PyTorch Tensor 形状
查看张量形状
有两种方法查看张量形状:
- 通过属性查看 Tensor.shape
- 通过方法查看 Tensor.size()
两种方式的结果都是一个 torch.Size 类型(元组的子类)的对象
>>> t = torch.empty(3, 4)
>>> t.size()
torch.Size([3, 4])
# 获取 dim=1 维度的 size
>>> t.size(dim=1)
4
>>> t.shape
torch.Size([3, 4])
>>> isinstance(t.shape, tuple)
True
改变张量形状
- 返回新的张量
以下方法均要求: 形状改变前后元素的数量一致, 名称以 as 结尾的方法表示参考其他张量的形状
- Tensor.view(*shape)
- Tensor.view_as(other)
- Tensor.reshape(*shape)
- Tensor.reshape_as(other)
在张量数据连续(contiguous)的情况下, 这两种方式均共享底层数据
>>> t = torch.arange(6)
>>> t_1 = t.view(2, 3)
>>> t_1
tensor([[0, 1, 2],[3, 4, 5]])
# 可以有一个维度是 -1, PyTorch 根据其余维度推理该维度的大小
>>> t_2 = t.reshape(3, -1)
>>> t_2
tensor([[0, 1],[2, 3],[4, 5]])
# 获取底层数据地址
>>> p = t.storage().data_ptr()
>>> p_1 = t_1.storage().data_ptr()
>>> p_2 = t_2.storage().data_ptr()
# 底层数据地址相等
>>> p == p_1 == p_2
True
当张量数据不连续时(例如改变张量的维度顺序), 无法使用 Tensor.view() 方法, 而 Tensor.reshape() 方法会拷贝底层数据
>>> a = torch.tensor([[0, 1],[2, 3]])
>>> a
tensor([[0, 1],[2, 3]])
# 转置操作
>>> t = a.t()
>>> t
tensor([[0, 2],[1, 3]])
# t 已经不连续了, 当然 a 还是连续的
>>> t.is_contiguous()
False# t.view 抛出异常
>>> t.view(1, 4)
-----------------------------------------------------------
RuntimeError Traceback (most recent call last)
Input In [10], in <cell line: 1>()
----> 1 t.view(1, 4)RuntimeError: view size is not compatible with input tensor's size and stride (at least one dimension spans across two contiguous subspaces). Use .reshape(...) instead.# t.reshape 会拷贝数据
>>> t_2 = t.reshape(1, 4)
>>> t_2
tensor([[0, 2, 1, 3]])
>>> t.storage().data_ptr() == t_2.storage().data_ptr()
False
- 就地修改张量
这是一个比较底层的方法, 以 _ 为结尾表示直接修改张量本身, 不会创建新的张量, 并且不要求前后元素的数量一致
- Tensor.resize_(*sizes)
- Tensor.resize_as_(other)
代码示例:
>>> t = torch.arange(5)
>>> t
tensor([0, 1, 2, 3, 4])
>>> t.resize_(2, 2)
tensor([[0, 1],[2, 3]])
# 原张量已被修改
>>> t
tensor([[0, 1],[2, 3]])
调整维度顺序
- 矩阵转置
- Tensor.t()
仅对 2 维张量有效, 0 维和 1 维张量原样返回
>>> t = torch.tensor([[1, 2, 3]])
>>> t
tensor([[1, 2, 3]])
# 或者 t.T
>>> t.t()
tensor([[1],[2],[3]])
- 交换两个维度
- Tensor.transpose(dim0, dim1)
交换 Tensor 的 dim0 与 dim1 维度, Tensor.t() 就相当于 Tensor.transpose(0, 1)
- 调整维度顺序
- Tensor.permute(*dims)
指定 Tensor 维度的顺序, 将 HxWxC 顺序的图片张量转为 CxHxW 顺序, 可以调用: img.permute(2, 0, 1)
- 维度逆序
Tensor.T(deprecated)
相当于 Tensor.permute(n-1, n-2, …, 0), 在未来的版本 Tensor.T 仅对二维张量有效, 即矩阵转置
- Tensor.mT
末尾两个维度表示矩阵, 前面的所有维度表示 mini-batch, 仅对末尾两个维度逆序, 其余维度的顺序保持不变
>>> t = torch.arange(6).view(1,2,3)
>>> t.shape
torch.Size([1, 2, 3])
>>> t.permute(2, 1, 0).shape
torch.Size([3, 2, 1])
>>> t.T.shape
torch.Size([3, 2, 1])
插入或移除维度
-
插入大小为 1 的维度 Tensor.unsqueeze(dim)
-
删除大小为 1 的维度 Tensor.squeeze(dim=None) dim 为 None 时删除所有的 1-dim
