Dataworks API:调取 MC 项目下所有表单
文章目录
- 前言
- Dataworks API 文档解读
- GetMetaDBTableList 接口文档
- API 调试
- 在线调试
- 本地调试
- 运行环境
- 账密问题
- 请求数据
- 进一步处理
- 小结
前言
最近,我需要对公司的数据资产进行梳理,这其中便包括了Dataworks各个项目下的表单。这些表单,作为公司的重要数据资产之一,也需要进行整理和规范。幸运的是,官方提供了API接口,可以辅助我更高效地获取各个项目下的所有表单。
Dataworks API 提供了很多项目及表单的信息,比如表单列表、表单的名称、创建时间、所属项目、调度信息等等。
本文以一个比较简单的例子(获取表单列表)展开详细讲解下整个流程。
Dataworks API 文档解读
DataWorks OpenAPI 概述文档:https://help.aliyun.com/zh/dataworks/developer-reference/api
调取 Dataworks API 之前,需要留一下 API 的调取是有限额的。
基础版每日API总调用次数≤100次,标准版每日API总调用次数≤1000次,专业版每日API总调用次数≤10000次,而且不支持额外付费调用。而企业版几乎可以忽略调用限制,调用次数多且支持额外付费调用。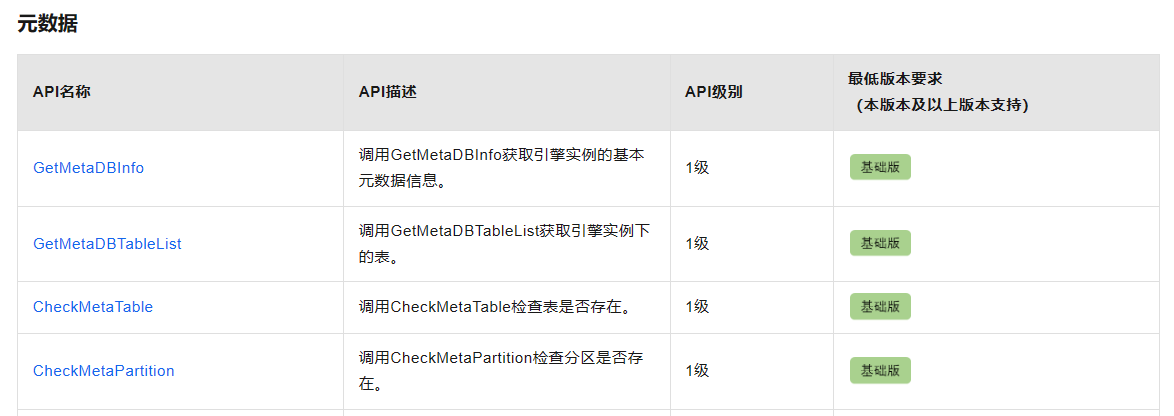
