python之Scrapy爬虫案例:豆瓣
- 运行命令创建项目:scrapy startproject scrapySpider
- 进入项目目录:cd .\scrapySpider\
- 运行命令创建爬虫:scrapy genspider douban movie.douban.com
- 目录结构说明
|-- scrapySpider 项目目录 | |-- scrapySpider 项目目录 | | |-- spiders 爬虫文件目录 | | | |-- douban.py 爬虫文件 | | |-- items.py 定义数据模型文件,类似于数据库表的模式或数据结构的定义 | | |-- middlewares.py 定义中间件文件,用于对请求和响应进行处理和修改 | | |-- pipelines.py 定义数据处理管道(Pipeline)文件,用于处理爬取到的数据的组件 | | |-- settings.py 定义配置文件,用于配置 Scrapy 项目的各种设置选项和参数 | |-- scrapy.cfg 框架中的配置文件,用于指定项目的结构和元数据信息 - 创建快代理文件scrapySpider>kuaidaili.py:https://www.kuaidaili.com/
import requestsclass Kuaidaili():request_url = {# 获取代理ip前面'getIpSignature': 'https://auth.kdlapi.com/api/get_secret_token',# 获取代理ip'getIp': 'https://dps.kdlapi.com/api/getdps?secret_id=oy2q5xu76k4s8olx59et&num=1&signature={}'}headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/116.0.0.0 Safari/537.36'}ip_use = '购买代理用户名'ip_password = '购买代理密码'def __init__(self):'''创建request会话对象'''self.request_session = requests.Session()self.request_session.headers.update(self.headers)# 获取代理ip签名@classmethoddef get_ip_url(cls):par = {'secret_id': 'oy2q5xu76k4s8olx59et','secret_key': '5xg6gvouc0vszfw0kxs1a8vrw1r6ity7'}response = requests.post(cls.request_url['getIpSignature'],data=par)response_data = response.json()return cls.request_url['getIp'].format(response_data['data']['secret_token'])@classmethoddef get_ip(cls):url = cls.get_ip_url()response = requests.get(url)return f'http://{cls.ip_use}:{cls.ip_password}@{response.text}/'if __name__ == '__main__':kuaidaili = Kuaidaili()print(kuaidaili.get_ip()) - 爬取豆瓣案例
- douban.py
import scrapy from scrapy import cmdline from scrapy.http import HtmlResponse,Request from scrapySpider.items import DoubanItemclass DoubanSpider(scrapy.Spider):name = 'douban'allowed_domains = ['movie.douban.com']start_urls = ['https://movie.douban.com/top250']def parse(self, response: HtmlResponse,**kwargs):video_list = response.xpath('//ol[@class="grid_view"]/li')for li in video_list:item = DoubanItem()item['title'] = li.xpath('.//div[@class="hd"]/a/span[1]/text()').extract_first()item['rating'] = li.xpath('.//div[@class="bd"]//span[@class="rating_num"]/text()').extract_first()item['quote'] = li.xpath('.//div[@class="bd"]//p[@class="quote"]/span/text()').extract_first()detail_url = li.xpath('.//div[@class="hd"]/a/@href').extract_first()yield Request(url=detail_url,callback=self.get_detail_info,meta={'item':item})#获取下一页数据next_page_url = response.xpath('//div[@class="paginator"]//link[@rel="next"]/@href').extract_first()if next_page_url:yield Request(url=response.urljoin(next_page_url),callback=self.parse)#重写start_requests获取多页数据# def start_requests(self):# for i in range(0,2):# yield Request(url=f'{self.start_urls[0]}?start={i*25}&filter=',dont_filter=True,callback=self.parse)def get_detail_info(self,response:HtmlResponse):item = response.meta['item']detail = response.xpath('//span[@class="all hidden"]/text()').extract_first()if not detail:detail = response.xpath('//div[@id="link-report-intra"]/span[1]/text()').extract_first()item['intro'] = detail.strip()request itemif __name__ == '__main__':cmdline.execute('scrapy crawl douban'.split()) - settings.py
