Python 编写 Flink 应用程序经验记录(Flink1.17.1)
目录
官方API文档
提交作业到集群运行
官方示例
环境
编写一个 Flink Python Table API 程序
执行一个 Flink Python Table API 程序
实例处理Kafka后入库到Mysql
下载依赖
flink-kafka jar
读取kafka数据
写入mysql数据
flink-mysql jar
官方API文档
https://nightlies.apache.org/flink/flink-docs-release-1.17/zh/docs/dev/python/overview/
https://nightlies.apache.org/flink/flink-docs-release-1.17/zh/docs/connectors/datastream/kafka/
提交作业到集群运行
#! /usr/bin/env python
# -*- coding: utf-8 -*-# /opt/test_flink.py
if __name__ == "__main__":print("这是一个简单的测试用例")flink 安装目录下的 examples 目录里面已经提供了一些测试案例,我们也可以直接拿它来做实验。
提交至集群
./bin/flink run -py 代码文件通过 flink run 即可运行应用程序,由于 flink 既可运行 Java 程序、也可以运行 Python 程序,所以这里我们需要指定 -py 参数,表示运行的是 py 文件。但默认情况下解释器使用的 python2,当然如果你终端输入 python 进入的就是 python3 的话则当我没说,要是我们想指定 flink 使用 python3 解释器的话,则需要配置一个环境变量。
export PYFLINK_CLIENT_EXECUTABLE=/usr/bin/python3下面来测试一下:
./bin/flink run -py /opt/test_flink.py
很明显结果是成功的,当然这里面没有涉及到任何与 Flink 有关的内容,只是演示如何提交一个 Python 应用程序。当然 flink run 是同时支持 Java、Python 等语言的。
不管使用哪种 API 进行编程,最终客户端都会生成 JobGraph 提交到 JM 上。但毕竟 Flink 的内核是采用 Java 语言编写的,如果 Python 应用程序变成 JobGraph 对象被提交到 Flink 集群上运行的话,那么 Python 虚拟机和 Java 虚拟机之间一定有某种方式,使得 Python 可以直接动态访问 Java 中的对象、Java 也可以回调 Python 中的对象。没错,实现这一点的便是 py4j。
提交单个 py 文件知道怎么做了,但如果该文件还导入了其它文件该怎么办呢?一个项目中还会涉及到包的存在。其实不管项目里的文件有多少,启动文件只有一个,只需要把这个启动文件提交上去即可。举例说明,当然这里仍不涉及具体和 Flink 相关的内容,先把如何提交程序这一步给走通。因为不管编写的程序多复杂,提交这一步骤是不会变的。
先来看看编写的程序:
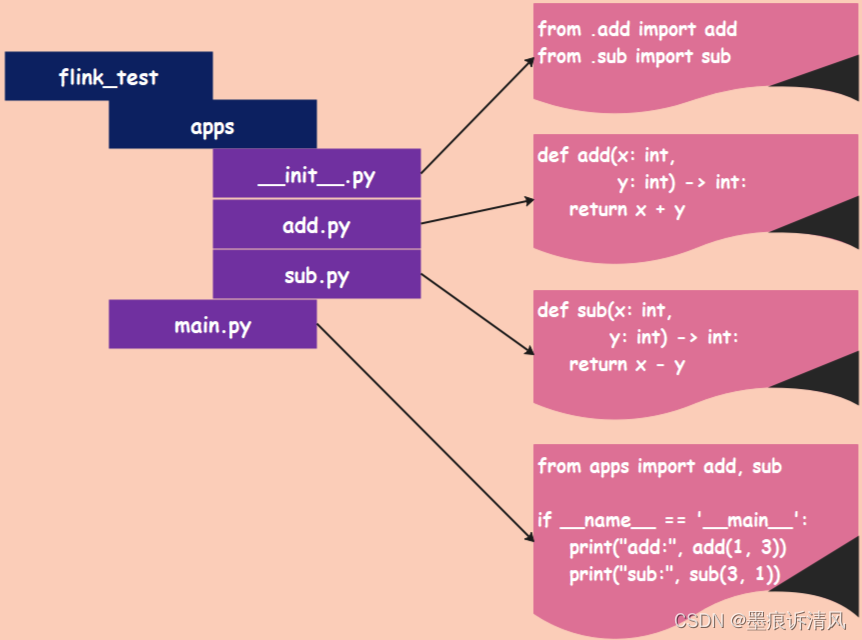
flink_test 就是主目录,里面有一个 apps 子目录和一个 main.py 文件,apps 目录里面有三个 py 文件,对应的内容分别如图所示。然后将其提交到 Flink Standalone 集群上运行,命令和提交单个文件是一样的:

