CentOS 搭建 Hadoop3 高可用集群
Hadoop FullyDistributed Mode 完全分布式
| spark101 | spark102 | spark103 |
|---|---|---|
| 192.168.171.101 | 192.168.171.102 | 192.168.171.103 |
| namenode | namenode | |
| journalnode | journalnode | journalnode |
| datanode | datanode | datanode |
| nodemanager | nodemanager | nodemanager |
| recource manager | recource manager | |
| job history | ||
| job log | job log | job log |
1. 准备
1.1 升级操作系统和软件
yum -y update
升级后建议重启
1.2 安装常用软件
yum -y install gcc gcc-c++ autoconf automake cmake make rsync vim man zip unzip net-tools zlib zlib-devel openssl openssl-devel pcre-devel tcpdump lrzsz tar wget openssh-server
1.3 修改主机名
hostnamectl set-hostname spark01
hostnamectl set-hostname spark02
hostnamectl set-hostname spark03
1.4 修改IP地址
vim /etc/sysconfig/network-scripts/ifcfg-ens160
网卡 配置文件示例
TYPE="Ethernet"
PROXY_METHOD="none"
BROWSER_ONLY="no"
BOOTPROTO="none"
DEFROUTE="yes"
IPV4_FAILURE_FATAL="no"
IPV6INIT="yes"
IPV6_AUTOCONF="yes"
IPV6_DEFROUTE="yes"
IPV6_FAILURE_FATAL="no"
IPV6_ADDR_GEN_MODE="stable-privacy"
NAME="ens32"
DEVICE="ens32"
ONBOOT="yes"
IPADDR="192.168.171.101"
PREFIX="24"
GATEWAY="192.168.171.2"
DNS1="192.168.171.2"
IPV6_PRIVACY="no"
1.5 关闭防火墙
sed -i 's/SELINUX=enforcing/SELINUX=disabled/g' /etc/selinux/configsetenforce 0
systemctl stop firewalld
systemctl disable firewalld
1.6 修改hosts配置文件
vim /etc/hosts
修改内容如下:
192.168.171.101 spark01
192.168.171.102 spark02
192.168.171.103 spark03
1.7 上传软件配置环境变量
在所有主机节点创建软件目录
mkdir -p /opt/soft
以下操作在 hadoop101 主机上完成
进入软件目录
cd /opt/soft
下载 JDK
wget https://download.oracle.com/otn/java/jdk/8u391-b13/b291ca3e0c8548b5a51d5a5f50063037/jdk-8u391-linux-x64.tar.gz?AuthParam=1698206552_11c0bb831efdf87adfd187b0e4ccf970
下载 zookeeper
wget https://dlcdn.apache.org/zookeeper/zookeeper-3.8.3/apache-zookeeper-3.8.3-bin.tar.gz
下载 hadoop
wget https://dlcdn.apache.org/hadoop/common/hadoop-3.3.5/hadoop-3.3.5.tar.gz
解压 JDK 修改名称
解压 zookeeper 修改名称
解压 hadoop 修改名称
tar -zxvf jdk-8u391-linux-x64.tar.gz -C /opt/soft/
mv jdk1.8.0_391/ jdk-8
tar -zxvf apache-zookeeper-3.8.3-bin.tar.gz
mv apache-zookeeper-3.8.3-bin zookeeper-3
tar -zxvf hadoop-3.3.5.tar.gz -C /opt/soft/
mv hadoop-3.3.5/ hadoop-3
配置环境变量
vim /etc/profile.d/my_env.sh
编写以下内容:
export JAVA_HOME=/opt/soft/jdk-8
export set JAVA_OPTS="--add-opens java.base/java.lang=ALL-UNNAMED"export ZOOKEEPER_HOME=/opt/soft/zookeeper-3export HDFS_NAMENODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_ZKFC_USER=root
export HDFS_JOURNALNODE_USER=rootexport YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=rootexport HADOOP_HOME=/opt/soft/hadoop-3
export HADOOP_INSTALL=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoopexport PATH=$PATH:$JAVA_HOME/bin:$ZOOKEEPER_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin生成新的环境变量
注意:分发软件和配置文件后 在所有主机执行该步骤
source /etc/profile
2. zookeeper
2.1 编辑配置文件
cd $ZOOKEEPER_HOME/conf
vim zoo.cfg
# 心跳单位,2s
tickTime=2000
# zookeeper-3初始化的同步超时时间,10个心跳单位,也即20s
initLimit=10
# 普通同步:发送一个请求并得到响应的超时时间,5个心跳单位也即10s
syncLimit=5
# 内存快照数据的存储位置
dataDir=/home/zookeeper-3/data
# 事务日志的存储位置
dataLogDir=/home/zookeeper-3/datalog
# 当前zookeeper-3节点的端口
clientPort=2181
# 单个客户端到集群中单个节点的并发连接数,通过ip判断是否同一个客户端,默认60
maxClientCnxns=1000
# 保留7个内存快照文件在dataDir中,默认保留3个
autopurge.snapRetainCount=7
# 清除快照的定时任务,默认1小时,如果设置为0,标识关闭清除任务
autopurge.purgeInterval=1
#允许客户端连接设置的最小超时时间,默认2个心跳单位
minSessionTimeout=4000
#允许客户端连接设置的最大超时时间,默认是20个心跳单位,也即40s,
maxSessionTimeout=300000
#zookeeper-3 3.5.5启动默认会把AdminService服务启动,这个服务默认是8080端口
admin.serverPort=9001
#集群地址配置
server.1=spark01:2888:3888
server.2=spark02:2888:3888
server.3=spark03:2888:3888
tickTime=2000
initLimit=10
syncLimit=5
dataDir=/home/zookeeper-3/data
dataLogDir=/home/zookeeper-3/datalog
clientPort=2181
maxClientCnxns=1000
autopurge.snapRetainCount=7
autopurge.purgeInterval=1
minSessionTimeout=4000
maxSessionTimeout=300000
admin.serverPort=9001
server.1=spark01:2888:3888
server.2=spark02:2888:3888
server.3=spark03:2888:3888
2.2 保存后根据配置文件创建目录
在每台服务器上执行
mkdir -p /home/zookeeper-3/data
mkdir -p /home/zookeeper-3/datalog
2.3 myid
spark01
echo 1 > /home/zookeeper-3/data/myid
more /home/zookeeper-3/data/myid
spark02
echo 2 > /home/zookeeper-3/data/myid
more /home/zookeeper-3/data/myid
spark03
echo 3 > /home/zookeeper-3/data/myid
more /home/zookeeper-3/data/myid
2.4 编写zookeeper-3开机启动脚本
在/etc/systemd/system/文件夹下创建一个启动脚本zookeeper-3.service
注意:在每台服务器上编写
cd /etc/systemd/system
vim zookeeper.service
内容如下:
[Unit]
Description=zookeeper
After=syslog.target network.target[Service]
Type=forking
# 指定zookeeper-3 日志文件路径,也可以在zkServer.sh 中定义
Environment=ZOO_LOG_DIR=/home/zookeeper-3/datalog
# 指定JDK路径,也可以在zkServer.sh 中定义
Environment=JAVA_HOME=/opt/soft/jdk-8
ExecStart=/opt/soft/zookeeper-3/bin/zkServer.sh start
ExecStop=/opt/soft/zookeeper-3/bin/zkServer.sh stop
Restart=always
User=root
Group=root[Install]
WantedBy=multi-user.target
[Unit]
Description=zookeeper
After=syslog.target network.target[Service]
Type=forking
