0基础学习PyFlink——用户自定义函数之UDAF
大纲
- UDAF
- 入参并非表中一行(Row)的集合
- 计算每个人考了几门课
- 计算每门课有几个人考试
- 计算每个人的平均分
- 计算每课的平均分
- 计算每个人的最高分和最低分
- 入参是表中一行(Row)的集合
- 计算每个人的最高分、最低分以及所属的课程
- 计算每课的最高分数、最低分数以及所属人
- 完整代码
- 入参并非表中一行(Row)的集合
- 入参是表中一行(Row)的集合
在前面几篇文章中,我们学习了非聚合类的用户自定义函数。这节我们将介绍最简单的聚合函数UDAF。
UDAF
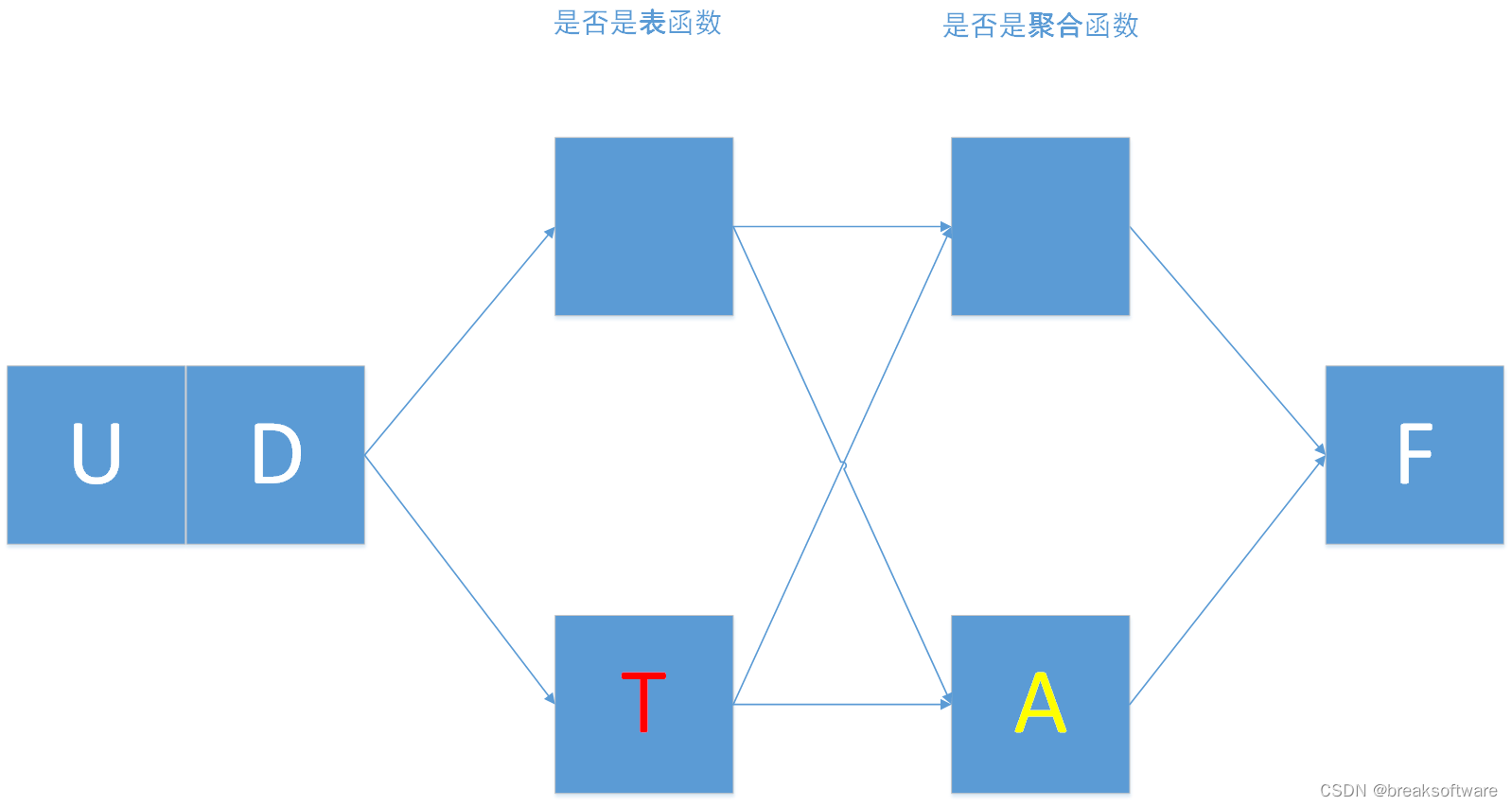
我们对比下UDAF和UDF的定义
def udaf(f: Union[Callable, AggregateFunction, Type] = None,input_types: Union[List[DataType], DataType, str, List[str]] = None,result_type: Union[DataType, str] = None, accumulator_type: Union[DataType, str] = None,deterministic: bool = None, name: str = None,func_type: str = "general") -> Union[UserDefinedAggregateFunctionWrapper, Callable]:
def udf(f: Union[Callable, ScalarFunction, Type] = None,input_types: Union[List[DataType], DataType, str, List[str]] = None,result_type: Union[DataType, str] = None,deterministic: bool = None, name: str = None, func_type: str = "general",udf_type: str = None) -> Union[UserDefinedScalarFunctionWrapper, Callable]:
可以发现:
- udaf比udf多了一个参数accumulator_type
- udaf比udf少了一个参数udf_type
accumulator中文是“累加器”。我们可以将其看成聚合过后(比如GroupBy)的成批数据,每批都要走一次函数。
举一个例子:我们对图中左侧的成绩单,使用人名(name)进行聚类,然后计算出最高分数。即算出每个人考出的最高分数是多少。
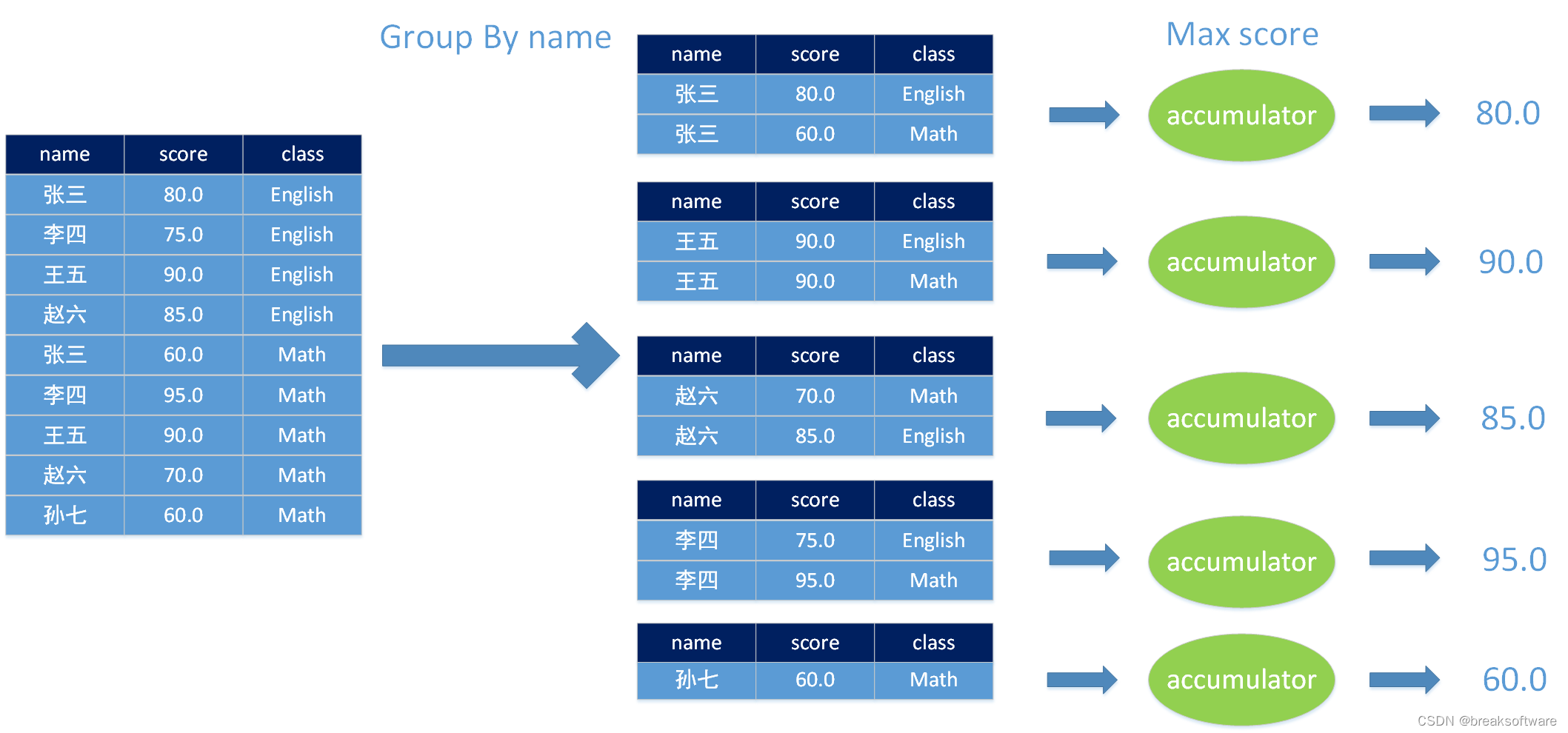
如图所示,聚合后的数据每个都会经过accumulator计算。计算出来的值的类型就是accumulator_type。这个类型的数据是中间态,它并不是最终UDAF返回的数据类型——result_type。具体这块的知识我们会在后面讲解。
为了方便讲解,我们就以上面例子来讲解其使用。先贴出准备的代码:
from pyflink.common import Configuration
from pyflink.table import (EnvironmentSettings, TableEnvironment, Schema)
from pyflink.table.types import DataTypes
from pyflink.table.table_descriptor import TableDescriptor
from pyflink.table.expressions import lit, col
from pyflink.common import Row
from pyflink.table.udf import udf,udtf,udaf,udtaf
import pandas as pd
from pyflink.table.udf import UserDefinedFunctiondef word_count():config = Configuration()# write all the data to one fileconfig.set_string('parallelism.default', '1')env_settings = EnvironmentSettings \.new_instance() \.in_batch_mode() \.with_configuration(config) \.build()t_env = TableEnvironment.create(env_settings)row_type_tab_source = DataTypes.ROW([DataTypes.FIELD('name', DataTypes.STRING()), DataTypes.FIELD('score', DataTypes.FLOAT()), DataTypes.FIELD('class', DataTypes.STRING())])students_score = [("张三", 80.0, "English"),("李四", 75.0, "English"),("王五", 90.0, "English"),("赵六", 85.0, "English"),("张三", 60.0, "Math"),("李四", 95.0, "Math"),("王五", 90.0, "Math"),("赵六", 70.0, "Math"),("孙七", 60.0, "Math"),]tab_source = t_env.from_elements(students_score, row_type_tab_source )
我们在tab_source表中录入了学生的成绩信息,其中包括姓名(name)、成绩(score)和科目(class)。
入参并非表中一行(Row)的集合
计算每个人考了几门课
- 按姓名(name)聚类
- UDTF统计聚类后集合的个数并返回
- 别名UDTF返回的列名
- select出数据
@udaf(result_type=DataTypes.ROW([DataTypes.FIELD("count", DataTypes.BIGINT())]), func_type="pandas")def exam_count(pandas_df: pd.DataFrame):return Row(pandas_df.count())tab_student_exam_count = tab_source.group_by(col('name')) \.aggregate(exam_count(col('name')).alias("count")) \.select(col('name'), col('count')) tab_student_exam_count.execute().print()
+--------------------------------+----------------------+
| name | count |
+--------------------------------+----------------------+
| 孙七 | 1 |
| 张三 | 2 |
| 李四 | 2 |
| 王五 | 2 |
| 赵六 | 2 |
+--------------------------------+----------------------+
5 rows in set
计算每门课有几个人考试
- 按姓名(class)聚类
- UDTF统计聚类后集合的个数并返回
- 别名UDTF返回的列名
- select出数据
@udaf(result_type=DataTypes.ROW([DataTypes.FIELD("count", DataTypes.BIGINT())]), func_type="pandas")def exam_count(pandas_df: pd.DataFrame):return Row(pandas_df.count())tab_class_exam_count = tab_source.group_by(col('class')) \.aggregate(exam_count(col('class')).alias("count")) \.select(col('class'), col('count')) tab_class_exam_count.execute().print()
