MySQL3:MySQL中一条更新SQL是如何执行的?
MySQL3:MySQL中一条更新SQL是如何执行的?
- MySQL中一条更新SQL是如何执行的?
- 1.Buffer Pool缓冲池
- 2.Redo log
- redo log作用
- Redo log文件位置
- redo log为什么是2个?
- 3.Undo log
- 4.更新过程
- 5.InnoDB官网架构
- InnoDB架构-内存结构
- ①Buffer Pool
- 内存的缓冲池写满了怎么办?
- 预读机制
- 线性预读和随机预读
- Buffer Pool List(LRU)官网架构
- Buffer Pool List冷热分离
- 为什么有Buffer Pool,二次查询相同SQL还是很慢?
- Buffer Pool总结
- ②Change Buffer写缓冲
- ③Adaptive Hash Index
- ④Redo Log Buffer
- Redo Log Buffe刷盘机制
- 总结
- InnoDB架构-磁盘结构
- InnoDB Doublewrite Buffer双写缓冲区
- 6.后台线程
- 7.Binlog
- MySQL合集
MySQL中一条更新SQL是如何执行的?
讲完了查询流程,我们是不是再讲讲更新流程、插入流程和删除流程?
在数据库里面,我们说的update操作其实包括了更新、插入和删除。如果大家有看 过MyBatis的源码,应该知道Executor里面也只有doQuery()和doUpdate()的方法, 没有doDelete()和dolnsert()。
更新流程和查询流程有什么不同呢?
基本流程也是一致的,也就是说,它也要经过解析器、优化器的处理,最后交给执 行器。区别就在于拿到符合条件的数据之后的操作。
1.Buffer Pool缓冲池
首先,对于InnoDB存储引擎来说,数据都是放在磁盘上的,存储引擎要操作数据, 必须先把磁盘里面的数据加载到内存里面才可以操作。
这里就有个问题,是不是我们需要的数据多大,我们就一次从磁盘加载多少数据到内存呢?比如我要读6个字节,磁盘就只返回6字节吗?
并不是,因为磁盘I/O的读写相对于内存的操作来说是很慢的。如果我们需要的数据分散在磁盘的不同的地方,那就意味着会产生很多次的I/O操作。所以,无论是操作系统也好,还是存储引擎也好,都有一个预读取的概念。也就是 说,当磁盘上的一块数据被读取的时候,很有可能它附近的位置也会马上被读取到,这个就叫做局部性原理。所以它会每次多读取一点,而不是用多少读多少。从磁盘读取数据到内存的最小的单位,叫做页,操作系统的页大小一般是4KB。
InnoDB也有这样的设置,在InnoDB里面,这个最小的单位默认是16KB大小。如果要修改这个值的大小,需要清空数据重新初始化服务。我们要操作的数据就在这样的页里面,数据所在的页叫数据页。
这里有一个问题,操作数据的时候,每次都要从磁盘读取到内存(再返回给Server),有没有什么办法可以提高效率?
还是缓存的思想。把读取过的数据页缓存起来。
InnoDB设计了一个内存的缓冲区,读取数据的时候,先判断是不是在这个内存区域里面,如果是,就直接读取,然后操作,不用再次从磁盘加载。如果不是,读取后就写到这个内存的缓冲区。这个内存区域有个专属的名字,叫缓冲池Buffer PooL。
修改数据的时候,也是先写入到Buffer PooL,而不是直接写到磁盘。内存的数据页和磁盘数据不一致的时候,我们把它叫做脏页。
那脏页什么时候才同步到磁盘呢?
InnoDB里面有专门的后台线程把Buffer Pool的数据写入到磁盘,每隔一段时间就一次性地把多个修改写入磁盘,这个动作就叫做刷脏。
总结:Buffer Pool的作用是为了提高读写的效率。
2.Redo log
思考一个问题:因为刷脏不是实时的,如果Buffer Pool里面的脏页还没有刷入磁盘时,也就是说,写入磁盘是有一个延时的过程,如果这个时候,数据库宕机或者重启,这些数据就会丢失。那怎么办呢?
所以内存的数据必须要有一个持久化的措施。为了避免这个问题,InnoDB把所有对页面的修改操作专门写入一个日志文件。如果有未同步到磁盘的数据,数据库在启动的时候,会从这个日志文件进行恢复操作(实现crash-safe)。我们说的事务的ACID里面D(持久性),就是用它来实现的。这个日志文件就是磁盘的redo log(重做日志)。
那么有个新的疑问,现在要写Buffer Pool,为了保证Buffer Pool的可用性还要做持久化,写redo log,那么同样需要写磁盘,为什么不直接写到dbfile里面去?为什么先写日志再写磁盘?是否性能上有差异呢?
写日志文件和和写到数据文件有什么区别?
我们先说一下磁盘寻址的过程。
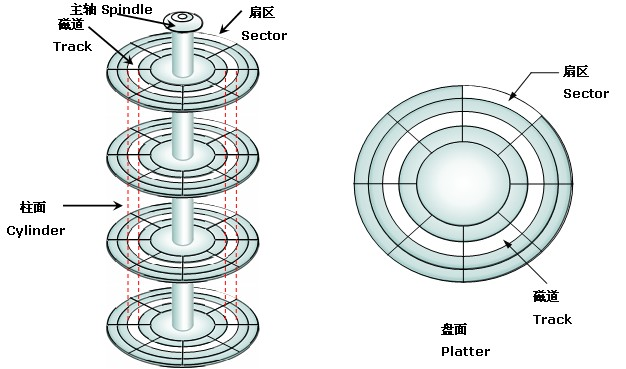
上图是磁盘的构造。
磁盘的盘片不停地旋转,磁头会在磁盘表面画出一个圆形轨迹,这个就叫磁道。从内到位半径不同有很多磁道。然后 又用半径线,把磁道分割成了扇区(两根射线之内的扇区组成扇面)。如果要读写数据,必须找到数据对应的扇区,这个过程就叫寻址。
如果我们所需要的数据是随机分散在磁盘上不同页的不同扇区中,那么找到相应的数据需要等到磁臂旋转到指定的页,然后盘片寻找到对应的扇区,才能找到我们所需要的一块数据,依次进行此过程直到找完所有数据,这个就是随机IO,读取数据速度较慢。
假设我们已经找到了第一块数据,并且其他所需的数据就在这一块数据后边,那么就不需要重新寻址,可以依次拿到我们所需的数据,这个就叫顺序IO。
刷盘是随机I/O,而记录日志是顺序I/O(连续写的),顺序I/O效率更高,本质上是数据集中存储和分散存储的区别。
redo log作用
因此先把修改写入日志文件,在保证了内存数据的安全性的情况下,可以延迟刷盘时机,进而提升系统吞吐量。
