【基础篇】四、本地部署Flink
文章目录
- 1、本地独立部署会话模式的Flink
- 2、本地独立部署会话模式的Flink集群
- 3、向Flink集群提交作业
- 4、Standalone方式部署单作业模式
- 5、Standalone方式部署应用模式的Flink
Flink的常见三种部署方式:
- 独立部署(Standalone部署)
- 基于K8S部署
- 基于Yarn部署
1、本地独立部署会话模式的Flink
独立部署就是独立运行,即Flink自己管理Flink资源,不依靠任何外部的资源管理平台,比如K8S或者Hadoop的Yarn,当然,独立部署的代价就是:如果资源不足,或者出现故障,没有自动扩展或重分配资源的保证,必须手动处理,生产环境或者作业量大的场景下不建议采用独立部署。
- 下载安装包
# 下载地址:
https://archive.apache.org/dist/flink/flink-1.17.0/
flink-1.17.0-bin-scala_2.12.tgz
- 上传安装包到Linux节点服务器上的某目录:
/opt/moudle/flink-1.17.0-bin-scala_2.12.tgz
- 解压
tar -zxvf flink-1.17.0-bin-scala_2.12.tgz -C /opt/module/
- 启动,进入安装目录执行start-cluster.sh
[code9527@node01 flink-1.17.0] bin/start-cluster.sh