+--------------------------------+----------------------+
| class | count |
+--------------------------------+----------------------+
| English | 4 |
| Math | 5 |
+--------------------------------+----------------------+
2 rows in set
计算每个人的平均分
- 按姓名(name)聚类
- UDTF统计聚类后集合的均值并返回
- 别名UDTF返回的列名
- select出数据
@udaf(result_type=DataTypes.ROW([DataTypes.FIELD("avg", DataTypes.FLOAT())]), func_type="pandas")def avg_score(pandas_df: pd.DataFrame):return Row(pandas_df.mean())tab_student_avg_score = tab_source.group_by(col('name')) \.aggregate(avg_score(col('score')).alias("avg")) \.select(col('name'), col('avg')) tab_student_avg_score.execute().print()
+--------------------------------+--------------------------------+
| name | avg |
+--------------------------------+--------------------------------+
| 孙七 | 60.0 |
| 张三 | 70.0 |
| 李四 | 85.0 |
| 王五 | 90.0 |
| 赵六 | 77.5 |
+--------------------------------+--------------------------------+
5 rows in set
计算每课的平均分
- 按姓名(class)聚类
- UDTF统计聚类后集合的均值并返回
- 别名UDTF返回的列名
- select出数据
@udaf(result_type=DataTypes.ROW([DataTypes.FIELD("avg", DataTypes.FLOAT())]), func_type="pandas")def avg_score(pandas_df: pd.DataFrame):return Row(pandas_df.mean())tab_class_avg_score = tab_source.group_by(col('class')) \.aggregate(avg_score(col('score')).alias("avg")) \.select(col('class'), col('avg')) tab_class_avg_score.execute().print()
+--------------------------------+--------------------------------+
| class | avg |
+--------------------------------+--------------------------------+
| English | 82.5 |
| Math | 75.0 |
+--------------------------------+--------------------------------+
2 rows in set
计算每个人的最高分和最低分
- 按姓名(name)聚类
- UDTF统计聚类后集合的最大值和最小值,并返回
- 别名UDTF返回的列名
- select出数据
@udaf(result_type=DataTypes.ROW([DataTypes.FIELD("max", DataTypes.FLOAT()), DataTypes.FIELD("min", DataTypes.FLOAT())]), func_type="pandas")def max_min_score(pandas_df: pd.DataFrame):return Row(pandas_df.max(), pandas_df.min())tab_student_max_min_score = tab_source.group_by(col('name')) \.aggregate(max_min_score(col('score')).alias("max", "min")) \.select(col('name'), col('max'), col('min')) tab_student_max_min_score.execute().print()
+--------------------------------+--------------------------------+--------------------------------+
| name | max | min |
+--------------------------------+--------------------------------+--------------------------------+
| 孙七 | 60.0 | 60.0 |
| 张三 | 80.0 | 60.0 |
| 李四 | 95.0 | 75.0 |
| 王五 | 90.0 | 90.0 |
| 赵六 | 85.0 | 70.0 |
+--------------------------------+--------------------------------+--------------------------------+
5 rows in set
入参是表中一行(Row)的集合
计算每个人的最高分、最低分以及所属的课程
- 按姓名(name)聚类
- UDTF统计聚类后集合中分数最大值、最小值;分数最大值所在行的课程名,和分数最小值所在行的课程名,并返回
- 别名UDTF返回的列名
- select出数据
@udaf(result_type=DataTypes.ROW([DataTypes.FIELD("max", DataTypes.FLOAT()), DataTypes.FIELD("max tag", DataTypes.STRING()), DataTypes.FIELD("min", DataTypes.FLOAT()), DataTypes.FIELD("min tag", DataTypes.STRING())]), func_type="pandas")def max_min_score_with_class(pandas_df: pd.DataFrame):return Row(pandas_df["score"].max(), pandas_df.loc[pandas_df["score"].idxmax(), "class"], pandas_df["score"].min(), pandas_df.loc[pandas_df["score"].idxmin(), "class"])tab_student_max_min_score = tab_source.group_by(col('name')) \.aggregate(max_min_score_with_class.alias("max", "class(max)", "min", "class(min)")) \.select(col('name'), col('max'), col('class(max)'), col('min'), col('class(min)')) tab_student_max_min_score.execute().print()
+--------------------------------+--------------------------------+--------------------------------+--------------------------------+--------------------------------+
| name | max | class(max) | min | class(min) |
