MPP 架构在 OLAP 数据库的运用
MPP 架构:
MPP 架构的产品:
-
Impala
-
ClickHouse
-
Druid
-
Doris
很多 OLAP 引擎都采用了 MPP 架构
批处理系统 - 使用场景分钟级、小时级以上的任务,目前很多大型互联网公司都大规模运行这样的系统,稳定可靠,低成本。
MPP系统 - 使用场景秒级、毫秒级以下的任务,主要服务于即席查询场景,对外提供各种数据查询和可视化服务。
MPP 架构针对问题:
MPP解决方案的最原始想法就是消除共享资源。每个执行器有单独的CPU,内存和硬盘资源。一个执行器无法直接访问另一个执行器上的资源,除非通过网络上的受控的数据交换。这种资源独立的概念,对于MPP架构来说很完美的解决了可扩展性的问题。
MPP的第二个主要概念就是并行。每个执行器运行着完全一致的数据处理逻辑,使用着本地存储上的私有数据块。在不同的执行阶段中间有一些同步点(我的理解:了解Java Gc机制的,可以对比GC中stop-the-world,在这个同步点,所有执行器处于等待状态),这些同步点通常被用于进行数据交换(像Spark和MapReduce中的shuffle阶段)。这里有一个经典的MPP查询时间线的例子: 每个垂直的虚线是一个同步点。例如:同步阶段要求在集群中”shuffle”数据以用于join和聚合(aggregations)操作,因此同步阶段可能执行一些数据聚合,表join,数据排序的操作,而每个执行器执行剩下的计算任务。
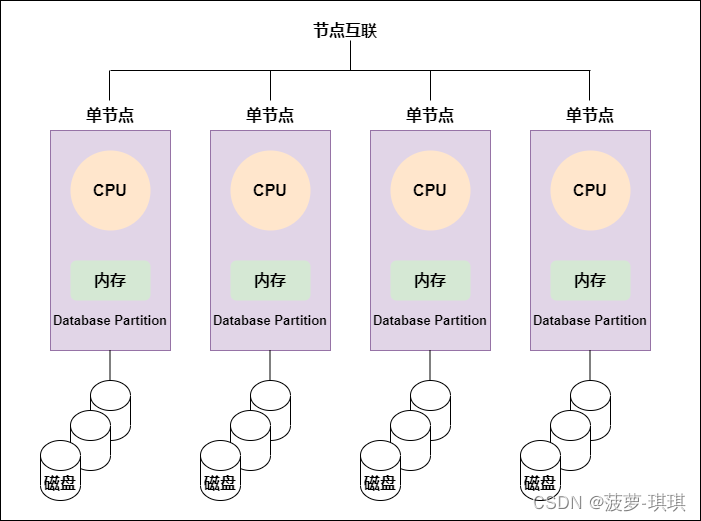
每个节点内的 CPU 不能访问另一个节点的内存,节点之间的信息交互是通过节点互联网络实现的,这个过程称为数据重分配。
NUMA 架构和 MPP 架构很多时候会被搞混,其实区别还是比较明显的。
首先是节点互联机制不同,NUMA 的节点互联是在同一台物理服务器内部实现的,MPP 的节点互联是在不同的 SMP 服务器外部通过 I/O 实现的。
其次是内存访问机制不同,在 NUMA 服务器内部,任何一个 CPU 都可以访问整个系统的内存,但异地内存访问的性能远远低于本地内存访问,因此,在开发应用程序时应该尽量避免异地内存访问。而在 MPP 服务器中,每个节点只访问本地内存,不存在异地内存访问问题。
MPP 架构的优势:
-
任务并行执行;
-
数据分布式存储(本地化);
-
分布式计算;
-
横向扩展,支持集群节点的扩容;
-
Shared Nothing(完全无共享)架构。
MPP的设计缺陷:
所有的MPP解决方案来说都有一个主要的问题——短板效应。如果一个节点总是执行的慢于集群中其他的节点,整个集群的性能就会受限于这个故障节点的执行速度(所谓木桶的短板效应),无论集群有多少节点,都不会有所提高。这里有一个例子展示了故障节点(下图中的Executor 7)是如何降低集群的执行速度的。
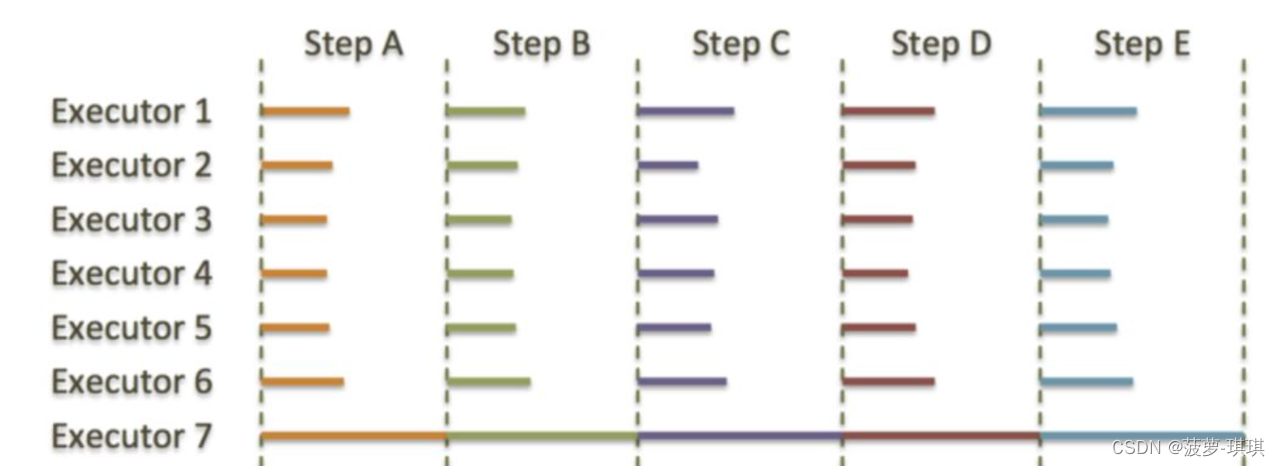
大多数情况下,除了Executor 7 其他的所有执行器都是空闲状态。这是因为他们都在等待Executor 7执行完成后才能执行同步过程,这也是我们的问题的根本。比如,当MPP系统中某个节点的RAID由于磁盘问题导致的性能很慢,或者硬件或者系统问题带来的CPU性能问题等等,都会产生这样的问题。所有的MPP系统都面临这样的问题。
