Hudi第三章:集成Flink
系列文章目录
Hudi第一章:编译安装
Hudi第二章:集成Spark
Hudi第二章:集成Spark(二)
Hudi第三章:集成Flink
文章目录
- 系列文章目录
- 前言
- 一、环境准备
- 1.上传并解压
- 2.修改配置文件
- 3.拷贝jar包
- 4.启动sql-client
- 1.启动hadoop
- 2.启动session
- 3.启动sql-client
- 二、sql-client编码
- 1.创建表
- 2.插入数据
- 3.查询数据
- 4.更新数据
- 5.流式插入
- 三、IDEA编码
- 1.编写pom.xml
- 2.编写demo
- 总结
前言
之前的两次博客学习了hudi和spark的集成,现在我们来学习hudi和flink的集成。
一、环境准备
1.上传并解压

2.修改配置文件
vim /opt/module/flink-1.13.6/conf/flink-conf.yaml
直接在最后追加即可。
classloader.check-leaked-classloader: false
taskmanager.numberOfTaskSlots: 4state.backend: rocksdb
execution.checkpointing.interval: 30000
state.checkpoints.dir: hdfs://hadoop102:8020/ckps
state.backend.incremental: true
sudo vim /etc/profile.d/my_env.sh
export HADOOP_CLASSPATH=`hadoop classpath`
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
source /etc/profile.d/my_env.sh
3.拷贝jar包
cp /opt/software/hudi-0.12.0/packaging/hudi-flink-bundle/target/hudi-flink1.13-bundle-0.12.0.jar /opt/module/flink-1.13.6/lib/
cp /opt/module/hadoop/share/hadoop/common/lib/guava-27.0-jre.jar /opt/module/flink-1.13.6/lib/
cp /opt/module/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-client-core-3.1.3.jar /opt/module/flink-1.13.6/lib/
4.启动sql-client
1.启动hadoop
2.启动session
/opt/module/flink-1.13.6/bin/yarn-session.sh -d
3.启动sql-client
bin/sql-client.sh embedded -s yarn-session
启动成功后可以在web端看一下。

也可以跳转到flink的webui。

现在我们就可以在终端写代码了。
二、sql-client编码
1.创建表
CREATE TABLE t1(uuid VARCHAR(20) PRIMARY KEY NOT ENFORCED,name VARCHAR(10),age INT,ts TIMESTAMP(3),`partition` VARCHAR(20)
)
PARTITIONED BY (`partition`)
WITH ('connector' = 'hudi','path' = 'hdfs://hadoop102:8020/tmp/hudi_flink/t1','table.type' = 'MERGE_ON_READ'
);

