像,作为Alphapose的输入)
orig_img:[480,854,3] (原始BGR图像)
im_name:'examples/demo/1.jpg'
boxes: [6,4] (x1,y1,x2,y2)(yolo原始输出,原图坐标系)
scores: [6,1] (yolo输出conf)
pt1: [6,2] (x1,y1)(yolo输出扩大后坐标,原图坐标系)
pt2: [6,2] (x2,y2)(yolo输出扩大后坐标,原图坐标系)
2. POSE
2.1 pose 模型推理
输入:inps[6,3,320,256]
输出:hm[6,17,80,64],即6个目标,每个目标17个关键点对应的热力图
2.2 输出后处理
(1)第一阶段:热力图转坐标
- 获取
hm[6,17,80,64]中每个关键点的热力图中最大值的索引preds[6,17,2] - 由于
opt.matching=False,此处使用简单的后处理,源码如下
以preds中某个索引[x,y]为例,取出其热力图中相邻的上下左右四个位置的值,并且分别在 x x x 和 y y y 轴上往较高的方向偏移 0.25 0.25 0.25
以 x x x 轴为例: p l e f t = h m [ y ] [ x − 1 ] p_\mathrm{left}=\mathrm{hm}[y][x-1] pleft=hm[y][x−1], p r i g h t = h m [ y ] [ x + 1 ] p_\mathrm{right}=\mathrm{hm}[y][x+1] pright=hm[y][x+1],若 p l e f t > p r i g h t p_\mathrm{left}>p_\mathrm{right} pleft>pright则 x + 0.25 x+0.25 x+0.25,若 p l e f t = p r i g h t p_\mathrm{left}=p_\mathrm{right} pleft=pright 则 x x x 保持不变
最后会在所有的坐标值上 + 0.2 +0.2 +0.2
for i in range(preds.size(0)):for j in range(preds.size(1)):hm = hms[i][j]pX, pY = int(round(float(preds[i][j][0]))), int(round(float(preds[i][j][1])))if 0 < pX < opt.outputResW - 1 and 0 < pY < opt.outputResH - 1:diff = torch.Tensor((hm[pY][pX + 1] - hm[pY][pX - 1], hm[pY + 1][pX] - hm[pY - 1][pX]))preds[i][j] += diff.sign() * 0.25
preds += 0.2
- 目前得到的坐标
preds[6,17,2]是相对于输出分辨率[80,64]坐标系下的,转换到原图分辨率[480,854]坐标系下,得到preds_tf[6,17,2]
输出:
preds: [6,17,2] (经过第二步偏移处理后的坐标,相对于热力图坐标系)
preds_tf: [6,17,2] (最终坐标,相对于原图坐标系)
maxval: [6,17,1] (热力图最大值)
(2)第二阶段:pose nms
输入:
ori_bboxs: [6,4] (yolo原始输出,原图坐标系)
ori_bbox_scores:[6,1] (yolo输出conf)
ori_pose_preds: [6,17,2] (对应preds_tf,关键点坐标,原图坐标系)
ori_pose_scores:[6,17,1] (对应maxval,热力图最大值)
- 根据
bboxs计算每个目标框的w,h,选择每个目标框中的最大值max(w,h)并乘上alpha=0.1构成ref_dists[6] - 根据
pose_scores计算每个目标17个关键点得分的均值,得到human_scores[6] - 开始循环,直到
human_scores无目标- 选择
human_scores最高的目标,坐标和得分分别记为pick_preds[17,2], pick_scores[17,1]
全部的坐标和得分记为all_preds[6,17,2], all_scores[6,17,1](此处命名方式与源码略有不同,以便于区分) - 计算距离:
final_dist[6]目标的同类别关键点的距离,距离越近数值越大
score_dists计算位置距离非常近的同类别关键点的得分距离
point_dist= e − d / 2.65 =e^{-d/2.65} =e−d/2.65,因为 d ≥ 0 d\ge0 d≥0,所以 0 < p o i n t _ d i s t ≤ 1 0<\mathrm{point\_dist}\le1 0<point_dist≤1。 d d d 越小, p o i n t _ d i s t \mathrm{point\_dist} point_dist 越大,目标本身则最大全为1 - 计算关键点匹配数量:
num_match_keypoints[6]目标之间同类别关键点中距离较近的数量 - 去除多余目标:目标之间的距离超过阈值 or 目标之间距离相近的关键点数量超过阈值 → 判定为多余的目标。
由于选出的目标本身也在其中,因此目标自身必然在去除的队伍中,如果除了自身还有目标被去除,那么会把额外的目标与自身的索引放在一起得到merge_ids,这些目标相互之间距离很近,用于后续融合目标。
- 选择
对应第2步
def get_parametric_distance(i, all_preds, all_scores):pick_preds, pick_scores = all_preds[i], all_scores[i]'计算坐标位置的欧氏距离 dist[6,17](同类别关键点之间的距离)'dist = torch.sqrt(torch.sum(torch.pow(pick_preds[np.newaxis, :] - all_preds, 2), dim=2))'计算dist<=1的点之间的得分距离 score_dists[6,17]'mask = (dist <= 1)score_dists = torch.zeros(all_preds.shape[0], 17)score_dists[mask] = torch.tanh(pick_scores[mask]/delta1) * torch.tanh(all_scores[mask]/delta1) 'delta1=1''final_dist[6]'point_dist = torch.exp((-1) * dist / delta2) 'delta2=2.65'final_dist = torch.sum(score_dists, dim=1) + mu * torch.sum(point_dist, dim=1) 'mu=1.7'return final_dist