即使是多文件,提交方式也是相似的,输出结果表明提交成功了。
官方示例
环境
- Java 11
- Python 3.7, 3.8, 3.9 or 3.10
python -m pip install apache-flink==1.17.1编写一个 Flink Python Table API 程序
编写 Flink Python Table API 程序的第一步是创建 TableEnvironment。这是 Python Table API 作业的入口类。
t_env = TableEnvironment.create(EnvironmentSettings.in_streaming_mode())
t_env.get_config().set("parallelism.default", "1")接下来,我们将介绍如何创建源表和结果表。
t_env.create_temporary_table('source',TableDescriptor.for_connector('filesystem').schema(Schema.new_builder().column('word', DataTypes.STRING()).build()).option('path', input_path).format('csv').build())
tab = t_env.from_path('source')t_env.create_temporary_table('sink',TableDescriptor.for_connector('filesystem').schema(Schema.new_builder().column('word', DataTypes.STRING()).column('count', DataTypes.BIGINT()).build()).option('path', output_path).format(FormatDescriptor.for_format('canal-json').build()).build())你也可以使用 TableEnvironment.execute_sql() 方法,通过 DDL 语句来注册源表和结果表:
my_source_ddl = """create table source (word STRING) with ('connector' = 'filesystem','format' = 'csv','path' = '{}')
""".format(input_path)my_sink_ddl = """create table sink (word STRING,`count` BIGINT) with ('connector' = 'filesystem','format' = 'canal-json','path' = '{}')
""".format(output_path)t_env.execute_sql(my_source_ddl)
t_env.execute_sql(my_sink_ddl)上面的程序展示了如何创建及注册表名分别为 source 和 sink 的表。 其中,源表 source 有一列: word,该表代表了从 input_path 所指定的输入文件中读取的单词; 结果表 sink 有两列: word 和 count,该表的结果会输出到 output_path 所指定的输出文件中。
接下来,我们介绍如何创建一个作业:该作业读取表 source 中的数据,进行一些变换,然后将结果写入表 sink。
最后,需要做的就是启动 Flink Python Table API 作业。上面所有的操作,比如创建源表 进行变换以及写入结果表的操作都只是构建作业逻辑图,只有当 execute_insert(sink_name) 被调用的时候, 作业才会被真正提交到集群或者本地进行执行。
@udtf(result_types=[DataTypes.STRING()])
def split(line: Row):for s in line[0].split():yield Row(s)# 计算 word count
tab.flat_map(split).alias('word') \.group_by(col('word')) \.select(col('word'), lit(1).count) \.execute_insert('sink') \.wait()该教程的完整代码如下:
import argparse
import logging
import sysfrom pyflink.common import Row
from pyflink.table import (EnvironmentSettings, TableEnvironment, TableDescriptor, Schema,DataTypes, FormatDescriptor)
from pyflink.table.expressions import lit, col
from pyflink.table.udf import udtfword_count_data = ["To be, or not to be,--that is the question:--","Whether 'tis nobler in the mind to suffer","The slings and arrows of outrageous fortune","Or to take arms against a sea of troubles,","And by opposing end them?