# Scrapy settings for scrapySpider project # # For simplicity, this file contains only settings considered important or # commonly used. You can find more settings consulting the documentation: # # https://docs.scrapy.org/en/latest/topics/settings.html # https://docs.scrapy.org/en/latest/topics/downloader-middleware.html # https://docs.scrapy.org/en/latest/topics/spider-middleware.htmlBOT_NAME = "scrapySpider"SPIDER_MODULES = ["scrapySpider.spiders"] NEWSPIDER_MODULE = "scrapySpider.spiders"# Crawl responsibly by identifying yourself (and your website) on the user-agent # USER_AGENT = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/116.0.0.0 Safari/537.36"# Obey robots.txt rules ROBOTSTXT_OBEY = False# Configure maximum concurrent requests performed by Scrapy (default: 16) #CONCURRENT_REQUESTS = 32# Configure a delay for requests for the same website (default: 0) # See https://docs.scrapy.org/en/latest/topics/settings.html#download-delay # See also autothrottle settings and docs #DOWNLOAD_DELAY = 3 # The download delay setting will honor only one of: #CONCURRENT_REQUESTS_PER_DOMAIN = 16 #CONCURRENT_REQUESTS_PER_IP = 16# Disable cookies (enabled by default) #COOKIES_ENABLED = False# Disable Telnet Console (enabled by default) #TELNETCONSOLE_ENABLED = False# Override the default request headers: DEFAULT_REQUEST_HEADERS = {"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8","Accept-Language": "en", }# Enable or disable spider middlewares # See https://docs.scrapy.org/en/latest/topics/spider-middleware.html #SPIDER_MIDDLEWARES = { # "scrapySpider.middlewares.ScrapyspiderSpiderMiddleware": 543, #}# Enable or disable downloader middlewares # See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html DOWNLOADER_MIDDLEWARES = {"scrapySpider.middlewares.DoubanDownloaderMiddleware": 543, }# Enable or disable extensions # See https://docs.scrapy.org/en/latest/topics/extensions.html # EXTENSIONS = { # 'scrapeops_scrapy.extension.ScrapeOpsMonitor': 500, # }# Configure item pipelines # See https://docs.scrapy.org/en/latest/topics/item-pipeline.html ITEM_PIPELINES = {"scrapySpider.pipelines.MysqlPipeLine": 300,"scrapySpider.pipelines.MongoPipeLine": 301, }# Enable and configure the AutoThrottle extension (disabled by default) # See https://docs.scrapy.org/en/latest/topics/autothrottle.html #AUTOTHROTTLE_ENABLED = True # The initial download delay #AUTOTHROTTLE_START_DELAY = 5 # The maximum download delay to be set in case of high latencies #AUTOTHROTTLE_MAX_DELAY = 60 # The average number of requests Scrapy should be sending in parallel to # each remote server #AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0 # Enable showing throttling stats for every response received: #AUTOTHROTTLE_DEBUG = False# Enable and configure HTTP caching (disabled by default) # See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings #HTTPCACHE_ENABLED = True #HTTPCACHE_EXPIRATION_SECS = 0 #HTTPCACHE_DIR = "httpcache" #HTTPCACHE_IGNORE_HTTP_CODES = [] #HTTPCACHE_STORAGE = "scrapy.extensions.httpcache.FilesystemCacheStorage"# Set settings whose default value is deprecated to a future-proof value REQUEST_FINGERPRINTER_IMPLEMENTATION = "2.7" TWISTED_REACTOR = "twisted.internet.asyncioreactor.AsyncioSelectorReactor" FEED_EXPORT_ENCODING = "utf-8"#日志配置 # LOG_FILE = 'log.log' # LOG_FILE_APPEND = False # LOG_LEVEL = 'INFO' - items.py
# Define here the models for your scraped items # # See documentation in: # https://docs.scrapy.org/en/latest/topics/items.htmlimport scrapyclass DoubanItem(scrapy.Item):# define the fields for your item here like:# name = scrapy.Field()title = scrapy.Field()rating = scrapy.Field()quote = scrapy.Field()intro = scrapy.Field() - pipelines.py
# Define your item pipelines here # # Don't forget to add your pipeline to the ITEM_PIPELINES setting # See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html# useful for handling different item types with a single interface from itemadapter import ItemAdapter import pymysql import pymongovideo_spider = ['douban']class DoubanPipeline:def process_item(self, item, spider):print(item)return itemclass MysqlPipeLine:def open_spider(self, spider):self.spider = spiderself.mysql = pymysql.connect(host='localhost',port=3306,user='root',password='root')self.cursor = self.mysql.cursor()# 创建video数据库和相关爬虫表if self.spider.name in video_spider:self.create_db('video')'''创建数据库'''def create_db(self,db_name):sql = f'''CREATE DATABASE IF NOT EXISTS {db_name}'''try:self.cursor.execute(sql)self.mysql.select_db(db_name)if self.spider.name == 'douban':self.create_douban_table()except Exception as e:print(f'创建{db_name}数据库失败:{e}')'''创建表douban'''def create_douban_table(self):sql = f'''CREATE TABLE IF NOT EXISTS {self.spider.name}(id INT AUTO_INCREMENT,title VARCHAR(255),rating FLOAT,quote VARCHAR(255),intro TEXT,PRIMARY KEY(id))'''try:self.cursor.execute(sql)except Exception as e:print(f'创建douban表失败:{e}')def process_item(self, item, spider):if spider.name == 'douban':sql = f'''INSERT INTO {spider.name}(title,rating,quote,intro) VALUES(%(title)s,%(rating)s,%(quote)s,%(intro)s)'''try:item['rating'] = float(item['rating'])self.cursor.execute(sql,dict(item))self.mysql.commit()except Exception as e:print(f'”{item["title"]}”插入失败:{e}')self.mysql.rollback()return itemdef close_spider(self,spider):self.mysql.close()class MongoPipeLine:def open_spider(self, spider):self.spider = spiderself.mongo = pymongo.MongoClient(host='localhost',port=27017)# 创建video数据库和相关爬虫表if self.spider.name in video_spider:self.cursor = self.mongo['video'][self.spider.name]def process_item(self, item, spider):try:self.cursor.insert_one(dict(item))except Exception as e:print(f'”{item["title"]}”插入失败:{e}')return itemdef close_spider(self, spider):self.mongo.close() - middlewares.py
# Define here the models for your spider middleware # # See documentation in: # https://docs.scrapy.org/en/latest/topics/spider-middleware.htmlfrom scrapy import signals from fake_useragent import UserAgent from scrapy.http import Request,HtmlResponse from scrapySpider.kuaidaili import Kuaidaili# useful for handling different item types with a single interface from itemadapter import is_item, ItemAdapterclass DoubanDownloaderMiddleware:def __init__(self):self.ua = UserAgent()self.kuaidaili = Kuaidaili()#初始化一个代理ipself.first_ip = self.kuaidaili.get_ip()@classmethoddef from_crawler(cls, crawler):s = cls()crawler.signals.connect(s.spider_opened, signal=signals.spider_opened)return sdef process_request(self, request:Request, spider):#设置UArequest.headers['User-Agent'] = self.ua.random#设置代理request.meta['proxy'] = self.first_iprequest.meta['download_timeout'] = 5spider.logger.info(f'ip:{request.meta["proxy"]}')return Nonedef process_response(self, request, response:HtmlResponse, spider):spider.logger.info(f'ip:{request.meta["proxy"]}')if response.status == 200:return response#代理失效小重新设置代理,并返回request重新请求request.meta['proxy'] = self.kuaidaili.get_ip()request.meta['download_timeout'] = 2return requestdef spider_opened(self, spider):spider.logger.info(f'"{spider.name}"Spide')
相关文章:

python之Scrapy爬虫案例:豆瓣
运行命令创建项目:scrapy startproject scrapySpider进入项目目录:cd .\scrapySpider\运行命令创建爬虫:scrapy genspider douban movie.douban.com目录结构说明|-- scrapySpider 项目目录 | |-- scrapySpider 项目目录 | | |-- spider…...
2023最新UI酒桌喝酒游戏小程序源码 娱乐小程序源码 带流量主
2023最新UI酒桌喝酒游戏小程序源码 娱乐小程序源码 带流量主 修改增加了广告位,根据文档直接替换,原版本没有广告位 直接上传源码到开发者端即可 通过后改广告代码,然后关闭广告展示提交,通过后打开即可 无广告引流 流量主版…...
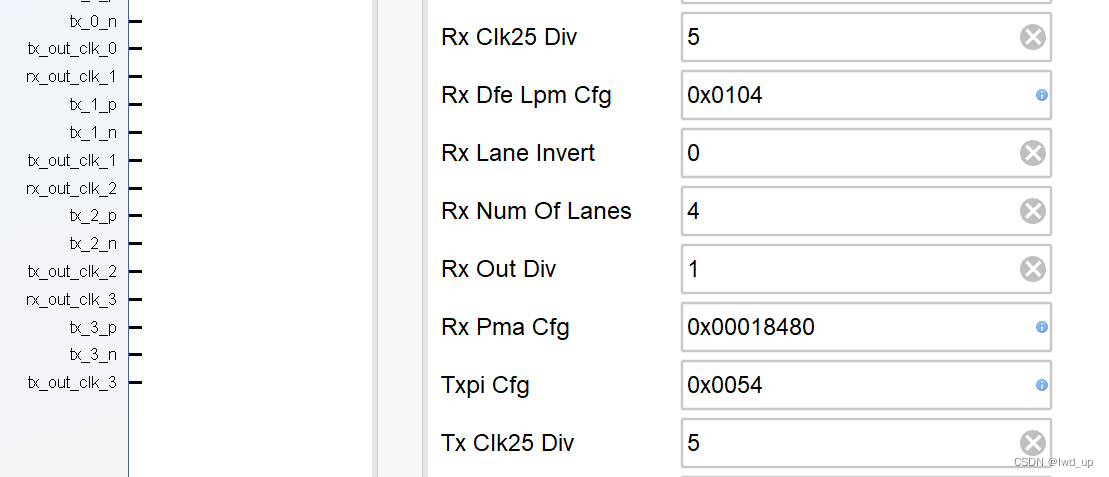
AD9371 官方例程HDL详解之JESD204B TX_CLK生成 (二)
AD9371 系列快速入口 AD9371ZCU102 移植到 ZCU106 : AD9371 官方例程构建及单音信号收发 ad9371_tx_jesd -->util_ad9371_xcvr接口映射: AD9371 官方例程之 tx_jesd 与 xcvr接口映射 AD9371 官方例程 时钟间的关系与生成 : AD9371 官方…...

Qt扫盲-Qt Concurrent概述
Qt Concurrent概述 一、概述二、Concurrent Map 和 Map- reduce1. 并发 Map2. 并发 Map-Reduce3. 其他API特性1. 使用迭代器而不是Sequence3. 阻塞变量4. 使用成员函数5. 使用函数对象6. 包装接受多个参数的函数 三、Concurrent Filter and Filter-Reduce1. 并发过滤器2. 并发F…...
