自然语言处理---Transformer构建语言模型
语言模型概述
以一个符合语言规律的序列为输入,模型将利用序列间关系等特征,输出一个在所有词汇上的概率分布,这样的模型称为语言模型。
# 语言模型的训练语料一般来自于文章,对应的源文本和目标文本形如:
src1 = "I can do" tgt1 = "can do it"
src2 = "can do it", tgt2 = "do it <eos>"
语言模型能解决哪些问题:
- 根据语言模型的定义,可以在它的基础上完成机器翻译,文本生成等任务,因为通过最后输出的概率分布来预测下一个词汇是什么。
- 语言模型可以判断输入的序列是否为一句完整的话,因为可以根据输出的概率分布查看最大概率是否落在句子结束符上,来判断完整性。
- 语言模型本身的训练目标是预测下一个词,因为它的特征提取部分会抽象很多语言序列之间的关系,这些关系可能同样对其他语言类任务有效果。因此可以作为预训练模型进行迁移学习。
语言模型实现
- 第一步: 导入必备的工具包
- 第二步: 导入wikiText-2数据集并作基本处理
- 第三步: 构建用于模型输入的批次化数据
- 第四步: 构建训练和评估函数
- 第五步: 进行训练和评估(包括验证以及测试)
1. 导入必备的工具包
# 数学计算工具包math
import math# torch以及torch.nn, torch.nn.functional
import torch
import torch.nn as nn
import torch.nn.functional as F# torch中经典文本数据集有关的工具包
# 具体详情参考下方torchtext介绍
import torchtext# torchtext中的数据处理工具, get_tokenizer用于英文分词
from torchtext.data.utils import get_tokenizer# 已经构建完成的TransformerModel
from pyitcast.transformer import TransformerModel2. 导入wikiText-2数据集并作基本处理
# 创建语料域, 语料域是存放语料的数据结构,
# 它的四个参数代表给存放语料(或称作文本)施加的作用.
# 分别为 tokenize,使用get_tokenizer("basic_english")获得一个分割器对象,
# 分割方式按照文本为基础英文进行分割.
# init_token为给文本施加的起始符 <sos>给文本施加的终止符<eos>,
# 最后一个lower为True, 存放的文本字母全部小写.
TEXT = torchtext.data.Field(tokenize=get_tokenizer("basic_english"),init_token='<sos>',eos_token='<eos>',lower=True)# 最终获得一个Field对象.
# <torchtext.data.field.Field object at 0x7fc42a02e7f0># 然后使用torchtext的数据集方法导入WikiText2数据,
# 并切分为对应训练文本, 验证文本,测试文本, 并对这些文本施加刚刚创建的语料域.
train_txt, val_txt, test_txt = torchtext.datasets.WikiText2.splits(TEXT)# 我们可以通过examples[0].text取出文本对象进行查看.
# >>> test_txt.examples[0].text[:10]
# ['<eos>', '=', 'robert', '<unk>', '=', '<eos>', '<eos>', 'robert', '<unk>', 'is']# 将训练集文本数据构建一个vocab对象,
# 这样可以使用vocab对象的stoi方法统计文本共包含的不重复词汇总数.
TEXT.build_vocab(train_txt)# 然后选择设备cuda或者cpu
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
3. 构建用于模型输入的批次化数据
- 批次化过程的第一个函数batchify代码分析:
def batchify(data, bsz):"""batchify函数用于将文本数据映射成连续数字, 并转换成指定的样式, 指定的样式可参考下图.它有两个输入参数, data就是我们之前得到的文本数据(train_txt, val_txt, test_txt),bsz是就是batch_size, 每次模型更新参数的数据量"""# 使用TEXT的numericalize方法将单词映射成对应的连续数字.data = TEXT.numericalize([data.examples[0].text])# >>> data# tensor([[ 3],# [ 12],# [3852],# ...,# [ 6],# [ 3],# [ 3]])# 接着用数据词汇总数除以bsz,# 取整数得到一个nbatch代表需要多少次batch后能够遍历完所有数据nbatch = data.size(0) // bsz# 之后使用narrow方法对不规整的剩余数据进行删除,# 第一个参数是代表横轴删除还是纵轴删除, 0为横轴,1为纵轴# 第二个和第三个参数代表保留开始轴到结束轴的数值.类似于切片# 可参考下方演示示例进行更深理解.data = data.narrow(0, 0, nbatch * bsz)# >>> data# tensor([[ 3],# [ 12],# [3852],# ...,# [ 78],# [ 299],# [ 36]])# 后面不能形成bsz个的一组数据被删除# 接着我们使用view方法对data进行矩阵变换, 使其成为如下样式:# tensor([[ 3, 25, 1849, ..., 5, 65, 30],# [ 12, 66, 13, ..., 35, 2438, 4064],# [ 3852, 13667, 2962, ..., 902, 33, 20],# ...,# [ 154, 7, 10, ..., 5, 1076, 78],# [ 25, 4, 4135, ..., 4, 56, 299],# [ 6, 57, 385, ..., 3168, 737, 36]])# 因为会做转置操作, 因此这个矩阵的形状是[None, bsz],# 如果输入是训练数据的话,形状为[104335, 20], 可以通过打印data.shape获得.# 也就是data的列数是等于bsz的值的.data = data.view(bsz, -1).t().contiguous()# 最后将数据分配在指定的设备上.return data.to(device)