--To die,--to sleep,--","No more; and by a sleep to say we end","The heartache, and the thousand natural shocks","That flesh is heir to,--'tis a consummation","Devoutly to be wish'd. To die,--to sleep;--","To sleep! perchance to dream:--ay, there's the rub;","For in that sleep of death what dreams may come,","When we have shuffled off this mortal coil,","Must give us pause: there's the respect","That makes calamity of so long life;","For who would bear the whips and scorns of time,","The oppressor's wrong, the proud man's contumely,","The pangs of despis'd love, the law's delay,","The insolence of office, and the spurns","That patient merit of the unworthy takes,","When he himself might his quietus make","With a bare bodkin? who would these fardels bear,","To grunt and sweat under a weary life,","But that the dread of something after death,--","The undiscover'd country, from whose bourn","No traveller returns,--puzzles the will,","And makes us rather bear those ills we have","Than fly to others that we know not of?","Thus conscience does make cowards of us all;","And thus the native hue of resolution","Is sicklied o'er with the pale cast of thought;","And enterprises of great pith and moment,","With this regard, their currents turn awry,","And lose the name of action.--Soft you now!","The fair Ophelia!--Nymph, in thy orisons","Be all my sins remember'd."]def word_count(input_path, output_path):t_env = TableEnvironment.create(EnvironmentSettings.in_streaming_mode())# write all the data to one filet_env.get_config().set("parallelism.default", "1")# define the sourceif input_path is not None:t_env.create_temporary_table('source',TableDescriptor.for_connector('filesystem').schema(Schema.new_builder().column('word', DataTypes.STRING()).build()).option('path', input_path).format('csv').build())tab = t_env.from_path('source')else:print("Executing word_count example with default input data set.")print("Use --input to specify file input.")tab = t_env.from_elements(map(lambda i: (i,), word_count_data),DataTypes.ROW([DataTypes.FIELD('line', DataTypes.STRING())]))# define the sinkif output_path is not None:t_env.create_temporary_table('sink',TableDescriptor.for_connector('filesystem').schema(Schema.new_builder().column('word', DataTypes.STRING()).column('count', DataTypes.BIGINT()).build()).option('path', output_path).format(FormatDescriptor.for_format('canal-json').build()).build())else:print("Printing result to stdout. Use --output to specify output path.")t_env.create_temporary_table('sink',TableDescriptor.for_connector('print').schema(Schema.new_builder().column('word', DataTypes.STRING()).column('count', DataTypes.BIGINT()).build()).build())@udtf(result_types=[DataTypes.STRING()])def split(line: Row):for s in line[0].split():yield Row(s)# compute word counttab.flat_map(split).alias('word') \.group_by(col('word')) \.select(col('word'), lit(1).count) \.execute_insert('sink') \.wait()# remove .wait if submitting to a remote cluster, refer to# https://nightlies.apache.org/flink/flink-docs-stable/docs/dev/python/faq/#wait-for-jobs-to-finish-when-executing-jobs-in-mini-cluster# for more detailsif __name__ == '__main__':logging.basicConfig(stream=sys.stdout, level=logging.INFO, format="%(message)s")parser = argparse.ArgumentParser()parser.add_argument('--input',dest='input',required=False,help='Input file to process.')parser.add_argument('--output',dest='output',required=False,help='Output file to write results to.')argv = sys.argv[1:]known_args, _ = parser.parse_known_args(argv)word_count(known_args.input, known_args.output)执行一个 Flink Python Table API 程序