如果你看一下Google的磁盘错误率统计报告,你就能发现观察到的AFR(annualized failure rate,年度故障率)在最好情况下,磁盘在刚开始使用的3个月内有百分之二十会发生故障。
如果一个集群有1000个磁盘,一年中将会有20个出现故障或者说每两周会有一个故障发生。如果有2000个磁盘,你将每周都会有故障发生,如果有4000个,将每周会有两次错误发生。两年的使用之后,你将把这个数字乘以4,也就是说,一个1000个磁盘的集群每周会有两次故障发生。
事实上,在一个确定的量级,你的MPP系统将总会有一个节点的磁盘队列出现问题,这将导致该节点的性能降低,从而像上面所说的那样限制整个集群的性能。这也是为什么在这个世界上没有一个MPP集群是超过50个节点服务器的。
MPP和批处理方案如MapReduce之间有一个更重要的不同就是并发度。并发度就是同一时刻可以高效运行的查询数。MPP是完美对称的,当查询运行的时候,集群中每个节点并发的执行同一个任务。这也就意味着MPP集群的并发度和集群中节点的数量是完全没有关系的。比如说,4个节点的集群和400个节点的集群将支持同一级别的并发度,而且他们性能下降的点基本上是同样。下面是一个例子。
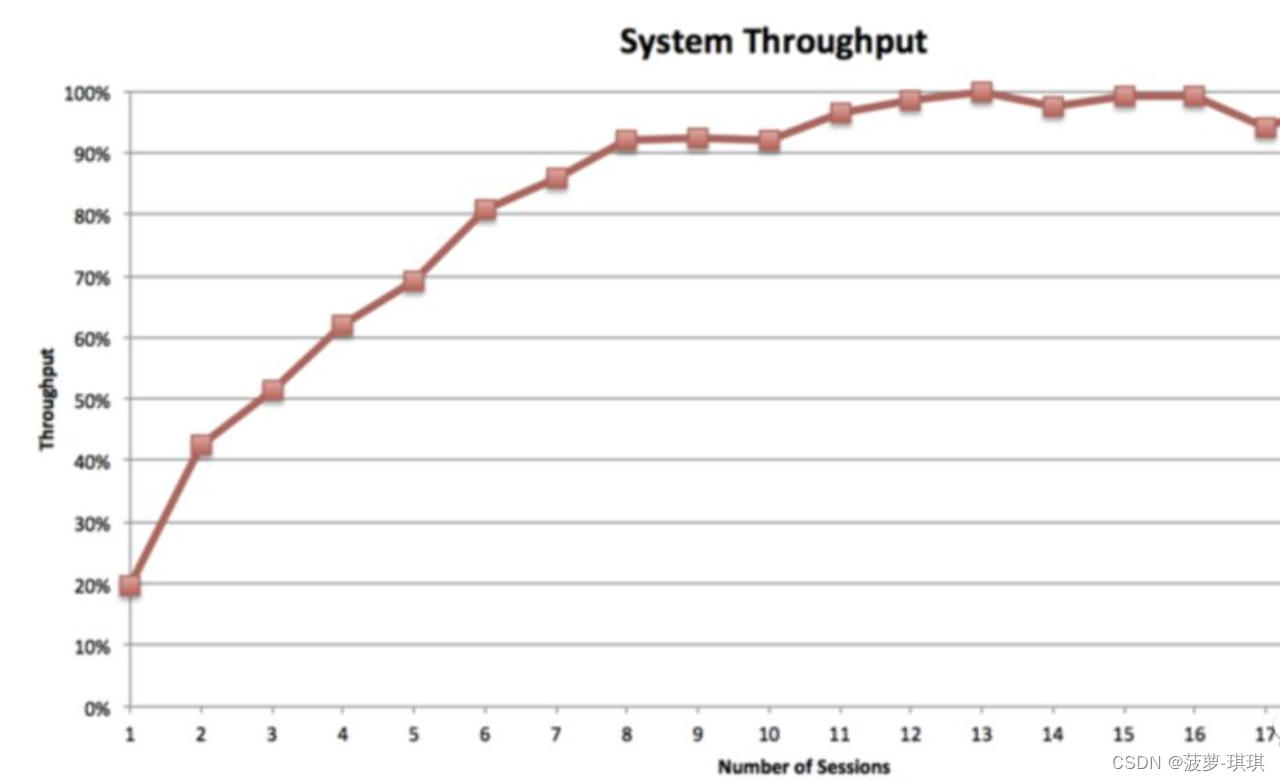
16个并行查询会话产生了整个集群最大的吞吐量。如果你将会话数提高到20个以上的时候,吞吐量将慢慢下降到70%甚至更低。在此声明,吞吐量是在一个固定的时间区间内(时间足够长以产生一个代表性的结果),执行的相同种类的查询任务的数量。Yahoo团队调查Impala并发度限制时产生了一个相似的测试结果。Impala是一个基于Hadoop的MPP引擎。因此从根本上来说,较低的并发度是MPP方案必须承担的以提供它的低查询延迟和高数据处理速度。
MPP 架构的 OLAP 引擎
采用 MPP 架构的 OLAP 引擎分为两类,一类是自身不存储数据,只负责计算的引擎;一类是自身既存储数据,也负责计算的引擎。
只计算不存储数据:
-
Impala
Apache Impala 是采用 MPP 架构的查询引擎,本身不存储任何数据,直接使用内存进行计算,兼顾数据仓库,具有实时,批处理,多并发等优点。
提供了类 SQL(类 Hsql)语法,在多用户场景下也能拥有较高的响应速度和吞吐量。它是由 Java 和 C++实现的,Java 提供的查询交互的接口和实现,C++实现了查询引擎部分。
Impala 支持共享 Hive Metastore,但没有再使用缓慢的 Hive+MapReduce 批处理,而是通过使用与商用并行关系数据库中类似的分布式查询引擎(由 Query Planner、Query Coordinator 和 Query Exec Engine 三部分组成),可以直接从 HDFS 或 HBase 中用 SELECT、JOIN 和统计函数查询数据,从而大大降低了延迟。
Impala 经常搭配存储引擎 Kudu 一起提供服务,这么做最大的优势是查询比较快,并且支持数据的 Update 和 Delete。
-
Presto