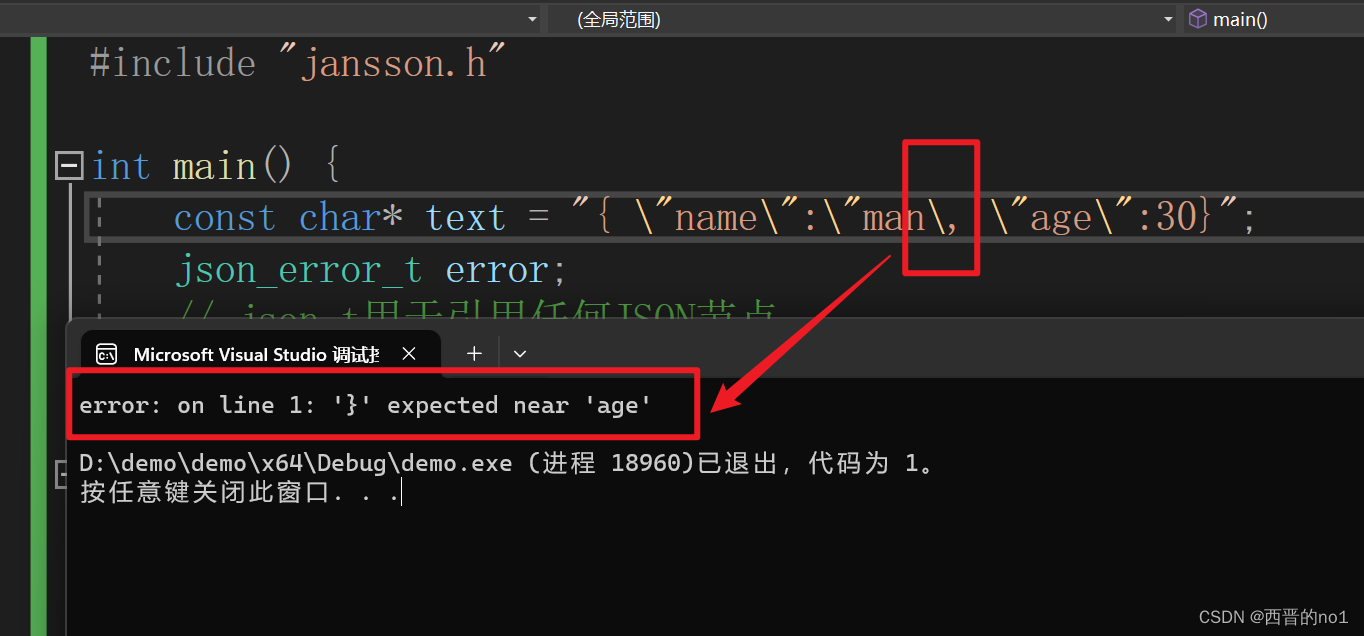
c语言用json解析库(jansson)检测字符串是否是json格式的数据
C语言检测字符串是否是json格式的数据,可以用jansson库检测,也可以用cjson库来校验。但是若数据格式有问题,jansson可以指出哪里有错误,cjson无法指出。 下面就演示C语言如何使用jansson库检测字符串是否是json格式的数据。 1.下载…...

我再记录一个bug
项目场景: 提示:这里简述项目相关背景: 例如:项目场景:示例:通过蓝牙芯片(HC-05)与手机 APP 通信,每隔 5s 传输一批传感器数据(不是很大) 问题描述 提示:这里描述项目中遇到的问题࿱…...
AJAX: 对话框大全
AJAX:$.ajax({url: "/admin/cutting/getDataWeek",type: "GET",data:{},dataType:json,success: function (res) {if (res.code 1) {}},error:function (error) {console.log(请求失败);console.log(error);}}); $(.sub).unbind(click).click(funct…...