Environment=ZOO_LOG_DIR=/home/zookeeper-3/datalog
Environment=JAVA_HOME=/opt/soft/jdk-8
ExecStart=/opt/soft/zookeeper-3/bin/zkServer.sh start
ExecStop=/opt/soft/zookeeper-3/bin/zkServer.sh stop
Restart=always
User=root
Group=root[Install]
WantedBy=multi-user.target
systemctl daemon-reload
# 等所有主机配置好后再执行以下命令
systemctl start zookeeper
systemctl enable zookeeper
systemctl status zookeeper
3. hadoop
修改配置文件
cd $HADOOP_HOME/etc/hadoop
- hadoop-env.sh
- core-site.xml
- hdfs-site.xml
- workers
- mapred-site.xml
- yarn-site.xml
hadoop-env.sh 文件末尾追加
export JAVA_HOME=/opt/soft/jdk-8
export HADOOP_OPTS="--add-opens java.base/java.lang=ALL-UNNAMED"export HDFS_NAMENODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_ZKFC_USER=root
export HDFS_JOURNALNODE_USER=rootexport YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=rootcore-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--Licensed under the Apache License, Version 2.0 (the "License");you may not use this file except in compliance with the License.You may obtain a copy of the License athttp://www.apache.org/licenses/LICENSE-2.0Unless required by applicable law or agreed to in writing, softwaredistributed under the License is distributed on an "AS IS" BASIS,WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.See the License for the specific language governing permissions andlimitations under the License. See accompanying LICENSE file.
--><!-- Put site-specific property overrides in this file. --><configuration><property><name>fs.defaultFS</name><value>hdfs://lihaozhe</value></property><property><name>hadoop.tmp.dir</name><value>/home/hadoop/data</value></property><property><name>ha.zookeeper.quorum</name><value>spark01:2181,spark02:2181,spark03:2181</value></property><property><name>hadoop.http.staticuser.user</name><value>root</value></property><property><name>dfs.permissions.enabled</name><value>false</value></property><property><name>hadoop.proxyuser.root.hosts</name><value>*</value></property><property><name>hadoop.proxyuser.root.groups</name><value>*</value></property>
</configuration>hdfs-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--Licensed under the Apache License, Version 2.0 (the "License");you may not use this file except in compliance with the License.You may obtain a copy of the License athttp://www.apache.org/licenses/LICENSE-2.0Unless required by applicable law or agreed to in writing, softwaredistributed under the License is distributed on an "AS IS" BASIS,WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.See the License for the specific language governing permissions andlimitations under the License. See accompanying LICENSE file.
--><!-- Put site-specific property overrides in this file. --><configuration><property><name>dfs.nameservices</name><value>lihaozhe</value></property><property><name>dfs.ha.namenodes.lihaozhe</name><value>nn1,nn2</value></property><property><name>dfs.namenode.rpc-address.lihaozhe.nn1</name><value>spark01:8020</value></property><property><name>dfs.namenode.rpc-address.lihaozhe.nn2</name><value>spark02:8020</value></property><property><name>dfs.namenode.http-address.lihaozhe.nn1</name><value>spark01:9870</value></property><property><name>dfs.namenode.http-address.lihaozhe.nn2</name><value>spark02:9870</value></property><property><name>dfs.namenode.shared.edits.dir</name><value>qjournal://spark01:8485;spark02:8485;spark03:8485/lihaozhe</value></property><property><name>dfs.client.failover.proxy.provider.lihaozhe</name><value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value></property><property><name>dfs.ha.fencing.methods</name><value>sshfence</value></property><property><name>dfs.ha.fencing.ssh.private-key-files</name><value>/root/.ssh/id_rsa</value></property><property><name>dfs.journalnode.edits.dir</name><value>/home/hadoop/journalnode/data</value></property><property><name>dfs.ha.automatic-failover.enabled</name><value>true</value></property><property><name>dfs.safemode.threshold.pct</name><value>1</value></property>
</configuration>workers
spark01
spark02
spark03
mapred-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--Licensed under the Apache License, Version 2.0 (the "License");you may not use this file except in compliance with the License.You may obtain a copy of the License athttp://www.apache.org/licenses/LICENSE-2.0Unless required by applicable law or agreed to in writing, softwaredistributed under the License is distributed on an "AS IS" BASIS,WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.See the License for the specific language governing permissions andlimitations under the License. See accompanying LICENSE file.
