【Selenium】提高测试爬虫效率:Selenium与多线程的完美结合

前言
使用Selenium 创建多个浏览器,这在自动化操作中非常常见。
而在Python中,使用 Selenium + threading 或 Selenium + ThreadPoolExecutor 都是很好的实现方法。
应用场景:
- 创建多个浏览器用于测试或者数据采集;
- 使用Selenium 控制本地安装的 chrome浏览器 去做一些操作
- …
文章提供了 Selenium + threading 和 Selenium + ThreadPoolExecutor 结合的代码模板,拿来即用。
知识点📖📖

上面两个都是 Python 内置模块,无需手动安装~
导入模块
import threading
from concurrent.futures import ThreadPoolExecutor, as_completed多线程还是线程池?
在Selenium中,使用 多线程 或者是 线程池,差别并不大。主要都是网络I/O的操作。
在使用 ThreadPoolExecutor 的情况下,任务将被分配到不同的线程中执行,从而提高并发处理能力。与使用 threading 模块相比,使用 ThreadPoolExecutor 有以下优势:
- 更高的并发处理能力:线程池 可以动态地调整线程数量,以适应任务的数量和处理要求,从而提高并发处理能力。
- 更好的性能:线程池 可以根据任务的类型和大小动态地调整线程数量,从而提高性能和效率。
- …
总之,使用 线程池 可以提高并发处理能力,更易于管理,并且可以提供更好的性能和效率。
但是选择多线程,效果也不差。
所以使用哪个都不必纠结,哪个代码量更少就选哪个自然是最好的。
多个浏览器✨
Selenium自动化中需要多个浏览器,属于是非常常见的操作了。
不管是用于自动化测试、还是爬虫数据采集,这都是个可行的方法。
这里示例的代码中,线程池的运行时候只有 多线程 的一半!!!
多线程与 多 浏览器🧨
这份代码的应用场景会广一些,后续复用修改一下 browser_thread 函数的逻辑就可以了。
这里模拟相对复杂的操作,在创建的浏览器中新打开一个标签页,用于访问指定的网站。
然后切换到新打开的标签页,进行截图。
代码释义:
- 定义一个名为 start_browser 的函数,用于创建 webdriver.Chrome 对象。
- 定义一个名为 browser_thread 的函数,接受一个 webdriver.Chrome 对象和一个整数作为参数,用于打开指定网页并截图。 切换到最后一个窗口,然后截图。
- main函数创建了5个浏览器,5个线程,执行上面的操作,然后等待所有线程执行完毕。
# -*- coding: utf-8 -*-
# Name: multi_thread.py
# Author: 小月
# Date: 2023/10/26 20:00
# Description:
import threading
from selenium import webdriver
from selenium.webdriver.chrome.service import Service as ChromeService
from webdriver_manager.chrome import ChromeDriverManager
def start_browser():
service = ChromeService(ChromeDriverManager().install())
driver = webdriver.Chrome(service=service)
return driver
def browser_thread(driver: webdriver.Chrome, idx: int):
url_list = ['https://www.csdn.net/', 'https://www.baidu.com',
'https://music.163.com/', 'https://y.qq.com/', 'https://cn.vuejs.org/']
try:
driver.execute_script(f"window.open('{url_list[idx]}')")
driver.switch_to.window(driver.window_handles[-1])
driver.save_screenshot(f'{idx}.png')
return True
except Exception:
return False
def main():
for idx in range(5):
driver = start_browser()
threading.Thread(target=browser_thread, args=(driver, idx)).start()
# 等待所有线程执行完毕
for thread in threading.enumerate():
if thread is not threading.current_thread():
thread.join()
if __name__ == "__main__":
main()运行结果
- 运行时长在9.28秒(速度与网络环境有很大关系,木桶效应,取决于最后运行完成的浏览器
- 看到程序运行完成后,多出了5张截图。

线程池与 多 浏览器🎍
这份代码与 多线程与 多浏览器 的操作基本一致。速度上却比多线程节省了一半。
# -*- coding: utf-8 -*-
# Name: demo2.py
# Author: 小月
# Date: 2023/10/26 20:00
# Description:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service as ChromeService
from webdriver_manager.chrome import ChromeDriverManager
from concurrent.futures import ThreadPoolExecutor, as_completed
MAX_WORKERS = 5
service = ChromeService(ChromeDriverManager().install())
def start_browser():
driver = webdriver.Chrome(service=service)
return driver
def browser_task(driver: webdriver.Chrome, idx: int):
url_list = ['https://www.csdn.net/', 'https://www.baidu.com',
'https://music.163.com/', 'https://y.qq.com/', 'https://cn.vuejs.org/']
try:
driver.execute_script(f"window.open('{url_list[idx]}')")
driver.switch_to.window(driver.window_handles[-1])
driver.save_screenshot(f'{idx}.png')
return True
except Exception:
return False
def main():
executor = ThreadPoolExecutor(max_workers=MAX_WORKERS)
ths = list()
for idx in range(5):
driver = start_browser()
th = executor.submit(browser_task, driver, idx=idx)
ths.append(th)
# 获取结果
for future in as_completed(ths):
print(future.result())
if __name__ == "__main__":
main()运行结果
- 运行时长在4.5秒(运行效果图不是很匹配,但确实是比多线程快很多。
- 看到程序运行完成后,多出了5张截图。