- 访问WebUI,对Flink集群进行监控管理
http://IP:8081
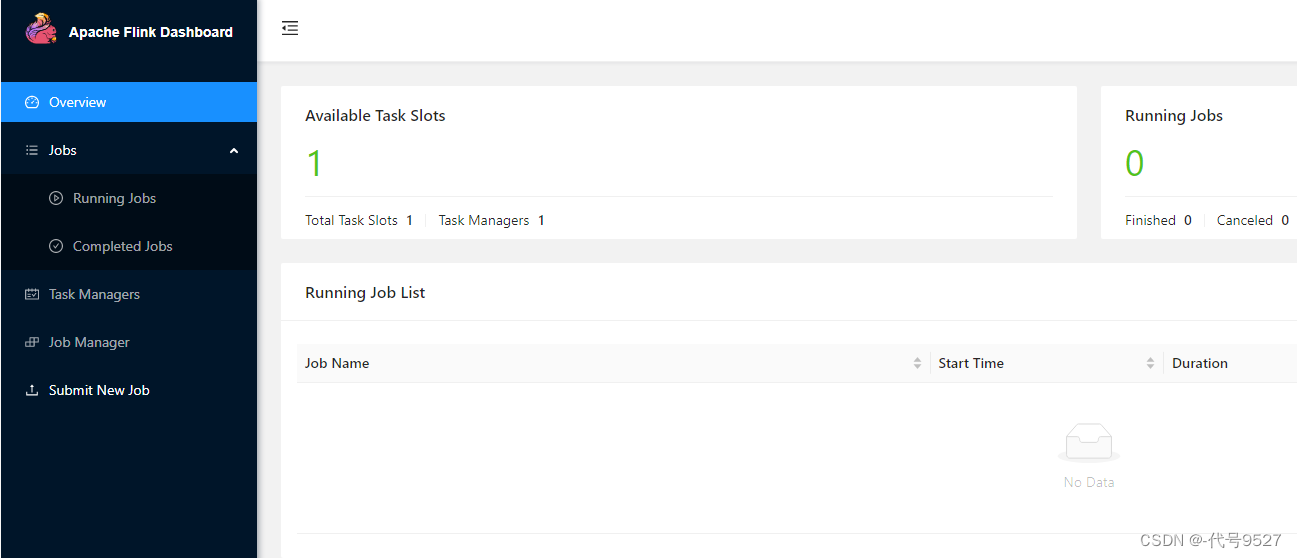
独立安装会话模式的Flink成功,控制台中,可以看到,TaskManager的数量为1(本来就一台机器,一个节点),由于默认每个TaskManager的Slot数量为1,所以总Slot数和可用Slot数都为1。最后,可停止集群:
[code9527@node01 flink-1.17.0] /bin/stop-cluster.sh
可能遇到的坑:
坑1:
start-cluster.sh执行报错:Please specify JAVA_HOME. Either in Flink config ./conf/flink-conf.yaml or as system-wide JAVA_HOME.
原因:未安装Java环境
yum install -y java-1.8.0-openjdk.x86_64
坑2:
http://IP:8081访问不通
处理下防火墙:
firewall-cmd --add-port 8081/tcp --permanentfirewall-cmd --reload
2、本地独立部署会话模式的Flink集群
上面部署的单机Flink,当你有多台服务器,要部署一个集群时,大体流程和上面一样。假设有三台服务器,角色分配规划如下:
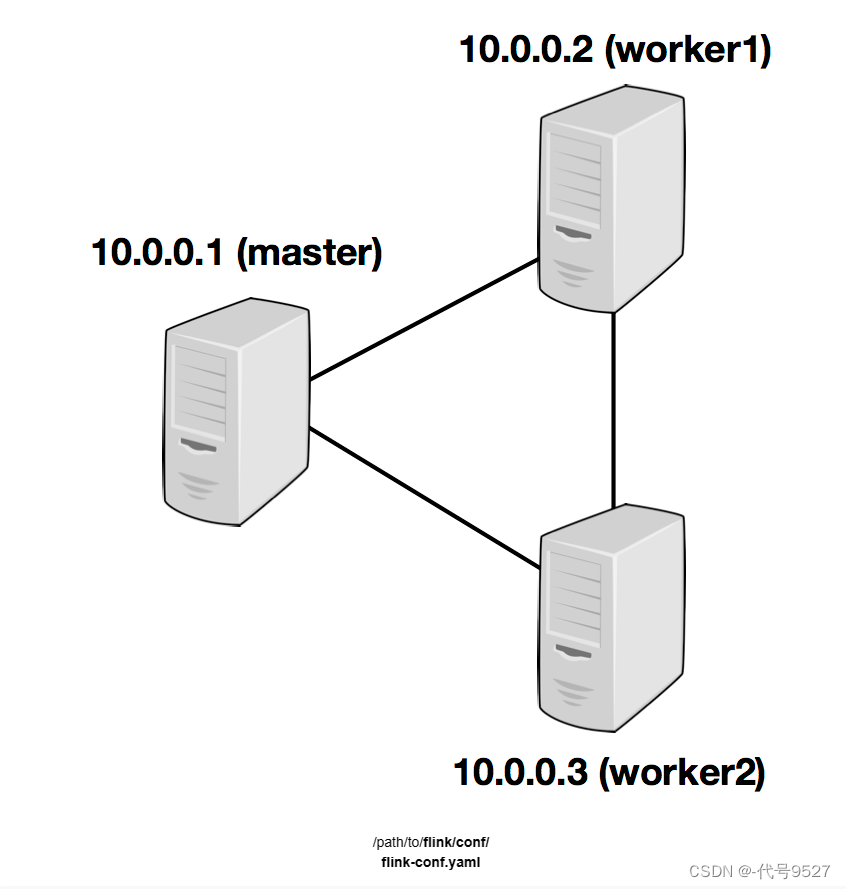
| 节点服务器 | node-01 | node-02 | node-03 |
|---|---|---|---|
| 角色 | JobManager+TaskManager | TaskManager | TaskManager |
主节点上的操作:
- 上传安装包到Linux节点服务器上的某目录:
/opt/moudle/flink-1.17.0-bin-scala_2.12.tgz
- 解压
tar -zxvf flink-1.17.0-bin-scala_2.12.tgz -C /opt/module/
- 进入解压目录/conf目录,修改flink-conf.yaml文件
vi flink-conf.yaml# 修改内容如下:
# JobManager节点地址,我写了IP,这里IP或者hostname都行
jobmanager.rpc.address: node-01
jobmanager.bind-host: 0.0.0.0
rest.address: node-01
rest.bind-address: 0.0.0.0
# TaskManager节点地址.需要配置为当前机器名
taskmanager.bind-host: 0.0.0.0
taskmanager.host: node-01- 其他可选配置:在flink-conf.yaml文件中还可以对集群中的JobManager和TaskManager组件进行优化配置
- jobmanager.memory.process.size:对JobManager进程可使用到的全部内存进行配置,包括JVM元空间和其他开销,默认为1600M,可以根据集群规模进行适当调整。- taskmanager.memory.process.size:对TaskManager进程可使用到的全部内存进行配置,包括JVM元空间和其他开销,默认为1728M,可以根据集群规模进行适当调整。- taskmanager.numberOfTaskSlots:对每个TaskManager能够分配的Slot数量进行配置,默认为1,可根据TaskManager所在的机器能够提供给Flink的CPU数量决定。所谓Slot就是TaskManager中具体运行一个任务所分配的计算资源。- parallelism.default:Flink任务执行的并行度,默认为1。优先级低于代码中进行的并行度配置和任务提交时使用参数指定的并行度数量。
- 修改workers文件,指定干活儿的节点TaskManager的信息,这里是node01和另外两台主机02、03
[code9527@node01 conf] vi workers# 修改如下内容:
node-01
node-02
node-03# 用IP也行,这就是上面单机我也用用IP,而不用默认localhost的原因,多节点下看着乱得很
- 修改masters文件
vi masters# 修改内容,hostname也行
node-01:8081
至于两个Task的从节点,直接把上面改好的Flink安装目录拷贝或分发给另外两个节点服务器:
# node02、node03上建好/opt/moudle/flink-1.17.0/目录后,01节点执行
scp /opt/moudle/flink-1.17.0 root@node02:/opt/moudle/flink-1.17.0/
scp /opt/moudle/flink-1.17.0 root@node03:/opt/moudle/flink-1.17.0/再修改node02的taskmanager.host:
# conf目录下
vim flink-conf.yaml# 改为:
taskmanager.host: node02 # IP或hostname
再修改node03的taskmanager.host:
# conf目录下
vim flink-conf.yaml# 改为:
taskmanager.host: node03 # IP或hostname
回node01启动,执行start-cluster.sh
[code9527@node01 flink-1.17.0] bin/start-cluster.sh
此时,在控制台,应该可以看到当前集群的TaskManager数量为3,总Slot数和可用Slot数都为3
3、向Flink集群提交作业
上一篇,写了读取socket发送的单词并统计单词个数的程序,这里演示将它提交到集群中年去执行,首先将程序打包,在pom.xml中添加打包插件:
<build><plugins><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-shade-plugin</artifactId><version>3.2.4</version><executions><execution><phase>package</phase><goals><goal>shade</goal></goals><configuration><artifactSet><excludes><exclude>com.google.code.findbugs:jsr305</exclude><exclude>org.slf4j:*</exclude><exclude>log4j:*</exclude></excludes></artifactSet><filters><filter><!-- Do not copy the signatures in the META-INF folder.Otherwise, this might cause SecurityExceptions when using the JAR. --><artifact>*:*</artifact><excludes><exclude>META-INF/*.SF</exclude><exclude>META-INF/*.DSA</exclude><exclude>META-INF/*.RSA</exclude></excludes></filter></filters><transformers combine.children="append"><transformerimplementation="org.apache.maven.plugins.shade.resource.ServicesResourceTransformer"></transformer></transformers></configuration></execution></executions></plugin></plugins>
</build>打包,指令或者IDEA页面上操作:
mvn clean
mvn package
打包完成后,在target目录下即可找到所需JAR包,JAR包会有两个,一个原始包,一个带依赖的包(类似SpringBoot打包插件),因为集群中已经具备任务运行所需的所有依赖,所以建议使用原始包original-xxx.jar。下面打开Flink的控制台,在右侧导航栏点击“Submit New Job”,然后点击按钮“+ Add New”,选择要上传运行的JAR包:
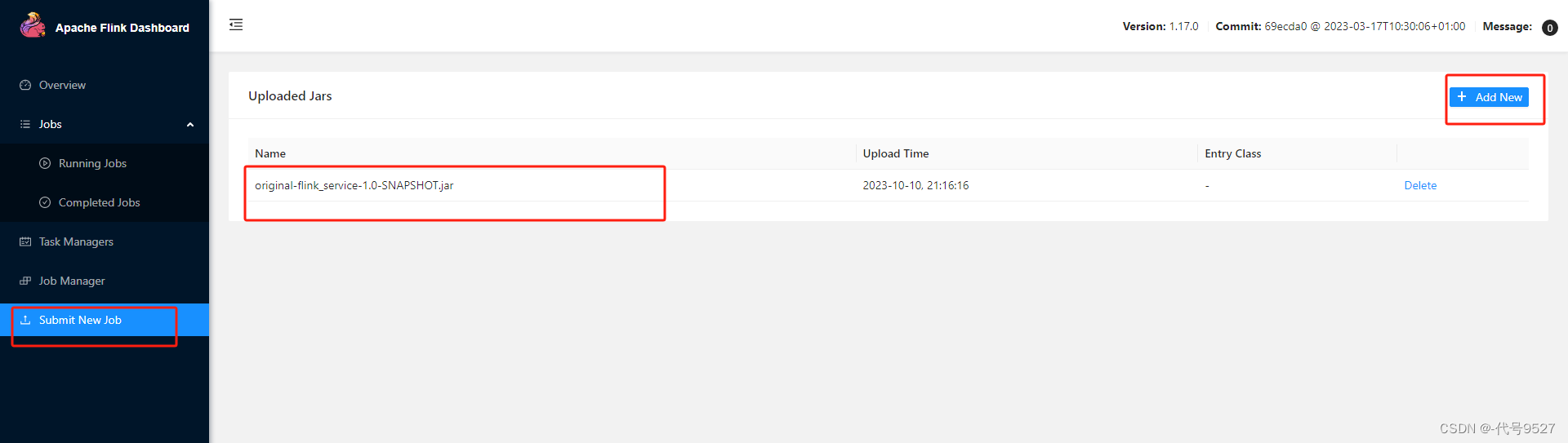
点击该JAR包,出现任务配置页面,进行相应配置:
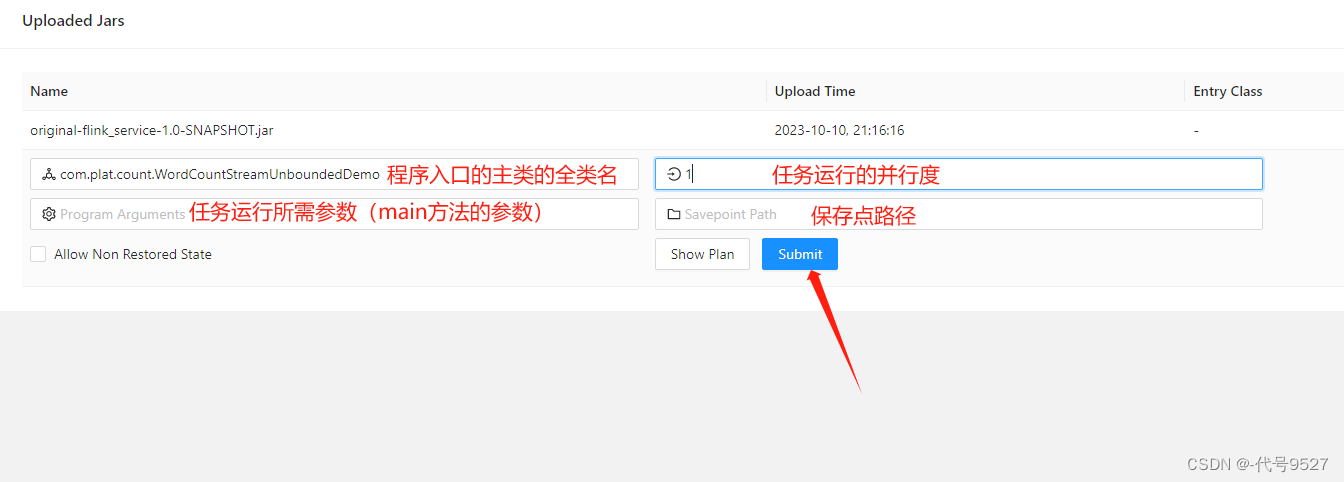
点Submit提交作业(点Submit没反应参考【这篇】),导航栏的Running Jobs可查看程序运行列表情况
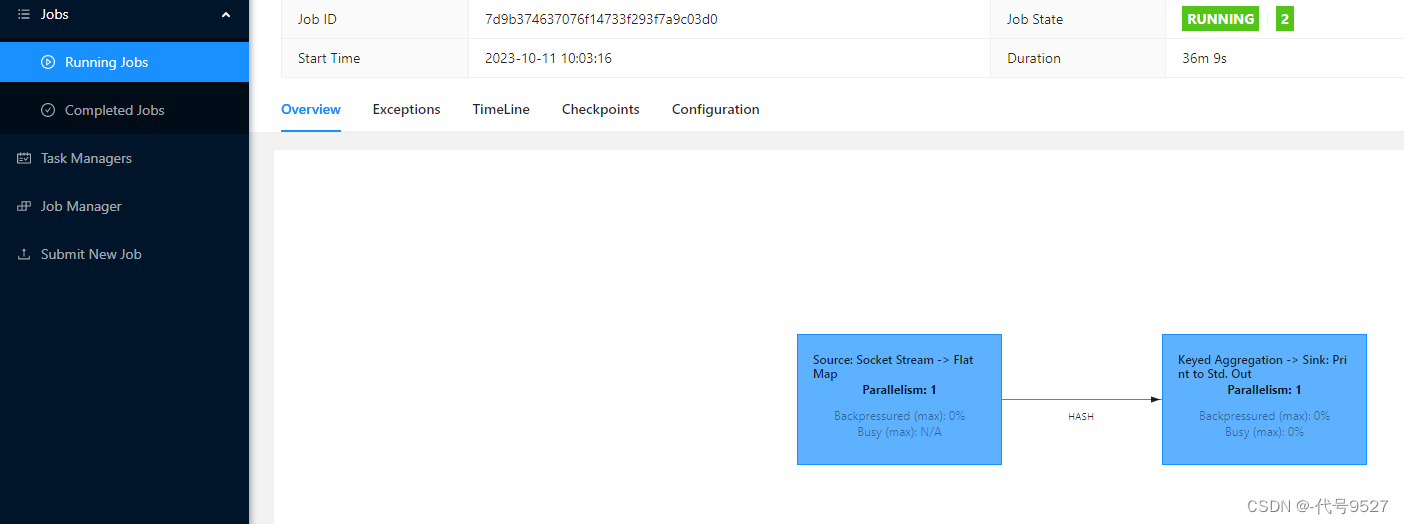
在Flink程序里写的Linux主机里开启端口监听,并在socket端口中输入一些字符串:

先点击Task Manager侧边栏,再切StdOut的tab页,点刷新,可以看到运行成功:
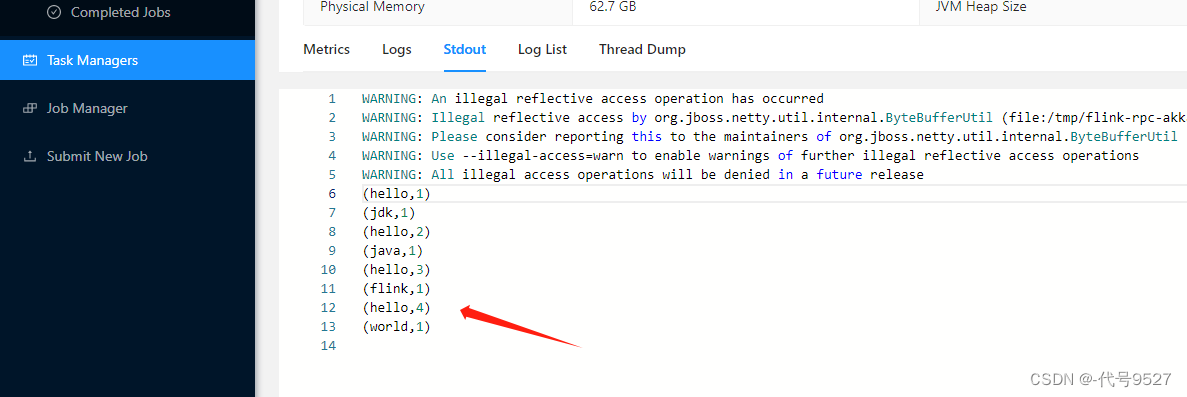
先取消任务,接下来用命令行提交任务:

使用命令行提交,会话模式下还是先启动集群:
bin/start-cluster.sh
进入flink安装目录/opt/module/flink-1.17.0,把前面的jar包上传到该目录下,执行flink run指令提交作业
bin/flink run -m 10.4.95.27:8081 -c com.plat.count.SocketStreamWordCount ./FlinkService-1.0-SNAPSHOT.jar# -m指定了提交到的JobManager
# -c指定了入口类
提交成功:

此时web控制台还是可以看到同样的效果,且/opt/module/flink-1.17.0/log路径中,也可以查看TaskManager的输出:
[root@node-105-69 log] cat flink-atguigu-standalonesession-0-node-105-69.out(hello,1)
(hello,2)
(flink,1)
(hello,3)
(scala,1)4、Standalone方式部署单作业模式
部署不了单作业模式,前面说了,Standalone方式下,Flink并不支持单作业模式部署。因为单作业模式需要借助一些资源管理平台,比如K8S
5、Standalone方式部署应用模式的Flink
应用模式下不会提前创建集群,所以不能调用start-cluster.sh脚本。需要使用同样在bin目录下的standalone-job.sh来创建一个JobManager
# 先停掉会话模式
[root@node-105-69 flink-1.17.0] bin/stop-cluster.sh
# 继续开启对应的Linux主机的netcat
nc -lk 9527
将上面的安装包放到flink的lib目录下
[root@node-105-69 flink-1.17.0] mv FlinkService-1.0-SNAPSHOT.jar lib/
启动JobManager,这里我们直接指定作业入口类,脚本会到lib目录扫描所有的jar包
[root@node-105-69 flink-1.17.0] bin/standalone-job.sh start --job-classname com.plat.count.SocketStreamWordCount
启动TaskManager:(独立部署,这个时候干活的Task是手动起的)
[root@node-105-69 flink-1.17.0] bin/taskmanager.sh start
发送数据到9527端口:
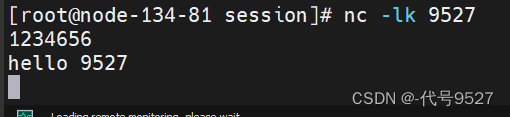
查看控制台:
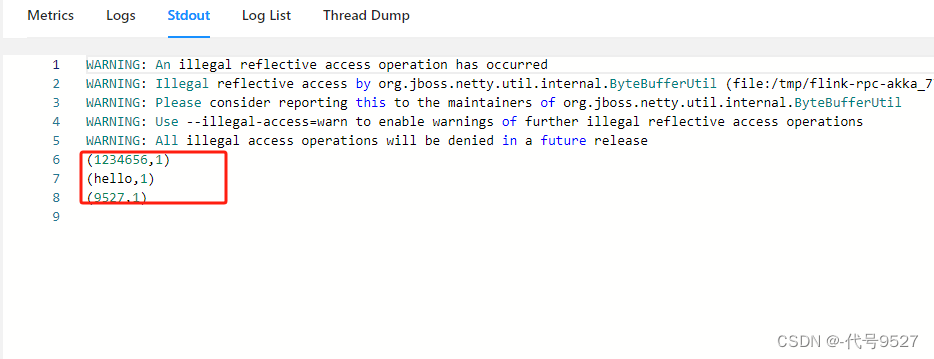
停掉集群:
bin/taskmanager.sh stop
bin/standalone-job.sh stop
相关文章:
【基础篇】四、本地部署Flink
文章目录 1、本地独立部署会话模式的Flink2、本地独立部署会话模式的Flink集群3、向Flink集群提交作业4、Standalone方式部署单作业模式5、Standalone方式部署应用模式的Flink Flink的常见三种部署方式: 独立部署(Standalone部署)基于K8S部署…...
?)
简述什么是迭代器(Iterator)?
迭代器(Iterator)是一种设计模式,Java 中的迭代器是集合框架中的一个接口,它可以让程序员遍历集合中的元素而无需暴露集合的内部结构。使用迭代器可以遍历任何类型的集合,例如 List、Set 和 Map 等。 通过调用集合类的 iterator() 方法可以获取一个迭代器,并使用 hasNext…...