对应第3步
def PCK_match(pick_pred, all_preds, ref_dist):dist = torch.sqrt(torch.sum(torch.pow(pick_preds[np.newaxis, :] - all_preds, 2), dim=2))ref_dist = min(ref_dist, 7)num_match_keypoints = torch.sum(dist / ref_dist <= 1, dim=1)return num_match_keypoints
对应第4步
'gamma=22.48, matchThreds=5'
delete_ids = torch.from_numpy(np.arange(human_scores.shape[0]))[(final_dist > gamma) | (num_match_keypoints >= matchThreds)]
输出:
merge_ids: [6,x]
preds_pick: [6,17,2]
scores_pick: [6,17,1]
bbox_scores_pick: [6,1]
'''
这里的输出是从各个输入 orig_xxxx, 例如 ori_bbox_scores 中挑选出来的(nms后的目标)
只是在这个例子中, nms判断并没有重复的目标, 因此和原始输入保持一致merge_ids 是一个列表, x代表每一项的长度, 本例中x都=1
如果nms判断存在重复目标, 那么会把这些目标在原始输入中的索引记录在 merge_ids 中, 此时x>1
在第三阶段中会把这些目标进行融合
'''
(3)第三阶段:融合与过滤
- 去除17个关键点中最高得分 m a x _ s c o r e < s c o r e T h r e d s = 0.3 \mathrm{max\_score < scoreThreds = 0.3} max_score<scoreThreds=0.3 的目标
- 融合目标,具体看下面代码,简单来说就是把距离比较近的关键点根据得分的高低作为权重,把坐标位置和得分进行加权求和作为融合后的目标
- 去除融合后,17个关键点中最高得分 m a x _ s c o r e < s c o r e T h r e d s = 0.3 \mathrm{max\_score < scoreThreds = 0.3} max_score<scoreThreds=0.3 的目标
- 根据能包含目标所有关键点的矩形框面积来过滤目标,
1.5**2 * (xmax-xmin) * (ymax-ymin) < areaThres=0,具体为外接矩形长宽都乘1.5后计算面积,由于这里阈值为0,过滤基本无效 - 最后会把所有关键点坐标数值 − 0.3 -0.3 −0.3,并且根据关键点得分和目标框得分生成
proposal_score,具体见下面代码
此阶段过滤掉了一个目标,最终得到5个目标。
merge_pose, merge_score = p_merge_fast(preds_pick[j], ori_pose_preds[merge_id], ori_pose_scores[merge_id], ref_dists[pick[j]])def p_merge_fast(ref_pose, cluster_preds, cluster_scores, ref_dist):'''Score-weighted pose mergingINPUT: 本博客中文别称ref_pose: reference pose -- [17, 2] 挑选目标关键点cluster_preds: redundant poses -- [n, 17, 2] 多余目标关键点(挑选目标本身包含在多余目标中)cluster_scores: redundant poses score -- [n, 17, 1]ref_dist: reference scale -- ConstantOUTPUT:final_pose: merged pose -- [17, 2]final_score: merged score -- [17]''''计算与多余目标关键点距离 dist[n,17]'dist = torch.sqrt(torch.sum(torch.pow(ref_pose[np.newaxis, :] - cluster_preds, 2),dim=2))kp_num = 17'回顾一下, ref_dist是挑选目标的目标框的 max(h,w)*0.1'ref_dist = min(ref_dist, 15)mask = (dist <= ref_dist)final_pose = torch.zeros(kp_num, 2)final_score = torch.zeros(kp_num)if cluster_preds.dim() == 2:cluster_preds.unsqueeze_(0)cluster_scores.unsqueeze_(0)if mask.dim() == 1:mask.unsqueeze_(0)# Weighted Merge'根据pose的得分来决定每个目标所占的比例, 具体为该得分占总得分的比例'masked_scores = cluster_scores.mul(mask.float().unsqueeze(-1))normed_scores = masked_scores / torch.sum(masked_scores, dim=0)'根据计算得到的比例做加权和, 得到最终的pose及其得分'final_pose = torch.mul(cluster_preds, normed_scores.repeat(1, 1, 2)).sum(dim=0)final_score = torch.mul(masked_scores, normed_scores).sum(dim=0)return final_pose, final_score
final_result.append({'keypoints': merge_pose - 0.3,'kp_score': merge_score,'proposal_score': torch.mean(merge_score) + bbox_scores_pick[j] + 1.25 * max(merge_score)
})keypoints [17,2]
kp_score [17,1]
proposal_score [1]
3. Alphapose 网络结构
3.1 总流程