- batchify的样式转化图
大写字母A,B,C ... 代表句子中的每个单词
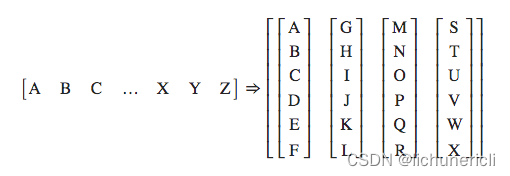
- 接下来将使用batchify来处理训练数据,验证数据以及测试数据
# 训练数据的batch size
batch_size = 20# 验证和测试数据(统称为评估数据)的batch size
eval_batch_size = 10# 获得train_data, val_data, test_data
train_data = batchify(train_txt, batch_size)
val_data = batchify(val_txt, eval_batch_size)
test_data = batchify(test_txt, eval_batch_size)
- 上面的分割批次并没有进行源数据与目标数据的处理,接下来将根据语言模型训练的语料规定来构建源数据与目标数据。
- 语言模型训练的语料规定:如果源数据为句子ABCD,ABCD代表句子中的词汇或符号,则它的目标数据为BCDE,BCDE分别代表ABCD的下一个词汇
- 如图所示,这里的句子序列是竖着的,而且发现如果用一个批次处理完所有数据,以训练数据为例,每个句子长度高达104335,这明显是不科学的,因此在这里要限定每个批次中的句子长度允许的最大值bptt。
- 批次化过程的第二个函数get_batch代码分析
# 令子长度允许的最大值bptt为35
bptt = 35def get_batch(source, i):"""用于获得每个批次合理大小的源数据和目标数据.参数source是通过batchify得到的train_data/val_data/test_data.i是具体的批次次数."""# 首先我们确定句子长度, 它将是在bptt和len(source) - 1 - i中最小值# 实质上, 前面的批次中都会是bptt的值, 只不过最后一个批次中, 句子长度# 可能不够bptt的35个, 因此会变为len(source) - 1 - i的值.seq_len = min(bptt, len(source) - 1 - i)# 语言模型训练的源数据的第i批数据将是batchify的结果的切片[i:i+seq_len]data = source[i:i+seq_len]# 根据语言模型训练的语料规定, 它的目标数据是源数据向后移动一位# 因为最后目标数据的切片会越界, 因此使用view(-1)来保证形状正常.target = source[i+1:i+1+seq_len].view(-1)return data, target
4. 构建训练和评估函数
- 设置模型超参数和初始化模型
# 通过TEXT.vocab.stoi方法获得不重复词汇总数
ntokens = len(TEXT.vocab.stoi)# 词嵌入大小为200
emsize = 200# 前馈全连接层的节点数
nhid = 200# 编码器层的数量
nlayers = 2# 多头注意力机制的头数
nhead = 2# 置0比率
dropout = 0.2# 将参数输入到TransformerModel中
model = TransformerModel(ntokens, emsize, nhead, nhid, nlayers, dropout).to(device)# 模型初始化后, 接下来进行损失函数和优化方法的选择.# 关于损失函数, 我们使用nn自带的交叉熵损失
criterion = nn.CrossEntropyLoss()# 学习率初始值定为5.0
lr = 5.0# 优化器选择torch自带的SGD随机梯度下降方法, 并把lr传入其中
optimizer = torch.optim.SGD(model.parameters(), lr=lr)# 定义学习率调整方法, 使用torch自带的lr_scheduler, 将优化器传入其中.
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, 1.0, gamma=0.95)
- 模型训练代码分析
# 导入时间工具包
import timedef train():"""训练函数"""# 模型开启训练模式model.train()# 定义初始损失为0total_loss = 0.