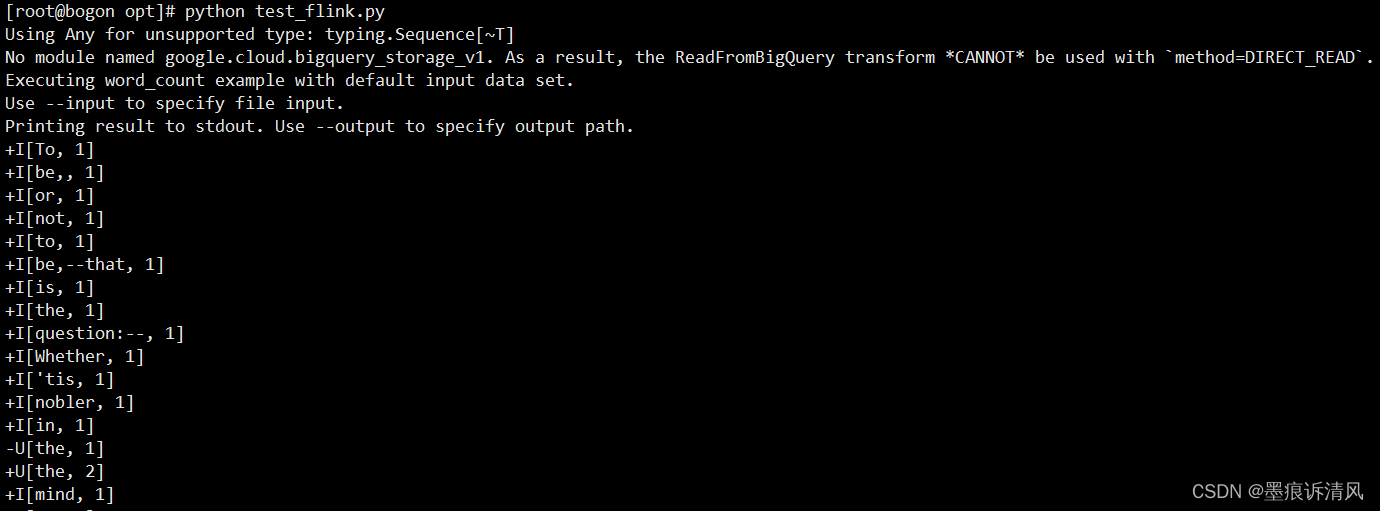
接下来,可以在命令行中运行作业(假设作业名为 word_count.py):
python word_count.py上述命令会构建 Python Table API 程序,并在本地 mini cluster 中运行。如果想将作业提交到远端集群执行, 可以参考作业提交示例。
最后,你可以得到如下运行结果:
实例处理Kafka后入库到Mysql
下载依赖
flink-kafka jar
wget https://repo.maven.apache.org/maven2/org/apache/flink/flink-sql-connector-kafka/1.17.1/flink-sql-connector-kafka-1.17.1.jar
读取kafka数据
#! /usr/bin/env python
# -*- coding: utf-8 -*-import sys
import loggingfrom pyflink.datastream import StreamExecutionEnvironment
from pyflink.common import WatermarkStrategy, Types
from pyflink.common.serialization import SimpleStringSchema
from pyflink.datastream.connectors.kafka import KafkaSource, KafkaOffsetsInitializerfrom pyflink.common import Row
from pyflink.datastream import FlatMapFunctiondef read_kafka():env = StreamExecutionEnvironment.get_execution_environment()env.add_jars("file:///D:/安技汇/运营平台/DataManage/flink-sql-connector-kafka-1.17.1.jar")source = KafkaSource.builder() \.set_bootstrap_servers("172.16.12.128:9092") \.set_topics("test") \.set_group_id("my-group") \.set_starting_offsets(KafkaOffsetsInitializer.earliest()) \.set_value_only_deserializer(SimpleStringSchema()) \.build()# 从消费组提交的位点开始消费,不指定位点重置策略#.set_starting_offsets(KafkaOffsetsInitializer.committed_offsets()) \# 从消费组提交的位点开始消费,如果提交位点不存在,使用最早位点#.set_starting_offsets(KafkaOffsetsInitializer.committed_offsets(KafkaOffsetResetStrategy.EARLIEST)) \# 从时间戳大于等于指定时间戳(毫秒)的数据开始消费#.set_starting_offsets(KafkaOffsetsInitializer.timestamp(1657256176000)) \# 从最早位点开始消费#.set_starting_offsets(KafkaOffsetsInitializer.earliest()) \# 从最末尾位点开始消费#.set_starting_offsets(KafkaOffsetsInitializer.latest()) \#.set_property("partition.discovery.interval.ms", "10000") # 每 10 秒检查一次新分区#.set_property("security.protocol", "SASL_PLAINTEXT") \#.set_property("sasl.mechanism", "PLAIN") \#.set_property("sasl.jaas.config", "org.apache.kafka.common.security.plain.PlainLoginModule required username=\"username\" password=\"password\";")kafka_stream = env.from_source(source, WatermarkStrategy.no_watermarks(), "Kafka Source")kafka_stream.print()env.execute("Source")if __name__ == "__main__":logging.basicConfig(stream=sys.stdout, level=logging.INFO, format="%(message)s")read_kafka()
写入mysql数据
flink-mysql jar
没通,待补充。。
相关文章:
Python 编写 Flink 应用程序经验记录(Flink1.17.1)
目录 官方API文档 提交作业到集群运行 官方示例 环境 编写一个 Flink Python Table API 程序 执行一个 Flink Python Table API 程序 实例处理Kafka后入库到Mysql 下载依赖 flink-kafka jar 读取kafka数据 写入mysql数据 flink-mysql jar 官方API文档 https://nigh…...