- SEResnet 作为 backbone 提取特征
- 用
nn.PixelShuffle(2)提升分辨率 - 经过两个 DUC 模块进一步提升分辨率
- 通过一个卷积得到输出
- 此时获得的输出如图所示
out[6,33,80,64]有33个关键点,通过out.narrow(1, 0, 17)获取前17个关键点作为最终的输出hm[6,17,80,64]
3.2 DUC 模块
- 2个DUC模块结构相同,都是先用卷积升维,再用一个
nn.PixelShuffle(2)提升分辨率 - 图中以 DUC1 模块的参数为例进行绘制
3.3 PixelShuffle 操作
import torch
import torch.nn as nninput_tensor = torch.arange(1, 17).view(1, 16, 1, 1).float()
pixel_shuffle = nn.PixelShuffle(2)
output_tensor = pixel_shuffle(input_tensor)print(output_tensor)>>>
tensor([[[[ 1., 2.],[ 3., 4.]],[[ 5., 6.],[ 7., 8.]],[[ 9., 10.],[11., 12.]],[[13., 14.],[15., 16.]]]])
3.4 SEResnet 框架

图中省略了 batchsize 维度,主要分为4层,分别相对原图下采样4、8、16、32倍
3.5 SEResnet 细节

仿照代码,把这4个由 Bottleneck_SE 和 Bottleneck 构成的层级记作 l a y e r 1 ∼ 4 \mathrm{layer1\sim4} layer1∼4,图中为 l a y e r 1 \mathrm{layer1} layer1 的数据。
每个层中两种 Bottleneck 都会通过三个卷积层,先把特征维度控制为输出特征维度的 1/4,第二个保持不变,第三个达到输出特征维度,再以第二层为例:
l a y e r 2 : \mathrm{layer2:} layer2:
B o t t l e n e c k _ S E : 256 → 128 → 128 → 512 \mathrm{Bottleneck\_ SE:256\to128\to128\to512} Bottleneck_SE:256→128→128→512
B o t t l e n e c k : 512 → 128 → 128 → 512 \mathrm{Bottleneck:512\to128\to128\to512} Bottleneck:512→128→128→512
相关文章:
AlphaPose Pytorch 代码详解(一):predict
前言 代码地址:AlphaPose-Pytorch版 本文以图像 1.jpg(854x480)为例对整个预测过程的各个细节进行解读并记录 python demo.py --indir examples/demo --outdir examples/res --save_img1. YOLO 1.1 图像预处理 cv2读取BGR图像 img [480,…...
日常学习记录随笔-zabix实战
使用zabix结合 实现一套监控报警装置 不管是web开发还是大数据开发 我们的离线项目还是实时项目也好,都需要把我们的应用提交到我们服务器或者容器中去执行 整个应用过程中怎么保证线上整体环境的稳定运行 监控很重要 现在比较主流的就是 普罗米修斯以及zabix 我要做…...

vw+rem自适应布局
开发过程中,我们希望能够直接按照设计图来开发,不管设计图是两倍还是三倍图,能够直接写设计图尺寸而不需要换算,同时有高质的设计图还原度,想想都比较爽。 这里介绍一种使用vw和rem来布局的方案。 该方案思路主要是&am…...

