HDFS集群NameNode高可用改造
文章目录
- 背景
- 高可用改造
- 方案实施
- 环境准备
- 配置文件修改
- 应用配置
- 集群状态验证
- 高可用验证
背景
假定目前有3台zookeeper服务器,分别为zk-01/02/03,DataNode服务器若干;
目前HDFS集群的Namenode没有高可用配置,Namenode和Secondary Namenode同时位于zk-03上,
且Secondary Namenode的作用是辅助Namenode恢复,并不是Namenode的高可用备份。
高可用改造
集群规划
| zk-01 | zk-02 | zk-03 |
|---|---|---|
| Active NameNode | Standby NameNode | |
| JournalNode | JournalNode | JournalNode |
| ZK Failover Controller | ZK Failover Controller |
Hadoop版本为3.0之前,仅支持启用单个Standby Namenode。Hadoop版本3.0后支持启用多个Standby Namenode。
方案实施
环境准备
- 关闭防火墙
- zk-01/02/03之间配置ssh免密登录
- 配置jdk环境变量
配置文件修改
-
hadoop-2.7.3/etc/hadoop/core-site.xml
<configuration><property><name>fs.defaultFS</name><!-- delete next line --><value>hdfs://zk-03:9000</value> <!-- delete --><!-- delete done --><!-- add next line --><value>hdfs://hacluster</value><!-- add done --></property><property><name>io.file.buffer.size</name><value>131072</value></property><property><name>hadoop.tmp.dir</name><value>/data/0/hadoop/hadoop/tmp</value></property><!-- add next 5 lines --><property><name>ha.zookeeper.quorum</name><value>zk-01:2181,zk-02:2181,zk-03:2181</value><description>指定zookeeper地址</description></property><!-- add done --> </configuration> -
hadoop-2.7.3/etc/hadoop/hdfs-site.xml
<configuration><!-- add next multi-lines --><property><name>dfs.nameservices</name><value>hacluster</value><description>指定hdfs的nameservice为ns,需要和core-site.xml中的保持一致</description></property><property><name>dfs.ha.namenodes.hacluster</name><value>namenode1,namenode2</value><description>hacluster下面有两个NameNode</description></property><property><name>dfs.namenode.rpc-address.hacluster.namenode1</name><value>zk-01:9000</value></property><property><name>dfs.namenode.http-address.hacluster.namenode1</name><value>zk-01:50070</value></property><property><name>dfs.namenode.rpc-address.hacluster.namenode2</name><value>zk-02:9000</value></property><property><name>dfs.namenode.http-address.hacluster.namenode2</name><value>zk-02:50070</value></property><property><name>dfs.ha.fencing.methods</name><value>sshfence</value><description>配置隔离机制,同一时刻只有一个Namenode对外响应</description></property><property><name>dfs.ha.fencing.ssh.private-key-files</name><value>/home/hadoop/.ssh/id_rsa</value><description>使用隔离机制时需要ssh免登陆</description></property><property><name>dfs.ha.automatic-failover.enabled</name><value>true</value><description>开启NameNode故障时自动切换</description></property><property><name>dfs.client.failover.proxy.provider.hacluster</name><value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value><description>配置失败自动切换实现方式</description></property><property><name>dfs.namenode.shared.edits.dir</name><value>qjournal://zk-01:8485;zk-02:8485;zk-03:8485/hacluster</value><description>指定NameNode的元数据在JournalNode上的存放位置</description></property><property><name>dfs.journalnode.edits.dir</name><value>/data/0/hadoop/hadoop/journal</value><description>指定JournalNode在本地磁盘存放数据的位置</description></property><!