2.插入数据
INSERT INTO t1 VALUES('id1','Danny',23,TIMESTAMP '1970-01-01 00:00:01','par1'),('id2','Stephen',33,TIMESTAMP '1970-01-01 00:00:02','par1'),('id3','Julian',53,TIMESTAMP '1970-01-01 00:00:03','par2'),('id4','Fabian',31,TIMESTAMP '1970-01-01 00:00:04','par2'),('id5','Sophia',18,TIMESTAMP '1970-01-01 00:00:05','par3'),('id6','Emma',20,TIMESTAMP '1970-01-01 00:00:06','par3'),('id7','Bob',44,TIMESTAMP '1970-01-01 00:00:07','par4'),('id8','Han',56,TIMESTAMP '1970-01-01 00:00:08','par4');
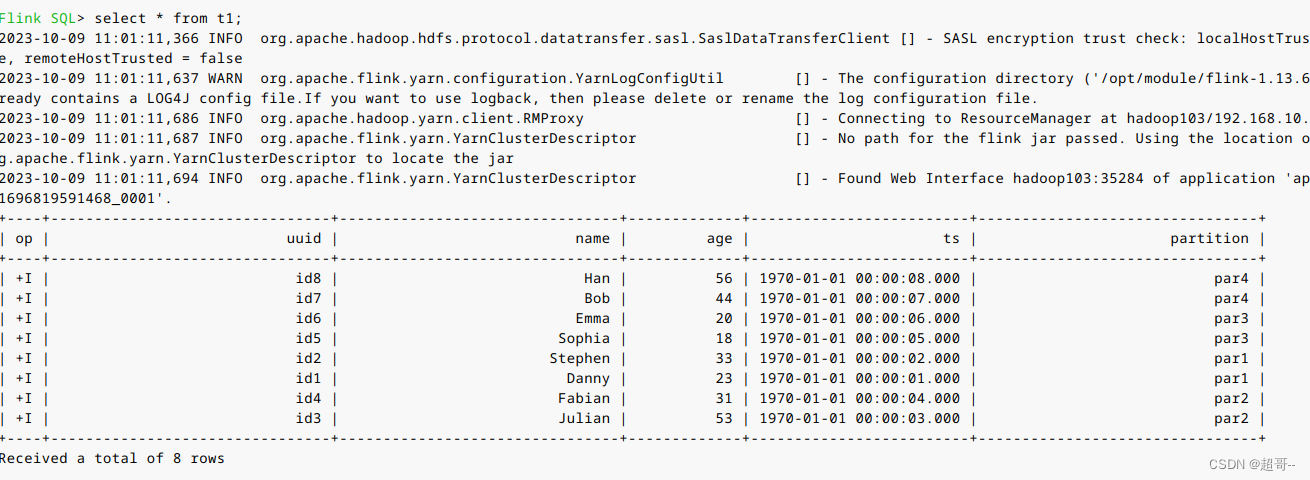
3.查询数据
我们先更改一下表格式,默认的看得可能不习惯。
set sql-client.execution.result-mode=tableau;
select * from t1;
4.更新数据
前面说过hudi的更新操作就是插入一条主键相同的新数据,由更新的ts来覆盖旧的。
insert into t1 values('id1','Danny',27,TIMESTAMP '1970-01-02 00:00:01','par1');
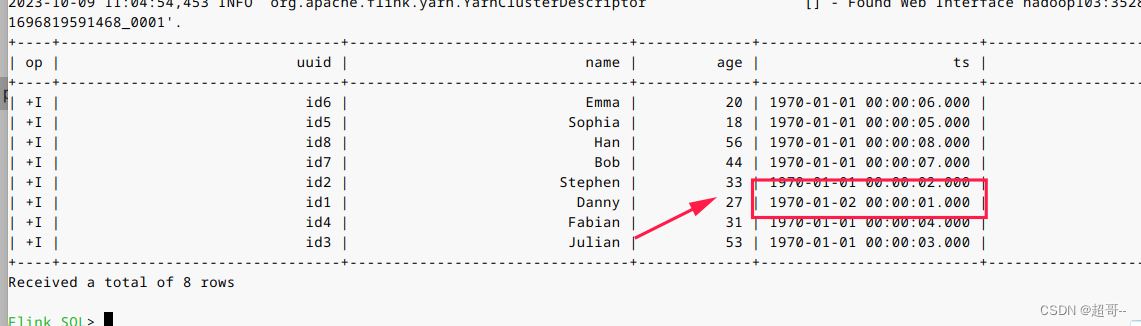
可以看到数据已经完成了更新。
5.流式插入
flink最常用的还是流式数据的处理。
CREATE TABLE sourceT (uuid varchar(20),name varchar(10),age int,ts timestamp(3),`partition` varchar(20)
) WITH ('connector' = 'datagen','rows-per-second' = '1'
);create table t2(uuid varchar(20),name varchar(10),age int,ts timestamp(3),`partition` varchar(20)
)
with ('connector' = 'hudi','path' = '/tmp/hudi_flink/t2','table.type' = 'MERGE_ON_READ'
);
我们创建两张表,第一张的连接器是datagen可以用来流式的生产数据。第二张表是正常的hudi表。
insert into t2 select * from sourceT;
我们可以在webui看一下。
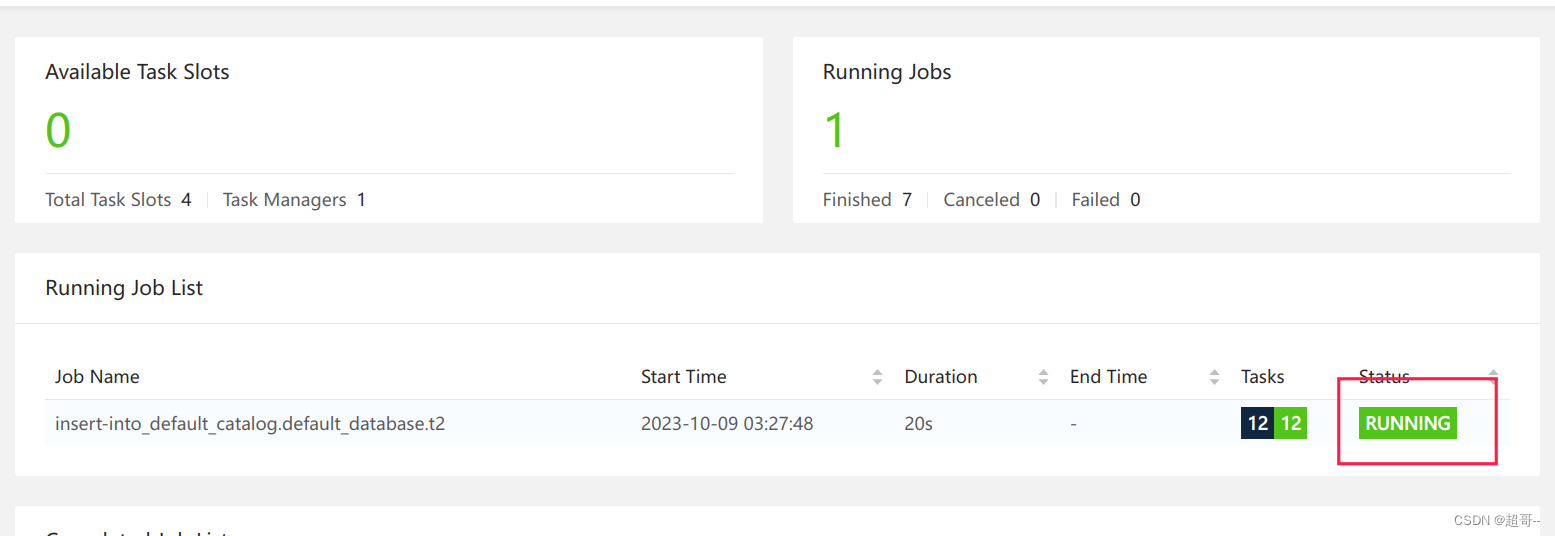
因为是流式处理,所以这个进程是不会停止的。
select * from t2 limit 10;