【MySql】mysql之MHA高可用配置及故障切换
一、MHA概念 MHA(Master High Availability)是一套优秀的Mysql高可用环境下故障切换和主从复制的软件。 MHA的出现就是解决Mysql单点的问题。 Mysql故障切换过程中,MHA能做到0-30秒内自动完成故障切换操作。 MHA能在故障切换的过程中最大程…...

如何在 Spring Boot 中进行数据备份
在Spring Boot中进行数据备份 数据备份是确保数据安全性和可恢复性的关键任务之一。Spring Boot提供了多种方法来执行数据备份,无论是定期备份数据库,还是将数据导出到外部存储。本文将介绍在Spring Boot应用程序中进行数据备份的不同方法。 方法1: 使用…...
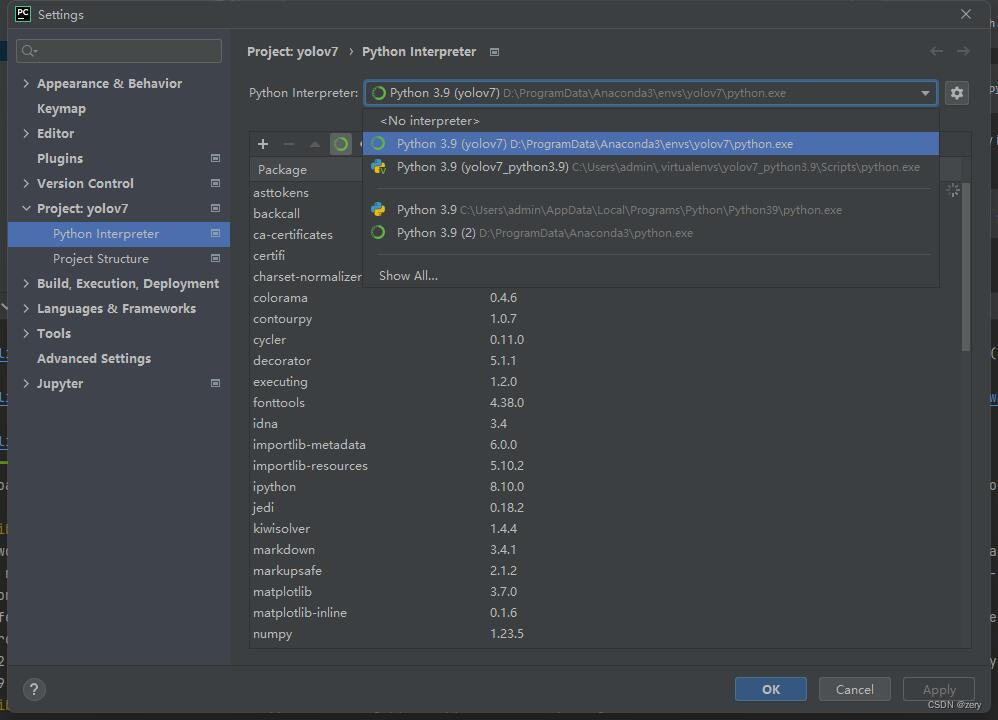
为Yolov7环境安装Cuba匹配的Pytorch
1. 查看Cuba版本 方法一 nvidia-smi 找到CUDA Version 方法二 Nvidia Control Panel > 系统信息 > 组件 > 2. 安装Cuba匹配版本的PyTorch https://pytorch.org/get-started/locally/这里使用conda安装 conda install pytorch torchvision torchaudio pytorch-cu…...

