【MySQL】表的查询与连接
文章目录
- 预备工作
- 一、表的基本查询
- 1、简单基本查询
- 2、分组聚合统计
- 3、基本查询练习
- 二、表的复合查询
- 1、多表查询
- 2、子查询
- 2.1 **单行子查询**
- 2.2 **多行子查询**
- 2.3 **多列子查询**
- 2.4 在from子句中使用子查询
- 3、合并查询
- 三、表的连接
- 1、自连接
- 2、内连接
- 3、外连接
预备工作
scott 数据库是 oracle 9i 的经典测试数据库,用于为初学者提供一些简单的应用示例,便于初学者进行练习,其中的表和表间的关系演示了关系型数据库的一些基本原理。本文所有的查询工作都是基于 scott 数据库进行的,scott 数据库的 .sql 文件代码如下:
DROP database IF EXISTS `scott`;
CREATE database IF NOT EXISTS `scott` DEFAULT CHARACTER SET utf8 COLLATE utf8_general_ci;USE `scott`;DROP TABLE IF EXISTS `dept`;
CREATE TABLE `dept` (`deptno` int(2) unsigned zerofill NOT NULL COMMENT '部门编号',`dname` varchar(14) DEFAULT NULL COMMENT '部门名称',`loc` varchar(13) DEFAULT NULL COMMENT '部门所在地点'
);DROP TABLE IF EXISTS `emp`;
CREATE TABLE `emp` (`empno` int(6) unsigned zerofill NOT NULL COMMENT '雇员编号',`ename` varchar(10) DEFAULT NULL COMMENT '雇员姓名',`job` varchar(9) DEFAULT NULL COMMENT '雇员职位',`mgr` int(4) unsigned zerofill DEFAULT NULL COMMENT '雇员领导编号',`hiredate` datetime DEFAULT NULL COMMENT '雇佣时间',`sal` decimal(7,2) DEFAULT NULL COMMENT '工资月薪',`comm` decimal(7,2) DEFAULT NULL COMMENT '奖金',`deptno` int(2) unsigned zerofill DEFAULT NULL COMMENT '部门编号'
);DROP TABLE IF EXISTS `salgrade`;
CREATE TABLE `salgrade` (`grade` int(11) DEFAULT NULL COMMENT '等级',`losal` int(11) DEFAULT NULL COMMENT '此等级最低工资',`hisal` int(11) DEFAULT NULL COMMENT '此等级最高工资'
);insert into dept (deptno, dname, loc)
values (10, 'ACCOUNTING', 'NEW YORK');
insert into dept (deptno, dname, loc)
values (20, 'RESEARCH', 'DALLAS');
insert into dept (deptno, dname, loc)
values (30, 'SALES', 'CHICAGO');
insert into dept (deptno, dname, loc)
values (40, 'OPERATIONS', 'BOSTON');insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7369, 'SMITH', 'CLERK', 7902, '1980-12-17', 800, null, 20);insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7499, 'ALLEN', 'SALESMAN', 7698, '1981-02-20', 1600, 300, 30);insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7521, 'WARD', 'SALESMAN', 7698, '1981-02-22', 1250, 500, 30);insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7566, 'JONES', 'MANAGER', 7839, '1981-04-02', 2975, null, 20);insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7654, 'MARTIN', 'SALESMAN', 7698, '1981-09-28', 1250, 1400, 30);insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7698, 'BLAKE', 'MANAGER', 7839, '1981-05-01', 2850, null, 30);insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7782, 'CLARK', 'MANAGER', 7839, '1981-06-09', 2450, null, 10);insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7788, 'SCOTT', 'ANALYST', 7566, '1987-04-19', 3000, null, 20);insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7839, 'KING', 'PRESIDENT', null, '1981-11-17', 5000, null, 10);insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7844, 'TURNER', 'SALESMAN', 7698,'1981-09-08', 1500, 0, 30);insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7876, 'ADAMS', 'CLERK', 7788, '1987-05-23', 1100, null, 20);insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7900, 'JAMES', 'CLERK', 7698, '1981-12-03', 950, null, 30);insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7902, 'FORD', 'ANALYST', 7566, '1981-12-03', 3000, null, 20);insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7934, 'MILLER', 'CLERK', 7782, '1982-01-23', 1300, null, 10);insert into salgrade (grade, losal, hisal) values (1, 700, 1200);
insert into salgrade (grade, losal, hisal) values (2, 1201, 1400);
insert into salgrade (grade, losal, hisal) values (3, 1401, 2000);
insert into salgrade (grade, losal, hisal) values (4, 2001, 3000);
insert into salgrade (grade, losal, hisal) values (5, 3001, 9999);
大家可以在自己的工作目录下创建 scott_data.sql 文件,然后将上述代码拷贝进去,最后在 mysql 中使用 source 语句将其导入即可。
scott 数据库中一共有三张表 – emp、dept、salgrade,它们分别代表员工信息、部门信息以及薪资等级信息,具体的表结构以及表中数据如下: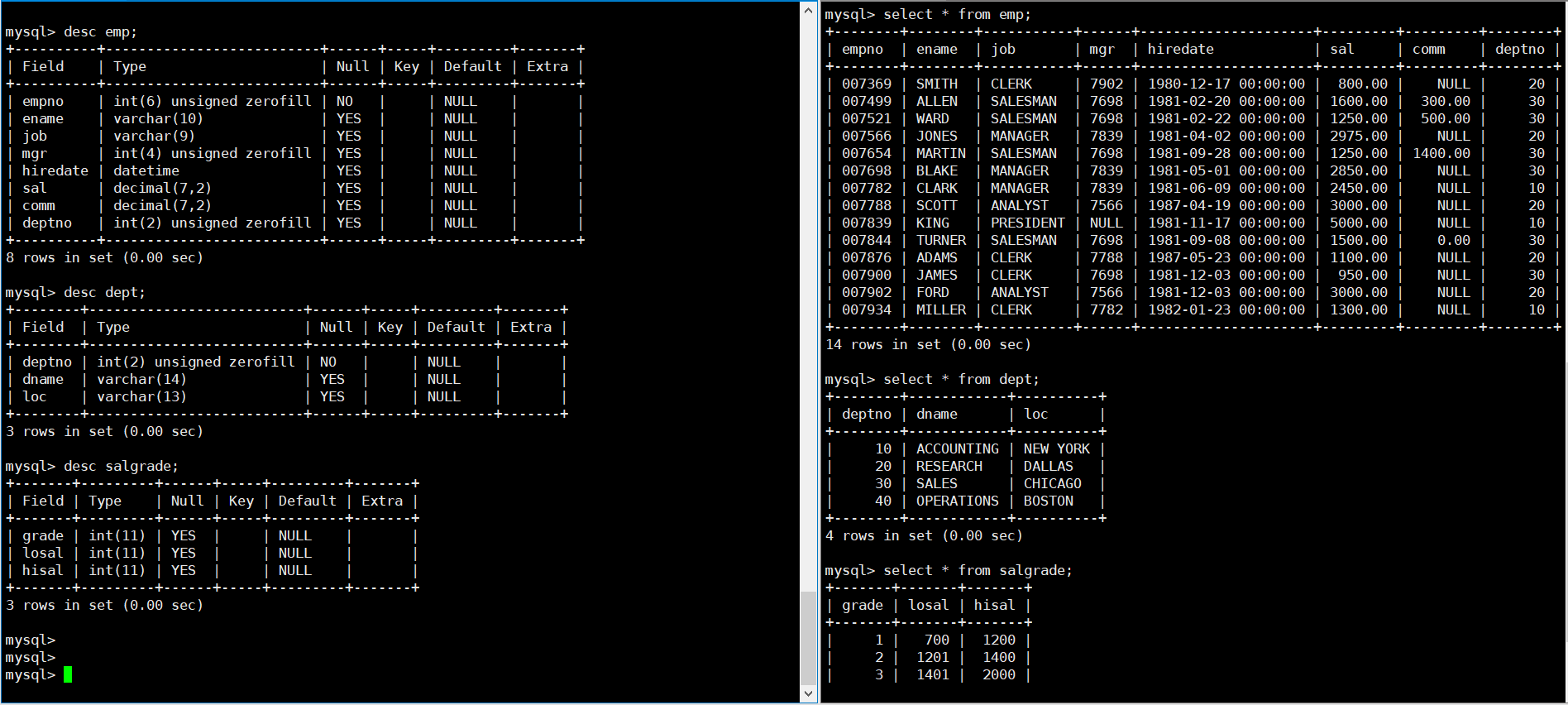
一、表的基本查询
1、简单基本查询
MySQL 表查询的基本语法格式如下:
SELECT
[DISTINCT] {* | {column [, column] ...}
[FROM table_name]
[WHERE ...]
[ORDER BY column [ASC | DESC], ...]
LIMIT ...
其中 select from where 是查询的基本关键字,其余部分关键字的含义如下:
- distinct:对查询到的结果进行去重。
- order by:按照某一列或某几列对查询结果进行排序,默认使用 ASC 排升序,排降序可以指定 DESC。
- limit:筛选分页结果,即指定显示查询结果的哪些行。(注:对未知表进行查询时,最好加一条 LIMIT 1,避免因为表中数据过大,查询全表数据导致数据库卡死)
注意:MySQL 不区分大小写和单双引号,所以这些关键字在使用是无论是大写还是小写都可以。
下面是关于针对这些关键字使用的一些基本案例:
- 查找SMITH员工的基本信息,包括员工名、部门号以及薪资。
select ename, deptno, sal from emp where ename = 'SMITH';