多个标签页
这个的应用场景有点意思。
这里的操作与上面的 多个浏览器其实是差不多的。
区别在于:上面打开多个浏览器,这里打开多个标签页。
所以这个需要考量一个问题:资源争夺。与是这里用上了 threading.Lock 锁,用以保护资源线程安全。
多线程与 多 标签页🎃
代码释义:
与上面差不多,不解释了。
# -*- coding: utf-8 -*-
# Name: demo2.py
# Author: 小月
# Date: 2023/10/26 20:00
# Description:
import threading
from selenium import webdriver
from selenium.webdriver.chrome.service import Service as ChromeService
from webdriver_manager.chrome import ChromeDriverManager
service = ChromeService(ChromeDriverManager().install())
lock = threading.Lock()
def start_browser():
driver = webdriver.Chrome(service=service)
return driver
def browser_thread(driver: webdriver.Chrome, idx: int):
url_list = ['https://www.csdn.net/', 'https://www.baidu.com',
'https://music.163.com/', 'https://y.qq.com/', 'https://cn.vuejs.org/']
try:
lock.acquire()
driver.execute_script(f"window.open('{url_list[idx]}')")
driver.switch_to.window(driver.window_handles[idx + 1])
driver.save_screenshot(f'{idx}.png')
return True
except Exception:
return False
finally:
lock.release()
def main():
driver = start_browser()
for idx in range(5):
threading.Thread(target=browser_thread, args=(driver, idx)).start()
# 等待所有线程执行完毕
for thread in threading.enumerate():
if thread is not threading.current_thread():
thread.join()
if __name__ == "__main__":
main()运行结果
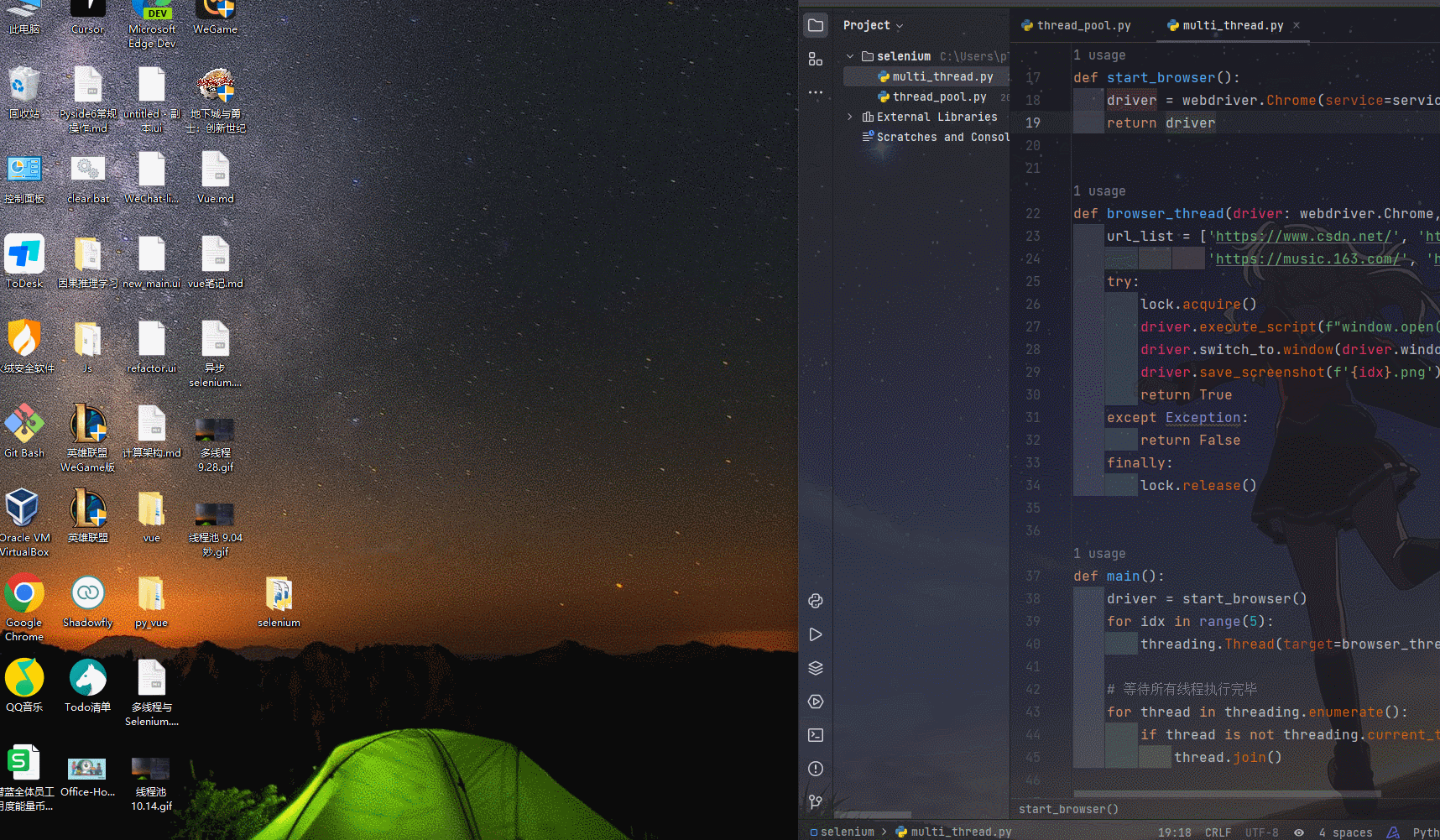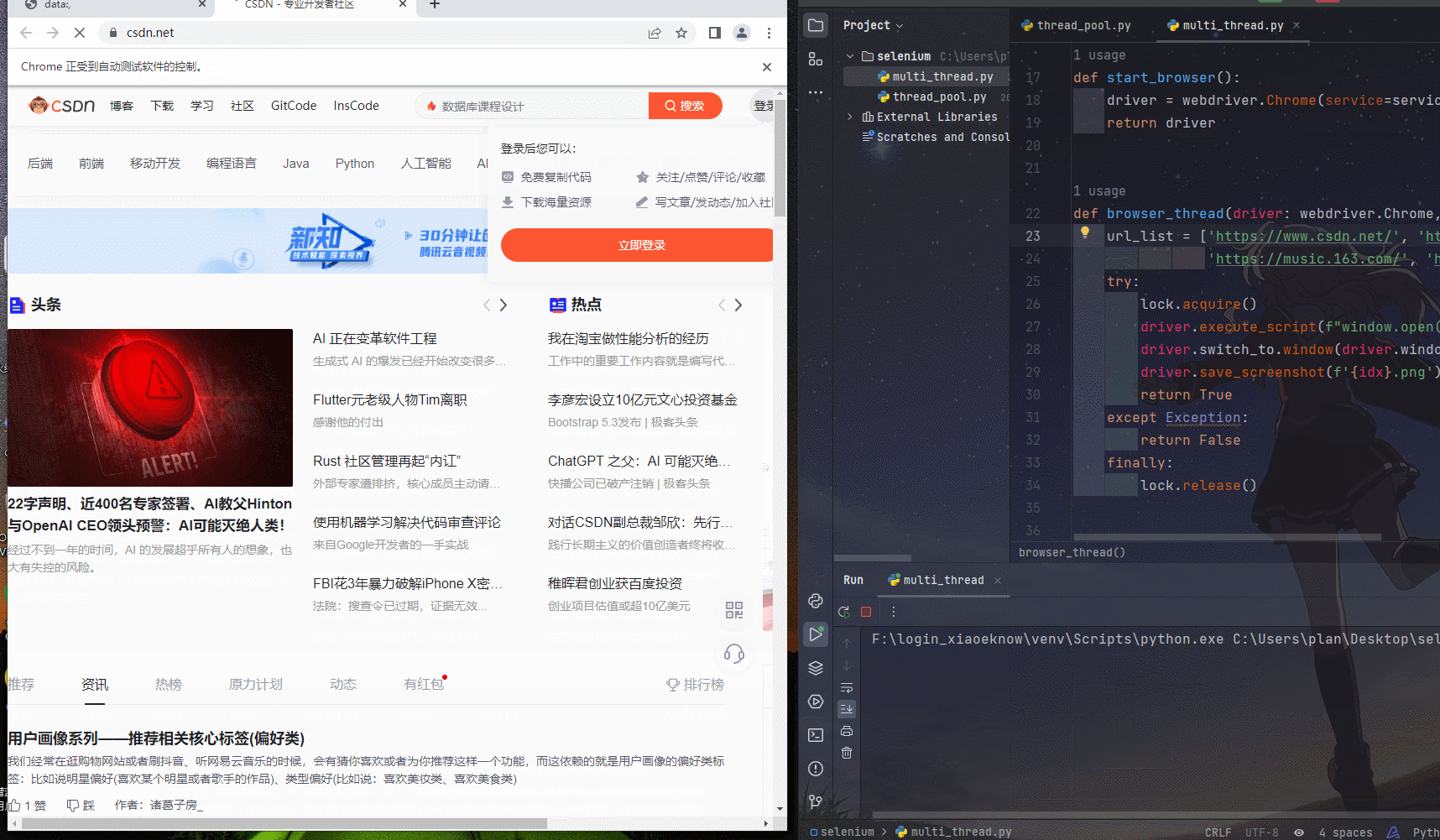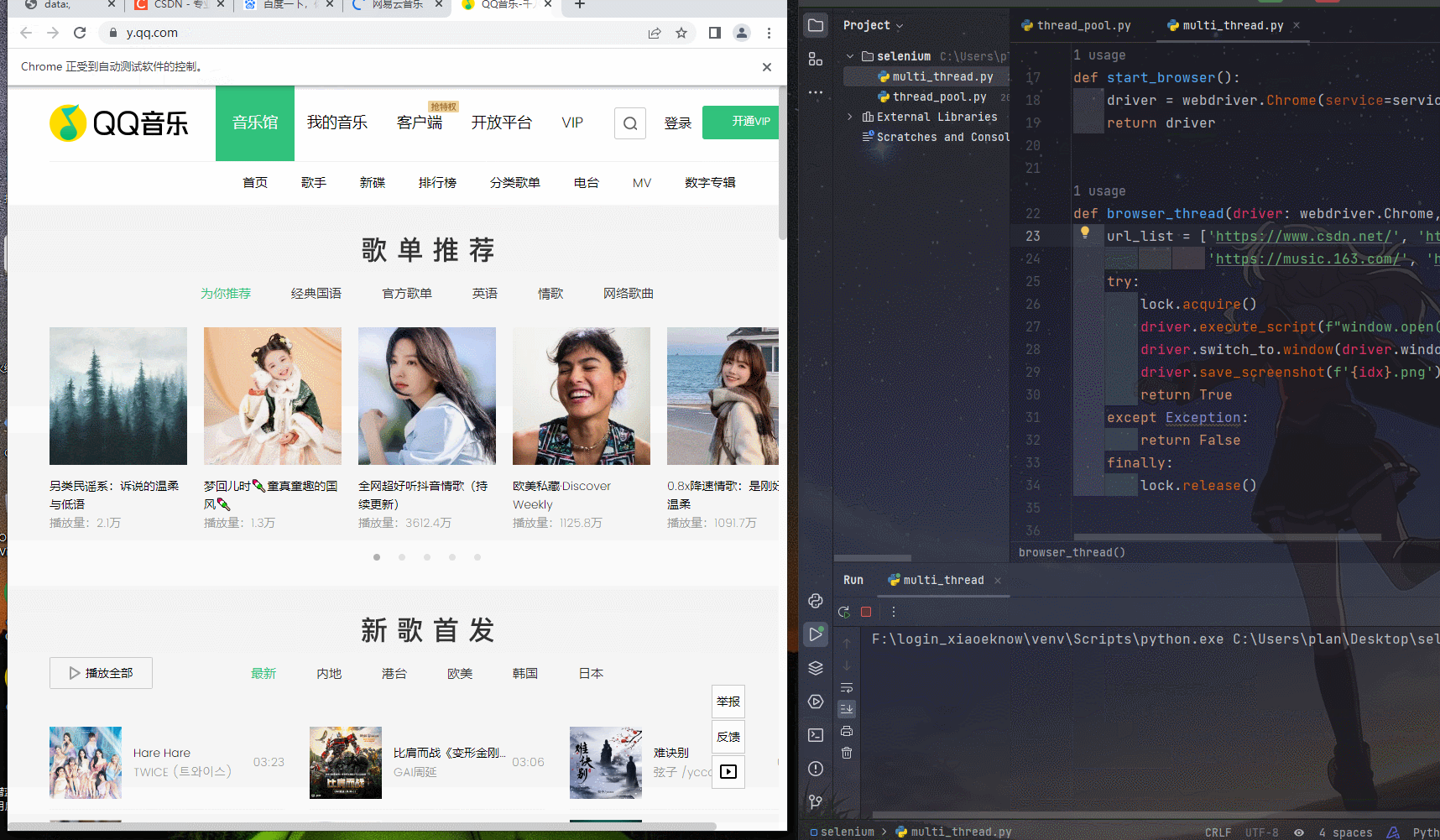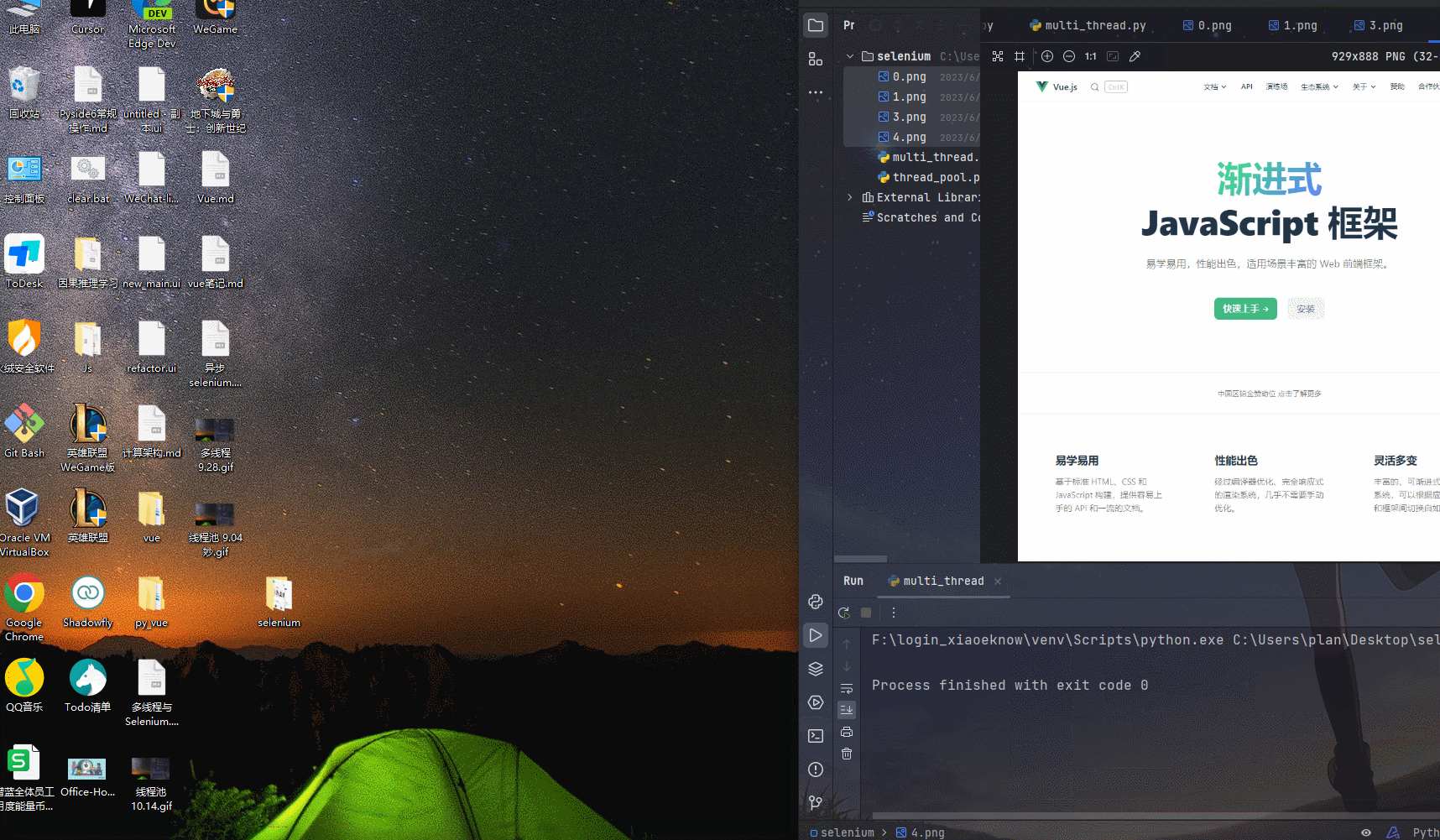
线程池与 多 标签页👀
这里不展示运行结果了,因为效果与 多线程与 多 标签页 一致。
# -*- coding: utf-8 -*-
# Name: thread_pool.py
# Author: 小月
# Date: 2023/10/26 20:00
# Description:
import time