SpringBoot基于jackson对象映射器扩展mvc框架的消息转换器
在SpringBoot中,可以基于jackson对象映射器扩展mvc框架的消息转换器 具体步骤如下: 1、创建对象映射器: package com.java.demo.common;import com.fasterxml.jackson.databind.DeserializationFeature; import com.fasterxml.jackson.datab…...
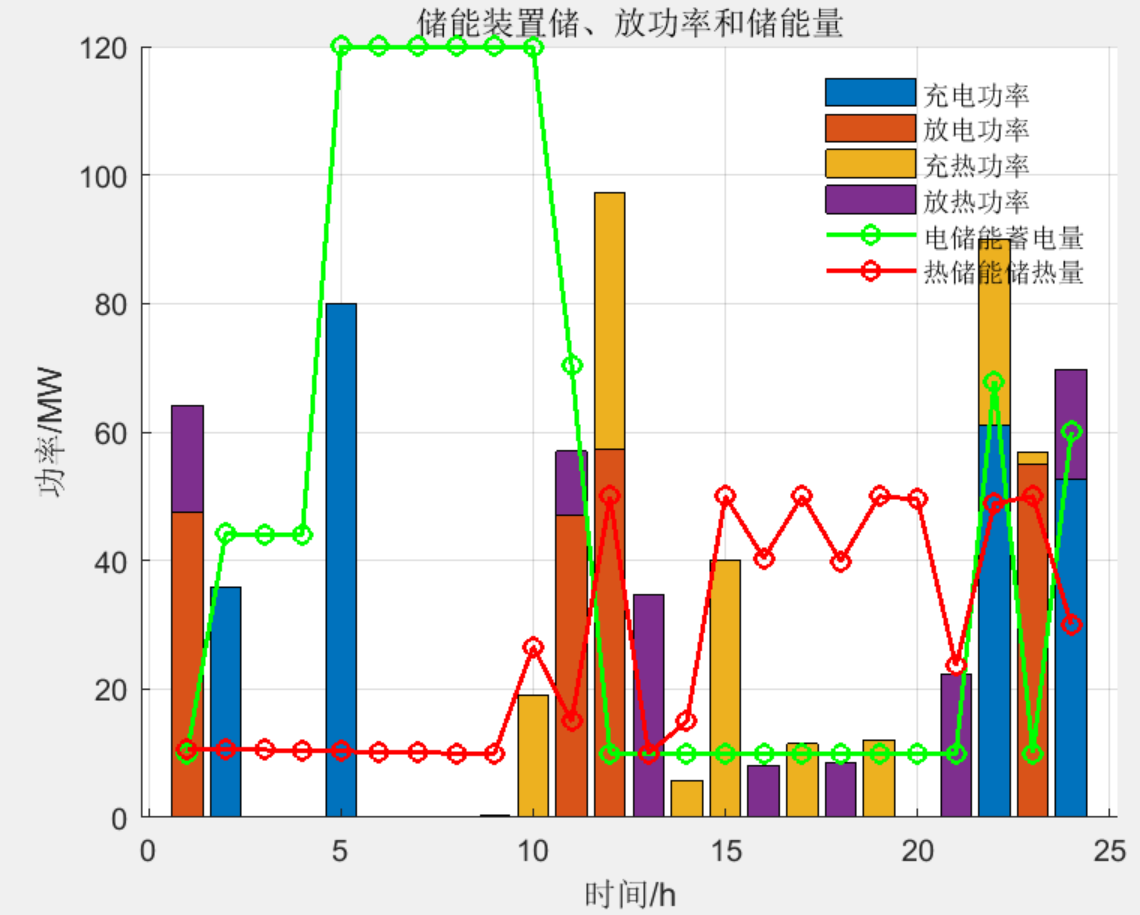
计及电转气协同的含碳捕集与垃圾焚烧虚拟电厂优化调度(matlab代码)
目录 1 主要内容 系统结构 CCPP-P2G-燃气机组子系统 非线性处理缺陷 2 部分代码 3 程序结果 4 程序链接 1 主要内容 该程序参考《计及电转气协同的含碳捕集与垃圾焚烧虚拟电厂优化调度》模型,主要实现的是计及电转气协同的含碳捕集与垃圾焚烧虚拟电厂优化调度…...

【低代码表单设计器】:创造高效率的流程化办公!
当前,有不少用户朋友对低代码表单设计器挺感兴趣。其实,如果想要实现提质增效的办公效率,创造一个流程化办公,那么确实可以了解低代码技术平台。流辰信息作为服务商,拥有较强的自主研发能力,根据市场的变化…...