--><!-- Put site-specific property overrides in this file. --><configuration><property><name>mapreduce.framework.name</name><value>yarn</value></property><property><name>mapreduce.application.classpath</name><value>$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/*:$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/lib/*</value></property><!-- yarn历史服务端口 --><property><name>mapreduce.jobhistory.address</name><value>spark01:10020</value></property><!-- yarn历史服务web访问端口 --><property><name>mapreduce.jobhistory.webapp.address</name><value>hadoop102:19888</value></property>
</configuration>yarn-site.xml
<?xml version="1.0"?>
<!--Licensed under the Apache License, Version 2.0 (the "License");you may not use this file except in compliance with the License.You may obtain a copy of the License athttp://www.apache.org/licenses/LICENSE-2.0Unless required by applicable law or agreed to in writing, softwaredistributed under the License is distributed on an "AS IS" BASIS,WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.See the License for the specific language governing permissions andlimitations under the License. See accompanying LICENSE file.
-->
<configuration><!-- Site specific YARN configuration properties --><property><name>yarn.resourcemanager.ha.enabled</name><value>true</value></property><property><name>yarn.resourcemanager.cluster-id</name><value>cluster1</value></property><property><name>yarn.resourcemanager.ha.rm-ids</name><value>rm1,rm2</value></property><property><name>yarn.resourcemanager.hostname.rm1</name><value>spark01</value></property><property><name>yarn.resourcemanager.hostname.rm2</name><value>spark02</value></property><property><name>yarn.resourcemanager.webapp.address.rm1</name><value>spark01:8088</value></property><property><name>yarn.resourcemanager.webapp.address.rm2</name><value>spark02:8088</value></property><property><name>yarn.resourcemanager.zk-address</name><value>spark01:2181,spark02:2181,spark03:2181</value></property><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property><property><name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name><value>org.apache.hadoop.mapred.ShuffleHandler</value></property><property><name>yarn.nodemanager.env-whitelist</name><value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value></property><!-- 是否将对容器实施物理内存限制 --><property><name>yarn.nodemanager.pmem-check-enabled</name><value>false</value></property><!-- 是否将对容器实施虚拟内存限制。 --><property><name>yarn.nodemanager.vmem-check-enabled</name><value>false</value></property><!-- 开启日志聚集 --><property><name>yarn.log-aggregation-enable</name><value>true</value></property><!-- 设置yarn历史服务器地址 --><property><name>yarn.log.server.url</name><value>http://spark01:19888/jobhistory/logs</value></property><!-- 保存的时间7天 --><property><name>yarn.log-aggregation.retain-seconds</name><value>604800</value></property>
</configuration>4. 配置ssh免密钥登录
创建本地秘钥并将公共秘钥写入认证文件
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
ssh-copy-id root@spark01
ssh-copy-id root@spark02
ssh-copy-id root@spark03
ssh root@spark01
exit
ssh root@spark02
exit
ssh root@spark03
exit
5. 分发软件和配置文件
scp -r /etc/profile.d root@spark02:/etc
scp -r /etc/profile.d root@spark03:/etc
scp -r /opt/soft/zookeeper-3 root@spark02:/opt/soft
scp -r /opt/soft/zookeeper-3 root@spark03:/opt/soft
scp -r /opt/soft/hadoop-3/etc/hadoop/* root@spark02:/opt/soft/hadoop-3/etc/hadoop/
scp -r /opt/soft/hadoop-3/etc/hadoop/* root@spark03:/opt/soft/hadoop-3/etc/hadoop/
6. 在各服务器上使环境变量生效
source /etc/profile
7. 启动zookeeper
7.1 myid
spark01
echo 1 > /home/zookeeper-3/data/myid
more /home/zookeeper-3/data/myid
spark02
echo 2 > /home/zookeeper-3/data/myid
more /home/zookeeper-3/data/myid
spark03
echo 3 > /home/zookeeper-3/data/myid
more /home/zookeeper-3/data/myid
7.2 启动服务
在各节点执行以下命令
systemctl daemon-reload
systemctl start zookeeper
systemctl enable zookeeper
systemctl status zookeeper
7.3 验证
jps
zkServer.sh status
8. Hadoop初始化
1. 启动三个zookeeper:zkServer.sh start
2. 启动三个JournalNode:hadoop-daemon.sh start journalnode 或者 hdfs --daemon start journalnode
7. 在其中一个namenode上格式化:hdfs namenode -format
8. 把刚刚格式化之后的元数据拷贝到另外一个namenode上a) 启动刚刚格式化的namenode :hadoop-daemon.sh start namenodeb) 在没有格式化的namenode上执行:hdfs namenode -bootstrapStandbyc) 启动第二个namenode: hadoop-daemon.sh start namenode
9. 在其中一个namenode上初始化hdfs zkfc -formatZK
10. 停止上面节点:stop-dfs.sh
11. 全面启动:start-all.sh
12. 启动resourcemanager节点 yarn-daemon.sh start resourcemanager
start-yarn.shhttp://dl.bintray.com/sequenceiq/sequenceiq-bin/hadoop-native-64-2.5.0.tar高版本不需要执行第 12 步13. 启动历史服务
mapred --daemon start historyserver
14 15 16 不需要执行
14、安全模式hdfs dfsadmin -safemode enter
hdfs dfsadmin -safemode leave15、查看哪些节点是namenodes并获取其状态
hdfs getconf -namenodes
hdfs haadmin -getServiceState spark0116、强制切换状态
hdfs haadmin -transitionToActive --forcemanual spark01
重点提示:
# 关机之前 依关闭服务
stop-yarn.sh
stop-dfs.sh
# 开机后 依次开启服务
start-dfs.sh
start-yarn.sh
或者
# 关机之前关闭服务
stop-all.sh
# 开机后开启服务
start-all.sh
#jps 检查进程正常后开启胡哦关闭在再做其它操作
9. 修改windows下hosts文件
C:\Windows\System32\drivers\etc\hosts
追加以下内容:
192.168.171.101 hadoop101
192.168.171.102 hadoop102
192.168.171.103 hadoop103
Windows11 注意 修改权限
-
开始搜索 cmd
找到命令头提示符 以管理身份运行