为规范 DataWorks OpenAPI 的调用,官方将 OpenAPI 分为1级、2级和3级,具体分类方式没有介绍,不过每一个 API 都有对应的级别说明,详见文档介绍。
GetMetaDBTableList 接口文档
本次要获取的是某项目下的表单名称,所以查看 GetMetaDBTableList 接口。
注意,文档中说的【引擎实例】其实就是 MaxCompute 的项目,所以这个相当于是在 DataWorks 中获取 MaxCompute 的项目的表。这个在工作空间中可以看到相关的配置信息。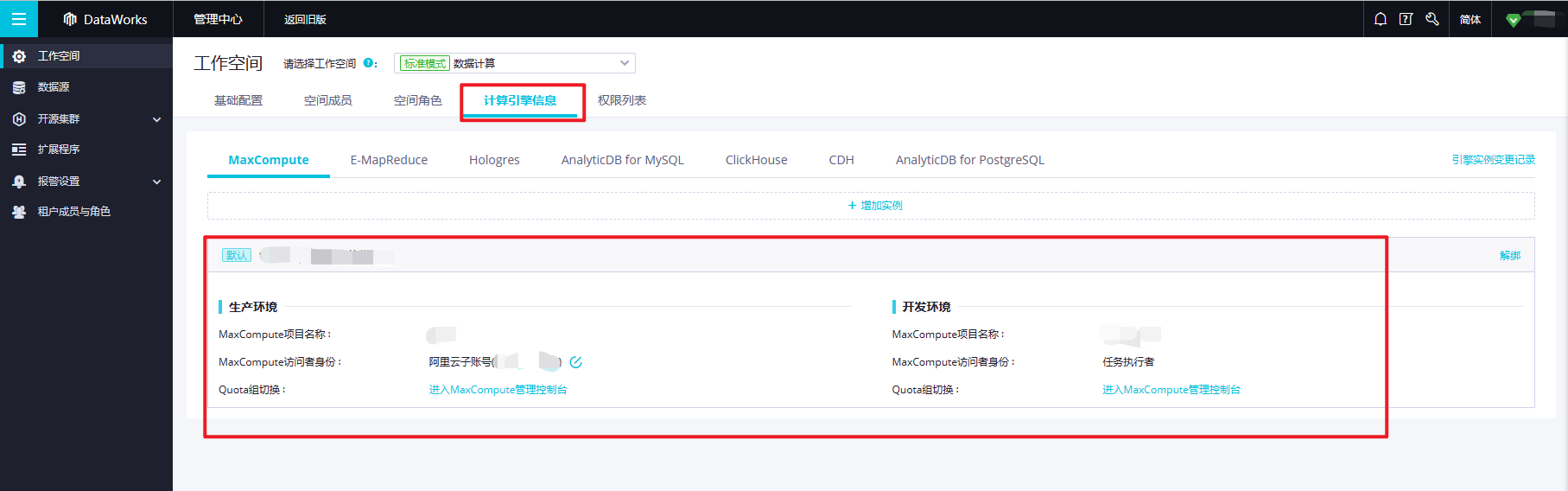
另外,DataWorks 和 MaxCompute 的关系:
DataWorks 是阿里云提供的一站式大数据开发治理平台,可以在 DataWorks 上进行 MaxCompute 作业开发、周期性调度、作业运维、数据治理等一站式数据开发治理操作。可在 DataWorks 控制台创建 DataWorks 工作空间,并在这过程中直接创建并绑定 MaxCompute 项目,后续即可在 DataWorks 工作空间中开发 MaxCompute 作业。