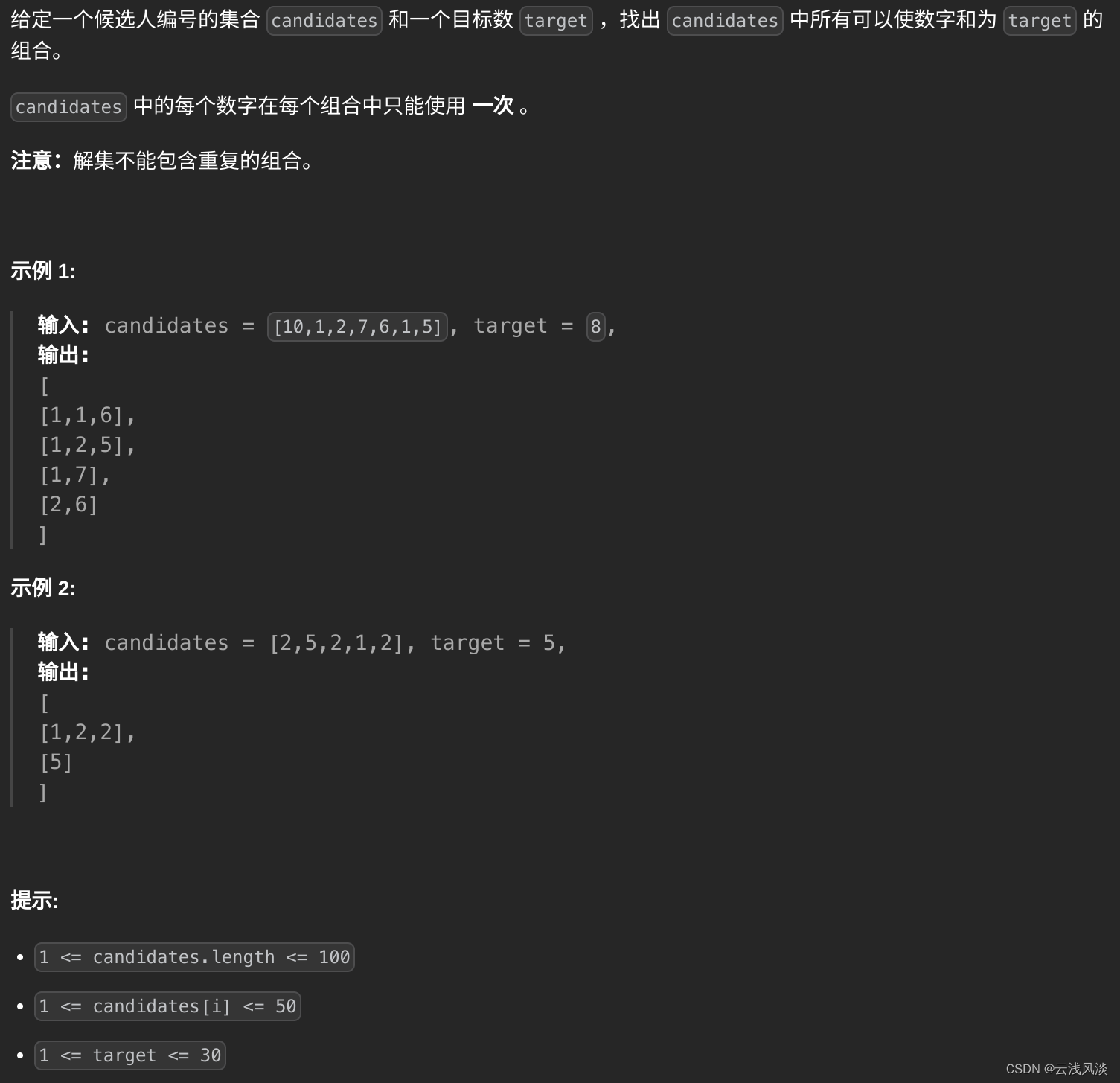
LeetCode讲解篇之40. 组合总和 II
文章目录 题目描述题解思路题解代码 题目描述 题解思路 按升序排序candidates,然后遍历candidates,目标数减去当前candidates的数,若该结果小于0,因为candidates的元素大于0,所以后续不会再出现让计算结果等于0的情况…...
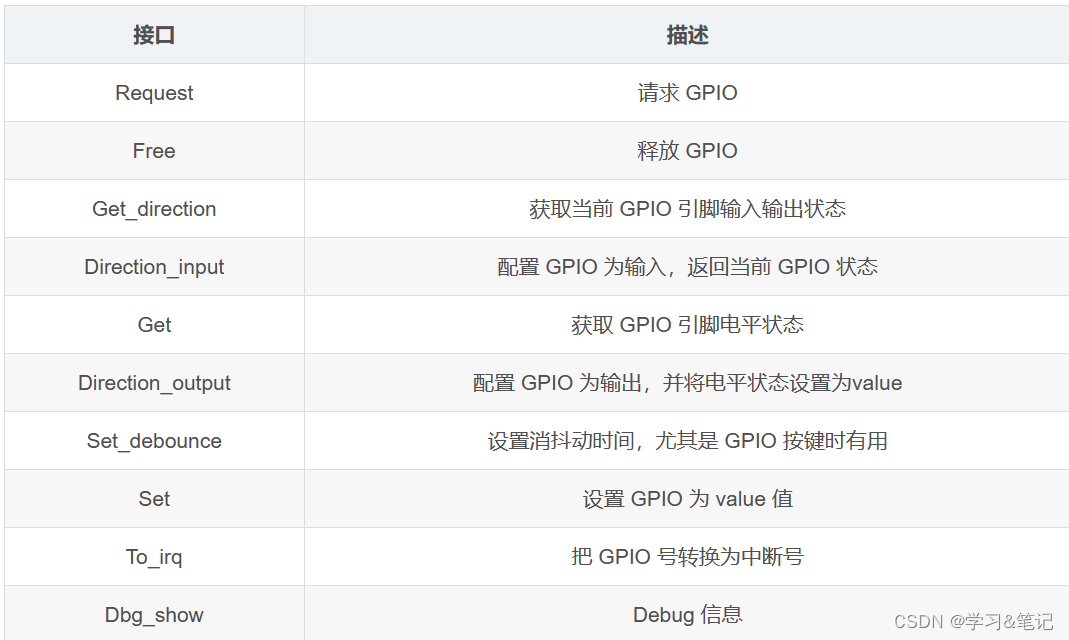
RK3568平台 GPIO子系统框架
一.gpio 子系统简介 gpio 子系统顾名思义,就是用于初始化 GPIO 并且提供相应的 API 函数,比如设置 GPIO为输入输出,读取 GPIO 的值等。gpio 子系统的主要目的就是方便驱动开发者使用 gpio,驱动 开发者在设备树中添加 gpio 相关信…...