+--------------------------------+--------------------------------+--------------------------------+--------------------------------+--------------------------------+
| 孙七 | 60.0 | Math | 60.0 | Math |
| 张三 | 80.0 | English | 60.0 | Math |
| 李四 | 95.0 | Math | 75.0 | English |
| 王五 | 90.0 | English | 90.0 | English |
| 赵六 | 85.0 | English | 70.0 | Math |
+--------------------------------+--------------------------------+--------------------------------+--------------------------------+--------------------------------+
5 rows in set
计算每课的最高分数、最低分数以及所属人
- 按姓名(class)聚类
- UDTF统计聚类后集合中分数最大值、最小值;分数最大值所在行的人名,和分数最小值所在行的人名,并返回
- 别名UDTF返回的列名
- select出数据
@udaf(result_type=DataTypes.ROW([DataTypes.FIELD("max", DataTypes.FLOAT()), DataTypes.FIELD("max tag", DataTypes.STRING()), DataTypes.FIELD("min", DataTypes.FLOAT()), DataTypes.FIELD("min tag", DataTypes.STRING())]), func_type="pandas")def max_min_score_with_name(pandas_df: pd.DataFrame):return Row(pandas_df["score"].max(), pandas_df.loc[pandas_df["score"].idxmax(), "name"], pandas_df["score"].min(), pandas_df.loc[pandas_df["score"].idxmin(), "name"])tab_class_max_min_score = tab_source.group_by(col('class')) \.aggregate(max_min_score_with_name.alias("max", "name(max)", "min", "name(min)")) \.select(col('class'), col('max'), col('name(max)'), col('min'), col('name(min)')) tab_class_max_min_score.execute().print()
+--------------------------------+--------------------------------+--------------------------------+--------------------------------+--------------------------------+
| class | max | name(max) | min | name(min) |
+--------------------------------+--------------------------------+--------------------------------+--------------------------------+--------------------------------+
| English | 90.0 | 王五 | 75.0 | 李四 |
| Math | 95.0 | 李四 | 60.0 | 张三 |
+--------------------------------+--------------------------------+--------------------------------+--------------------------------+--------------------------------+
2 rows in set
完整代码
入参并非表中一行(Row)的集合
from pyflink.common import Configuration
from pyflink.table import (EnvironmentSettings, TableEnvironment, Schema)
from pyflink.table.types import DataTypes
from pyflink.table.table_descriptor import TableDescriptor
from pyflink.table.expressions import lit, col
from pyflink.common import Row
from pyflink.table.udf import udf,udtf,udaf,udtaf
import pandas as pd
from pyflink.table.udf import UserDefinedFunctiondef word_count():config = Configuration()# write all the data to one fileconfig.set_string('parallelism.default', '1')env_settings = EnvironmentSettings \.new_instance() \.in_batch_mode() \.with_configuration(config) \.build()t_env = TableEnvironment.create(env_settings)row_type_tab_source = DataTypes.ROW([DataTypes.FIELD('name', DataTypes.STRING()), DataTypes.FIELD('score', DataTypes.FLOAT()), DataTypes.FIELD('class', DataTypes.STRING())])students_score = [("张三", 80.0, "English"),("李四", 75.0, "English"),("王五", 90.0, "English"),("赵六", 85.0, "English"),("张三", 60.0, "Math"),("李四", 95.0, "Math"),("王五", 90.0, "Math"),("赵六", 70.0, "Math"),("孙七", 60.0, "Math"),]tab_source = t_env.from_elements(students_score, row_type_tab_source )@udaf(result_type=DataTypes.ROW([DataTypes.FIELD("count", DataTypes.BIGINT())]), func_type="pandas")def exam_count(pandas_df: pd.DataFrame):return Row(pandas_df.count())tab_student_exam_count = tab_source.group_by(col('name')) \.aggregate(exam_count(col('name')).alias("count")) \.select(col('name'), col('count')) tab_student_exam_count.execute().print()tab_class_exam_count = tab_source.group_by(col('class')) \.aggregate(exam_count(col('class')).alias("count")) \.select(col('class'), col('count')) tab_class_exam_count.execute().print()@udaf(result_type=DataTypes.ROW([DataTypes.FIELD("avg", DataTypes.FLOAT())]), func_type="pandas")def