MaxCompute通过 DataWorks 采用可视化方式,进行任务工作流的配置、周期性调度执行及元数据管理,保障数据生产及管理的高效稳定。
回到文档上,可以看到需要的参数有很多,但是并不是所有都需要,具体可以在调试部分点击【调试】按钮,到调试页面进行测试,或者直接点击该链接直达:https://next.api.aliyun.com/api/dataworks-public/2020-05-18/GetMetaDBTableList
调试入口
再往下,看看返回的数据,返回的数据结构如下。RequestId 和 Data 是同级的,我需要的 TableName 的路径是 Data -> TableEntityList -> TableName。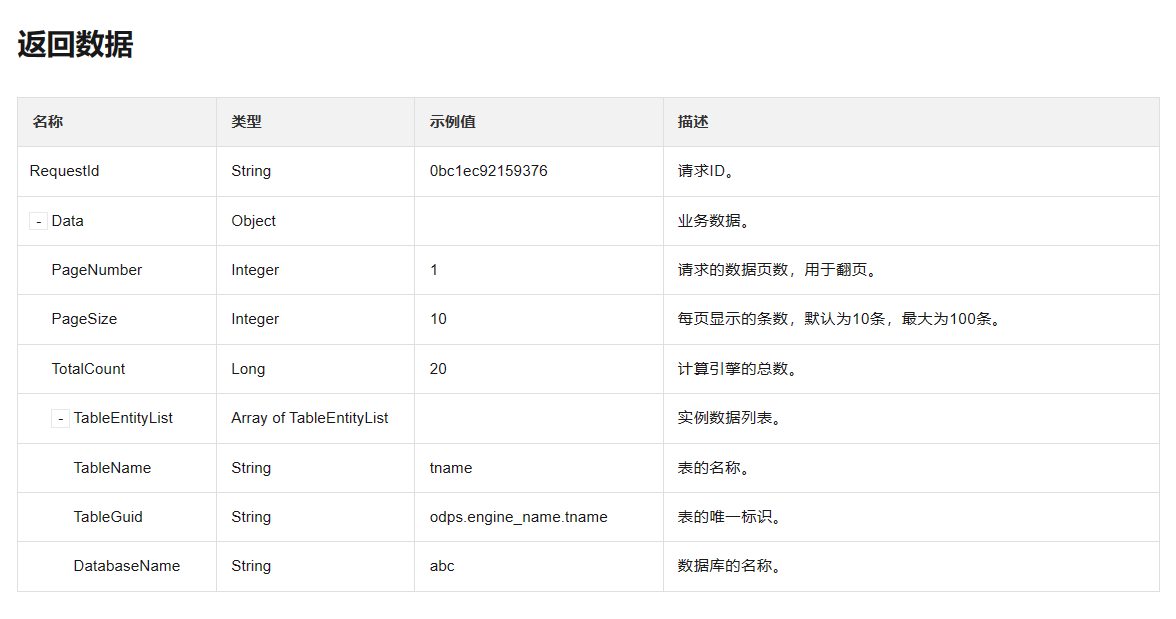
“剧透”下,这些数据都是 body 的值,后续调用可以看到对应的结构,处理值的时候,也需要从 body 层级开始取。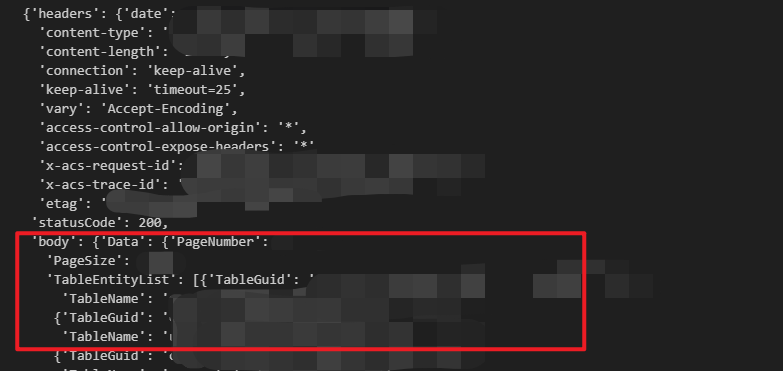
文档下面是一些示例和错误码,自行查看即可。
可能你看完后跟我一样,一脸懵逼!这就能取数了?不,取数的逻辑不在这里,具体的代码逻辑,可以在调试界面获取相关的参考代码,而且支持多种编程语言调取接口。
API 调试
在线调试
了解了基本的信息,接下来调试下。