-- add done --><property><name>dfs.replication</name><value>2</value></property><property><name>dfs.namenode.name.dir</name><value>/data/0/hadoop/hadoop/name</value></property><property><name>dfs.blocksize</name><value>268435456</value></property><property><name>dfs.namenode.handler.count</name><value>100</value></property><property><name>dfs.datanode.data.dir</name> <value>/data/0/hadoop/hadoop/data,/data/1/hadoop/hadoop/data,/data/2/hadoop/hadoop/data,/data/3/hadoop/hadoop/data,/data/4/hadoop/hadoop/data,/data/5/hadoop/hadoop/data,/data/6/hadoop/hadoop/data,/data/7/hadoop/hadoop/data,/data/8/hadoop/hadoop/data,/data/9/hadoop/hadoop/data,/data/10/hadoop/hadoop/data,/data/11/hadoop/hadoop/data</value></property> </configuration>
应用配置
- 登录zk-03
$ scp -r /home/hadoop/hadoop-2.7.3 zk-02:/home/hadoop/
$ scp -r /home/hadoop/hadoop-2.7.3 zk-01:/home/hadoop/
# 停止现有HDFS集群的服务
$ hdfs/sbin/stop-dfs.sh
- zk-01/02/03: 全部启动JournalNode
$ hdfs/sbin/hadoop-daemon.sh start journalnode
- zk-01: 初始化并启动namenode1、zkfc
# 初始化并启动namenode1
$ hdfs/bin/hdfs namenode -format
$ hdfs/bin/hdfs namenode -initializeSharedEdits
$ hdfs/sbin/hadoop-daemon.sh start namenode
# 在ZK中初始化ha集群的信息
$ hdfs/bin/hdfs zkfc -formatZK
- zk-02:启动namenode2、zkfc
# 同步zk01上namenode的元数据信息并启动namenode2
$ hdfs/bin/hdfs namenode -bootstrapStandby
$ hdfs/sbin/hadoop-daemon.sh start namenode
# 在ZK02中同步ha集群的信息
$ hdfs/bin/hdfs zkfc -formatZK
- zk-01: 启动集群中其他服务,包括datanode
$ hdfs/sbin/start-dfs.sh
集群状态验证
- 登录zk-01/02,分别执行
jps, 结果中应存在:- PID1 JournalNode
- PID2 NameNode
- PID3 DFSZKFailoverController
- 若不存在JournalNode进程则执行:
sbin/hadoop-daemon.sh start journalnode - 若不存在DFSZKFailoverController进程则执行:
sbin/hadoop-daemon.sh start zkfc - 若不存在NameNode进程则执行:
sbin/hadoop-daemon.sh start namenode
- 登录zk-03,执行
jps,结果中应存在:- PID JournalNode
-
若不存在JournalNode进程则执行:
sbin/hadoop-daemon.sh start journalnode
- 在任意DataNode服务器上,执行
jps,结果中应存在:- PID1 DataNode
-
若不存在DataNode进程则执行:
sbin/hadoop-daemon.sh start datanode
高可用验证
-
登录zk-01,查看namenode1的状态:
bin/hdfs haadmin -getServiceState namenode1,输出结果应为active;若上述结果为standby,可以执行如下命令将主namenode切换为namenode1:
bin/hdfs haadmin -transitionToActive --forcemanual namenode1再次执行命令查看namenode1和namenode2的状态:
bin/hdfs haadmin -getServiceState namenode1,输出应为active;bin/hdfs haadmin -getServiceState namenode2,输出应为standby。 -
登录zk-01,停止namenode1:
bin/hdfs --daemon stop namenode
zkfc进程应自动随之停止,执行jps,结果中不存在NameNode和DFSZKFailoverController。
查看namenode2的状态:
bin/hdfs haadmin -getServiceState namenode2,结果应为active。 -
重新启动namenode1:
bin/hdfs --daemon start namenode
查看namenode1的状态:bin/hdfs haadmin -getServiceState namenode1,结果应为standby。此时可以使用第1步中切换主节点的命令将主节点切换到namenode1。
相关文章:

HDFS集群NameNode高可用改造
文章目录 背景高可用改造方案实施环境准备配置文件修改应用配置集群状态验证高可用验证 背景 假定目前有3台zookeeper服务器,分别为zk-01/02/03,DataNode服务器若干; 目前HDFS集群的Namenode没有高可用配置,Namenode和Secondary…...
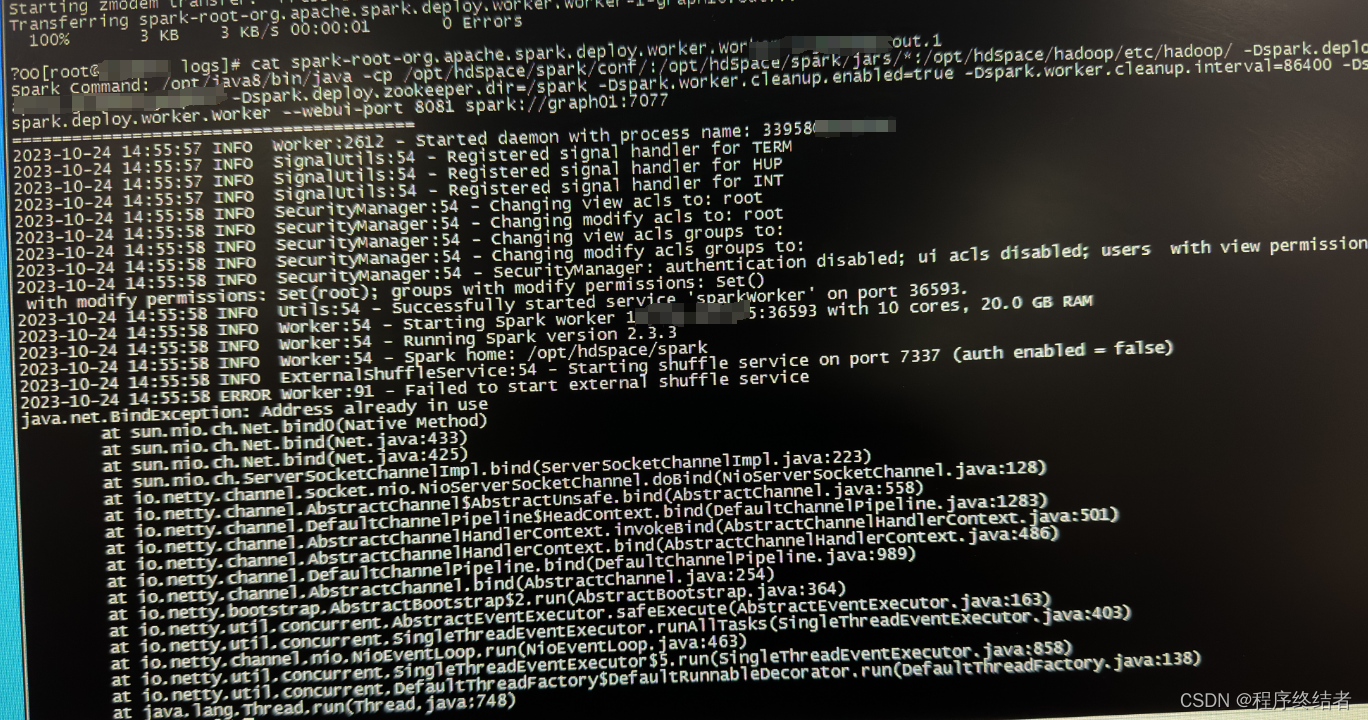
Spark集群中一个Worker启动失败的排错记录
文章目录 1 检查失败节点worker启动日志2 检查正常节点worker启动日志3 查看正常节点spark环境配置4 又出现新的ERROR4.1 报错解释4.2 报错解决思路4.3 端口报错解决操作 集群下电停机后再次启动时,发现其中一台节点的worker启动失败。 1 检查失败节点worker启动日…...