再查看一次
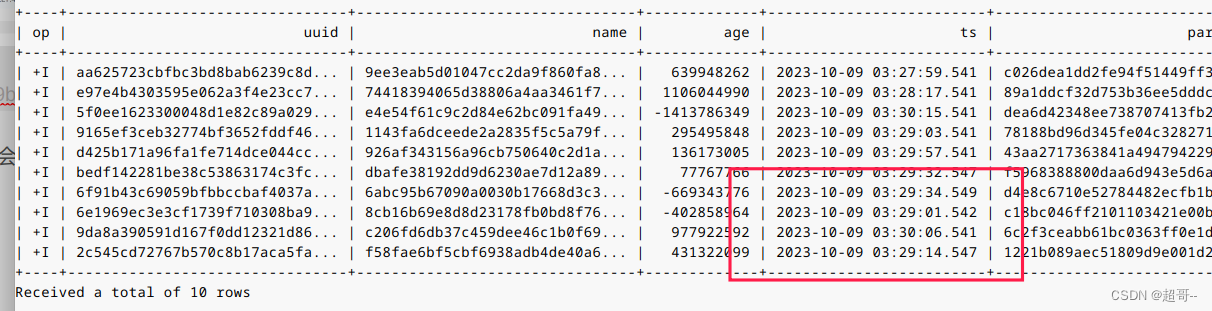
我们会发现是不断有数据产生。
三、IDEA编码
我们需要将编译好的一个包拉到本地。
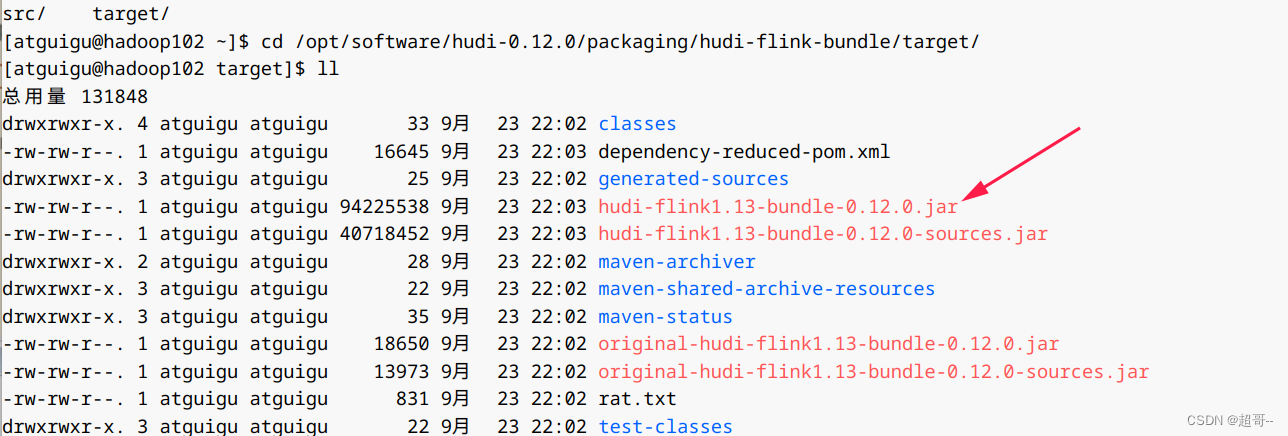
然后将他倒入maven仓库
mvn install:install-file -DgroupId=org.apache.hudi -DartifactId=hudi-flink_2.12 -Dversion=0.12.0 -Dpackaging=jar -Dfile=./hudi-flink1.13-bundle-0.12.0.jar
1.编写pom.xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><groupId>com.atguigu.hudi</groupId><artifactId>flink-hudi-demo</artifactId><version>1.0-SNAPSHOT</version><properties><maven.compiler.source>8</maven.compiler.source><maven.compiler.target>8</maven.compiler.target><flink.version>1.13.6</flink.version><hudi.version>0.12.0</hudi.version><java.version>1.8</java.version><scala.binary.version>2.12</scala.binary.version><slf4j.version>1.7.30</slf4j.version></properties><dependencies><dependency><groupId>org.apache.flink</groupId><artifactId>flink-java</artifactId><version>${flink.version}</version><scope>provided</scope> <!--不会打包到依赖中,只参与编译,不参与运行 --></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-streaming-java_${scala.binary.version}</artifactId><version>${flink.version}</version><scope>provided</scope></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-clients_${scala.binary.version}</artifactId><version>${flink.version}</version><scope>provided</scope></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-table-planner-blink_${scala.binary.version}</artifactId><version>${flink.version}</version><scope>provided</scope></dependency><!--idea运行时也有webui--><dependency><groupId>org.apache.flink</groupId><artifactId>flink-runtime-web_${scala.binary.version}</artifactId><version>${flink.version}</version><scope>provided</scope></dependency><dependency><groupId>org.slf4j</groupId><artifactId>slf4j-api</artifactId><version>${slf4j.version}</version><scope>provided</scope></dependency><dependency><groupId>org.slf4j</groupId><artifactId>slf4j-log4j12</artifactId><version>${slf4j.version}</version><scope>provided</scope></dependency><dependency><groupId>org.apache.logging.log4j</groupId><artifactId>log4j-to-slf4j</artifactId><version>2.14.0</version><scope>provided</scope></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-statebackend-rocksdb_${scala.binary.version}</artifactId><version>${flink.version}</version></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-client</artifactId><version>3.1.3</version><scope>provided</scope></dependency><!--手动install到本地maven仓库--><dependency><groupId>org.apache.hudi</groupId><artifactId>hudi-flink_2.12</artifactId><version>${hudi.version}</version><scope>provided</scope></dependency></dependencies><build><plugins><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-shade-plugin</artifactId><version>3.2.4</version><executions><execution><phase>package</phase><goals><goal>shade</goal></goals><configuration><artifactSet><excludes><exclude>com.google.code.findbugs:jsr305</exclude><exclude>org.slf4j:*</exclude><exclude>log4j:*</exclude><exclude>org.apache.hadoop:*</exclude></excludes></artifactSet><filters><filter><!