dim 参数指定插入或删除的索引位
>>> t = torch.arange(4).view(2, -1)
>>> t.shape
torch.Size([2, 2])# 在开头插入 1-dim
>>> t_2 = t.unsqueeze(0)
>>> t_2.shape
torch.Size([1, 2, 2])# 在末尾插入 1-dim
>>> t_3 = t_2.unsqueeze(-1)
>>> t_3.shape
torch.Size([1, 2, 2, 1])# squeeze 默认移除所有的 1-dim
>>> t_3.squeeze().shape
torch.Size([2, 2])
维度数据重复
- Tensor.expand(*sizes)
*sizes 参数指定扩张后各个维度的大小, -1 表示表示该维度不扩张, 仅能对 1-dim 进行数据扩张
该方法不会额外分配空间, 与原张量共享底层数据, 可以在左侧新增维度
>>> t = torch.tensor([1, 2]).view(2, 1)
>>> t
tensor([[1],[2]])
>>> t.shape
torch.Size([2, 1])# 将维度 (2, 1) 扩张为 (2, 3),
# 原维度 (2, 1) 中的 2 保持不变, 1 扩为 2
>>> e = t.expand(-1, 2)
>>> e
tensor([[1, 1, 1],[2, 2, 2]])
>>> e.shape
torch.Size([2, 3])# 修改原张量会影响到扩张后的张量
>>> t[0, 0] = 0
>>> e
tensor([[0, 0, 0],[2, 2, 2]])
- Tensor.repeat(*sizes)
*sizes 参数指定各个维度的重复次数, 重复 1 次等同于维度保持不变
该方法复制底层数据, 与 Tensor.expand() 类似也可以在左侧新增维度
>>> t = torch.tensor([1, 2]).view(2, 1)
>>> t
tensor([[1],[2]])
>>> t.shape
torch.Size([2, 1])# # 原维度 (2, 1) 中的 2 和 1 均重复 2 次
>>> r = t.repeat(2, 2)
>>> r.shape
torch.Size([4, 2])
>>> r
tensor([[1, 1],[2, 2],[1, 1],[2, 2]])
拼接
torch.cat(tensors, dim=0) 拼接多个张量, 除了 dim 参数指定的拼接维度, 其他维度必须一致
>>> a = torch.arange(3, 9).view(3, 2).t()
>>> a
tensor([[3, 5, 7],[4, 6, 8]])
>>> b = torch.tensor([[1], [2]])
>>> b
tensor([[1],[2]])
>>> b.shape
torch.Size([2, 1])
# 维度(2, 3)与维度(2, 1)拼接
# 第 1 个维度相同(都是 2), 第 2 个维度不同(在此维度上拼接)
>>> torch.cat([b, a], dim=1)
tensor([[1, 3, 5, 7],[2, 4, 6, 8]])
叠加
torch.stack(tensors, dim=0) 叠加多个张量, 所有张量的维度必须一致, dim 指定叠加后新增的维度
>>> t = torch.arange(4).view(2, 2)
>>> t
tensor([[0, 1],[2, 3]])
# 叠加后变成三维张量
>>> n = torch.stack([t, t, t], dim=2)
>>> n
tensor([[[0, 0, 0],[1, 1, 1]],[[2, 2, 2],[3, 3, 3]]])
>>> n.shape
torch.Size([2, 2, 3])
与 torch.cat 保持原有的维度数量不同, torch.stack 会新增一个维度
分割
沿着指定的维度分割张量
- Tensor.split(split_size, dim=0)
- torch.split(tensor, split_size, dim=0)
参数 split_size:
- 整数: 表示分割后每一块的大小(最后一块可能略小)
- 列表: 具体指定每一个块的大小
>>> t = torch.arange(10).view(2, 5)
>>> t
tensor([[0, 1, 2, 3, 4],[5, 6, 7, 8, 9]])
# 按列分割, 每一个张量均为 2 列, 一共有 5 列, 最后一个张量不够分, 仅有 1 列
>>> t.split(2, dim=1)
(tensor([[0, 1],[5, 6]]),tensor([[2, 3],[7, 8]]),tensor([[4],[9]]))
# 3 个张量分别为 1, 3, 1 列
>>> t.split([1, 3, 1], dim=1)
(tensor([[0],[5]]),tensor([[1, 2, 3],[6, 7, 8]]),tensor([[4],[9]]))
分割后的张量是原张量的视图
分块
chunk 与 split 功能基本相同, 不同之处在于: chunk 的参数指定了分块的数量, 而 split 的参数指定每一个分块的大小
- Tensor.chunk(chunks, dim=0)
- torch.chunk(input, chunks, dim=0)
>>> t = torch.arange(10).view(2, 5)
>>> t
tensor([[0, 1, 2, 3, 4],[5, 6, 7, 8, 9]])
# 将 5 列分为 3 块, 没法均分, 最后一块略小
>>> t.chunk(3, dim=1)
(tensor([[0, 1],[5, 6]]),tensor([[2, 3],[7, 8]]),tensor([[4],[9]]))
分块后的张量也是原张量的视图
相关文章:

PyTorch Tensor 形状
查看张量形状 有两种方法查看张量形状: 通过属性查看 Tensor.shape通过方法查看 Tensor.size() 两种方式的结果都是一个 torch.Size 类型(元组的子类)的对象 >>> t torch.empty(3, 4) >>> t.size() torch.Size([3, 4]) # 获取 dim1 维度的 size >>…...
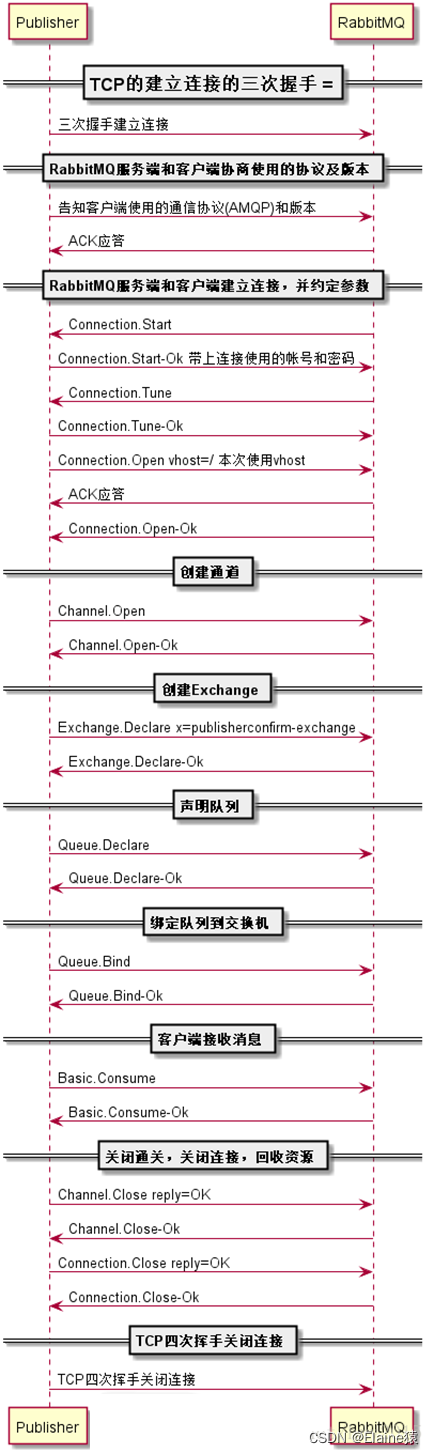
RabbitMQ运行机制和通讯过程介绍
文章目录 1.RabbitMQ 环境搭建2.RabbitMQ简介3.RabbitMQ的优势:4. rabbitmq服务介绍4.1 rabbitmq关键词说明4.2 消息队列运行机制4.3 exchange类型 5.wireshark抓包查看RabbitMQ通讯过程 1.RabbitMQ 环境搭建 参考我的另一篇:RabbitMQ安装及使用教程&am…...