Mysql的JDBC知识点
什么是JDBC JDBC(Java DataBase Connectivity) 称为Java数据库连接,它是一种用于数据库访问的应用程序API,由一组用Java语言编写的类和接口组成,有了JDBC就可以用统一的语法对多种关系数据库进行访问,而不用担心其数据库操作语…...
git的实际操作
文章目录 删除GitHub上的某个文件夹克隆仓库到另一个仓库 删除GitHub上的某个文件夹 克隆仓库到另一个仓库 从原地址克隆一份裸板仓库 –bare创建的克隆版本库都不包含工作区,直接就是版本库的内容,这样的版本库称为裸版本库 git clone --bare ****(原…...

数据结构零基础C语言版 严蔚敏-线性表、顺序表
二、顺序表和链表 1. 线性表 线性表(linear list)是n个具有相同特性的数据元素的有限序列。线性表是一种在实际中广泛使用的数据结构,常见的线性表:顺序表、链表、栈、队列、字符串...... 线性表在逻辑上是线性结构,…...
Keil uVision 5 MDK版软件安装包下载及安装教程(最详细图文教程)
目录 一.简介 二.安装步骤 软件:Keil uvision5版本:MDKv518语言:中文/英文大小:377.01M安装环境:Win11/Win10/Win8/Win7硬件要求:CPU2.59GHz 内存4G(或更高)下载通道①百度网盘丨64位下载链接…...
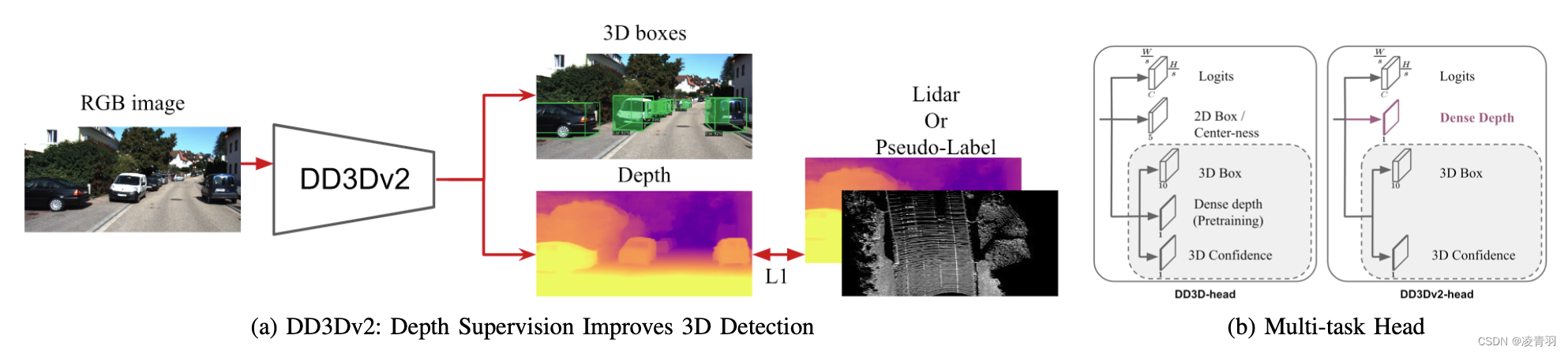
单目3D目标检测[基于深度辅助篇]
基于深度辅助的方法 1. Pseudo-LiDAR Pseudo-LiDAR from Visual Depth Estimation: Bridging the Gap in 3D Object Detection for Autonomous Driving康奈尔大学https://zhuanlan.zhihu.com/p/52803631 首先利用DRON或PSMNET从单目 (Monocular)或双目 (Stereo)图像获取对应的…...
Ubuntu20.04下安装MySQL8环境
Ubuntu20.04下安装MySQL8环境 1.下载MySQL客户端和服务器2.配置MySQL3.测试MySQL4.设置MySQL服务开机自启动5.修改root密码MySQL数据库基本使用启动MySQL数据库服务重启MySQL数据库服务停止MySQL数据库服务查看MySQL运行状态设置MySQL服务开机自启动停止MySQL服务开机自启动MyS…...

html鼠标悬停图片放大
要在HTML中实现鼠标悬停时图片放大的效果,你可以使用CSS和JavaScript来完成。下面是一个简单的示例: 首先,创建一个HTML文档,包含一张图片和相应的CSS和JavaScript代码。 <!DOCTYPE html> <html lang"en">…...