-- Do not copy the signatures in the META-INF folder.Otherwise, this might cause SecurityExceptions when using the JAR. --><artifact>*:*</artifact><excludes><exclude>META-INF/*.SF</exclude><exclude>META-INF/*.DSA</exclude><exclude>META-INF/*.RSA</exclude></excludes></filter></filters><transformers combine.children="append"><transformer implementation="org.apache.maven.plugins.shade.resource.ServicesResourceTransformer"></transformer></transformers></configuration></execution></executions></plugin></plugins></build>
</project>
2.编写demo
HudiDemo.java
一个简单的流式数据处理和刚刚一样。
package com.atguigu.hudi.flink;import org.apache.flink.configuration.Configuration;
import org.apache.flink.contrib.streaming.state.EmbeddedRocksDBStateBackend;
import org.apache.flink.contrib.streaming.state.PredefinedOptions;
import org.apache.flink.streaming.api.CheckpointingMode;
import org.apache.flink.streaming.api.environment.CheckpointConfig;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;import java.util.concurrent.TimeUnit;public class HudiDemo {public static void main(String[] args) {System.setProperty("HADOOP_USER_NAME", "atguigu");StreamExecutionEnvironment env = StreamExecutionEnvironment.createLocalEnvironmentWithWebUI(new Configuration());// 设置状态后端RocksDBEmbeddedRocksDBStateBackend embeddedRocksDBStateBackend = new EmbeddedRocksDBStateBackend(true);embeddedRocksDBStateBackend.setDbStoragePath("/home/chaoge/Downloads/hudi");embeddedRocksDBStateBackend.setPredefinedOptions(PredefinedOptions.SPINNING_DISK_OPTIMIZED_HIGH_MEM);env.setStateBackend(embeddedRocksDBStateBackend);// checkpoint配置env.enableCheckpointing(TimeUnit.SECONDS.toMillis(30), CheckpointingMode.EXACTLY_ONCE);CheckpointConfig checkpointConfig = env.getCheckpointConfig();checkpointConfig.setCheckpointStorage("hdfs://hadoop102:8020/ckps");checkpointConfig.setMinPauseBetweenCheckpoints(TimeUnit.SECONDS.toMillis(20));checkpointConfig.setTolerableCheckpointFailureNumber(5);checkpointConfig.setCheckpointTimeout(TimeUnit.MINUTES.toMillis(1));checkpointConfig.enableExternalizedCheckpoints(CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);StreamTableEnvironment sTableEnv = StreamTableEnvironment.create(env);sTableEnv.executeSql("CREATE TABLE sourceT (\n" +" uuid varchar(20),\n" +" name varchar(10),\n" +" age int,\n" +" ts timestamp(3),\n" +" `partition` varchar(20)\n" +") WITH (\n" +" 'connector' = 'datagen',\n" +" 'rows-per-second' = '1'\n" +")");sTableEnv.executeSql("create table t2(\n" +" uuid varchar(20),\n" +" name varchar(10),\n" +" age int,\n" +" ts timestamp(3),\n" +" `partition` varchar(20)\n" +")\n" +"with (\n" +" 'connector' = 'hudi',\n" +" 'path' = 'hdfs://hadoop102:8020/tmp/hudi_idea/t2',\n" +" 'table.type' = 'MERGE_ON_READ'\n" +")");sTableEnv.executeSql("insert into t2 select * from sourceT");}
}
当我们运行的时候,可以再本地webui查看。
127.0.0.1:8081/
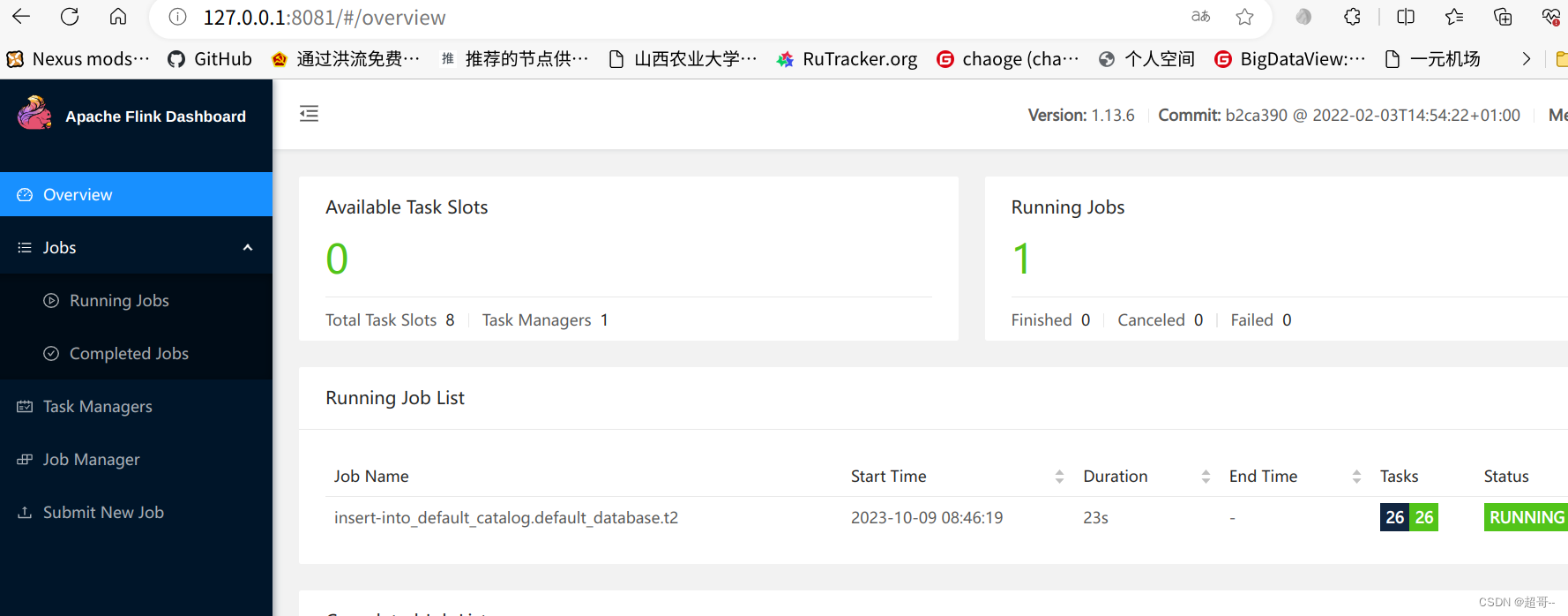
也可以在hdfs路径看一下。