DarkGate恶意软件通过消息服务传播
导语 近日,一种名为DarkGate的恶意软件通过消息服务平台如Skype和Microsoft Teams进行传播。它冒充PDF文件,利用用户的好奇心诱使其打开,进而下载并执行恶意代码。这种攻击手段使用了Visual Basic for Applications(VBA࿰…...
)
LeetCode——动态规划篇(六)
刷题顺序及思路来源于代码随想录,网站地址:https://programmercarl.com 目录 300. 最长递增子序列 - 力扣(LeetCode) 674. 最长连续递增序列 - 力扣(LeetCode) 718. 最长重复子数组 - 力扣(…...
, 文件读写 木马植入 远程控制)
sql 注入(2), 文件读写 木马植入 远程控制
sql 注入 文件读写 木马植入 远程控制 一, 检测读写权限 查看mysql全局变量 SHOW GLOBAL VARIABLES LIKE %secure%secure_file_priv 空, 则任意读写secure_file_priv 路径, 则只能读写该路径下的文件secure_file_priv NULL, 则禁止读写二, 读取文件, 使用 load_file() 函数…...
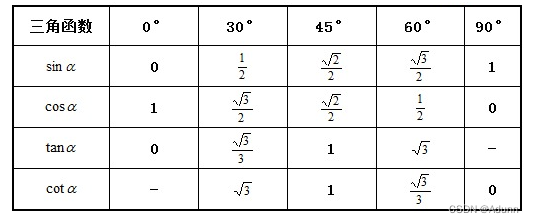
求直角三角形第三点的坐标
文章目录 求直角三角形第三点的坐标1. 原理2. 数学公式3. 推导过程 求直角三角形第三点的坐标 1. 原理 已知内容有: P1、P2 两点的坐标; dis1 为 P1与P2两点之间的距离; dis2 为 P2与P3两点之间的距离; 求解: …...
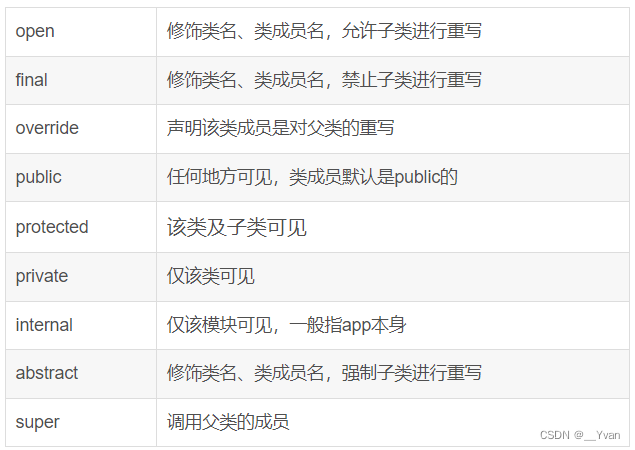
【Kotlin精简】第3章 类与接口
1 简介 Kotlin类的声明和Java没有什么区别,Kotlin中,类的声明也使用class关键字,如果只是声明一个空类,Kotlin和Java没有任何区别,不过定义类的其他成员会有一些区别。实例化类不用写new,类被继承或者重写…...
关于面试以及小白入职后的一些建议
面试的本质 面试的过程是一个互相选择的过程;面试官的诉求是,了解应聘者的个人基本信息、工作态度、专业能力及其他综合能力是否与公司招聘岗位匹配;面试者的诉求是,拿下招聘岗位offer,获得工作报酬; 面试…...
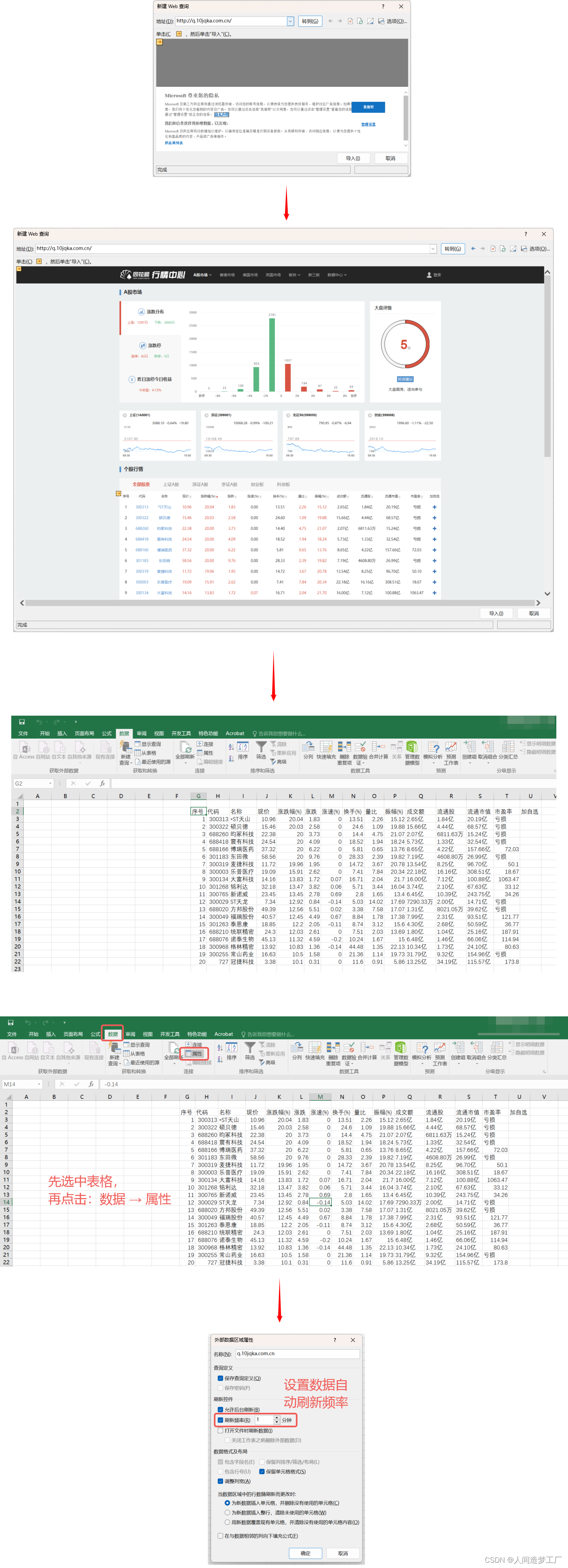
Excel 从网站获取表格
文章目录 导入网站数据导入股票实时行情 用 Excel 获取网站数据的缺点:只能获取表格类的数据,不能获取非结构化的数据。 导入网站数据 转到地址之后: 实测该功能经常导致 Excel 卡死。 导入股票实时行情...

rsync 备份工具(附rsync+inotify 实时同步部署实例)
rsync 备份工具(附rsyncinotify 实时同步部署实例) 1、rsync概述1.1关于rsync1.2rsync 的特点1.3工作原理 2、rsync相关命令2.1基本格式和常用选项2.2启动和关闭rsync服务2.3下行同步基本格式2.4上行同步基本格式2.5免交互2.5.1指定密码文件2.5.2rsync-daemon方式2.…...

Java架构师缓存性能优化
目录 1 缓存的负载策略2 缓存的序列化问题3 缓存命中率低4 缓存对数据库高并发访问5 缓存数据刷新的策略5.1. 实时策略5.2. 异步策略5.3. 定时策略6 何时写缓存7 批量数据来更新缓存8 缓存数据过期的策略9 缓存数据如何恢复10 缓存数据如何迁移11 缓存冷启动和缓存预热想学习架…...

探索服务器潜能:创意项目、在线社区与其他应用
目录 一、部署自己的创意项目 优势: 劣势: 结论: 二、打造一款全新的在线社区 优势: 劣势: 结论: 三、其他用途 总结: 随着互联网的发展,越来越多的人开始拥有自己的服务器…...
「网络编程」网络层协议_ IP协议学习_及深入理解
「前言」文章内容是网络层的IP协议讲解。 「归属专栏」网络编程 「主页链接」个人主页 「笔者」枫叶先生(fy) 目录 一、IP协议简介二、IP协议报头三、IP网段划分(子网划分)四、特殊的IP地址五、IP地址的数量限制六、私有IP地址和公网IP地址七、路由八、分…...

Go 1.21 新内置函数:min、max 和 clear
max 函数 func max[T cmp.Ordered](x T, y …T) T 这是一个泛型函数,用于从一组值中寻找并返回 最大值,该函数至少要传递一个参数。在上述函数签名中,T 表示类型参数,它必须满足 cmp.Ordered 接口中定义的数据类型要求࿰…...