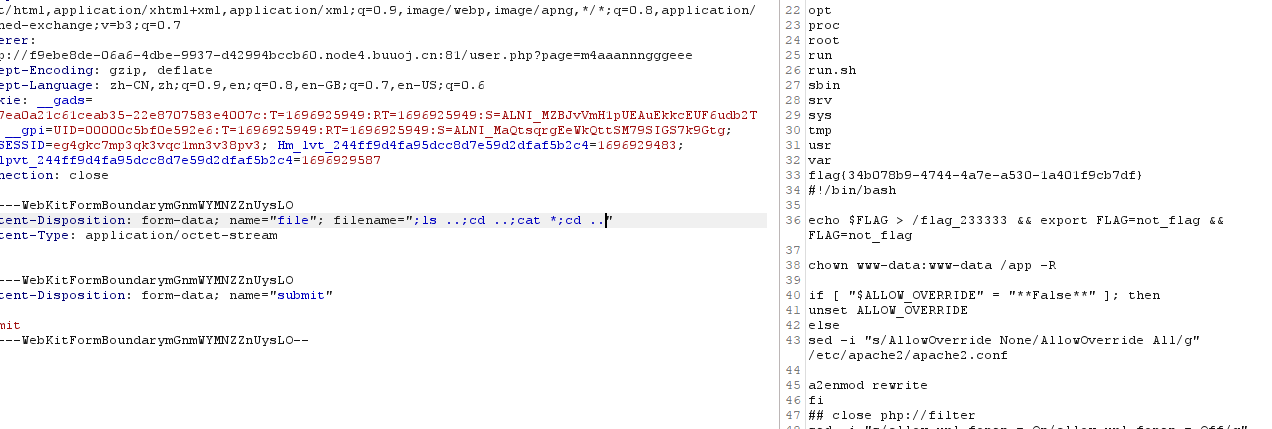
buu第五页 wp
[RootersCTF2019]babyWeb 预期解 一眼就是sql注入,发现过滤了 UNION SLEEP " OR - BENCHMARK盲注没法用了,因为union被过滤,堆叠注入也不考虑,发现报错有回显,尝试报错注入。 尝试: 1||(updatex…...
【论文阅读】以及部署BEVFusion: A Simple and Robust LiDAR-Camera Fusion Framework
BEVFusion: A Simple and Robust LiDAR-Camera Fusion Framework BEVFusion:一个简单而强大的LiDAR-相机融合框架 NeurIPS 2022 多模态传感器融合意味着信息互补、稳定,是自动驾驶感知的重要一环,本文注重工业落地,实际应用 融…...
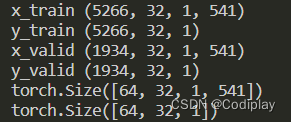
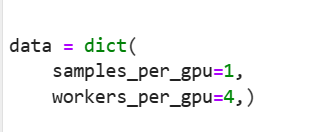
N——>BatchSize 数据维度理解和处理(chun, cat, squeeze, unsqueeze)
数据处理之N——>BatchSize N——>batch_size train_data TensorDataset(torch.Tensor(x_train).double(), torch.Tensor(y_train).double()) train_loader DataLoader(train_data, batch_sizeargs.bs, shuffleTrue, drop_lastTrue) for batch_idx, (inputs, results…...

【编解码格式】AV1
AV1 AOMedia Video 1(简称AV1)是一个开放、免专利的视频编码格式,专为通过网络进行流传输而设计。它由开放媒体联盟(AOMedia)开发,目标是取代其前身VP9[2],该联盟由半导体企业、视频点播供应商…...
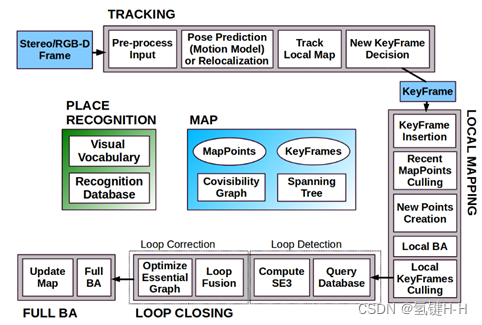
SLAM ORB-SLAM2(6)系统对象
SLAM ORB-SLAM2(6)系统对象 1. 封装2. 成员变量2.1. 核心数据2.2. 三个对象2.3. 三个线程2.4. 跟踪状态3. 成员函数4. 构造函数5. 数据驱动接口1. 封装 在 《SLAM ORB-SLAM2(5)例程了解》 了解到创建了一个 ORB_SLAM2::System 类型的对象 然后不断的把数据供给该对象就可以…...