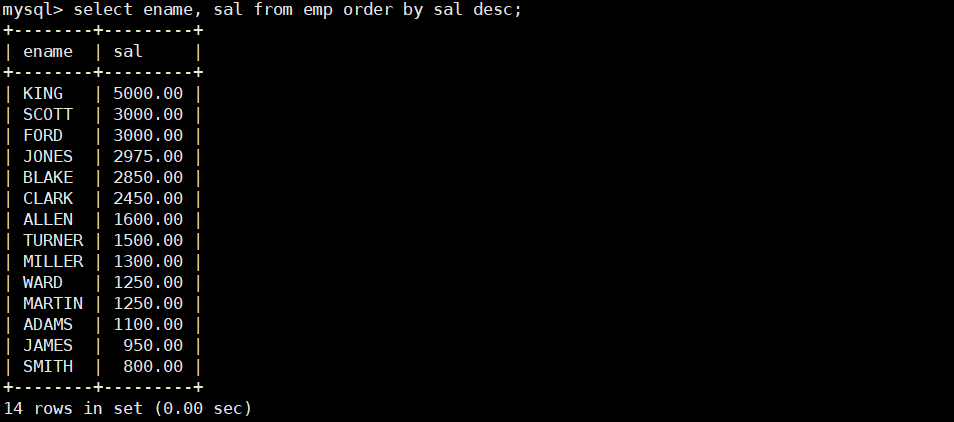
- 查询所有员工的工资信息,并按工资降序排序。
select ename, sal from emp order by sal desc;
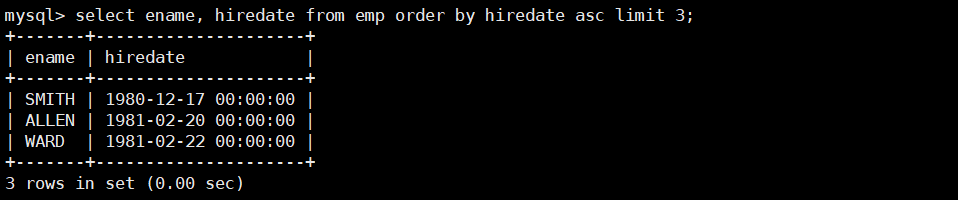
- 查找公司中工龄排名前三的员工。
select ename, hiredate from emp order by hiredate asc limit 3;
2、分组聚合统计
聚合统计
MySQL 中存在一些用于对数据进行计算和汇总的聚合函数,它们可以对一组行的数据执行操作,并返回单个结果。常见的聚合函数如下:
| -函数 | -说明 |
|---|---|
| COUNT([DISTINCT] expr) | 返回查询到的数据的 数量 |
| SUM([DISTINCT] expr) | 返回查询到的数据的 总和,不是数字没有意义 |
| AVG([DISTINCT] expr) | 返回查询到的数据的 平均值,不是数字没有意义 |
| MAX([DISTINCT] expr) | 返回查询到的数据的 最大值,不是数字没有意义 |
| MIN([DISTINCT] expr) | 返回查询到的数据的 最小值,不是数字没有意义 |
- 统计公司一共有多少员工以及公司所有的最高、最低工资分别是多少。
select count(*) 员工数量, max(sal) 最高工资, min(sal) 最低工资 from emp;