# 获得当前时间start_time = time.time()# 开始遍历批次数据for batch, i in enumerate(range(0, train_data.size(0) - 1, bptt)):# 通过get_batch获得源数据和目标数据data, targets = get_batch(train_data, i)# 设置优化器初始梯度为0梯度optimizer.zero_grad()# 将数据装入model得到输出output = model(data)# 将输出和目标数据传入损失函数对象loss = criterion(output.view(-1, ntokens), targets)# 损失进行反向传播以获得总的损失loss.backward()# 使用nn自带的clip_grad_norm_方法进行梯度规范化, 防止出现梯度消失或爆炸torch.nn.utils.clip_grad_norm_(model.parameters(), 0.5)# 模型参数进行更新optimizer.step()# 将每层的损失相加获得总的损失total_loss += loss.item()# 日志打印间隔定为200log_interval = 200# 如果batch是200的倍数且大于0,则打印相关日志if batch % log_interval == 0 and batch > 0:# 平均损失为总损失除以log_intervalcur_loss = total_loss / log_interval# 需要的时间为当前时间减去开始时间elapsed = time.time() - start_time# 打印轮数, 当前批次和总批次, 当前学习率, 训练速度(每豪秒处理多少批次),# 平均损失, 以及困惑度, 困惑度是衡量语言模型的重要指标, 它的计算方法就是# 对交叉熵平均损失取自然对数的底数.print('| epoch {:3d} | {:5d}/{:5d} batches | ''lr {:02.2f} | ms/batch {:5.2f} | ''loss {:5.2f} | ppl {:8.2f}'.format(epoch, batch, len(train_data) // bptt, scheduler.get_lr()[0],elapsed * 1000 / log_interval,cur_loss, math.exp(cur_loss)))# 每个批次结束后, 总损失归0total_loss = 0# 开始时间取当前时间start_time = time.time()
- 模型评估代码分析
def evaluate(eval_model, data_source):"""评估函数, 评估阶段包括验证和测试,它的两个参数eval_model为每轮训练产生的模型data_source代表验证或测试数据集"""# 模型开启评估模式eval_model.eval()# 总损失归0total_loss = 0# 因为评估模式模型参数不变, 因此反向传播不需要求导, 以加快计算with torch.no_grad():# 与训练过程相同, 但是因为过程不需要打印信息, 因此不需要batch数for i in range(0, data_source.size(0) - 1, bptt):# 首先还是通过通过get_batch获得验证数据集的源数据和目标数据data, targets = get_batch(data_source, i)# 通过eval_model获得输出output = eval_model(data)# 对输出形状扁平化, 变为全部词汇的概率分布output_flat = output.view(-1, ntokens)# 获得评估过程的总损失total_loss += criterion(output_flat, targets).item()# 计算平均损失cur_loss = total_loss / ((data_source.size(0) - 1) / bptt) # 返回平均损失return cur_loss
5. 进行训练和评估
- 模型的训练与验证代码分析
# 首先初始化最佳验证损失,初始值为无穷大
import copy
best_val_loss = float("inf")# 定义训练轮数
epochs = 3# 定义最佳模型变量, 初始值为None
best_model = None# 使用for循环遍历轮数
for epoch in range(1, epochs + 1):# 首先获得轮数开始时间epoch_start_time = time.time()# 调用训练函数train()# 该轮训练后我们的模型参数已经发生了变化# 将模型和评估数据传入到评估函数中val_loss = evaluate(model, val_data)# 之后打印每轮的评估日志,分别有轮数,耗时,验证损失以及验证困惑度print('-' * 89)print('| end of epoch {:3d} | time: {:5.2f}s | valid loss {:5.2f} | ''valid ppl {:8.2f}'.format(epoch, (time.time() - epoch_start_time),val_loss, math.exp(val_loss)))print('-' * 89)# 我们将比较哪一轮损失最小,赋值给best_val_loss,# 并取该损失下的模型为best_modelif val_loss < best_val_loss:best_val_loss = val_loss# 使用深拷贝,拷贝最优模型best_model = copy.deepcopy(model)# 每轮都会对优化方法的学习率做调整scheduler.step()
- 模型测试代码分析
# 我们仍然使用evaluate函数,这次它的参数是best_model以及测试数据
test_loss = evaluate(best_model, test_data)# 打印测试日志,包括测试损失和测试困惑度
print('=' * 89)
print('| End of training | test loss {:5.2f} | test ppl {:8.2f}'.format(test_loss, math.exp(test_loss)))
print('=' * 89)
相关文章:
自然语言处理---Transformer构建语言模型
语言模型概述 以一个符合语言规律的序列为输入,模型将利用序列间关系等特征,输出一个在所有词汇上的概率分布,这样的模型称为语言模型。 # 语言模型的训练语料一般来自于文章,对应的源文本和目标文本形如: src1 "I can do&…...