总结
flink第一次就先写到这里剩下的还要在写一次。
相关文章:
Hudi第三章:集成Flink
系列文章目录 Hudi第一章:编译安装 Hudi第二章:集成Spark Hudi第二章:集成Spark(二) Hudi第三章:集成Flink 文章目录 系列文章目录前言一、环境准备1.上传并解压2.修改配置文件3.拷贝jar包4.启动sql-client1.启动hadoop2.启动ses…...

MTC证书|欧盟与英国金属类产品清关新要求
从10月1日起,欧盟海关将严格检查所有申报HS代码为7323、7326等含有金属的货物,所有进口国家的金属相关产品必须提供MTC证书,证明产品材料的来源并非源自俄罗斯。 对于未使用7323、7326等含有金属类的HS编码申报,且品名未明显体现…...
保护敏感数据的艺术:数据安全指南
多年来,工程和技术迅速转型,生成和处理了大量需要保护的数据,因为网络攻击和违规的风险很高。为了保护企业数据,组织必须采取主动的数据安全方法,了解保护数据的最佳实践,并使用必要的工具和平台来实现数据…...
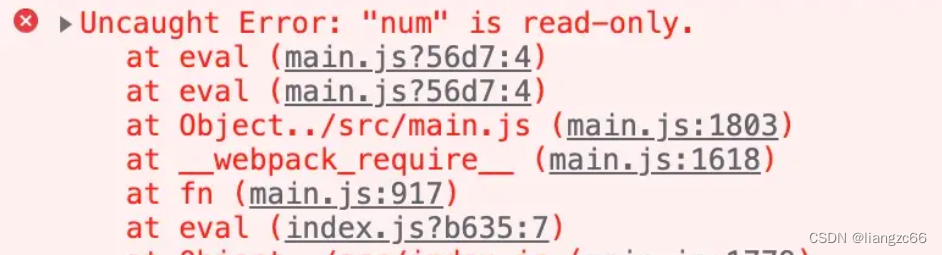
Commonjs与ES Module
commonjs 1 commonjs 实现原理 commonjs每个模块文件上存在 module,exports,require三个变量,然而这三个变量是没有被定义的,但是我们可以在 Commonjs 规范下每一个 js 模块上直接使用它们。在 nodejs 中还存在 __filename 和 __dirname 变…...

分布式对象存储
参考《分布式对象存储----原理、架构以及Go语言实现》(作者:胡世杰) 对象存储简介 数据的管理方式 以对象的方式管理数据,一个对象包括:对象的数据、对象的元数据、对象的全局唯一标识符 访问数据的方式 可扩展的分…...
跨境独立站代购中国电商平台商品PHP多语言多货币
跨境独立站代购中国电商平台商品是指代购者在海外建立自己的独立电商平台,代理中国主流电商平台(如淘宝、京东等)的商品进行销售和代购。这种模式的优势在于代购者可以自主选择产品和价格策略,同时还能提供更专业和优质的服务。 …...