在调试界面,可以看到,必填的参数其实只有一个,经过测试,填上该参数即可获取到相关的表单列表数据。
默认情况下,一页展示 10 条记录,最大可以展示 100 条,可以将分页参数的 PageSize 调到最大,使用最少的次数将表单数据都拉取下来。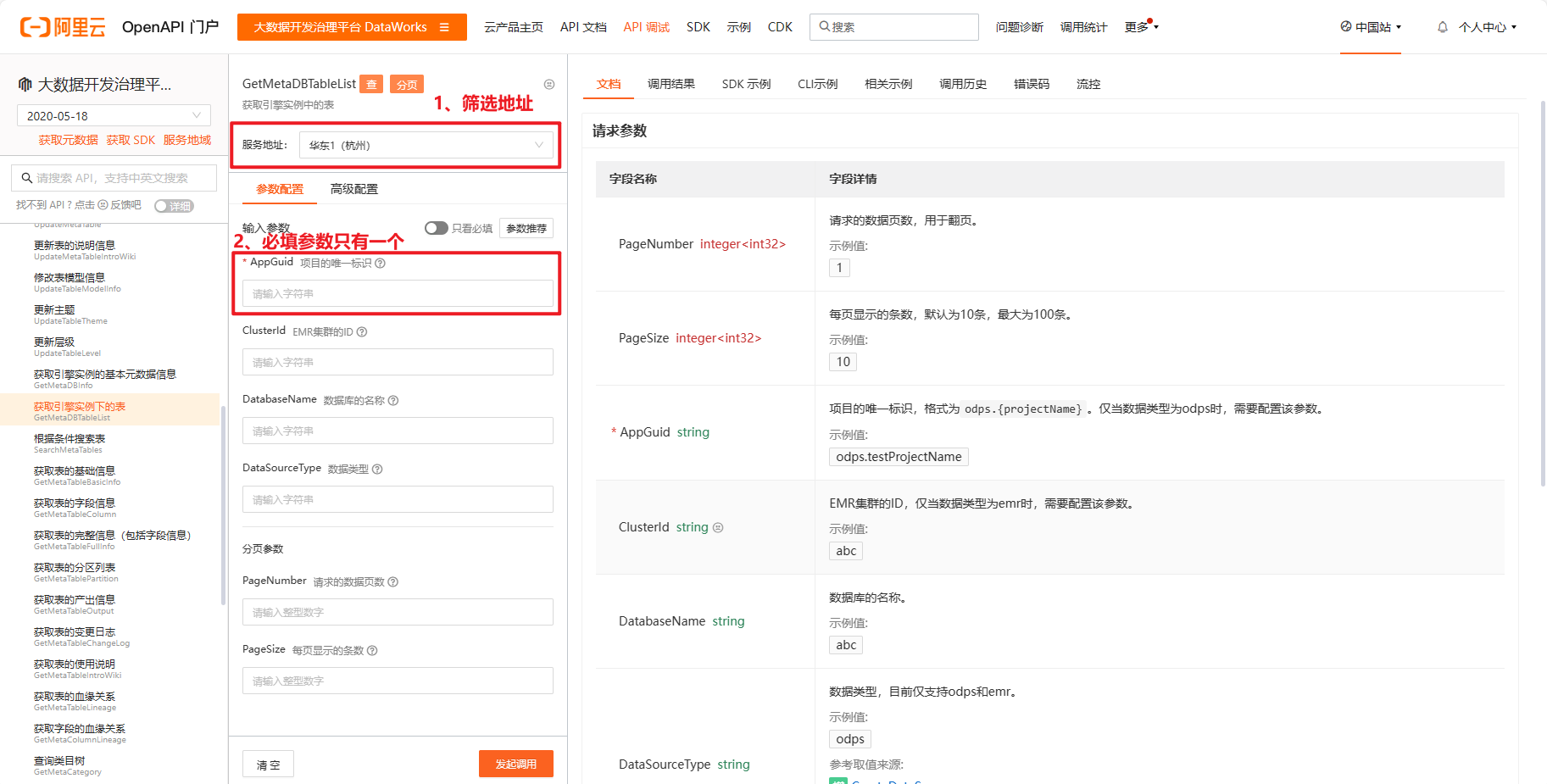
发起调用之后,可以看到调用的结果信息,里面有一个返回值:TotalCount,官方介绍是计算引擎的总数,其实就是表单数量,可以结合该值调整页数和每页的记录数。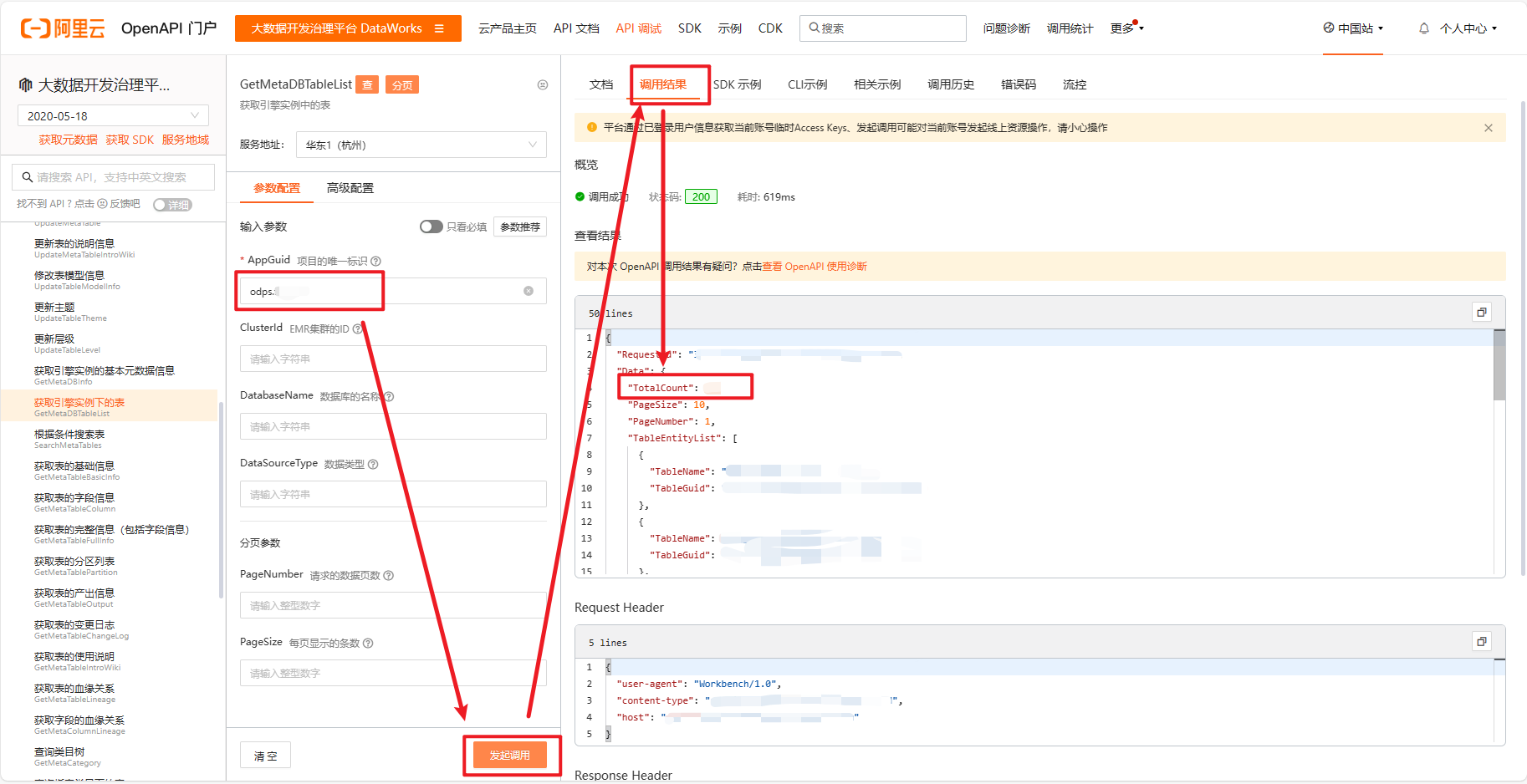
本地调试
调试没问题,那就进入下一步,在本地敲代码调 API 接口获取数据。
还是在调试页面,点击【SDK 示例】,这里以 Python 为例,点击 Python。可以看到一段完整的 Python 源码。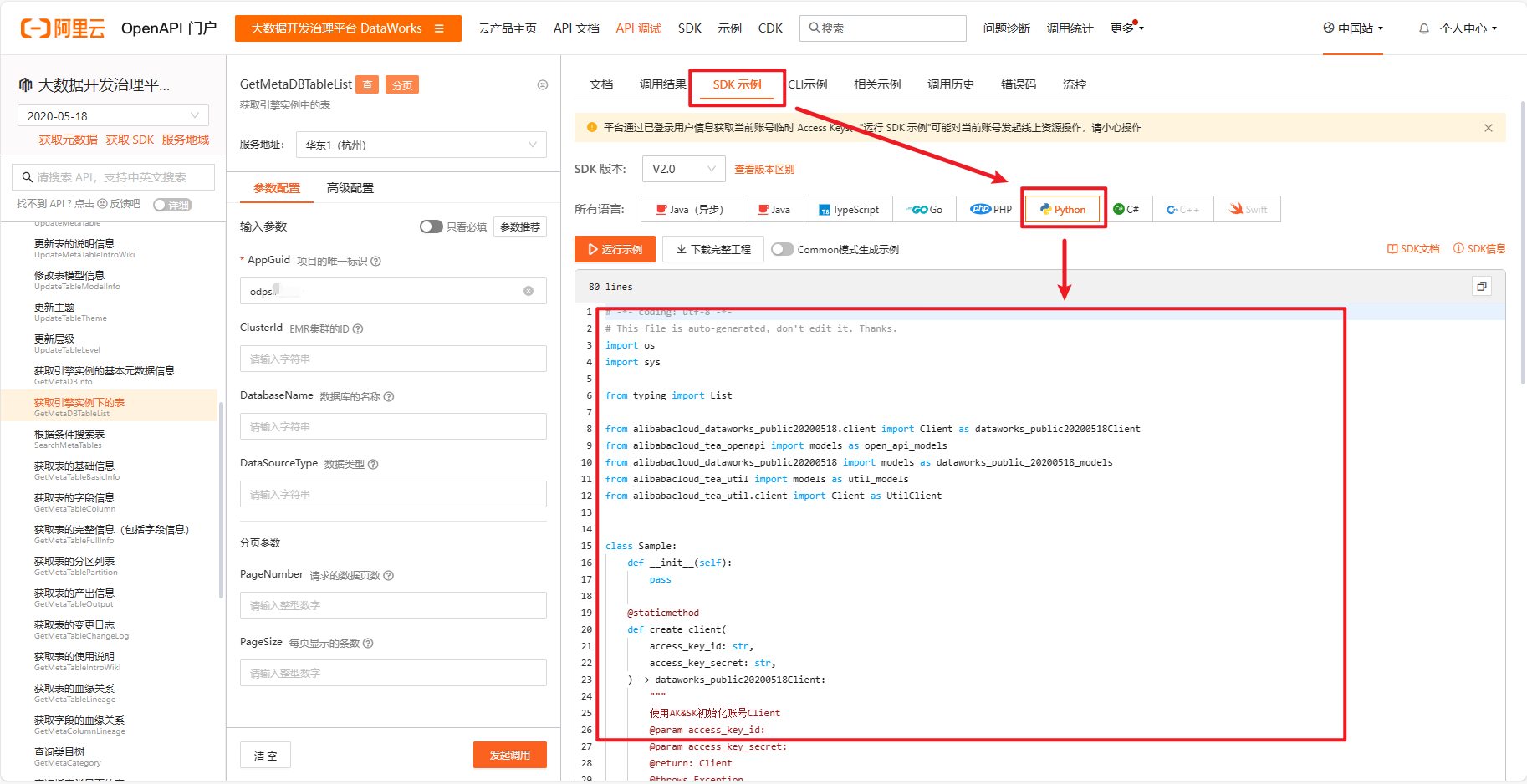
将其复制放到本地的 Python 编辑器中,此时还不能运行,还需要配置两个核心东西:运行环境 和 账户及密码(ACCESS_KEY_ID和ACCESS_KEY_SECRET)。
运行环境
点击右侧的【SDK 信息】,可以看到安装的命令:
pip install alibabacloud_dataworks_public20200518==4.7.2