- redo log是InnoDB存储弓|擎实现的,并不是所有存储引擎都有。支持崩溃恢复 是InnoDB的一个特性。
- redo log不是记录数据页更新之后的状态,而是记录的是"在某个数据页上做了 什么修改”。属于物理日志。
- redo log的大小是固定的,前面的内容会被覆盖,一旦写满,就会触发刷盘操作,完成buffer pool到磁盘的同步,以便腾出空间记录后面的修改,因此这个值可以稍微设置大点。
在innodb中,除了redo log之外,还有一个跟修改有关的日志,叫做undo log。redo log和undo log与事务密切相关,统称为事务日志。
Redo log文件位置
redo log文件的位置是由datadir参数决定的。一般情况下,redo log文件位于数据目录(datadir)下,默认由两个文件ib_logfile0和ib_logfile1组成。每个48M。
下面命令可以查看到数据文件存储的位置。
show global variables like 'datadir%';
show variables like 'innodb_log%';
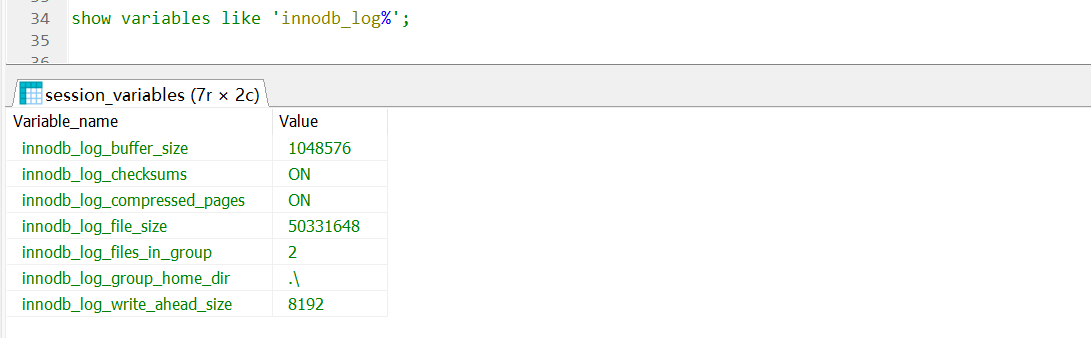
参数含义:
innodb_log_buffer_size:指定每个文件的大小,默认48M
innodb_log_file_size:指定每个文件的大小,默认48M
innodb_log_files_in_group:指定文件的数量,默认为2
innodb_log_group_home_dir:指定文件所在路径,相对或绝对。如果不指定,则为 datadir 路径
innodb_log_write_ahead_size:提前写入大小
redo log为什么是2个?
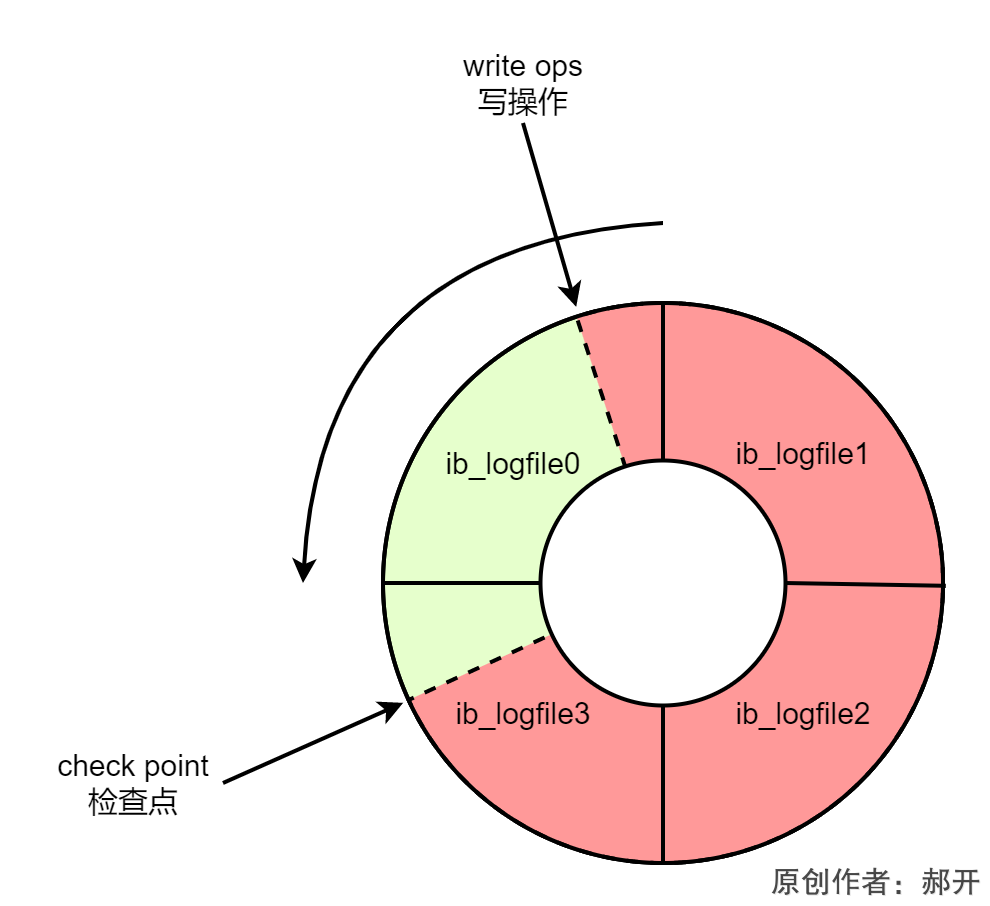
redo log的大小是固定的,所谓大小固定是指,它的结构是一个环状的,当新的内容写满了,会覆盖旧的内容,这个就是大小固定的意思。
它可以通过参数innodb_log_files_in_group来设置它的文件个数,可以通过innodb_log_buffer_size来指定每个redo log文件的大小,默认是两个文件,你设置成4就是4个文件。
所以在不断写的过程中,也需要不断地清理redo log的内容,如果一致不清理,那么当当前写的位置赶上了上一个清理的检查点的位置,那么就会触发buffer pool里面的内容刷盘。
3.Undo log
undo log(撤销日志或回滚日志)记录了事务发生之前的数据状态,分为insert undo log和update undo logo,如果修改数据时出现异常,可以用undo log来实现回滚操作(保持原子性)。
- undo log:记录的是反向的操作,比如insert会记录delete,update会记录update原来的值,所以叫做回滚日志
- redo log:记录在哪个物理页面做了什么操作不同,所以叫做逻辑格式的日志
show global variables like '%undo%';
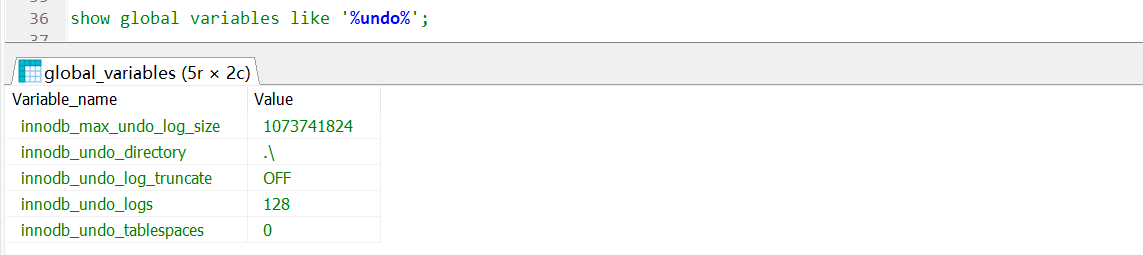
参数含义:
innodb_max_undo_log_size:如果innodb_undo_log_truncate设置为1,超过这个大小的时候会触发触发 truncate回收(收缩)动作,如果page大小是16KB, truncate后空间 缩小到10Mo默认1073741824字节二1G。
innodb_undo_directory:undo文件的路径
innodb_undo_log_truncate:设置为1,即开启在线回收(收缩;undo log 0志文件
innodb_undo_logs:回滚段的数量,默认128,这个参数已经过时。
innodb_undo_tablespaces:设置undo独立表空间个数,范围为0-95,默认为0,0表示不开启独立undo表空间,且undo日志存储在ibdata1文件中。这个参数已经过时。
redo log和undo log与事务密切相关,统称为事务日志。
4.更新过程
有了这些日志之后,我们来总结一下一个更新操作的流程,比如:将id=1001的数据,修改name原值是'小李',现在改为'小王'
update stu set name = '小王' where id=l001;
以下是一个简化的过程:
- 事务开始,从内存(buffer pool)或磁盘(data file)取到包含这条数据的数据
页,返回给Server的执行器; - Server的执行器修改数据页的这一行数据的值为 ‘小王’;
- 记录name=‘小李’ 到undo log,保证原子性;
- 记录name=‘小王’ 到redo log,保证持久性;
- 调用innodb存储引擎接口写入数据,记录数据页到Buffer Pool(修改name= ‘小王’);
- 事务提交。
5.InnoDB官网架构
了解了内存的Buffer Pool和磁盘的两个日志,我们也从总体上看下InnoDB的架构是什么样的。
下图是MySQL5.7的InnoDB的架构图
MySQL官方文档如何查看,MySQL中文文档
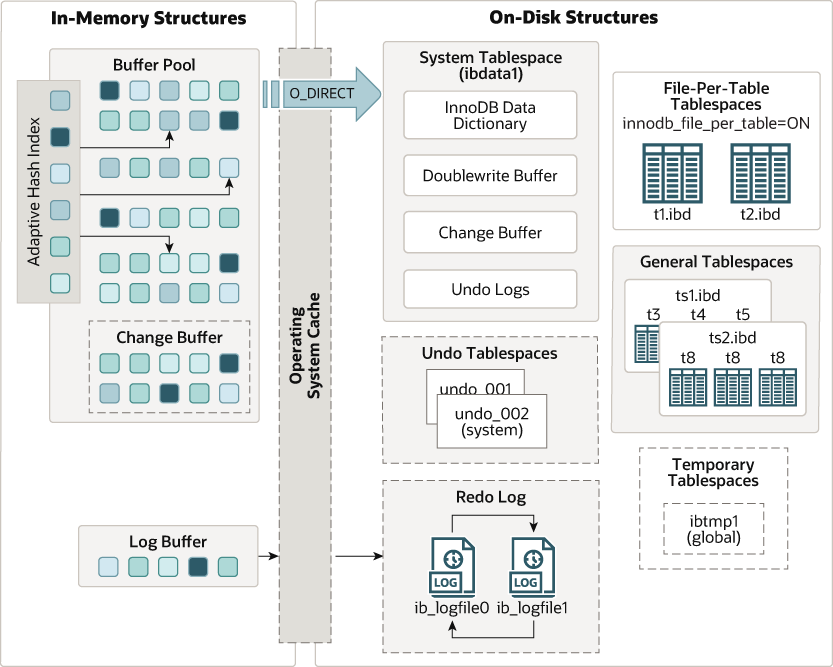
Buffer Pool主要分为3个部分:
Buffer Pool、Change Buffer、Adaptive Hash Index,另外还有一个(redo)log buffer。
左边为In-Memory Structures(内存结构),右边为On-Disk Structures(磁盘结构)。
InnoDB架构-内存结构
①Buffer Pool
Buffer Pool缓存的是页面信息,包括数据页、索引页。