Presto 是一个分布式的采用 MPP 架构的查询引擎,本身并不存储数据,但是可以接入多种数据源,并且支持跨数据源的级联查询。Presto 是一个 OLAP 的工具,擅长对海量数据进行复杂的分析;但是对于 OLTP 场景,并不是 Presto 所擅长,所以不要把 Presto 当做数据库来使用。
Presto 是一个低延迟高并发的内存计算引擎。需要从其他数据源获取数据来进行运算分析,它可以连接多种数据源,包括 Hive、RDBMS(Mysql、Oracle、Tidb 等)、Kafka、MongoDB、Redis 等。
计算 & 存储数据:
-
ClickHouse
ClickHouse 是近年来备受关注的开源列式数据库,主要用于数据分析(OLAP)领域。
它自包含了存储和计算能力,完全自主实现了高可用,而且支持完整的 SQL 语法包括 JOIN 等,技术上有着明显优势。相比于 hadoop 体系,以数据库的方式来做大数据处理更加简单易用,学习成本低且灵活度高。当前社区仍旧在迅猛发展中,并且在国内社区也非常火热,各个大厂纷纷跟进大规模使用。
ClickHouse 在计算层做了非常细致的工作,竭尽所能榨干硬件能力,提升查询速度。它实现了单机多核并行、分布式计算、向量化执行与 SIMD 指令、代码生成等多种重要技术。
ClickHouse 从 OLAP 场景需求出发,定制开发了一套全新的高效列式存储引擎,并且实现了数据有序存储、主键索引、稀疏索引、数据 Sharding、数据 Partitioning、TTL、主备复制等丰富功能。以上功能共同为 ClickHouse 极速的分析性能奠定了基础。
-
Doris
Doris 是百度主导的,根据 Google Mesa 论文和 Impala 项目改写的一个大数据分析引擎,是一个海量分布式 KV 存储系统,其设计目标是支持中等规模高可用可伸缩的 KV 存储集群。
Doris 可以实现海量存储,线性伸缩、平滑扩容,自动容错、故障转移,高并发,且运维成本低。部署规模,建议部署 4-100+台服务器。
Doris3 的主要架构: DT(Data Transfer)负责数据导入、DS(Data Seacher)模块负责数据查询、DM(Data Master)模块负责集群元数据管理,数据则存储在 Armor 分布式 Key-Value 引擎中。Doris3 依赖 ZooKeeper 存储元数据,从而其他模块依赖 ZooKeeper 做到了无状态,进而整个系统能够做到无故障单点。
-
Druid
Druid 是一个开源、分布式、面向列式存储的实时分析数据存储系统。
Druid 的关键特性如下:
-
亚秒级的 OLAP 查询分析:采用了列式存储、倒排索引、位图索引等关键技术;
-
在亚秒级别内完成海量数据的过滤、聚合以及多维分析等操作;
-
实时流数据分析:Druid 提供了实时流数据分析,以及高效实时写入;
-
实时数据在亚秒级内的可视化;
-
丰富的数据分析功能:Druid 提供了友好的可视化界面;
-
SQL 查询语言;
-
高可用性与高可拓展性:Druid 工作节点功能单一,不相互依赖;Druid 集群在管理、容错、灾备、扩容都很容易;
MPP架构和其他架构数据库的场景对比:

Hadoop和MPP两种技术的特定和适用场景为:
-
Hadoop在处理非结构化和半结构化数据上具备优势,尤其适合海量数据批处理等应用要求。
-
MPP适合替代现有关系数据机构下的大数据处理,具有较高的效率。
MPP适合多维度数据自助分析、数据集市等;Hadoop适合海量数据存储查询、批量数据ETL、非机构化数据分析(日志分析、文本分析)等。
适合场景
-
有上百亿以上离线数据,不更新,结构化数据,需要各种复杂分析的sql语句
-
不需要频繁重复离线计算,不需要大并发量
-
几秒、几十秒立即返回分析结果,即:即席查询。例如sum,count,group by,order
相关文章:
MPP 架构在 OLAP 数据库的运用
MPP 架构: MPP 架构的产品: Impala ClickHouse Druid Doris 很多 OLAP 引擎都采用了 MPP 架构 批处理系统 - 使用场景分钟级、小时级以上的任务,目前很多大型互联网公司都大规模运行这样的系统,稳定可靠,低成本。…...

什么影响香港服务器的速度原因
1、服务器缓存:清理缓存即可,不同服务器方法不一,根据自身服务器系统可百度。 2、运行内存被占满:运行内存被占满就好像我们手机的运行内存一样,一旦同时运行较多的程序或软件,那么运行内存就会 出现这种情…...