家居行业如何打破获客困局?2023重庆建博会现场,智哪儿AI营销第一课给出了答案
10月12日-14日,2023中国(重庆)建筑及装饰材料博览会(简称:2023中国重庆建博会)正在重庆国际博览中心如火如荼地进行。「智哪儿」携手2023中国重庆建博会主办方共同主办的《2023家居行业AI营销第一课&#x…...
Spring framework Day11:策略模式中注入所有实现类
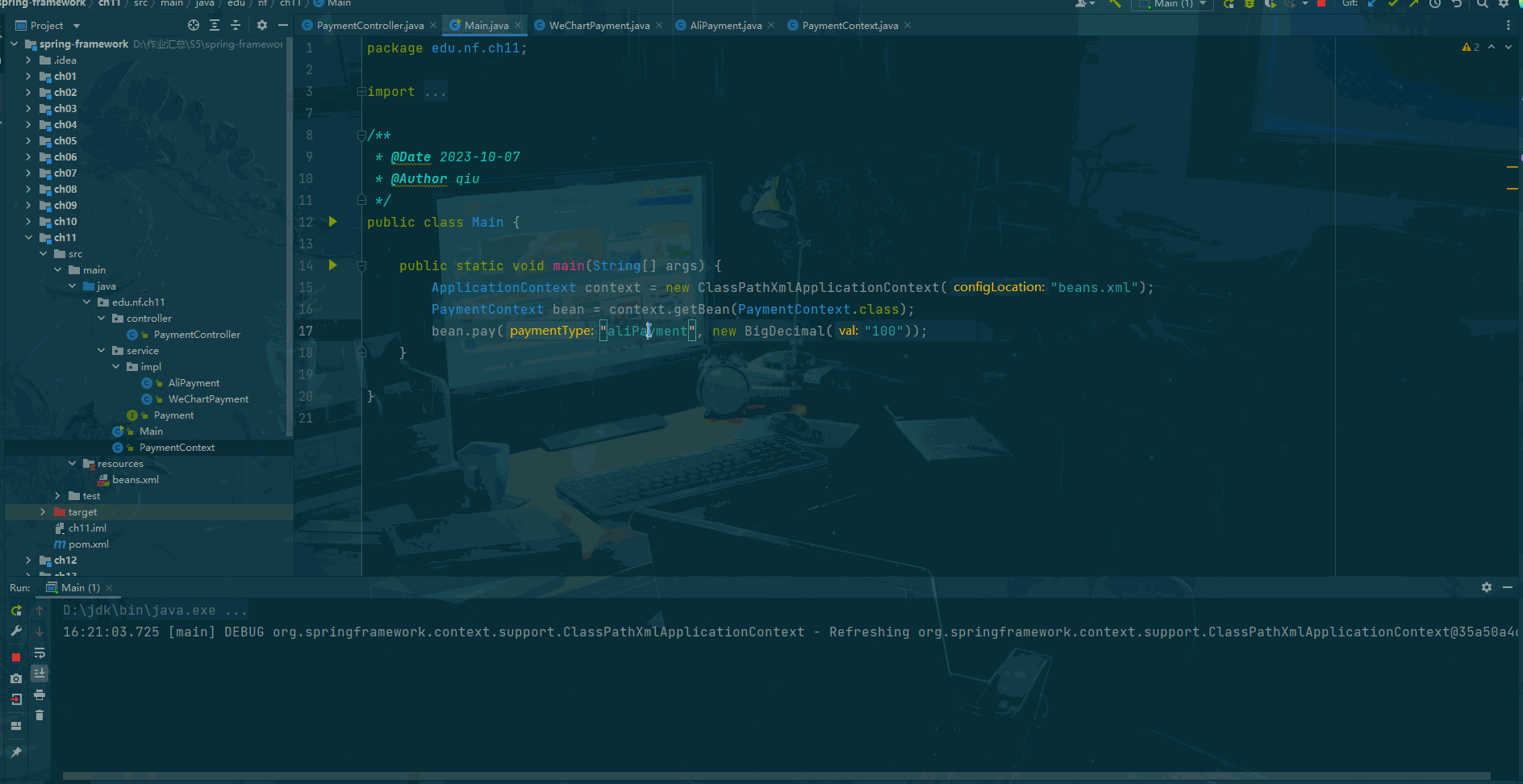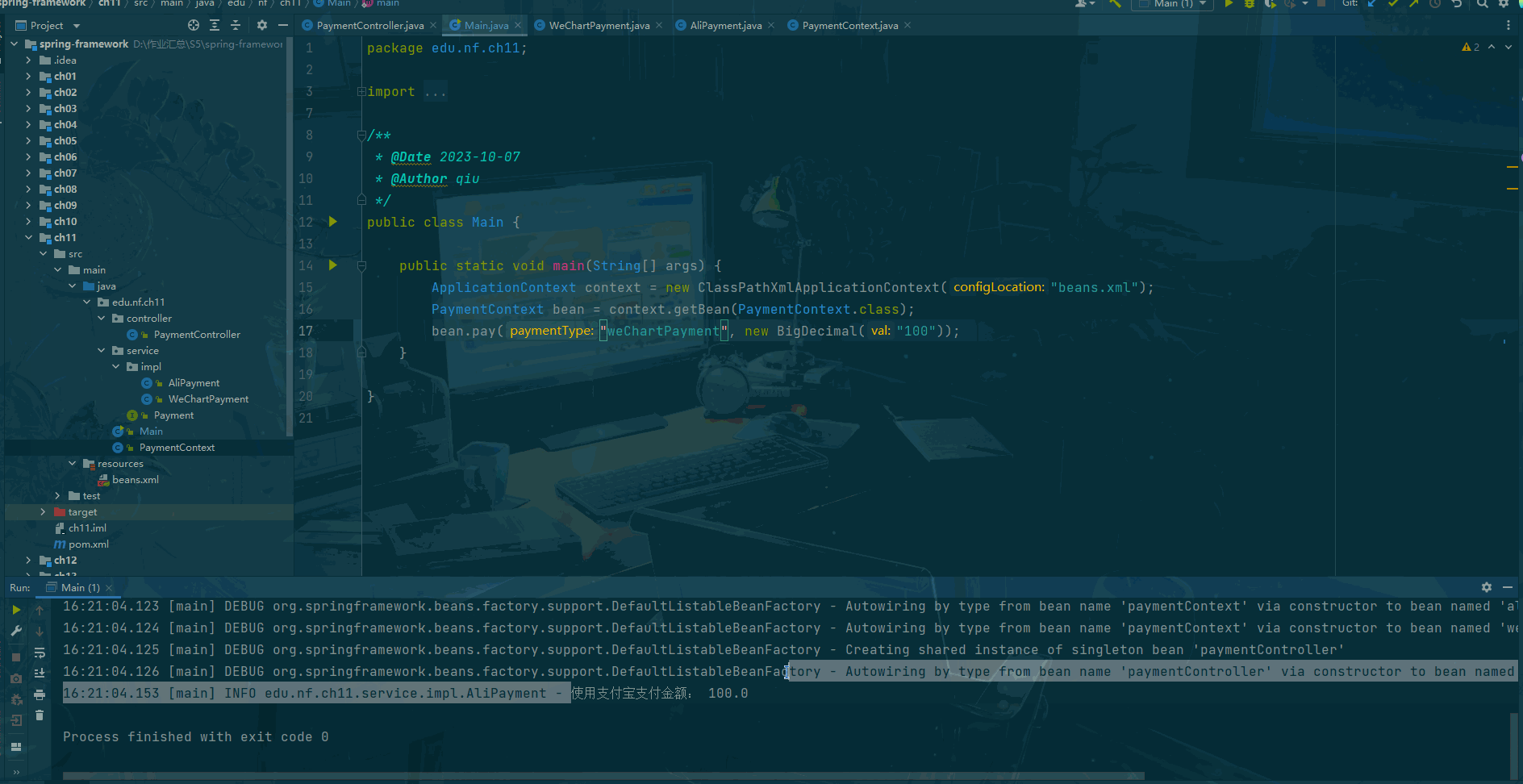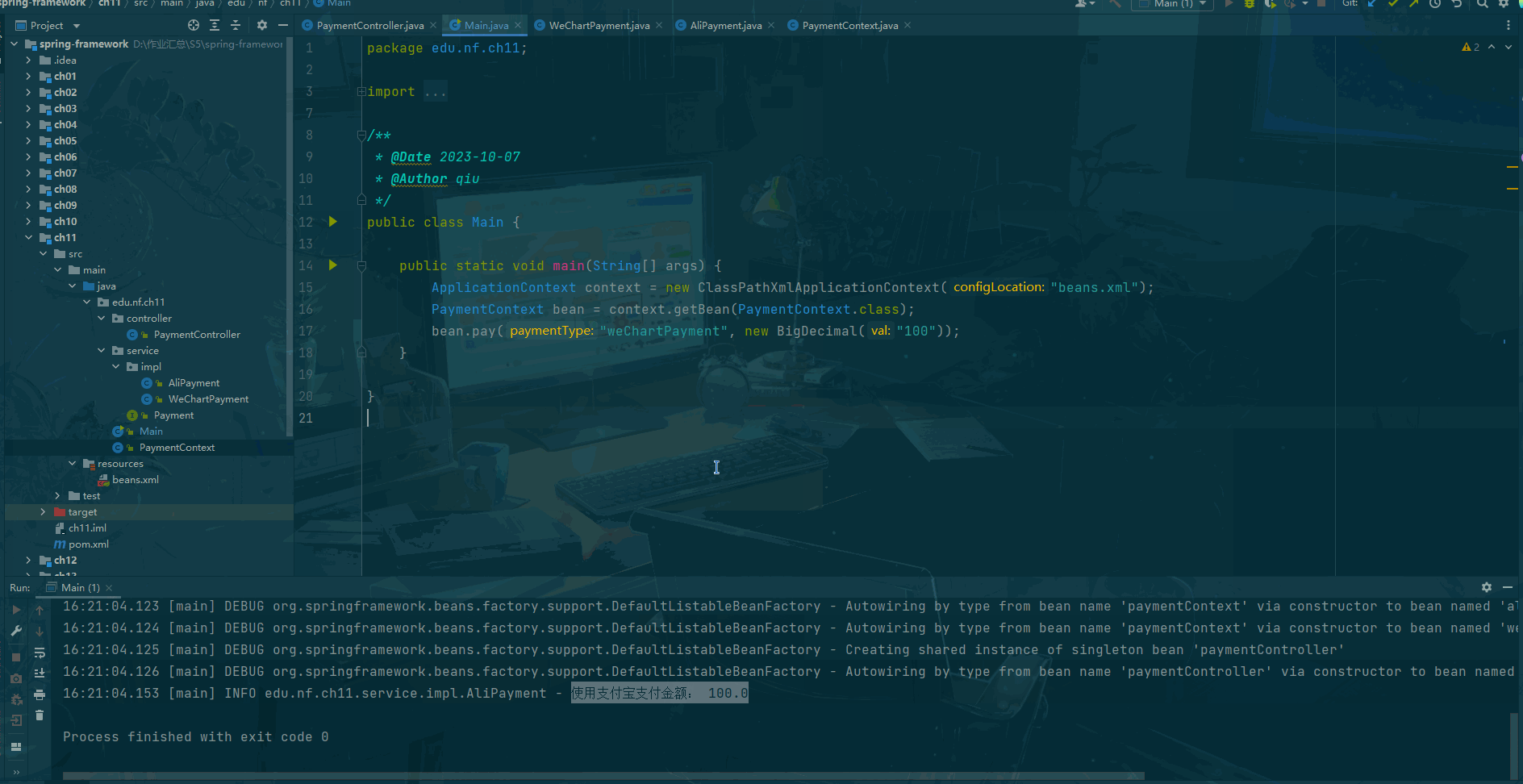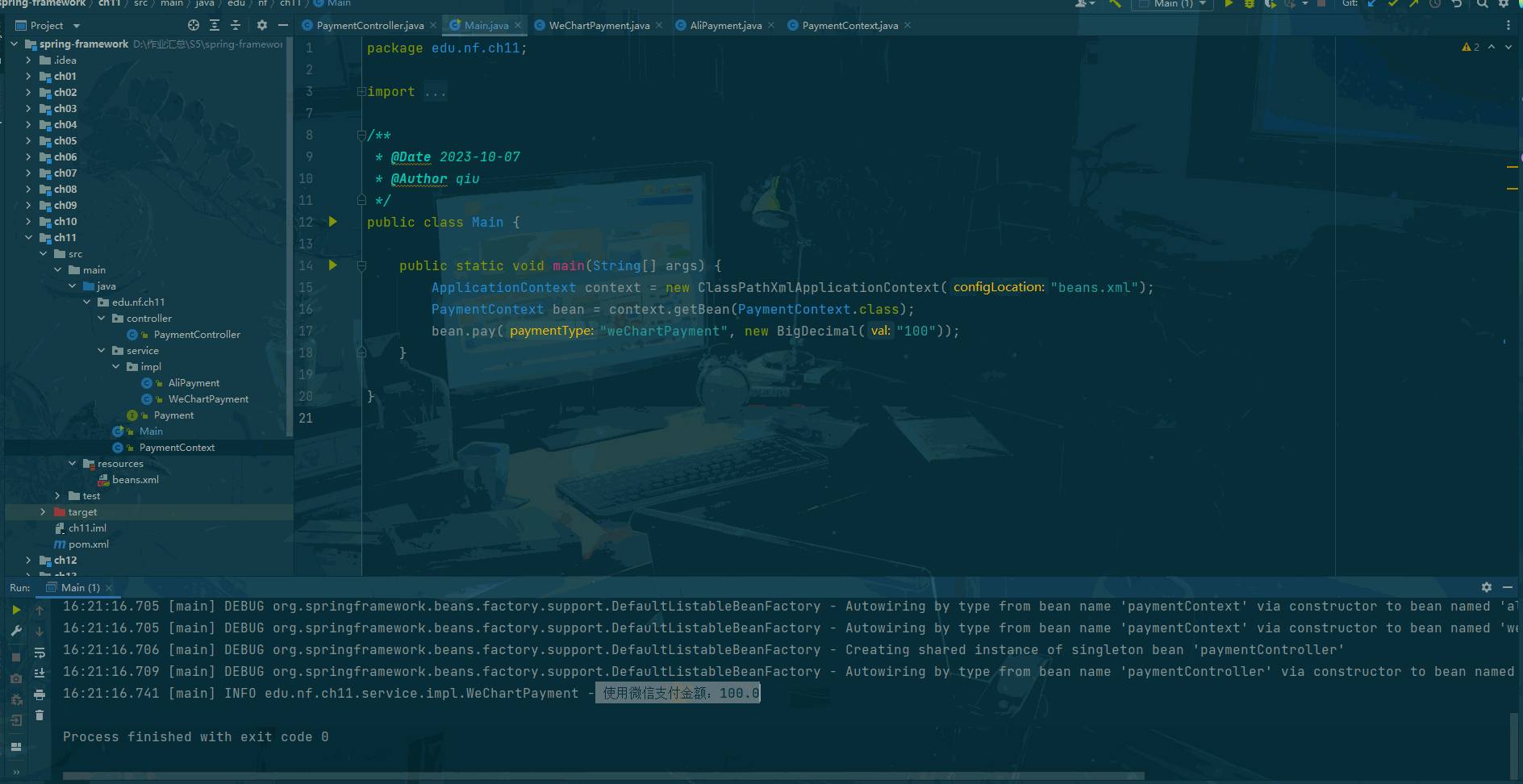
前言 什么是策略模式? 策略模式(Strategy Pattern)是一种面向对象设计模式,它定义了算法族(一组相似的算法),并且将每个算法都封装起来,使得它们可以互相替换。策略模式让算法的变…...