UE4 TextRender显示中文方法
UE4 TextRender显示中文 1.内容浏览器右键,用户界面->字体。新建一个。 2.添加字体,右边栏,细节。字体缓存类型:离线。 3.高度参数就是字体大小,导入选项勾选”仅透明度”,字符里输入字库的字符。 4.资产,重新导…...

C++动态规划算法的应用:得到 K 个半回文串的最少修改次数 原理源码测试用例
本文涉及的基础知识点 动态规划 题目 得到 K 个半回文串的最少修改次数 给你一个字符串 s 和一个整数 k ,请你将 s 分成 k 个 子字符串 ,使得每个 子字符串 变成 半回文串 需要修改的字符数目最少。 请你返回一个整数,表示需要修改的 最少…...
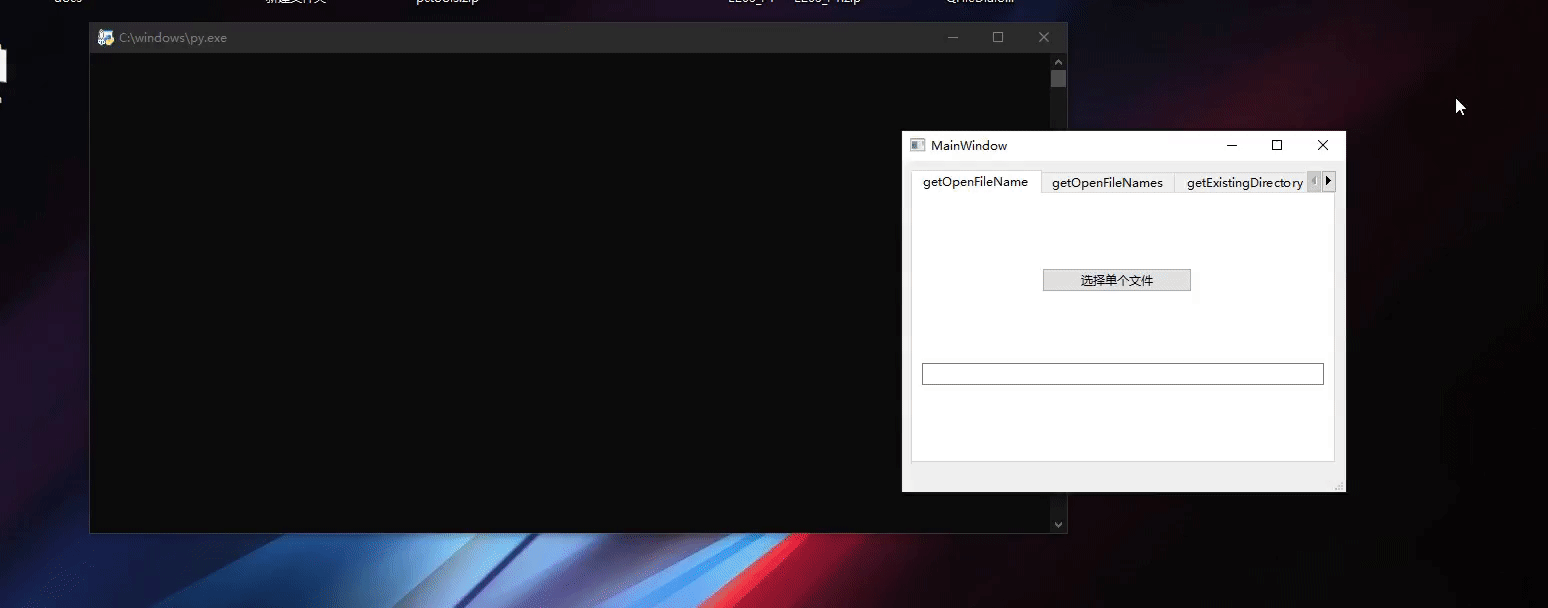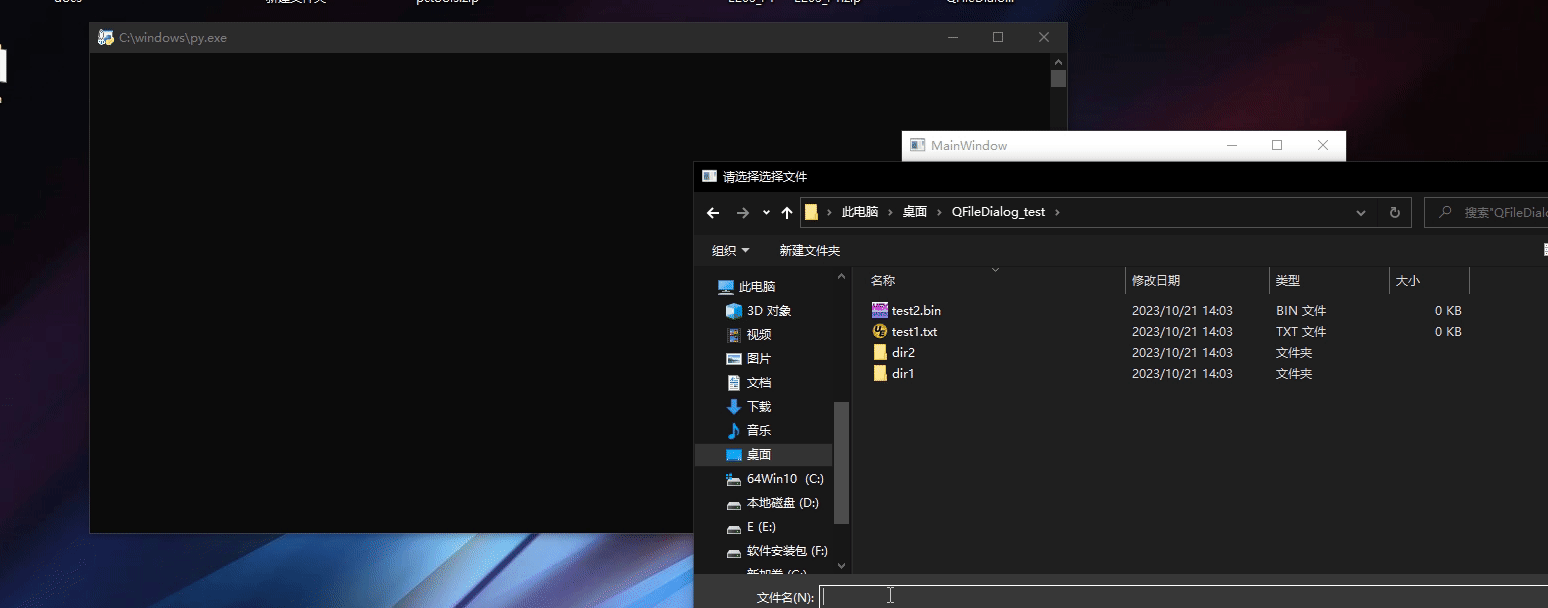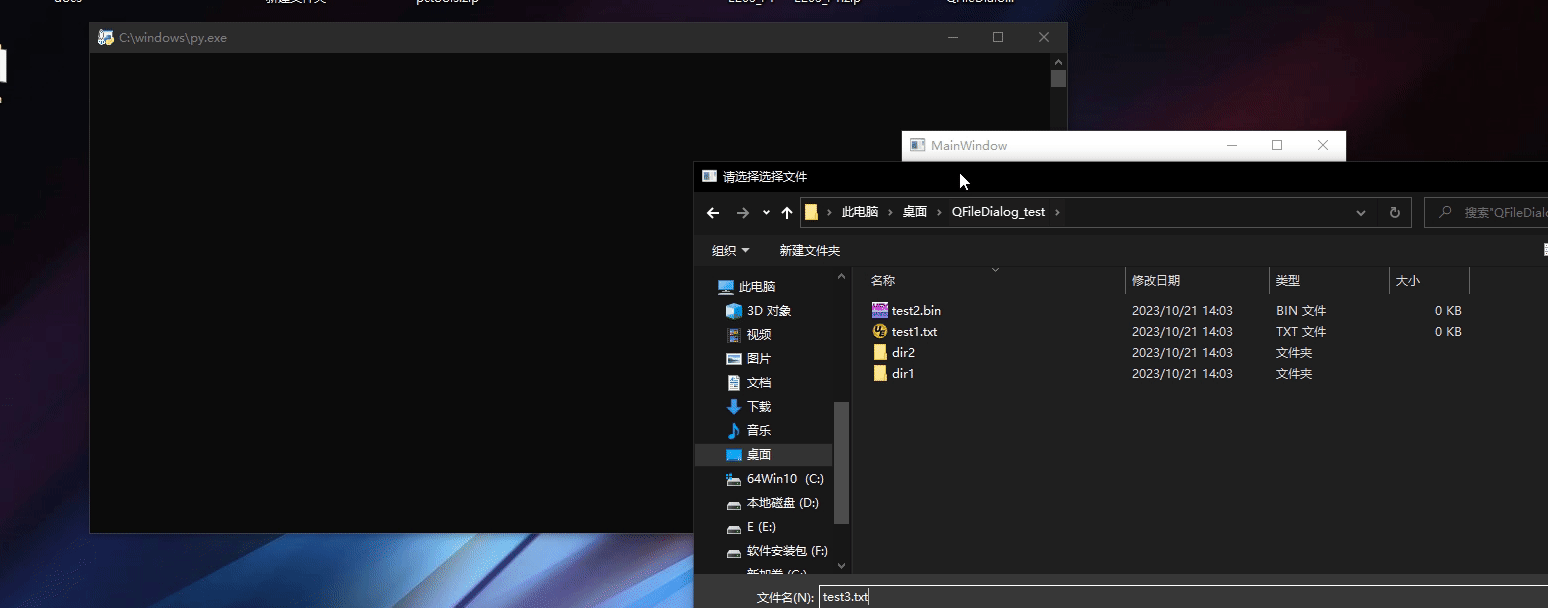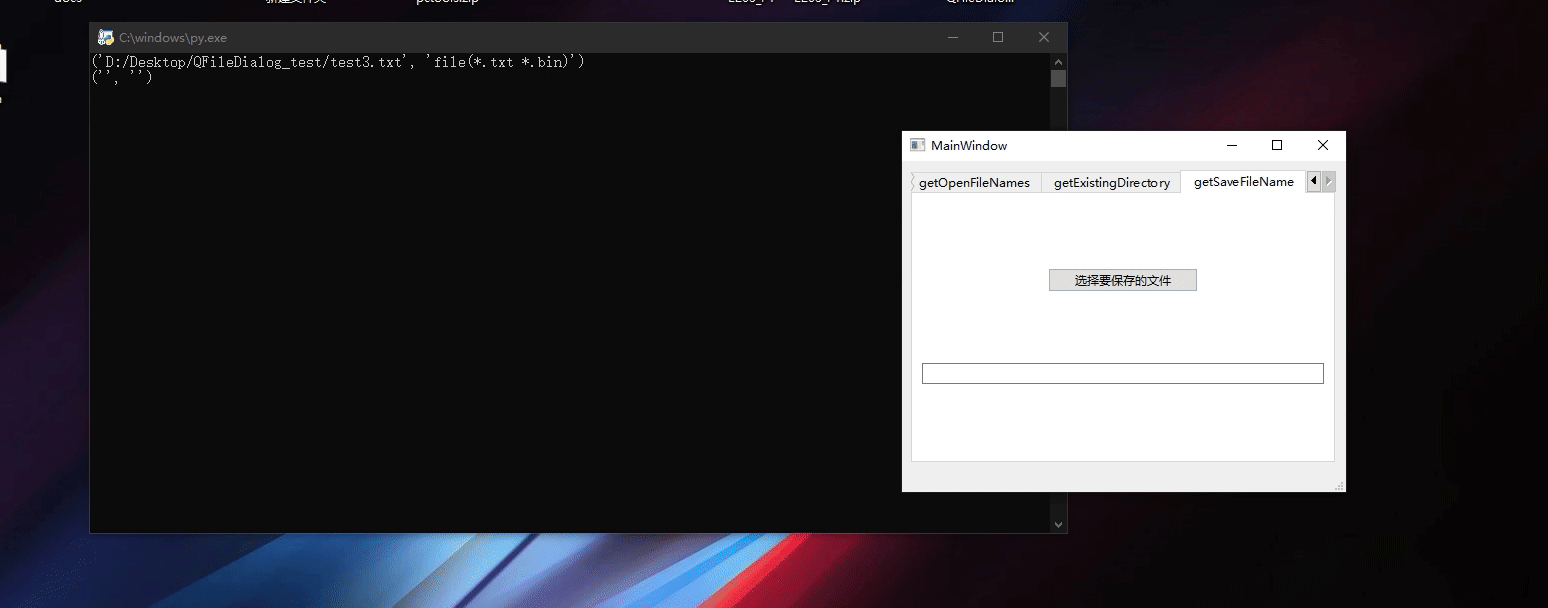
Pyside6 QFileDialog
Pyside6 QFileDialog Pyside6 QFileDialog常用函数getOpenFileNamegetOpenFileNamesgetExistingDirectorygetSaveFileName 程序界面程序主程序 Pyside6 QFileDialog提供了一个允许用户选择文件或目录的对话框。关于QFileDialog的使用可以参考下面的文档 https://doc.qt.io/qtfo…...