如何 通过使用优先级提示,来控制所有网页资源加载顺序
当你打开浏览器的网络标签时,你会看到大量的活动。资源正在下载,信息正在提交,事件正在记录,等等。 由于有太多的活动,有效地管理这些流量的优先级变得至关重要。带宽争用是真实存在的,当所有请求同时触发时…...

10月25日,每日信息差
今天是2023年10月26日,以下是为您准备的14条信息差 第一、百世集团牵头成立全国智慧物流与供应链行业产教融合共同体在杭州正式成立,该共同体由百世集团、浙江工商大学、浙江经济职业技术学院共同牵头 第二、问界M9预定量突破15000台 第三、前三季度我…...
泛微OA之获取每月固定日期
文章目录 1.需求及效果1.1需求1.2效果 2. 思路3. 实现 1.需求及效果 1.1需求 需要获取每个月的7号作为需发布日期,需要自动填充1.2效果 自动获取每个月的七号2. 思路 1.功能并不复杂,可以用泛微前端自带的插入代码块的功能来实现。 2.将这需要赋值的…...
Dataworks API:调取 MC 项目下所有表单
文章目录 前言Dataworks API 文档解读GetMetaDBTableList 接口文档 API 调试在线调试本地调试运行环境账密问题请求数据进一步处理 小结 前言 最近,我需要对公司的数据资产进行梳理,这其中便包括了Dataworks各个项目下的表单。这些表单,作为…...
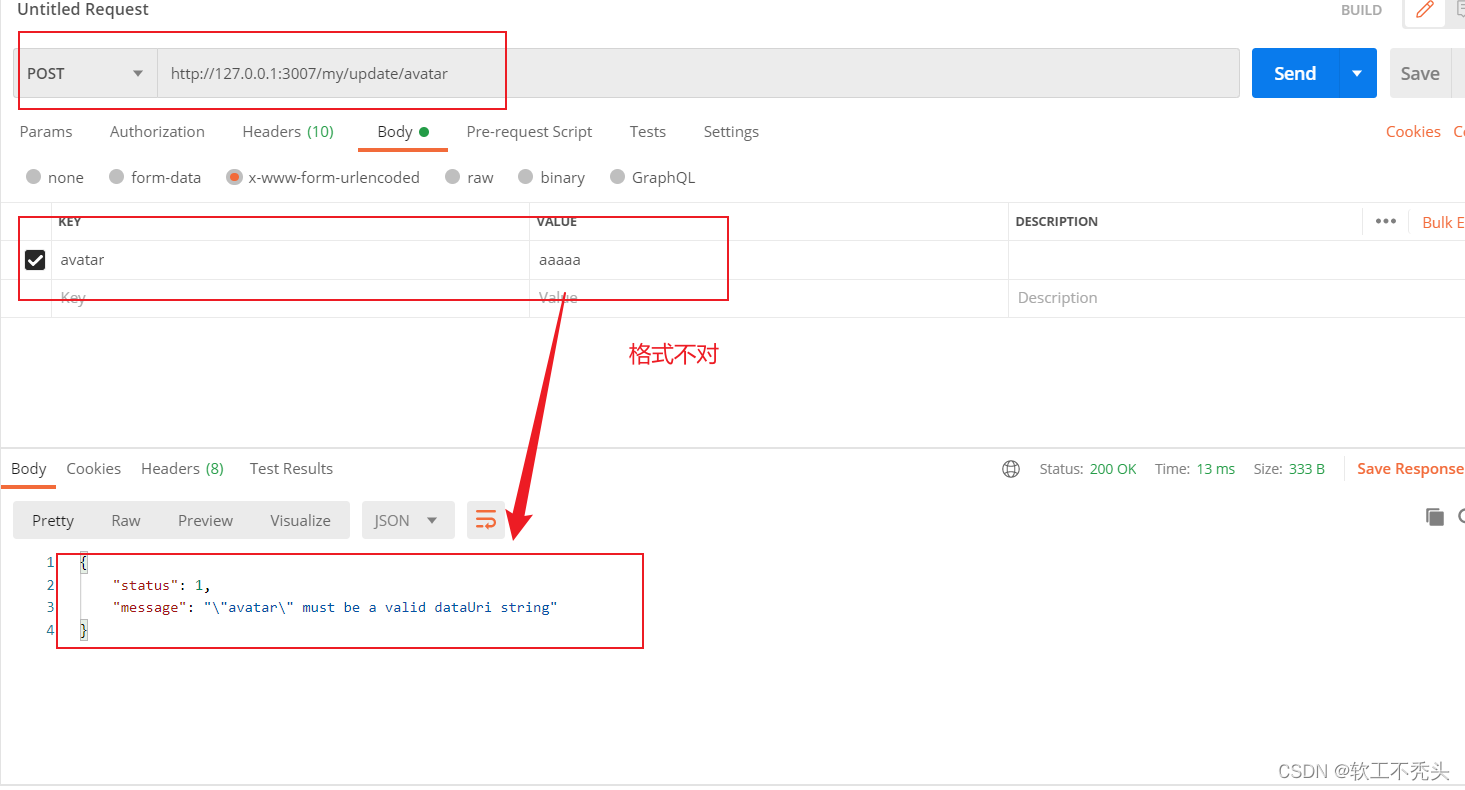
Node编写更新用户头像接口
目录 定义路由和处理函数 验证表单数据 编辑 实现更新用户头像的功能 定义路由和处理函数 向外共享定义的更新用户头像处理函数 // 更新用户头像的处理函数 exports.updateAvatar (req, res) > {res.send(更新成功) } 定义更新用户头像路由 // 更新用户头像的路由…...