【WPF】对Image元素进行缩放平移等操作
元素布局 <Border Grid.Row"1" Name"border" ClipToBounds"True" Margin"10,10,10,10"><Image Name"image" Visibility"Visible" Margin"3,3,3,3" Grid.Column"1" Source"{Bin…...

JavaScript中Bom节点和表单的获取值
Bom节点 代表浏览器对象模型(Browser Object Model),它是浏览器提供的 JavaScript API,用于与浏览器窗口和浏览器本身进行交互 获取当前网页的URL: const currentURL window.location.href; console.log(currentURL…...
RDB.js:适用于 Node.js 和 Typescript 的终极对象关系映射器
RDB.js 是适用于 Node.js 和 Typescript 的终极对象关系映射器,可与 Postgres、MS SQL、MySQL、Sybase SAP 和 SQLite 等流行数据库无缝集成。无论您是使用 TypeScript 还是 JavaScript(包括 CommonJS 和 ECMAScript)构建应用程序,…...
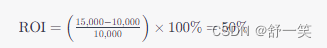
ROI的投入产出比是什么?
ROI的投入产出比是什么? 投入产出比(Return on Investment, ROI)是一种评估投资效益的财务指标,用于衡量投资带来的回报与投入成本之间的关系。它的计算公式如下: 投资收益:指的是投资带来的净收入&#x…...