分组聚合统计
除了聚合统计,MySQL 还支持在 select 中使用 group by 子句对指定列进行分组查询,group by 字句通常需要配合聚合函数使用。
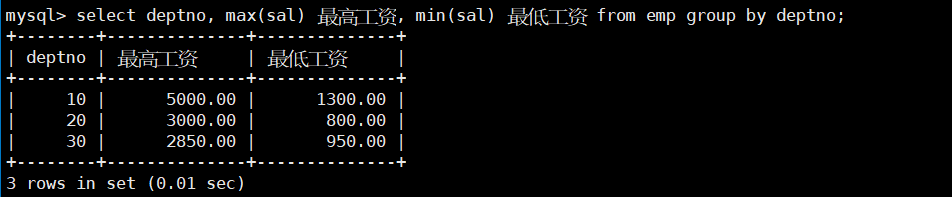
- 如何显示每个部门的平均工资和最高工资。
select deptno, max(sal) 最高工资, min(sal) 最低工资 from emp group by deptno;
如何理解分组 (重要):
在上面的案例中,我们要求每个部门的平均工资与最高工作,然而 scott 中并没有为每一个部门单独 create 一个工资表,而只有一个 emp 表,里面包含了所有部门的员工信息,所以我们需要对 emp 表按照 deptno 进行分组。
按照 deptno 进行 group by 之后,一张物理上的 emp 表就在逻辑上被分为了三张子表,每张子表中员工的部门号是相同的;所以我们就可以 将分组理解为分表 – 这个分表不是真的将存储在数据库中的一张 emp 表分为了三张表,而是将 emp 分成了逻辑上的三张表。
那么现在,我们只需要分别对每一张子表进行聚合统计得到最高工资和平均工作即可;所以,通过 “分表”,我们就可以将分组查询简化理解为对分组得到的子表的查询,只需要在最后面添加 group by 子句即可。
注:在分组查询中,select 后面的列信息通常只能包含聚合函数以及出现在分组条件中的列。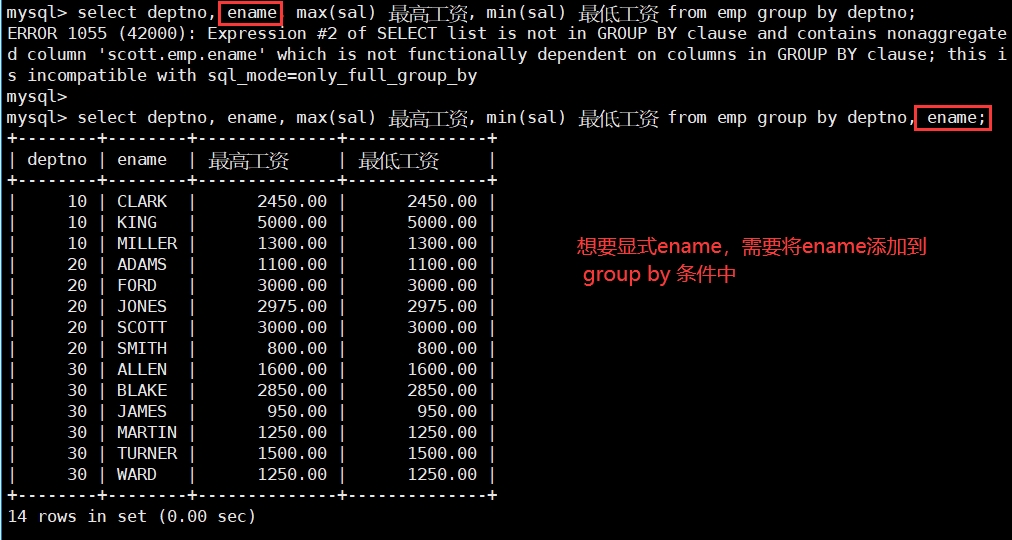
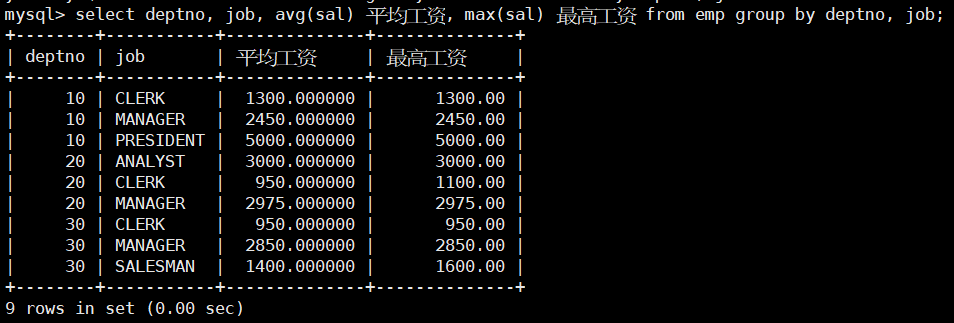
现在我们用 “分表” 的思想来求一下每个部门的每种岗位的平均工资和最低工资:
求每个部门每种岗位的平均工资与最低工资,肯定需要按部门和岗位进行分组,而分组就是分表,所以我们可以理解为对分组后得到的子表进行聚合统计查询平均工资和最低工资 –
select deptno, job, avg(sal), min(sal) from emp,最后再加上group by deptno, job即可。
select deptno, job, avg(sal) 平均工资, max(sal) 最高工资 from emp group by deptno, job;
having 条件筛选
having 用于和 group by 配合使用,对 group by 的结果进行过滤。
- 显示平均工资低于2000的部门和它的平均工资。
select deptno, avg(sal) 平均工资 from emp group by deptno having 平均工资 < 2000;