-
进入 C:\Windows\System32\drivers\etc 目录
cd drivers/etc
-
去掉 hosts文件只读属性
attrib -r hosts
-
打开 hosts 配置文件
start hosts
-
追加以下内容后保存
192.168.171.101 spark01 192.168.171.102 spark02 192.168.171.103 spark03
10. 测试
12.1 浏览器访问hadoop集群
浏览器访问: http://spark01:9870


浏览器访问:http://spark01:8088

浏览器访问:http://spark01:19888/

12.2 测试 hdfs
本地文件系统创建 测试文件 wcdata.txt
vim wcdata.txt
Spark HBaseHive Flink
Storm Hadoop HBase SparkFlinkHBase
StormHBase Hadoop Hive
FlinkHBase Flink
Hive StormHive Flink HadoopHBase
HiveHadoop Spark HBase StormHBase
Hadoop Hive FlinkHBase Flink Hive StormHive
Flink HadoopHBase Hive
Spark HBaseHive Flink
Storm Hadoop HBase SparkFlinkHBase
StormHBase Hadoop Hive
FlinkHBase Flink
Hive StormHive Flink HadoopHBase
HiveHadoop Spark HBase StormHBase
Hadoop Hive FlinkHBase Flink Hive StormHive
Flink HadoopHBase Hive
Spark HBaseHive Flink
Storm Hadoop HBase SparkFlinkHBase
StormHBase Hadoop Hive
FlinkHBase Flink
Hive StormHive Flink HadoopHBase
HiveHadoop Spark HBase StormHBase
Hadoop Hive FlinkHBase Flink Hive StormHive
Flink HadoopHBase Hive
HiveHadoop Spark HBase StormHBase
Hadoop Hive FlinkHBase Flink Hive StormHive
Flink HadoopHBase Hive
Spark HBaseHive Flink
Storm Hadoop HBase SparkFlinkHBase
StormHBase Hadoop Hive
FlinkHBase Flink
Hive StormHive Flink HadoopHBase
HiveHadoop Spark HBase StormHBase
Hadoop Hive FlinkHBase Flink Hive StormHive
Flink HadoopHBase Hive
Spark HBaseHive Flink
Storm Hadoop HBase SparkFlinkHBase
StormHBase Hadoop Hive
HiveHadoop Spark HBase StormHBase
Hadoop Hive FlinkHBase Flink Hive StormHive
Flink HadoopHBase Hive
Spark HBaseHive Flink
Storm Hadoop HBase SparkFlinkHBase
StormHBase Hadoop Hive
FlinkHBase Flink
Hive StormHive Flink HadoopHBase
HiveHadoop Spark HBase StormHBase
Hadoop Hive FlinkHBase Flink Hive StormHive
Flink HadoopHBase Hive
Spark HBaseHive Flink
Storm Hadoop HBase SparkFlinkHBase
StormHBase Hadoop Hive
Spark HBaseHive Flink
Storm Hadoop HBase SparkFlinkHBase
StormHBase Hadoop Hive
FlinkHBase Flink
Hive StormHive Flink HadoopHBase
HiveHadoop Spark HBase StormHBase
Hadoop Hive FlinkHBase Flink Hive StormHive
Flink HadoopHBase Hive
Spark HBaseHive Flink
Storm Hadoop HBase SparkFlinkHBase
StormHBase Hadoop Hive
FlinkHBase Flink
Hive StormHive Flink HadoopHBase
HiveHadoop Spark HBase StormHBase
Hadoop Hive FlinkHBase Flink Hive StormHive
Flink HadoopHBase Hive
HiveHadoop Spark HBase StormHBase
Hadoop Hive FlinkHBase Flink Hive StormHive
Flink HadoopHBase Hive
Spark HBaseHive Flink
Storm Hadoop HBase SparkFlinkHBase
StormHBase Hadoop Hive
FlinkHBase Flink
Hive StormHive Flink HadoopHBase
HiveHadoop Spark HBase StormHBase
Hadoop Hive FlinkHBase Flink Hive StormHive
Flink HadoopHBase Hive
Spark HBaseHive Flink
Storm Hadoop HBase SparkFlinkHBase
StormHBase Hadoop Hive
Spark HBaseHive Flink
Storm Hadoop HBase SparkFlinkHBase
StormHBase Hadoop Hive
FlinkHBase Flink
Hive StormHive Flink HadoopHBase
HiveHadoop Spark HBase StormHBase
Hadoop Hive FlinkHBase Flink Hive StormHive
Flink HadoopHBase Hive
Spark HBaseHive Flink
Storm Hadoop HBase SparkFlinkHBase
StormHBase Hadoop Hive
FlinkHBase Flink
Hive StormHive Flink HadoopHBase
HiveHadoop Spark HBase StormHBase
Hadoop Hive FlinkHBase Flink Hive StormHive
Flink HadoopHBase Hive
HiveHadoop Spark HBase StormHBase
Hadoop Hive FlinkHBase Flink Hive StormHive
Flink HadoopHBase Hive
Spark HBaseHive Flink
Storm Hadoop HBase SparkFlinkHBase
StormHBase Hadoop Hive
FlinkHBase Flink
Hive StormHive Flink HadoopHBase
HiveHadoop Spark HBase StormHBase
Hadoop Hive FlinkHBase Flink Hive StormHive
Flink HadoopHBase Hive
Spark HBaseHive Flink
Storm Hadoop HBase SparkFlinkHBase
StormHBase Hadoop Hive
Spark HBaseHive Flink
Storm Hadoop HBase SparkFlinkHBase
StormHBase Hadoop Hive
FlinkHBase Flink
Hive StormHive Flink HadoopHBase
HiveHadoop Spark HBase StormHBase
Hadoop Hive FlinkHBase Flink Hive StormHive
Flink HadoopHBase Hive
Spark HBaseHive Flink
Storm Hadoop HBase SparkFlinkHBase
StormHBase Hadoop Hive
FlinkHBase Flink
Hive StormHive Flink HadoopHBase
HiveHadoop Spark HBase StormHBase
Hadoop Hive FlinkHBase Flink Hive StormHive
Flink HadoopHBase Hive
Spark HBaseHive Flink
Storm Hadoop HBase SparkFlinkHBase
StormHBase Hadoop Hive
FlinkHBase Flink
Hive StormHive Flink HadoopHBase