avg_score(pandas_df: pd.DataFrame):return Row(pandas_df.mean())tab_student_avg_score = tab_source.group_by(col('name')) \.aggregate(avg_score(col('score')).alias("avg")) \.select(col('name'), col('avg')) tab_student_avg_score.execute().print()tab_class_avg_score = tab_source.group_by(col('class')) \.aggregate(avg_score(col('score')).alias("avg")) \.select(col('class'), col('avg')) tab_class_avg_score.execute().print()@udaf(result_type=DataTypes.ROW([DataTypes.FIELD("max", DataTypes.FLOAT()), DataTypes.FIELD("min", DataTypes.FLOAT())]), func_type="pandas")def max_min_score(pandas_df: pd.DataFrame):return Row(pandas_df.max(), pandas_df.min())tab_student_max_min_score = tab_source.group_by(col('name')) \.aggregate(max_min_score(col('score')).alias("max", "min")) \.select(col('name'), col('max'), col('min')) tab_student_max_min_score.execute().print()if __name__ == '__main__':word_count()
入参是表中一行(Row)的集合
from pyflink.common import Configuration
from pyflink.table import (EnvironmentSettings, TableEnvironment, Schema)
from pyflink.table.types import DataTypes
from pyflink.table.table_descriptor import TableDescriptor
from pyflink.table.expressions import lit, col
from pyflink.common import Row
from pyflink.table.udf import udf,udtf,udaf,udtaf
import pandas as pd
from pyflink.table.udf import UserDefinedFunctiondef word_count():config = Configuration()# write all the data to one fileconfig.set_string('parallelism.default', '1')env_settings = EnvironmentSettings \.new_instance() \.in_batch_mode() \.with_configuration(config) \.build()t_env = TableEnvironment.create(env_settings)row_type_tab_source = DataTypes.ROW([DataTypes.FIELD('name', DataTypes.STRING()), DataTypes.FIELD('score', DataTypes.FLOAT()), DataTypes.FIELD('class', DataTypes.STRING())])students_score = [("张三", 80.0, "English"),("李四", 75.0, "English"),("王五", 90.0, "English"),("赵六", 85.0, "English"),("张三", 60.0, "Math"),("李四", 95.0, "Math"),("王五", 90.0, "Math"),("赵六", 70.0, "Math"),("孙七", 60.0, "Math"),]tab_source = t_env.from_elements(students_score, row_type_tab_source )@udaf(result_type=DataTypes.ROW([DataTypes.FIELD("max", DataTypes.FLOAT()), DataTypes.FIELD("max tag", DataTypes.STRING()), DataTypes.FIELD("min", DataTypes.FLOAT()), DataTypes.FIELD("min tag", DataTypes.STRING())]), func_type="pandas")def max_min_score_with_class(pandas_df: pd.DataFrame):return Row(pandas_df["score"].max(), pandas_df.loc[pandas_df["score"].idxmax(), "class"], pandas_df["score"].min(), pandas_df.loc[pandas_df["score"].idxmin(), "class"])tab_student_max_min_score = tab_source.group_by(col('name')) \.aggregate(max_min_score_with_class.alias("max", "class(max)", "min", "class(min)")) \.select(col('name'), col('max'), col('class(max)'), col('min'), col('class(min)')) tab_student_max_min_score.execute().print()@udaf(result_type=DataTypes.ROW([DataTypes.FIELD("max", DataTypes.FLOAT()), DataTypes.FIELD("max tag", DataTypes.STRING()), DataTypes.FIELD("min", DataTypes.FLOAT()), DataTypes.FIELD("min tag", DataTypes.STRING())]), func_type="pandas")def max_min_score_with_name(pandas_df: pd.DataFrame):return Row(pandas_df["score"].max(), pandas_df.loc[pandas_df["score"].idxmax(), "name"], pandas_df["score"].min(), pandas_df.loc[pandas_df["score"].idxmin(), "name"])tab_class_max_min_score = tab_source.group_by(col('class')) \.aggregate(max_min_score_with_name.alias("max", "name(max)", "min", "name(min)")) \.select(col('class'), col('max'), col('name(max)'), col('min'), col('name(min)')) tab_class_max_min_score.execute().print()if __name__ == '__main__':word_count()相关文章:
0基础学习PyFlink——用户自定义函数之UDAF
大纲 UDAF入参并非表中一行(Row)的集合计算每个人考了几门课计算每门课有几个人考试计算每个人的平均分计算每课的平均分计算每个人的最高分和最低分 入参是表中一行(Row)的集合计算每个人的最高分、最低分以及所属的课程计算每课…...