基于hugging face的autogptq量化实践
1.量化并保存到本地的 #导入库: from transformers import AutoModelForCausalLM, AutoTokenizer, GPTQConfig model_id "facebook/opt-125m"quantization_config GPTQConfig(bits4,group_size128,dataset"c4",desc_actFalse, )tokenizer A…...

MySQL2:MySQL中一条查询SQL是如何执行的?
MySQL2:MySQL中一条查询SQL是如何执行的? MySQL中一条查询SQL是如何执行的?1.连接怎么查看MySQL当前有多少个连接?思考:为什么连接数是查看线程?客户端的连接和服务端的线程有什么关系?MySQL参数…...
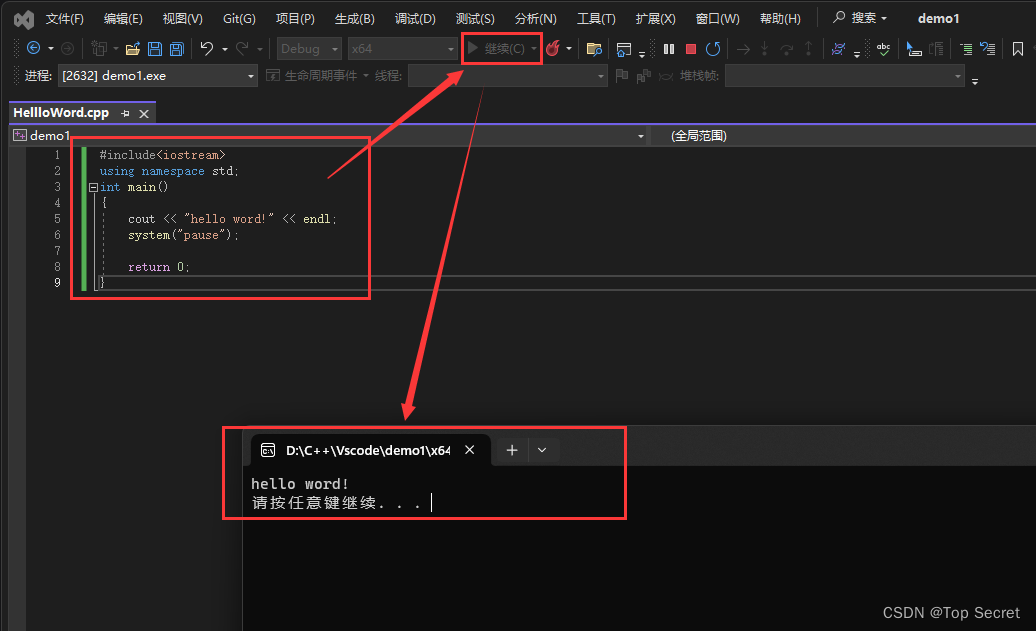
C++入门01—从hello word!开始
1.第一个C程序 1.1 创建项目 第一次使用Visual Studio时: 1.2 创建文件 1.3 编写代码 编写第一个代码: #include<iostream> using namespace std; int main() {cout << "hello word!" << endl;system("pause"…...
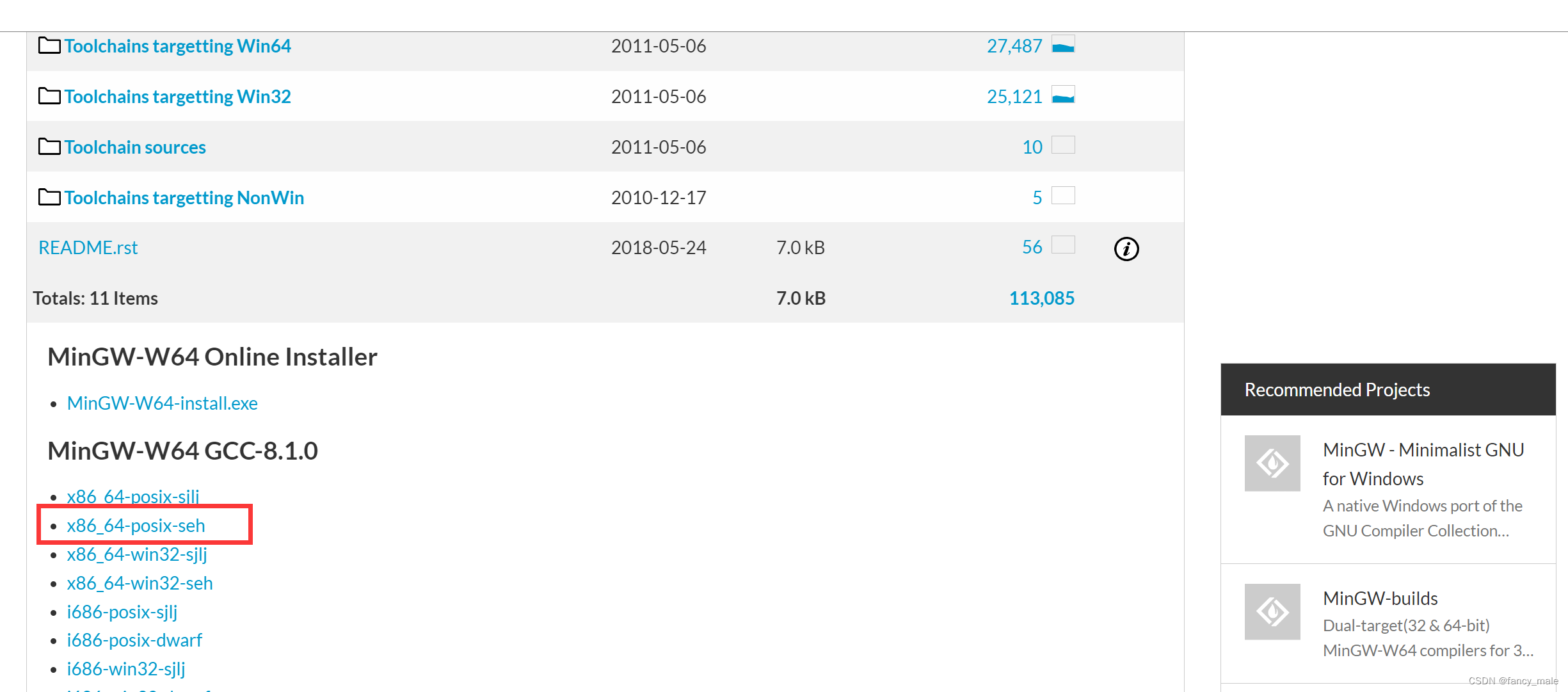
Mingw下载---运行vscodeC++文件
下载 下载网址: https://sourceforge.net/projects/mingw-w64/files/mingw-w64/mingw-w64-release/ 翻到最下面,选择win64的安装: 下载完,解压到没有空格和中文字符的路径。不然在vscode中运行不了C代码。...