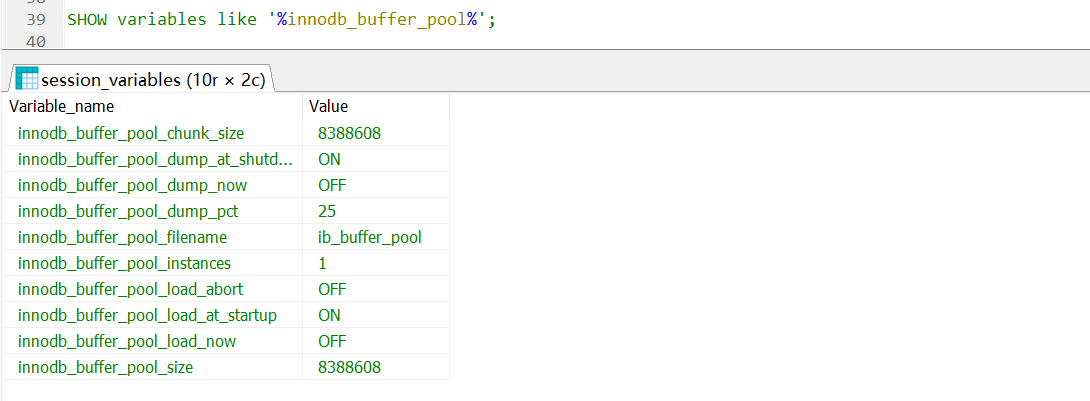
Buffer Pool在Linux系统下默认大小是128M(134217728字节),在Windows系统下是8M(8388608字节),可以调整。
査看系统变量:
SHOW VARIABLES like '%innodb_buffer_pool%‘;
查看服务器状态,里面有很多跟Buffer Pool相关的信息:
SHOW STATUS LIKE '%innodb_buffer_pool%‘;
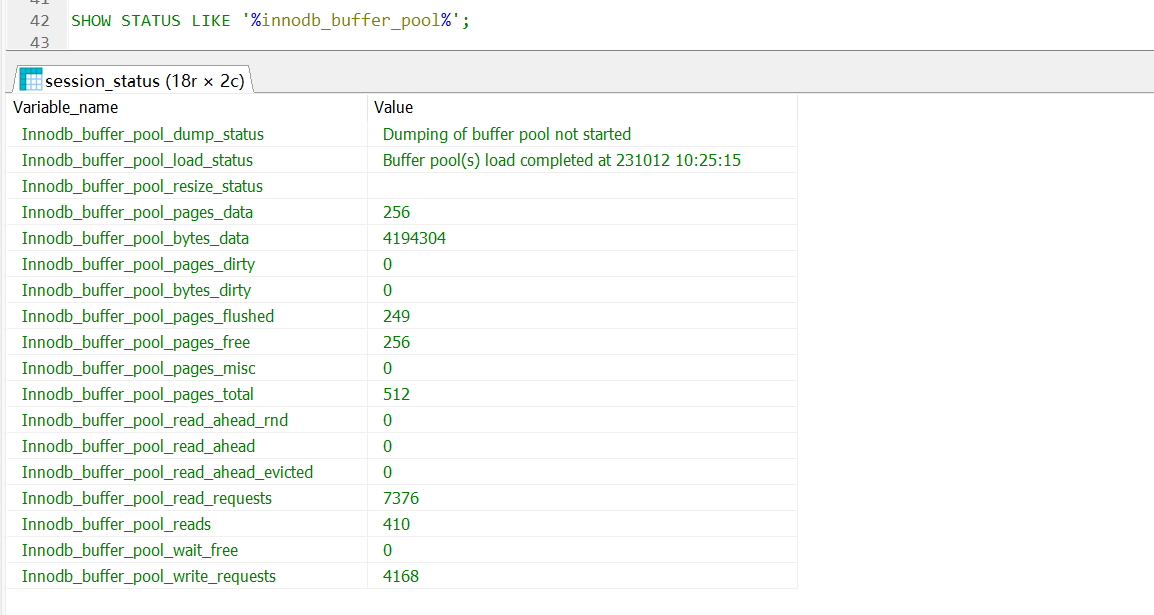
这些参数都可以在官网查到详细的含义,用搜索功能。
https://dev.mysql.com/doc/refman/5.7/en/server-system-variables.html
内存的缓冲池写满了怎么办?
InnoDB用LRU算法来管理缓冲(链表实现,不是传统的LRU,分成了young和old),经过淘汰的数据就是热点数据。
传统LRU,可以用Map+链表实现。value存的是在链表中的地址。
InnoDB中确实使用了一个双向链表,LRU list,也叫Buffer Pool List,它里面放的不是data page,而是指向缓存页的指针。
如果写buffer pool的时候发现没有空闲页了,就要从buffer pool中淘汰数据页了,它要根据LRU链表的数据来操作。
预读机制
首先,InnoDB的数据页并不是都在访问的时候才缓存到buffer pool的。
InnoDB有一个预读机制(read ahead)。也就是说,设计者认为访问某个page的数据的时候,相邻的一些page可能会很快被访问到,所以先把这些page放到buffer pool中缓存起来。
https://dev.mysql.com/doc/refman/5.7/en/innodb-performance-read_ahead.html
线性预读和随机预读
这种预读的机制又分为两种类型:
- Linear read-ahead——线性预读(异步的)
- 为了便于管理,InnoDB中把64个相邻的page叫做一个extent(区)。如果顺序地访问了一个extent的56个page,这个时候InnoDB就会把下一个extent(区)缓存到buffer pool。顺序访问多少个page才缓存下一个extent,由
innodb_read_ahead_threshold参数控制:show variables like '%innodb_read_ahead_threshold%';
- 为了便于管理,InnoDB中把64个相邻的page叫做一个extent(区)。如果顺序地访问了一个extent的56个page,这个时候InnoDB就会把下一个extent(区)缓存到buffer pool。顺序访问多少个page才缓存下一个extent,由
- Random read-ahead——随机预读
- 如果buffer pool已经缓存了同一个extent(区)的数据页的个数超过13时,就会把这个extent剩余的所有page全部缓存到buffer pool。随机预读的功能默认是不启用的,由
innodb_random_read_ahead参数控制:show variables like '%innodb_random_read_ahead%';
- 如果buffer pool已经缓存了同一个extent(区)的数据页的个数超过13时,就会把这个extent剩余的所有page全部缓存到buffer pool。随机预读的功能默认是不启用的,由
很明显,线性预读或者异步预读,都能够把可能即将用到的数据提前加载到buffer pool,肯定能提升I/O的性能,所以是一种非常有用的机制。
但是预读肯定也会带来一些副作用,就是导致占用的内存空间更多,剩余的空闲页更少。如果说buffer pool size不是很大,而预读的数据很多,很有可能那些真正的需要被缓存的热点数据被预读的数据挤出buffer pool,淘汰掉了,下次访问的时候又要先去磁盘。怎么让这些真正的热点数据不受到预读的数据的影响呢?
从Buffer Pool List的架构来入手,看看它是如何设计的。
Buffer Pool List(LRU)官网架构
Buffer Pool List官网架构图:https://dev.mysql.com/doc/refman/5.7/en/innodb-buffer-pool.html
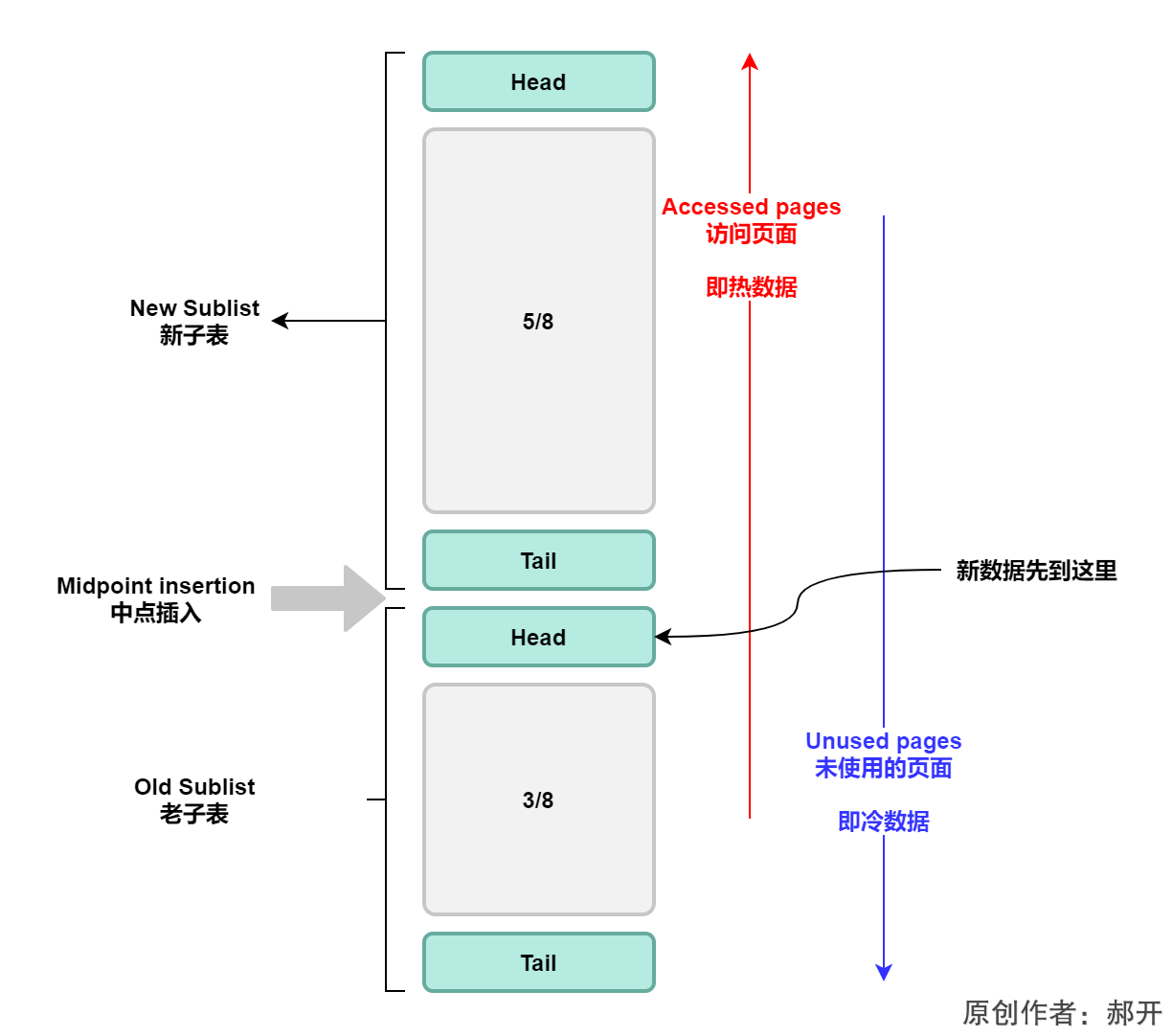
Buffer Pool List冷热分离
从Buffer Pool List官网架构可以得知,InnoDB是把LRU list分成了两部分,通过中间的分割线叫做Midpoint insertion(中点插入),也就是对buffer pool做一个冷热分离:
- new sublist:靠近head的叫做new sublist,用来放热数据(我们把它叫做热区)
- old sublist:靠近tail的叫做old sublist,用来放冷数据(我们把它叫做冷区)
所有新数据加入到buffer pool的时候,一律先放到冷数据区的head,不管是预读的,还是普通的读操作。所以如果有一些预读的数据没有被用到,会在old sublist(冷区)直接被淘汰。
放到LRU List以后,如果再次被访问,就把它移动到热区的head。如果热区的数据长时间没有被访问,会被先移动到冷区的head部,最后慢慢在tail被淘汰。
在默认情况下,热区占了5/8的大小,冷区占了3/8,这个值由参数innodb_old_blocks_pct控制,它代表的是old区的大小,默认是37%也就是3/8。
show variables like '%innodb_old_blocks_pct%';

