一键同步,无处不在的书签体验:探索多电脑Chrome书签同步插件
说在前面
平时大家都是怎么管理自己的浏览器书签数据的呢?有没有过公司和家里的电脑浏览器书签不同步的情况?有没有过电脑突然坏了但书签数据没有导出,导致书签数据丢失了?解决这些问题的方法有很多,我选择自己写个chrome插件来做书签同步。
实现方案
通过 gitee 来做存取
建一个私有仓库来保存自己的书签目录信息,需要同步的时候再获取 gitee 仓库的书签目录到本地。这样不用自己写服务端对数据进行存储,减少了很多不必要的开发工作。
实现步骤
一、准备工作
1、新建 gitee 仓库
直接在gitee上新建仓库即可。
我们不想要书签信息公开,所以选择勾选上私有:
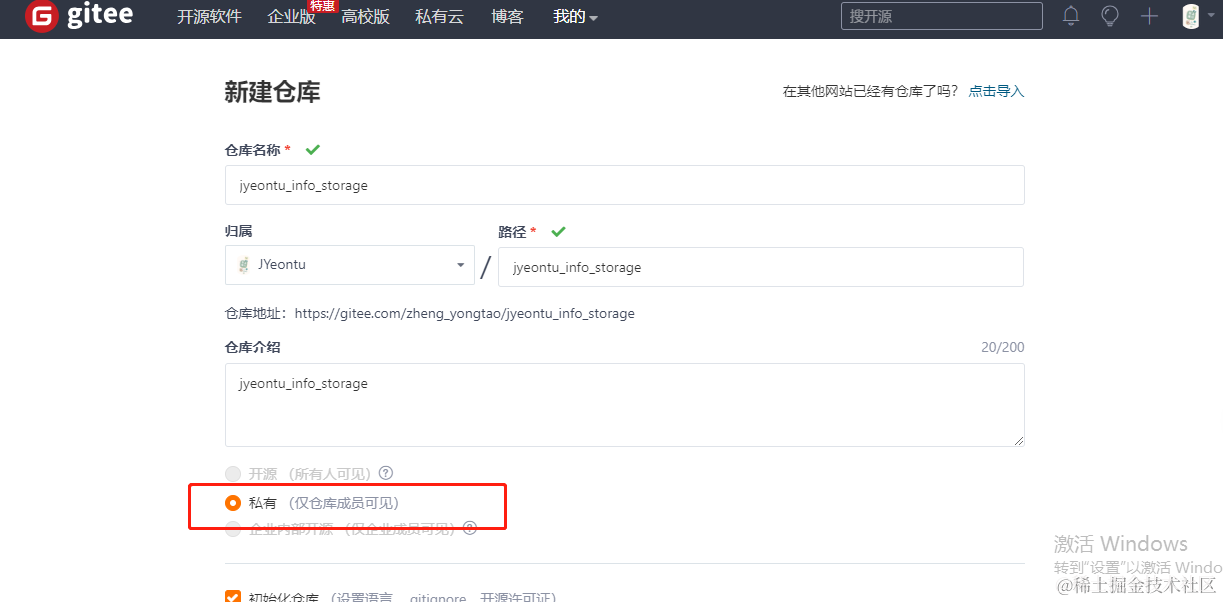
创建完的初始仓库是这样的:
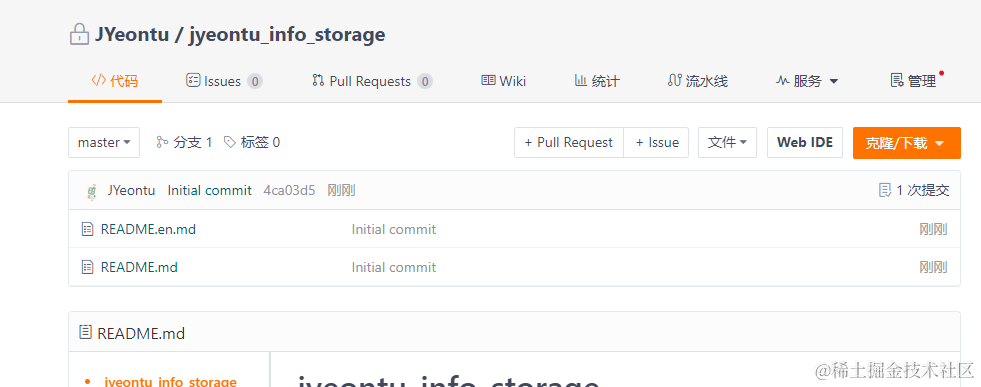
我们再新增一个目录,用于存放和书签相关的文件:
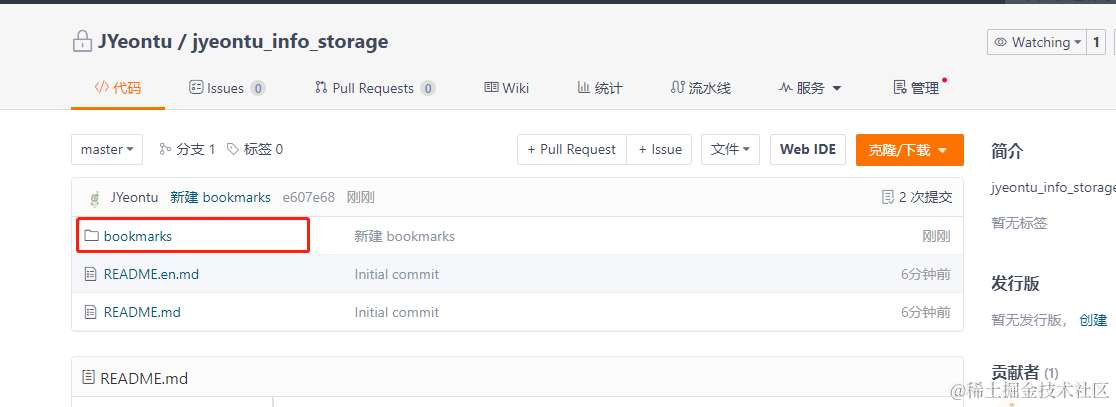
在该目录下新增一个文件,用于保存书签导出的数据:
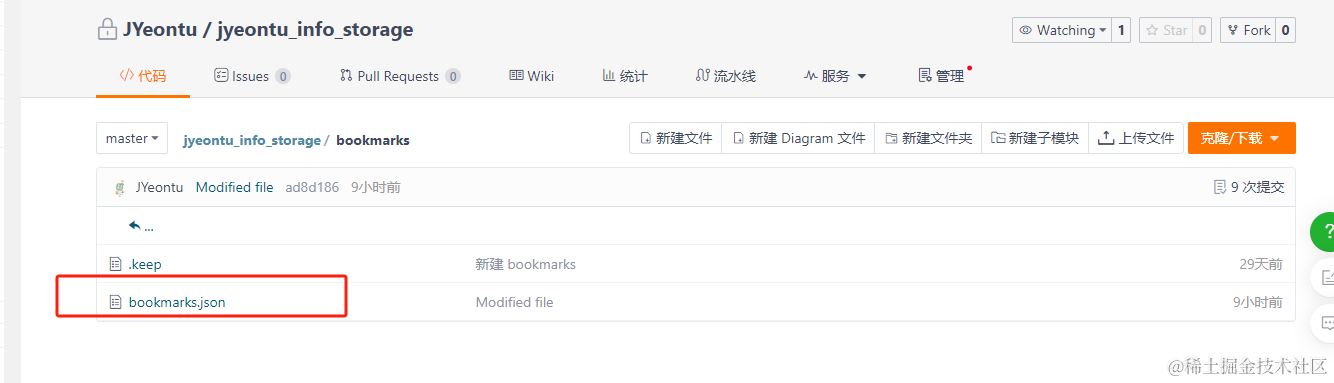
二、插件编写
完成前面的准备工作,新建完 gitee 仓库之后,我们便可以正式开始进行插件的编写了。
1、插件模板
- 安装依赖
jyeontu
npm i -g jyeontu
- 获取模板
jyeontu create
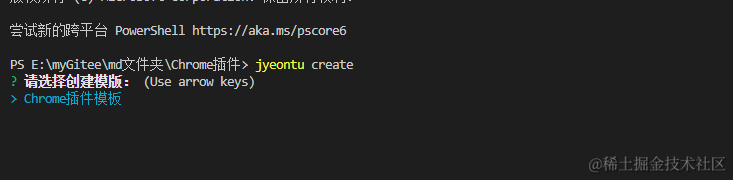
- 生成模板
根据提示输入相关信息即可

