49.Redis缓存设计与性能优化
缓存与数据库双写不一致小概率事件
//线程1 写数据库stock = 5 ---------------》更新缓存
//线程2 写数据库stock = 4 -----》更新缓存
//线程1 ------》写数据库stock = 10 -----》删除缓存
//线程2 -----------------------------------------------------------------------------------------------》写数据库stock = 9 -----》删除缓存
//线程3 -------------------------------------------------》查缓存(空)----》查数据库stock = 10------------------------------------------------------------------------》写缓存
使用 redisson 的 RReadWriteLock,让修改 stock 的地方串行执行,源码还是使用 lua 脚本实现。
开发规范与性能优化
key名设计
- 可读性和可管理性: 以业务名(或数据库名)为前缀(防止key冲突),用冒号分隔,比如业务名:表名:id
- 简洁性: 控制key的长度,不要包含特殊字符
vlaue设计原则
- 拒绝bigkey
- 字符串类型:它的big体现在单个value值很大,一般认为超过10KB就是bigkey
- 非字符串类型:哈希、列表、集合、有序集合,它们的big体现在元素个数太多。一般来说,string类型控制在10KB以内,hash、list、set、zset元素个数不要超过5000。
- 非字符串的bigkey,不要使用del删除,使用hscan、sscan、zscan方式渐进式删除,同时要注意防止bigkey过期时间自动删除问题(例如一个200万的zset设置1小时过期,会触发del操作,造成阻塞)
- bigkey的危害
- 导致redis阻塞
- 网络拥塞
- 过期删除
- 默认异步删除
bigkey的产生
一般来说,bigkey的产生都是由于程序设计不当,或者对于数据规模预料不清楚造成的,来看几个例子:
(1) 社交类:粉丝列表,如果某些明星或者大v不精心设计下,必是bigkey。
(2) 统计类:例如按天存储某项功能或者网站的用户集合,除非没几个人用,否则必是bigkey。
(3) 缓存类:将数据从数据库load出来序列化放到Redis里,这个方式非常常用,但有两个地方需要注意,第一,是不是有必要把所有字段都缓存;第二,有没有相关关联的数据,有的同学为了图方便把相关数据都存一个key下,产生bigkey。
如何优化bigkey
- 拆
- big list: list1、list2、…listN
- big hash:可以讲数据分段存储,比如一个大的key,假设存了1百万的用户数据,可以拆分成200个key,每个key下面存放5000个用户数据
- 如果bigkey不可避免,也要思考一下要不要每次把所有元素都取出来(例如有时候仅仅需要hmget,而不是hgetall)
- 选择适合的数据类型
- 控制key的生命周期
命令使用
- hgetall、lrange、smembers、zrange、sinter等并非不能使用,但是需要明确N的值。有遍历的需求可以使用hscan、sscan、zscan代替。
- 禁止线上使用keys、flushall、flushdb等,通过redis的rename机制禁掉命令,或者使用scan的方式渐进式处理。
- redis的多数据库较弱,使用数字进行区分,很多客户端支持较差,同时多业务用多数据库实际还是单线程处理,会有干扰。
- 使用批量操作提高效率
- 原生命令:例如mget、mset。
- 非原生命令:可以使用pipeline提高效率。
- 但要注意控制一次批量操作的元素个数(例如500以内,实际也和元素字节数有关)。
- 原生命令是原子操作,pipeline是非原子操作。
- Redis事务功能较弱,不建议过多使用,可以用lua替代
客户端使用
- 避免多个应用使用一个Redis实例
- 使用带有连接池的数据库,可以有效控制连接,同时提高效率
- 高并发下建议客户端添加熔断功能(例如sentinel、hystrix)
- 设置合理的密码,如有必要可以使用SSL加密访问
- redis的三种清除策略
- 被动删除:当读/写一个已经过期的key时,会触发惰性删除策略,直接删除掉这个过期key
- 主动删除:由于惰性删除策略无法保证冷数据被及时删掉,所以Redis会定期(默认每100ms)主动淘汰一批已过期的key,这里的一批只是部分过期key,所以可能会出现部分key已经过期但还没有被清理掉的情况,导致内存并没有被释放
- 当前已用内存超过maxmemory限定时,触发主动清理策略,八种淘汰策略
- 针对设置了过期时间的key做处理
- volatile-ttl:在筛选时,会针对设置了过期时间的键值对,根据过期时间的先后进行删除,越早过期的越先被删除
- volatile-random:就像它的名称一样,在设置了过期时间的键值对中,进行随机删除。
- volatile-lru:会使用 LRU 算法筛选设置了过期时间的键值对删除。
- volatile-lfu:会使用 LFU 算法筛选设置了过期时间的键值对删除。
- 针对所有的key做处理
- allkeys-random:从所有键值对中随机选择并删除数据。
- allkeys-lru:使用 LRU 算法在所有数据中进行筛选删除。
- allkeys-lfu:使用 LFU 算法在所有数据中进行筛选删除。
- 不处理
- noeviction:不会剔除任何数据,拒绝所有写入操作并返回客户端错误信息"(error) OOM command not allowed when used memory",此时Redis只响应读操作
- 针对设置了过期时间的key做处理
LRU 算法(Least Recently Used,最近最少使用)
淘汰很久没被访问过的数据,以最近一次访问时间作为参考。
LFU 算法(Least Frequently Used,最不经常使用)
淘汰最近一段时间被访问次数最少的数据,以次数作为参考。
maxmemory-policy(默认是noeviction),推荐使用volatile-lru
当Redis运行在主从模式时,只有主结点才会执行过期删除策略,然后把删除操作”del key”同步到从结点删除数据。
使用带有连接池的数据库,可以有效控制连接,同时提高效率,标准使用方式
- 连接池的最佳性能是maxTotal = maxIdle,这样就避免连接池伸缩带来的性能干扰。但是如果并发量不大或者maxTotal设置过高,会导致不必要的连接资源浪费。
- 计算资源池大小
- 一次命令时间(borrow|return resource + Jedis执行命令(含网络) )的平均耗时约为1ms,一个连接的QPS大约是1000
- 业务期望的QPS是50000
- 理论上需要的资源池大小是50000 / 1000 = 50个。但事实上这是个理论值,还要考虑到要比理论值预留一些资源,通常来讲maxTotal可以比理论值大一些。
- 可以给redis连接池做预热