Python接口自动化 —— Json 数据处理实战(详解)
简介 上一篇说了关于json数据处理,是为了断言方便,这篇就带各位小伙伴实战一下。首先捋一下思路,然后根据思路一步一步的去实现和实战,不要一开始就盲目的动手和无头苍蝇一样到处乱撞,撞得头破血流后而放弃了。不仅什么…...
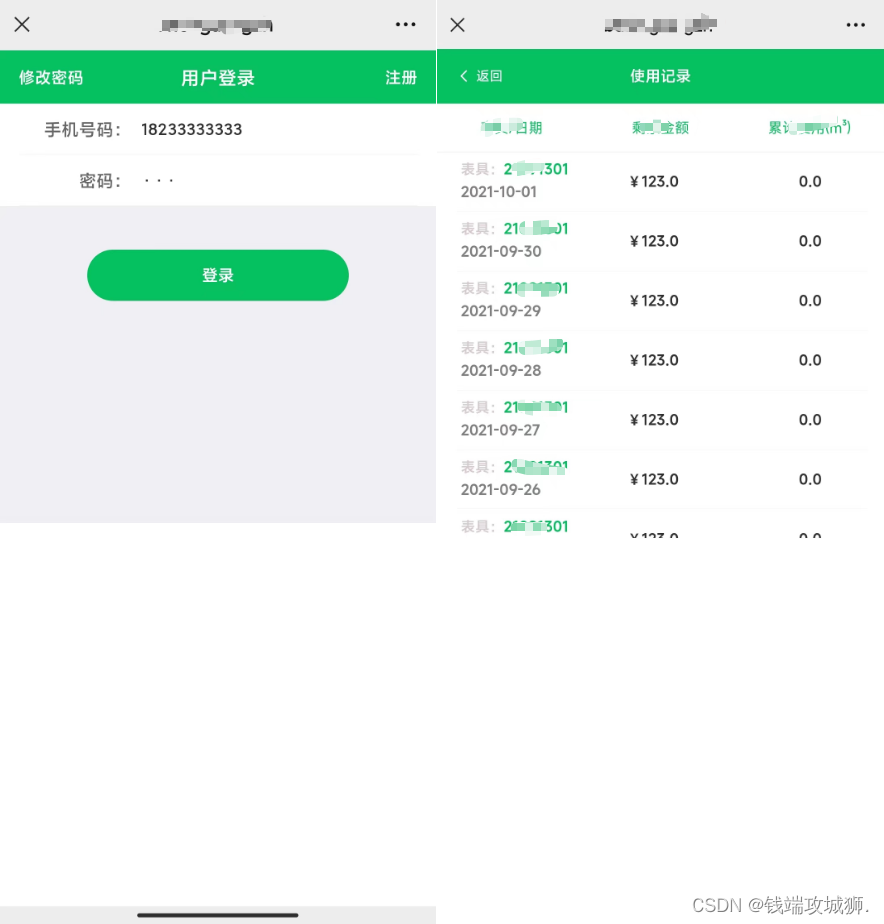
微信页面公众号页面 安全键盘收起后页面空白
微信浏览器打开H5页面和公众号页面,输入密码时调起安全键盘,键盘收起后 键盘下方页面留白 解决办法: 1、(简单)只有在调起安全键盘(输入密码)的时候会出现这种情况,将input属性改为n…...

数据结构 - 二叉树
递归实现前中后序遍历 #include<stdio.h> #include<stdlib.h>#define TElemType inttypedef struct BiTNode{TElemType data;struct BiTNode *lchild,*rchild; }BiTNode,*BiTree; BiTNode root;void visit(TElemType& e){printf("%d",e); }void Pre…...

【Overload游戏引擎细节分析】从视图投影矩阵提取视锥体及overload对视锥体的封装
overoad代码中包含一段有意思的代码,可以从视图投影矩阵逆推出摄像机的视锥体,本文来分析一下原理 一、平面的方程 视锥体是用平面来表示的,所以先看看平面的数学表达。 平面方程可以由其法线N(A, B, C)和一个点Q(x0,…...

Linux 安全 - LSM hook点
文章目录 一、LSM file system hooks1.1 LSM super_block hooks1.2 LSM file hooks1.3 LSM inode hooks 二、LSM Task hooks三、LSM IPC hooks四、LSM Network hooks五、LSM Module & System hooks 一、LSM file system hooks 在VFS(虚拟文件系统)层…...

【iOS逆向与安全】越狱检测与过检测附ida伪代码
首先在网上查找一些检测代码 放入项目运行,用 ida 打开后 F5 得到下面的 __int64 __usercall sub_10001B3F0<X0>(__int64 a1, __int64 a2, __int64 a3, __int64 a4, __int64 a5, __int64 a6, __int64 a7, __int64 a8, __int64 a9, __int64 a10, __int64 a11…...