innodb_old_blocks_pct的值可以调整,在5%到95%之间,这个值越大,new区越小,这个LRU算法就接近传统LRU。如果这个值太小,old区没有被访问的速度淘汰会更快。
预读的问题,通过冷热分离解决了,还有没有其他的问题呢?
我们先把数据放到冷区,用来避免占用热数据的存储空间。但是如果刚加载到冷区的数据立即被访问了一次,按照原来的逻辑,这个时候我们会马上把它移动至热区。假设这一次加载然后被立即访问的冷区数据量非常大,比如我们查询了一张几 千万数据的大表,没有使用索引,做了一个全表扫描;或者dump全表备份数据,这种查询属于短时间内访问,后面再也不会用到了。
如果短时间之内被访问了一次,导致它们全部被移动到热区的head,它会导致很多热点数据被移动到冷区甚至被淘汰,造成了缓冲池的污染。这个问题我们又怎么解决呢?
对于加载到冷区然后被访问的数据,设置一个时间窗口,只有超过这个时间之后被访问,我们才认为它是有效的访问。
InnoDB 里面通过innodb_old_blocks_time这个参数来控制,默认是1秒钟。
show variables like '%innodb_old_blocks_time%';

也就是说1秒钟之内被访问的,不算数,待在冷区不动。只有1秒钟以后被访问的,才从冷区移动到热区的head。这样就可以从很大程度上避免全表扫描或者预读的数据污染真正的热数据。
似乎比较完美了,还有没有可以优化的空间呢?
InnoDB支持读写并发,写不阻塞读(MVCC)。那么为了避免并发的问题,对于LRU链表的操作是要加锁的。也就是说每一次链表的移动,都会带来资源的竞争和等待。从这个角度来说,如果要进一步提升InnoDB LRU的效率,就要尽量地减少LRU链表的移动。
比如,把热区一个非常靠近head的page移动到head,有没有这个必要呢?
所以InnoDB对于new区还有一个特殊的优化:
如果一个缓存页处于热数据区域,且在热数据区域的前1/4区域(注意是热数据区域的1/4,不是整个链表的1/4),那么当访问这个缓存页的时候,就不用把它移动到热数据区域的头部;如果缓存页处于热区的后3/4区域,那么当访问这个缓存页的时候,会把它移动到热区的头部。
为什么有Buffer Pool,二次查询相同SQL还是很慢?
InnoDB中有Buffer Pool,二次查询相同SQL会优先查询Buffer Pool中的数据,但是如果你的查询结果超过了Buffer Pool的大小,根据LRU淘汰算法,那么一下就会将原来Buffer Pool加载进来的数据,全部挤出去,尤其是在做全表扫描的时候。
show VARIABLES LIKE '%innodb_buffer_pool_size%';