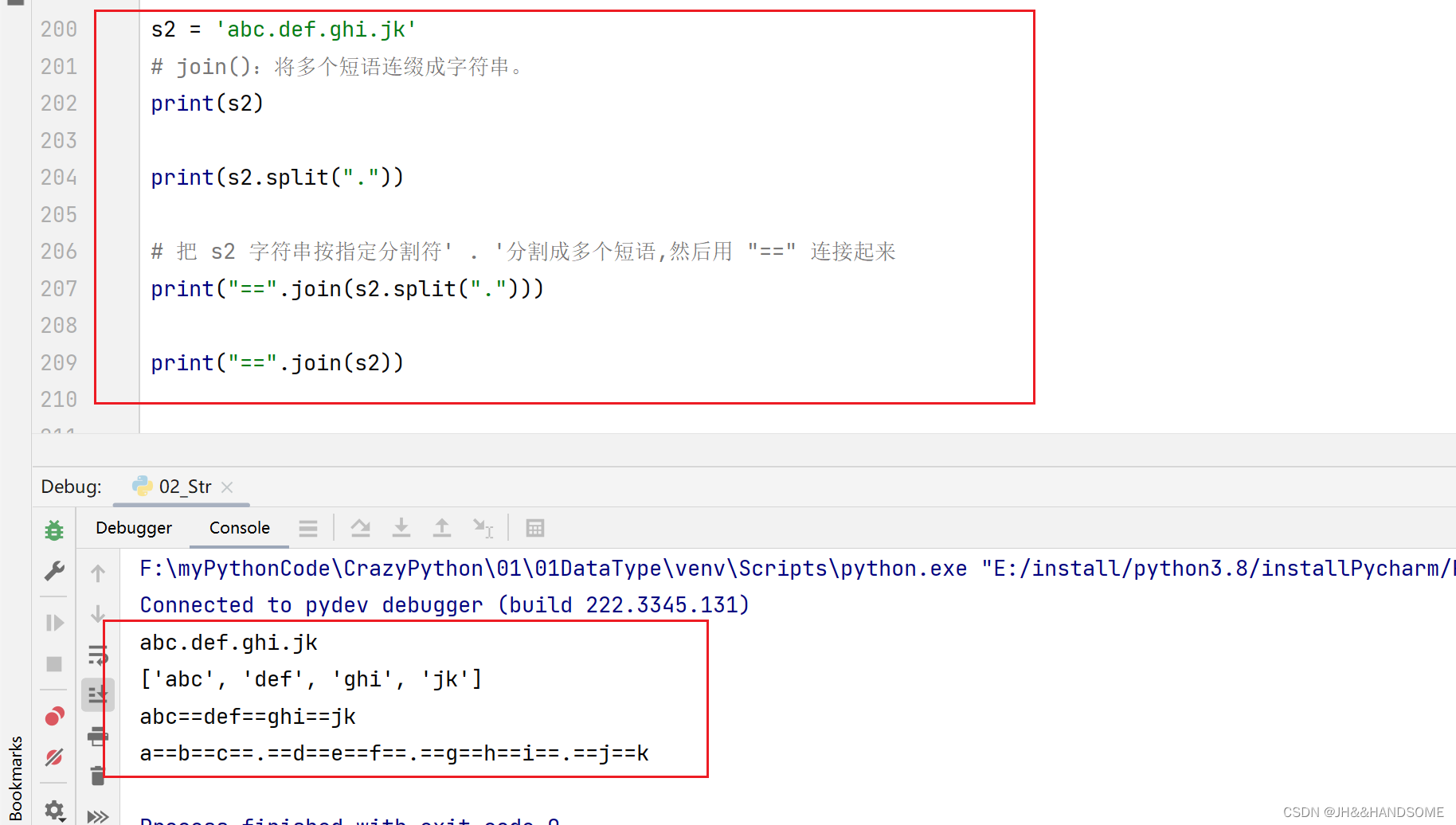
03、Python 字符串高级用法
目录 Python 字符串高级用法转义字符字符串格式化序列相关的方法大小写相关的方法dir 可以查看某个类的所有方法删除空白查找、替换相关方法 Python 字符串高级用法 转义字符 字符串格式化 序列相关的方法 字符串本质就是由多个字符组成,字符串的本质就是不可变序…...

armbian安装gcc、g++
文章目录 安装GCC安装G 安装GCC 打开终端,更新软件包列表: sudo apt update安装GCC: sudo apt install gcc如果需要安装特定版本的GCC,可以使用以下命令: sudo apt install gcc-<version> # sudo apt install g…...
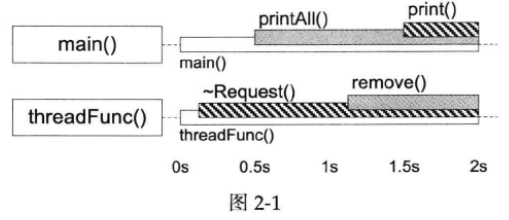
Linux多线程服务端编程:使用muduo C++网络库 学习笔记 第二章 线程同步精要
并发编程有两种基本模型,一种是message passing,另一种是shared memory。在分布式系统中,运行在多台机器上的多个进程的并行编程只有一种实用模型:message passing。在单机上,我们也可以照搬message passing作为多个进…...
