LLaVA:visual instruction tuning
对近期一些MLLM(Multimodal Large Language Model)的总结 - 知乎本文将从模型结构,训练方法,训练数据,模型表现四个方面对近期的一些MLLM(Multi-modal Large Language Models)进行总结并探讨这四个方面对模型表现的影响。本文覆盖的MLLM包括:LLaVA, MiniGPT-4, mPLUG-Owl, …![]() https://zhuanlan.zhihu.com/p/655770704
https://zhuanlan.zhihu.com/p/655770704
连接不同模态的可学习接口:挑战在于如何将视觉内容有效的转换为LLM能理解的文本。1.利用一组可学习的query token以查询方式提取信息,Flamingo和BLIP2,2.基于投影,llava采用简单的线性层嵌入图像特征,MedVInT-TE则使用两层多层感知机,3.LLaMA-Adapter在transformer中引入一个轻量级适配器模块进行训练,LaVIN设计了一个多模态适配器混合模型,动态决定多模态嵌入的权重。
1.related work
multimodel instruction-following agents. 1.端到端训练模型,2.langchain,例如visual chatgpt.
instruction tuning. Flamingo,Blip2,KOSMOS-1。
2.GPT-assisted Visual instruction data generation
总共收集了15.8w的语言-图像instruct样本,其中包括5.8w个对话样本,2.3w个详细描述样本和7.7w个复杂推理样本。
3.Visual instruction tuning
3.1 architecture
主要目标是有效利用预训练的llm和视觉模型的能力,llama作为llm,预训练的clip视觉编码器ViT-L/14,提供Zv,用一个简单的线性层来将图像特征连接到单词embedding空间,用一个可训练的投影矩阵w将Zv转换为语言embedding标记Hq,其维度与语言模型中的单词embedding空间相同。 也有复杂的方式,例如Flamingo中的gated cross-attention和BLIP2中的Q-former。
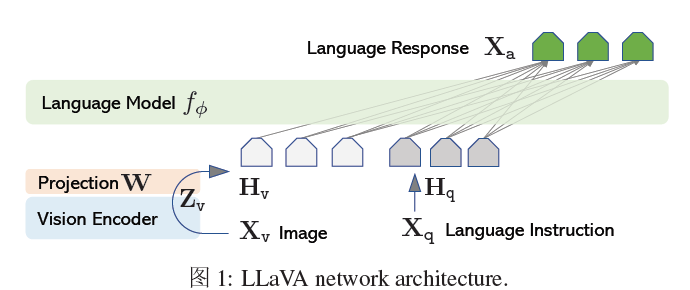
LLaVA主要由三部分组成:Pretrained LLM,Pretrained Vision Encoder和Projection Layers。其中,Pretrianed LLM即为目前比较火的Decoder-only language model,比如LLaMA,LLaMA-2等。Pretrained Vision Encoder即为一个预训练的视觉编码器,通常是CLIP的中的视觉分支。而连接在vison encoder和LLM之间的Projection Layers即为一个简单的线形层,这个projector的作用是将image通过vision encoder得到的visual feature从visual space转化到language space从而可以输入LLM。
整个模型的forward过程是先将图片输入vision encoder得到图片的visual feature,然后visual feature经过projection layers得到对应的linguistic vector 。然后,将prompt(通常为VQA认为中的问题,或者目前比较火的Instruction)通过LLM的word embedding层,得到prompt对应的linguistic feature。然后将图像的vector和文字vector concatnate起来得到一个长序列。将长序列输入LLM,然后LLM自回归地去生成prompt对应的结果,这个结果可以是VQA中的答案,也可以是图片的caption。
3.2 training
llava训练包含两个阶段:预训练和微调。
LLaVA的预训练阶段是在Image-Text pair数据上进行的,在这个过程之中,只有Projection layers部分是可训练的,模型的其他部分(LLM和vision encoder)都是冻住的。预训练这个阶段是为了训练一个较好的projection layer可以将visual feature映射到linguistic space。换句话说,为了让vision encoder的output space和LLM的input space实现一个对齐。这个阶段结束之后模型获得了一个初步的理解图像的能力。
LLaVA的微调阶段分为两种,一种是在instruct template数据上进行Instruct Tuning,另一种是在ScienceQA数据集上进行微调。这里我们以Instruct Tuning为主要展开。首先,这个阶段中可训练的部分包括整个LLM和projection layer。这一阶段可以对应于目前比较火的LLM的Instruction fine tuning,目的是为了让模型更好地遵循用户给出的Instruction。换句话说,为了让模型更好地和人类意图进行对齐。所以,这个阶段的作用可以类比到GPT-3向InstructGPT的转变,即模型可以更好地遵循人类指令。
4.训练数据
对应于LLaVA的两个训练阶段,LLaVA的训练数据也分为两部分:预训练阶段的数据和微调阶段的数据。
预训练阶段的数据直接来自CC3M。CC3M包含3 million的图像文本对,作者通过text中的noun-phrase的频率对3 million的数据进行了过滤最终得到595K个图像文本对。然后,作者通过GPT-4生成一些多样化的Instruction,用这些Instruction将简单的图像文本对扩展成了[Image, Instruction; Caption]的形式。