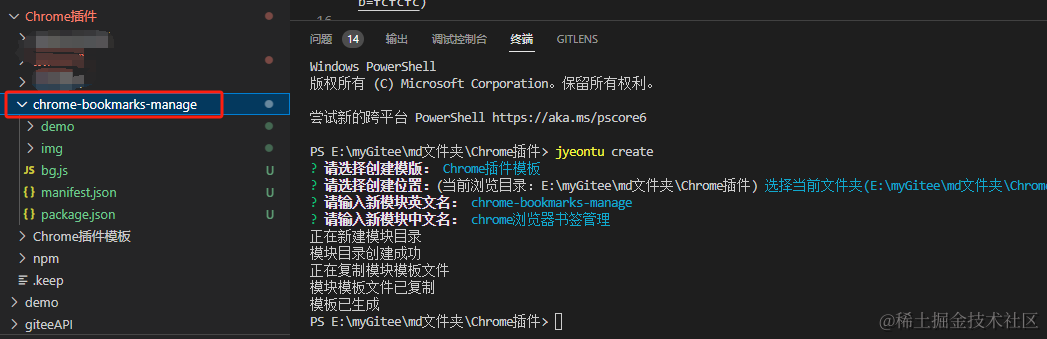
2、giteeAPI
我们可以通过 giteeAPI 来对 gitee 仓库进行操作,下面是 giteeAPI 的操作文档:
https://gitee.com/api/v5/swagger#/getV5ReposOwnerRepoStargazers?ex=no
获取gitee指定文件的内容
我们可以通过下面代码来获取到gitee指定仓库指定文件的内容:
async function fetchFileContent(apiUrl, accessToken) {const response = await fetch(apiUrl, {headers: {Authorization: "token " + accessToken,},});const fileData = await response.json();return fileData.content;
}export async function getFile(gitInfo) {const accessToken = gitInfo.token;const apiUrl ="https://gitee.com/api/v5/repos/" +gitInfo.owner +"/" +gitInfo.repo +"/contents/" +gitInfo.filePath;const fileContent = await fetchFileContent(apiUrl, accessToken);const decodedContent = atob(fileContent); // 解码Base64编码的文件内容const decoder = new TextDecoder();const decodedData = decoder.decode(new Uint8Array([...decodedContent].map((char) => char.charCodeAt(0))));return JSON.parse(decodedData);
}
修改指定文件的内容数据
我们需要先获取到文件,拿到文件的sha值,后面通过sha来对文件进行编辑操作。
btoa函数只能处理Latin1字符范围内的字符串,对超出Latin1字符范围的字符串进行Base64编码,我们需要进行以下操作,使用TextEncoder对象来将字符串转换为字节数组,然后再进行Base64编码。
async function fetchFileContent(apiUrl, accessToken) {const response = await fetch(apiUrl, {headers: {Authorization: "token " + accessToken,},});const fileData = await response.json();return fileData.content;
}
async function getDecodedContent(content) {const decodedContent = atob(content); // 解码Base64编码的文件内容const decoder = new TextDecoder();const decodedData = decoder.decode(new Uint8Array([...decodedContent].map((char) => char.charCodeAt(0))));return JSON.parse(decodedData);
}
async function putFileContent(apiUrl, accessToken, encodedContent, sha) {const commitData = {access_token: accessToken,content: encodedContent,message: "Modified file",sha: sha,};const putResponse = await fetch(apiUrl, {method: "PUT",headers: {"Content-Type": "application/json",Authorization: "token " + accessToken,},body: JSON.stringify(commitData),});if (putResponse.ok) {console.log("File modified successfully.");} else {console.error("Failed to modify file.");}
}
export async function modifyFile(gitInfo, modifiedContent) {const accessToken = gitInfo.token;const apiUrl ="https://gitee.com/api/v5/repos/" +gitInfo.owner +"/" +gitInfo.repo +"/contents/" +gitInfo.filePath;try {const fileContent = await fetchFileContent(apiUrl, accessToken);const content = await getDecodedContent(fileContent);modifiedContent = mergeBookmarks(content, modifiedContent);modifiedContent = JSON.stringify(modifiedContent);const encoder = new TextEncoder();const data = encoder.encode(modifiedContent);const encodedContent = btoa(String.fromCharCode.apply(null, new Uint8Array(data)));await putFileContent(apiUrl, accessToken, encodedContent, fileContent.sha);} catch (error) {console.error("An error occurred:", error);}
}
3、indexDb存取
我们不希望每次打开都需要去重新填写gitee仓库的相关信息,所以这里我们使用indexDb来对gitee仓库的相关信息做一个保存。
export class IndexedDB {constructor(databaseName, storeName) {this.databaseName = databaseName;this.storeName = storeName;this.db = null;}open() {return new Promise((resolve, reject) => {const request = window.indexedDB.open(this.databaseName);request.onerror = () => {reject(new Error("Failed to open database"));};request.onsuccess = () => {this.db = request.result;resolve();};request.onupgradeneeded = (event) => {this.db = event.target.result;if (!this.db.objectStoreNames.contains(this.storeName)) {this.db.createObjectStore(this.storeName, {keyPath: "id",autoIncrement: true,});}};});}createDatabase() {return new Promise((resolve, reject) => {const request = window.indexedDB.open(this.databaseName);request.onerror = () => {reject(new Error("Failed to create database"));};request.onsuccess = () => {this.db = request.result;this.db.close();resolve();};request.onupgradeneeded = (event) => {this.db = event.target.result;if (!this.db.objectStoreNames.contains(this.storeName)) {this.db.createObjectStore(this.storeName, {keyPath: "id",autoIncrement: true,});}this.db.close();resolve();};});}close() {if (this.db) {this.db.close();this.db = null;}}add(data) {return