打开终端/命令提示符,先安装上alibabacloud_dataworks_public20200518==4.7.2环境(大前提:已经安装了 Python,此处不展开)。
可能会由于网络问题出现超时的报错,多试几次,或者分不同的时间段试试。
WARNING: Retrying (Retry(total=4, connect=None, read=None, redirect=None, status=None)) after connection broken by 'ReadTimeoutError("HTTPSConnectionPool(host=‘files.pythonhosted.org’, port=443): Read timed out.

账密问题
源码的第 45~47 行中介绍了怎么配置账密的方法:添加两个环境变量,一个命名为:ALIBABA_CLOUD_ACCESS_KEY_ID,对应的值是你的 ACCESS_KEY_ID,另外一个命名为:ALIBABA_CLOUD_ACCESS_KEY_SECRET,对应的值是你的 ACCESS_KEY_SECRET。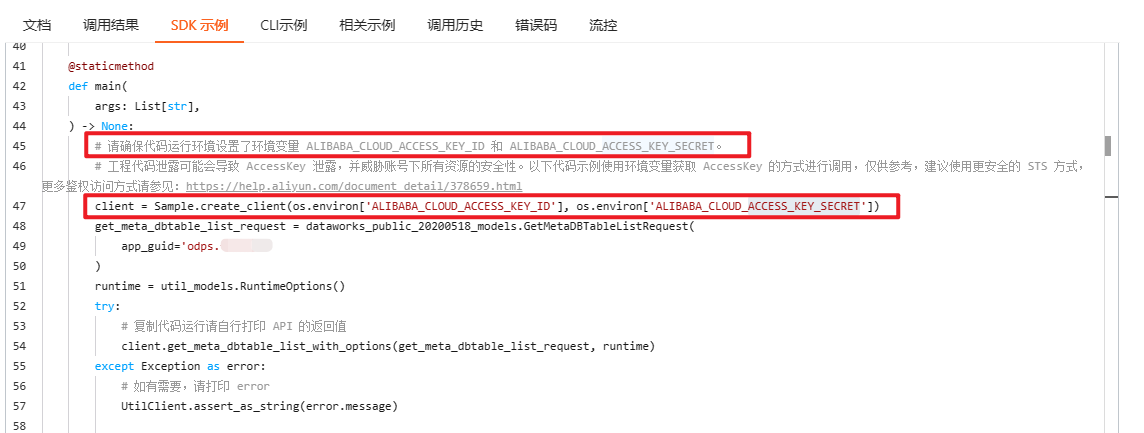
参考示例:
请求数据
两个准备工作做好之后,是不是就可以读取数据了呢?是的!不过可以读,但是读完没有保留下来。
直接运行源码,你会发现什么也没有……
这是因为源码没有打印(print())或者返回(return)API 返回的数据,官方给了提示,需要自行打印返回值。(见源码第 53 行)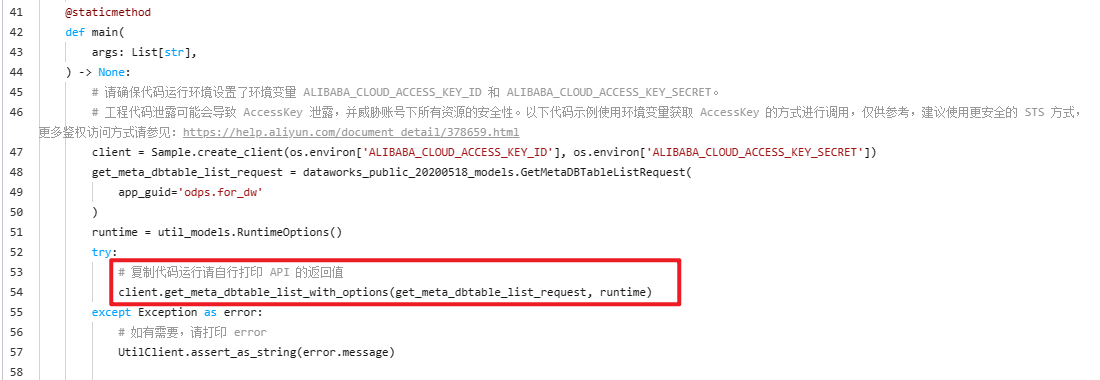
怎么改?print 一下,注意,由于返回的内容是一个对象,需要使用to_map()转换下对象,参考如下:
print(client.get_meta_dbtable_list_with_options(get_meta_dbtable_list_request, runtime).to_map())
再次运行就可以看到一个 字典结构的数据,和我前面“剧透”的那个截图的数据结构一致。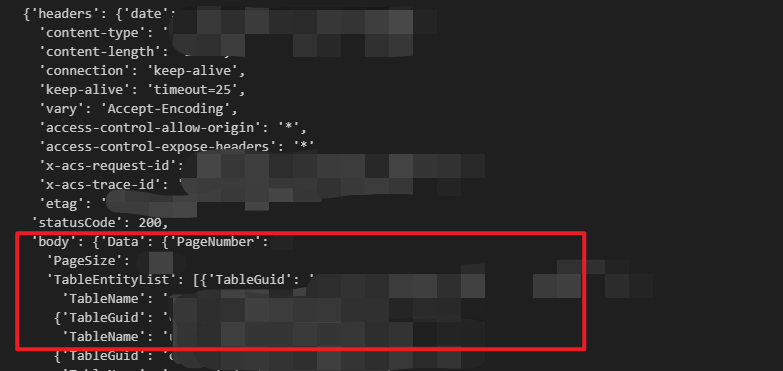
至此,恭喜你!已成功获取到你需要的数据。
进一步处理
尽管我们已经成功获取到数据,但目前仅获取了一页,最多只有100条记录。然而,在数据量比较大的情况下,我们需要进行多次调取。为提高效率,需要进一步完善代码,使程序能自动获取所有数据,同时保存每次调取的数据,以供后续分析和处理。
此处我加了一个for循环,并将数据临时存放在一个列表中,具体操作如下:
在class Sample中新增一个函数处理 body 的值,将 TableName 取出,然后返回。
@staticmethoddef gettable(response):TableInfos = response.to_map()['body']['Data']['TableEntityList']TableList = [table['TableGuid'] for table in TableInfos]return TableList
并修改main()方法,调用gettable()方法,将处理结果TableList返回。
@staticmethoddef main(args: List[str],) -> None:# 请确保代码运行环境设置了环境变量 ALIBABA_CLOUD_ACCESS_KEY_ID 和 ALIBABA_CLOUD_ACCESS_KEY_SECRET。# 工程代码泄露可能会导致 AccessKey 泄露,并威胁账号下所有资源的安全性。以下代码示例使用环境变量获取 AccessKey 的方式进行调用,仅供参考,建议使用更安全的 STS 方式,更多鉴权访问方式请参见:https://help.aliyun.com/document_detail/378659.htmlclient = Sample.create_client(os.environ['ALIBABA_CLOUD_ACCESS_KEY_ID'], os.environ['ALIBABA_CLOUD_ACCESS_KEY_SECRET'])get_meta_dbtable_list_request = dataworks_public_20200518_models.GetMetaDBTableListRequest(app_guid=args[0],page_size=args[1],page_number=args[2],)runtime = util_models.RuntimeOptions()try:# 复制代码运行请自行打印 API 的返回值# client.get_meta_dbtable_list_with_options(get_meta_dbtable_list_request, runtime)response = client.get_meta_dbtable_list_with_options(get_meta_dbtable_list_request, runtime)TableList = Sample.gettable(response)return TableListexcept Exception as error:# 如有需要,请打印 error# UtilClient.assert_as_string(error.message)response = UtilClient.assert_as_string(error.message)print(response)
最后在程序入库,修改传递的参数,并进行循环调用。
if __name__ == '__main__':# response = Sample.main(sys.argv[1:])TableList = []page_cnt = 10 #10*100,支持获取 1000 条记录for i in range(page_cnt):app_guid='odps.projectname';page_size=100;page_number=1+iresponse = Sample.main([app_guid,page_size,page_number])if response is None: #没有返回值,说明报错了。continueTableList.extend(response)print(TableList[:10])
到这里,所有的数据都获取到了,放在列表 TableList 中。
不过数据还没有保存下来,最后再通过 pandas 将数据写入 Excel 中(使用其他工具包也可以):
import pandas as pd
df = pd.DataFrame(TableList,columns=['tablename']);
df.to_excel('projectname_table.xlsx',index=False)
至此,数据获取大功告成!可以拿数据进行相关的分析了~~
小结
本文介绍了从 Dataworks 项目中获取所有表单字段的方法,基本步骤如下:
- 查看官方文档,了解约束和接口;
- 在线调试,并获取源码;
- 配置本地环境,安装 alibabacloud_dataworks_public20200518;
- 配置环境变量,新增两个环境变量ALIBABA_CLOUD_ACCESS_KEY_ID和 ALIBABA_CLOUD_ACCESS_KEY_SECRET,并将阿里云账号的 ACCESS_KEY_ID 和 ACCESS_KEY_SECRET 分别作为对应变量的值;
- 测试源码,打印数据,检验是否可行;
- 循环调用并保存数据。
整个流程比较繁琐,不过走一遍之后,便可以“一劳永逸”,因为其他的接口基本也是这个套路,改一些参数即可复用。
相关文章:
Dataworks API:调取 MC 项目下所有表单
文章目录 前言Dataworks API 文档解读GetMetaDBTableList 接口文档 API 调试在线调试本地调试运行环境账密问题请求数据进一步处理 小结 前言 最近,我需要对公司的数据资产进行梳理,这其中便包括了Dataworks各个项目下的表单。这些表单,作为…...
Node编写更新用户头像接口
目录 定义路由和处理函数 验证表单数据 编辑 实现更新用户头像的功能 定义路由和处理函数 向外共享定义的更新用户头像处理函数 // 更新用户头像的处理函数 exports.updateAvatar (req, res) > {res.send(更新成功) } 定义更新用户头像路由 // 更新用户头像的路由…...