MySQL3:MySQL中一条更新SQL是如何执行的?
MySQL3:MySQL中一条更新SQL是如何执行的? MySQL中一条更新SQL是如何执行的?1.Buffer Pool缓冲池2.Redo logredo log作用Redo log文件位置redo log为什么是2个? 3.Undo log4.更新过程5.InnoDB官网架构InnoDB架构-内存结构①Buffer …...

p5.js map映射
本文简介 带尬猴,我嗨德育处主任 p5.js 为开发者提供了很多有用的方法,这些方法实现起来可能不难,但却非常实用,能大大减少我们的开发时间。 本文将通过举例说明的方式来讲解 映射 map() 方法。 什么是映射 从 p5.js 文档 中可…...
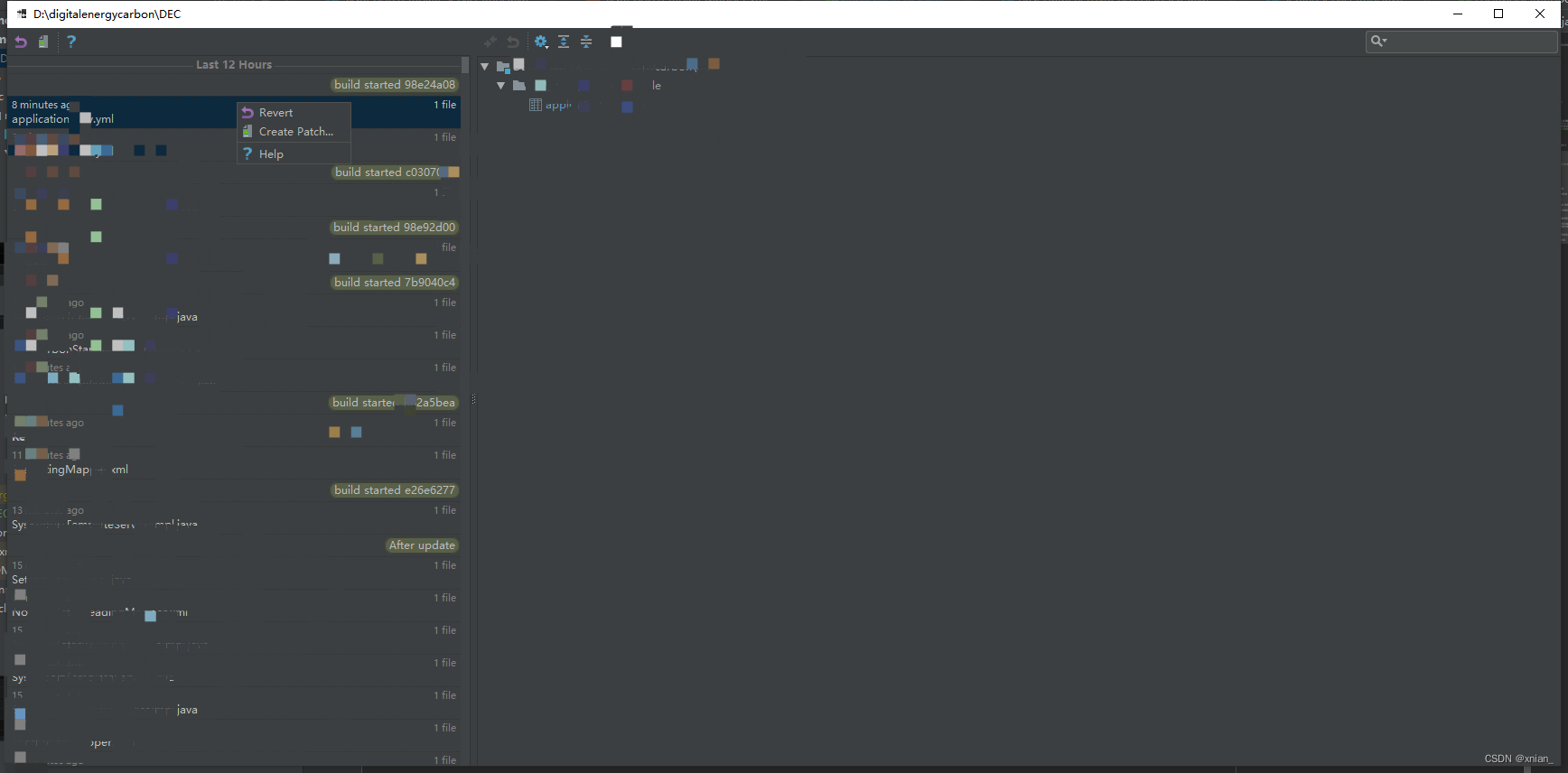
idea提交代码冲突后,代码意外消失解决办法
敲了大半天的代码,解决冲突后,直接消失了当时慌的一批CCCCC 右击项目Local History ----show History 找到最近提交的内容右击选择Revert,代码全回来了...
爬虫批量下载科研论文(SciHub)
系列文章目录 利用 eutils 实现自动下载序列文件 提示:写完文章后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 系列文章目录前言一、获取文献信息二、下载文献PDF文件参考 前言 大家好✨,这里是bio🦖。…...