Leetcode1793. Maximum Score of a Good Subarray
给定一个数组和一个下标 k k k 子数组 ( i , j ) (i,j) (i,j)分数定义为 min ( n u m s [ i ] , n u m s [ i 1 ] , ⋯ , n u m s [ j ] ) ∗ ( j − i 1 ) \min\left(nums[i], nums[i 1],\cdots, nums[j]\right)*\left(j-i1\right) min(nums[i],nums[i1],⋯,nums[j])∗(…...
只需五步,在Linux安装chrome及chromedriver(CentOS)
一、安装Chrome 1)先执行命令下载chrome: wget https://dl.google.com/linux/direct/google-chrome-stable_current_x86_64.rpm2)安装chrome yum localinstall google-chrome-stable_current_x86_64.rpm看到下图中的Complete出现则代表安装…...
第01章-Java语言概述
目录 1 常见DOS命令 常用指令 相对路径与绝对路径 2 转义字符 3 安装JDK与配置环境变量 JDK与JRE JDK的版本 JDK的下载 JDK的安装 配置path环境变量 4 Java程序的编写与执行 5 Java注释 6 Java API文档 7 Java核心机制:JVM 1 常见DOS命令 DOS(…...

Spring | Spring Cache 缓存框架
Spring Cache 缓存框架: Spring Cache功能介绍Spring Cache的Maven依赖Spring Cache的常用注解EnableCaching注解CachePut注解Cacheable注解CacheEvict注解 Spring Cache功能介绍 Spring Cache是Spring的一个框架,实现了基于注解的缓存功能。只需简单加一…...
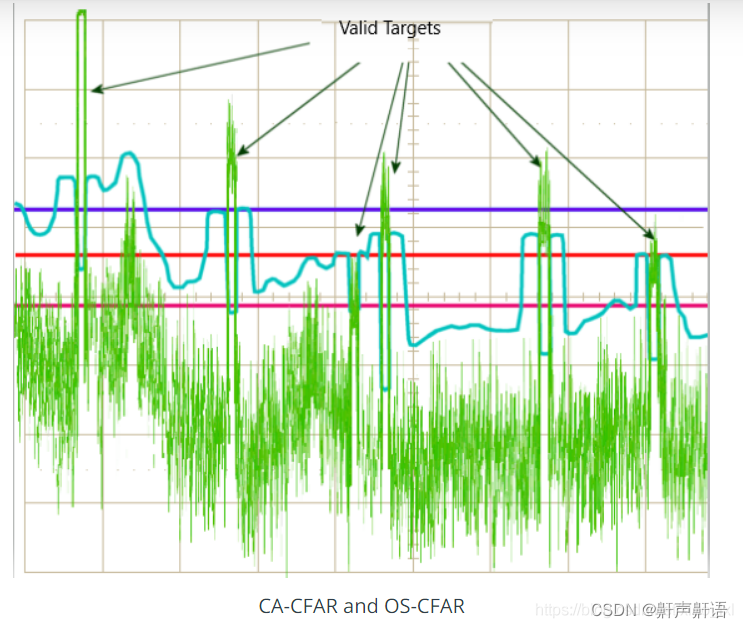
雷达开发的基本概念fft,cfar,以及Clutter, CFAR,AoA
CFAR Constant False-Alarm Rate的缩写。在雷达信号检测中,当外界干扰强度变化时,雷达能自动调整其灵敏度,使雷达的虚警概率保持不变。具有这种特性的接收机称为恒虚警接收机。雷达信号的检测总是在干扰背景下进行的,这些干扰包括…...