Linux打包发布常用命令
1、先下载一个FileZilla Client远程连接工具,并连接我们需要连接的服务器 2、进入xshell连接对应的服务器,连接后若不知道项目位置,可使用此命令查看 ps -ef | grep java 此时会出现一大串代码,找到以我这为例:root…...

Docker Swarm 节点维护
Docker Swarm Mode Docker Swarm 集群搭建 Docker Swarm 节点维护 Docker Service 创建 1.角色转换 Swarm 集群中节点的角色只有 manager 与 worker,所以其角色也只是在 manager 与worker 间的转换。即 worker 升级为 manager,或 manager 降级为 worke…...

AS/NZS 1859.3:2017 木基装饰板检测
木基装饰板是指以木质材料为基材,比如刨花板,胶合板等木质人造板,表面贴有PVC膜,三聚氰胺纸,木饰面等装饰层压制而成的木质复合材料,主要用于墙面装饰,家具等领域。 AS/NZS 1859.3:…...

深入理解算法:从基础到实践
深入理解算法:从基础到实践 1. 算法的定义2. 算法的特性3. 算法的分类按解决问题的性质分类:按算法的设计思路分类: 4. 算法分析5. 算法示例a. 搜索算法示例:二分搜索b. 排序算法示例:快速排序c. 动态规划示例…...
【java】A卷+B卷)
华为OD 机智的外卖员(100分)【java】A卷+B卷
华为OD统一考试A卷+B卷 新题库说明 你收到的链接上面会标注A卷还是B卷。目前大部分收到的都是B卷。 B卷对应20022部分考题以及新出的题目,A卷对应的是新出的题目。 我将持续更新最新题目 获取更多免费题目可前往夸克网盘下载,请点击以下链接进入: 我用夸克网盘分享了「华为O…...
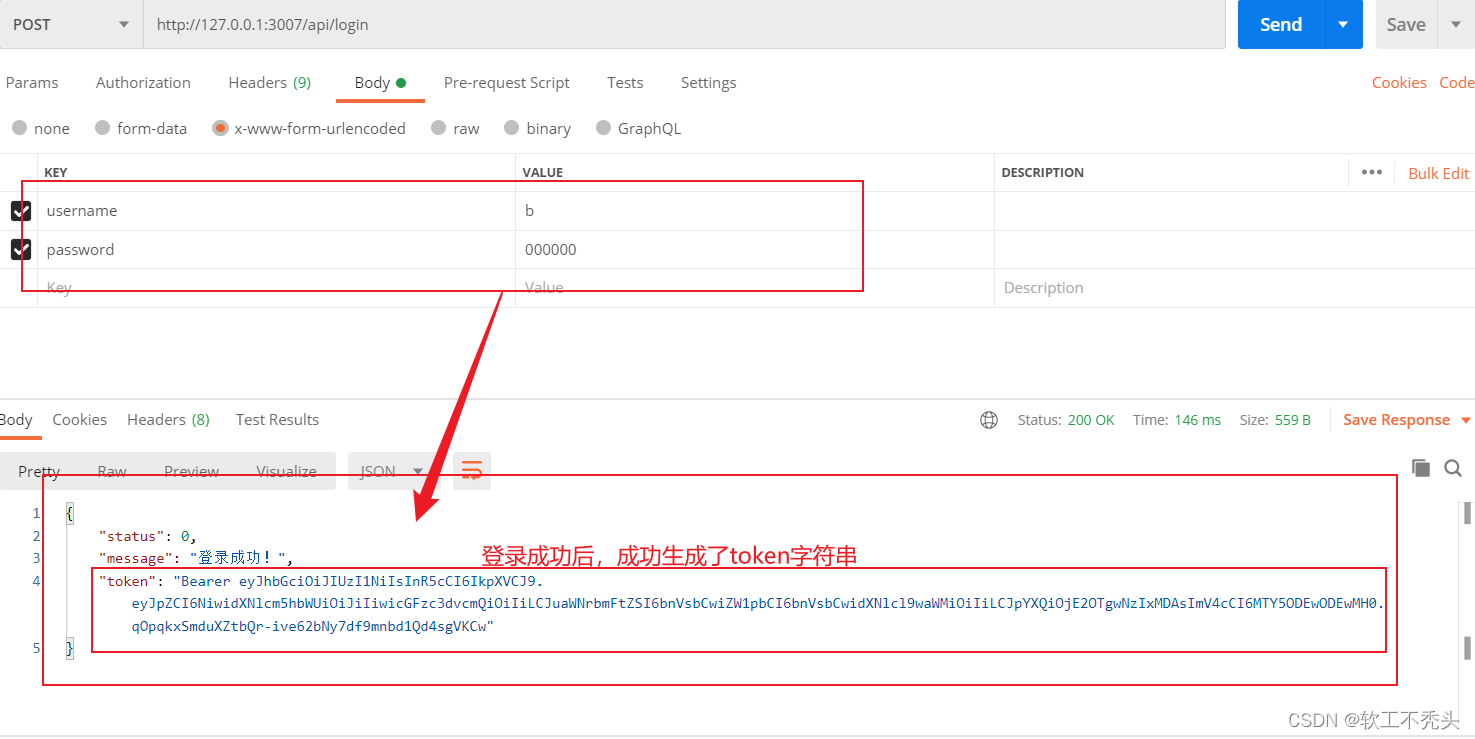
Node编写用户登录接口
目录 前言 服务器 编写登录接口API 使用sql语句查询数据库中是否有该用户 判断密码是否正确 生成JWT的Token字符串 配置解析token的中间件 配置捕获错误中间件 完整的登录接口代码 前言 本文介绍如何使用node编写登录接口以及解密生成token,如何编写注册接…...
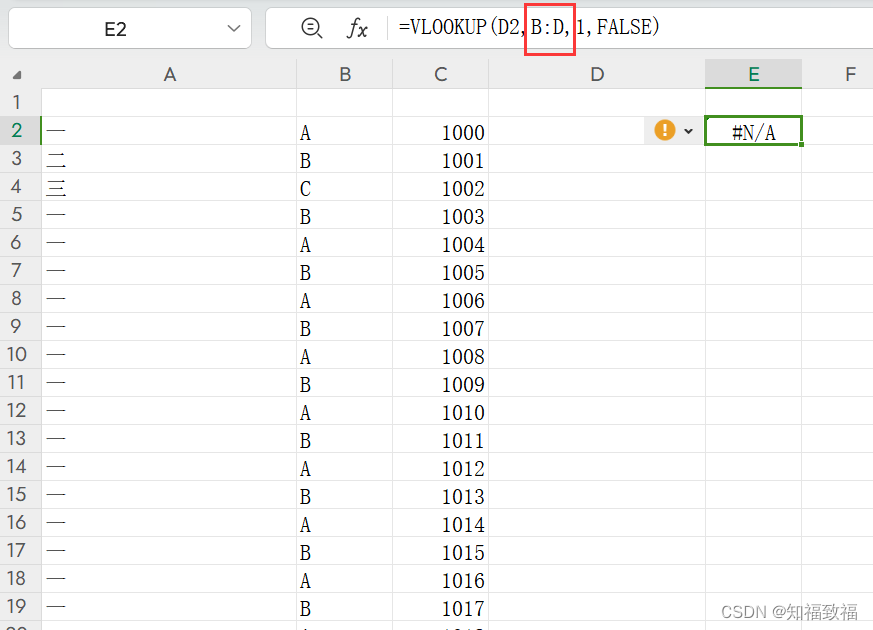
vlookup函数踩坑(wps)
使用wps的朋友看过来 vlookup函数踩坑,vlookup(查找值,查找范围,返回值的索引,精确查找or模糊查找) 我们要查找的数据的那一列,必须是查找范围的第一列! 案例,看下面的…...
))
老卫带你学---leetcode刷题(8. 字符串转换整数 (atoi))
8. 字符串转换整数 (atoi) 问题: 请你来实现一个 myAtoi(string s) 函数,使其能将字符串转换成一个 32 位有符号整数(类似 C/C 中的 atoi 函数)。 函数 myAtoi(string s) 的算法如下: 读入字符串并丢弃无用的前导空…...