explain查询sql执行计划返回的字段的详细说明
当使用EXPLAIN命令查看SQL语句的执行计划时,会返回一张表格,其中包含了该SQL语句的执行计划。下面是每个字段的详细分析: id:执行计划的唯一标识符。如果查询中有子查询,每个子查询都会有一个唯一的ID。在执行计划中&a…...

讯飞输入法13.0发布,推出行业首款生成式AI输入法
🦉 AI新闻 🚀 讯飞输入法13.0发布,推出行业首款生成式AI输入法 摘要:科大讯飞在2023年全球开发者节上发布了全新讯飞输入法13.0版本,其中最大的亮点是推出了行业首款生成式AI输入法。这次升级将生成式AI能力融入输入…...

35. 搜索插入位置、Leetcode的Python实现
博客主页:🏆看看是李XX还是李歘歘 🏆 🌺每天分享一些包括但不限于计算机基础、算法等相关的知识点🌺 💗点关注不迷路,总有一些📖知识点📖是你想要的💗 ⛽️今…...

使用 DDPO 在 TRL 中微调 Stable Diffusion 模型
引言 扩散模型 (如 DALL-E 2、Stable Diffusion) 是一类文生图模型,在生成图像 (尤其是有照片级真实感的图像) 方面取得了广泛成功。然而,这些模型生成的图像可能并不总是符合人类偏好或人类意图。因此出现了对齐问题,即如何确保模型的输出与…...

cocosCreator 之 crypto-es数据加密
版本: 3.8.0 语言: TypeScript 环境: Mac 简介 项目开发中,针对于一些明文数据,比如本地存储和Http数据请求等,进行加密保护,是有必要的。 关于加密手段主要有: 对称加密 使用相…...

Leetcode---368周赛
题目列表 2908. 元素和最小的山形三元组 I 2909. 元素和最小的山形三元组 II 2910. 合法分组的最少组数 2911. 得到 K 个半回文串的最少修改次数 一、元素和最小的山形三元组I 没什么好说的,不会其他方法就直接暴力,时间复杂度O(n^3),代…...
矢量图形编辑软件Illustrator 2023 mac中文版软件特点(ai2023) v27.9
illustrator 2023 mac是一款矢量图形编辑软件,用于创建和编辑排版、图标、标志、插图和其他类型的矢量图形。 illustrator 2023 mac软件特点 矢量图形:illustrator创建的图形是矢量图形,可以无限放大而不失真,这与像素图形编辑软…...

一、Docker Compose——什么是 Docker Compose
Docker Compose 是一个用来定义和运行多容器 Docker 应用程序的工具,他的方便之处就是可以使用 YAML 文件来配置将要运行的 Docker 容器,然后使用一条命令即可创建并启动配置好的 Docker 容器了;相比手动输入命令的繁琐,Docker Co…...