import threading
from selenium import webdriver
from selenium.webdriver.chrome.service import Service as ChromeService
from webdriver_manager.chrome import ChromeDriverManager
from concurrent.futures import ThreadPoolExecutor, as_completed
MAX_WORKERS = 5
service = ChromeService(ChromeDriverManager().install())
lock = threading.Lock()
def start_browser():
driver = webdriver.Chrome(service=service)
return driver
def browser_task(driver: webdriver.Chrome, idx: int):
url_list = ['https://www.csdn.net/', 'https://www.baidu.com',
'https://music.163.com/', 'https://y.qq.com/', 'https://cn.vuejs.org/']
try:
lock.acquire()
driver.execute_script(f"window.open('{url_list[idx]}')")
driver.switch_to.window(driver.window_handles[idx + 1])
driver.save_screenshot(f'{idx}.png')
return True
except Exception:
return False
finally:
lock.release()
def main():
driver = start_browser()
executor = ThreadPoolExecutor(max_workers=MAX_WORKERS)
ths = list()
for idx in range(5):
th = executor.submit(browser_task, driver, idx=idx)
ths.append(th)
# 获取结果
for future in as_completed(ths):
print(future.result())
if __name__ == "__main__":
st = time.time()
main()
et = time.time()
print(et - st)总结⚡⚡
本文章介绍了 Selenium + threading 和 Selenium + ThreadPoolExecutor 来创建多个浏览器或多个标签页的操作。
文中示例的代码比较简单,所以 线程池 比 多线程 运行的更加快。
但在实际的使用过程中,可以根据自己的喜好去选择 线程池 还是 多线程 。
后话
本次分享到此结束,
see you~🐱🏍🐱🏍
相关文章:
【Selenium】提高测试爬虫效率:Selenium与多线程的完美结合
前言 使用Selenium 创建多个浏览器,这在自动化操作中非常常见。 而在Python中,使用 Selenium threading 或 Selenium ThreadPoolExecutor 都是很好的实现方法。 应用场景: 创建多个浏览器用于测试或者数据采集;使用Selenium 控…...