JedisPoolConfig jedisPoolConfig = new JedisPoolConfig();JedisPool jedisPool;{System.out.println("=====初始化连接池=====");//资源池中最大连接数jedisPoolConfig.setMaxTotal(10);//资源池允许最大空闲的连接数jedisPoolConfig.setMaxIdle(10);//资源池确保最少空闲的连接数jedisPoolConfig.setMinIdle(2);//向资源池借用连接时是否做连接有效性检测(ping),无效连接会被移除。业务量很大时候建议设置为false(多一次ping的开销)jedisPoolConfig.setTestOnBorrow(true);jedisPool = new JedisPool(jedisPoolConfig, "127.0.0.1", 6379, 3000, null);//连接池预热示例代码List<Jedis> minIdleJedisList = new ArrayList<Jedis>(jedisPoolConfig.getMinIdle());for (int i = 0; i < jedisPoolConfig.getMinIdle(); i++) {Jedis jedis = null;try {jedis = jedisPool.getResource();jedis.clientSetname("client:" + i);minIdleJedisList.add(jedis);jedis.ping();} catch (Exception e) {e.printStackTrace();} finally {//注意,这里不能马上close将连接还回连接池,否则最后连接池里只会建立1个连接。。//jedis.close();}}//统一将预热的连接还回连接池for (int i = 0; i < jedisPoolConfig.getMinIdle(); i++) {Jedis jedis = null;try {jedis = minIdleJedisList.get(i);//将连接归还回连接池jedis.close();System.out.println("连接" + jedis.clientGetname() + "归还成功");} catch (Exception e) {e.printStackTrace();} finally {}}}@GetMapping("pool")public String pool() {Jedis jedis = null;try {jedis = jedisPool.getResource();//具体的命令String set = jedis.set("pool:redis:", "1");System.out.println("使用连接:" + jedis.clientGetname() + " 执行" + " 结果:" + set);} catch (Exception e) {e.printStackTrace();} finally {//注意这里不是关闭连接,在JedisPool模式下,Jedis会被归还给资源池。if (jedis != null)jedis.close();}return "success";}
慢查询日志:slowlog
config get slow* #查询有关慢日志的配置信息
config set slowlog-log-slower-than 20000 #设置慢日志使时间阈值,单位微秒,此处为20毫秒,即超过20毫秒的操作都会记录下来,生产环境建议设置1000,也就是1ms,这样理论上redis并发至少达到1000,如果要求单机并发达到1万以上,这个值可以设置为100
config set slowlog-max-len 1024 #设置慢日志记录保存数量,如果保存数量已满,会删除最早的记录,最新的记录追加进来。记录慢查询日志时Redis会对长命令做截断操作,并不会占用大量内存,建议设置稍大些,防止丢失日志
config rewrite #将服务器当前所使用的配置保存到redis.conf
slowlog len #获取慢查询日志列表的当前长度
slowlog get 5 #获取最新的5条慢查询日志。慢查询日志由四个属性组成:标识ID,发生时间戳,命令耗时,执行命令和参数
slowlog reset #重置慢查询日志
布隆过滤器
布隆过滤器就是一个大型的位数组和几个不一样的无偏 hash 函数。所谓无偏就是能够把元素的 hash 值算得比较均匀。
布隆过滤器的实现原理
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| k1 | 1 | 1 | 1 | ||||||||||||||||
| k2 | 1 | 1 | 1 | ||||||||||||||||
| k3 | 1 | 1 | 1 |
对 k1 进行多个 hash 计算获得数组索引值,add
对 k2 进行多个 hash 计算获得数组索引值,add
对 k3 进行多个 hash 计算获得数组索引值,exists,此时出现了 hash 碰撞,误判 k3 存在。
- 适用于数据命中不高、 数据相对固定、 实时性低(通常是数据集较大) 的应用场景, 代码维护较为复杂, 但是缓存空间占用很少。
- 根据预计元素、误差率生成数组的长度。
- 不能修改,只能重建。
布隆过滤器的代码示例
@GetMapping("bloom")
public String bloom() {Config config = new Config();List<String> nodes = Arrays.asList("redis://192.168.139.135:8001","redis://192.168.139.136:8002","redis://192.168.139.137:8003","redis://192.168.139.135:8004" ,"redis://192.168.139.136:8005","redis://192.168.139.137:8006");//集群配置config.useClusterServers().setNodeAddresses(nodes);config.useClusterServers().setPassword("yes");RedissonClient redisson = Redisson.create(config);RBloomFilter<String> nameFilter = redisson.getBloomFilter("nameFilter");//初始化布隆过滤器:预计元素为100000000L,误差率为3%,根据这两个参数会计算出底层的bit数组大小nameFilter.tryInit(100000000L,0.03);String[] nameList = { "a", "b", "c", "d", "e", "f", "g", "h", "i", "j", "k"};String[] checkList = { "a1", "b2", "c3", "d", "e4", "f5", "g6", "h7", "i8", "j", "k"};for (String name : nameList) {nameFilter.add(name);}//判断下面号码是否在布隆过滤器中for (String name : checkList) {boolean rs = nameFilter.contains(name);System.out.println(name + " 检查结果:" + rs);}return "success";
}
相关文章:

49.Redis缓存设计与性能优化
缓存与数据库双写不一致小概率事件 //线程1 写数据库stock 5 ---------------》更新缓存 //线程2 写数据库stock 4 -----》更新缓存 //线程1 ------》写数据库stock 10 -----》删除缓存 //线程2 ---------------------------------------------------------------------…...

IDEA常用的一些插件
1、CodeGlance 代码迷你缩放图插件,可以快速拖动代码,和VScode一样 2、Codota 代码提示工具,扫描你的代码后,根据你的敲击完美提示。 Codota基于数百万个开源Java程序和您的上下文来完成代码行,从而帮助您以更少的…...

基于定容积法标准容器容积标定中的电动针阀自动化解决方案
摘要:在目前的六氟化硫气体精密计量中普遍采用重量法和定容法两种技术,本文分析了重量法中存在的问题以及定容法的优势,同时也指出定容法在实际应用中还存在自动化水平较低的问题。为了提高定容法精密计量过程中的自动化水平,本文…...

26 行为型模式-命令模式
1 命令模式介绍 2 命令模式原理 3 命令模式实现 模拟酒店后厨的出餐流程,来对命令模式进行一个演示,命令模式角色的角色与案例中角色的对应关系如下: 服务员: 即调用者角色,由她来发起命令. 厨师: 接收者,真正执行命令的对象. 订单: 命令中包含订单 /*** 订单类**/ public cl…...