HTML复习笔记
HTML(超文本标记语言) 文章目录 HTML(超文本标记语言)1.HTML1.概念2.标签2.1双标签超链接音频标签视频标签无序列表有序列表定义列表表格合并单元格 表单表单项单选框-**radio**文件上传-file多选框-checkbox 下拉菜单文本域-text…...

「五度情报站」网罗全量企业情报,找客户、查竞品、寻商机!
在当下严峻的市场经济环境下,准确、及时的情报信息,就如同指引企业前行的明灯,能够让企业在风起云涌的市场大潮中保持敏锐的洞察力,掌握最新的市场动态,洞悉竞争对手的一举一动,先知先动,保持竞…...
Ubuntu 22.04‘Temporary failure resolving‘ 解决方案
终极解决方案 首先安装resolvconf sudo apt-get install resolvconf 使用 cd /etc/resolvconf/resolv.conf.d/ 进入文件夹,使用 ls 查看目录,会显示 base head tail 使用 sudo vim base 编辑base文件, 进入时为空,点击 i 添加 …...

移动电源被亚马逊下架怎么办?UL2056认证解析
亚马逊下架移动电源isting突然被下架了,这到底怎么回事?移动电源UL2056认证怎么做? 卖家随后就咨询客服客服原因: 亚马逊在4月25日开始实行对于充电宝品类产品的销售限制。发布此限制的原因是基于安全因素:锂离子便携式…...
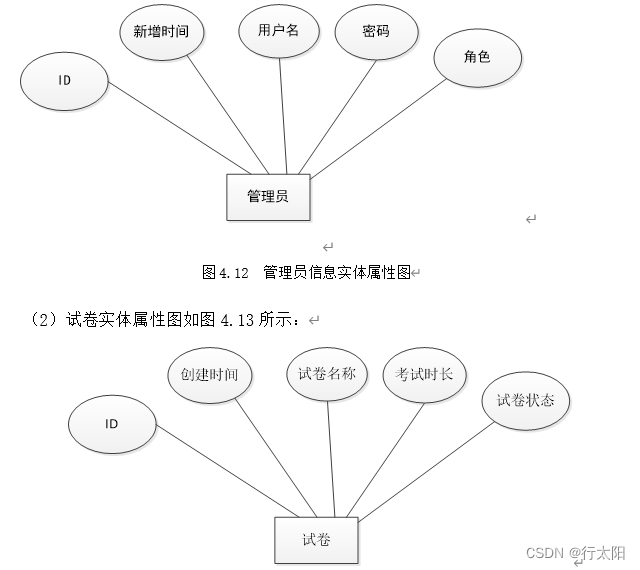
ssm+vue的课程网络学习平台管理系统(有报告)。Javaee项目,ssm vue前后端分离项目。
演示视频: ssmvue的课程网络学习平台管理系统(有报告)。Javaee项目,ssm vue前后端分离项目。 项目介绍: 采用M(model)V(view)C(controller)三层体…...