new Promise((resolve, reject) => {const transaction = this.db.transaction(this.storeName, "readwrite");const objectStore = transaction.objectStore(this.storeName);const request = objectStore.add(data);request.onsuccess = () => {resolve(request.result);};request.onerror = () => {reject(new Error("Failed to add data"));};});}getAll() {return new Promise((resolve, reject) => {const transaction = this.db.transaction(this.storeName, "readonly");const objectStore = transaction.objectStore(this.storeName);const request = objectStore.getAll();request.onsuccess = () => {resolve(request.result);};request.onerror = () => {reject(new Error("Failed to get data"));};});}getById(id) {return new Promise((resolve, reject) => {const transaction = this.db.transaction(this.storeName, "readonly");const objectStore = transaction.objectStore(this.storeName);const request = objectStore.get(id);request.onsuccess = () => {resolve(request.result);};request.onerror = () => {reject(new Error("Failed to get data"));};});}delete(id) {return new Promise((resolve, reject) => {const transaction = this.db.transaction(this.storeName, "readwrite");const objectStore = transaction.objectStore(this.storeName);const request = objectStore.delete(id);request.onsuccess = () => {resolve();};request.onerror = () => {reject(new Error("Failed to delete data"));};});}update(id, newData) {return new Promise((resolve, reject) => {const transaction = this.db.transaction(this.storeName, "readwrite");const objectStore = transaction.objectStore(this.storeName);const getRequest = objectStore.get(id);getRequest.onsuccess = () => {const oldData = getRequest.result;if (!oldData) {const addRequest = objectStore.add({ ...newData, id });addRequest.onsuccess = () => {resolve({ ...newData, id });};addRequest.onerror = () => {reject(new Error("Failed to add data"));};} else {const mergedData = { ...oldData, ...newData };const putRequest = objectStore.put(mergedData);putRequest.onsuccess = () => {resolve(mergedData);};putRequest.onerror = () => {reject(new Error("Failed to update data"));};}};getRequest.onerror = () => {reject(new Error("Failed to get data"));};});}
}
4、书签存取
获取chrome书签
要获取 Chrome 浏览器的书签目录,我们可以使用 Chrome 浏览器提供的 API——chrome.bookmarks。下面是一个示例代码,演示如何使用chrome.bookmarks API 获取 Chrome 浏览器的书签目录:
export const getBookmarks = () => {return new Promise((resolve) => {chrome.bookmarks.getTree(function (bookmarkTreeNodes) {resolve(bookmarkTreeNodes);});});
};
在上述代码中,我们首先使用chrome.bookmarks.getTree()方法获取 Chrome 浏览器的书签目录树。
请注意,要使用chrome.bookmarks API,你需要在你的 Chrome 插件中声明"bookmarks"权限。具体来说,在插件清单文件(manifest.json)中添加以下内容:
{"manifest_version": 2,"name": "你的插件名称","version": "1.0","permissions": ["bookmarks"],"background": {"scripts": ["bg.js"]}
}
在上述代码中,我们在"permissions"字段中声明了"bookmarks"权限,以便我们可以使用chrome.bookmarks API。同时,在"background"字段中指定了一个后台脚本(bg.js),以便我们在后台执行上述代码。
删除chrome浏览器书签
导入书签前我们需要先清除一下当前浏览器的书签,通过chrome.bookmarks.removeTree可以删除书签节点。
export function removeBookmarks(bookmarkTreeNodes) {// 遍历书签树,删除所有的书签function traverseBookmarks(bookmarkNodes) {for (const node of bookmarkNodes) {if (node.children) {traverseBookmarks(node.children);}// 删除书签节点chrome.bookmarks.removeTree(node.id);}}traverseBookmarks(bookmarkTreeNodes);
}
导入书签
使用chrome.bookmarks.create来新建书签。
export function importBookmarks(bookmarkTreeNodes) {// 遍历书签树function traverseBookmarks(bookmarkNodes, parentId) {for (const node of bookmarkNodes) {// 如果节点是文件夹if (node.children) {// 创建一个新的文件夹节点chrome.bookmarks.create({parentId: parentId,title: node.title,},function (newFolderNode) {// 递归遍历子节点traverseBookmarks(node.children, newFolderNode.id);});}// 如果节点是书签else {// 创建一个新的书签节点chrome.bookmarks.create({parentId: parentId,title: node.title,url: node.url,});}}}// 从根节点开始遍历书签树traverseBookmarks(bookmarkTreeNodes[0].children, "1");
}
插件使用
1、插件下载
直接到gitee上下载源码即可:
源码地址:https://gitee.com/zheng_yongtao/chrome-plug-in.git
2、导入插件
书签同步插件的目录如下:
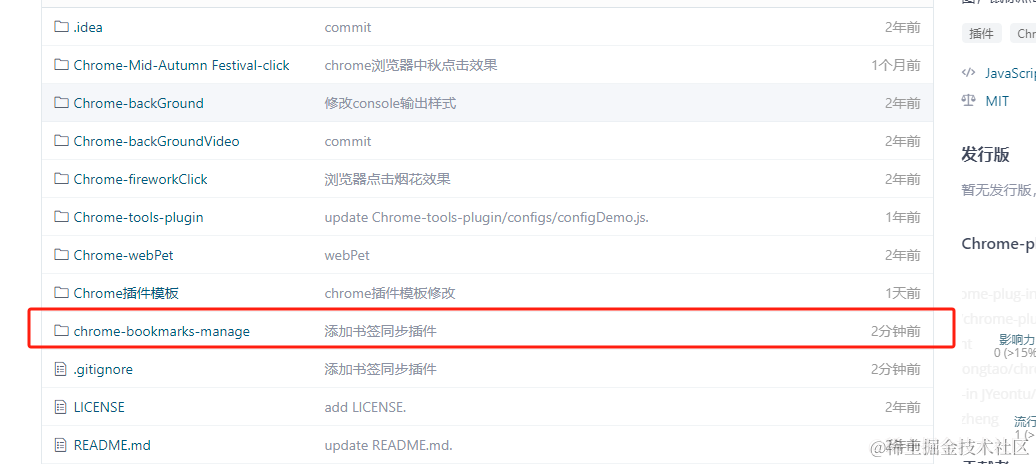
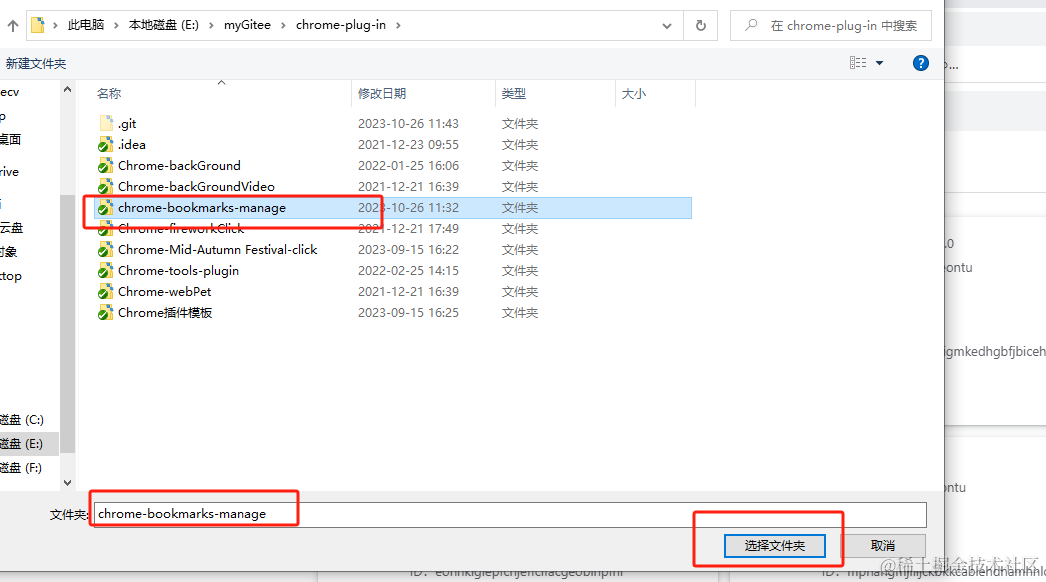
下载完后打开浏览器扩展程序管理页面(chrome://extensions/),选择加载已解压的扩展程序:

选择插件目录导入即可:
导入成功后就可以看到下面这个插件了
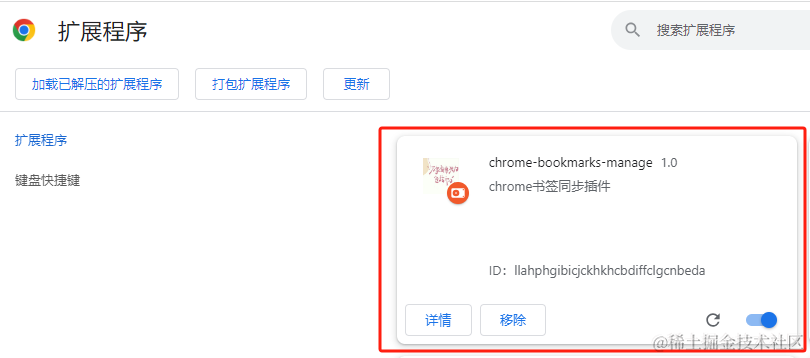
可以勾选上下面这个,勾选后插件就会显示在导航栏上
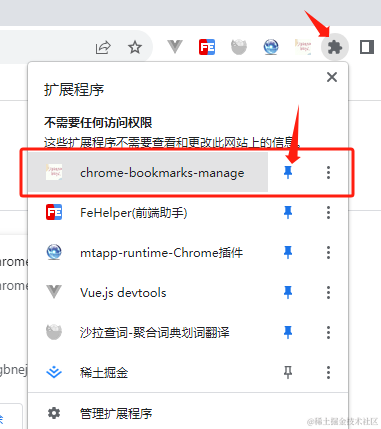
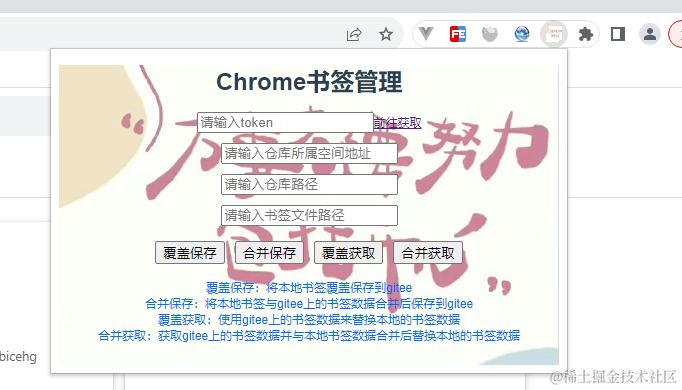
3、补充gitee仓库信息数据
导入插件后,我们点击导航栏的插件图标,可以看到这样一个面板,其中有四个数据需要我们填写:
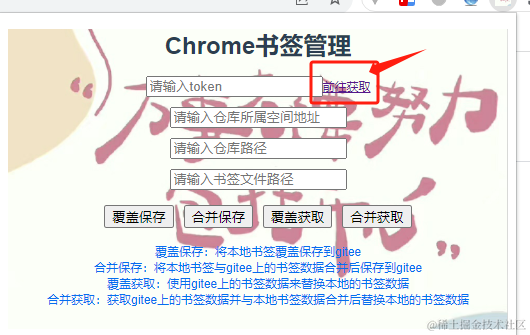
获取 token
进入到giteeAPI文档进行授权获取到返回填写即可,具体步骤如下:
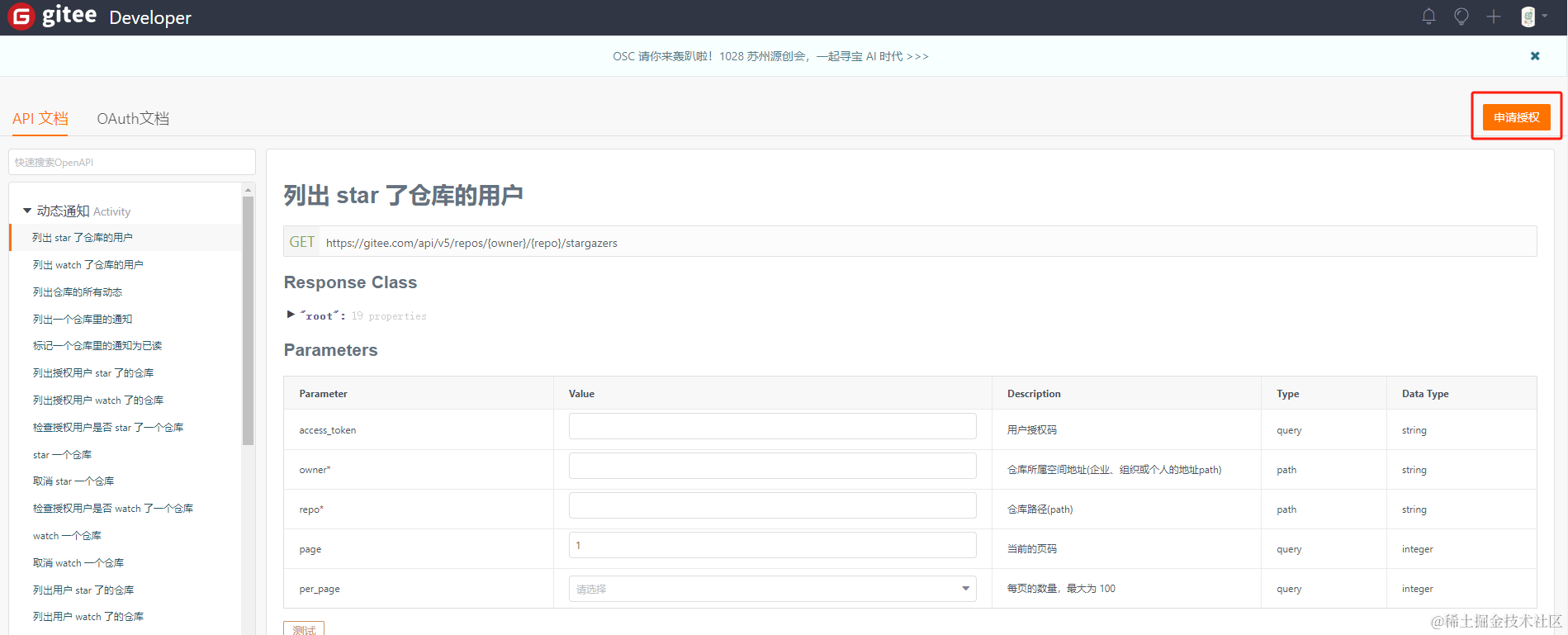
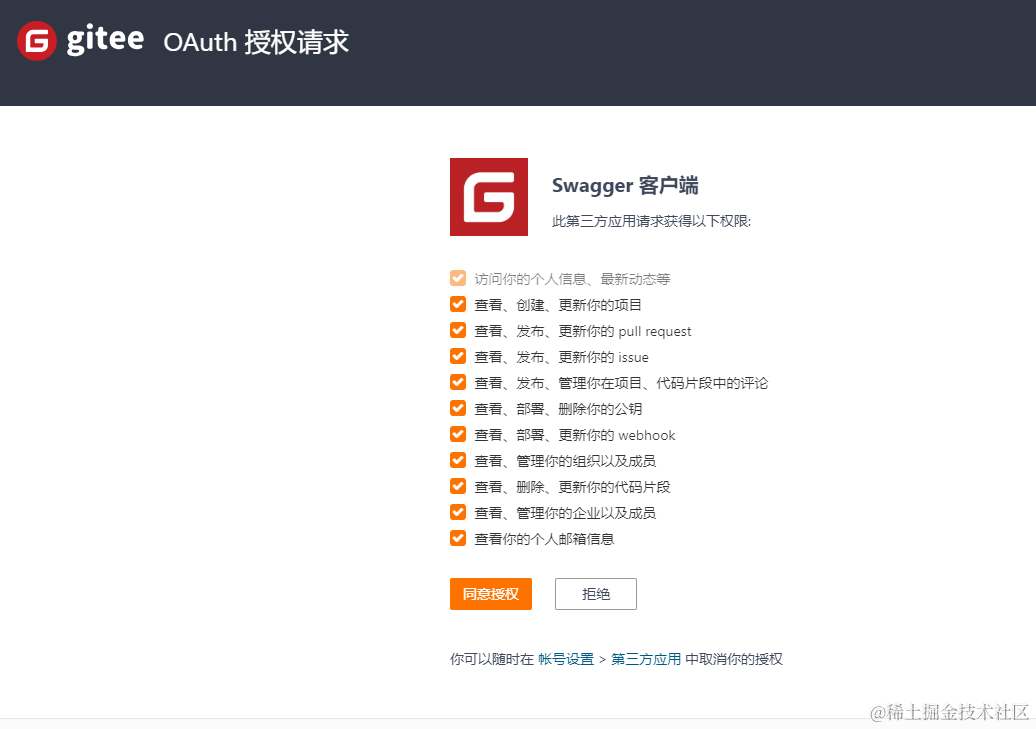
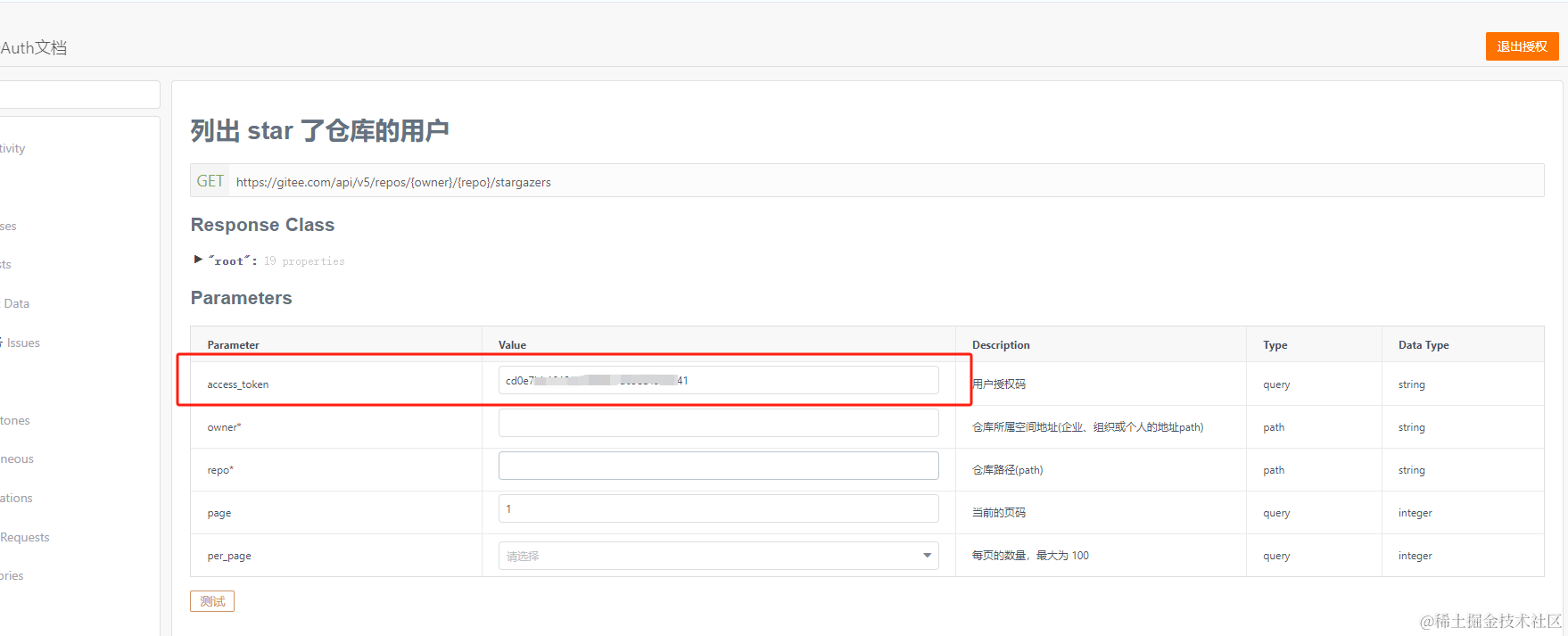
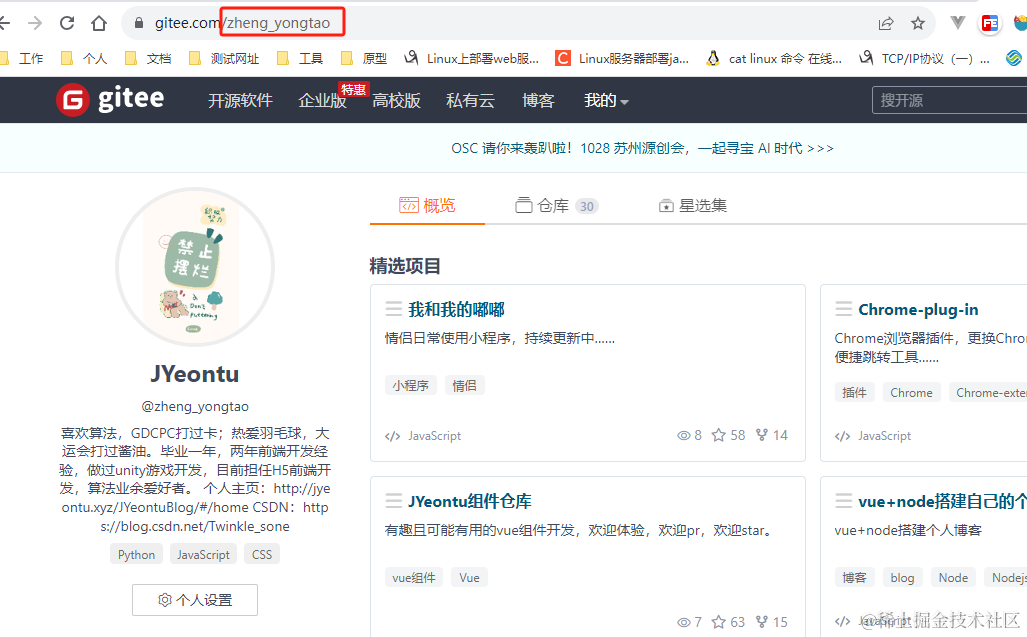
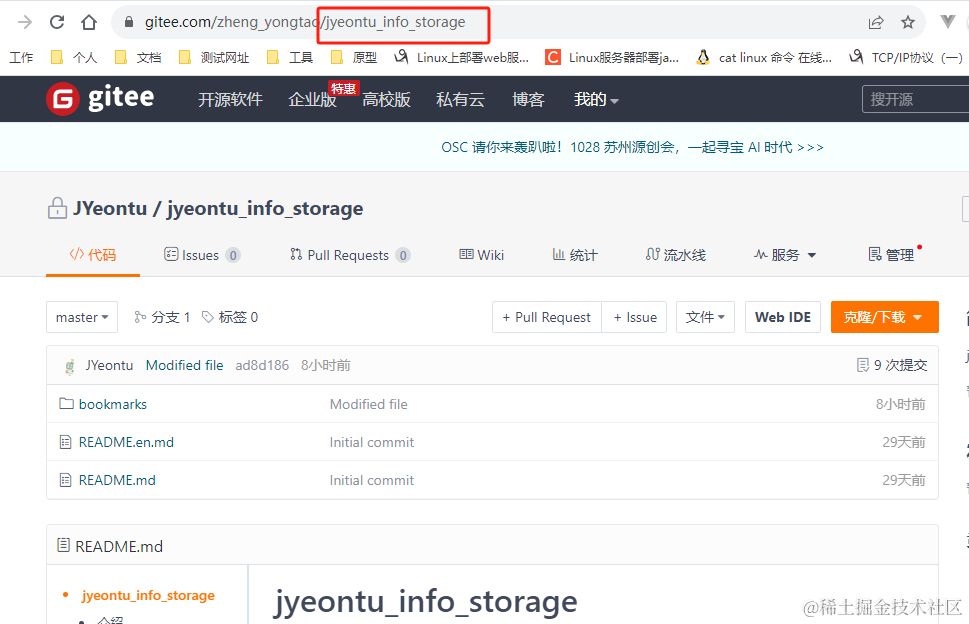
仓库所属空间地址(owner)
就是个人主页的一个空间地址,如下图:
仓库路径(repo)
前面新建仓库的路径(仓库名),如下图:
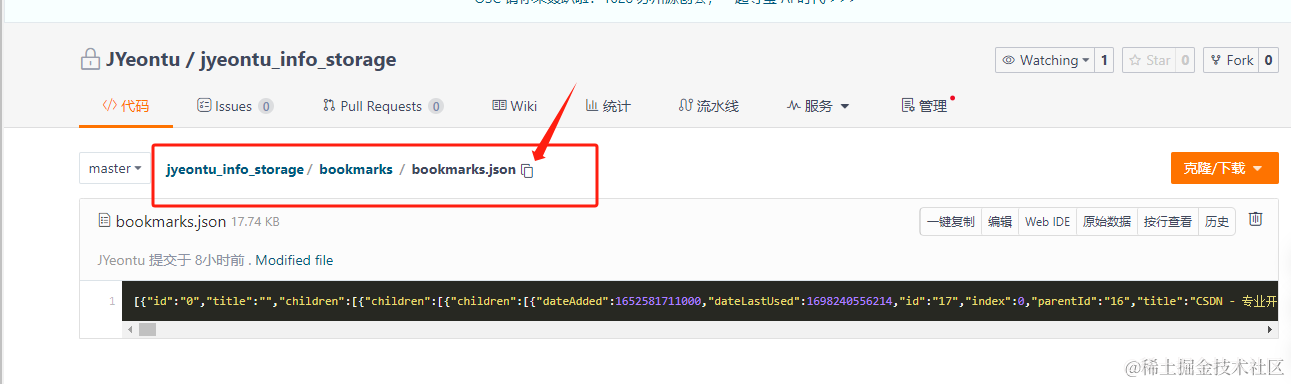
书签文件路径(filePath)
新建用于保存书签数据的文件,想保存多份不同的数据的话可以多件几个不同的文件分别进行存储,同步的时候选择对应的目录即可,如下图:
将对应信息填写上之后我们就可以开始进行同步操作了:
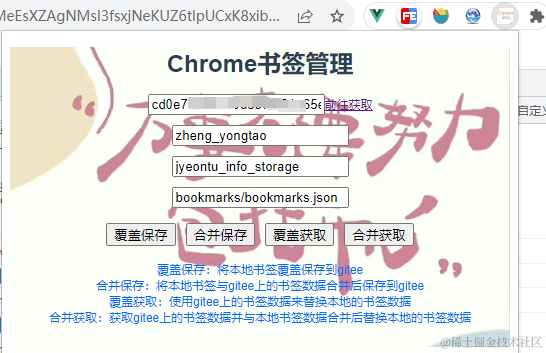
4、同步方式
(1)覆盖保存
使用当前浏览器书签数据覆盖保存到gitee仓库中。
(2)合并保存
将当前浏览器书签数据与gitee仓库中的书签数据合并好再进行保存。
(3)覆盖获取
使用gitee仓库中的书签数据覆盖掉本地的书签数据。
(4)合并获取
将gitee仓库中的书签数据和本地的书签数据合并后再覆盖掉本地的书签数据。
(5)合并规则
同一层级并且同名的目录我们会将其子节点合并到同一目录下,同一层级下我们会根据 书签名 + 书签url 对该层级的书签进行去重。
源码
1、gitee
gitee 地址:https://gitee.com/zheng_yongtao/chrome-plug-in/tree/master/chrome-bookmarks-manage
2、公众号
关注公众号『前端也能这么有趣』发送 chrome插件即可获取源码。
说在后面
🎉 这里是 JYeontu,现在是一名前端工程师,有空会刷刷算法题,平时喜欢打羽毛球 🏸 ,平时也喜欢写些东西,既为自己记录 📋,也希望可以对大家有那么一丢丢的帮助,写的不好望多多谅解 🙇,写错的地方望指出,定会认真改进 😊,偶尔也会在自己的公众号『前端也能这么有趣』发一些比较有趣的文章,有兴趣的也可以关注下。在此谢谢大家的支持,我们下文再见 🙌。
相关文章:
一键同步,无处不在的书签体验:探索多电脑Chrome书签同步插件
说在前面 平时大家都是怎么管理自己的浏览器书签数据的呢?有没有过公司和家里的电脑浏览器书签不同步的情况?有没有过电脑突然坏了但书签数据没有导出,导致书签数据丢失了?解决这些问题的方法有很多,我选择自己写个chr…...