一个Entity Framework Core的性能优化案例
概要 本文提供一个EF Core的优化案例,主要介绍一些EF Core常用的优化方法,以及在优化过程中,出现性能反复的时候的解决方法,并澄清一些对优化概念的误解,例如AsNoTracking并不包治百病。 本文使用的是Dotnet 6.0和EF…...

【Python 千题 —— 基础篇】列表排序
题目描述 题目描述 给定一个包含无序数字的列表,请将列表中的数字按从小到大的顺序排列,并输出排序后的列表。 输入描述 输入一个包含无序数字的列表。 输出描述 程序将对列表中的数字进行排序,并输出排序后的列表。 示例 示例 ① 1…...

leetcode26:删除有序数组中的重复项
leetcode26:删除有序数组中的重复项 方案一:依次遍历,如果不符合条件则冒泡交换到最后一个位置。o(n^2),结果超时 #include <algorithm> #include <iostream>using namespace std; class Solution { public:int removeDuplicat…...
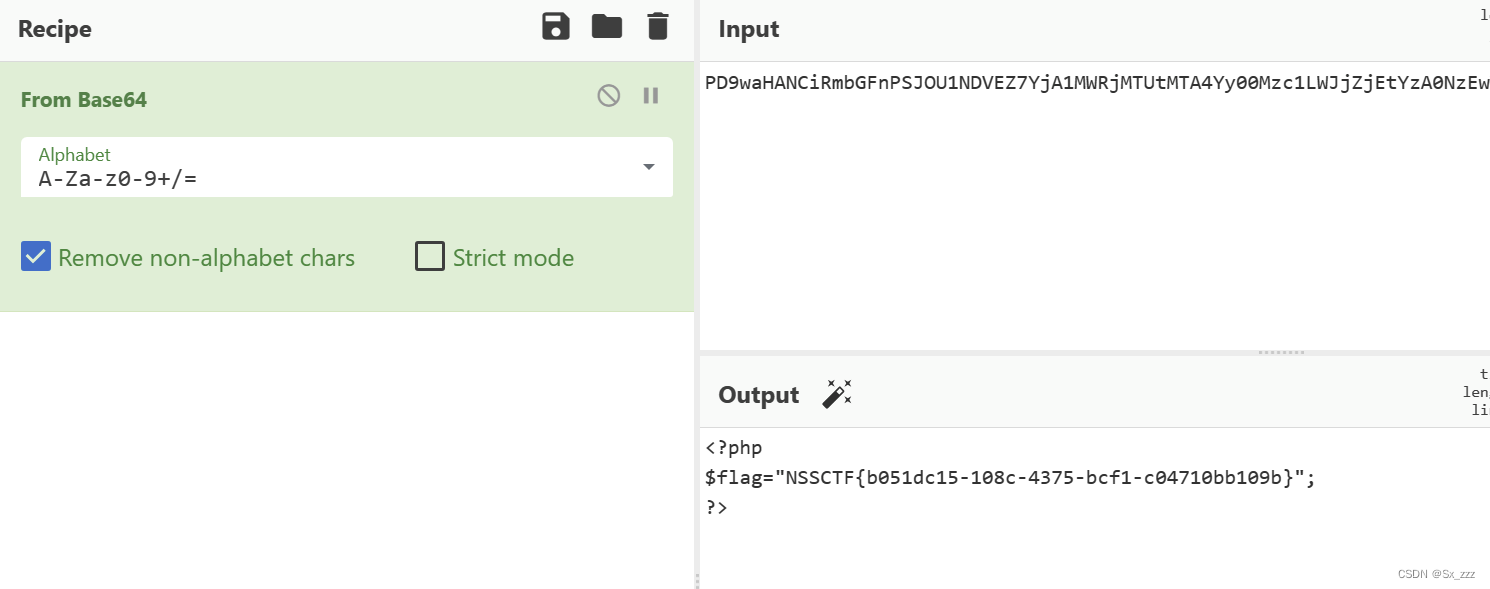
[FSCTF 2023] web题解
文章目录 源码!启动!webshell是啥捏细狗2.0ez_php1Hello,youEZ_eval巴巴托斯! 源码!启动! 打开题目,发现右键被禁了 直接ctrlu查看源码得到flag webshell是啥捏 源码 <?php highlight_file(__FILE__); $😀&qu…...

linux查看内存的方式
1、显示内存状态:free -h 以合适的单位显示内存使用情况,最大为三位数,自动计算对应的单位值。单位有: B bytes K kilos M megas G gigas T teras $free -htotal used free shared buff/cache available Me…...