HiveHadoop Spark HBase StormHBase
Hadoop Hive FlinkHBase Flink Hive StormHive
Flink HadoopHBase Hive
HiveHadoop Spark HBase StormHBase
Hadoop Hive FlinkHBase Flink Hive StormHive
Flink HadoopHBase Hive
Spark HBaseHive Flink
Storm Hadoop HBase SparkFlinkHBase
StormHBase Hadoop Hive
FlinkHBase Flink
Hive StormHive Flink HadoopHBase
HiveHadoop Spark HBase StormHBase
Hadoop Hive FlinkHBase Flink Hive StormHive
Flink HadoopHBase Hive
Spark HBaseHive Flink
Storm Hadoop HBase SparkFlinkHBase
StormHBase Hadoop Hive
HiveHadoop Spark HBase StormHBase
Hadoop Hive FlinkHBase Flink Hive StormHive
Flink HadoopHBase Hive
Spark HBaseHive Flink
Storm Hadoop HBase SparkFlinkHBase
StormHBase Hadoop Hive
FlinkHBase Flink
Hive StormHive Flink HadoopHBase
HiveHadoop Spark HBase StormHBase
Hadoop Hive FlinkHBase Flink Hive StormHive
Flink HadoopHBase Hive
Spark HBaseHive Flink
Storm Hadoop HBase SparkFlinkHBase
StormHBase Hadoop Hive
Spark HBaseHive Flink
Storm Hadoop HBase SparkFlinkHBase
StormHBase Hadoop Hive
FlinkHBase Flink
Hive StormHive Flink HadoopHBase
HiveHadoop Spark HBase StormHBase
Hadoop Hive FlinkHBase Flink Hive StormHive
Flink HadoopHBase Hive
Spark HBaseHive Flink
Storm Hadoop HBase SparkFlinkHBase
StormHBase Hadoop Hive
FlinkHBase Flink
Hive StormHive Flink HadoopHBase
HiveHadoop Spark HBase StormHBase
Hadoop Hive FlinkHBase Flink Hive StormHive
Flink HadoopHBase Hive
HiveHadoop Spark HBase StormHBase
Hadoop Hive FlinkHBase Flink Hive StormHive
Flink HadoopHBase Hive
Spark HBaseHive Flink
Storm Hadoop HBase SparkFlinkHBase
StormHBase Hadoop Hive
FlinkHBase Flink
Hive StormHive Flink HadoopHBase
HiveHadoop Spark HBase StormHBase
Hadoop Hive FlinkHBase Flink Hive StormHive
Flink HadoopHBase Hive
Spark HBaseHive Flink
Storm Hadoop HBase SparkFlinkHBase
StormHBase Hadoop Hive
Spark HBaseHive Flink
Storm Hadoop HBase SparkFlinkHBase
StormHBase Hadoop Hive
FlinkHBase Flink
Hive StormHive Flink HadoopHBase
HiveHadoop Spark HBase StormHBase
Hadoop Hive FlinkHBase Flink Hive StormHive
Flink HadoopHBase Hive
Spark HBaseHive Flink
Storm Hadoop HBase SparkFlinkHBase
StormHBase Hadoop Hive
FlinkHBase Flink
Hive StormHive Flink HadoopHBase
HiveHadoop Spark HBase StormHBase
Hadoop Hive FlinkHBase Flink Hive StormHive
Flink HadoopHBase Hive
HiveHadoop Spark HBase StormHBase
Hadoop Hive FlinkHBase Flink Hive StormHive
Flink HadoopHBase Hive
Spark HBaseHive Flink
Storm Hadoop HBase SparkFlinkHBase
StormHBase Hadoop Hive
FlinkHBase Flink
Hive StormHive Flink HadoopHBase
HiveHadoop Spark HBase StormHBase
Hadoop Hive FlinkHBase Flink Hive StormHive
Flink HadoopHBase Hive
Spark HBaseHive Flink
Storm Hadoop HBase SparkFlinkHBase
StormHBase Hadoop Hive
在 HDFS 上创建目录 /wordcount/input
hdfs dfs -mkdir -p /wordcount/input
查看 HDFS 目录结构
hdfs dfs -ls /
hdfs dfs -ls /wordcount
hdfs dfs -ls /wordcount/input
上传本地测试文件 wcdata.txt 到 HDFS 上 /wordcount/input
hdfs dfs -put wcdata.txt /wordcount/input
检查文件是否上传成功
hdfs dfs -ls /wordcount/input
hdfs dfs -cat /wordcount/input/wcdata.txt
12.2 测试 mapreduce
计算 PI 的值
hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.5.jar pi 10 10
单词统计
hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.5.jar wordcount /wordcount/input/wcdata.txt /wordcount/result
hdfs dfs -ls /wordcount/result
hdfs dfs -cat /wordcount/result/part-r-00000
11. 元数据
hadoop101
cd /home/hadoop_data/dfs/name/current
ls
看到如下内容:
edits_0000000000000000001-0000000000000000009 edits_inprogress_0000000000000000299 fsimage_0000000000000000298 VERSION
edits_0000000000000000010-0000000000000000011 fsimage_0000000000000000011 fsimage_0000000000000000298.md5
edits_0000000000000000012-0000000000000000298 fsimage_0000000000000000011.md5 seen_txid查看fsimage
hdfs oiv -p XML -i fsimage_0000000000000000011
将元数据内容按照指定格式读取后写入到新文件中
hdfs oiv -p XML -i fsimage_0000000000000000011 -o /opt/soft/fsimage.xml
查看edits
将元数据内容按照指定格式读取后写入到新文件中
hdfs oev -p XML -i edits_inprogress_0000000000000000299 -o /opt/soft/edit.xml
相关文章:
CentOS 搭建 Hadoop3 高可用集群
Hadoop FullyDistributed Mode 完全分布式 spark101spark102spark103192.168.171.101192.168.171.102192.168.171.103namenodenamenodejournalnodejournalnodejournalnodedatanodedatanodedatanodenodemanagernodemanagernodemanagerrecource managerrecource managerjob hist…...