Java提升技术,进阶为高级开发和架构师的路线
原文网址:Java提升技术,进阶为高级开发和架构师的路线-CSDN博客 简介 Java怎样提升技术?怎样进阶为高级开发和架构师?本文介绍靠谱的成长路线。 首先点明,只写业务代码是无法成长技术的。提升技术的两个方法是&…...

记一次 .Net+SqlSugar 查询超时的问题排查过程
环境和版本:.Net 6 SqlSuger 5.1.4.* ,数据库是mysql 5.7 ,数据量在2000多条左右 业务是一个非常简单的查询,代码如下: var list _dbClient.Queryable<tb_name>().ToList(); tb_name 下配置了一对多的关系…...

告别电脑“飞机起飞“噪音:FanControl风扇控制终极指南
告别电脑"飞机起飞"噪音:FanControl风扇控制终极指南 【免费下载链接】FanControl.Releases This is the release repository for Fan Control, a highly customizable fan controlling software for Windows. 项目地址: https://gitcode.com/GitHub_Tr…...

G-Helper终极指南:3步快速解决华硕笔记本色彩失真问题
G-Helper终极指南:3步快速解决华硕笔记本色彩失真问题 【免费下载链接】g-helper Lightweight Armoury Crate alternative for Asus laptops with nearly the same functionality. Works with ROG Zephyrus, Flow, TUF, Strix, Scar, ProArt, Vivobook, Zenbook, Ex…...

从零到一:我的CentOS私服游戏搭建实战与避坑指南
1. 环境准备:从零开始的CentOS系统部署 第一次接触游戏私服搭建时,我像大多数新手一样对Linux系统充满敬畏。但实际用CentOS搭建环境比想象中简单——只要避开几个关键雷区。推荐使用CentOS 7.9这个经典版本,它在稳定性和软件兼容性上表现最好…...

2026届最火的十大降AI率神器解析与推荐
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 人工智能生成内容也就是 AIGC 技术迅猛发展着,其在学术领域的应用引发着深刻变革…...

在OpenClaw中配置Taotoken作为其AI模型供应商的详细步骤
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在OpenClaw中配置Taotoken作为其AI模型供应商的详细步骤 OpenClaw是一个功能强大的AI智能体开发框架,它允许开发者灵活…...

MoviePilot媒体元数据服务连接异常的技术诊断与系统解决方案
MoviePilot媒体元数据服务连接异常的技术诊断与系统解决方案 【免费下载链接】MoviePilot NAS媒体库自动化管理工具 项目地址: https://gitcode.com/gh_mirrors/mo/MoviePilot MoviePilot作为专业的NAS媒体库自动化管理工具,其核心功能依赖于TheMovieDb&…...

解放原神玩家生产力的开源工具箱:Snap.Hutao如何用本地化数据处理重塑游戏体验
解放原神玩家生产力的开源工具箱:Snap.Hutao如何用本地化数据处理重塑游戏体验 【免费下载链接】Snap.Hutao 实用的开源多功能原神工具箱 🧰 / Multifunctional Open-Source Genshin Impact Toolkit 🧰 项目地址: https://gitcode.com/GitH…...

BookGet 终极指南:一键下载全球50+图书馆古籍资源的完整教程
BookGet 终极指南:一键下载全球50图书馆古籍资源的完整教程 【免费下载链接】bookget bookget 数字古籍图书下载工具。 项目地址: https://gitcode.com/gh_mirrors/bo/bookget 在数字时代,古籍研究者和历史爱好者面临着一个共同挑战:如…...

FanControl风扇控制:3分钟掌握专业级Windows散热管理终极指南
FanControl风扇控制:3分钟掌握专业级Windows散热管理终极指南 【免费下载链接】FanControl.Releases This is the release repository for Fan Control, a highly customizable fan controlling software for Windows. 项目地址: https://gitcode.com/GitHub_Tren…...

draw.io桌面版终极指南:免费跨平台图表编辑解决方案
draw.io桌面版终极指南:免费跨平台图表编辑解决方案 【免费下载链接】drawio-desktop Official electron build of draw.io 项目地址: https://gitcode.com/GitHub_Trending/dr/drawio-desktop 还在为不同操作系统间的图表兼容性问题而烦恼吗?&am…...