Python 编写 Flink 应用程序经验记录(Flink1.17.1)
目录 官方API文档 提交作业到集群运行 官方示例 环境 编写一个 Flink Python Table API 程序 执行一个 Flink Python Table API 程序 实例处理Kafka后入库到Mysql 下载依赖 flink-kafka jar 读取kafka数据 写入mysql数据 flink-mysql jar 官方API文档 https://nigh…...

如何 通过使用优先级提示,来控制所有网页资源加载顺序
当你打开浏览器的网络标签时,你会看到大量的活动。资源正在下载,信息正在提交,事件正在记录,等等。 由于有太多的活动,有效地管理这些流量的优先级变得至关重要。带宽争用是真实存在的,当所有请求同时触发时…...

10月25日,每日信息差
今天是2023年10月26日,以下是为您准备的14条信息差 第一、百世集团牵头成立全国智慧物流与供应链行业产教融合共同体在杭州正式成立,该共同体由百世集团、浙江工商大学、浙江经济职业技术学院共同牵头 第二、问界M9预定量突破15000台 第三、前三季度我…...
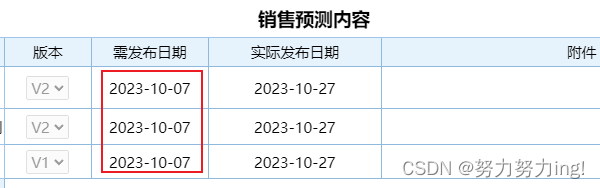
泛微OA之获取每月固定日期
文章目录 1.需求及效果1.1需求1.2效果 2. 思路3. 实现 1.需求及效果 1.1需求 需要获取每个月的7号作为需发布日期,需要自动填充1.2效果 自动获取每个月的七号2. 思路 1.功能并不复杂,可以用泛微前端自带的插入代码块的功能来实现。 2.将这需要赋值的…...
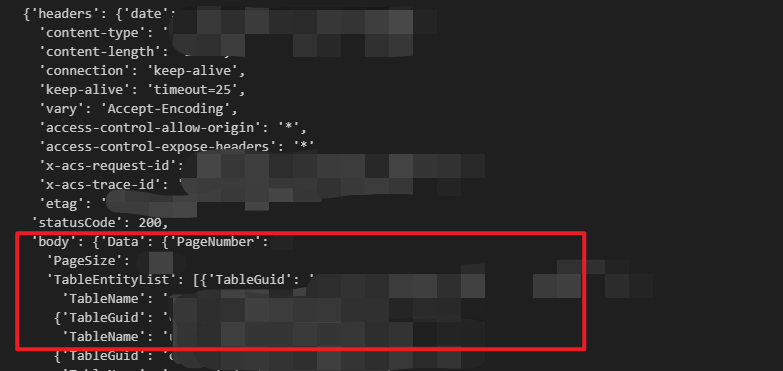
Dataworks API:调取 MC 项目下所有表单
文章目录 前言Dataworks API 文档解读GetMetaDBTableList 接口文档 API 调试在线调试本地调试运行环境账密问题请求数据进一步处理 小结 前言 最近,我需要对公司的数据资产进行梳理,这其中便包括了Dataworks各个项目下的表单。这些表单,作为…...
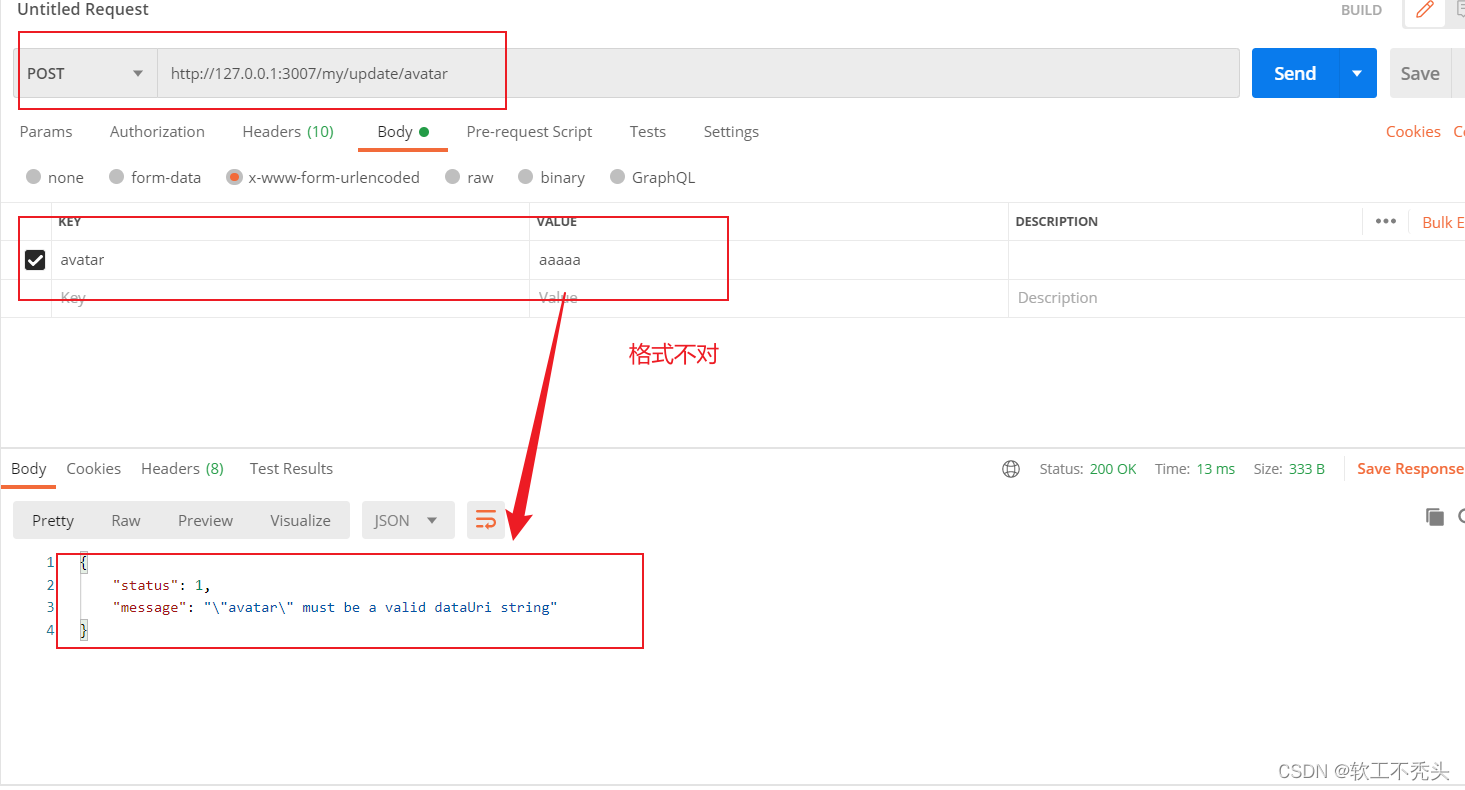
Node编写更新用户头像接口
目录 定义路由和处理函数 验证表单数据 编辑 实现更新用户头像的功能 定义路由和处理函数 向外共享定义的更新用户头像处理函数 // 更新用户头像的处理函数 exports.updateAvatar (req, res) > {res.send(更新成功) } 定义更新用户头像路由 // 更新用户头像的路由…...