可以看到,Windows环境下,默认buffer pool大小为8388608 bytes,也就是8M,old区3M,young区5M,在全表扫描的过程中,所有的page都会加入old区的头部。
从page中找到对应行的时候,所有的page都会移动到new区的头部,因为容量有限,前面的数据也全部被淘汰了。因此,可以将buffer pool调大,再进行测试。
通常来说,我们建议一个比较合理的、健康的比例,是给buffer pool设置你的机器内存的50%~60%左右 比如你有32GB的机器,那么给buffer设置个20GB的内存,剩下的留给OS和其他人来用,这样比较合理一些。 假设你的机器是128GB的内存,那么buffer pool可以设置个80GB左右,大概就是这样的一个规则。
Buffer Pool总结
内存缓冲区对于提升读写性能有很大的作用。当需要更新一个数据页时,如果数据页在Buffer Pool中存在,那么就直接更新好了。否则的话就需要从磁盘加载到内存,再对内存的数据页进行操作。也就是说,如果没有命中缓冲池,至少要产生一次磁盘IO,有没有优化的方式呢?
②Change Buffer写缓冲
Change Buffer是Buffer Pool的一部分,可以大大提升非唯一性索引的增删改效率。
如果这个数据页不是唯一索引,不存在数据重复的情况(或者说你的业务允许这些数据重复,因此没有使用unique),也就不需要从磁盘加载索引页判断数据是不是重复(唯一性检查)。这种情况下可以先把修改记录在内存的缓冲池中,从而提升更新语句(Insert、Delete、Update)的执行速度。
这一块区域就是Change Buffer,MySQL 5.5之前叫Insert Buffer(插入缓冲),现在也能支持 delete 和 update。最后把Change Buffer记录到数据页的操作叫做merge。
什么时候发生merge?分以下几种情况:
- 在访问这个数据页的时候
- 通过后台线程、或者数据库shut down
- redo log写满时触发
可以通过参数innodb_change_buffer_max_size来查看Change Buffer占Buffer Pool的比例。
show variables like '%innodb_change_buffer_max_size%';