如何理解 where 和 having 的关系:
where 和 having 都是用于条件筛选的关键字,二者的区别在于 where 主要用于在查询一张表时对查询条件做筛选;而 having 主要用于在分组时对分组的结果进行筛选。其实把 having 当成 where 来用 MySQL 的语法也不会报错,但我们不建议这样做。
SQL 查询中各个关键字的执行先后顺序:
from > on > join > where > group by > with > having > select > distinct > order by > limit
3、基本查询练习
- 查询工资高于500或岗位为MANAGER的雇员,同时还要满足他们的姓名首字母为大写的J;
select * from emp where (sal > 100 or job = 'MANAGER') and ename like 'J%';
- 按照部门号升序而雇员的工资降序排序;
select * from emp order by deptno asc, sal desc;
- 使用年薪进行降序排序;
select ename, sal*12+ifnull(comm, 0) 年薪 from emp order by 年薪 desc;
- 显示工资高于平均工资的员工信息;
select * from emp where sal > (select avg(sal) from emp);
- 显示每个部门的平均工资和最高工资;
select avg(sal) 平均工资, max(sal)最高工资 from emp group by deptno;
- 显示每种岗位的雇员总数,平均工资;
select job, count(*) 雇员总数, avg(sal) 平均工资 from emp group by job;
二、表的复合查询
1、多表查询
上面我们讲解的 mysql 表的查询都是对一张表进行查询,但在实际开发中数据往往来自不同的表,所以我们需要进行多表查询。
笛卡尔积
笛卡尔积(Cartesian Product)是指在没有使用任何条件连接的情况下,将两个或多个表中的每一行与其他表中的每一行进行组合,从而得到一个包含所有可能组合的表。如下: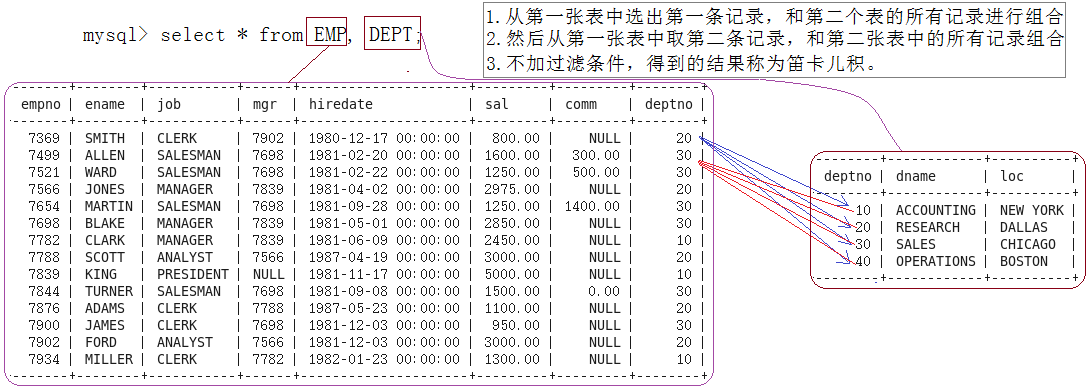
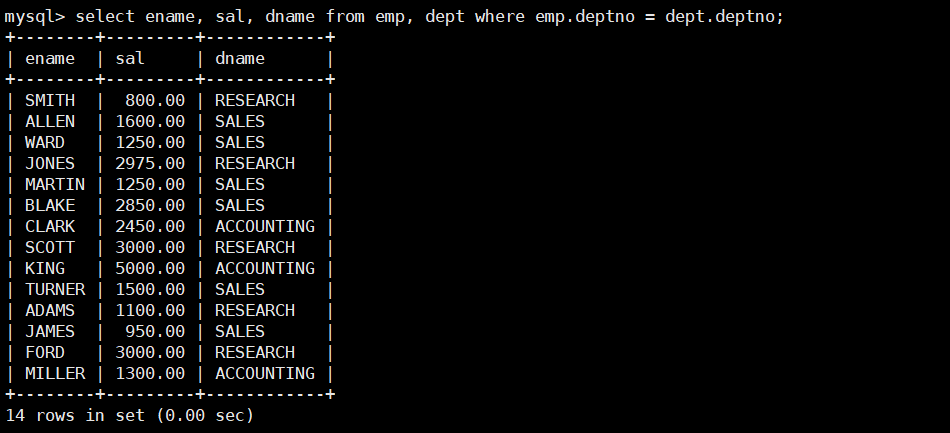
- 显示雇员名、雇员工资以及所在部门的名字。
题目要求我们显示雇员名、雇员工资以及所在部门的名字,其中名、雇员工资都在 emp 表中,但是部门名字在 dept 表中,所以我们需要对 emp 和 dept 这两张表做笛卡尔积,然后再筛选掉不需要的行即可。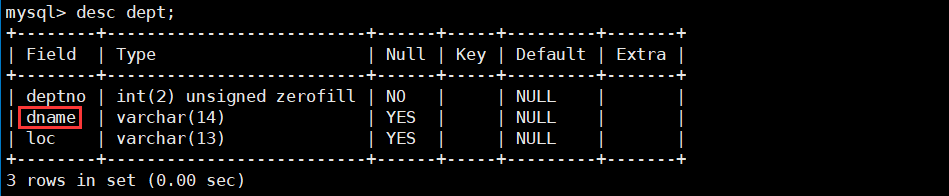
select ename, sal, dname from emp, dept where emp.deptno = dept.deptno;
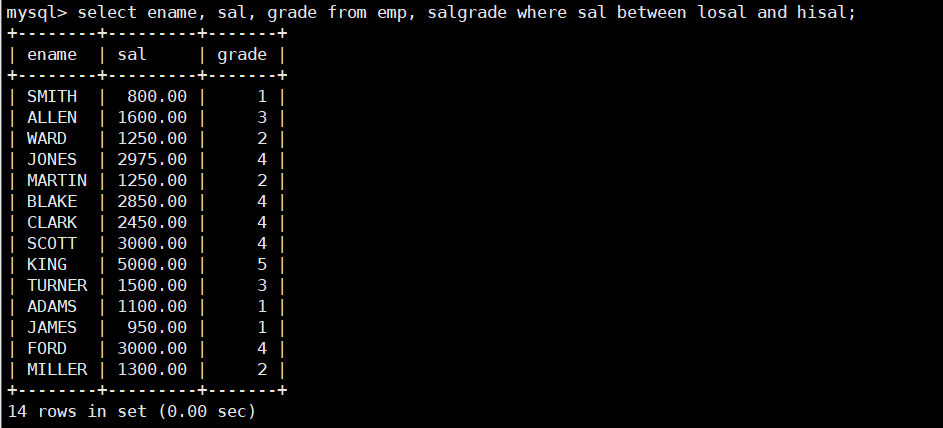
- 显示各个员工的姓名,工资,及工资级别;
select ename, sal, grade from emp, salgrade where sal between losal and hisal;
总结:其实多表查询本质上也是单表查询 – 对两张表笛卡尔积的结果 (单表) 进行条件筛选与查询。
2、子查询
子查询是指嵌入在其他 sql 语句中的 select 语句,也叫嵌套查询。
2.1 单行子查询
单行子查询是指嵌入在其他 sql 语句中的 select 语句的结果只有一行一列,即单个数据。
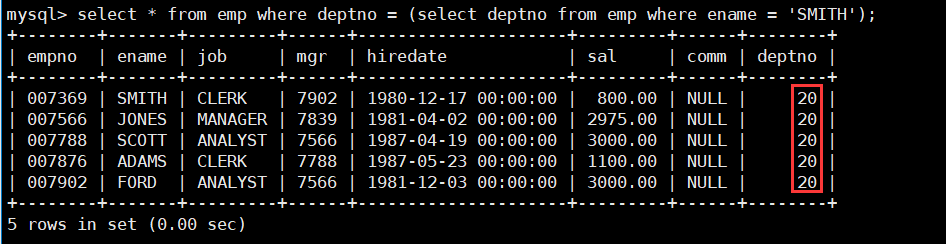
- 显示SMITH同一部门的员工。
显示SMITH同一部门的员工一共分为两步:1. 找出SMITH所在的部门;2. 找出在此部门工作的员工。而第一步的结果是单个数据(一个员工只属于一个部门),这就是单行子查询。
select * from emp where deptno = (select deptno from emp where ename = 'SMITH');
2.2 多行子查询
单行子查询是指嵌入在其他 sql 语句中的 select 语句的结果有多行,但只有一列,即多个数据。
与多行子查询相关的关键字有三个:
- in:表示在其中,即与多个数据中的一个相等即可。
- all:表示全部,即大于/小于/… 多个数据中的全部。
- any:表示任意,即大于/小于/… 多个数据中的任意一个。
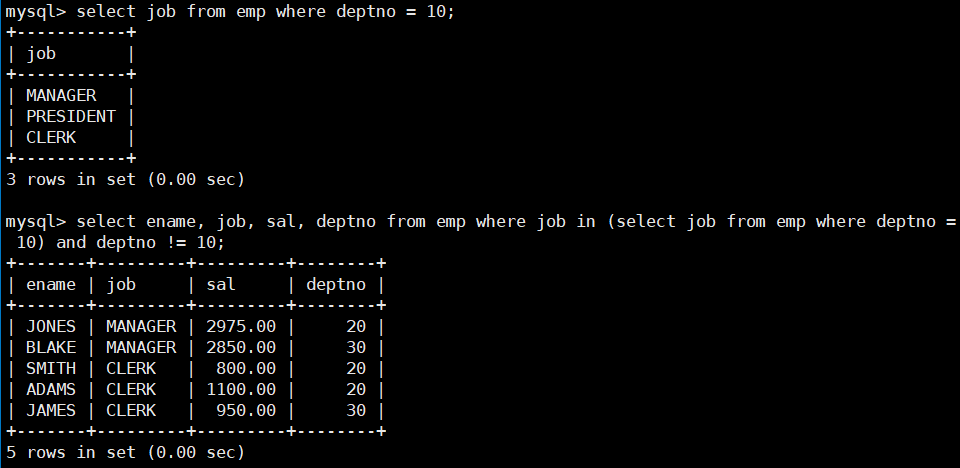
- 查询和10号部门的工作岗位相同的雇员的名字,岗位,工资,部门号,但是不包含10自己的。
select ename, job, sal, deptno from emp where job in (select job from emp where deptno = 10) and deptno != 10;
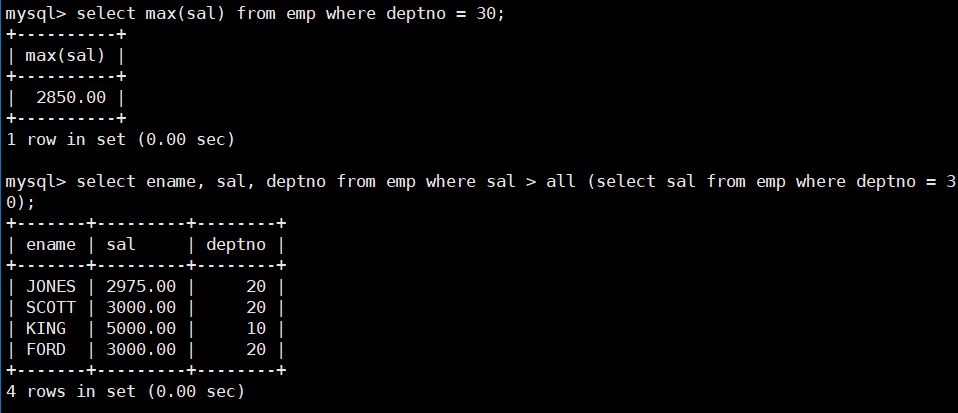
- 显示工资比部门30的所有员工的工资高的员工的姓名、工资和部门号。
select ename, sal, deptno from emp where sal > all (select sal from emp where deptno = 30);
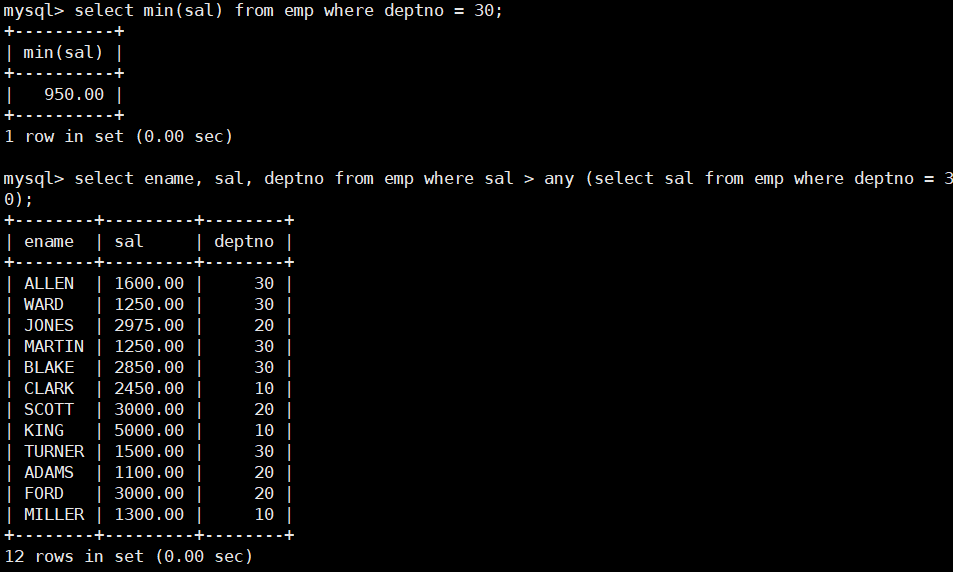
- 显示工资比部门30的任意员工的工资高的员工的姓名、工资和部门号(包含自己部门的员工)。
select ename, sal, deptno from emp where sal > any (select sal from emp where deptno = 30);
2.3 多列子查询
多列子查询是指嵌入在其他 sql 语句中的 select 语句的结果有多列 (不一定有多行)。多列子查询中也可以使用 in/all/any 关键字。
- 查询和SMITH的部门和岗位完全相同的所有雇员,不含SMITH本人。
select ename from emp where (deptno, job) = (select deptno, job from emp where ename='SMITH') and ename <> 'SMITH';