MySQL3:MySQL中一条更新SQL是如何执行的?
MySQL3:MySQL中一条更新SQL是如何执行的? MySQL中一条更新SQL是如何执行的?1.Buffer Pool缓冲池2.Redo logredo log作用Redo log文件位置redo log为什么是2个? 3.Undo log4.更新过程5.InnoDB官网架构InnoDB架构-内存结构①Buffer …...

p5.js map映射
本文简介 带尬猴,我嗨德育处主任 p5.js 为开发者提供了很多有用的方法,这些方法实现起来可能不难,但却非常实用,能大大减少我们的开发时间。 本文将通过举例说明的方式来讲解 映射 map() 方法。 什么是映射 从 p5.js 文档 中可…...
idea提交代码冲突后,代码意外消失解决办法
敲了大半天的代码,解决冲突后,直接消失了当时慌的一批CCCCC 右击项目Local History ----show History 找到最近提交的内容右击选择Revert,代码全回来了...
爬虫批量下载科研论文(SciHub)
系列文章目录 利用 eutils 实现自动下载序列文件 提示:写完文章后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 系列文章目录前言一、获取文献信息二、下载文献PDF文件参考 前言 大家好✨,这里是bio🦖。…...

explain查询sql执行计划返回的字段的详细说明
当使用EXPLAIN命令查看SQL语句的执行计划时,会返回一张表格,其中包含了该SQL语句的执行计划。下面是每个字段的详细分析: id:执行计划的唯一标识符。如果查询中有子查询,每个子查询都会有一个唯一的ID。在执行计划中&a…...