指令微调阶段的数据也是由GPT-4辅助生成的。由于GPT-4是纯文本输入,所以要使用GPT-4来生成一些针对图片的问题和答案就需要将图片表示成GPT-4可以理解的形式。在这里,对于一张图片,作者用5句caption以及图片中object的bounding box的坐标数值来表示一张图片。然后,通过设计特定的prompt以及例子,让GPT-4生成针对一张图片的conversation, detailed description和complex reasoning。

5.Experiments
作者从COCO Caption的val split中抽取了30张图片,针对每张图片设计了short question,detailed question和complex reasoning question,共得到90个evaluation sample。针对这90个sample,作者使用预训练+指令微调之后的LLaVA和GPT-4分别生成了答案,然后借助GPT-4对LLaVA生成的答案进行了Evaluation,并让GPT-4进行打分,结果如下:
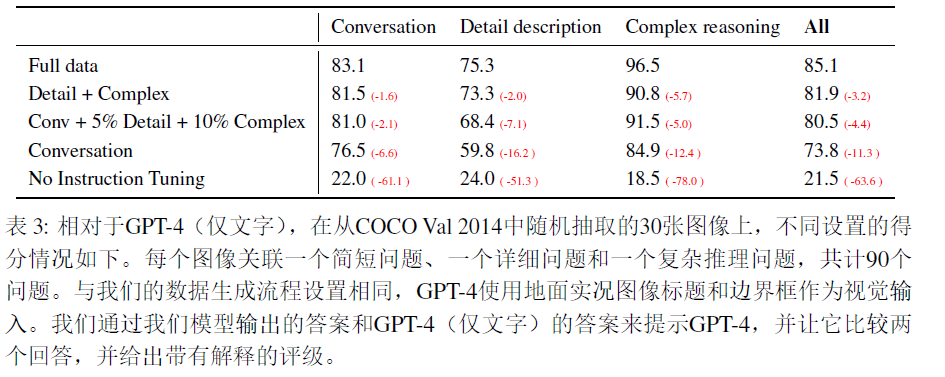
llava当时的GPT4还不支持图像输入,因此这样的测评也不完全能够展示GPT4的能力。
相关文章:
LLaVA:visual instruction tuning
对近期一些MLLM(Multimodal Large Language Model)的总结 - 知乎本文将从模型结构,训练方法,训练数据,模型表现四个方面对近期的一些MLLM(Multi-modal Large Language Models)进行总结并探讨这四个方面对模型表现的影响…...

Python实现双目标定、畸变矫正、立体矫正
一,双目标定、畸变矫正、立体矫正的作用 双目目标定: 3D重建和测距:通过双目目标定,您可以确定两个摄像头之间的相对位置和朝向,从而能够根据视差信息计算物体的深度,进行三维重建和测距。姿态估计…...
showdoc 文件上传 (cnvd-2020-26585)
showdoc 文件上传 (cnvd-2020-26585) 描述 ShowDoc是一个非常适合IT团队的在线API文档、技术文档工具。通过showdoc,你可以方便地使用markdown语法来书写出美观的API文档、数据字典文档、技术文档、在线excel文档等等。 api_page存在任意文…...

Java数据类型,变量与运算符
1.字面常量 常量是在程序运行期间,固定不变的量称为常量。 public class HelloWorld{public static void main(String[] args){System.out.println("Hello,world");} } 在以上程序中,输出的Hello Word,其中的“Hello Word”就是…...

Linux nm命令
Linux的nm命令主要用于列出对象文件中的符号。以下是一些使用示例: 基本用法:只需运行’nm’命令,并将对象文件的名称作为输入传递给它。例如,我使用’nm’命令与’apl’elf 文件:nm apl。 在输出中为每个符号前面添加…...

iOS发布证书.p12文件无密码解决办法及导出带密码的新.p12文件方法
摘要: 本文将以iOS技术博主身份,分享解决使用无密码的.p12文件发布应用时遇到的问题,并介绍如何以带密码的方式重新导出.p12文件的方法。通过本文提供的步骤,开发者可以顺利完成证书的发布流程。 引言 在iOS应用发布过程中&…...