在Go项目中二次封装Kafka客户端功能
1.摘要 在上一章节中,我利用Docker快速搭建了一个Kafka服务,并测试成功Kafka生产者和消费者功能,本章内容尝试在Go项目中对Kafka服务进行封装调用, 实现从Kafka自动接收消息并消费。 在本文中使用了Kafka的一个高性能开源库Sarama, Sarama是一个遵循MIT许可协议的Apache Kafk…...

CVE-2021-44228 Apache log4j 远程命令执行漏洞
一、漏洞原理 log4j(log for java)是由Java编写的可靠、灵活的日志框架,是Apache旗下的一个开源项目,使用Log4j,我们更加方便的记录了日志信息,它不但能控制日志输出的目的地,也能控制日志输出的内容格式;…...

前端跨域相关
注:前端配置跨域后服务器端(Nginx)也需要配置,否则接口无法访问 vue跨域 配置文件 /vue.config.js devServer: { port: 7100, proxy: { /api: { target: http://域名, changeOrigin: true, logLevel: debug, pathRewrite: { ^/…...
HTML笔记-狂神
1. 初识HTML 什么是HTML? Hyper Text Markup Language : 超文本标记语言 超文本包括:文字、图片、音频、视频、动画等 目前使用的是HTML5,使用 W3C标准 W3C标准包括: 结构化标准语言(HTML、XML) 表现标…...

python自动化测试工具selenium
概述 selenium是网页应用中最流行的自动化测试工具,可以用来做自动化测试或者浏览器爬虫等。官网地址为:Selenium。相对于另外一款web自动化测试工具QTP来说有如下优点: 免费开源轻量级,不同语言只需要一个体积很小的依赖包支持…...
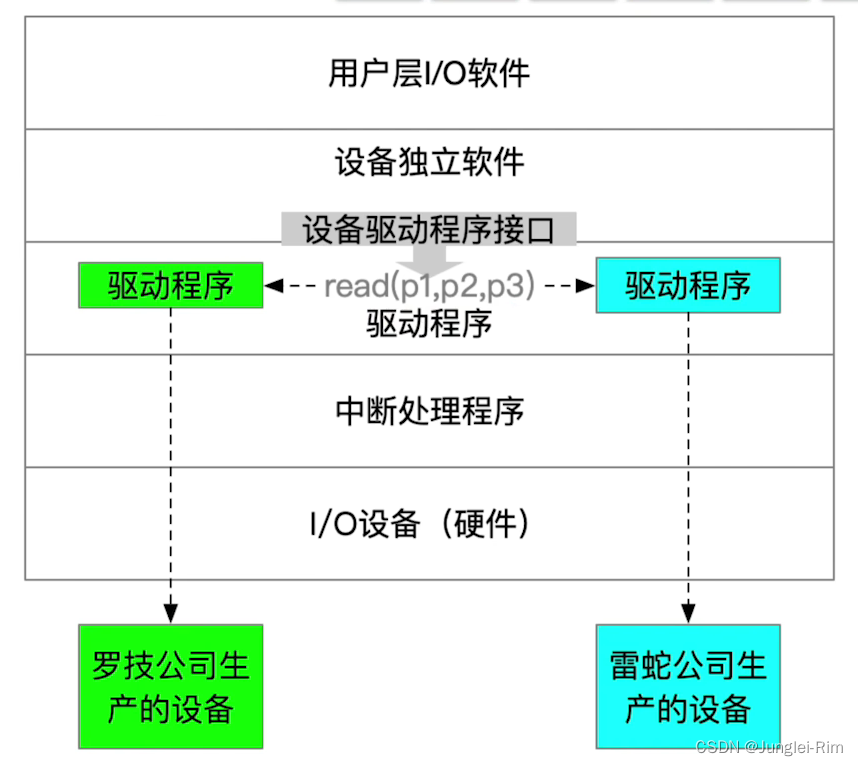
输入/输出应用程序接口和设备驱动程序接口
文章目录 1.输入/输出应用程序接口1.字符设备接口2.块设备接口3.网络设备接口1.网络设备套接字通信 4.阻塞/非阻塞I/O 2.设备驱动程序接口1.统一标准的设备驱动程序接口 1.输入/输出应用程序接口 1.字符设备接口 get/put系统调用:向字符设备读/写一个字符 2.块设备接口 read/wr…...