MySQL3:MySQL中一条更新SQL是如何执行的?
MySQL3:MySQL中一条更新SQL是如何执行的? MySQL中一条更新SQL是如何执行的?1.Buffer Pool缓冲池2.Redo logredo log作用Redo log文件位置redo log为什么是2个? 3.Undo log4.更新过程5.InnoDB官网架构InnoDB架构-内存结构①Buffer …...

p5.js map映射
本文简介 带尬猴,我嗨德育处主任 p5.js 为开发者提供了很多有用的方法,这些方法实现起来可能不难,但却非常实用,能大大减少我们的开发时间。 本文将通过举例说明的方式来讲解 映射 map() 方法。 什么是映射 从 p5.js 文档 中可…...
idea提交代码冲突后,代码意外消失解决办法
敲了大半天的代码,解决冲突后,直接消失了当时慌的一批CCCCC 右击项目Local History ----show History 找到最近提交的内容右击选择Revert,代码全回来了...
爬虫批量下载科研论文(SciHub)
系列文章目录 利用 eutils 实现自动下载序列文件 提示:写完文章后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 系列文章目录前言一、获取文献信息二、下载文献PDF文件参考 前言 大家好✨,这里是bio🦖。…...

explain查询sql执行计划返回的字段的详细说明
当使用EXPLAIN命令查看SQL语句的执行计划时,会返回一张表格,其中包含了该SQL语句的执行计划。下面是每个字段的详细分析: id:执行计划的唯一标识符。如果查询中有子查询,每个子查询都会有一个唯一的ID。在执行计划中&a…...