MBBF展示的奇迹绿洲:5G的过去、此刻与未来
如果你来迪拜,一定不会错过全世界面积最大的人工岛项目,这是被称为世界第八大奇迹的棕榈岛。多年以来,这座岛从一片砂石、一棵棕榈树开始,逐步建成了整个波斯湾地区的地标,吸引着全世界游人的脚步。 纵观整个移动通信发…...

加持智慧医疗,美格智能5G数传+智能模组让就医触手可及
智慧医疗将云计算、物联网、大数据、AI等新兴技术融合赋能医疗健康领域,是提高医疗健康服务的资源利用效率,创造高质量健康医疗的新途径。《健康中国2030规划纲要》把医疗健康提升到了国家战略层面,之后《“十四五”全面医疗保障规划》等一系…...

Stm32_标准库_14_串口蓝牙模块_手机与蓝牙模块通信_实现模块读取并修改信息
由手机向蓝牙模块传输时间信息,Stm32获取信息并将已存在信息修改为传入信息 测试代码: #include "stm32f10x.h" // Device header #include "Delay.h" #include "OLED.h" #include "Serial.h"uint16_t num…...

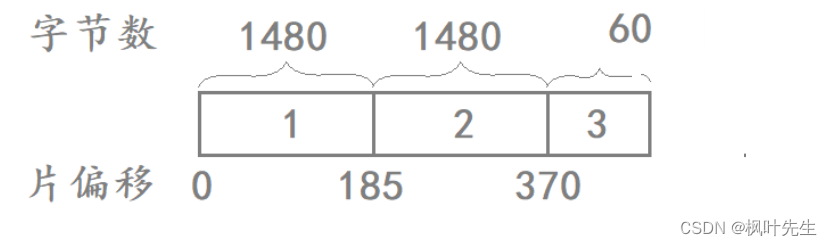
UDP 的报文结构
UDP的报文结构: 其中前面的源端口号和目的端口号,UDP长度和UDP检验和,它们都是2个字节。 那么什么是UDP长度呢,它指的是后面的数据的长度,换算单位也就是64kb,因此一个数据报(数据)最…...

如何用 writable 属性描述符限制 JavaScript 对象属性修改.txt
Lock wait timeout exceeded 表示事务等待行锁超时(默认50秒),本质是被其他长事务或未提交操作阻塞,并非数据库性能问题;需通过INNODB_TRX和performance_schema定位锁源,排查索引缺失、MDL锁及锁链式等待。…...

阿里从蚂蚁收到股息33亿:AI投入加大致后者年利润153亿 同比降60%
雷递网 乐天 5月13日阿里今日发布财报。财报披露,蚂蚁在2026年第一季度给阿里带来的投资收益为3.75亿(约5500万美元),较上年同期的17.63亿元下降78.7%。截至2026年3月31日,阿里对蚂蚁集团在全面摊薄基础上的股权为33%。…...

通用型数据采集系统选型指南:从原理到实战的七维评估
1. 数据采集系统:从物理世界到数字世界的桥梁在航空航天、汽车、工业自动化乃至国防军工这些领域里,我们工程师每天打交道最多的,可能就是那些看不见摸不着的物理量:发动机涡轮叶片的温度、飞机机翼的应变、汽车悬架的动态压力、或…...

C++多线程编程:深入剖析std::thread的使用方法
一、线程std::thread简介std::thread 是 C11 中引入的一个库,用于实现多线程编程。它允许程序创建和管理线程,从而实现并发执行。std::thread 在 #include<thread>头文件中声明,因此使用 std::thread 时需要包含 #include<thread>…...

基于React与Docker构建可定制个人仪表盘:homepage项目实战指南
1. 项目概述:一个现代、轻量的个人仪表盘如果你和我一样,每天上班第一件事就是打开十几个浏览器标签页,在邮箱、项目管理工具、服务器监控、待办清单、常用文档之间来回切换,那么你一定能理解那种“数字工作台”杂乱无章带来的烦躁…...

BaiduNetdiskPlugin-macOS:三步破解百度网盘限速,实现SVIP级别下载体验
BaiduNetdiskPlugin-macOS:三步破解百度网盘限速,实现SVIP级别下载体验 【免费下载链接】BaiduNetdiskPlugin-macOS For macOS.百度网盘 破解SVIP、下载速度限制~ 项目地址: https://gitcode.com/gh_mirrors/ba/BaiduNetdiskPlugin-macOS 还在为百…...

在Android 9上用vsomeip 3.3.8实现跨进程通信:一份保姆级编译与配置指南
在Android 9上实现跨进程通信:vsomeip 3.3.8编译与配置实战 在车载以太网和智能座舱系统开发中,跨进程通信(IPC)是基础且关键的技术环节。对于Android平台开发者而言,如何在NDK环境下高效实现Linux进程间通信ÿ…...
【玩转PB级数仓GaussDB(DWS)】)
windows系统下操作GaussDB(DWS)【玩转PB级数仓GaussDB(DWS)】
数据仓库服务GaussDB(DWS) 是一种基于华为云基础架构和平台的在线数据处理数据库,提供即开即用、可扩展且完全托管的分析型数据库服务。GaussDB(DWS)是基于华为融合数据仓库GaussDB产品的云原生服务 ,兼容标准ANSI SQL 99和SQL 2003,同时兼容…...

C# 结合 llama.cpp 实现 PaddleOCR-VL-1.5:本地 OCR 客户端开发全攻略
一、前言在日常工作中,我们经常需要从图片中提取文字信息。虽然市面上有不少 OCR 服务,但它们往往需要联网、存在隐私风险,或者需要付费。2026 年百度发布了开源文档解析模型 PaddleOCR-VL-1.5,该模型不仅支持常规文字识别&#x…...

从RRM到RIC:手把手拆解5G O-RAN智能控制器如何“接管”你的基站
从RRM到RIC:5G O-RAN智能控制器的技术演进与实战解析 在5G网络架构的演进浪潮中,O-RAN联盟提出的开放无线接入网理念正在重塑传统基站的控制方式。本文将带您深入探索无线资源管理(RRM)如何进化为近实时智能控制器(Nea…...