ElCLib类解析
OpenCascade 中的 ElCLib 类提供了对基本曲线(例如 2D 和 3D 空间中的二次曲线和直线)进行基本几何计算的函数。它提供与参数化、点评估和曲线参数范围内的定位相关的各种操作和计算。以下是一些需要注意的要点: 点和矢量计算:ElC…...
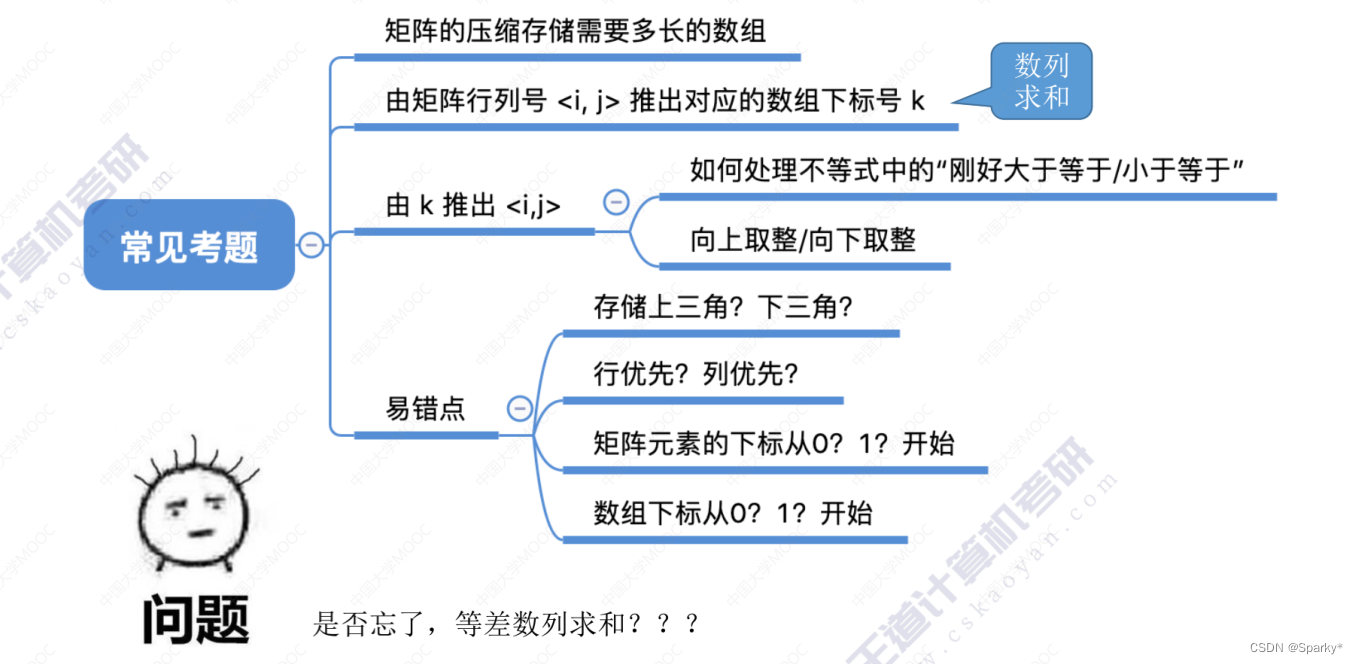
栈、队列、矩阵的总结
栈的应用 括号匹配 表达式求值(中缀,后缀) 中缀转后缀(机算) 中缀机算 后缀机算 总结 特殊矩阵 对称矩阵的压缩存储 三角矩阵 三对角矩阵 稀疏矩阵的压缩存储...
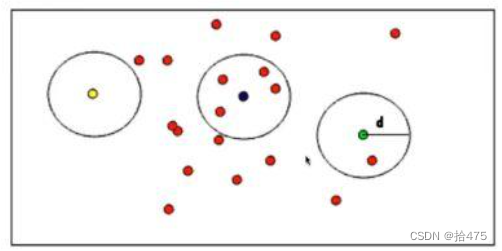
PCL 半径滤波剔除噪点
目录 一、算法原理二、注意事项三、代码实现一、算法原理 PCL半径滤波是删除在输入的点云一定范围内没有达到足够多领域的所有数据点。通俗的讲:就是以一个点p给定一个范围r,领域点要求的个数为m,r若在这个点的r范围内部的个数大于m则保留,小于m则删除。因此,使用该算法时…...
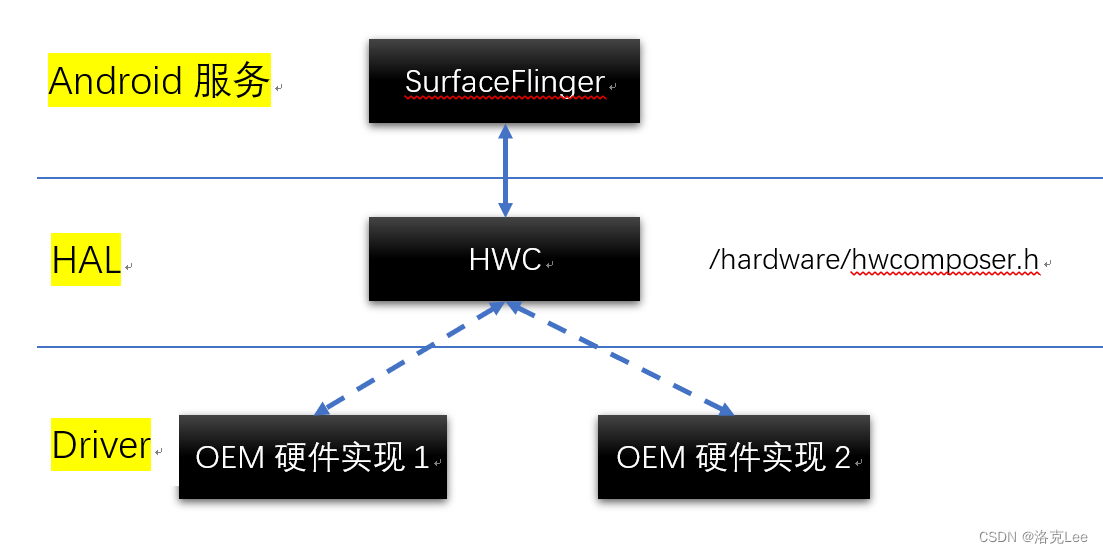
Android SurfaceFlinger做Layer合成时,如何与HAL层进行交互
目录 零、本文讨论问题的范围一、问题:SurfaceFlinger图层合成选择实现方式的两难1.1 从OpenGL ES、HWC本身来讲1.2 以HWC为主导的判断逻辑 二、SurfaceFlinger与HAL层进行交互的具体实现框架2.1 SurfaceFlinger 调用 OpenGL ES 流程2.2 FrameBuffer2.3 SurfaceFlin…...
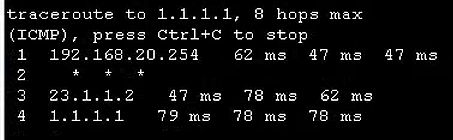
华为eNSP配置专题-策略路由的配置
文章目录 华为eNSP配置专题-策略路由的配置0、概要介绍1、前置环境1.1、宿主机1.2、eNSP模拟器 2、基本环境搭建2.1、终端构成和连接2.2、终端的基本配置 3、配置接入交换机上的VLAN4、配置核心交换机为网关和DHCP服务器5、配置核心交换机和出口路由器互通6、配置PC和出口路由器…...
JAVA实现智能停车场管理系统 开源
目录 一、摘要1.1 项目介绍1.2 项目录屏 二、研究内容A. 车主端功能B. 停车工作人员功能C. 系统管理员功能1. 停车位模块2. 车辆模块3. 停车记录模块4. IC卡模块5. IC卡挂失模块 三、界面展示3.1 登录注册3.2 车辆模块3.3 停车位模块3.4 停车数据模块3.5 IC卡档案模块3.6 IC卡挂…...