讯飞输入法13.0发布,推出行业首款生成式AI输入法
🦉 AI新闻 🚀 讯飞输入法13.0发布,推出行业首款生成式AI输入法 摘要:科大讯飞在2023年全球开发者节上发布了全新讯飞输入法13.0版本,其中最大的亮点是推出了行业首款生成式AI输入法。这次升级将生成式AI能力融入输入…...

35. 搜索插入位置、Leetcode的Python实现
博客主页:🏆看看是李XX还是李歘歘 🏆 🌺每天分享一些包括但不限于计算机基础、算法等相关的知识点🌺 💗点关注不迷路,总有一些📖知识点📖是你想要的💗 ⛽️今…...

使用 DDPO 在 TRL 中微调 Stable Diffusion 模型
引言 扩散模型 (如 DALL-E 2、Stable Diffusion) 是一类文生图模型,在生成图像 (尤其是有照片级真实感的图像) 方面取得了广泛成功。然而,这些模型生成的图像可能并不总是符合人类偏好或人类意图。因此出现了对齐问题,即如何确保模型的输出与…...

cocosCreator 之 crypto-es数据加密
版本: 3.8.0 语言: TypeScript 环境: Mac 简介 项目开发中,针对于一些明文数据,比如本地存储和Http数据请求等,进行加密保护,是有必要的。 关于加密手段主要有: 对称加密 使用相…...

Leetcode---368周赛
题目列表 2908. 元素和最小的山形三元组 I 2909. 元素和最小的山形三元组 II 2910. 合法分组的最少组数 2911. 得到 K 个半回文串的最少修改次数 一、元素和最小的山形三元组I 没什么好说的,不会其他方法就直接暴力,时间复杂度O(n^3),代…...
矢量图形编辑软件Illustrator 2023 mac中文版软件特点(ai2023) v27.9
illustrator 2023 mac是一款矢量图形编辑软件,用于创建和编辑排版、图标、标志、插图和其他类型的矢量图形。 illustrator 2023 mac软件特点 矢量图形:illustrator创建的图形是矢量图形,可以无限放大而不失真,这与像素图形编辑软…...

一、Docker Compose——什么是 Docker Compose
Docker Compose 是一个用来定义和运行多容器 Docker 应用程序的工具,他的方便之处就是可以使用 YAML 文件来配置将要运行的 Docker 容器,然后使用一条命令即可创建并启动配置好的 Docker 容器了;相比手动输入命令的繁琐,Docker Co…...

Java提升技术,进阶为高级开发和架构师的路线
原文网址:Java提升技术,进阶为高级开发和架构师的路线-CSDN博客 简介 Java怎样提升技术?怎样进阶为高级开发和架构师?本文介绍靠谱的成长路线。 首先点明,只写业务代码是无法成长技术的。提升技术的两个方法是&…...

记一次 .Net+SqlSugar 查询超时的问题排查过程
环境和版本:.Net 6 SqlSuger 5.1.4.* ,数据库是mysql 5.7 ,数据量在2000多条左右 业务是一个非常简单的查询,代码如下: var list _dbClient.Queryable<tb_name>().ToList(); tb_name 下配置了一对多的关系…...
PHP危险函数
PHP危险函数 文章目录 PHP危险函数PHP 代码执行函数eval 语句assert()语句preg_replace()函数正则表达式里修饰符 回调函数call_user_func()函数array_map()函数 OS命令执行函数system()函数exec()函数shell_exec()函数passthru() 函数popen 函数反引号 实列 通过构造函数可以执…...