ModuleNotFoundError: No module named ‘paddle.fluid.incubate.fleet‘
在使用rocketqa的时候可能会遇到下面的问题: 问题: 解决方法: 这完全是paddlepaddle的问题。 在rocketqa/utils/optimization.py出现下面的语句,这个时候直接把出错的注释掉就可以,因为它完全没有用到。(…...

【Java】Java中的引用类型
强引用(StrongReference) 通过new直接创建的对象,只要该对象还可以被其它对象使用或访问到,就不会被回收 软引用(SoftReference) 引用一个对象,该对象在系统内存溢出不足时,会自动…...

File类、方法递归
File:代表文本 IO流:读写数据 1、 File 类构建对象的方式是什么样的? File 的对象可以代表哪些东西? 注意 File 对象既可以代表文件、也可以代表文件夹。 ● File 封装的对象仅仅是一个路径名,这个路径可以是存在的,…...

MySQL - 系统库之 sys
sys 系统库用于管理和监控MySQL服务器的性能和运行状态: 用途: 性能监控和分析:sys 系统库用于监控MySQL服务器的性能和资源利用情况。它提供了各种视图和函数,用于分析查询性能、资源利用、等待事件等方面的数据。性能调优&…...
基础工具之Gin框架使用JWT(前后端分离))
GoLong的学习之路(十七)基础工具之Gin框架使用JWT(前后端分离)
文章目录 JWT安装JWT使用什么是Claims默认Claims自定义Claims生成JWT解析JWT 在gin框架中使用JWT获取Token渠道定义方法设置中间件注册路由 总结一下 JWT JWT全称JSON Web Token是一种跨域认证解决方案,属于一个开放的标准,它规定了一种Token实现方式&a…...

【代码数据】2023粤港澳大湾区金融数学建模B题分享
基于中国特色估值体系的股票模型分析和投资策略 首先非常建议大家仔细的阅读这个题的题目介绍,还有附赠的就是那个附件里的那几篇材料,我觉得你把这些内容读透理解了,就可以完成大部分内容。然后对于题目里它主要第一部分给出了常用的估值模…...
)
大数据之LibrA数据库系统告警处理(ALM-12006 节点故障)
告警解释 Controller按30秒周期检测NodeAgent状态。当Controller连续三次未接收到某个NodeAgent的状态报告时,产生该告警。 当Controller可以正常接收时,告警恢复。 告警属性 告警ID 告警级别 可自动清除 12006 严重 是 告警参数 参数名称 参…...

poi兴趣点推荐数据集介绍
介绍 foursquare数据集包含2153471个用户,1143092个场所,1021970个签到,27098490个社交关系以及用户分配给场所的2809581评级,我们常用的是根据NYC和TKY都是从该数据集中抽取出来的。 下载地址:https://sites.google.…...