26、类型别名
类型别名 顾名思义,其实就是类型类型起别名(新起一个名字) demo: type Name string; type NameConsole () > string; type NameUnite Name | NameConsole; function getName(n: NameUnite): Name {if( typeof n string)…...

nslookup命令查询指定域名或ingress地址对应的IP地址。举个例子
使用nslookup命令查询指定域名或ingress地址的IP地址时,可以按照以下方式进行操作: 对于域名查询: 复制代码 nslookup www.example.com 这将返回该域名对应的IP地址。 对于ingress地址查询: 复制代码 nslookup your-ingress-a…...
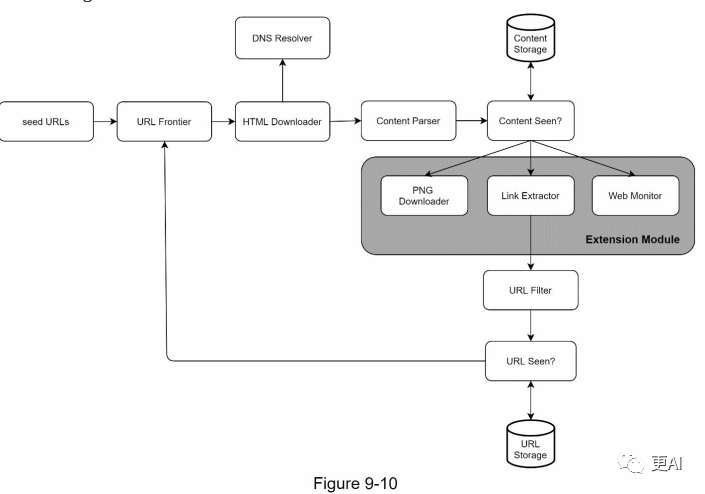
如何设计一个网络爬虫?
网络爬虫也被称为机器人或蜘蛛,它被搜索引擎用于发现网络上的新内容或更新内容。内容可以是网页、图片、视频、PDF文件等。网络爬虫开始时会收集一些网页,然后跟随这些网页上的链接收集新的内容。图9-1展示了爬取过程的可视化示例。 爬虫的作用ÿ…...

风储联合系统的仿真模型研究
摘要 风能是目前国内外应用较为广泛的一种绿色可再生能源,近几年我国风电产业的发展十分迅速。然后,越来越多的风力发电系统建并网,风力发电产生的电能受外界因素影响较大,具有一定的随机性和波动性,给并网后的电力系统…...

JS VUE 用 canvas 给图片加水印
最近写需求,遇到要给图片加水印的需求。 刚开始想的方案是给图片上覆盖一层水印照片,但是这样的话用户直接下载图片水印也会消失。 后来查资料发现用 canvas 就可以给图片加水印,下面是处理过程。 首先我们要确认图片的格式,我们通…...
主动配电网故障恢复的重构与孤岛划分matlab程序
微❤关注“电气仔推送”获得资料(专享优惠) 参考文档: A New Model for Resilient Distribution Systems by Microgrids Formation; 主动配电网故障恢复的重构与孤岛划分统一模型; 同时考虑孤岛与重构的配电网故障…...

2023C语言暑假作业day6
1.选择题 1 1、以下叙述中正确的是( ) A: 只能在循环体内和switch语句体内使用break语句 B: 当break出现在循环体中的switch语句体内时,其作用是跳出该switch语句体,并中止循环体的执行 C: continue语句的作用是:在执…...

java try 自动关闭流
Java Try自动关闭流实现步骤 在开始之前,我们先来了解一下整个实现过程的流程。下面的表格展示了实现"try自动关闭流"的步骤: 步骤 描述 1 创建需要操作的流对象 2 在try语句块中使用流对象 3 在try语句块中自动关闭流对象 接下来…...

WebDAV之π-Disk派盘 + 元思笔记
元思笔记是一款面向大众的卡片笔记软件,解决了笔记类软件的一个痛点:绝大多数人都很难坚持每天记一点东西。任何笔记工具,不论是纸笔还是电子,能够让人坚持记录就是好工具。 元思笔记是一款基于卢曼卡片盒的移动端卡片笔记软件;隐私优先,本地存储数据且支持云备份;丰富的…...

electron自定义标题栏,并监听双击以及右键改变窗口大小。
1、前言 当需要在标题栏添加一些额外的操作时候,比如添加 帮助 菜单,自带的标题栏开发起来比较困难(没了解不知道能不能实现),这时候,自己写一个标题栏就比较方便。 2、实现 首先是禁止掉原先的标题栏&a…...
Beam Focusing for Near-Field Multi-User MIMO Communications阅读笔记
abstract 大天线阵列和高频段是未来无线通信系统的两个关键特征。大规模天线与高传输频率的组合通常导致通信设备在近场(菲涅耳)区域中操作。在本文中,我们研究了潜在的波束聚焦,可行的近场操作,在促进高速率多用户下…...