数据安全与PostgreSQL:最佳保护策略
在当今数字化时代,数据安全成为了企业不可或缺的一环。特别是对于使用数据库管理系统(DBMS)的组织来说,确保数据的完整性、保密性和可用性至关重要。在众多DBMS中,PostgreSQL作为一个强大而灵活的开源数据库系统&#…...

火山引擎实时、低延时拥塞控制算法的优化实践
摘要 火山引擎智能拥塞控制算法 VICC(Volcano Intelligent Congestion Control)是一种自适应的拥塞控制算法,旨在解决全球不同网络环境下,不同音视频应用对带宽利用率和延时的差异化要求。它结合了传统拥塞控制算法(如…...

adb设备调试常用命令
自从工作越来越忙后,越来越懒得写文章了,趁着1024程序员节,仪式性地写篇文章,分享一下最近调试设备经常用到的adb指令~ 1.查看应用内存占用 1.1 dumpsys meminfo package dumpsys是查看系统服务信息的一个常用指令,可…...

ubuntu下Docker的简单使用并利用主机显示
首先分享一个docker镜像的网站:https://hub.docker.com/search?q 这个网站里面有很多配置好的镜像,可以直接拉取。 下面介绍一下docker的安装和使用。 1、docker得到安装: sudo apt-get install docker 2、docker拉取一个镜像到本地,这里我…...