Android Studio gradle手动下载配置
项目同步时,有时候会遇到Android Studio第一步下载gradle就是连接失败的问题。 这种情况,我们可以手动去gradle官网下载好gradle文件,放置在Android Studio的缓存目录下,这样AS在同步代码时就会自动解压下载好的文件。 步骤如下&…...
)
ChatGPT Prompting开发实战(十三)
一. 如何评估prompts是否包含有害内容 用户在与ChatGPT交互时提供的prompts可能会包括有害内容,这时可以通过调用OpenAI提供的API来进行判断,接下来给出示例,通过调用模型“gpt-3.5-turbo”来演示这个过程。 prompt示例如下&…...
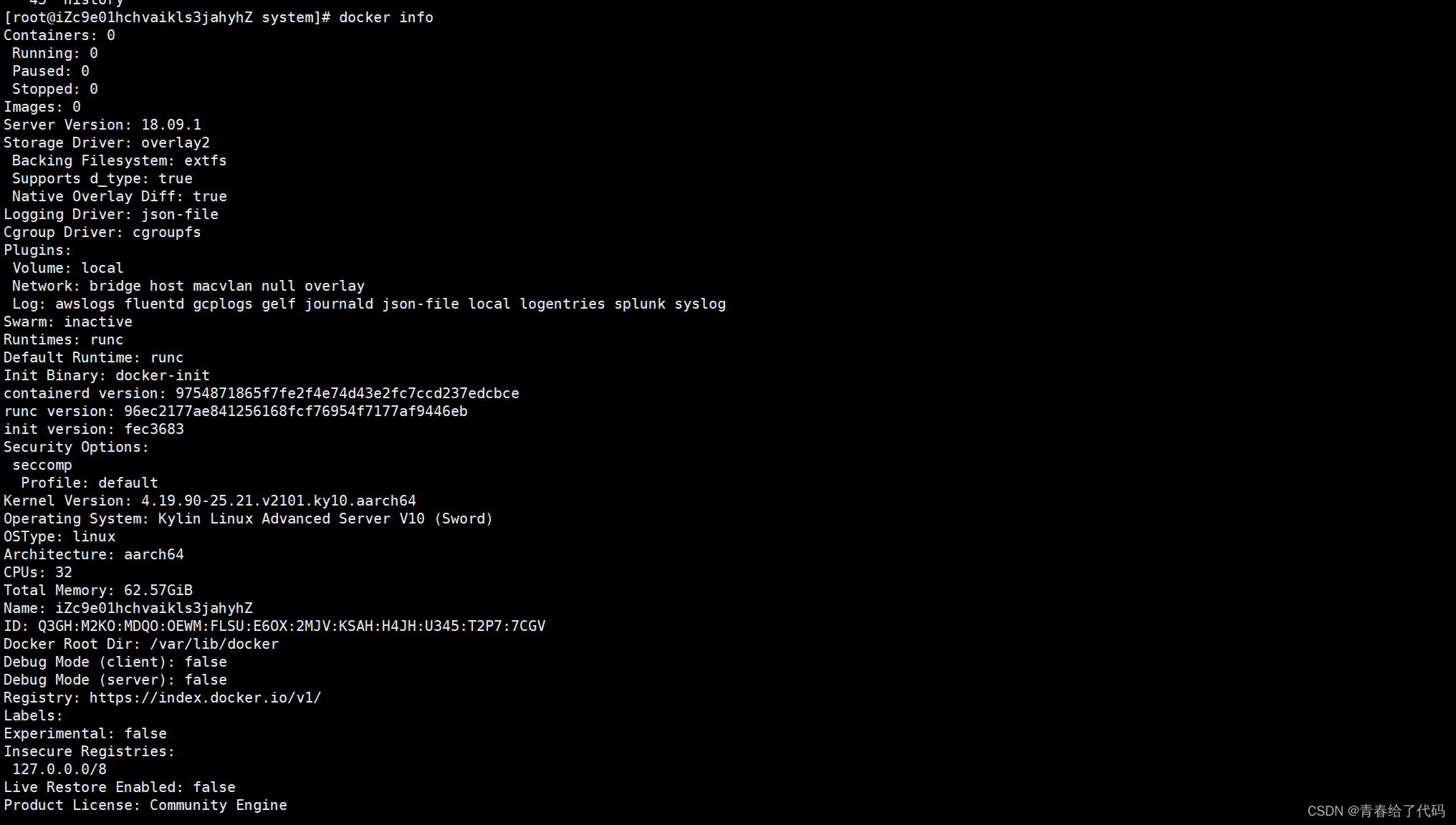
银河麒麟 ARM 架构 离线安装Docker
1. 下载对应的安装包 进入此地址下载对应的docker 离线安装包 下载地址 将文件上传到服务器 解压此文件 tar zxf docker-18.09.1.tgz将 docker 相关命令拷贝到 /usr/bin,方便直接运行命令 cp docker/* /usr/bin/启动Docker守护程序 dockerd &验证是否安装成…...

虹科科技 | 探索CAN通信世界:PCAN-Explorer 6软件的功能与应用
CAN(Controller Area Network)总线是一种广泛应用于汽车和工业领域的通信协议,用于实时数据传输和设备之间的通信。而虹科的PCAN-Explorer 6软件是一款功能强大的CAN总线分析工具,为开发人员提供了丰富的功能和灵活性。本文将重点…...