OpenCamera拍照的代码流程
按理来说,拍照应该是很简单的。随着功能的复杂,代码也是越来越多,流程越来越长。想看看地理位置是怎么保存的,于是就研究了一下OpenCamera的拍照流程。在回调时有点乱。 MainActivity clickedTakePhoto() takePicture() takePic…...
华为OD机考算法题:矩阵最大值
题目部分 题目矩阵最大值难度难题目说明给定一个仅包含 0 和 1 的 N*N 二维矩阵,请计算二维矩阵的最大值,计算规则如下: 1. 每行元素按下标顺序组成一个二进制数(下标越大越排在低位),二进制数的值就是该行…...
【Javascript】函数之形参与实参
function c(a,b){return ab;}var sumc(3,4);console.log(sum);a,b为形参 3,4为实参 形参和实参是⼀⼀对应的数量可以不对应参数的类型不确定函数可以设置默认参数实参可以是字⾯量也可以是变量...

PAT 乙级1090危险品装箱
题目: 集装箱运输货物时,我们必须特别小心,不能把不相容的货物装在一只箱子里。比如氧化剂绝对不能跟易燃液体同箱,否则很容易造成爆炸。 本题给定一张不相容物品的清单,需要你检查每一张集装箱货品清单,…...
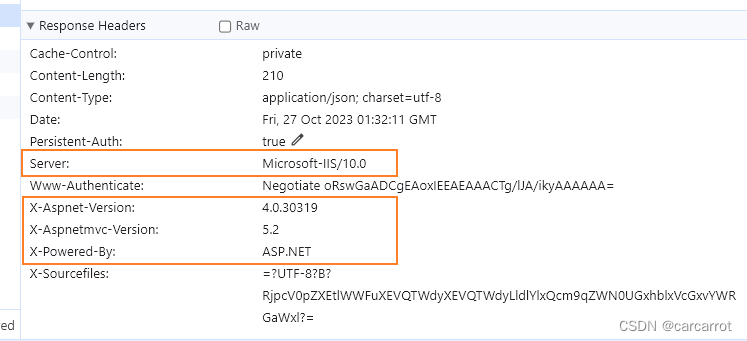
Response Header中不暴露Server(IIS)版本、ASP.NET及相关版本等信息
ASP MVC开发的Web默认情况下会在请求的回应中暴露Server、X-AspNet-Version、X-AspNetMvc-Version、X-Powered-By等相关服务端信息,公开这些敏感信息会存在一定的安全风险。 X-SourceFiles标头用于被IIS / IIS Express中某些调试模块理解,它包含到磁盘上…...
测试C#调用Vlc.DotNet组件播放视频
除了Windows Media Player组件,在百度上搜索到还有不少文章介绍采用Vlc.DotNet组件播放视频,关于Vlc.DotNet的详细介绍见参考文献1,本文学习Vlc.DotNet的基本用法。 VS2022中新建基于.net core的winform程序,在Nuget包管理器中…...
)
JS的事件委托(Event Delegation)
✨ 事件委托(Event Delegation)及其优势和缺点 🎃 什么是事件委托 事件委托是一种在JavaScript中处理事件的技术。它利用了事件的冒泡机制,将事件处理程序绑定到它们的共同祖先元素上,而不是直接绑定到每个子元素上。…...