MVC架构_Qt自己的MV架构
文章目录 前言模型/视图编程1.先写模型2. 视图3. 委托 例子(Qt代码)例1 查询本机文件系统例2 标准模型项操作例3 自定义模型示例:军事武器模型例4 只读模型操作示例例5 选择模型操作例6 自 定 义委 托(在testSelectionModel上修改) 前言 在Qt中…...
CentOS - 安装 Elasticsearch
"Elasticsearch"是一个流行的开源搜索和分析引擎,它可以用于实时搜索、日志和事件数据分析等任务。以下是在 CentOS 上安装 Elasticsearch 的基本步骤: 安装 Java: Elasticsearch 是基于 Java 的应用程序,所以首先需要…...
IDEA 断点高阶
一、按钮介绍 1.1 补充 返回断点处: 设置debug配置: 二、增加/切换debugger视图 三、window快捷键 所在行处: CtrlF8断点属性编辑: CtrlShiftF8 四、一些常用的高级功能 4.1 查看对象内存-Attach memory agent 1.勾选Atta…...

Qt中的单例模式
QT单例类管理信号和槽函数 Chapter1 Qt中的单例模式一、什么是单例模式?二、Qt中单例模式的实现2.1、静态成员变量2.2、静态局部变量2.3、Q_GLOBAL_STATIC 宏实例2 三、使用场景四、注意事项 Chapter2 QT单例类管理信号和槽函数一、创建单例类二、主界面添加组件三、…...
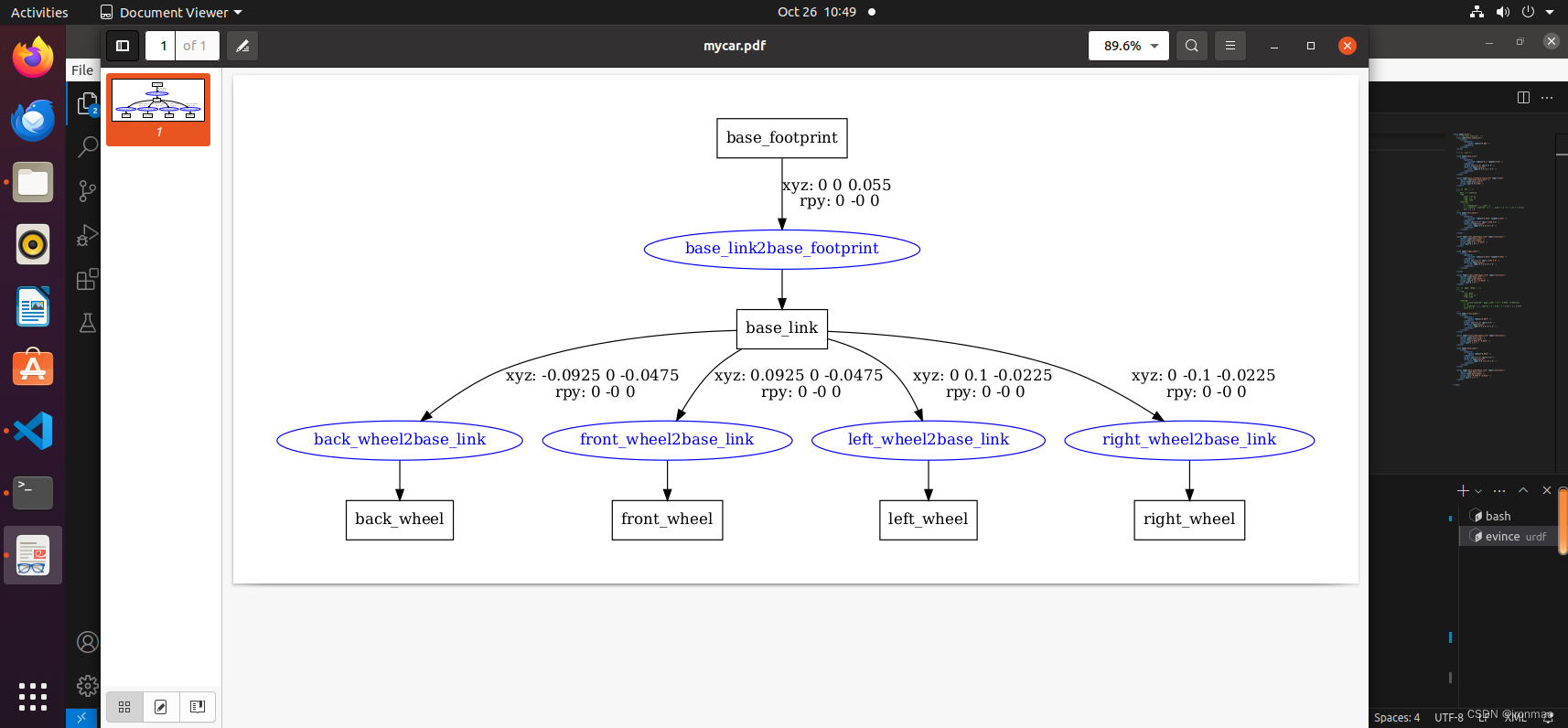
ROS自学笔记十五:URDF工具
要使用工具之前,首先需要安装,安装命令: sudo apt install liburdfdom-tools 1.check_urdf 语法检查 在ROS中,你可以使用.check_urdf命令行工具来对URDF(Unified Robot Description Format)文件进行语法检查和验证。…...
Pytorch代码入门学习之分类任务(三):定义损失函数与优化器
一、定义损失函数 1.1 代码 criterion nn.CrossEntropyLoss() 1.2 损失函数简介 神经网络的学习通过某个指标表示目前的状态,然后以这个指标为基准,寻找最优的权重参数。神经网络以某个指标为线索寻找最优权重参数,该指标称为损失函数&am…...