第12章 PyTorch图像分割代码框架-1
从本章开始,本书将会进行深度学习图像分割的实战阶段。PyTorch作为目前最为流行的一款深度学习计算框架,在计算机视觉和图像分割任务中已经广泛使用。本章将介绍基于PyTorch的深度学习图像分割代码框架,在总体框架的基础上,基于PA…...

2023CSPJ 旅游巴士 —— dijkstra
This way 题意: 给你一个有向图,1号点为起点,n为终点。你可以在k的倍数的时间点在起点开始,每条边的边长为1,同时,每条边有一个限定时间ai,表示你必须在大于等于ai的时间点才能走这条边。 …...
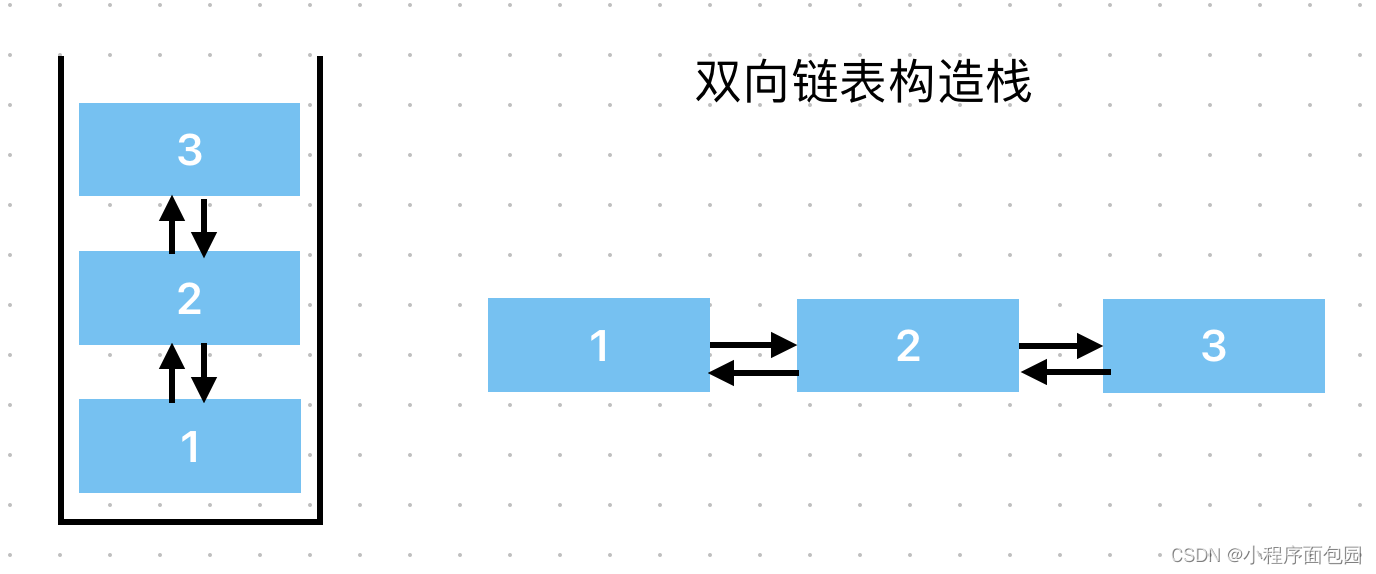
数据结构之栈的讲解(源代码+图解+习题)
我们在学习过顺序表和链表之后,了解了使用数组存储数据,使用结构体来存储数据和有关的指针,这些都是底层的东西,链表是靠指针的链接,顺序表是靠数组的下标才能得以实现增删查改。众多数据结构其实底层都离不开数组&…...