如果数据库大部分索引都是非唯一索引,并且业务是写多读少,不会在写数据后立 刻读取,就可以使用Change Buffer(写缓冲)。Change Buffer占Buffer Pool的比例默认25%;可以调大这个值,来扩大Change Buffer的大小,以支持写多读少的业务场景。
③Adaptive Hash Index
自适应的hash索引。
索引应该是放在磁盘的,为什么要专门把一种哈希的索引放到内存?
在InnoDB中,不能显式地创建一个哈希索引,所谓的InnoDB支持hsh索引,指Adaptive Hash Index——自适应的hash索引,它是在内存中进行维护的,为什么要专门把一种哈希的索引放到内存?它是InnoDB自动为buffer pool中的热点页创建的索引,这个hash索引是InnoDB去维护的,我们不能干涉。
④Redo Log Buffer
Redo log也不是每一次都直接写入磁盘,在Buffer Pool里面有一块内存区域(Log
Buffer)专门用来保存即)镀写入日志文件的数据,默认16M,其设计初衷也是一样为了较少磁盘IO。
SHOW VARIABLES LIKE '%innodb_log_buffer_size%';

需要注意:redo log的内容主要是用于崩溃恢复。磁盘的数据文件,数据来自buffer pool,redo log写入磁盘,不是写入数据文件。
Redo Log Buffe刷盘机制
在我们写入数据到磁盘的时候,操作系统本身是有缓存的。flush就是把操作系统缓冲区写入到磁盘,也叫刷盘。
log buffer写入磁盘的时机,由参数innodb_flush_log_at_trx_commit的状态控制刷盘时机,默认是1,实时写。
SHOW VARIABLES LIKE '%innodb_flush_log_at_trx_commit%';

log buffer写入磁盘的时机一共由三种状态,分别是0,1,2,如下图:
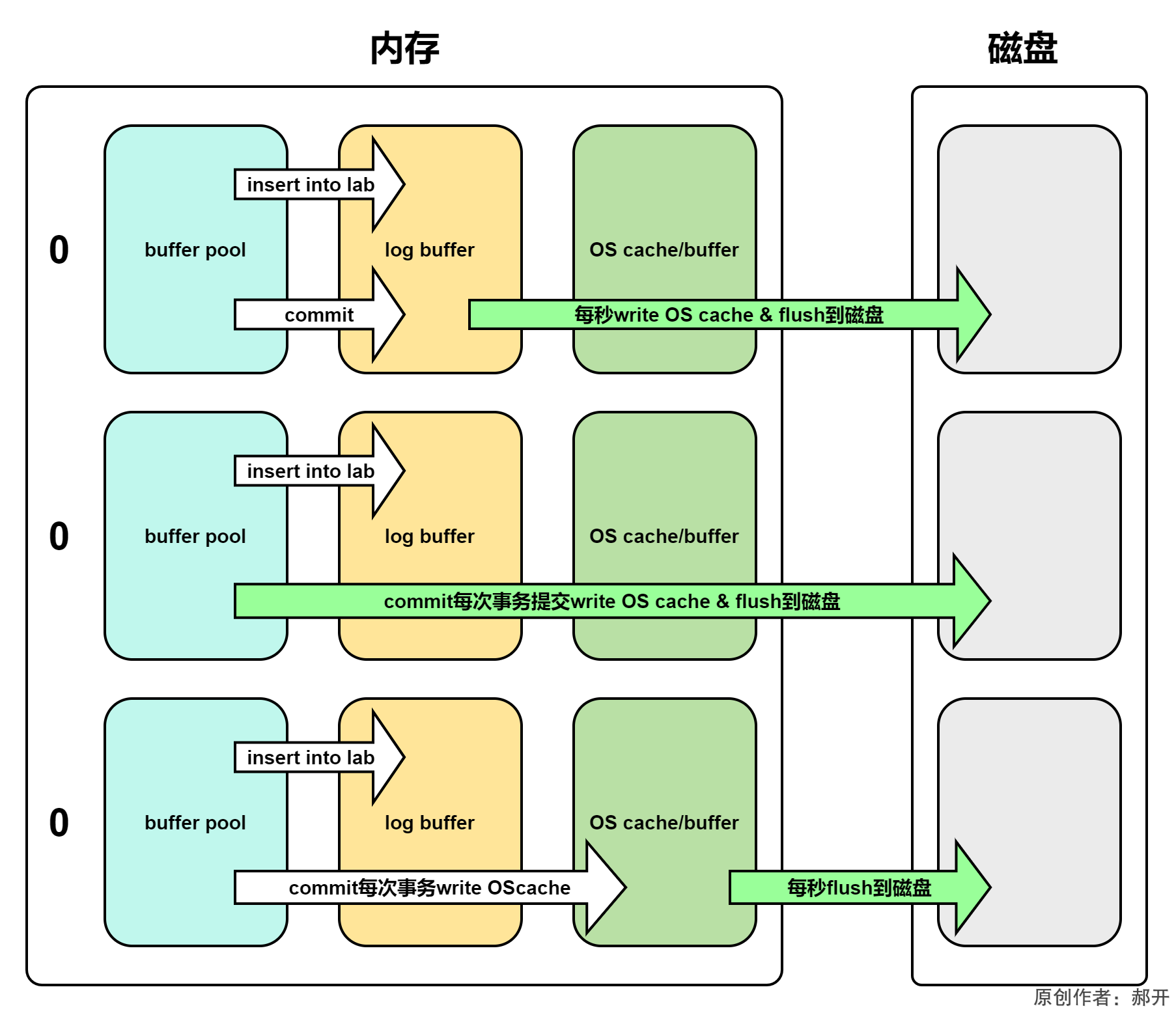
- 0 :延退写。log buffer将每秒一次地写入log file中,并且log file的flush操作同时进行。该模式下,在事务提交的时候,不会主动触发写入磁盘的操作。
- 1 :默认,实时写,实时刷。每次事务提交时MySQL都会把log buffer的数据写入log file,并且刷到磁盘 中去。
- 2 :实时写,延迟刷。每次事务提交时MySQL都会把log buffer的数据写入log file。但是flush操作并不会同时进行。该模式下,MySQL会每秒执行一次flush操作。
刷盘越快,越安全,但是也会越消耗性能;反之,你更想提升性能,你认为你的MySQL足够稳定,崩溃或者重启的情况是很少的,就可以尽量将log buffer的内容晚一点写入磁盘中去,这样性能吞吐量上去了,但是可靠性降低了。
总结
以上是MySQL的InnoDB架构-内存结构,分为:
Buffer pool、change buffer、Adaptive Hash Index、log buffer。
InnoDB架构-磁盘结构
下面我们来看一下磁盘结构,磁盘结构里面主要是各种各样的表空间,叫做Table space。
表空间可以看做是InnoDB存储引擎逻辑结构的最高层,所有的数据都存放在表空 间中。InnoDB的表空间分为5大类:
- System Tablespace:InnoDB存储引擎有一个共享表空间,在默认情况下,所有的表共享一个系统表空间,这个文件会越来越大,而且它的空间不会收缩。它是一个文件,就是
ibdata1这个文件,文件的位置是由datadir参数决定的。文件里面会存很多的内容,包括如下:- InnoDB Data Dictionary:InnoDB数据字典。所谓数据字典就是表结构定义的那些相关元数据的信息。
- Doublewrite Buffer:双写缓冲区,InnoDB的一大特性,独有的设计。
- Change Buffer:写缓冲区。它同时也作为内存的一个区域划分,因此磁盘中也会有这样一个操作。
- Undo logs:有了Undo Tablespace,为什么这里还要Undo logs?你既可以把undo log放在系统表空间存储,也可以把undo log独立出来,放在它自己的表空间中,只是在那里存的区别
- 如果没有指定File-Per-Table Tablespace,也包含用户创建的表和索引数据
- Undo Tablespace:能够提供回滚的操作来保证原子性。undo log的数据默认在系统表空间
ibdata1文件中,因为共享表空间不会自动收
缩,也可以单独创建一个undo表空间 - Redo Log:log buffer的数据会通过到此,主要是用于崩溃恢复
- File-Per-Table Tablespace:独占表空间
-
我们可以让每张表独占一个表空间。这个开关通过
innodb_file_per_table设置,默认开启。SHOW VARIABLES LIKE '%innodb_file_per_table%';
开启后,则每张表会开辟一个表空间,这个文件就是数据目录下的ibd文件,存放表的索引和数据。但是其他类的数据,如回滚(undo)信息,插入缓冲索引页、系统事务信息,二次写缓冲(Double write buffer)等还是存放在原来的共享表空间内。
-
- General Tablespace:通用表空间,多个表共享。也是一种共享的表空间,跟ibdata1类似。
-
可以创建一个通用的表空间,用来存储不同数据库的表,数据路径(路径要用
'/'而不是'\','\'会语法错误)和文件可以自定义,没有指定存储目录,使用的是默认存储路径。语法:create tablespace mytblspace add datafile 'C:/ProgramData/MySQL/mytblspace/mytblspace.ibd' file_block_size= 16K engine=innodb; create tablespace mytblspace1 add datafile 'mytblspace1.ibd' file_block_size= 16K engine=innodb;查看已存在的表空间和对应的文件
select TABLESPACE_NAME,FILE_NAME from information_schema.FILES;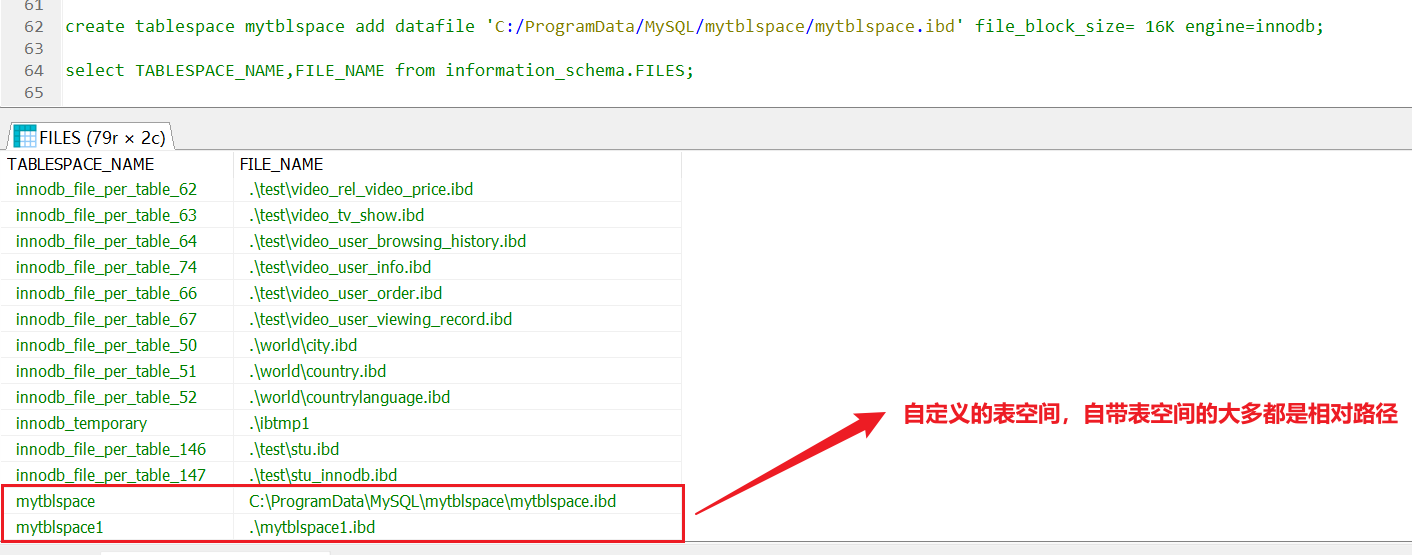
查看表空间文件