2.4 在from子句中使用子查询
对 mysql 表的理解
在前面分组聚合统计中我们提到,分组其实就是 “分表”,我们可以将分组的结果当成逻辑上的子表来看待,然后分组查询就简化为了对子表进行查询,而这其实就是最基础的表查询。
同样,我们也可以将 select 查询过程中的中间结果以及查询出来的最终结果都看作是逻辑上的表,那么我们自然也就可以将这个 “表” 放在 from 子句的后面了。
所以,我们可以认为 mysql 中一切皆表,任何表的查询其本质上都是单表查询,这和我们 Linux 中的一切皆文件很类似。
比如,我们要显示每个高于自己部门平均工资的员工的姓名、部门、工资、平均工资,我们可以一步步的来拆解这个查询:
-
查出每个部门的平均工资:
select deptno, avg(sal) avg_sal from emp group by deptno; -
将查询出来的 “deptno, avg_sal” 这个中间结果当成表,与 emp 表进行笛卡尔积,得到一张新的表:
select * from emp t1, (select deptno, avg(sal) avg_sal from emp group by deptno) t2; -
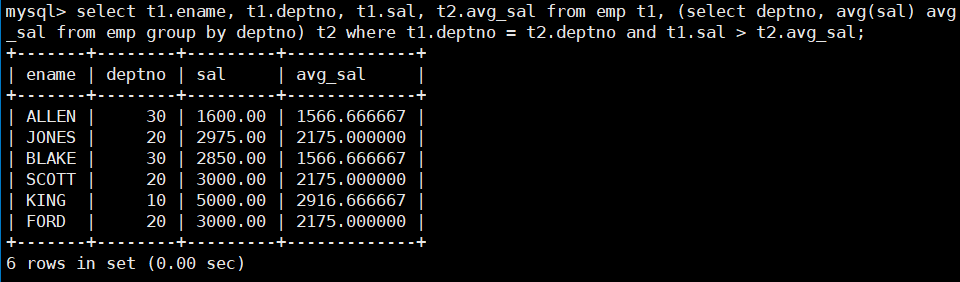
在这个大的表中找出是同一部门且工作高于部门平均工资 agv_sal 的员工的姓名、部门、工资以及部门的平均工资:
select t1.ename, t1.deptno, t1.sal, t2.avg_sal from emp t1, (select deptno, avg(sal) avg_sal from emp group by deptno) t2 where t1.deptno = t2.deptno and t1.sal > t2.avg_sal;
查找每个部门工资最高的人的姓名、工资、部门、最高工资:
-
找出每个部门工资最高的人:
select deptno, max(sal) max_sal from emp group by deptno; -
将这个表与 emp 表进行笛卡尔积:
select * from emp t1, (select deptno, max(sal) max_sal from emp group by deptno) t2; -
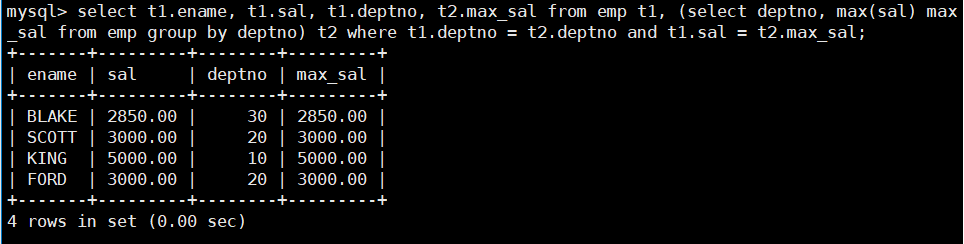
在这个大表中找出同一部门且工资等于部门最高工资的员工的姓名、工资、部门以及部门的最高工资:
select t1.ename, t1.sal, t1.deptno, t2.max_sal from emp t1, (select deptno, max(sal) max_sal from emp group by deptno) t2 where t1.deptno = t2.deptno and t1.sal = t2.max_sal;
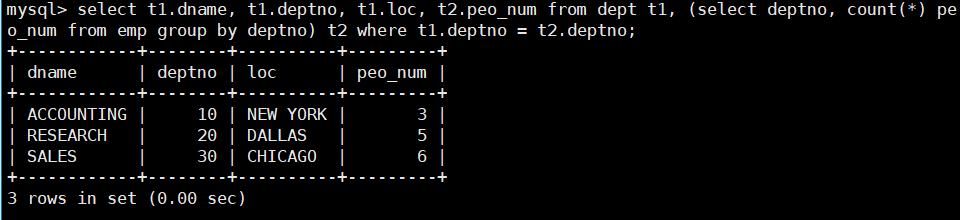
- 显示每个部门的信息(部门名,编号,地址)和人员数量。
select t1.dname, t1.deptno, t1.loc, t2.peo_num from dept t1, (select deptno, count(*) peo_num from emp group by deptno) t2 where t1.deptno = t2.deptno;
3、合并查询
在实际应用中,为了合并多个 select 的执行结果,可以使用集合操作符 union,union all。
union
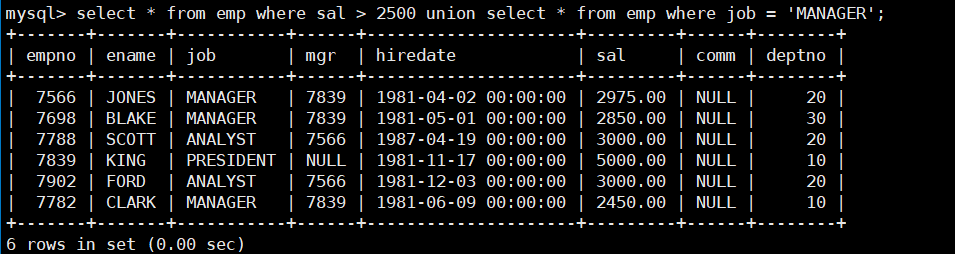
union 操作符用于取得两个结果集的并集,当使用该操作符时,会自动去掉结果集中的重复行。
- 将工资大于2500或职位是MANAGER的人找出来。
select * from emp where sal > 2500 union select * from emp where job = 'MANAGER';
union all
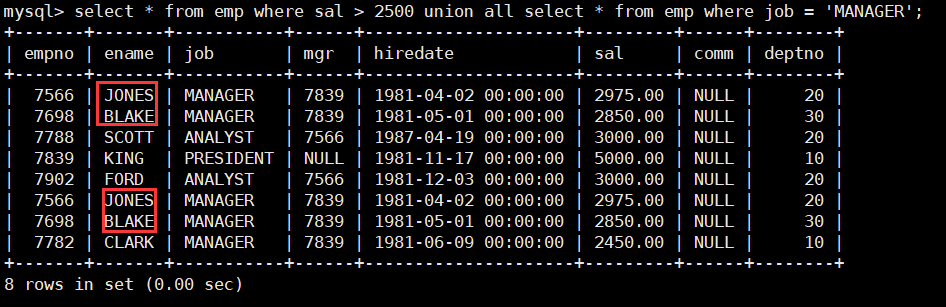
union all 操作符用于取得两个结果集的并集,当使用该操作符时,不会去掉结果集中的重复行。
select * from emp where sal > 2500 union all select * from emp where job = 'MANAGER';
三、表的连接
1、自连接
自连接是指在同一张表上进行连接查询,即自己与自己做笛卡尔积。
- 显示员工FORD的上级领导的编号和姓名。
select t2.empno, t2.ename from emp t1, emp t2 where t1.ename = 'FORD' and t2.empno = t1.mgr;