selenium+python自动化安装驱动 碰到的问题
刚开始使用谷歌驱动,我的谷歌浏览器版本是最新版下载驱动地址,访问不了。 Chrome for Testing availability只能使用火狐驱动,我这里的火狐版本也是最新版119.0 查找全网找到驱动geckodriver下载地址 https://mirrors.huaweicloud.com/ge…...
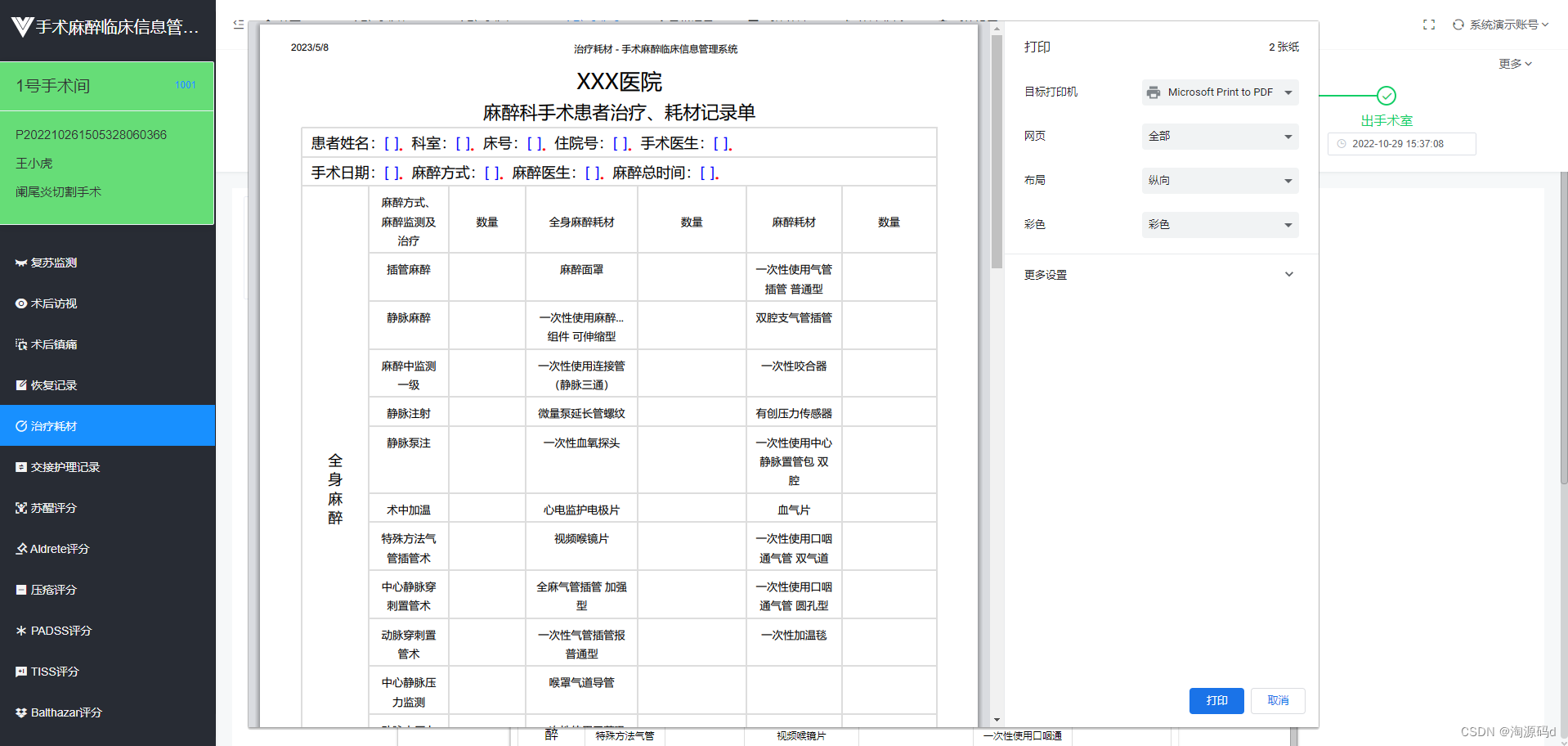
laravel+vue2 element 一套项目级医院手术麻醉信息系统源码
手术麻醉临床信息系统源码,PHPmysqllaravelvue2 手术麻醉临床信息系统,采用计算机和通信技术,实现监护仪、麻醉机、输液泵等设备输出数据的自动采集,采集的数据能够如实准确地反映患者生命体征参数的变化,并实现信息高…...

GEE——使用MODIS GPP和LAI数据进行一元线性回归计算和R2分析
使用两种方法计算一元线性回归,一种使用GEE本身自带的函数,另一种使用自己编写代码的方式进行,对比两者结果的差异。 简介 一元线性趋势分析是指利用一元线性回归模型来分析一组数据的趋势性。在一元线性回归模型中,我们假设自变量(x)和因变量(y)之间存在一定的线性关…...
[论文阅读]Point Density-Aware Voxels for LiDAR 3D Object Detection(PDV)
PDV Point Density-Aware Voxels for LiDAR 3D Object Detection 论文网址:PDV 论文代码:PDV 简读论文 摘要 LiDAR 已成为自动驾驶中主要的 3D 目标检测传感器之一。然而,激光雷达的发散点模式随着距离的增加而导致采样点云不均匀&#x…...
自动化学报格式 Overleaf 在线使用 【2023最新教程】
自动化学报格式 Overleaf 在线使用 摘要 2023年10月26日19:28:17(云南昆明) 今天课程老师要我们期末提交一篇论文,以自动化学报格式提交。因此,去官网发现只有 latex 格式,下载下来发现各种格式不兼容;由于…...