什么是大数据测试?有哪些类型?应该怎么测?
随着目前世界上各个国家使用大数据应用程序或应用大数据技术场景的数量呈指数增长,相应的,对于测试大数据应用时所需的知识与大数据测试工程师的需求也在同步增加。 针对大数据测试的相关技术已慢慢成为当下软件测试人员需要了解和掌握的一门通用技术。…...

03-垃圾收集策略与算法
垃圾收集策略与算法 程序计数器、虚拟机栈、本地方法栈随线程而生,也随线程而灭;栈帧随着方法的开始而入栈,随着方法的结束而出栈。这几个区域的内存分配和回收都具有确定性,在这几个区域内不需要过多考虑回收的问题,因…...

1.AUTOSAR的架构及方法论
在15、16年之前,AUTOSAR这个东西其实是被国内很多大的OEM或者供应商所排斥的。为什么?最主要的原因还是以前采用手写底层代码+应用层模型生成代码的方式进行开发。每个供应商或者OEM都有自己的软件规范或者技术壁垒,现在提个AUTOSAR想搞统一,用一个规范来收割汽车软件供应链…...

Kotlin中的List集合
在Kotlin中,List集合用于存储一组有序的元素。List集合分为可变集合(MutableList)和不可变集合(List)。本篇博客将分别介绍可变集合和不可变集合,并提供相关的API示例代码。 不可变集合(List&a…...

微信小程序WeUI项目weui-miniprogram如何运行起来?
微信小程序WeUI项目weui-miniprogram如何运行起来? 解决方法: 1、下载 https://github.com/wechat-miniprogram/weui-miniprogram 2、在项目根目录weui-miniprogram-master执行以下命令安装依赖: npm install 3、继续执行编译命令: npm r…...
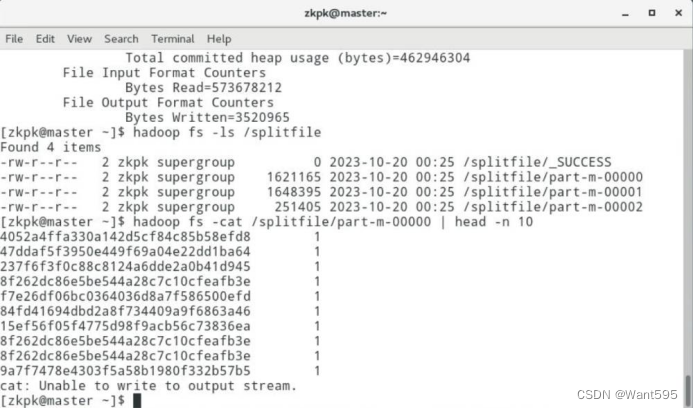
MapReduce编程:检索特定群体搜索记录和定义分片操作
文章目录 MapReduce 编程:检索特定群体搜索记录和定义分片操作一、实验目标二、实验要求及注意事项三、实验内容及步骤 附:系列文章 MapReduce 编程:检索特定群体搜索记录和定义分片操作 一、实验目标 熟悉MapReduce编程涉及的主要类和接口…...
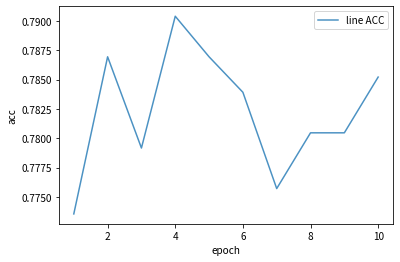
pytorch 入门 (四)案例二:人脸表情识别-VGG16实现
实战教案二:人脸表情识别-VGG16实现 本文为🔗小白入门Pytorch内部限免文章 参考本文所写记录性文章,请在文章开头注明以下内容,复制粘贴即可 🍨 本文为🔗小白入门Pytorch中的学习记录博客🍦 参…...