2、内连接
内连接实际上就是利用 where 子句对两种表形成的笛卡儿积进行筛选,我们前面学习的查询本质上也是内连接,内连接也是在开发过程中使用的最多的连接查询。
内连接语法如下:
select 字段 from 表1 inner join 表2 on 连接条件 and 其他条件;
- 显示SMITH的名字和部门名称。
select emp.ename, dept.dname from emp inner join dept on emp.deptno = dept.deptno and emp.ename = 'SMITH';

3、外连接
外连接分为左外连接和右外连接。
左外连接
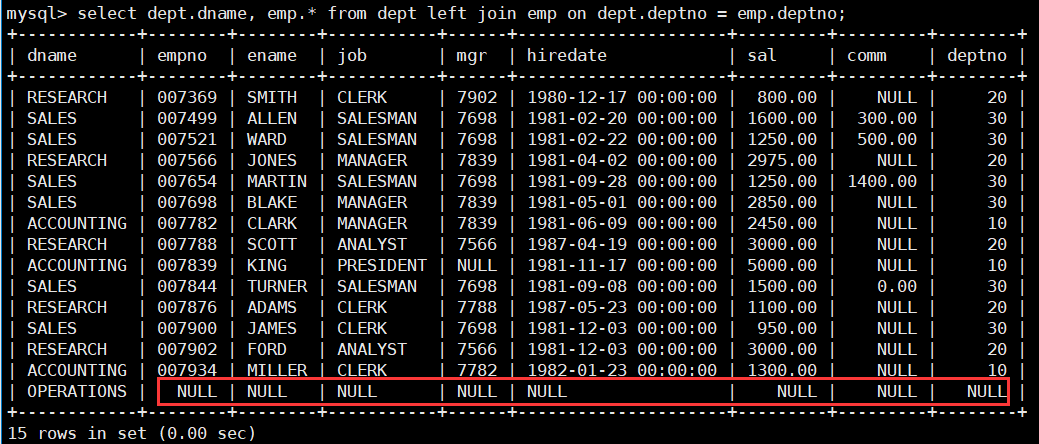
左外连接是指左边表中的数据保持不变,右边表中的数据按照筛选条件过滤,记录不足的列使用 NULL 填充,然后将二者连接起来。
语法如下:
select 字段名 from 表名1 left join 表名2 on 连接条件
- 列出部门名称和这些部门的员工信息,同时列出没有员工的部门。
select dept.dname, emp.* from dept left join emp on dept.deptno = emp.deptno;
右外连接
右外连接是指右外表中的数据保持不变,右外表中的数据按照筛选条件过滤,记录不足的列使用 NULL 填充,然后将二者连接起来。
语法如下:
select 字段名 from 表名1 right join 表名2 on 连接条件
注:其实左外连接完全可以实现右外连接的效果 – 将左右两张表的顺序交换即可。
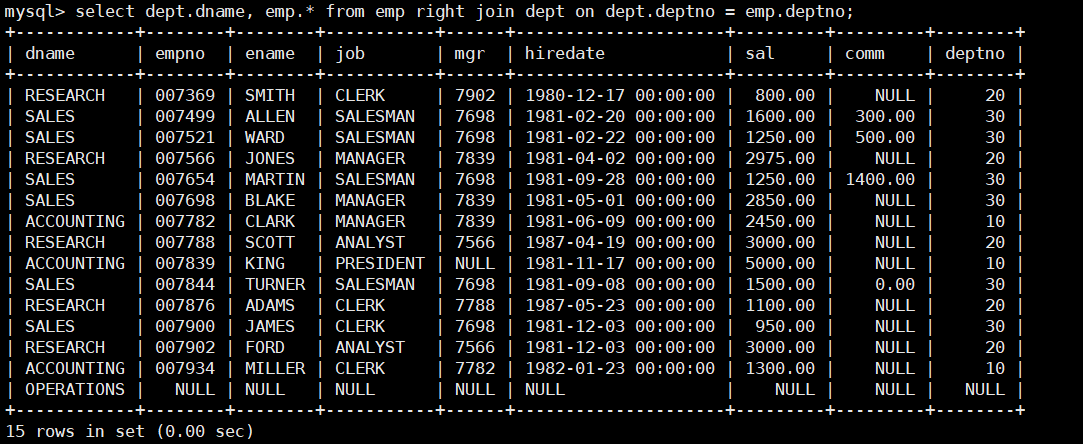
- 列出部门名称和这些部门的员工信息,同时列出没有员工的部门。
select dept.dname, emp.* from emp right join dept on dept.deptno = emp.deptno;
相关文章:
【MySQL】表的查询与连接
文章目录 预备工作一、表的基本查询1、简单基本查询2、分组聚合统计3、基本查询练习 二、表的复合查询1、多表查询2、子查询2.1 **单行子查询**2.2 **多行子查询**2.3 **多列子查询**2.4 在from子句中使用子查询 3、合并查询 三、表的连接1、自连接2、内连接3、外连接 预备工作…...
)
AtCoder Beginner Contest 324(F)
AtCoder Beginner Contest 324 F Beautiful Path 需要一点思维的转化,一时竟然没想到。 题意 给定大小为 n n n 的有向图, m m m 条边,每条边有 b i , c i b_i,c_i bi,ci 两个属性,需要找到一条从 1 ∼ n 1\sim n 1∼n…...
-- i2s - 数字音频)
LuatOS-SOC接口文档(air780E)-- i2s - 数字音频
示例 -- 这个库属于底层适配库, 具体用法请查阅示例 -- demo/multimedia -- demo/tts -- demo/record常量 常量 类型 解释 i2s.MODE_I2S number I2S标准,比如ES7149 i2s.MODE_LSB number LSB格式 i2s.MODE_MSB number MSB格式,比如TM8211 …...