深入理解Docker之:存储卷相关概念详解和分析
深入理解Docker之:存储卷相关概念详解和分析 1. 为什么要使用存储卷 Docker镜像由多个只读层叠加而成,启动容器时,Docker会加载只读镜像层,并在镜像栈顶部添加一个读写层如果运行中的容器修改了现有的一个已经存在的文件&#x…...

Node.js的基本概念node -v 和npm -v 这两个命令的作用
Node.js 是一个开源且跨平台的 JavaScript 运行时环境,它可以让你在服务器端运行 JavaScript 代码。Node.js 使用了 Chrome 的 V8 JavaScript 引擎来执行代码,非常高效。 在 Node.js 出现之前,JavaScript 通常只在浏览器中运行,用…...

mysql bin_log日志恢复数据
1、开启bin_log日志 开启方式1 my.ini 下配置开启或者vi /etc/my.cnf log_binmysql-bin server_id1 2、参考文章 https://blog.csdn.net/DreamEhome/article/details/130010601 (重点) 【mysql】binlog日志_mysql binlog日志-CSDN博客 MySQL 开启binlog日志和windows服务…...

C++系列之list的模拟实现
💗 💗 博客:小怡同学 💗 💗 个人简介:编程小萌新 💗 💗 如果博客对大家有用的话,请点赞关注再收藏 🌞 list的节点类 template struct list_Node { public: list_Node* _prev; list_…...
?)
什么情况下你会使用AI工具(chatgpt、bard)?
在当今数字化和智能化的时代,AI工具已成为许多领域的常见工具。在本文中,我将探讨什么情况下会使用AI工具。前言 – 人工智能教程 ChatGPT是一款由OpenAI开发的大型语言模型,可以生成文本、翻译语言、编写不同类型的创意内容,并以…...
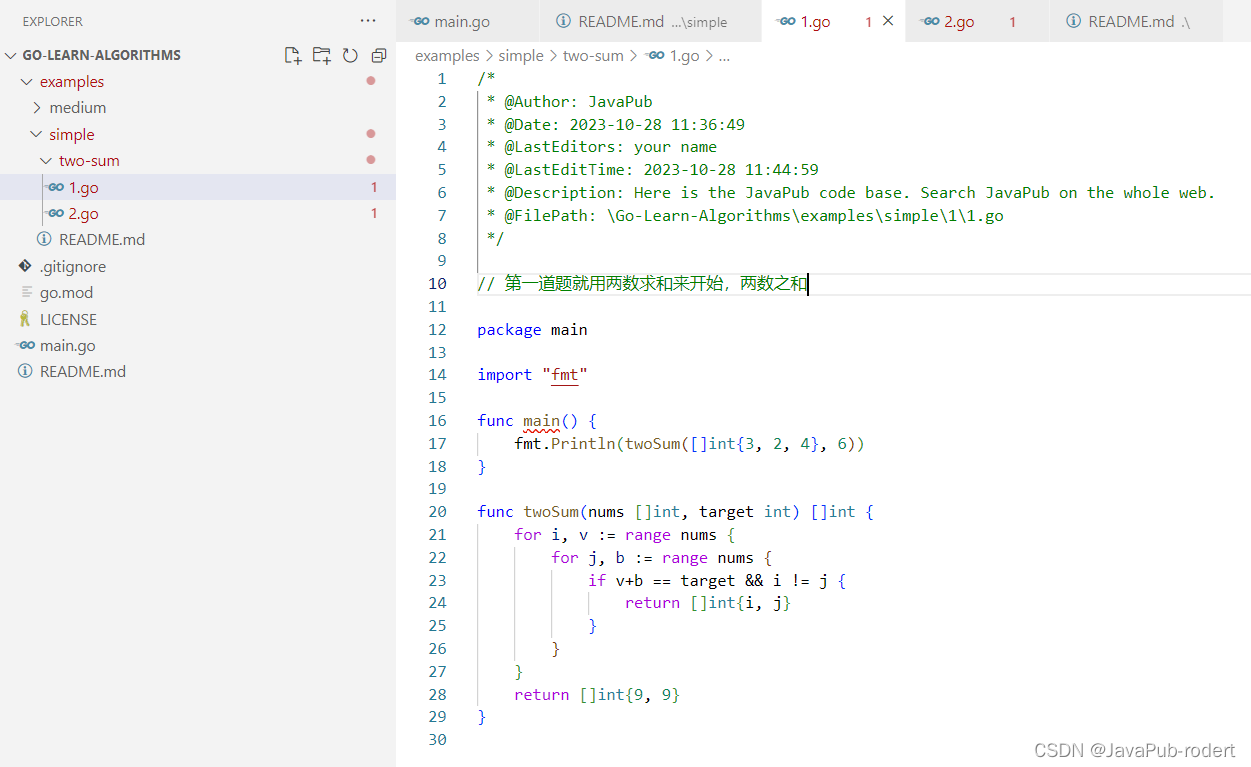
【go】两数求和
文章目录 题目代码解法2 代码仓库 题目 给定一个整数数组 nums 和一个整数目标值 target,请你在该数组中找出 和为目标值 target 的那 两个 整数,并返回它们的数组下标。 你可以假设每种输入只会对应一个答案。但是,数组中同一个元素在答案…...

软考高项-成本管理
工具和技术 三点估算 通过考虑估算中的不确定性与风险,使用3种估算值来界定活动成本的近似区间,可以提高活动成本估算的准确性; 储备分析 为应对成本的不确定性,成本估算中可以包括应急储备。应急储备的管理方法: 将…...

24年FRM备考知识点以及一级公式表
FRM一级公示表以及备考知识点 链接:https://pan.baidu.com/s/17RpFF9OyfRk7FGtEQrxf3A?pwd1234 提取码:1234 FRM二级公示表以及备考知识点 链接:https://pan.baidu.com/s/175D05wV1p94dIfBZThutCQ?pwd1234 提取码:1234...
Spring Cloud学习:二【详细】
目录 Nacos的配置 Nacos的单机启动 服务注册 Nacos服务分级存储模型 优先访问同集群的服务 根据权重负载均衡 环境隔离Namespace Nacos调用流程 Nacos与Eureka注册对比 Nacos与Eureka的共同点 Nacos与Eureka的区别 Nacos配置管理 统一配置 配置自动刷新 多环境配…...