用快马ai五分钟生成java学习路线可视化原型,清晰规划你的编程进阶之路
今天想和大家分享一个特别实用的Java学习路线可视化工具的开发过程。作为一个Java初学者,我经常被各种知识点搞得晕头转向,直到发现用InsCode(快马)平台可以快速搭建一个学习路线图,整个开发过程只用了不到半小时,效果却出奇地好。…...

开源电子书工具:如何用鸿蒙系统打造专属个性化阅读空间
开源电子书工具:如何用鸿蒙系统打造专属个性化阅读空间 【免费下载链接】legado-Harmony 开源阅读鸿蒙版仓库 项目地址: https://gitcode.com/gh_mirrors/le/legado-Harmony 你是否曾因阅读应用充斥广告而烦躁?是否渴望完全掌控自己的阅读体验&am…...

ollama-QwQ-32B模型微调+OpenClaw:个性化自动化助手训练实录
ollama-QwQ-32B模型微调OpenClaw:个性化自动化助手训练实录 1. 为什么需要个性化AI助手? 去年处理法律文书时,我发现通用大模型对专业术语的理解总差那么点意思。一个简单的"请整理这份合同中的关键条款"指令,模型返回…...

深入解析Cache工作原理与多核一致性机制
深入理解Cache工作原理与技术实现1. 计算机体系中的Cache基础1.1 Cache存在的必要性现代计算机系统中,处理器性能与存储器访问性能之间存在显著差距。从历史发展数据来看,CPU计算性能每18个月翻一番(遵循摩尔定律),而D…...

别再一条条Update了!MyBatis批量更新数据,用这个Case When写法性能翻倍
MyBatis批量更新性能优化实战:告别低效循环,拥抱CASE WHEN 每次看到代码里用循环一条条执行update语句,我的数据库性能监控图表就会剧烈波动——这简直是DBA的噩梦。上周排查一个后台任务卡死问题,发现同事在处理5万条数据更新时&…...

冒险岛V128单机版服务端魔改指南:从基础搭建到自定义任务/装备修改
冒险岛V128单机版深度定制指南:从零构建个性化游戏世界 在数字娱乐的黄金时代,怀旧游戏焕发新生已成为一种文化现象。作为横版卷轴网游的经典之作,冒险岛凭借其独特的艺术风格和社交属性,至今仍拥有大量忠实玩家。而单机版的出现&…...

全格式文档智能处理:AnythingLLM的多模态知识管理解决方案
全格式文档智能处理:AnythingLLM的多模态知识管理解决方案 【免费下载链接】anything-llm 这是一个全栈应用程序,可以将任何文档、资源(如网址链接、音频、视频)或内容片段转换为上下文,以便任何大语言模型(…...

nRF51822 RTC1深度睡眠唤醒与80μA低功耗优化
1. nRF51822低功耗唤醒系统深度解析:RTC1驱动的深度睡眠唤醒机制与80μA电流优化实践1.1 项目背景与工程痛点定位nRF51_WakeUp项目聚焦于nRF51822 SoC在超低功耗场景下的精准唤醒能力构建,其核心目标是通过RTC1(Real-Time Counter 1ÿ…...

多项式朴素贝叶斯
多项式朴素贝叶斯(二分类) 题意 实现一个 Multinomial Naive Bayes 二分类器。 train:二维列表,每行最后一列为标签 y \in \{0,1\},其余列为非负整数词频test:二维列表,仅包含词频特征ÿ…...

GaussDB JDBC SSL加密全攻略:从零配置到生产环境最佳实践
GaussDB JDBC SSL加密全攻略:从零配置到生产环境最佳实践 在数据驱动的时代,数据库连接的安全性已成为企业级应用不可忽视的生命线。作为华为云推出的分布式关系型数据库,GaussDB在金融、政务等对安全性要求极高的场景中广泛应用。而JDBC作为…...