把两个4点的结构相加
( A, B )---3*30*2---( 1, 0 )( 0, 1 ) 让网络的输入只有3个节点,训练集中只有5张图片,让A中有4个1,B全是0,排列组合,统计迭代次数并排序。 其中有3个结构 3差值结构 迭代次数 4差值结构 迭代次数 31 3-2 0 1 …...
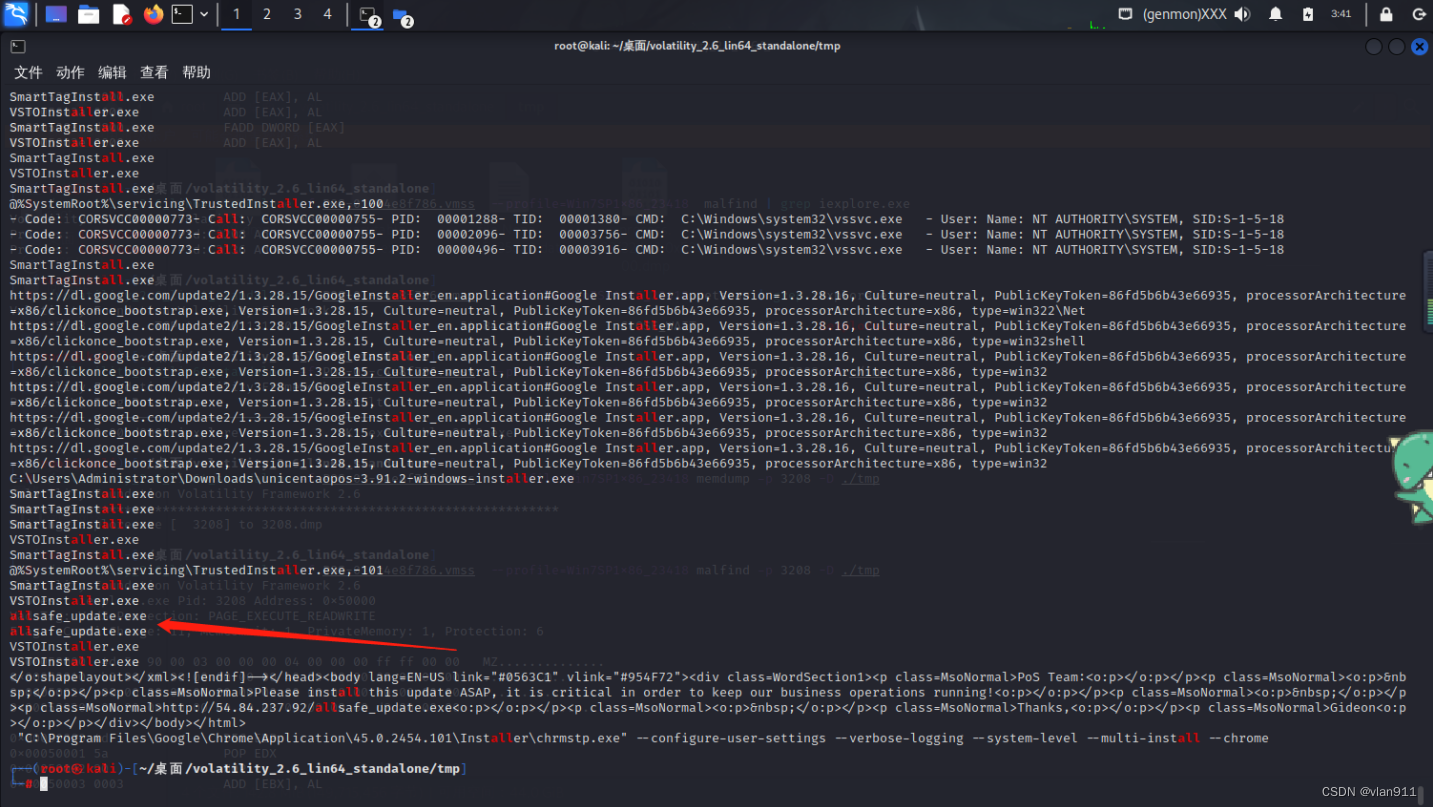
windows内存取证-中等难度-下篇
上文我们对第一台Target机器进行内存取证,今天我们继续往下学习,内存镜像请从上篇获取,这里不再进行赘述 Gideon 攻击者访问了“Gideon”,他们向AllSafeCyberSec域控制器窃取文件,他们使用的密码是什么? 攻击者执…...

代码随想录算法训练营第7天|454 四数相加II 383. 赎金信 15.三数之和 18 四数之和
JAVA代码编写 454. 四数相加 II 给你四个整数数组 nums1、nums2、nums3 和 nums4 ,数组长度都是 n ,请你计算有多少个元组 (i, j, k, l) 能满足: 0 < i, j, k, l < nnums1[i] nums2[j] nums3[k] nums4[l] 0 示例 1:…...
负载均衡深度解析:算法、策略与Nginx实践
引言 如今,网站和应用服务面临着巨大的访问流量,如何高效、稳定地处理这些流量成为了一个亟待解决的问题。负载均衡技术因此应运而生,它通过将流量合理分配到多个服务器上,不仅优化了资源的利用率,还大大提升了系统的…...

7. 一文快速学懂常用工具——Makefile
本章讲解知识点 引言MakefileMakefile 入门本专栏适合于软件开发刚入职的学生或人士,有一定的编程基础,帮助大家快速掌握工作中必会的工具和指令。本专栏针对面试题答案进行了优化,尽量做到好记、言简意赅。如专栏内容有错漏,欢迎在评论区指出或私聊我更改,一起学习,共同…...

[ACTF2023]复现
MDH 源题: from hashlib import sha256 from secret import flagr 128 c 96 p 308955606868885551120230861462612873078105583047156930179459717798715109629 Fp GF(p)def gen():a1 random_matrix(Fp, r, c)a2 random_matrix(Fp, r, c)A a1 * a2.Treturn…...
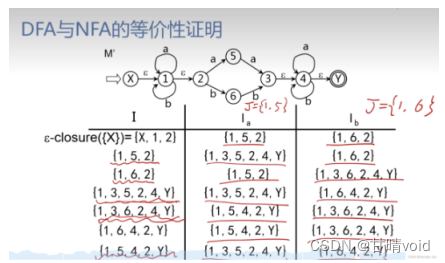
HNU-编译原理-讨论课1
讨论课安排:2次4学时,分别完成四大主题讨论 分组:每个班分为8组,每组4~5人,自选组长1人 要求和说明: 以小组为单位上台报告;每次每组汇报2个小主题,每组按要求在2个小主题中各选1…...