Python---Socket 网络通信
Socket :进程之间通信的工具,进程之间想要进行网络通信需要Socket,两个进程之间通过socket进行相互通讯,就必须有服务端和客服端。 Socket服务端编程 # 1.创建socket对象 import socketsocket_server socket.socket()# 2. 绑定socket_server到指定IP和…...
使用 jdbc 技术升级水果库存系统(优化版本)
抽取执行更新方法抽取查询方法 —— ResultSetMetaData ResultSetMetaData rsmd rs.getMetaData();//元数据,结果集的结构数据 抽取查询方法 —— 解析结果集封装成实体对象提取 获取连接 和 释放资源 的方法将数据库配置信息转移到配置文件 <dependencies><depend…...
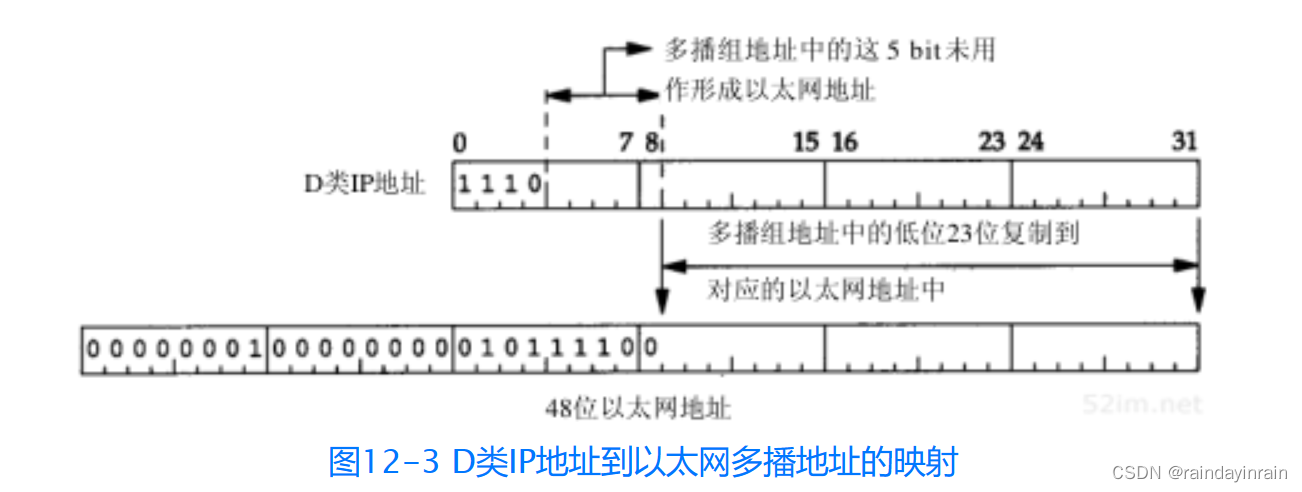
网络协议--广播和多播
12.1 引言 在第1章中我们提到有三种IP地址:单播地址、广播地址和多播地址。本章将更详细地介绍广播和多播。 广播和多播仅应用于UDP,它们对需将报文同时传往多个接收者的应用来说十分重要。TCP是一个面向连接的协议,它意味着分别运行于两主…...
正则表达式)
python爬虫入门(三)正则表达式
开源中国提供的正则表达式测试工具 http://tool.oschina.net/regex/,输入待匹配的文本,然后选择常用的正则表达式,就可以得出相应的匹配结果了 常用的匹配规则如下 模 式描 述\w匹配字母、数字及下划线\W匹配不是字母、数字及下划线的…...

fabric.js介绍
fabric.js是可以简化canvas编写的js库,提供canvas缺少的对象模型,包含动画、数据序列化和反序列化的等高级功能的js库,开源项目,在GitHub有很多人贡献。 官网:Fabric.js Javascript Canvas Library (fabricjs.com) 文档…...

YOLOv5源码中的参数超详细解析(3)— 训练部分(train.py)| 模型训练调参
前言:Hello大家好,我是小哥谈。YOLOv5项目代码中,train.py是用于模型训练的代码,是YOLOv5中最为核心的代码之一,而代码中的训练参数则是核心中的核心,只有学会了各种训练参数的真正含义,才能使用YOLOv5进行最基本的训练。🌈 前期回顾: YOLOv5源码中的参数超详细解析…...

Linux高性能编程学习-TCP/IP协议族
一、TCP/IP协议族结构与主要协议 分层:数据链路层、网络层、传输层、应用层 1. 数据链路层 功能:实现网卡驱动程序,处理数据在不同物理介质的传输 协议: ARP:将目标机器的IP地址转成MAC地址RARP:将MAC地…...