了解事件冒泡
事件冒泡是指在网页中,当某个元素触发了一个事件时,这个事件会逐级向上传播到它的父元素,直至达到文档树的根节点。这种传播方式被称为事件冒泡。 为什么会有事件冒泡? 事件冒泡是为了方便处理多个嵌套元素的事件而引入的机制。…...
线性代数1:线性方程和系统
Digital Collection (staedelmuseum.de) 图片来自施泰德博物馆 一、前言 通过这些文章,我希望巩固我对这些基本概念的理解,同时如果可能的话,通过我希望成为一种基于直觉的数学学习方法为其他人提供额外的清晰度。如果有任何错误或机会需要我…...
“第四十八天” 计算机组成原理
数据结构学完了,不过也就是匆匆过了一遍,后面肯定还是要重来的。现在开始学机组了。 计算机发展历程: 计算机硬件唯一能识别的数据是二进制的 0/1,而在计算机中用低/高电平表示 0 / 1,也就是通过电信号传递数据&#x…...

【算法|贪心算法系列No.4】leetcode55. 跳跃游戏 45. 跳跃游戏 II
个人主页:兜里有颗棉花糖 欢迎 点赞👍 收藏✨ 留言✉ 加关注💓本文由 兜里有颗棉花糖 原创 收录于专栏【手撕算法系列专栏】【LeetCode】 🍔本专栏旨在提高自己算法能力的同时,记录一下自己的学习过程,希望…...