【Linux】关于Nginx的详细使用,部署项目
前言: 今天小编给大家带来的是关于Nginx的详细使用,部署项目,希望可以给正在学习,工作的你带来有效的帮助! 一,Nginx简介 Nginx是一个高性能的开源Web服务器和反向代理服务器。它最初由Igor Sysoev在2004年…...

编写 navigation2 控制器插件
简介 本教程展示了如何创建自己的控制器插件。在本教程中,我们将基于这篇论文实现纯追踪路径跟踪算法。建议您阅读该论文。 注意:本教程基于 Nav2 堆栈中以前存在的简化版本的 Regulated Pure Pursuit 控制器。您可以在此处找到与本教程相匹配的源代…...

计算机网络 第六章应用层
文章目录 1 应用层功能概述2 网络应用模型:客户服务器(CS)3 网络应用模型:PeerToPeer(P2P)4 域名和域名系统5 常见域名解析服务器6 两种域名解析过程7 什么是FTP8 FTP的工作原理9 EMail的组成 1 应用层功能概述 2 网络应用模型:客户服务器(CS…...
)
人工智能领域CCF推荐国际学术刊物最新目录(全)
2021年1月,CCF决定启动新一轮中国计算机学会推荐国际学术会议和期刊目录调整工作并委托CCF学术工作委员会组织实施。 2023年3月8日, 中国计算机学会正式发布了2022版《中国计算机学会推荐国际学术会议和期刊目录》(以下简称《目录》) 。 相较于上一版目录࿰…...

BetterGI:解放双手的5大自动化场景终极解决方案
BetterGI:解放双手的5大自动化场景终极解决方案 【免费下载链接】better-genshin-impact 📦BetterGI 更好的原神 - 自动拾取 | 自动剧情 | 全自动钓鱼(AI) | 全自动七圣召唤 | 自动伐木 | 自动刷本 | 自动采集/挖矿/锄地 | 一条龙 | 全连音游 | 自动烹饪…...

FanControl终极指南:5步实现Windows风扇智能控制,让电脑散热更安静更高效
FanControl终极指南:5步实现Windows风扇智能控制,让电脑散热更安静更高效 【免费下载链接】FanControl.Releases This is the release repository for Fan Control, a highly customizable fan controlling software for Windows. 项目地址: https://g…...

Loop:终极免费开源Mac窗口管理工具,彻底解决桌面杂乱问题
Loop:终极免费开源Mac窗口管理工具,彻底解决桌面杂乱问题 【免费下载链接】Loop Window management made elegant. 项目地址: https://gitcode.com/GitHub_Trending/lo/Loop 你是否曾经因为Mac上杂乱的窗口布局而效率低下?当多个应用同…...

《元创力》纪实录·卷宗2.1对话态对位法的预习:在“审查通过”与“舆论倒查”之间
叙事背景:最近关于姚晨因《监狱来的妈妈》在国际获奖而微博发声评论引发广泛关注和讨论,由于媒体出现一份判决文书,群众发现《监狱来的妈妈》电影的叙事内容与判决文书不符,引发了舆论声讨,姚晨被迫道歉,删…...

3分钟掌握Ditto:物联网设备管理的数字孪生革命
3分钟掌握Ditto:物联网设备管理的数字孪生革命 【免费下载链接】ditto Eclipse Ditto™: Digital Twin framework of Eclipse IoT - main repository 项目地址: https://gitcode.com/gh_mirrors/ditto6/ditto 还在为管理成千上万的物联网设备而头疼吗&#x…...

Mermaid在线编辑器:5分钟掌握专业图表制作的终极指南
Mermaid在线编辑器:5分钟掌握专业图表制作的终极指南 【免费下载链接】mermaid-live-editor Edit, preview and share mermaid charts/diagrams. New implementation of the live editor. 项目地址: https://gitcode.com/GitHub_Trending/me/mermaid-live-editor …...

开发者在进行多轮对话应用测试时如何利用Taotoken快速切换模型对比
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 开发者在进行多轮对话应用测试时如何利用Taotoken快速切换模型对比 在开发基于大语言模型的多轮对话应用时,评估不同模…...

MASA模组全家桶中文资源包:为中文玩家打造的无缝本地化体验终极指南
MASA模组全家桶中文资源包:为中文玩家打造的无缝本地化体验终极指南 【免费下载链接】masa-mods-chinese 一个masa mods的汉化资源包 项目地址: https://gitcode.com/gh_mirrors/ma/masa-mods-chinese 你是否曾经在Minecraft中面对MASA模组复杂的英文界面感到…...

跨平台资源包管理工具VPKEdit:游戏开发者的终极解决方案
跨平台资源包管理工具VPKEdit:游戏开发者的终极解决方案 【免费下载链接】VPKEdit A CLI/GUI tool to create, read, and write several pack file formats. 项目地址: https://gitcode.com/gh_mirrors/vp/VPKEdit 在游戏开发和MOD制作过程中,资源…...

终极解密:如何使用unluac工具实现Lua字节码逆向工程
终极解密:如何使用unluac工具实现Lua字节码逆向工程 【免费下载链接】unluac fork from http://hg.code.sf.net/p/unluac/hgcode 项目地址: https://gitcode.com/gh_mirrors/un/unluac unluac是一款专业的Lua 5.x字节码反编译工具,能够将编译后的…...