10月13日上课内容 Ansible 的脚本 --- playbook 剧本
playbooks 本身由以下各部分组成 (1)Tasks:任务,即通过 task 调用 ansible 的模板将多个操作组织在一个 playbook 中运行 (2)Variables:变量 (3)Templates:模…...
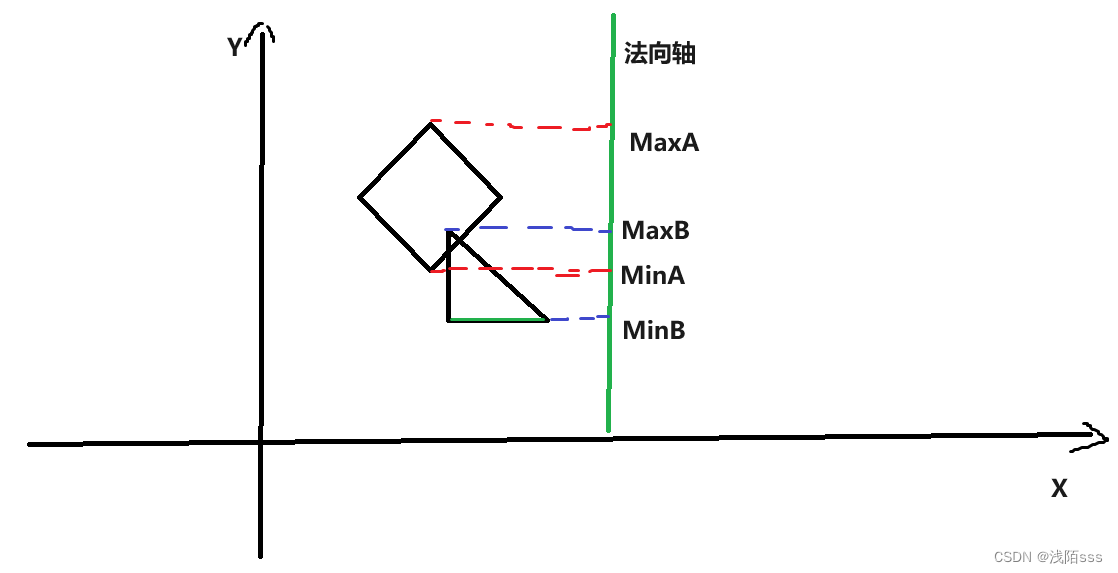
碰撞检测算法——分离轴算法在Unity中实现(二)
一、介绍 分离轴算法(简称SAT)通常用于检查两个简单多边形(凸边形)之间或多边形与圆之间的碰撞。本质上,如果您能够绘制一条线来分隔两个多边形,则它们不会发生碰撞,如果找不到一条线来分割两个…...

04在命令行中使用Maven命令创建Maven版的Web工程,并将工程部署到服务器的步骤
创建Maven版的Web工程 使用命令生成Web工程 使用mvn archetype:generate命令生成Web工程时,需要使用一个专门生成Web工程骨架的archetype(参照官网看到它的用法) -D表示后面要附加命令的参数,字母D和后面的参数是紧挨着的,中间没有任何其它…...

什么是指标体系,怎么搭建一套完整的指标体系?(附PDF素材)
什么是指标体系,怎么搭建一套完整的指标体系?数字化转型过程中,这个问题一直困扰着数据分析师。主要体现在: 各部门根据业务需求,都有一部分量化指标,但不够全面,对企业整体数据分析应用能力提…...
Windows提权方法论
Windows提权方法论 1.溢出漏洞提权2.计划任务提权3.SAM文件提权4.启动项提权5.不带引号的服务路径提权 1.溢出漏洞提权 溢出提权攻击的基本原理是,通过向目标系统发送过长的输入数据,超出了程序所分配的缓冲区大小,导致溢出。攻击者可以利用…...

推荐系统领域,over-uniform和oversmoothing问题
在推荐系统领域,“over-uniform” 和 “oversmoothing” 是与模型性能和推荐结果相关的两个概念,它们通常用于描述模型的行为和性能问题。以下是它们的区别: Over-Uniform(过于一致): Over-Uniform 推荐系…...

360测试开发技术面试题目
最近面试了360测试开发的职位,将面试题整理出来分享~ 一、java方面 1、java重载和重写的区别 重载overloading 多个方法、相同的名字,不同的参数 重写overwrite 子类继承父类,对方法进行重写 2、java封装的特性 可以改变内部实现,…...

智能井盖传感器扣好“城市纽扣”,让市民脚下更有安全感
随着城市化进程的快速推进,城市基础设施的维护和管理面临着日益严峻的挑战。作为城市生命线的重要组成部分,城市井盖在保障城市安全和稳定运行方面具有举足轻重的地位。然而,日益繁重的城市交通压力使得井盖的维护和管理问题逐渐显现。 城市井…...

1 随机事件与概率
首先声明【这个括号内的都是批注】 文章目录 1 古典概型求概率1.1 随机分配问题【放球】例子 1.2 简单随机抽样问题【取球】例子 2 几何概型求概率例子 3 重要公式求概率3.1 对立3.2 互斥3.3 独立3.4 条件(要做分母的必须大于0)例子 3.5 不等式或包含例…...