中间件安全-CVE复现WeblogicJenkinsGlassFish漏洞复现
目录 服务攻防-中间件安全&CVE复现&Weblogic&Jenkins&GlassFish漏洞复现中间件-Weblogic安全问题漏洞复现CVE_2017_3506漏洞复现 中间件-JBoos安全问题漏洞复现CVE-2017-12149漏洞复现CVE-2017-7504漏洞复现 中间件-Jenkins安全问题漏洞复现CVE-2017-1000353漏…...

辅助驾驶功能开发-功能规范篇(16)-2-领航辅助系统NAP-HMI人机交互
书接上回 2.3.7HMI人机交互 2.3.7.1显示 (1)图标 序号 图标状态 (图形、颜色供参考) 含义说明 备注 1 辅助驾驶功能READY (允许激活) 2 辅助驾驶功能激活 3 辅助驾驶系统故障 4...
[计算机入门] 应用软件介绍(娱乐类)
3.21 应用软件介绍(娱乐类) 3.21.1 音乐:酷狗 音乐软件是一类可以帮助人们播放、管理和发现音乐的应用程序。它们提供了丰富的音乐内容,用户可以通过搜索、分类浏览或个性化推荐等方式找到自己喜欢的歌曲、专辑或艺术家。音乐软件还通常支持创建和管理…...
重构波前相位(附完整代码))
Matlab实战:手把手教你用区域法(zonal method)重构波前相位(附完整代码)
Matlab实战:区域法波前重构技术详解与代码实现 在自适应光学系统中,波前重构是从斜率测量数据中恢复原始波前相位分布的核心技术。区域法(zonal method)因其计算效率高、实现简单等优势,成为工程实践中的首选方案。本文将深入解析Southwell和…...

城通网盘直连解析工具终极指南:3大技术突破实现高速下载
城通网盘直连解析工具终极指南:3大技术突破实现高速下载 【免费下载链接】ctfileGet 获取城通网盘一次性直连地址 项目地址: https://gitcode.com/gh_mirrors/ct/ctfileGet 你是否曾经面对城通网盘的龟速下载而束手无策?每次下载文件都要经历漫长…...

从FSL-BET2、SPM-CAT12到Deepbet:一次MRI颅骨剥离工具的实战效果评测与选择指南
1. 为什么颅骨剥离是MRI分析的第一步? 做过脑部MRI分析的朋友都知道,拿到原始扫描数据后,第一步往往不是直接分析,而是要进行颅骨剥离(Skull Stripping)。这个步骤看似简单,却直接影响后续分析的…...

Git核心概念与版本控制思想启蒙
Git核心概念与版本控制思想启蒙 那天下午,调试器停在一个诡异的堆栈溢出位置。我盯着屏幕上的十六进制地址,突然意识到——三小时前能正常运行的代码,现在彻底崩了。更糟糕的是,我完全想不起自己改过哪些文件。Ctrl+Z按到手酸,文件恢复对话框弹了又弹,最后只能对着编译错…...

抖音无水印视频批量下载:3分钟快速上手完整指南
抖音无水印视频批量下载:3分钟快速上手完整指南 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallback support. 抖…...
)
SpringBoot 全局异常处理 + 参数校验,企业级规范写法(代码直接复制)
一、前言 在 SpringBoot 前后端分离项目里,这两个东西几乎是必写基础: 1.接口参数乱传,直接报错到前端 2.异常满天飞,前端各种无法解析 3.每个接口都写 try-catch,代码又臭又长 4.参数校验逻辑重复,维护成…...

java面试必问6:Spring IOC 是什么?从概念到原理,一篇讲透
Spring IOC 是什么?从概念到原理,一篇讲透面试官:“说一下 Spring IOC 是什么?” 你:“IOC 即控制反转,把对象创建和依赖管理的控制权从程序员手中交给 Spring 容器,不再需要手动 new。核心好处…...

快速部署FLUX.1-dev镜像:无需复杂配置,直接访问Web界面开始创作
快速部署FLUX.1-dev镜像:无需复杂配置,直接访问Web界面开始创作 想体验当前开源界画质最强的文生图模型,但被复杂的本地部署、环境配置和显存问题劝退?今天,我们带来一个“开箱即用”的解决方案。通过部署 FLUX.1-dev…...

Step3-VL-10B-Base模型部署避坑指南:解决C盘空间不足与依赖冲突
Step3-VL-10B-Base模型部署避坑指南:解决C盘空间不足与依赖冲突 最近有不少朋友在尝试部署Step3-VL-10B-Base这个视觉语言大模型时,遇到了两个特别头疼的问题。一个是刚跑起来没多久,C盘就飘红了,系统提示空间不足;另…...
首次发布)
“AI写的歌能拿格莱美吗?”——2026奇点大会法律与艺术双委员会联合声明:原创性认定新标准、人类协作度黄金阈值(≥37.6%)首次发布
第一章:AI音乐创作的格莱美资格争议与奇点大会历史意义 2026奇点智能技术大会(https://ml-summit.org) 2024年,美国国家录音艺术与科学学院(The Recording Academy)正式修订《格莱美奖参赛规则》,明确将“由AI生成且…...