掌握CSS动画技巧:打造引人注目的页面过渡效果!
🎬 江城开朗的豌豆:个人主页 🔥 个人专栏 :《 VUE 》 《 javaScript 》 📝 个人网站 :《 江城开朗的豌豆🫛 》 ⛺️ 生活的理想,就是为了理想的生活 ! 目录 ⭐ 专栏简介 📘 文章引言 一…...

薛定谔的猫重出江湖?法国初创公司AliceBob研发猫态量子比特
总部位于巴黎的初创公司Alice&Bob使用超导芯片的两个相反的量子态(他们称之为“猫态量子比特”芯片)来帮助开发量子计算的不同自旋方式。(图片来源:网络) 有的人认为,构建量子计算机的模块模仿了著名的…...

Kafka Connect集群部署踩坑实录:从单机到高可用的完整配置与监控方案
Kafka Connect生产级部署实战:高可用架构设计与监控体系构建 当数据管道成为企业核心基础设施时,Kafka Connect的稳定性直接关系到业务连续性。去年某电商大促期间,因单点故障导致数据同步延迟6小时的教训仍历历在目——这正是我们需要深入探…...

GARbro:跨平台视觉小说游戏资源解析与提取工具
GARbro:跨平台视觉小说游戏资源解析与提取工具 【免费下载链接】GARbro Visual Novels resource browser 项目地址: https://gitcode.com/gh_mirrors/ga/GARbro GARbro是一款专门用于解析和提取视觉小说游戏资源文件的跨平台开源工具,支持数百种游…...

Touchpoint:命令行工具集中管理工作上下文,提升开发效率
1. 项目概述:一个被低估的开发者效率工具如果你和我一样,日常开发工作需要在多个代码仓库、项目管理工具(如Jira、Linear)、文档平台(如Confluence、Notion)和沟通软件(如Slack)之间…...

如何免费解锁WeMod专业版:2026年终极完整指南
如何免费解锁WeMod专业版:2026年终极完整指南 【免费下载链接】Wand-Enhancer Advanced UX and interoperability extension for Wand (WeMod) app 项目地址: https://gitcode.com/gh_mirrors/we/Wand-Enhancer 还在为WeMod专业版的高昂费用而烦恼吗…...

城通网盘解析工具终极指南:免费获取高速直连下载地址
城通网盘解析工具终极指南:免费获取高速直连下载地址 【免费下载链接】ctfileGet 获取城通网盘一次性直连地址 项目地址: https://gitcode.com/gh_mirrors/ct/ctfileGet 你是否厌倦了城通网盘那令人抓狂的下载速度?每次下载文件都要面对漫长的等待…...

如何快速突破平台限制:跨平台Steam创意工坊模组下载终极指南
如何快速突破平台限制:跨平台Steam创意工坊模组下载终极指南 【免费下载链接】WorkshopDL WorkshopDL - The Best Steam Workshop Downloader 项目地址: https://gitcode.com/gh_mirrors/wo/WorkshopDL 还在为Epic Games或GOG平台无法访问Steam创意工坊而烦恼…...

高性能键盘映射与SOCD清理架构解析:解决游戏输入冲突的技术方案
高性能键盘映射与SOCD清理架构解析:解决游戏输入冲突的技术方案 【免费下载链接】socd Key remapper for epic gamers 项目地址: https://gitcode.com/gh_mirrors/so/socd 在竞技游戏和高速动作游戏中,键盘输入的处理方式直接影响玩家的操作精度和…...

去中心化AI市场BloomBee:技术架构、挑战与开发者实践指南
1. 项目概述:当AI遇见去中心化,BloomBee想解决什么?最近在AI和Web3的交叉领域,一个名为BloomBee的项目引起了我的注意。它的名字很有意思,“Bloom”是开花、繁荣的意思,“Bee”是蜜蜂,合起来像是…...

如何选蜂蜜品牌?2026年5月推荐靠谱蜂蜜品牌避坑指南
一、引言买蜂蜜怕踩坑?市面上的蜂蜜产品琳琅满目,但勾兑蜜、浓缩蜜、添加糖浆的“科技蜜”层出不穷,消费者往往花了高价却买不到真正的纯正好蜜。对于注重健康饮食、追求天然原生态食品的消费者而言,如何从海量品牌中筛选出真正无…...

物联网安防系统故障排查与ESP8266固件刷写实战指南
1. 物联网安防系统故障排查实战做物联网安防系统,最怕的就是“哑火”。你花了好几天时间,把ESP8266、Raspberry Pi、MQTT Broker、Adafruit.IO和IFTTT像搭积木一样连起来,满心期待它能在关键时刻给你发条短信。结果,门被推开了&am…...