SAP屏幕导航:从SET到LEAVE,实战解析六大跳转策略
1. SAP屏幕导航的核心逻辑 在SAP ABAP开发中,屏幕导航就像是在迷宫中寻找出口。想象你手里有六把不同的钥匙(六种跳转策略),每把钥匙对应不同的门锁(业务场景)。选错钥匙要么打不开门,要么可能把…...

使用Gemini-OpenAI代理实现零成本AI模型迁移与协议转换
1. 项目概述:一个让OpenAI生态无缝接入Gemini的桥梁如果你和我一样,长期在AI应用开发的一线折腾,肯定遇到过这样的场景:手头有一个基于OpenAI API(比如ChatGPT的gpt-3.5-turbo或gpt-4)构建得相当成熟的应用…...

CircuitJS1 Desktop Mod:跨平台离线电路仿真软件的终极指南
CircuitJS1 Desktop Mod:跨平台离线电路仿真软件的终极指南 【免费下载链接】circuitjs1 Standalone (offline) version of the Circuit Simulator with small modifications based on modified NW.js. 项目地址: https://gitcode.com/gh_mirrors/circ/circuitjs1…...

Ubuntu 20.04上virt-manager报GDBus错误?别慌,三步排查法搞定它
Ubuntu 20.04 virt-manager报GDBus错误的深度排查指南 当你正准备用virt-manager管理KVM虚拟机时,突然弹出一个令人困惑的GDBus错误——这种场景对于Linux虚拟化用户来说并不陌生。这个看似简单的错误背后,其实涉及Linux桌面环境中多个关键组件的协同工作…...

别再傻傻分不清!CANoe里CAPL节点到底该放Measurement Setup还是Simulation Setup?
CANoe实战指南:CAPL节点在Measurement与Simulation Setup中的精准选择策略 在汽车电子系统开发与测试领域,CANoe作为行业标准工具,其CAPL(CAN Access Programming Language)节点的正确配置直接影响测试结果的准确性和可…...

终极免费音频编辑神器:告别昂贵软件,开启专业音频创作之旅
终极免费音频编辑神器:告别昂贵软件,开启专业音频创作之旅 【免费下载链接】audacity Audio Editor 项目地址: https://gitcode.com/GitHub_Trending/au/audacity 你是否曾因音频编辑软件的复杂界面而望而却步?是否在寻找一款既能满足…...
)
内网开发环境救星:保姆级教程搞定Docker与Docker Compose离线安装(附避坑清单)
内网开发环境救星:保姆级教程搞定Docker与Docker Compose离线安装(附避坑清单) 在企业级开发环境中,内网隔离是常见的安全策略,但这也给技术栈的部署带来了挑战。想象一下,当你需要在完全离线的环境中搭建一…...

避开4D毫米波雷达性能坑:详解AWR2243天线通道失配原因与校准策略
避开4D毫米波雷达性能坑:详解AWR2243天线通道失配原因与校准策略 在自动驾驶与高级驾驶辅助系统(ADAS)领域,4D毫米波雷达正逐渐成为环境感知的核心传感器。德州仪器(TI)的AWR2243级联方案凭借其192个虚拟通…...

CircuitPython开发板选型指南:从需求到Adafruit产品实战解析
1. 项目概述:为什么选择CircuitPython开发板是个技术活如果你刚开始接触硬件编程,或者是从Arduino转向更友好的开发环境,那么CircuitPython绝对是一个让人眼前一亮的选项。它把Python的简洁语法带到了微控制器上,让你能用几行代码…...

Neovim原生GitHub Copilot客户端gp.nvim:从安装配置到高级实战
1. 项目概述:一个为Neovim量身打造的GitHub Copilot客户端如果你和我一样,是个重度Neovim用户,同时又对GitHub Copilot这类AI编程助手爱不释手,那你肯定也经历过那种“鱼与熊掌”的纠结时刻。在VSCode里,Copilot的集成…...