计算机视觉--通过HSV和YIQ颜色空间处理图像噪声
计算机视觉 文章目录 计算机视觉前言一、实现步骤二、实现总结 前言 利用HSV和YIQ颜色空间处理图像噪声。在本次实验中,我们使用任意一张图片,通过RGB转HSV和YIQ的操作,加入了椒盐噪声并将其转换回RGB格式,最终实现对图像的噪声处…...
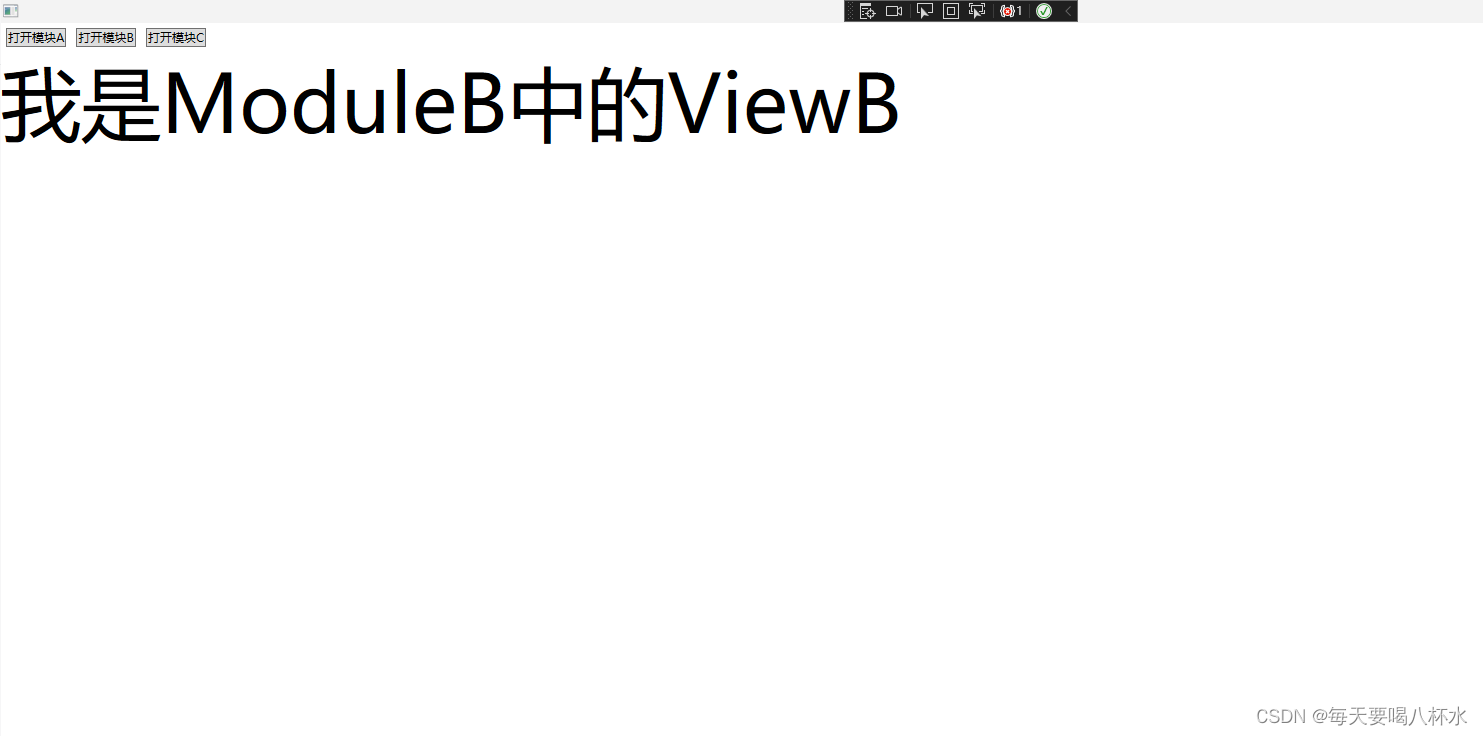
WPF中prism模块化
1、参照(wpf中prism框架切换页面-CSDN博客)文中配置MainView和MainViewModel 2、模块其实就是引用类库,新建两个类库ModuleA ModuleB,修改输出类型为类库,并配置以下文件: ModuleA ModuleAProfile ModuleB Module…...

MyBatis基础之注解与SQL 语句构建器
文章目录 注解实现简单增删改查SQL 语句构建器SelectProvider举例 注解实现简单增删改查 在 MyBatis 的核心配置文件中,你需要配置的不是 mapper 映射文件,而是 Mapper 接口所在的包路径。 <!-- 在配置文件中 关联包下的 接口类--> <mappers&…...