【ARM Cortex-M 系列 4 番外篇 -- 常用 benchmark 介绍】
文章目录 1.1 CPU 性能测试 MIPS 计算1.1.1 Cortex-M7 CPI 1.2 benchmark 小节1.3.1 Geekbenck 介绍 1.3 编译参数配置 1.1 CPU 性能测试 MIPS 计算 每秒百万指令数 (MIPS):在数据压缩测试中,MIPS 每秒测量一次 CPU 执行的低级指令的数量。越高越好&…...
web安全-原发抗抵赖
原发抗抵赖 原发抗抵赖也称不可否认性,主要表现以下两种形式: 数据发送者无法否认其发送数据的事实。例如,A向B发信,事后,A不能否认该信是其发送的。数据接收者事后无法否认其收到过这些数据。例如,A向B发…...

强化学习------PPO算法
目录 简介一、PPO原理1、由On-policy 转化为Off-policy2、Importance Sampling(重要性采样)3、off-policy下的梯度公式推导 二、PPO算法两种形式1、PPO-Penalty2、PPO-Clip 三、PPO算法实战四、参考 简介 PPO 算法之所以被提出,根本原因在于…...

别再手动调参了!用Simulink系统辨识工具箱,5分钟搞定Buck电路的PID控制器设计
电力电子工程师的效率革命:用Simulink系统辨识工具箱5步完成Buck电路PID设计 在电力电子领域,Buck电路作为最基础的DC-DC降压拓扑,其控制器设计一直是工程师的必修课。传统的手工计算和试错调参方法不仅耗时费力,还难以达到理想的…...
)
你还在手动调参?——用Python自动化脚本批量生成表现主义变体并智能评分(GitHub开源已验证)
更多请点击: https://intelliparadigm.com 第一章:你还在手动调参?——用Python自动化脚本批量生成表现主义变体并智能评分(GitHub开源已验证) 表现主义图像生成常依赖艺术家风格参数(如笔触强度、色域饱和…...

MA730/MT6835/MT6825/MT6709磁编码器SPI通信实战:从寄存器配置到角度解析
1. 磁编码器SPI通信基础与选型指南 磁编码器作为现代电机控制和机器人系统中的核心传感器,其精度和响应速度直接影响整个系统的性能。MA730、MT6835、MT6825和MT6709这几款磁编码器在工业界应用广泛,它们都采用SPI接口进行通信,但在具体实现上…...
上电自动重枚举的两种实现方法)
告别反复拔插!STM32F103 USB Device(CDC/MSC)上电自动重枚举的两种实现方法
STM32F103 USB设备免拔插重枚举技术深度解析 引言 在嵌入式开发领域,STM32F103系列微控制器因其出色的性价比和丰富的外设资源,成为众多工程师的首选。其中,USB接口的开发应用尤为广泛,从虚拟串口(CDC)到大容量存储设备(MSC)&…...
:Voice Cloning商用授权条款升级对SaaS产品的3重合规冲击)
ElevenLabs 2024定价突变预警(附迁移成本计算器):Voice Cloning商用授权条款升级对SaaS产品的3重合规冲击
更多请点击: https://intelliparadigm.com 第一章:ElevenLabs定价策略分析 核心订阅层级与功能边界 ElevenLabs 当前采用三层订阅模型(Starter、Creator、Professional),各层级在语音生成时长、并发请求、自定义声音…...

ChatGPT-PerfectUI:开源前端界面部署与核心功能解析
1. 项目概述:一个为ChatGPT打造的“完美”前端界面如果你和我一样,是ChatGPT的重度用户,每天都要和它进行大量的对话,那么你肯定对官方那个略显简陋的Web界面有过一些“怨念”。功能切换不够直观、对话管理略显笨拙、界面风格万年…...

Windows和Office智能激活终极指南:KMS_VL_ALL_AIO完整使用教程
Windows和Office智能激活终极指南:KMS_VL_ALL_AIO完整使用教程 【免费下载链接】KMS_VL_ALL_AIO Smart Activation Script 项目地址: https://gitcode.com/gh_mirrors/km/KMS_VL_ALL_AIO 还在为Windows系统频繁弹出激活提示而烦恼吗?Office文档突…...

基于MCP协议构建加密货币数据查询工具:coinpaprika-mcp详解
1. 项目概述:一个连接加密货币数据世界的桥梁 最近在折腾一个需要实时获取多种加密货币数据的项目,从价格、市值到社区动态,需求五花八门。市面上数据源不少,但要么API调用限制太死,要么数据维度不够全,要…...

电商网站滑块验证码破解:OpenCV图像识别+轨迹模拟方案
一、前言当前主流电商、会员登录、抢购下单、接口风控场景中,滑块拼图验证码已是最常见的人机校验方式。传统简单爬虫直接请求接口极易被拦截,而滑块验证码核心防护逻辑分为两点:一是缺口位置图像匹配校验,二是人为滑动轨迹行为风…...

AI自动化工具开发实战:从免费API整合到浏览器自动化
1. 项目概述与核心价值最近在GitHub上闲逛,发现了一个挺有意思的项目,叫ruwiss/ai-auto-free。光看名字,你可能会有点懵,“AI自动免费”?这到底是个啥玩意儿。我花了不少时间研究源码、测试功能,还把它部署…...