SELECT COUNT(*)会不会导致全表扫描引起慢查询
SELECT COUNT(*)会不会导致全表扫描引起慢查询呢? SELECT COUNT(*) FROM SomeTable 网上有一种说法,针对无 where_clause 的 COUNT(*),MySQL 是有优化的,优化器会选择成本最小的辅助索引查询计数,其实反而性能最高&…...

英国物联网初创公司【FourJaw】完成180万英镑融资
来源:猛兽财经 作者:猛兽财经 猛兽财经获悉,总部位于英国谢菲尔德的物联网初创公司【FourJaw】今日宣布已完成180万英镑融资。 本轮融资完成后,FourJaw的总融资金额已达400万英镑,本轮融资的投资机构包括:…...

许战海战略文库|无增长则衰亡:中小型制造企业增长困境
竞争环境不是匀速变化,而是加速变化。企业的衰退与进化、兴衰更迭在不断发生,这成为一种不可避免的现实。事实上,在产业链竞争中增长困境不分企业大小,而是一种普遍存在的问题,许多收入在1亿至10亿美元间的制造企业也同…...

广州华锐互动:候车室智能数字孪生系统实现交通信息可视化
随着科技的不断发展,数字化技术在各个领域得到了广泛的应用。智慧车站作为一种新型的交通服务模式,通过运用先进的数字化技术,为乘客提供了更加便捷、舒适的出行体验。 将智慧车站与数字孪生大屏结合,可以将实际现实世界的实体车站…...

2026年主流行工具有何不同?subAgent是趋势还是营销?深度解析!
AI Coding工具中的“subAgent”正从营销词发展为工程抽象,实现上下文、权限、任务和执行的拆分管理。主流工具如Claude Code、Codex、OpenClaw、Gemini CLI均在强化subAgent能力,但设计哲学各异。文章从技术视角解析subAgent的本质、各工具异同及使用选择…...

STM32CUBEMX+Keil AC6编译提速实战:解决LWIP和绝对地址警告的坑
STM32CUBEMXKeil AC6编译提速实战:解决LWIP和绝对地址警告的坑 当STM32开发者从Keil AC5编译器切换到AC6时,往往会遇到两个典型问题:LWIP编译错误和绝对地址警告。本文将深入分析这些问题的根源,并提供经过验证的解决方案…...

C++-练习-109
题目:对Tv和Remote类进行如下修改a.让它们互为友元b.在Remote类中添加一个状态变量成员,该成员描述遥控器使处于常规状态还是互动模式c.在Remote中添加一个显式模式的方法d.在Tv类中添加一个对Remote中新成员进行切换的方法,该方法仅当Tv处于…...

深入RPMsg-Lite virtqueue:拆解异构多核芯片共享内存通信的‘黑盒子’
深入RPMsg-Lite virtqueue:拆解异构多核芯片共享内存通信的‘黑盒子’ 在现代异构多核芯片设计中,核间通信(IPC)的效率直接决定了系统整体性能。当你在调试一个基于NXP i.MX RT1170的双核系统时,是否曾好奇过ÿ…...

探索Harepacker复活版:打造你的MapleStory创意工坊
探索Harepacker复活版:打造你的MapleStory创意工坊 【免费下载链接】Harepacker-resurrected All in one .wz file/map editor for MapleStory game files 项目地址: https://gitcode.com/gh_mirrors/ha/Harepacker-resurrected 你是否曾经梦想过亲手改造Map…...

HPM6750 LVGL性能优化:片内SRAM帧缓冲实战解析
1. 项目概述:当LVGL遇上HPM6750的片内“新大陆”最近在嵌入式图形界面开发的圈子里,一个关于HPM6750的话题热度不低。起因是有开发者发现,在基于HPM6750这款高性能RISC-V MCU进行LVGL(Light and Versatile Graphics Library&#…...

手把手教你用UE5 C++为角色添加动态攀爬:支持移动平台与高度自适应
手把手实现UE5动态攀爬系统:移动平台与高度自适应全解析 在当代3A级动作游戏中,角色与环境的动态交互已成为沉浸感的核心要素。想象一个场景:玩家在摇晃的空中浮岛上追逐目标,需要连续攀爬移动中的平台;或是潜入敌方基…...
)
Cadence SKILL脚本实战:5分钟搞定TESTKEY原理图批量创建(附完整代码)
Cadence SKILL脚本实战:5分钟搞定TESTKEY原理图批量创建(附完整代码) 在集成电路设计领域,TESTKEY(测试结构)的创建是验证工艺模型和器件特性的基础工作。传统手动放置器件的方式不仅效率低下,还…...

DELL R730XD加装二手阵列卡后风扇狂转?手把手教你用ipmitool命令降噪
DELL R730XD二手阵列卡引发的风扇狂转:深度解析与ipmitool实战降噪指南 当你为心爱的DELL R730XD服务器加装二手阵列卡后,迎接你的不是性能提升的喜悦,而是直升机起飞般的风扇轰鸣——这种场景对于许多精打细算的企业IT人员来说再熟悉不过。本…...

智慧零售技术架构解析:从智能终端到边缘计算,如何重塑购物体验
1. 智慧零售的“科技感”从何而来?最近,一段关于智能购物车的视频火了。视频里,消费者推着一辆看似普通,实则“暗藏玄机”的购物车在超市里穿梭,无需排队,扫码即走,最后在出口处轻松完成支付。这…...