瑞芯微RK3568核心板在边缘服务器产品中的应用-迅为电子
迅为RK3568核心板在边缘服务器产品中可以发挥关键作用,为边缘计算应用提供高性能的计算和多媒体处理能力。边缘服务器通常用于处理和存储数据,执行本地计算任务,并支持与远程云服务的通信。以下是RK3568核心板在边缘服务器产品中的应用方案&a…...

pg ash自制版 pg_active_session_history
一、 实现功能 由于pgsentinel插件存在严重的内存占用问题,本篇改为自行实现,但其语句仍可以参考pgsentinel插件。PostgreSQL ash —— pgsentinel插件 学习与踩坑记录_CSDN博客 v1.0 根据pg 14版本设计及测试,仅支持收集主库信息。默认每10秒…...
Elasticsearch系列组件:Kibana无缝集成的数据可视化和探索平台
Elasticsearch 是一个开源的、基于 Lucene 的分布式搜索和分析引擎,设计用于云计算环境中,能够实现实时的、可扩展的搜索、分析和探索全文和结构化数据。它具有高度的可扩展性,可以在短时间内搜索和分析大量数据。 Elasticsearch 不仅仅是一个…...
phpcms_v9模板制作及二次开发常用代码
0:调用最新文章,带所在版块 {pc:get sql"SELECT a.title, a.catid, b.catid, b.catname, a.url as turl ,b.url as curl,a.id FROM v9_news a, v9_category b WHERE a.catid b.catid ORDER BY a.id DESC " num"15" cache"300"} {lo…...
-概述)
自然语言处理(NLP)-概述
NLP 一、什么是自然语言处理(NLP)二、NLP的发展三、相关理论1 语言模型2 词向量表征和语义分析3 深度学习 一、什么是自然语言处理(NLP) 什么是自然语言处理 二、NLP的发展 三、相关理论 1 语言模型 序列数据形式多样…...

Python开发者的宝典:CSV和JSON数据处理技巧大公开!
更多资料获取 📚 个人网站:涛哥聊Python 在Python中处理CSV和JSON数据时,需要深入了解这两种数据格式的读取、写入、处理和转换方法。 下面将详细介绍如何在Python中处理CSV和JSON数据,并提供一些示例和最佳实践。 CSV数据处理…...

Unity中Commpont类获取子物体的示例
// 本脚本用于演示Component类 方法 //任何一个组件 都可以从游戏物体获取或者从其父对象哪里 子对象哪里获取,一个组件也可以拿到同一个物体上的其他组件 using System.Collections; using System.Collections.Generic; using UnityEngine; public class Component…...
【Vue面试题二十一】、Vue中的过滤器了解吗?过滤器的应用场景有哪些?
文章底部有个人公众号:热爱技术的小郑。主要分享开发知识、学习资料、毕业设计指导等。有兴趣的可以关注一下。为何分享? 踩过的坑没必要让别人在再踩,自己复盘也能加深记忆。利己利人、所谓双赢。 面试官:Vue中的过滤器了解吗&am…...

Unity 3D基础——缓动效果
1.在场景中新建两个 Cube 立方体,在 Scene 视图中将两个 Cude的位置错开。 2.新建 C# 脚本 MoveToTarget.cs(写完记得保存) using System.Collections; using System.Collections.Generic; using UnityEngine;public class MoveToTarget : M…...

高校教务系统登录页面JS分析——南京邮电大学
高校教务系统密码加密逻辑及JS逆向 本文将介绍南京邮电大学教务系统的密码加密逻辑以及使用JavaScript进行逆向分析的过程。通过本文,你将了解到密码加密的基本概念、常用加密算法以及如何通过逆向分析来破解密码。 本文仅供交流学习,勿用于非法用途。 一…...
css实现排行榜样式(vue组件)
先看效果图: <template><div class"lawyer-refund-wrap"><div class"content"><divv-for"(item, index) in dataList" :key"index":style"{width: calc(100% - ${(index 1) * 10}px)}"c…...

I2VGen-XL高清图像生成视频大模型
本项目I2VGen-XL旨在解决根据输入图像生成高清视频任务。I2VGen-XL由达摩院研发的高清视频生成基础模型之一,其核心部分包含两个阶段,分别解决语义一致性和清晰度的问题,参数量共计约37亿,模型经过在大规模视频和图像数据混合预训…...
-每天10个小知识)
Angular知识点系列(1)-每天10个小知识
目录 1. Angular工作原理和与其他前端框架的区别2. 使用Angular的经验和最喜欢的特性3. 使用的最复杂的Angular组件或指令4. Angular的依赖注入系统和示例5. Angular的模块和组件生命周期6. 使用Angular路由和路由保护7. 在Angular应用中实现延迟加载8. 处理Angular应用中的状态…...
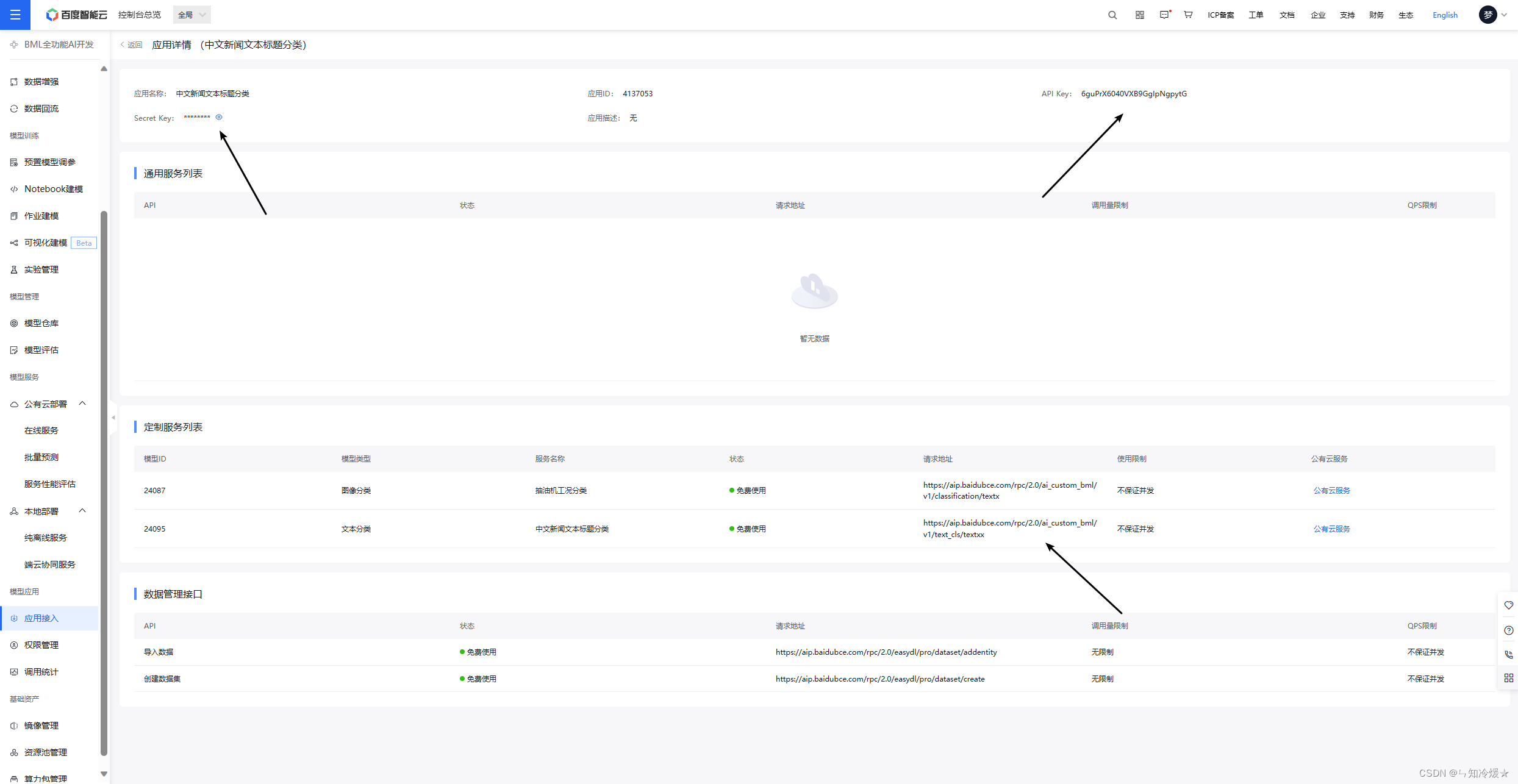
【从0开发】百度BML全功能AI开发平台【实操:以部署情感分析模型为例】
目录 一、全功能AI开发平台介绍二、AI项目落地应用流程(以文本分类为例)2-0、项目开始2-1、项目背景2-2、数据准备介绍2-3、项目数据2-4、建模调参介绍2-5、项目的建模调参2-6、开发部署2-7、项目在公有云的部署 附录:调用api代码总结 一、全…...