【Linux】安装VMWare虚拟机(安装配置)和配置Windows Server 2012 R2(安装配置连接vm虚拟机)以及环境配置
前言: 一、操作系统简介 1、什么是操作系统 操作系统是一种软件,它管理计算机系统的硬件和软件资源,并提供给用户和应用程序接口,使它们能够与计算机系统交互和运行。操作系统负责调度和分配系统资源,例如处理器、内存…...

Python入口顶部人体检测统计进出人数
程序示例精选 Python入口顶部人体检测统计进出人数 如需安装运行环境或远程调试,见文章底部个人QQ名片,由专业技术人员远程协助! 前言 这篇博客针对《Python入口顶部人体检测统计进出人数》编写代码,代码整洁,规则&a…...

移动端自动化-Appium元素定位
文章目录 Appium元素定位第一类:属性定位第二类:路径定位 常见问题理解appium server 和 appium inspector 以及 appium-python-client的关系 appium是跨平台的,支持OSX,Windows以及Linux系统。它允许测试人员在不同的平台&#x…...
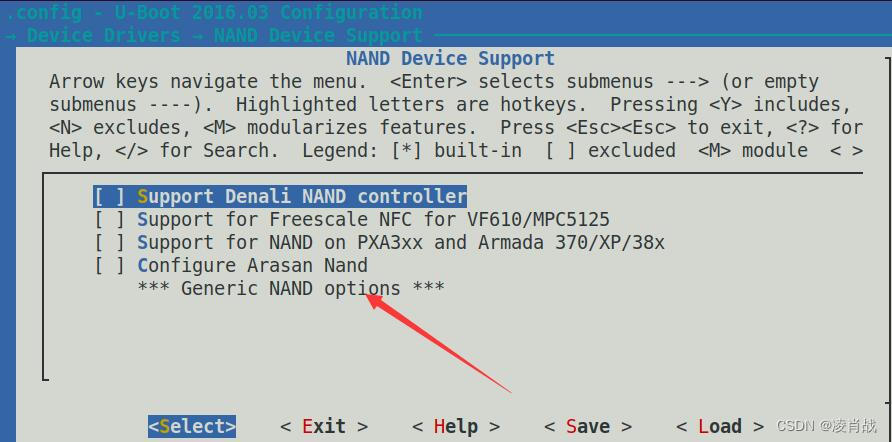
menuconfig 图形化配置原理说明三
一. 简介 本文继续简单了解一下,uboot的图形化配置原理。具体了解 Kconfig语法。 之前文章了解了几个 Kconfig语法。地址如下: menuconfig 图形化配置原理说明二-CSDN博客 二. menuconfig 图形化配置之 Kconfig语法 1. config 条目 顶层 Kconfig …...
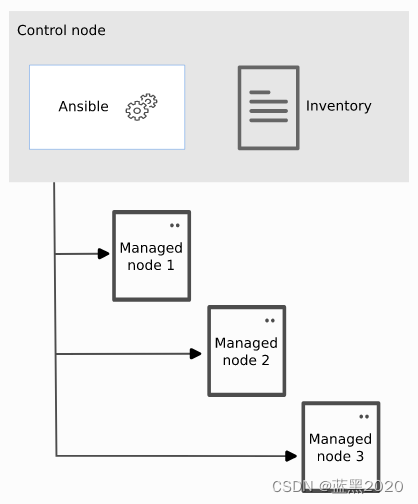
Ansible简介
环境 控制节点:Ubuntu 22.04Ansible 2.10.8管理节点:CentOS 8 组成 Ansible环境主要由三部分组成: 控制节点(Control node):安装Ansible的节点,在此节点上运行Ansible命令管理节点ÿ…...
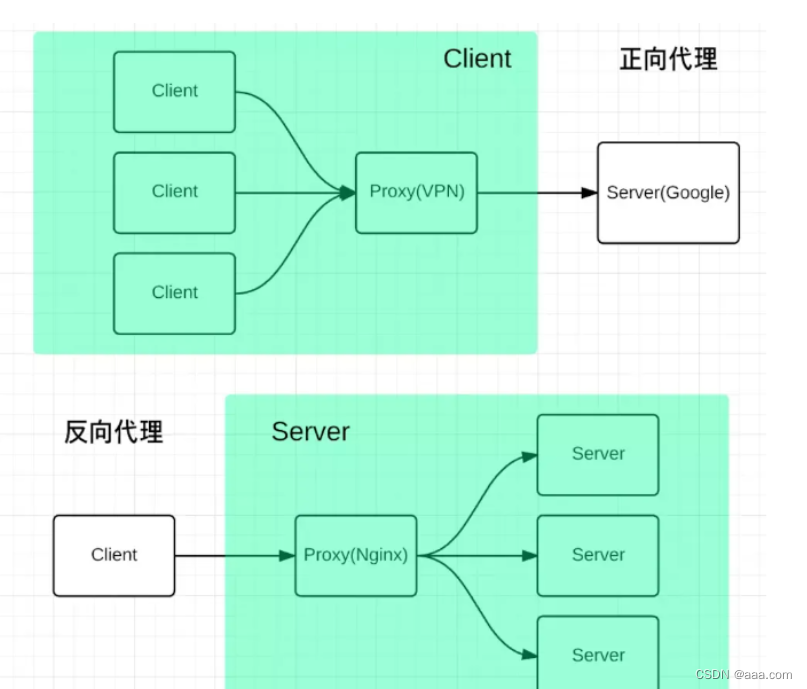
Tomcat+nginx负载均衡和动静分离
Nginx实现负载均衡和动静分离的原理 Nginx实现负载均衡是通过反向代理实现Nginx服务器作为前端,Tomcat服务器作为后端,web页面请求由Nginx服务来进行转发。 但是不是把所有的web请求转发,而是将静态页面请求Ncinx服务器自己来处理,…...