第九章 JDBC
文章目录 一. 单选题(共5题,50分)二. 判断题(共5题,50分) 一. 单选题(共5题,50分) (单选题) 下列选项,可用于存储结果集的对象是() A.…...
Kubernetes基础概念及架构和组件
目录 一、kubernetes简介 1、kubernetes的介绍与作用 2、为什么要用K8S? 二、kubernetes特性 1、自我修复 2、弹性伸缩 3、服务发现和负载均衡 4、自动发布(滚动发布/更新)和回滚 5、集中化配置管理和密钥管理 6、存储编排 7、任务批…...
04.Finetune vs. Prompt
目录 语言模型回顾大模型的两种路线专才通才二者的比较 专才养成记通才养成记Instruction LearningIn-context Learning 自动Prompt 部分截图来自原课程视频《2023李宏毅最新生成式AI教程》,B站自行搜索 语言模型回顾 GPT:文字接龙 How are __. Bert&a…...

RIGOL DS2302A-S数字示波器:高性能信号分析的终极解决方案
1. 为什么工程师都爱用RIGOL DS2302A-S? 第一次接触RIGOL DS2302A-S是在调试一块高速PCB板时,当时手头的示波器死活抓不到那个诡异的时钟抖动。同事把他的DS2302A-S推过来,300MHz带宽配合2GSa/s采样率,瞬间就让那个藏在噪声里的3n…...

基于Python的考试系统毕业设计
博主介绍:✌ 专注于Java,python,✌关注✌私信我✌具体的问题,我会尽力帮助你。 一、研究目的 本研究旨在设计并实现一个基于Python的考试系统,以满足现代教育环境中对在线考试系统的需求。该系统旨在提供一种高效、安全、便捷的考试环境&am…...
)
避坑指南:时间序列PCA分析最常见的5个错误(附正确操作)
避坑指南:时间序列PCA分析最常见的5个错误(附正确操作) 在金融预测、工业传感器监测或用户行为分析中,时间序列数据正以每秒TB级的速度增长。当数据科学家试图用PCA这把"瑞士军刀"处理这类数据时,约67%的案例…...

如何快速掌握deepdoctection:文档智能解析的终极指南
如何快速掌握deepdoctection:文档智能解析的终极指南 【免费下载链接】deepdoctection A Repo For Document AI 项目地址: https://gitcode.com/gh_mirrors/de/deepdoctection deepdoctection是一个强大的文档智能解析工具,能够帮助用户高效处理各…...

SetDPI完全指南:掌握Windows多显示器DPI缩放控制的高效方案
SetDPI完全指南:掌握Windows多显示器DPI缩放控制的高效方案 【免费下载链接】SetDPI 项目地址: https://gitcode.com/gh_mirrors/se/SetDPI Windows多显示器DPI缩放控制一直是专业用户面临的痛点,SetDPI作为一款开源命令行工具,提供了…...

WinBtrfs:让Windows用户也能享受Btrfs文件系统的强大功能
WinBtrfs:让Windows用户也能享受Btrfs文件系统的强大功能 【免费下载链接】btrfs WinBtrfs - an open-source btrfs driver for Windows 项目地址: https://gitcode.com/gh_mirrors/bt/btrfs WinBtrfs是一款专为Windows系统设计的开源Btrfs文件系统驱动程序&…...

kaishi啦啦啦啦
...

Legacy iOS Kit:让旧款iPhone/iPad重获新生的终极降级工具
Legacy iOS Kit:让旧款iPhone/iPad重获新生的终极降级工具 【免费下载链接】Legacy-iOS-Kit An all-in-one tool to restore/downgrade, save SHSH blobs, jailbreak legacy iOS devices, and more 项目地址: https://gitcode.com/gh_mirrors/le/Legacy-iOS-Kit …...

SD-PPP:Photoshop AI插件终极指南,5分钟让Photoshop变身AI图像生成工作站
SD-PPP:Photoshop AI插件终极指南,5分钟让Photoshop变身AI图像生成工作站 【免费下载链接】sd-ppp A Photoshop AI plugin 项目地址: https://gitcode.com/gh_mirrors/sd/sd-ppp 你是否厌倦了在Photoshop和AI工具之间来回切换?每次想要…...

left join详解
left join详解LEFT JOIN 详解一、基本语法二、执行逻辑与结果特点三、示例说明四、与其他 JOIN 的对比五、ON 条件与 WHERE 条件的区别(重要!)六、多表 LEFT JOIN七、性能考虑八、常见应用场景九、与其他数据库的差异十、小结1.不考虑where条…...