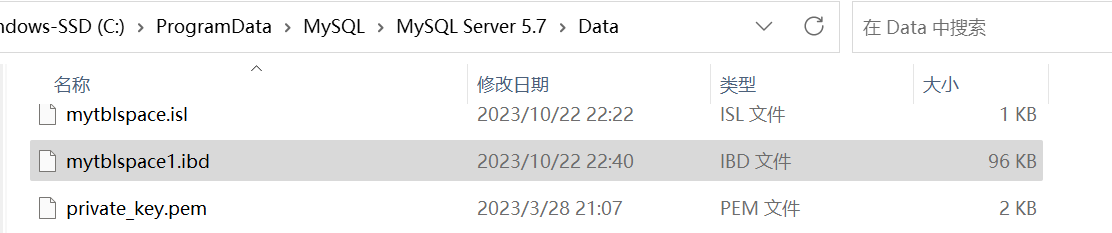
在创建表的时候可以指定表空间,用ALTER修改表空间可以转移表空间。create table mytbl(id integer) tablespace mytblspace ;表导出为SQL脚本的时候可以看到会指定表空间

不同表空间的数据是可以移动的,删除表空间需要先删除里面的所有表:
drop table mytbl; drop tablespace mytblspace ;
-
- Temporary Tablespace:临时表空间,存储系统临时的一些数据。比如用户创建的临时表,还有磁盘去做数据排序的时候,要占用磁盘的一块临时空间。它是一个文件,就是
ibtmp1这个文件,文件的位置是由datadir参数决定的。
InnoDB Doublewrite Buffer双写缓冲区
Doublewrite Buffer它是页的一个备份,它保证了内存同步磁盘的可靠性。解决防止页写到一半,没写完,被破坏了,而没法恢复。
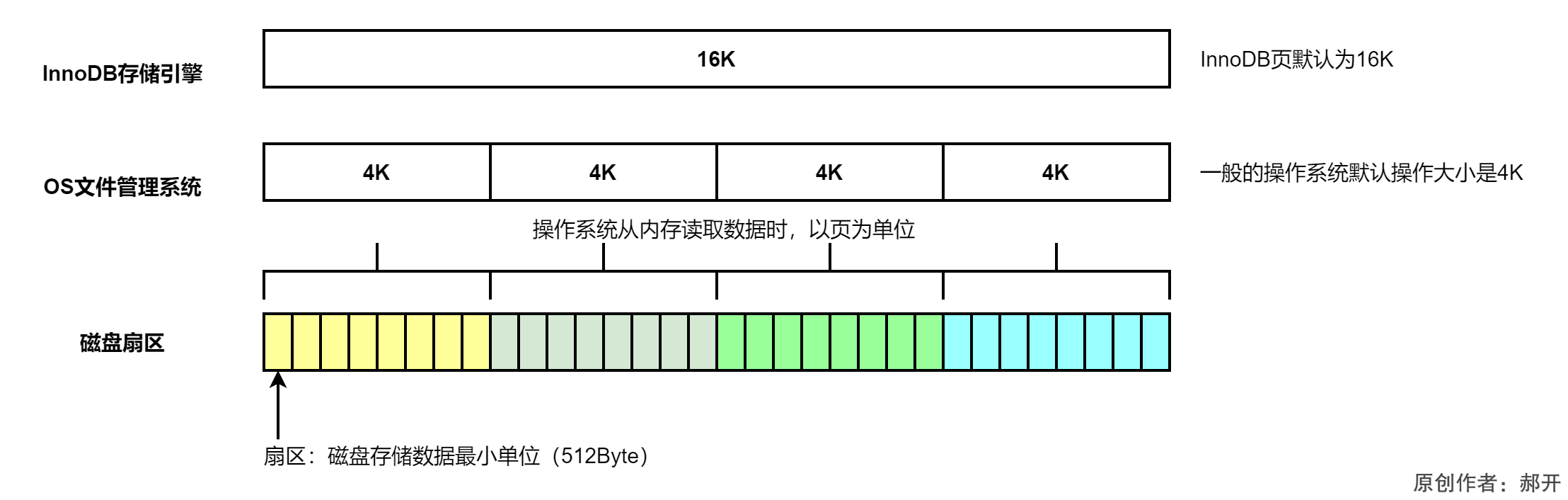
InnoDB的页和操作系统的页大小不一致,InnoDB页大小一般为16K,InnoDB存储引擎16K,操作系统页 大小为4K,InnoDB的页写入到磁盘时,一个页需要分4次写。
操作系统从内存读取数据时,以页为单位,如果存储引擎正在写入页的数据到磁盘时发生了宕机,可能出现页只写了一部分的情况,比如只写了 4K,就宕机了,这种情况叫做部分写失效(partial page write),可能会导致数据丢失。
show variables like Innodb doublewrite1;
我们不是有redo log吗?是否可以基于redo log将没有写完的16K的文件做一个恢复呢?
这里有个问题,当你把内存的16K的内容写到磁盘的16K的内容,因为只写了一个4K,已经导致磁盘页上的内容遭到破坏了,这个磁盘上的页已经不完整了,那么用它来做崩溃恢复是没有意义的。
所以在对于应用red log之前,需要一个页的副本。如果出现了 写入失效,就用页的副本来还原这个页,然后再应用redo log。这个页的副本就是double write, InnoDB的双写技术,通过它实现了数据页的可靠性。
跟redo log —样,double write由两部分组成,一部分是内存的double write, —个部分是磁盘上的double write。因为double write是顺序写入的,不会带来很大的开销。
6.后台线程
后台线程的主要作用是负责刷新内存池中的数据和把修改的数据页刷新到磁盘。后 台线程分为:master thread,IO thread,purge thread,page cleaner thread。- - - master thread:负责刷新缓存数据到磁盘并协调调度其它后台进程。
- IO thread:分为 insert buffer、log、read、write 进程。分别用来处理 insert buffer. 重做日志、读写请求的io回调。
- purge thread:用来回收 undo 页。
- page cleaner thread:用来刷新脏页。
7.Binlog
除了InnoDB架构中的日志文件,MySQL的Server层也有一个日志文件,叫做 binlog,它可以被所有的存储引擎使用。
binlog以事件的形式记录了所有的DDL和DML语句(因为它记录的是操作而不是
数据值,属于逻辑日志),可以用来做主从复制和数据恢复。
跟redo log不一样,它的文件内容是可以追加的,没有固定大小限制。
在开启了 binlog功能的情况下,我们可以把binlog导出成SQL语句,把所有的操
作重放一遍,来实现数据的恢复。
binlog的另一个功能就是用来实现主从复制,它的原理就是从服务器读取主服务器 的binlog,然后执行一遍。
有了这两个日志之后,我们来看一下一条更新语句是怎么执行的(redo不能一次写
入了):
有了这些日志之后,我们来总结一下一个更新操作的流程,这里redo log是两阶段提交,比如:将id=1001的数据,修改name原值是'小李',现在改为'小王':
update stu set name = '小王' where id=1001;

- 先查询到这条数据,如果有缓存,也会用到缓存。
- 把name改成盆鱼宴,然后调用引擎的API接口,写入这一行数据到内存, 同时InnoDB记录redo logo这时redo log进入prepare状态,然后告诉执行器,执行完成了,可以随时提交。
- 执行器收到通知后记录binlog,然后调用存储引擎接口提交事务,InnoDB设置redo log为commit状态。
- 更新完成。
图中重点步骤:
- 先记录到内存,再写日志文件。
- 记录redo log分为两个阶段。
- 存储引擎和Server记录不同的日志。
- 先记录redo,再记录binloq。
为什么需要两阶段提交?
两阶段提交的作用,就是提供一个可以协调的机制,如果一次写完,那么是没有办法做到你成功他失败的,因此MySQL中设置了两阶段提交的方式,来保证redo log和binlog的内容是一致的。
举例:
如果我们执行的是把name改成'小王',如果写完redo log,在还没有写binlog的时候,MySQL重启了。因为redo log可以在重启的时候用于恢复数据,所以写入磁盘的是'小王',但是 binlog里面没有记录这个逻辑日志,所以这时候用binlog去恢复数据或者同步到从库, 就会出现数据不一致的情况。
所以在写两个日志的情况下,binlog就充当了一个事务的协调者。通知InnoDB来执行prepare或者commit或者rollback。
如果第⑥步Server层写入binlog失败,就不会提交。
简单地来说,这里有两个写日志的操作,类似于分布式事务,不用两阶段提交,就
不能保证都成功或者都失败。
在崩溃恢复时,判断事务是否需要提交:
- binlog无记录,redo log无记录:在redo log写之前crash(崩溃),恢复操作:回滚事务
- binlog无记录, redo log状态prepare:在binlog写完之前的crash(崩溃),恢复操作:回滚事务
- binlog有记录,redo log状态prepare:在binlog写完提交事务之前的crash(崩溃),恢复操作:提交事务
- binlog有记录,redo log状态commit:正常完成的事务,不需要恢复
如果binlog不开启,redo log也就不需要两阶段提交了,因为不需要保证和binlog的内容一致,它也不会影响到主从复制,和基于binlog的数据恢复。
MySQL合集
MySQL1:MySQL发展史,MySQL流行分支及其对应存储引擎
MySQL2:MySQL中一条查询SQL是如何执行的?
MySQL3:MySQL中一条更新SQL是如何执行的?
MySQL4:索引是什么;索引类型;索引存储模型发展:1.二分查找,2.二叉查找树,3.平衡二叉树,4.多路平衡查找树,5. B+树,6.索引为什么不用红黑树?7.InnoDB的hash索引指什么?
MySQL5:MySQL数据存储文件;MylSAM中索引和数据是两个独立的文件,它是如何通过索引找到数据呢?聚集索引/聚簇索引,InnoDB中二级索引为什么不存地址而是存键值?row ID如何理解?
相关文章:
MySQL3:MySQL中一条更新SQL是如何执行的?
MySQL3:MySQL中一条更新SQL是如何执行的? MySQL中一条更新SQL是如何执行的?1.Buffer Pool缓冲池2.Redo logredo log作用Redo log文件位置redo log为什么是2个? 3.Undo log4.更新过程5.InnoDB官网架构InnoDB架构-内存结构①Buffer …...

p5.js map映射
本文简介 带尬猴,我嗨德育处主任 p5.js 为开发者提供了很多有用的方法,这些方法实现起来可能不难,但却非常实用,能大大减少我们的开发时间。 本文将通过举例说明的方式来讲解 映射 map() 方法。 什么是映射 从 p5.js 文档 中可…...
idea提交代码冲突后,代码意外消失解决办法
敲了大半天的代码,解决冲突后,直接消失了当时慌的一批CCCCC 右击项目Local History ----show History 找到最近提交的内容右击选择Revert,代码全回来了...
爬虫批量下载科研论文(SciHub)
系列文章目录 利用 eutils 实现自动下载序列文件 提示:写完文章后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 系列文章目录前言一、获取文献信息二、下载文献PDF文件参考 前言 大家好✨,这里是bio🦖。…...

explain查询sql执行计划返回的字段的详细说明
当使用EXPLAIN命令查看SQL语句的执行计划时,会返回一张表格,其中包含了该SQL语句的执行计划。下面是每个字段的详细分析: id:执行计划的唯一标识符。如果查询中有子查询,每个子查询都会有一个唯一的ID。在执行计划中&a…...

讯飞输入法13.0发布,推出行业首款生成式AI输入法
🦉 AI新闻 🚀 讯飞输入法13.0发布,推出行业首款生成式AI输入法 摘要:科大讯飞在2023年全球开发者节上发布了全新讯飞输入法13.0版本,其中最大的亮点是推出了行业首款生成式AI输入法。这次升级将生成式AI能力融入输入…...

35. 搜索插入位置、Leetcode的Python实现
博客主页:🏆看看是李XX还是李歘歘 🏆 🌺每天分享一些包括但不限于计算机基础、算法等相关的知识点🌺 💗点关注不迷路,总有一些📖知识点📖是你想要的💗 ⛽️今…...