全景环视AVM标定
目录 一、前言 二、鱼眼模型 三、标定流程 四、角点提取 4.1 亚像素坐标计算...

【JavaScript】leetcode链表相关题解
【JavaScript】leetcode链表相关题解 一、什么是链表?二、Javascript中的链表三、leetcode相关链表2.两数相加237.删除链表中的节点206.反转链表 💎个人主页: 阿选不出来 💎个人简介: 大三学生,热爱Web前端,随机掉落学…...
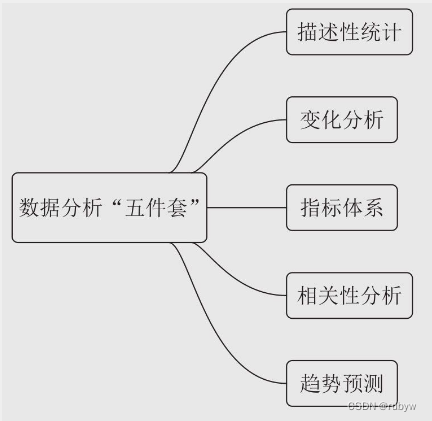
洞察运营机会的数据分析利器
这套分析方法包括5个分析工具: 用“描述性统计”来快速了解数据的整体特点。用“变化分析”来寻找数据的问题和突破口。用“指标体系”来深度洞察变化背后的原因。用“相关性分析”来精确判断原因的影响程度。用“趋势预测”来科学预测未来数据的走势,...