用爬虫代码爬取高音质音频示例
目录 一、准备工作 1、安装Python和相关库 2、确定目标网站和数据结构 二、编写爬虫代码 1、导入库 2、设置代理IP 3、发送HTTP请求并解析HTML页面 4、查找音频文件链接 5、提取音频文件名和下载链接 6、下载音频文件 三、完整代码示例 四、注意事项 1、遵守法律法…...
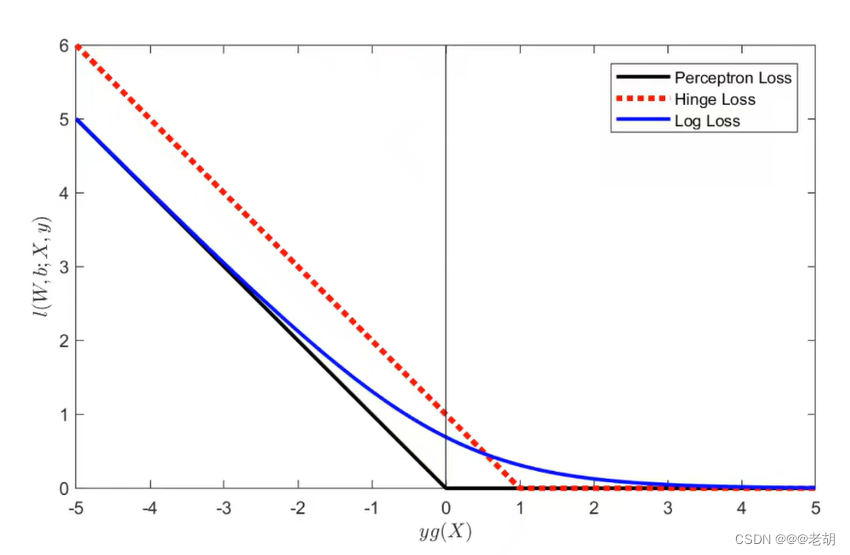
深度学习与计算机视觉(一)
文章目录 计算机视觉与图像处理的区别人工神经元感知机 - 分类任务Sigmoid神经元/对数几率回归对数损失/交叉熵损失函数梯度下降法- 极小化对数损失函数线性神经元/线性回归均方差损失函数-线性回归常用损失函数使用梯度下降法训练线性回归模型线性分类器多分类器的决策面 soft…...
【vector题解】杨辉三角 | 删除有序数组中的重复项 | 只出现一次的数字Ⅱ
杨辉三角 力扣(LeetCode)官网 - 全球极客挚爱的技术成长平台 给定一个非负整数 numRows,生成「杨辉三角」的前 numRows 行。 在「杨辉三角」中,每个数是它左上方和右上方的数的和。 示例 1: 输入: numRows 5 输出: [[1],[1,1…...
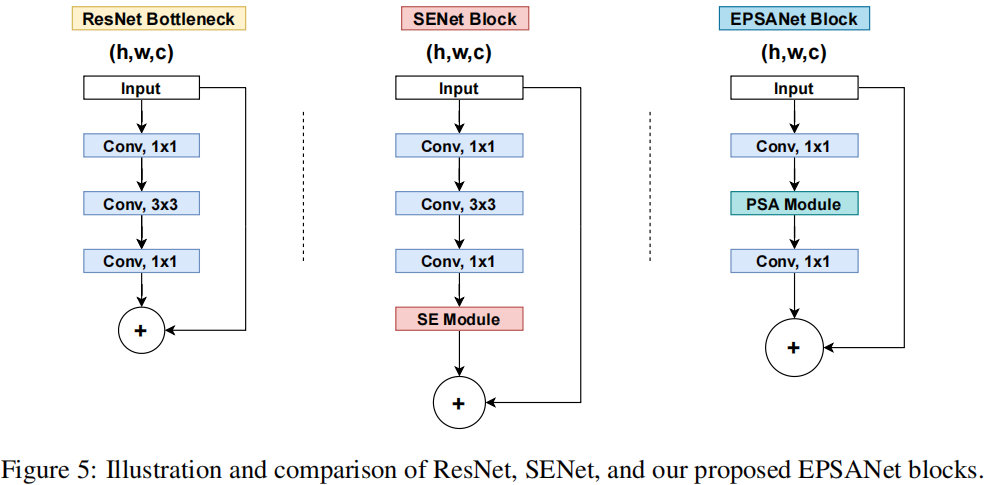
金字塔切分注意力模块PSA学习笔记 (附代码)
已有研究表明:将注意力模块嵌入到现有CNN中可以带来显著的性能提升。比如,SENet、BAM、CBAM、ECANet、GCNet、FcaNet等注意力机制均带来了可观的性能提升。但是,目前仍然存在两个具有挑战性的问题需要解决。一是如何有效地获取和利用不同尺度…...
Jenkins自动化测试
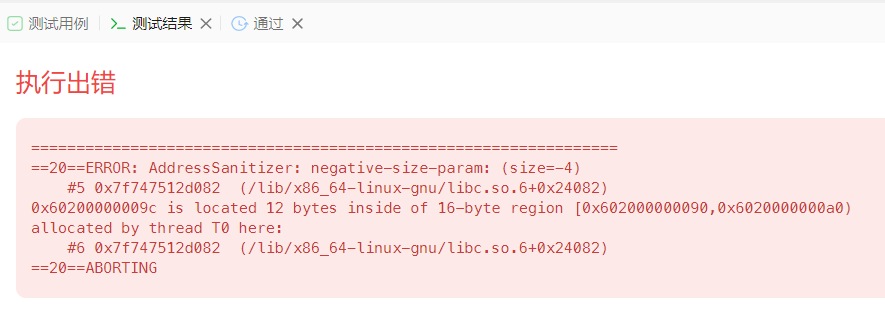
学习 Jenkins 自动化测试的系列文章 Robot Framework 概念Robot Framework 安装Pycharm Robot Framework 环境搭建Robot Framework 介绍Jenkins 自动化测试 1. Robot Framework 概念 Robot Framework是一个基于Python的,可扩展的关键字驱动的自动化测试框架。 它…...

python 字典dict和列表list的读取速度问题, range合并
嗨喽,大家好呀~这里是爱看美女的茜茜呐 python 字典和列表的读取速度问题 最近在进行基因组数据处理的时候,需要读取较大数据(2.7G)存入字典中, 然后对被处理数据进行字典key值的匹配,在被处理文件中每次…...

Unity 2018 + Facebook SDK 7.15.1避坑指南:从崩溃解决到完整功能实现
Unity 2018与Facebook SDK 7.15.1深度适配实战手册 当老牌游戏引擎遇上社交巨头的SDK,版本兼容性问题往往成为开发者的噩梦。本文将带您深入探索Unity 2018与Facebook SDK 7.15.1这对"经典组合"的适配之道,从环境搭建到功能实现,完…...

OpenClaw+Qwen3-14b_int4_awq内容创作:从大纲生成到公众号发布全自动
OpenClawQwen3-14b_int4_awq内容创作:从大纲生成到公众号发布全自动 1. 为什么需要全自动内容创作 作为一个技术博主,我经常面临一个困境:有太多想写的内容,但时间总是不够用。从构思大纲到完成写作,再到排版发布&am…...

爱站网SEO工具包的站点诊断功能有什么用
爱站网SEO工具包的站点诊断功能有什么用 随着互联网市场的日益竞争,网站的SEO优化成为了每一个网站运营者必须面对的挑战。在这样的背景下,SEO工具包成为了网站运营者的得力助手。其中,爱站网SEO工具包的站点诊断功能尤为重要。这个功能到底…...

2026-04-06:字典序最小和为目标值且绝对值是排列的数组。用go语言,给你一个正整数 n 和一个整数 target。 你需要构造一个长度为 n 的整数数组,要求同时满足: 1.数组中所有元素的总
2026-04-06:字典序最小和为目标值且绝对值是排列的数组。用go语言,给你一个正整数 n 和一个整数 target。 你需要构造一个长度为 n 的整数数组,要求同时满足: 1.数组中所有元素的总和必须等于 target。 2.把数组里每个元素取绝对值…...

西交提出 OdysseyArena:让智能体真正“学会探索”的长程归纳推理基准
📌 一句话总结: 本工作提出 OdysseyArena,一个面向长时程(long-horizon)、主动探索(active)、归纳学习(inductive)三大核心能力的交互式评测平台,系统性检验…...

OpenClaw文件自动化实战:Phi-3-mini-128k-instruct实现智能归档
OpenClaw文件自动化实战:Phi-3-mini-128k-instruct实现智能归档 1. 为什么需要智能文件归档 我的桌面和下载文件夹常年处于"灾难现场"状态——各种PDF、Word文档、截图混杂在一起,文件名要么是随机生成的乱码,要么是随手输入的&q…...

嵌入式设备参数存储优化方案与实践
1. 嵌入式设备参数存储的痛点与常见方案在嵌入式系统开发中,参数存储是个看似简单却暗藏玄机的基础功能。我经历过多个量产项目,发现参数管理不当导致的现场问题占比高达30%。最常见的场景是:设备运行多年后需要功能升级,新增几个…...

2026届学术党必备的降AI率平台横评
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 降低那个AIGC率的关键要点在于削弱机器生成所呈现出的模式化特性。其一,对句式结…...

数据治理与数据质量:从策略到实践
数据治理与数据质量:从策略到实践 前言 作为一个在数据深渊里捞了十几年 Bug 的女码农,我深知数据治理和数据质量在企业数据管理中的重要性。随着数据量的爆炸式增长和数据类型的多样化,数据治理和数据质量已经成为企业数据管理的核心挑战。今…...

2026届最火的六大降重复率神器实际效果
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 目前人工智能生成内容大范围运用的情形下,致使 AIGC 检测识别率降低的工具适时出…...