源码解析FlinkKafkaConsumer支持punctuated水位线发送
背景 FlinkKafkaConsumer支持当收到某个kafka分区中的某条记录时发送水位线,比如这条特殊的记录代表一个完整记录的结束等,本文就来解析下发送punctuated水位线的源码 punctuated 水位线发送源码解析 1.首先KafkaFetcher中的runFetchLoop方法 public…...
--- 父子组件传值)
vue3学习(五)--- 父子组件传值
文章目录 defineProps普通写法TS写法 defineEmits普通写法TS写法 defineExpose defineProps 和 defineEmits 都是只能在 <script setup> 中使用的编译器宏。他们不需要导入,且会随着 <script setup> 的处理过程一同被编译掉。 defineProps 接收父组件传…...

寻找AI时代的关键拼图,从美国橡树岭国家实验室读懂AI存力信标
超算,是计算产业的明珠,是人类探索未知的航船。超算的发展与变化,不仅代表着各个国家与地区间的科技竞争力,更将作为趋势风向标,影响整个数字化体系的走向。 在目前阶段,超算与AI计算的融合是大势所趋。为了…...

终极指南:如何深度探索Alerter的10个隐藏高级功能
终极指南:如何深度探索Alerter的10个隐藏高级功能 【免费下载链接】Alerter Tapadoo/Alerter: 是一个简单易用的 Android 通知和进度条控件库。适合对 Android 开发、用户界面以及想要在 Android 应用中显示通知和进度条的开发者。 项目地址: https://gitcode.com…...

预制指标、宽表、SQL、本体ABC:真正决定长期成本的,是一次变更会波及多少层
企业做智能问数,最常见的比较题是:预制指标、宽表、人工 SQL、本体ABC,到底哪条路线维护成本更低?如果只给一个笼统答案,往往容易失真。因为真正决定长期成本的,不是“今天开发快不快”,也不是“…...

一站式屏幕神器eSearch:如何5分钟打造你的智能工作流?
一站式屏幕神器eSearch:如何5分钟打造你的智能工作流? 【免费下载链接】eSearch 截屏 离线OCR 搜索翻译 以图搜图 贴图 录屏 万向滚动截屏 屏幕翻译 Screenshot Offline OCR Search Translate Search for picture Paste the picture on the screen Scree…...
)
别再手动点啦!用Android无障碍服务+讯飞语音,5分钟实现App语音操控(保姆级教程)
用Android无障碍服务打造语音操控神器:5分钟实现"可见即可说" 你是否厌倦了在手机上反复点击屏幕的操作?想象一下,只需对着手机说出"打开微信"、"点击朋友圈"、"返回主页",设备就能自动完…...

【AI+实战】零基础部署私人ChatGPT网站:从NextChat到功能定制
1. 为什么你需要一个私人ChatGPT网站? 最近两年AI对话机器人的火爆程度,相信大家都有目共睹。但你是否遇到过这些问题:公共平台经常排队、担心隐私泄露、或者想要定制专属功能?这就是为什么越来越多的个人和小团队开始搭建自己的C…...

博德之门3 Mod管理器:解决Mod加载顺序被重置的终极指南 [特殊字符]
博德之门3 Mod管理器:解决Mod加载顺序被重置的终极指南 🎮 【免费下载链接】BG3ModManager A mod manager for Baldurs Gate 3. 项目地址: https://gitcode.com/gh_mirrors/bg/BG3ModManager 如果你在使用BG3ModManager(博德之门3模组…...

别再踩坑了!KubeKey离线安装K8s v1.26.12时,containerd镜像拉取失败的完整避坑指南
KubeKey离线部署K8s集群:containerd镜像拉取全流程避坑手册 第一次用KubeKey离线部署Kubernetes集群时,containerd镜像拉取失败的问题让我折腾了大半天。看着部署日志里反复出现的证书错误提示,才意识到离线环境下的镜像仓库配置远比想象中复…...

zynq7020 u-boot 外设配置实战指南
1. Zynq7020 U-Boot外设配置概述 在嵌入式系统开发中,U-Boot作为系统启动加载器扮演着关键角色。对于Xilinx Zynq-7020平台来说,正确配置U-Boot外设是确保系统正常启动和运行的基础。本文将重点介绍网口、QSPI Flash和eMMC这三个核心外设的配置方法。 为…...

Ostrakon-VL终端实战:从扫码识别到生成抖音短视频脚本的创意延伸
Ostrakon-VL终端实战:从扫码识别到生成抖音短视频脚本的创意延伸 1. 像素特工终端介绍 想象你是一名零售侦探,手持的不是笨重的扫描枪,而是一个充满复古游戏风格的AI终端。这就是基于Ostrakon-VL-8B模型开发的像素风格交互界面,…...
Translategemma-27b-it与OCR结合:图片翻译完整流程
Translategemma-27b-it与OCR结合:图片翻译完整流程 1. 引言 想象一下这样的场景:你在异国旅行时看到一份精美的菜单,却因为语言障碍而不知道点什么;或者在研究国外产品时,标签上的说明文字完全看不懂。传统的翻译工具…...