Redis沙盒体验:在浏览器中零门槛掌握NoSQL核心技能
Redis沙盒体验:在浏览器中零门槛掌握NoSQL核心技能 【免费下载链接】try.redis A demonstration of the Redis database. 项目地址: https://gitcode.com/gh_mirrors/tr/try.redis 当你第一次听说Redis时,是否被那些晦涩的技术术语吓退࿱…...
)
别再只测accuracy!DeepSeek集成测试必须监控的5个隐性指标(P99首token延迟、context bleed率、tool-call schema漂移)
更多请点击: https://intelliparadigm.com 第一章:DeepSeek集成测试的核心范式演进 DeepSeek大模型的工程化落地对集成测试提出了全新挑战:传统基于接口响应码与字段校验的测试范式已难以覆盖语义一致性、推理链鲁棒性、上下文敏感度等高阶质…...

金融合规审核为何人力堆积却仍漏洞百出?2026年RegTech演进与Agent全链路闭环解决方案
在2026年的金融监管环境下,合规审核已不再是简单的“查漏补缺”,而是演变为一场高强度的算力与逻辑博弈。尽管金融机构在合规成本上的投入逐年攀升,甚至不惜以“人海战术”填补流程断点,但监管罚单的数额与频率却并未显著下降。这…...

MongoDB Limit 与 Skip 方法详解
MongoDB Limit 与 Skip 方法详解 引言 MongoDB 是一个高性能、可伸缩的文档存储系统,它提供了强大的数据存储和查询功能。在处理大量数据时,Limit 与 Skip 方法是 MongoDB 中常用的查询优化工具。本文将详细介绍 MongoDB 中的 Limit 与 Skip 方法,包括其基本用法、性能影响…...

Adobe-GenP 3.0:轻松激活Adobe全家桶的完整指南
Adobe-GenP 3.0:轻松激活Adobe全家桶的完整指南 【免费下载链接】Adobe-GenP Adobe CC 2019/2020/2021/2022/2023 GenP Universal Patch 3.0 项目地址: https://gitcode.com/gh_mirrors/ad/Adobe-GenP Adobe-GenP 3.0是一款专为Adobe Creative Cloud系列软件…...

HiveWE终极指南:快速掌握魔兽争霸III现代化地图编辑器
HiveWE终极指南:快速掌握魔兽争霸III现代化地图编辑器 【免费下载链接】HiveWE A Warcraft III world editor. 项目地址: https://gitcode.com/gh_mirrors/hi/HiveWE 还在为传统魔兽争霸III地图编辑器缓慢的加载速度和复杂的操作界面而烦恼吗?Hiv…...

万星easy-vibe:描述需求即发布 零基础无需学语法
开源Easy-Vibe是一套开源AI编程学习方案,把学习顺序从先学语法再做项目翻转为直接做项目。文章拆解了项目驱动、提示词编写、AI编辑器和多Agent协作的完整流程,解释了为什么想法比语法更重要。 github上datawhalechina/easy-vibe:它在GitHub…...
)
告别杂乱!用FileMenu Tools 8.4.2一键清理Windows 11右键菜单(附隐藏技巧)
Windows 11右键菜单精简指南:用FileMenu Tools打造高效工作流每次在文件上点击右键时,那个缓慢弹出的冗长菜单是否让你感到烦躁?随着安装的软件越来越多,Windows的右键菜单往往会变得臃肿不堪,严重影响工作效率。今天&…...

java项目011-ssm 宠物医院系统
java项目011-ssm 宠物医院系统 是一款基于springspringmvcmybatis的宠物系统, 包含界面布局、医生信息管理、客户信息管理、宠物管理、浏览管理、 诊断管理、医生管理、用户管理 其中医生管理、用户管理只能管理员有权限进行操作。 采用spingboot方式启动 运行截图...

告别鼠标点击,微博图片批量下载的轻松方案
告别鼠标点击,微博图片批量下载的轻松方案 【免费下载链接】weiboPicDownloader Download weibo images without logging-in 项目地址: https://gitcode.com/gh_mirrors/we/weiboPicDownloader 还记得那个周末的下午吗?你喜欢的博主发布了九宫格美…...