Unity的live2dgalgame多语言可配置剧情框架
这段代码用于读取表格 using System; using System.Collections; using System.Collections.Generic; using UnityEngine; using OfficeOpenXml; using System.IO; using UnityEngine.Networking; using UnityEngine.UI; using Random UnityEngine.Random;public class Plots…...

再畅通工程(最小生成树)
题目描述:还是畅通工程 某省调查乡村交通状况,得到的统计表中列出了任意两村庄间的距离。省政府“畅通工程”的目标是使全省任何两个村庄间都可以实现公路交通(但不一定有直接的公路相连,只要能间接通过公路可达即可)&…...
前后端分离不可忽视的陷阱,深入剖析挑战,分享解决方案,助你顺利实施分离开发。
不管你设计的系统架构是怎么样,最后都是你的组织内的沟通结构胜出。这个观点一直在组织内不断地被证明,但也不断地被忽略。 前后端分离的利与弊 近几年,随着微服务架构风格的引入、前后端生态的快速发展、多端产品化的出现,前后…...

(四)库存超卖案例实战——优化redis分布式锁
前言 在上一节内容中,我们已经实现了使用redis分布式锁解决商品“超卖”的问题,本节内容是对redis分布式锁的优化。在上一节的redis分布式锁中,我们的锁有俩个可以优化的问题。第一,锁需要实现可重入,同一个线程不用重…...

OpenCV图像预处理失效全解析,深度解读光照不均、反光伪影、亚像素抖动下的鲁棒代码实现
第一章:OpenCV图像预处理失效的典型工业场景综述在工业视觉检测系统中,OpenCV常被用作图像预处理的核心工具,但其默认参数与理想假设在真实产线环境中频繁失效。光照剧烈波动、镜头污损、金属反光、高速运动拖影以及低信噪比成像等物理约束&a…...

ESP32烧录全攻略:从命令行到GUI工具,新手也能轻松搞定
ESP32烧录全攻略:从命令行到GUI工具,新手也能轻松搞定 第一次接触ESP32开发板时,那块小小的芯片里蕴藏着无限可能,但如何将自己的代码"装进"这个硬件大脑却成了拦路虎。记得我最初尝试烧录时,面对各种专业术…...

从CISCN2019华北赛区Web1看SQL注入的巧妙绕过技巧
1. 从CISCN2019华北赛区Web1看SQL注入的巧妙绕过技巧 在CTF比赛中,Web安全题目常常会设置各种过滤规则来阻止常见的攻击手法。CISCN2019华北赛区的Web1题目"Hack World"就是一个典型的例子,它通过组合过滤的方式限制了传统SQL注入手段。这道题…...

Fast-GitHub:突破网络瓶颈的开发效率工具解决方案
Fast-GitHub:突破网络瓶颈的开发效率工具解决方案 【免费下载链接】Fast-GitHub 国内Github下载很慢,用上了这个插件后,下载速度嗖嗖嗖的~! 项目地址: https://gitcode.com/gh_mirrors/fa/Fast-GitHub 1 痛点直击ÿ…...

提升嵌入式代码注释质量的工具与技术方案
提升代码注释质量的实用工具与技术方案1. 代码注释工具概述1.1 代码注释的重要性在嵌入式系统开发中,良好的代码注释是保证项目可维护性的关键因素。专业的注释工具能够帮助开发者:创建可视化注释,提升代码可读性生成标准化的文档结构维护代码…...

咱就说中小厂房、仓库的火灾报警系统,用S7-200 PLC加组态王真的是性价比天花板——够稳定、好上手,成本还低,完全满足日常需求
基于S7-200 PLC和组态王火灾报警控制系统 我们主要的后发送的产品有,带解释的梯形图接线图原理图图纸,io分配,组态画面咱先从最基础的IO分配说起,直接给大家上我常用的分配表(都是经过3个项目验证的,靠谱…...
)
LVGL 7.11.0 Chart控件实战:5分钟搞定动态心率折线图(附完整代码)
LVGL 7.11.0 Chart控件实战:5分钟搞定动态心率折线图(附完整代码) 在嵌入式设备上实现流畅的数据可视化一直是开发者的痛点。LVGL作为轻量级图形库,其Chart控件能完美解决这一问题。本文将手把手教你用LVGL 7.11.0的Chart控件&am…...

Ubuntu系统下Intel D405深度相机与Realsense-viewer的初次邂逅与配置实战
1. 开箱初体验:Intel D405深度相机的硬件揭秘 第一次拿到Intel D405深度相机时,那个黑色包装盒比想象中要小巧。拆开包装后,你会看到相机本体、USB数据线和几份纸质文档。相机重量约100克,尺寸和一副扑克牌相当,非常适…...
)
告别ZooKeeper!ClickHouse Keeper双机集群搭建全攻略(含常见报错解决方案)
ClickHouse Keeper双机集群实战指南:从零搭建到故障排查 1. 为什么选择ClickHouse Keeper替代ZooKeeper 在ClickHouse集群架构中,协调服务一直扮演着关键角色。传统方案依赖ZooKeeper实现分布式协调,但这种方式存在几个明显痛点: …...

巨有科技:银发文旅风口来了!康养旅游这样做才赚
随着老龄化社会加深与全民健康意识提升,康养旅游成为2026年文旅行业最具潜力的风口赛道,银发旅游群体持续壮大,成为文旅市场核心增量。但当下康养旅游普遍存在产品单一、服务不专业、运营不规范、适配性不足等问题,传统观光式旅游…...