使用 DDPO 在 TRL 中微调 Stable Diffusion 模型
引言 扩散模型 (如 DALL-E 2、Stable Diffusion) 是一类文生图模型,在生成图像 (尤其是有照片级真实感的图像) 方面取得了广泛成功。然而,这些模型生成的图像可能并不总是符合人类偏好或人类意图。因此出现了对齐问题,即如何确保模型的输出与…...

cocosCreator 之 crypto-es数据加密
版本: 3.8.0 语言: TypeScript 环境: Mac 简介 项目开发中,针对于一些明文数据,比如本地存储和Http数据请求等,进行加密保护,是有必要的。 关于加密手段主要有: 对称加密 使用相…...

Leetcode---368周赛
题目列表 2908. 元素和最小的山形三元组 I 2909. 元素和最小的山形三元组 II 2910. 合法分组的最少组数 2911. 得到 K 个半回文串的最少修改次数 一、元素和最小的山形三元组I 没什么好说的,不会其他方法就直接暴力,时间复杂度O(n^3),代…...
矢量图形编辑软件Illustrator 2023 mac中文版软件特点(ai2023) v27.9
illustrator 2023 mac是一款矢量图形编辑软件,用于创建和编辑排版、图标、标志、插图和其他类型的矢量图形。 illustrator 2023 mac软件特点 矢量图形:illustrator创建的图形是矢量图形,可以无限放大而不失真,这与像素图形编辑软…...

一、Docker Compose——什么是 Docker Compose
Docker Compose 是一个用来定义和运行多容器 Docker 应用程序的工具,他的方便之处就是可以使用 YAML 文件来配置将要运行的 Docker 容器,然后使用一条命令即可创建并启动配置好的 Docker 容器了;相比手动输入命令的繁琐,Docker Co…...

Java提升技术,进阶为高级开发和架构师的路线
原文网址:Java提升技术,进阶为高级开发和架构师的路线-CSDN博客 简介 Java怎样提升技术?怎样进阶为高级开发和架构师?本文介绍靠谱的成长路线。 首先点明,只写业务代码是无法成长技术的。提升技术的两个方法是&…...

记一次 .Net+SqlSugar 查询超时的问题排查过程
环境和版本:.Net 6 SqlSuger 5.1.4.* ,数据库是mysql 5.7 ,数据量在2000多条左右 业务是一个非常简单的查询,代码如下: var list _dbClient.Queryable<tb_name>().ToList(); tb_name 下配置了一对多的关系…...
PHP危险函数
PHP危险函数 文章目录 PHP危险函数PHP 代码执行函数eval 语句assert()语句preg_replace()函数正则表达式里修饰符 回调函数call_user_func()函数array_map()函数 OS命令执行函数system()函数exec()函数shell_exec()函数passthru() 函数popen 函数反引号 实列 通过构造函数可以执…...

【ARM Cortex-M 系列 4 番外篇 -- 常用 benchmark 介绍】
文章目录 1.1 CPU 性能测试 MIPS 计算1.1.1 Cortex-M7 CPI 1.2 benchmark 小节1.3.1 Geekbenck 介绍 1.3 编译参数配置 1.1 CPU 性能测试 MIPS 计算 每秒百万指令数 (MIPS):在数据压缩测试中,MIPS 每秒测量一次 CPU 执行的低级指令的数量。越高越好&…...
web安全-原发抗抵赖
原发抗抵赖 原发抗抵赖也称不可否认性,主要表现以下两种形式: 数据发送者无法否认其发送数据的事实。例如,A向B发信,事后,A不能否认该信是其发送的。数据接收者事后无法否认其收到过这些数据。例如,A向B发…...

强化学习------PPO算法
目录 简介一、PPO原理1、由On-policy 转化为Off-policy2、Importance Sampling(重要性采样)3、off-policy下的梯度公式推导 二、PPO算法两种形式1、PPO-Penalty2、PPO-Clip 三、PPO算法实战四、参考 简介 PPO 算法之所以被提出,根本原因在于…...
express框架)
node(三)express框架
文章目录 1.express介绍2.express初体验3.express路由3.1什么是路由?3.2路由的使用 1.express介绍 是一个基于Node平台的极简、灵活的WEB应用开发框架,官网地址:https://www.expressjs.com.cn/ 简单来说,express是一个封装好的工…...

linux find命令搜索日志内容
linux find命令搜索日志内容 查询服务器log日志 find /opt/logs/ -name "filename.log" | xargs grep -a "这里是要查询的字符"加上-a 是为了不报查出 binary 的错 服务器会返回 包含所查字符的整行日志信息...

HTML图片怎么在Firefox中调试对齐_Firefox开发者工具调图方法.txt
连接数爆满主因是线程卡住而非数量多,应重点关注SHOW FULL PROCESSLIST中State非Sleep且Time>60秒的阻塞线程,优先排查应用端连接未释放、监控脚本高频查询及本地进程异常连接。直接看 SHOW PROCESSLIST 里哪些线程在“卡住”连接数爆满&…...

5大隐藏功能揭秘:Markor如何重塑Android移动文本创作生态
5大隐藏功能揭秘:Markor如何重塑Android移动文本创作生态 【免费下载链接】markor Text editor - Notes & ToDo (for Android) - Markdown, todo.txt, plaintext, math, .. 项目地址: https://gitcode.com/gh_mirrors/ma/markor 在移动设备成为主要生产力…...

跨越网络鸿沟:Qt Creator配置CDB实现远程调试实战
1. 为什么需要远程调试? 在嵌入式开发或者跨平台开发中,我们经常会遇到这样的场景:开发环境在本地PC上,但目标程序需要运行在远程设备上。比如开发一个工业控制软件,本地使用Qt Creator开发,但最终程序要部…...

QtUnblockNeteaseMusic终极指南:高效解锁网易云音乐地区限制
QtUnblockNeteaseMusic终极指南:高效解锁网易云音乐地区限制 【免费下载链接】QtUnblockNeteaseMusic A desktop client for UnblockNeteaseMusic, made with Qt. 项目地址: https://gitcode.com/gh_mirrors/qt/QtUnblockNeteaseMusic QtUnblockNeteaseMusic…...

Decepticon:大语言模型越狱攻击与防御的系统化评估框架
1. 项目概述与核心价值最近在开源社区里,一个名为“Decepticon”的项目引起了我的注意。这个项目由PurpleAILAB团队发布,名字本身就充满了趣味和深意——“Decepticon”直译是“霸天虎”,在《变形金刚》里是擅长伪装和欺骗的反派角色。这名字…...

别再只盯着网线了!从双绞线到光纤,聊聊家庭网络布线选材的实战避坑指南
家庭网络布线实战指南:从铜缆到光缆的智能选择 装修新房或升级旧宅网络时,面对琳琅满目的网线规格和新兴的光纤方案,普通消费者往往陷入选择困境。Cat5e、Cat6、Cat7这些数字背后究竟意味着什么?光纤是否真的高不可攀?…...
)
别再只做静态分析了!用DPABI探索小鼠大脑rs-fMRI的动态功能连接(含Matlab代码片段)
动态功能连接分析:解锁小鼠大脑rs-fMRI的时变奥秘 在神经影像研究领域,静息态功能磁共振成像(rs-fMRI)已成为探索大脑功能组织的强大工具。传统静态分析方法虽然提供了宝贵的基础认知,但大脑本质上是一个动态系统,其功能连接会随时…...

2026年5月AI Agent技术全景:多模态与自主决策的范式跃迁
核心结论:2026年5月,AI Agent技术正在从"工具调用"向"自主决策"跃迁。六大趋势——多模态感知、长期记忆、多Agent协作、安全对齐、开发者生态、边缘部署——正在重塑Agent技术栈。12大主流框架(LangGraph、AutoGPT、Met…...

告别‘鬼影’与模糊:深入解读RangeNet++如何用高效kNN后处理搞定LiDAR语义分割的边界难题
RangeNet:用GPU加速的kNN后处理破解LiDAR语义分割的边界模糊难题 当自动驾驶车辆以每小时60公里的速度行驶时,每100毫秒的决策延迟意味着1.67米的盲区——这恰好是许多交通事故发生的临界距离。在LiDAR语义分割领域,传统方法在点云投影与反投…...

小白程序员看过来!TS同学半年逆袭AI大模型产品经理,收藏这份转行避坑指南!
TS同学从景观设计转行AI大模型产品经理的经历分享。他经历了离职、脱产学习、国企子公司项目被裁等波折,最终以20%薪资涨幅加入AI公司。文章重点介绍了他的心态调整、求职策略变化以及对“稳定”的新理解,同时探讨了AI时代教育孩子的思考。 本期嘉宾TS同…...