Spring Boot项目搭建流程
Spring Boot是一款基于Spring Framework的开源框架,用于快速构建独立的、可运行的、生产级的Spring应用程序。它通过自动化配置、减少样板代码和默认的项目结构,极大地简化了Spring应用程序的开发过程。本文将详细介绍Spring Boot项目搭建的流程。 一、…...
)
文献综述怎么写?研一萌新用Scholaread三天搞定开题文献综述(附100+篇文献整合方法)
开题在即,你面对电脑屏幕上50个PDF发呆,复制粘贴了20页摘要却被导师批"毫无逻辑"。问题不在于你不努力,而在于缺少系统化的文献综述工具链。本文拆解用Scholaread完成高质量文献综述的完整流程,让你从"不知道怎么开…...
)
STM32F030 HAL库驱动W25Q16实战:从数据手册到SPI读写代码(附避坑指南)
STM32F030 HAL库驱动W25Q16实战:从数据手册到SPI读写代码(附避坑指南) 1. 理解W25Q16存储芯片的核心特性 W25Q16作为一款16Mbit容量的SPI Flash存储器,在嵌入式系统中扮演着重要角色。这款芯片采用标准的SPI接口,支持单…...

ETime:高效推动你的时间
我做了一个开源时间工作台:ETime 如果你也试过很多时间管理工具,可能会遇到同一种疲惫:记录本身变成了另一件需要坚持的事。 ETime 想解决的不是“怎样把每一分钟都管起来”,而是更朴素的一件事:让开始更轻ÿ…...

Ubuntu 下 P106-100 矿卡 `nvidia-smi No devices were found` 问题解决全过程
Ubuntu 下 P106-100 矿卡 nvidia-smi No devices were found 问题解决全过程 最近折腾一张老矿卡 P106-100,在 Ubuntu 下遇到一个非常经典的问题: nvidia-smi No devices were found但是: lspci | grep -i nvidia却能看到显卡: 01:00.0 3D controller: NVIDIA Corporat…...

通勤便携首选:2026电脑推荐笔记本,日常出行无负担
对于每天往返于家和公司、背着电脑挤地铁公交的职场人来说,挑选笔记本的核心诉求愈发清晰,既要机身轻薄便携,不会给通勤增加额外负担,又要性能够用,多开办公软件、线上会议不卡顿,还要续航持久,…...

麦肯锡AI揭秘:AI的真正价值不在算法,而在重构组织与结构竞争力
【摘者按:麦肯锡在《The State of AI 2025》报告中深刻指出,AI的真正价值早已超越了单纯的算法性能,其核心在于通过“重构”来重塑企业的组织与结构竞争力。当企业走出“试点炼狱”,不再将AI视为简单的技术堆砌,而是将…...

Teledyne PDS后处理软件保姆级教程:从新建项目到格网导出的完整流程
Teledyne PDS后处理软件从入门到精通:多波束数据处理全流程实战指南 第一次打开Teledyne PDS后处理软件时,满屏的专业术语和复杂菜单让不少水下测量工程师感到无从下手。作为处理T50P等多波束测深数据的核心工具,PDS软件的操作流程直接关系到…...

Google 的 IDE 演进小史
不知道你平时用的 IDE 是什么?小七的工程师同事有在用 Vim 的,也有 Emacs 党,IntelliJ 全家桶也有人在用,用得最多的可能是 VS Code。只要代码能写好、工具链能跑通,似乎大家没有必要使用同一个 IDE。 Google 早年也是…...

❌别再硬拆QA了!谷歌SEO最大的坑你还在踩
2026年5月7日,谷歌在官方开发者文档悄然更新了一则重磅公告:FAQ 富摘要(FAQ Rich Results)正式全面下线,即日起不再搜索结果中展示。这不是临时调整,而是持续三年收紧后的终极收尾 —— 从 2023 年仅对政府、医疗站开放,到 2026 年 3 月大幅缩减展示量,再到如今彻底关闭…...

OpenRGB技术架构深度解析:如何用开源统一协议打破RGB生态壁垒
OpenRGB技术架构深度解析:如何用开源统一协议打破RGB生态壁垒 【免费下载链接】OpenRGB Open source RGB lighting control that doesnt depend on manufacturer software. Supports Windows, Linux, MacOS. Mirror of https://gitlab.com/CalcProgrammer1/OpenRGB.…...