数据结构--线性表回顾
目录 线性表 1.定义 2.线性表的基本操作 3.顺序表的定义 3.1顺序表的实现--静态分配 3.2顺序表的实现--动态分配 4顺序表的插入、删除 4.1插入操作的时间复杂度 4.2顺序表的删除操作-时间复杂度 5 顺序表的查找 5.1按位查找 5.2 动态分配的方式 5.3按位查找的时间…...
ChatGPT(1):ChatGPT初识
1 ChatGPT原理 ChatGPT 是基于 GPT-3.5 架构的一个大型语言模型,它的工作原理涵盖了深度学习和自然语言处理技术。以下是 ChatGPT 的工作原理的一些关键要点: 神经网络架构:ChatGPT 的核心是一个深度神经网络,采用了变种的 Tran…...

PostgreSQL 插件 CREATE EXTENSION 原理
PostgreSQL 提供了丰富的数据库内核编程接口,允许开发者在不修改任何 Postgres 核心代码的情况下以插件的形式将自己的代码融入内核,扩展数据库功能。本文探究了 PostgreSQL 插件的一般源码组成,梳理插件的源码内容和实现方式;并介…...

3步颠覆微信数据管理:让87%用户告别聊天记录丢失烦恼
3步颠覆微信数据管理:让87%用户告别聊天记录丢失烦恼 【免费下载链接】WeChatMsg 提取微信聊天记录,将其导出成HTML、Word、CSV文档永久保存,对聊天记录进行分析生成年度聊天报告 项目地址: https://gitcode.com/GitHub_Trending/we/WeChat…...
)
从田间到大屏只要1.8秒:PHP异步任务队列+Redis流式渲染农业可视化看板(实测QPS 1270+)
第一章:从田间到大屏只要1.8秒:PHP异步任务队列Redis流式渲染农业可视化看板(实测QPS 1270)在智慧农业场景中,传感器集群每秒上报数千条温湿度、土壤EC值、光照强度等时序数据,传统同步渲染方式导致看板平均…...

高效管理Windows驱动:Driver Store Explorer实战指南
高效管理Windows驱动:Driver Store Explorer实战指南 【免费下载链接】DriverStoreExplorer Driver Store Explorer 项目地址: https://gitcode.com/gh_mirrors/dr/DriverStoreExplorer Driver Store Explorer(简称RAPR)是一款专业开源…...

一个简洁易用的 Delphi JSON 封装库,基于 System.JSON`单元封装,提供更直观的 API远
一、前言:什么是 OFA VQA 模型? OFA(One For All)是字节跳动提出的多模态预训练模型,支持视觉问答、图像描述、图像编辑等多种任务,其中视觉问答(VQA)是最常用的功能之一——输入一…...

短剧小程序系统选型指南:为什么1%加密+99%开源是最优解?
最近半年,短剧赛道持续火爆,不少开发者和创业者找我咨询短剧小程序的源码选型问题。我自己带团队从零到一搭建了一套日活过万的短剧平台,期间踩过SaaS的坑、全加密的坑、所谓“全开源”的坑,最终落地了一套1%核心加密99%全开源的方…...

Vibe Coding初体验之Trae CN
用了AI之后的真实感受就是时代真的变了,以前想都不敢想的,一句话居然就能生成想要的代码,同时内心又有一些紧迫感和思考,如何让自己保持竞争力,不被AI所淘汰,如何在AI时代体现人的价值。...

kill-doc:让文档下载效率提升90%的自动化工具
kill-doc:让文档下载效率提升90%的自动化工具 【免费下载链接】kill-doc 看到经常有小伙伴们需要下载一些免费文档,但是相关网站浏览体验不好各种广告,各种登录验证,需要很多步骤才能下载文档,该脚本就是为了解决您的烦…...
)
精益目视设计全指南 | 2026工厂目视化从0到1全流程(第一弹)
2026 年,精益生产早已成为制造企业降本增效、规范管理的核心抓手,而精益目视设计(精益目视化设计),正是精益生产、5S/6S 管理、TPM 设备管理落地的核心载体,被称为现场管理的 “无声管理者”。但绝大多数工…...

三个角度分析AI自动写文+自动发布自媒体矩阵提效实测
搞自媒体干久了,有谁没动过心思琢磨能不能让机器来帮忙写、帮忙发?尤其是你手头上攥着五六个账号,天天瞅着不同平台的规则、排版、发布时间的安排,脑袋都快给弄炸。最近我试了这么一个流程:用人工智能自动去写文章然后…...

SDMatte多GPU并行推理配置:提升企业级批量处理吞吐量
SDMatte多GPU并行推理配置:提升企业级批量处理吞吐量 1. 为什么需要多GPU并行推理 当企业需要处理大批量图片时,单张GPU往往难以满足需求。想象一下,你有一家电商公司,每天需要处理上万张商品图片的背景替换。如果只用一张GPU&a…...