使用Python实现文字的声音播放
winsound 是 Python 的一个内置模块,它提供了访问 Windows 操作系统的声音播放功能的接口。这个模块可以用来播放简单的声音,例如提示音或者短促的音效。 # Author : 小红牛 # 微信公众号:WdPython import win32com.client import winsound#…...
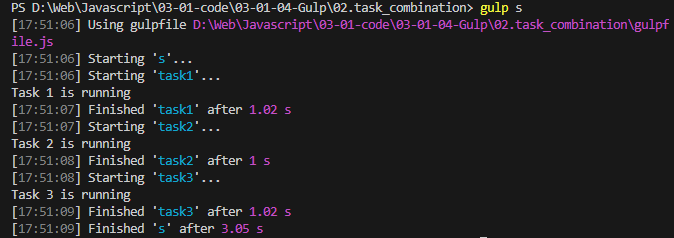
gulp自动化构建
什么是Gulp? Gulp是一种前端开发过程中广泛使用的自动化构建工具,它是基于Node.js构建的,能够极大地提高开发效率和代码质量。Gulp的主要功能包括文件的压缩、合并、重命名等,同时它也支持文件监听和浏览器自动刷新等功能。使用Gulp&#x…...

java时间解析生成定时Cron表达式工具类
Cron表达式工具类CronUtil 构建Cron表达式 /****方法摘要:构建Cron表达式*param taskScheduleModel*return String*/public static String createCronExpression(TaskScheduleModel taskScheduleModel){StringBuffer cronExp new StringBuffer("");if(…...
JavaEE 网络原理——TCP的工作机制(末篇 其余TCP特点)
文章目录 一、滑动窗口二、流量控制三、拥堵控制四、延时应答五、捎带应答六、面向字节流七、异常情况八、总结 其余相关文章: JavaEE 网络原理——TCP的工作机制(中篇 三次握手和四次挥手) 本篇文章衔接的是前面两篇文章的内容,在这里继续解释 TCP 的内…...

PlayCover:重新定义Apple Silicon Mac的iOS应用运行体验
PlayCover:重新定义Apple Silicon Mac的iOS应用运行体验 【免费下载链接】PlayCover Community fork of PlayCover 项目地址: https://gitcode.com/gh_mirrors/pl/PlayCover 价值定位:突破生态壁垒的三大核心创新 如何打破苹果生态系统的应用边界…...
Transformer原理探讨
Transformer模型自2017年Google提出以来,已成为深度学习领域最核心的架构之一,推动了自然语言处理、计算机视觉等领域的革命性发展。本教程将系统性地从零开始解析Transformer的原理与架构,帮助您深入理解这一改变AI格局的模型。 核心学习路径: 掌握序列建模背景知识与Tra…...

基于YOLO26的人脸识别技术
基于YOLO26的人脸识别技术方案代表了边缘计算与轻量化视觉AI的前沿突破。YOLO26作为Ultralytics团队于2026年初发布的最新一代YOLO模型,通过"无NMS端到端推理+架构精简优化"的核心设计理念,实现了在CPU和边缘设备上43%的推理速度提升,同时保持了优秀的检测精度。本…...

终极指南:3个阶段让旧款Mac免费升级到最新macOS系统
终极指南:3个阶段让旧款Mac免费升级到最新macOS系统 【免费下载链接】OpenCore-Legacy-Patcher Experience macOS just like before 项目地址: https://gitcode.com/GitHub_Trending/op/OpenCore-Legacy-Patcher 你是否拥有一台2012-2017年的旧款Mac…...

GCP 成本优化指南
5 分钟速览 我想… 用什么 预期效果 看钱花在哪了 Billing Reports + Cost Table 按服务/项目/标签拆分费用 费用超了自动告警 Budget Alerts 50%/80%/100% 阈值通知 深度分析费用趋势 BigQuery 费用导出 自定义 SQL 分析任意维度 降低计算成本 CUD / Spot VM 计算费用降 30%-7…...
)
大模型应用落地:新手/程序员必备五类关键技术选型指南(收藏版)
大模型应用落地:新手/程序员必备五类关键技术选型指南(收藏版) 本文从产品经理视角出发,详细介绍了大模型应用落地的五类关键技术(Prompt、RAG、Workflow、Agent、模型微调)及其适用场景。强调技术选型应遵…...

Phi-3-mini-128k-instruct效果展示:128K上下文下跨段落事实一致性问答实例
Phi-3-mini-128k-instruct效果展示:128K上下文下跨段落事实一致性问答实例 1. 模型简介 Phi-3-Mini-128K-Instruct 是一个38亿参数的轻量级开放模型,属于Phi-3系列的最新成员。这个模型最引人注目的特点是它支持长达128K token的上下文窗口,…...

浏览器魔法师:Greasy Fork用户脚本终极指南,5分钟解锁网页超能力
浏览器魔法师:Greasy Fork用户脚本终极指南,5分钟解锁网页超能力 【免费下载链接】greasyfork An online repository of user scripts. 项目地址: https://gitcode.com/gh_mirrors/gr/greasyfork 你是否厌倦了网页上烦人的广告?想要一…...

2025届最火的六大AI科研平台推荐
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 在学术写作这个领域当中 ,那论文AI网站正一步一步地变成研究者的重要辅助工具。这…...

基于 N-gram 全新模型:嵌入扩展新范式,实现轻量化 MoE 高效进化
在技术领域,我们常常被那些闪耀的、可见的成果所吸引。今天,这个焦点无疑是大语言模型技术。它们的流畅对话、惊人的创造力,让我们得以一窥未来的轮廓。然而,作为在企业一线构建、部署和维护复杂系统的实践者,我们深知…...